Spotlight Poster
Qidong Liu · Xian Wu · Yejing Wang · Zijian Zhang · Feng Tian · Yefeng Zheng · Xiangyu Zhao
[ East Exhibit Hall A-C ]
Abstract
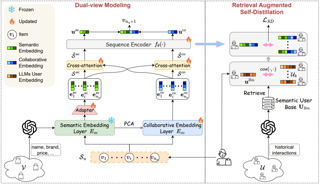
Sequential recommender systems (SRS) aim to predict users' subsequent choices based on their historical interactions and have found applications in diverse fields such as e-commerce and social media. However, in real-world systems, most users interact with only a handful of items, while the majority of items are seldom consumed. These two issues, known as the long-tail user and long-tail item challenges, often pose difficulties for existing SRS. These challenges can adversely affect user experience and seller benefits, making them crucial to address. Though a few works have addressed the challenges, they still struggle with the seesaw or noisy issues due to the intrinsic scarcity of interactions. The advancements in large language models (LLMs) present a promising solution to these problems from a semantic perspective. As one of the pioneers in this field, we propose the Large Language Models Enhancement framework for Sequential Recommendation (LLM-ESR). This framework utilizes semantic embeddings derived from LLMs to enhance SRS without adding extra inference load. To address the long-tail item challenge, we design a dual-view modeling framework that combines semantics from LLMs and collaborative signals from conventional SRS. For the long-tail user challenge, we propose a retrieval augmented self-distillation method to enhance user preference representation …
Spotlight Poster
Bobak Kiani · Lukas Fesser · Melanie Weber
[ East Exhibit Hall A-C ]

Abstract
Data with geometric structure is ubiquitous in machine learning often arising from fundamental symmetries in a domain, such as permutation-invariance in graphs and translation-invariance in images. Group-convolutional architectures, which encode symmetries as inductive bias, have shown great success in applications, but can suffer from instabilities as their depth increases and often struggle to learn long range dependencies in data. For instance, graph neural networks experience instability due to the convergence of node representations (over-smoothing), which can occur after only a few iterations of message-passing, reducing their effectiveness in downstream tasks. Here, we propose and study unitary group convolutions, which allow for deeper networks that are more stable during training. The main focus of the paper are graph neural networks, where we show that unitary graph convolutions provably avoid over-smoothing. Our experimental results confirm that unitary graph convolutional networks achieve competitive performance on benchmark datasets compared to state-of-the-art graph neural networks. We complement our analysis of the graph domain with the study of general unitary convolutions and analyze their role in enhancing stability in general group convolutional architectures.
Spotlight Poster
Zhenxiong Tan · Kaixin Wang · Xinchao Wang
[ West Ballroom A-D ]
Abstract
Procedurally generated environments such as Procgen Benchmark provide a testbed for evaluating the agent's ability to robustly learn a relevant skill, by situating the agent in ever-changing levels. The diverse levels associated with varying contexts are naturally connected to curriculum learning. Existing works mainly focus on arranging the levels to explicitly form a curriculum. In this work, we take a close look at the learning process itself under the multi-level training in Procgen. Interestingly, the learning process exhibits a gradual shift from easy contexts to hard contexts, suggesting an implicit curriculum in multi-level training. Our analysis is made possible through C-Procgen, a benchmark we build upon Procgen that enables explicit control of the contexts. We believe our findings will foster a deeper understanding of learning in diverse contexts, and our benchmark will benefit future research in curriculum reinforcement learning.
Spotlight Poster
Yann Dauphin · Atish Agarwala · Hossein Mobahi
[ East Exhibit Hall A-C ]
Abstract
Recent work has shown that methods that regularize second order information like SAM can improve generalization in deep learning. Seemingly similar methods like weight noise and gradient penalties often fail to provide such benefits. We investigate this inconsistency and reveal its connection to the the structure of the Hessian of the loss. Specifically, its decomposition into the positive semi-definite Gauss-Newton matrix and an indefinite matrix, which we call the Nonlinear Modeling Error (NME) matrix. Previous studies have largely overlooked the significance of the NME in their analysis for various reasons. However, we provide empirical and theoretical evidence that the NME is important to the performance of gradient penalties and explains their sensitivity to activation functions. We also provide evidence that the difference in regularization performance between gradient penalties and weight noise can be explained by the NME. Our findings emphasize the necessity of considering the NME in both experimental design and theoretical analysis for sharpness regularization.
Spotlight Poster
Jianzong Wu · Xiangtai Li · Yanhong Zeng · Jiangning Zhang · Qianyu Zhou · Yining Li · Yunhai Tong · Kai Chen
[ East Exhibit Hall A-C ]
Abstract
In this work, we present MotionBooth, an innovative framework designed for animating customized subjects with precise control over both object and camera movements. By leveraging a few images of a specific object, we efficiently fine-tune a text-to-video model to capture the object's shape and attributes accurately. Our approach presents subject region loss and video preservation loss to enhance the subject's learning performance, along with a subject token cross-attention loss to integrate the customized subject with motion control signals. Additionally, we propose training-free techniques for managing subject and camera motions during inference. In particular, we utilize cross-attention map manipulation to govern subject motion and introduce a novel latent shift module for camera movement control as well. MotionBooth excels in preserving the appearance of subjects while simultaneously controlling the motions in generated videos. Extensive quantitative and qualitative evaluations demonstrate the superiority and effectiveness of our method. Models and codes will be made publicly available.
Spotlight Poster
Chengyu Fang · Chunming He · Fengyang Xiao · Yulun Zhang · Longxiang Tang · Yuelin Zhang · Kai Li · Xiu Li
[ East Exhibit Hall A-C ]
Abstract
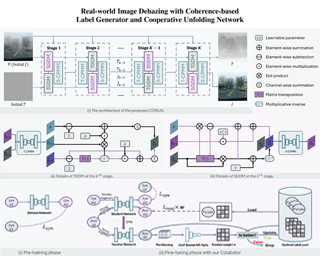
Real-world Image Dehazing (RID) aims to alleviate haze-induced degradation in real-world settings. This task remains challenging due to the complexities in accurately modeling real haze distributions and the scarcity of paired real-world data. To address these challenges, we first introduce a cooperative unfolding network that jointly models atmospheric scattering and image scenes, effectively integrating physical knowledge into deep networks to restore haze-contaminated details. Additionally, we propose the first RID-oriented iterative mean-teacher framework, termed the Coherence-based Label Generator, to generate high-quality pseudo labels for network training. Specifically, we provide an optimal label pool to store the best pseudo-labels during network training, leveraging both global and local coherence to select high-quality candidates and assign weights to prioritize haze-free regions. We verify the effectiveness of our method, with experiments demonstrating that it achieves state-of-the-art performance on RID tasks. Code will be available at https://github.com/cnyvfang/CORUN-Colabator.
Spotlight Poster
Benno Krojer · Dheeraj Vattikonda · Luis Lara · Varun Jampani · Eva Portelance · Chris Pal · Siva Reddy
[ East Exhibit Hall A-C ]

Abstract
An image editing model should be able to perform diverse edits, ranging from object replacement, changing attributes or style, to performing actions or movement, which require many forms of reasoning. Current *general* instruction-guided editing models have significant shortcomings with action and reasoning-centric edits.Object, attribute or stylistic changes can be learned from visually static datasets. On the other hand, high-quality data for action and reasoning-centric edits is scarce and has to come from entirely different sources that cover e.g. physical dynamics, temporality and spatial reasoning.To this end, we meticulously curate the **A**U**RO**R**A** Dataset (**A**ction-**R**easoning-**O**bject-**A**ttribute), a collection of high-quality training data, human-annotated and curated from videos and simulation engines.We focus on a key aspect of quality training data: triplets (source image, prompt, target image) contain a single meaningful visual change described by the prompt, i.e., *truly minimal* changes between source and target images.To demonstrate the value of our dataset, we evaluate an **A**U**RO**R**A**-finetuned model on a new expert-curated benchmark (**A**U**RO**R**A-Bench**) covering 8 diverse editing tasks.Our model significantly outperforms previous editing models as judged by human raters.For automatic evaluations, we find important flaws in previous metrics and caution their use for semantically hard editing tasks.Instead, we propose a new automatic metric that focuses …
Spotlight Poster
Shakiba Kheradmand · Daniel Rebain · Gopal Sharma · Weiwei Sun · Yang-Che Tseng · Hossam Isack · Abhishek Kar · Andrea Tagliasacchi · Kwang Moo Yi
[ East Exhibit Hall A-C ]
Abstract
While 3D Gaussian Splatting has recently become popular for neural rendering, current methods rely on carefully engineered cloning and splitting strategies for placing Gaussians, which does not always generalize and may lead to poor-quality renderings. For many real-world scenes this leads to their heavy dependence on good initializations. In this work, we rethink the set of 3D Gaussians as a random sample drawn from an underlying probability distribution describing the physical representation of the scene—in other words, Markov Chain Monte Carlo (MCMC) samples. Under this view, we show that the 3D Gaussian updates can be converted as Stochastic Gradient Langevin Dynamics (SGLD) update by simply introducing noise. We then rewrite the densification and pruning strategies in 3D Gaussian Splatting as simply a deterministic state transition of MCMC samples, removing these heuristics from the framework. To do so, we revise the ‘cloning’ of Gaussians into a relocalization scheme that approximately preserves sample probability. To encourage efficient use of Gaussians, we introduce an L1-regularizer on the Gaussians. On various standard evaluation scenes, we show that our method provides improved rendering quality, easy control over the number of Gaussians, and robustness to initialization. The project website is available at https://3dgs-mcmc.github.io/.
Spotlight Poster
Alex Hägele · Elie Bakouch · Atli Kosson · Loubna Ben allal · Leandro Von Werra · Martin Jaggi
[ East Exhibit Hall A-C ]
Abstract
Scale has become a main ingredient in obtaining strong machine learning models. As a result, understanding a model's scaling properties is key to effectively designing both the right training setup as well as future generations of architectures. In this work, we argue that scale and training research has been needlessly complex due to reliance on the cosine schedule, which prevents training across different lengths for the same model size. We investigate the training behavior of a direct alternative --- constant learning rate and cooldowns --- and find that it scales predictably and reliably similar to cosine. Additionally, we show that stochastic weight averaging yields improved performance along the training trajectory, without additional training costs, across different scales. Importantly, with these findings we demonstrate that scaling experiments can be performed with significantly reduced compute and GPU hours by utilizing fewer but reusable training runs. Our code is available at https://github.com/epfml/schedules-and-scaling/.
Spotlight Poster
Joel Oskarsson · Tomas Landelius · Marc Deisenroth · Fredrik Lindsten
[ East Exhibit Hall A-C ]

Abstract
In recent years, machine learning has established itself as a powerful tool for high-resolution weather forecasting. While most current machine learning models focus on deterministic forecasts, accurately capturing the uncertainty in the chaotic weather system calls for probabilistic modeling. We propose a probabilistic weather forecasting model called Graph-EFM, combining a flexible latent-variable formulation with the successful graph-based forecasting framework. The use of a hierarchical graph construction allows for efficient sampling of spatially coherent forecasts. Requiring only a single forward pass per time step, Graph-EFM allows for fast generation of arbitrarily large ensembles. We experiment with the model on both global and limited area forecasting. Ensemble forecasts from Graph-EFM achieve equivalent or lower errors than comparable deterministic models, with the added benefit of accurately capturing forecast uncertainty.
Spotlight Poster
Quoc Trung Trinh · Markus Heinonen · Luigi Acerbi · Samuel Kaski
[ East Exhibit Hall A-C ]

Abstract
Deep neural networks (DNNs) excel on clean images but struggle with corrupted ones. Incorporating specific corruptions into the data augmentation pipeline can improve robustness to those corruptions but may harm performance on clean images and other types of distortion. In this paper, we introduce an alternative approach that improves the robustness of DNNs to a wide range of corruptions without compromising accuracy on clean images. We first demonstrate that input perturbations can be mimicked by multiplicative perturbations in the weight space. Leveraging this, we propose Data Augmentation via Multiplicative Perturbation (DAMP), a training method that optimizes DNNs under random multiplicative weight perturbations. We also examine the recently proposed Adaptive Sharpness-Aware Minimization (ASAM) and show that it optimizes DNNs under adversarial multiplicative weight perturbations. Experiments on image classification datasets (CIFAR-10/100, TinyImageNet and ImageNet) and neural network architectures (ResNet50, ViT-S/16, ViT-B/16) show that DAMP enhances model generalization performance in the presence of corruptions across different settings. Notably, DAMP is able to train a ViT-S/16 on ImageNet from scratch, reaching the top-1 error of 23.7% which is comparable to ResNet50 without extensive data augmentations.
Spotlight Poster
Robert Garrett · Trevor Harris · Zhuo Wang · Bo Li
[ East Exhibit Hall A-C ]
Abstract
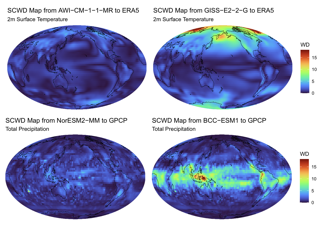
The validation of global climate models is crucial to ensure the accuracy and efficacy of model output. We introduce the spherical convolutional Wasserstein distance to more comprehensively measure differences between climate models and reanalysis data. This new similarity measure accounts for spatial variability using convolutional projections and quantifies local differences in the distribution of climate variables. We apply this method to evaluate the historical model outputs of the Coupled Model Intercomparison Project (CMIP) members by comparing them to observational and reanalysis data products. Additionally, we investigate the progression from CMIP phase 5 to phase 6 and find modest improvements in the phase 6 models regarding their ability to produce realistic climatologies.
Spotlight Poster
Jaivardhan Kapoor · Auguste Schulz · Julius Vetter · Felix Pei · Richard Gao · Jakob H Macke
[ East Exhibit Hall A-C ]
Abstract
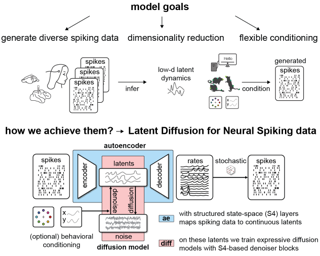
Modern datasets in neuroscience enable unprecedented inquiries into the relationship between complex behaviors and the activity of many simultaneously recorded neurons. While latent variable models can successfully extract low-dimensional embeddings from such recordings, using them to generate realistic spiking data, especially in a behavior-dependent manner, still poses a challenge. Here, we present Latent Diffusion for Neural Spiking data (LDNS), a diffusion-based generative model with a low-dimensional latent space: LDNS employs an autoencoder with structured state-space (S4) layers to project discrete high-dimensional spiking data into continuous time-aligned latents. On these inferred latents, we train expressive (conditional) diffusion models, enabling us to sample neural activity with realistic single-neuron and population spiking statistics. We validate LDNS on synthetic data, accurately recovering latent structure, firing rates, and spiking statistics. Next, we demonstrate its flexibility by generating variable-length data that mimics human cortical activity during attempted speech. We show how to equip LDNS with an expressive observation model that accounts for single-neuron dynamics not mediated by the latent state, further increasing the realism of generated samples. Finally, conditional LDNS trained on motor cortical activity during diverse reaching behaviors can generate realistic spiking data given reach direction or unseen reach trajectories. In summary, LDNS simultaneously enables …
Spotlight Poster
Nadav Merlis · Dorian Baudry · Vianney Perchet
[ West Ballroom A-D ]

Abstract
In reinforcement learning (RL), agents sequentially interact with changing environments while aiming to maximize the obtained rewards. Usually, rewards are observed only _after_ acting, and so the goal is to maximize the _expected_ cumulative reward. Yet, in many practical settings, reward information is observed in advance -- prices are observed before performing transactions; nearby traffic information is partially known; and goals are oftentimes given to agents prior to the interaction. In this work, we aim to quantifiably analyze the value of such future reward information through the lens of _competitive analysis. In particular, we measure the ratio between the value of standard RL agents and that of agents with partial future-reward lookahead. We characterize the worst-case reward distribution and derive exact ratios for the worst-case reward expectations. Surprisingly, the resulting ratios relate to known quantities in offline RL and reward-free exploration. We further provide tight bounds for the ratio given the worst-case dynamics. Our results cover the full spectrum between observing the immediate rewards before acting to observing all the rewards before the interaction starts.
Spotlight Poster
Guowen Zhang · Lue Fan · Chenhang HE · Zhen Lei · ZHAO-XIANG ZHANG · Lei Zhang
[ East Exhibit Hall A-C ]

Abstract
Serialization-based methods, which serialize the 3D voxels and group them into multiple sequences before inputting to Transformers, have demonstrated their effectiveness in 3D object detection. However, serializing 3D voxels into 1D sequences will inevitably sacrifice the voxel spatial proximity. Such an issue is hard to be addressed by enlarging the group size with existing serialization-based methods due to the quadratic complexity of Transformers with feature sizes. Inspired by the recent advances of state space models (SSMs), we present a Voxel SSM, termed as Voxel Mamba, which employs a group-free strategy to serialize the whole space of voxels into a single sequence. The linear complexity of SSMs encourages our group-free design, alleviating the loss of spatial proximity of voxels. To further enhance the spatial proximity, we propose a Dual-scale SSM Block to establish a hierarchical structure, enabling a larger receptive field in the 1D serialization curve, as well as more complete local regions in 3D space. Moreover, we implicitly apply window partition under the group-free framework by positional encoding, which further enhances spatial proximity by encoding voxel positional information. Our experiments on Waymo Open Dataset and nuScenes dataset show that Voxel Mamba not only achieves higher accuracy than state-of-the-art methods, but …
Spotlight Poster
Zican Dong · Junyi Li · Xin Men · Xin Zhao · Bingning Wang · Zhen Tian · weipeng chen · Ji-Rong Wen
[ East Exhibit Hall A-C ]

Abstract
Transformer-based large language models (LLMs) typically have a limited context window, resulting in significant performance degradation when processing text beyond the length of the context window. Extensive studies have been proposed to extend the context window and achieve length extrapolation of LLMs, but there is still a lack of in-depth interpretation of these approaches. In this study, we explore the positional information within and beyond the context window for deciphering the underlying mechanism of LLMs. By using a mean-based decomposition method, we disentangle positional vectors from hidden states of LLMs and analyze their formation and effect on attention. Furthermore, when texts exceed the context window, we analyze the change of positional vectors in two settings, i.e., direct extrapolation and context window extension. Based on our findings, we design two training-free context window extension methods, positional vector replacement and attention window extension. Experimental results show that our methods can effectively extend the context window length.
Spotlight Poster
Yiming Li · Zehong Wang · Yue Wang · Zhiding Yu · Zan Gojcic · Marco Pavone · Chen Feng · Jose M. Alvarez
[ East Exhibit Hall A-C ]

Abstract
Humans naturally retain memories of permanent elements, while ephemeral moments often slip through the cracks of memory. This selective retention is crucial for robotic perception, localization, and mapping. To endow robots with this capability, we introduce 3D Gaussian Mapping (3DGM), a self-supervised, camera-only offline mapping framework grounded in 3D Gaussian Splatting. 3DGM converts multitraverse RGB videos from the same region into a Gaussian-based environmental map while concurrently performing 2D ephemeral object segmentation. Our key observation is that the environment remains consistent across traversals, while objects frequently change. This allows us to exploit self-supervision from repeated traversals to achieve environment-object decomposition. More specifically, 3DGM formulates multitraverse environmental mapping as a robust 3D representation learning problem, treating pixels of the environment and objects as inliers and outliers, respectively. Using robust feature distillation, feature residual mining, and robust optimization, 3DGM simultaneously performs 2D segmentation and 3D mapping without human intervention. We build the Mapverse benchmark, sourced from the Ithaca365 and nuPlan datasets, to evaluate our method in unsupervised 2D segmentation, 3D reconstruction, and neural rendering. Extensive results verify the effectiveness and potential of our method for self-driving and robotics.
Spotlight Poster
Zhuoming Chen · Avner May · Ruslan Svirschevski · Yu-Hsun Huang · Max Ryabinin · Zhihao Jia · Beidi Chen
[ East Exhibit Hall A-C ]

Abstract
As the usage of large language models (LLMs) grows, it becomes increasingly important to serve them quickly and efficiently. While speculative decoding has recently emerged as a promising direction for accelerating LLM serving, existing methods are limited in their ability to scale to larger speculation budgets and adapt to different hyperparameters. This paper introduces Sequoia, a scalable and robust algorithm for speculative decoding. To improve scalability, Sequoia introduces a dynamic programming algorithm to find an optimal tree structure for the speculated tokens. To achieve robust speculative decoding, Sequoia uses a novel sampling and verification method that outperforms prior work across different decoding temperatures. Sequoia improves the decoding speed of Llama2-7B, Llama2-13B, and Vicuna-33B on an A100 GPU by up to $4.04\times$, $3.73\times$, and $2.27 \times$. To serve Llama3-70B-Instruct on a single L40 GPU through offloading, Sequoia reduces the per-token decoding latency to 0.60 s/token, $9.5\times$ faster than DeepSpeed-Zero-Inference.
Spotlight Poster
Vasilis Kontonis · Mingchen Ma · Christos Tzamos
[ West Ballroom A-D ]
Abstract
We study pool-based active learning, where a learner has a large pool $S$ of unlabeled examples and can adaptively ask a labeler questions to learn these labels. The goal of the learner is to output a labeling for $S$ that can compete with the best hypothesis from a given hypothesis class $\mathcal{H}$. We focus on halfspace learning, one of the most important problems in active learning.It is well known that in the standard active learning model, learning the labels of an arbitrary pool of examples labeled by some halfspace up to error $\epsilon$ requires at least $\Omega(1/\epsilon)$ queries. To overcome this difficulty, previous work designs simple but powerful query languages to achieve $O(\log(1/\epsilon))$ query complexity, but only focuses on the realizable setting where data are perfectly labeled by some halfspace.However, when labels are noisy, such queries are too fragile and lead to high query complexity even under the simple random classification noise model. In this work, we propose a new query language called threshold statistical queries and study their power for learning under various noise models. Our main algorithmic result is the first query-efficient algorithm for learning halfspaces under the popular Massart noise model. With an arbitrary dataset corrupted with …
Spotlight Poster
Chaoqi Chen · Luyao Tang · Hui Huang
[ East Exhibit Hall A-C ]
Abstract
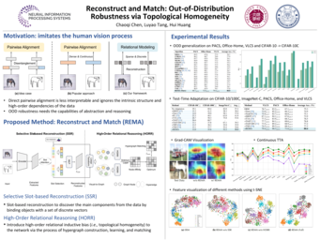
Since deep learning models are usually deployed in non-stationary environments, it is imperative to improve their robustness to out-of-distribution (OOD) data. A common approach to mitigate distribution shift is to regularize internal representations or predictors learned from in-distribution (ID) data to be domain invariant. Past studies have primarily learned pairwise invariances, ignoring the intrinsic structure and high-order dependencies of the data. Unlike machines, human recognizes objects by first dividing them into major components and then identifying the topological relation of these components. Motivated by this, we propose Reconstruct and Match (REMA), a general learning framework for object recognition tasks to endow deep models with the capability of capturing the topological homogeneity of objects without human prior knowledge or fine-grained annotations. To identify major components from objects, REMA introduces a selective slot-based reconstruction module to dynamically map dense pixels into a sparse and discrete set of slot vectors in an unsupervised manner. Then, to model high-order dependencies among these components, we propose a hypergraph-based relational reasoning module that models the intricate relations of nodes (slots) with structural constraints. Experiments on standard benchmarks show that REMA outperforms state-of-the-art methods in OOD generalization and test-time adaptation settings.
Spotlight Poster
Konstantinos Kogkalidis · Jean-Philippe Bernardy · Vikas Garg
[ East Exhibit Hall A-C ]
Abstract
We introduce a novel positional encoding strategy for Transformer-style models, addressing the shortcomings of existing, often ad hoc, approaches. Our framework implements a flexible mapping from the algebraic specification of a domain to a positional encoding scheme where positions are interpreted as orthogonal operators. This design preserves the structural properties of the source domain, thereby ensuring that the end-model upholds them. The framework can accommodate various structures, including sequences, grids and trees, but also their compositions. We conduct a series of experiments demonstrating the practical applicability of our method. Our results suggest performance on par with or surpassing the current state of the art, without hyper-parameter optimizations or ``task search'' of any kind.Code is available through https://aalto-quml.github.io/ape/.
Spotlight Poster
Paul Soulos · Henry Conklin · Mattia Opper · Paul Smolensky · Jianfeng Gao · Roland Fernandez
[ East Exhibit Hall A-C ]
Abstract
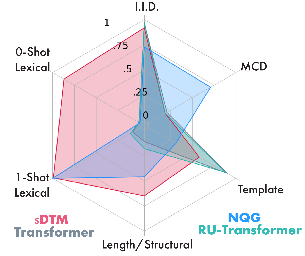
Neural networks continue to struggle with compositional generalization, and this issue is exacerbated by a lack of massive pre-training. One successful approach for developing neural systems which exhibit human-like compositional generalization is $\textit{hybrid}$ neurosymbolic techniques. However, these techniques run into the core issues that plague symbolic approaches to AI: scalability and flexibility. The reason for this failure is that at their core, hybrid neurosymbolic models perform symbolic computation and relegate the scalable and flexible neural computation to parameterizing a symbolic system. We investigate a $\textit{unified}$ neurosymbolic system where transformations in the network can be interpreted simultaneously as both symbolic and neural computation. We extend a unified neurosymbolic architecture called the Differentiable Tree Machine in two central ways. First, we significantly increase the model’s efficiency through the use of sparse vector representations of symbolic structures. Second, we enable its application beyond the restricted set of tree2tree problems to the more general class of seq2seq problems. The improved model retains its prior generalization capabilities and, since there is a fully neural path through the network, avoids the pitfalls of other neurosymbolic techniques that elevate symbolic computation over neural computation.
Spotlight Poster
Yury Kuratov · Aydar Bulatov · Petr Anokhin · Ivan Rodkin · Dmitry Sorokin · Artyom Sorokin · Mikhail Burtsev
[ West Ballroom A-D ]
Abstract
In recent years, the input context sizes of large language models (LLMs) have increased dramatically. However, existing evaluation methods have not kept pace, failing to comprehensively assess the efficiency of models in handling long contexts. To bridge this gap, we introduce the BABILong benchmark, designed to test language models' ability to reason across facts distributed in extremely long documents. BABILong includes a diverse set of 20 reasoning tasks, including fact chaining, simple induction, deduction, counting, and handling lists/sets. These tasks are challenging on their own, and even more demanding when the required facts are scattered across long natural text. Our evaluations show that popular LLMs effectively utilize only 10-20% of the context and their performance declines sharply with increased reasoning complexity. Among alternatives to in-context reasoning, Retrieval-Augmented Generation methods achieve a modest 60% accuracy on single-fact question answering, independent of context length. Among context extension methods, the highest performance is demonstrated by recurrent memory transformers after fine-tuning, enabling the processing of lengths up to 50 million tokens. The BABILong benchmark is extendable to any length to support the evaluation of new upcoming models with increased capabilities, and we provide splits up to 10 million token lengths.
Spotlight Poster
Hao Shao · Shengju Qian · Han Xiao · Guanglu Song · ZHUOFAN ZONG · Letian Wang · Yu Liu · Hongsheng Li
[ West Ballroom A-D ]
Abstract
Multi-Modal Large Language Models (MLLMs) have demonstrated impressive performance in various VQA tasks. However, they often lack interpretability and struggle with complex visual inputs, especially when the resolution of the input image is high or when the interested region that could provide key information for answering the question is small. To address these challenges, we collect and introduce the large-scale Visual CoT dataset comprising 438k question-answer pairs, annotated with intermediate bounding boxes highlighting key regions essential for answering the questions. Additionally, about 98k pairs of them are annotated with detailed reasoning steps. Importantly, we propose a multi-turn processing pipeline that dynamically focuses on visual inputs and provides interpretable thoughts. We also introduce the related benchmark to evaluate the MLLMs in scenarios requiring specific local region identification.Extensive experiments demonstrate the effectiveness of our framework and shed light on better inference strategies. The Visual CoT dataset, benchmark, and pre-trained models are available on this [website](https://hao-shao.com/projects/viscot.html) to support further research in this area.
Spotlight Poster
Leo Zhou · Joao Basso · Song Mei
[ West Ballroom A-D ]
Abstract
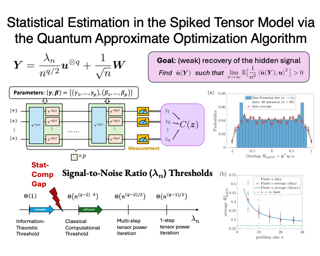
The quantum approximate optimization algorithm (QAOA) is a general-purpose algorithm for combinatorial optimization that has been a promising avenue for near-term quantum advantage. In this paper, we analyze the performance of the QAOA on the spiked tensor model, a statistical estimation problem that exhibits a large computational-statistical gap classically. We prove that the weak recovery threshold of $1$-step QAOA matches that of $1$-step tensor power iteration. Additional heuristic calculations suggest that the weak recovery threshold of $p$-step QAOA matches that of $p$-step tensor power iteration when $p$ is a fixed constant. This further implies that multi-step QAOA with tensor unfolding could achieve, but not surpass, the asymptotic classical computation threshold $\Theta(n^{(q-2)/4})$ for spiked $q$-tensors. Meanwhile, we characterize the asymptotic overlap distribution for $p$-step QAOA, discovering an intriguing sine-Gaussian law verified through simulations. For some $p$ and $q$, the QAOA has an effective recovery threshold that is a constant factor better than tensor power iteration.Of independent interest, our proof techniques employ the Fourier transform to handle difficult combinatorial sums, a novel approach differing from prior QAOA analyses on spin-glass models without planted structure.
Spotlight Poster
Hien Vu · Omkar Chandrakant Prabhune · Unmesh Raskar · Dimuth Panditharatne · Hanwook Chung · Christopher Choi · Younghyun Kim
[ West Ballroom A-D ]

Abstract
Precision livestock farming (PLF) has been transformed by machine learning (ML), enabling more precise and timely interventions that enhance overall farm productivity, animal welfare, and environmental sustainability. However, despite the availability of various sensing technologies, few datasets leverage multiple modalities, which are crucial for developing more accurate and efficient monitoring devices and ML models. To address this gap, we present MmCows, a multimodal dataset for dairy cattle monitoring. This dataset comprises a large amount of synchronized, high-quality measurement data on behavioral, physiological, and environmental factors. It includes two weeks of data collected using wearable and implantable sensors deployed on ten milking Holstein cows, such as ultra-wideband (UWB) sensors, inertial sensors, and body temperature sensors. In addition, it features 4.8 million frames of high-resolution image sequences from four isometric view cameras, as well as temperature and humidity data from environmental sensors. We also gathered milk yield data and outdoor weather conditions. One full day’s worth of image data is annotated as ground truth, totaling 20,000 frames with 213,000 bounding boxes of 16 cows, along with their 3D locations and behavior labels. An extensive analysis of MmCows is provided to evaluate the modalities individually and their complementary benefits. The release of MmCows …
Spotlight Poster
Saiyue Lyu · Shadab Shaikh · Frederick Shpilevskiy · Evan Shelhamer · Mathias Lécuyer
[ East Exhibit Hall A-C ]

Abstract
We propose Adaptive Randomized Smoothing (ARS) to certify the predictions of our test-time adaptive models against adversarial examples.ARS extends the analysis of randomized smoothing using $f$-Differential Privacy to certify the adaptive composition of multiple steps.For the first time, our theory covers the sound adaptive composition of general and high-dimensional functions of noisy inputs.We instantiate ARS on deep image classification to certify predictions against adversarial examples of bounded $L_{\infty}$ norm.In the $L_{\infty}$ threat model, ARS enables flexible adaptation through high-dimensional input-dependent masking.We design adaptivity benchmarks, based on CIFAR-10 and CelebA, and show that ARS improves standard test accuracy by 1 to 15\% points.On ImageNet, ARS improves certified test accuracy by up to 1.6% points over standard RS without adaptivity. Our code is available at [https://github.com/ubc-systopia/adaptive-randomized-smoothing](https://github.com/ubc-systopia/adaptive-randomized-smoothing).
Spotlight Poster
Shentong Mo · Peter Tong
[ West Ballroom A-D ]
Abstract
In recent advancements in unsupervised visual representation learning, the Joint-Embedding Predictive Architecture (JEPA) has emerged as a significant method for extracting visual features from unlabeled imagery through an innovative masking strategy. Despite its success, two primary limitations have been identified: the inefficacy of Exponential Moving Average (EMA) from I-JEPA in preventing entire collapse and the inadequacy of I-JEPA prediction in accurately learning the mean of patch representations. Addressing these challenges, this study introduces a novel framework, namely C-JEPA (Contrastive-JEPA), which integrates the Image-based Joint-Embedding Predictive Architecture with the Variance-Invariance-Covariance Regularization (VICReg) strategy. This integration is designed to effectively learn the variance/covariance for preventing entire collapse and ensuring invariance in the mean of augmented views, thereby overcoming the identified limitations. Through empirical and theoretical evaluations, our work demonstrates that C-JEPA significantly enhances the stability and quality of visual representation learning. When pre-trained on the ImageNet-1K dataset, C-JEPA exhibits rapid and improved convergence in both linear probing and fine-tuning performance metrics.
Spotlight Poster
Tao Hu · Wenhang Ge · Yuyang Zhao · Gim Hee Lee
[ East Exhibit Hall A-C ]

Abstract
We introduce X-Ray, a novel 3D sequential representation inspired by the penetrability of x-ray scans. X-Ray transforms a 3D object into a series of surface frames at different layers, making it suitable for generating 3D models from images. Our method utilizes ray casting from the camera center to capture geometric and textured details, including depth, normal, and color, across all intersected surfaces. This process efficiently condenses the whole 3D object into a multi-frame video format, motivating the utilize of a network architecture similar to those in video diffusion models. This design ensures an efficient 3D representation by focusing solely on surface information. Also, we propose a two-stage pipeline to generate 3D objects from X-Ray Diffusion Model and Upsampler. We demonstrate the practicality and adaptability of our X-Ray representation by synthesizing the complete visible and hidden surfaces of a 3D object from a single input image. Experimental results reveal the state-of-the-art superiority of our representation in enhancing the accuracy of 3D generation, paving the way for new 3D representation research and practical applications. Our project page is in \url{https://tau-yihouxiang.github.io/projects/X-Ray/X-Ray.html}.
Spotlight Poster
Kai Sandbrink · Jan Bauer · Alexandra Proca · Andrew Saxe · Christopher Summerfield · Ali Hummos
[ East Exhibit Hall A-C ]
Abstract
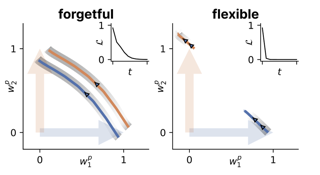
Animals survive in dynamic environments changing at arbitrary timescales, but such data distribution shifts are a challenge to neural networks. To adapt to change, neural systems may change a large number of parameters, which is a slow process involving forgetting past information. In contrast, animals leverage distribution changes to segment their stream of experience into tasks and associate them with internal task abstracts. Animals can then respond flexibly by selecting the appropriate task abstraction. However, how such flexible task abstractions may arise in neural systems remains unknown. Here, we analyze a linear gated network where the weights and gates are jointly optimized via gradient descent, but with neuron-like constraints on the gates including a faster timescale, non-negativity, and bounded activity. We observe that the weights self-organize into modules specialized for tasks or sub-tasks encountered, while the gates layer forms unique representations that switch the appropriate weight modules (task abstractions). We analytically reduce the learning dynamics to an effective eigenspace, revealing a virtuous cycle: fast adapting gates drive weight specialization by protecting previous knowledge, while weight specialization in turn increases the update rate of the gating layer. Task switching in the gating layer accelerates as a function of curriculum block size …
Spotlight Poster
Jifan Zhang · Lalit Jain · Yang Guo · Jiayi Chen · Kuan Zhou · Siddharth Suresh · Andrew Wagenmaker · Scott Sievert · Timothy T Rogers · Kevin Jamieson · Bob Mankoff · Robert Nowak
[ East Exhibit Hall A-C ]
Abstract
We present a novel multimodal preference dataset for creative tasks, consisting of over 250 million human votes on more than 2.2 million captions, collected through crowdsourcing rating data for The New Yorker's weekly cartoon caption contest over the past eight years. This unique dataset supports the development and evaluation of multimodal large language models and preference-based fine-tuning algorithms for humorous caption generation. We propose novel benchmarks for judging the quality of model-generated captions, utilizing both GPT4 and human judgments to establish ranking-based evaluation strategies. Our experimental results highlight the limitations of current fine-tuning methods, such as RLHF and DPO, when applied to creative tasks. Furthermore, we demonstrate that even state-of-the-art models like GPT4 and Claude currently underperform top human contestants in generating humorous captions. As we conclude this extensive data collection effort, we release the entire preference dataset to the research community, fostering further advancements in AI humor generation and evaluation.
Spotlight Poster
Morris Yau · Nikolaos Karalias · Eric Lu · Jessica Xu · Stefanie Jegelka
[ East Exhibit Hall A-C ]
Abstract
In this work we design graph neural network architectures that capture optimalapproximation algorithms for a large class of combinatorial optimization problems,using powerful algorithmic tools from semidefinite programming (SDP). Concretely, we prove that polynomial-sized message-passing algorithms can representthe most powerful polynomial time algorithms for Max Constraint SatisfactionProblems assuming the Unique Games Conjecture. We leverage this result toconstruct efficient graph neural network architectures, OptGNN, that obtain high quality approximate solutions on landmark combinatorial optimization problemssuch as Max-Cut, Min-Vertex-Cover, and Max-3-SAT. Our approach achievesstrong empirical results across a wide range of real-world and synthetic datasetsagainst solvers and neural baselines. Finally, we take advantage of OptGNN’sability to capture convex relaxations to design an algorithm for producing boundson the optimal solution from the learned embeddings of OptGNN.
Spotlight Poster
Kehan Guo · Bozhao Nan · Yujun Zhou · Taicheng Guo · Zhichun Guo · Mihir Surve · Zhenwen Liang · Nitesh Chawla · Olaf Wiest · Xiangliang Zhang
[ East Exhibit Hall A-C ]

Abstract
Large Language Models (LLMs) have shown significant problem-solving capabilities across predictive and generative tasks in chemistry. However, their proficiency in multi-step chemical reasoning remains underexplored. We introduce a new challenge: molecular structure elucidation, which involves deducing a molecule’s structure from various types of spectral data. Solving such a molecular puzzle, akin to solving crossword puzzles, poses reasoning challenges that require integrating clues from diverse sources and engaging in iterative hypothesis testing. To address this challenging problem with LLMs, we present \textbf{MolPuzzle}, a benchmark comprising 217 instances of structure elucidation, which feature over 23,000 QA samples presented in a sequential puzzle-solving process, involving three interlinked sub-tasks: molecule understanding, spectrum interpretation, and molecule construction. Our evaluation of 12 LLMs reveals that the best-performing LLM, GPT-4o, performs significantly worse than humans, with only a small portion (1.4\%) of its answers exactly matching the ground truth. However, it performs nearly perfectly in the first subtask of molecule understanding, achieving accuracy close to 100\%. This discrepancy highlights the potential of developing advanced LLMs with improved chemical reasoning capabilities in the other two sub-tasks. Our MolPuzzle dataset and evaluation code are available at this \href{https://github.com/KehanGuo2/MolPuzzle}{link}.
Spotlight Poster
Jianming Pan · Zeqi Ye · Xiao Yang · Xu Yang · Weiqing Liu · Lewen Wang · Jiang Bian
[ West Ballroom A-D ]
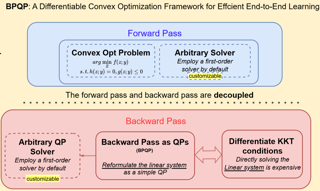
Abstract
Data-driven decision-making processes increasingly utilize end-to-end learnable deep neural networks to render final decisions. Sometimes, the output of the forward functions in certain layers is determined by the solutions to mathematical optimization problems, leading to the emergence of differentiable optimization layers that permit gradient back-propagation.However, real-world scenarios often involve large-scale datasets and numerous constraints, presenting significant challenges. Current methods for differentiating optimization problems typically rely on implicit differentiation, which necessitates costly computations on the Jacobian matrices, resulting in low efficiency.In this paper, we introduce BPQP, a differentiable convex optimization framework designed for efficient end-to-end learning. To enhance efficiency, we reformulate the backward pass as a simplified and decoupled quadratic programming problem by leveraging the structural properties of the Karush–Kuhn–Tucker (KKT) matrix. This reformulation enables the use of first-order optimization algorithms in calculating the backward pass gradients, allowing our framework to potentially utilize any state-of-the-art solver. As solver technologies evolve, BPQP can continuously adapt and improve its efficiency.Extensive experiments on both simulated and real-world datasets demonstrate that BPQP achieves a significant improvement in efficiency—typically an order of magnitude faster in overall execution time compared to other differentiable optimization layers. Our results not only highlight the efficiency gains of BPQP but also …
Spotlight Poster
Hugh Zhang · Jeff Da · Dean Lee · Vaughn Robinson · Catherine Wu · William Song · Tiffany Zhao · Pranav Raja · Charlotte Zhuang · Dylan Slack · Qin Lyu · Sean Hendryx · Russell Kaplan · Michele Lunati · Summer Yue
[ West Ballroom A-D ]
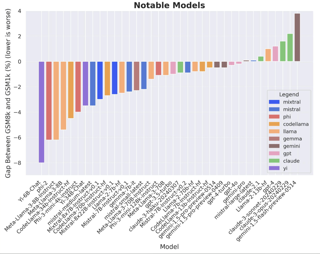
Abstract
Large language models (LLMs) have achieved impressive success on many benchmarks for mathematical reasoning.However, there is growing concern that some of this performance actually reflects dataset contamination, where data closely resembling benchmark questions leaks into the training data, instead of true reasoning ability.To investigate this claim rigorously, we commission Grade School Math 1000 (GSM1k). GSM1k is designed to mirror the style and complexity of the established GSM8k benchmark,the gold standard for measuring elementary mathematical reasoning. We ensure that the two benchmarks are comparable across important metrics such as human solve rates, number of steps in solution, answer magnitude, and more.When evaluating leading open- and closed-source LLMs on GSM1k, we observe accuracy drops of up to 8%, with several families of models showing evidence of systematic overfitting across almost all model sizes.Further analysis suggests a positive relationship (Spearman's r^2=0.36) between a model's probability of generating an example from GSM8k and its performance gap between GSM8k and GSM1k, suggesting that some models may have partially memorized GSM8k.Nevertheless, many models, especially those on the frontier, show minimal signs of overfitting, and all models broadly demonstrate generalization to novel math problems guaranteed to not be in their training data.
Spotlight Poster
Abhishek Sinha · Rahul Vaze
[ West Ballroom A-D ]
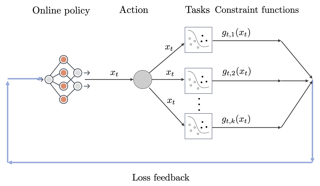
Abstract
A well-studied generalization of the standard online convex optimization (OCO) framework is constrained online convex optimization (COCO). In COCO, on every round, a convex cost function and a convex constraint function are revealed to the learner after it chooses the action for that round. The objective is to design an online learning policy that simultaneously achieves a small regret while ensuring a small cumulative constraint violation (CCV) against an adaptive adversary interacting over a horizon of length $T$. A long-standing open question in COCO is whether an online policy can simultaneously achieve $O(\sqrt{T})$ regret and $\tilde{O}(\sqrt{T})$ CCV without any restrictive assumptions. For the first time, we answer this in the affirmative and show that a simple first-order policy can simultaneously achieve these bounds. Furthermore, in the case of strongly convex cost and convex constraint functions, the regret guarantee can be improved to $O(\log T)$ while keeping the CCV bound the same as above. We establish these results by effectively combining adaptive OCO policies as a blackbox with Lyapunov optimization - a classic tool from control theory. Surprisingly, the analysis is short and elegant.
Spotlight Poster
Minkyu Jeon · Rishwanth Raghu · Miro Astore · Geoffrey Woollard · J. Feathers · Alkin Kaz · Sonya Hanson · Pilar Cossio · Ellen Zhong
[ West Ballroom A-D ]

Abstract
Cryo-electron microscopy (cryo-EM) is a powerful technique for determining high-resolution 3D biomolecular structures from imaging data. Its unique ability to capture structural variability has spurred the development of heterogeneous reconstruction algorithms that can infer distributions of 3D structures from noisy, unlabeled imaging data. Despite the growing number of advanced methods, progress in the field is hindered by the lack of standardized benchmarks with ground truth information and reliable validation metrics. Here, we introduce CryoBench, a suite of datasets, metrics, and benchmarks for heterogeneous reconstruction in cryo-EM. CryoBench includes five datasets representing different sources of heterogeneity and degrees of difficulty. These include conformational heterogeneity generated from designed motions of antibody complexes or sampled from a molecular dynamics simulation, as well as {compositional heterogeneity from mixtures of ribosome assembly states or 100 common complexes present in cells. We then analyze state-of-the-art heterogeneous reconstruction tools, including neural and non-neural methods, assess their sensitivity to noise, and propose new metrics for quantitative evaluation. We hope that CryoBench will be a foundational resource for accelerating algorithmic development and evaluation in the cryo-EM and machine learning communities. Project page: https://cryobench.cs.princeton.edu.
Spotlight Poster
Guillaume Jaume · Paul Doucet · Andrew Song · Ming Yang Lu · Cristina Almagro Pérez · Sophia Wagner · Anurag Vaidya · Richard Chen · Drew Williamson · Ahrong Kim · Faisal Mahmood
[ East Exhibit Hall A-C ]
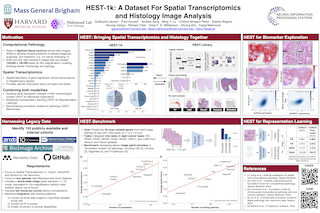
Abstract
Spatial transcriptomics enables interrogating the molecular composition of tissue with ever-increasing resolution and sensitivity. However, costs, rapidly evolving technology, and lack of standards have constrained computational methods in ST to narrow tasks and small cohorts. In addition, the underlying tissue morphology, as reflected by H&E-stained whole slide images (WSIs), encodes rich information often overlooked in ST studies. Here, we introduce HEST-1k, a collection of 1,229 spatial transcriptomic profiles, each linked to a WSI and extensive metadata. HEST-1k was assembled from 153 public and internal cohorts encompassing 26 organs, two species (Homo Sapiens and Mus Musculus), and 367 cancer samples from 25 cancer types. HEST-1k processing enabled the identification of 2.1 million expression-morphology pairs and over 76 million nuclei. To support its development, we additionally introduce the HEST-Library, a Python package designed to perform a range of actions with HEST samples. We test HEST-1k and Library on three use cases: (1) benchmarking foundation models for pathology (HEST-Benchmark), (2) biomarker exploration, and (3) multimodal representation learning. HEST-1k, HEST-Library, and HEST-Benchmark can be freely accessed at https://github.com/mahmoodlab/hest.
Spotlight Poster
Maurice Weber · Dan Fu · Quentin Anthony · Yonatan Oren · Shane Adams · Anton Alexandrov · Xiaozhong Lyu · Huu Nguyen · Xiaozhe Yao · Virginia Adams · Ben Athiwaratkun · Rahul Chalamala · Kezhen Chen · Max Ryabinin · Tri Dao · Percy Liang · Christopher Ré · Irina Rish · Ce Zhang
[ West Ballroom A-D ]
Abstract
Large language models are increasingly becoming a cornerstone technology in artificial intelligence, the sciences, and society as a whole, yet the optimal strategies for dataset composition and filtering remain largely elusive. Many of the top-performing models lack transparency in their dataset curation and model development processes, posing an obstacle to the development of fully open language models. In this paper, we identify three core data-related challenges that must be addressed to advance open-source language models. These include (1) transparency in model development, including the data curation process, (2) access to large quantities of high-quality data, and (3) availability of artifacts and metadata for dataset curation and analysis. To address these challenges, we release RedPajama-V1, an open reproduction of the LLaMA training dataset. In addition, we release RedPajama-V2, a massive web-only dataset consisting of raw, unfiltered text data together with quality signals and metadata.Together, the RedPajama datasets comprise over 100 trillion tokens spanning multiple domains and with their quality signals facilitate the filtering of data, aiming to inspire the development of numerous new datasets. To date, these datasets have already been used in the training of strong language models used in production, such as Snowflake Arctic, Salesforce's XGen and AI2's OLMo. …
Spotlight Poster
Siyuan Huang · Yunchong Song · Jiayue Zhou · Zhouhan Lin
[ East Exhibit Hall A-C ]
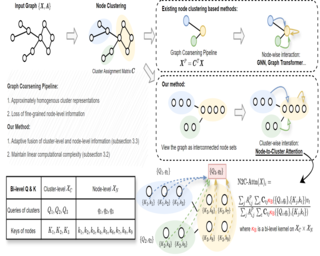
Abstract
In the realm of graph learning, there is a category of methods that conceptualize graphs as hierarchical structures, utilizing node clustering to capture broader structural information. While generally effective, these methods often rely on a fixed graph coarsening routine, leading to overly homogeneous cluster representations and loss of node-level information. In this paper, we envision the graph as a network of interconnected node sets without compressing each cluster into a single embedding. To enable effective information transfer among these node sets, we propose the Node-to-Cluster Attention (N2C-Attn) mechanism. N2C-Attn incorporates techniques from Multiple Kernel Learning into the kernelized attention framework, effectively capturing information at both node and cluster levels. We then devise an efficient form for N2C-Attn using the cluster-wise message-passing framework, achieving linear time complexity. We further analyze how N2C-Attn combines bi-level feature maps of queries and keys, demonstrating its capability to merge dual-granularity information. The resulting architecture, Cluster-wise Graph Transformer (Cluster-GT), which uses node clusters as tokens and employs our proposed N2C-Attn module, shows superior performance on various graph-level tasks. Code is available at https://github.com/LUMIA-Group/Cluster-wise-Graph-Transformer.
Spotlight Poster
Gokul Gowri · Xiaokang Lun · Allon Klein · Peng Yin
[ East Exhibit Hall A-C ]
Abstract
Mutual information (MI) is a general measure of statistical dependence with widespread application across the sciences. However, estimating MI between multi-dimensional variables is challenging because the number of samples necessary to converge to an accurate estimate scales unfavorably with dimensionality. In practice, existing techniques can reliably estimate MI in up to tens of dimensions, but fail in higher dimensions, where sufficient sample sizes are infeasible. Here, we explore the idea that underlying low-dimensional structure in high-dimensional data can be exploited to faithfully approximate MI in high-dimensional settings with realistic sample sizes. We develop a method that we call latent MI (LMI) approximation, which applies a nonparametric MI estimator to low-dimensional representations learned by a simple, theoretically-motivated model architecture. Using several benchmarks, we show that unlike existing techniques, LMI can approximate MI well for variables with $> 10^3$ dimensions if their dependence structure is captured by low-dimensional representations. Finally, we showcase LMI on two open problems in biology. First, we approximate MI between protein language model (pLM) representations of interacting proteins, and find that pLMs encode non-trivial information about protein-protein interactions. Second, we quantify cell fate information contained in single-cell RNA-seq (scRNA-seq) measurements of hematopoietic stem cells, and find a sharp …
Spotlight Poster
Ayush Jain · Rajat Sen · Weihao Kong · Abhimanyu Das · Alon Orlitsky
[ East Exhibit Hall A-C ]
Abstract
In many learning applications, data are collected from multiple sources, each providing a \emph{batch} of samples that by itself is insufficient to learn its input-output relationship. A common approach assumes that the sources fall in one of several unknown subgroups, each with an unknown input distribution and input-output relationship. We consider one of this setup's most fundamental and important manifestations where the output is a noisy linear combination of the inputs, and there are $k$ subgroups, each with its own regression vector. Prior work [KSS$^+$20] showed that with abundant small-batches, the regression vectors can be learned with only few, $\tilde\Omega( k^{3/2})$, batches of medium-size with $\tilde\Omega(\sqrt k)$ samples each. However, the paper requires that the input distribution for all $k$ subgroups be isotropic Gaussian, and states that removing this assumption is an ``interesting and challenging problem". We propose a novel gradient-based algorithm that improves on the existing results in several ways. It extends the applicability of the algorithm by: (1) allowing the subgroups' underlying input distributions to be different, unknown, and heavy-tailed; (2) recovering all subgroups followed by a significant proportion of batches even for infinite $k$; (3) removing the separation requirement between the regression vectors; (4) reducing the number …
Spotlight Poster
Dongyan Lucy Huo · Yixuan Zhang · Yudong Chen · Qiaomin Xie
[ West Ballroom A-D ]
Abstract
In this work, we investigate stochastic approximation (SA) with Markovian data and nonlinear updates under constant stepsize $\alpha>0$. Existing work has primarily focused on either i.i.d. data or linear update rules. We take a new perspective and carefully examine the simultaneous presence of Markovian dependency of data and nonlinear update rules, delineating how the interplay between these two structures leads to complications that are not captured by prior techniques. By leveraging the smoothness and recurrence properties of the SA updates, we develop a fine-grained analysis of the correlation between the SA iterates $\theta_k$ and Markovian data $x_k$. This enables us to overcome the obstacles in existing analysis and establish for the first time the weak convergence of the joint process $(x_k, \theta_k)$. Furthermore, we present a precise characterization of the asymptotic bias of the SA iterates, given by $\mathbb{E}[\theta_\infty]-\theta^\ast=\alpha(b_\textup{m}+b_\textup{n}+b_\textup{c})+\mathcal{O}(\alpha^{3/2})$. Here, $b_\textup{m}$ is associated with the Markovian noise, $b_\textup{n}$ is tied to the nonlinearity of the SA operator, and notably, $b_\textup{c}$ represents a multiplicative interaction between the Markovian noise and the nonlinearity of the operator, which is absent in previous works. As a by-product of our analysis, we derive finite-time bounds on higher moment $\mathbb{E}[||\theta_k-\theta^\ast||^{2p}]$ and present non-asymptotic geometric convergence …
Spotlight Poster
Zitong Lan · Chenhao Zheng · Zhiwei Zheng · Mingmin Zhao
[ East Exhibit Hall A-C ]
Abstract
Realistic audio synthesis that captures accurate acoustic phenomena is essential for creating immersive experiences in virtual and augmented reality. Synthesizing the sound received at any position relies on the estimation of impulse response (IR), which characterizes how sound propagates in one scene along different paths before arriving at the listener position. In this paper, we present Acoustic Volume Rendering (AVR), a novel approach that adapts volume rendering techniques to model acoustic impulse responses. While volume rendering has been successful in modeling radiance fields for images and neural scene representations, IRs present unique challenges as time-series signals. To address these challenges, we introduce frequency-domain volume rendering and use spherical integration to fit the IR measurements. Our method constructs an impulse response field that inherently encodes wave propagation principles and achieves state of-the-art performance in synthesizing impulse responses for novel poses. Experiments show that AVR surpasses current leading methods by a substantial margin. Additionally, we develop an acoustic simulation platform, AcoustiX, which provides more accurate and realistic IR simulations than existing simulators. Code for AVR and AcoustiX are available at https://zitonglan.github.io/avr.
Spotlight Poster
Ling Yang · Zhaochen Yu · Tianjun Zhang · Shiyi Cao · Minkai Xu · Wentao Zhang · Joseph Gonzalez · Bin CUI
[ East Exhibit Hall A-C ]
Abstract
We introduce Buffer of Thoughts (BoT), a novel and versatile thought-augmented reasoning approach for enhancing accuracy, efficiency and robustness of large language models (LLMs). Specifically, we propose meta-buffer to store a series of informative high-level thoughts, namely thought-template, distilled from the problem-solving processes across various tasks. Then for each problem, we retrieve a relevant thought-template and adaptively instantiate it with specific reasoning structures to conduct efficient reasoning. To guarantee the scalability and stability, we further propose buffer-manager to dynamically update the meta-buffer, thus enhancing the capacity of meta-buffer as more tasks are solved. We conduct extensive experiments on 10 challenging reasoning-intensive tasks, and achieve significant performance improvements over previous SOTA methods: 11\% on Game of 24, 20\% on Geometric Shapes and 51\% on Checkmate-in-One. Further analysis demonstrate the superior generalization ability and model robustness of our BoT, while requiring only 12\% of the cost of multi-query prompting methods (e.g., tree/graph of thoughts) on average. Code is available at: https://github.com/YangLing0818/buffer-of-thought-llm
Spotlight Poster
Damien Ferbach · Quentin Bertrand · Joey Bose · Gauthier Gidel
[ East Exhibit Hall A-C ]
Abstract
The rapid progress in generative models has resulted in impressive leaps in generation quality, blurring the lines between synthetic and real data. Web-scale datasets are now prone to the inevitable contamination by synthetic data, directly impacting the training of future generated models. Already, some theoretical results on self-consuming generative models (a.k.a., iterative retraining) have emerged in the literature, showcasing that either model collapse or stability could be possible depending on the fraction of generated data used at each retraining step. However, in practice, synthetic data is often subject to human feedback and curated by users before being used and uploaded online. For instance, many interfaces of popular text-to-image generative models, such as Stable Diffusion or Midjourney, produce several variations of an image for a given query which can eventually be curated by the users. In this paper, we theoretically study the impact of data curation on iterated retraining of generative models and show that it can be seen as an implicit preference optimization mechanism. However, unlike standard preference optimization, the generative model does not have access to the reward function or negative samples needed for pairwise comparisons. Moreover, our study doesn't require access to the density function, only to samples. …
Spotlight Poster
Francesco Bacchiocchi · Matteo Bollini · Matteo Castiglioni · Alberto Marchesi · Nicola Gatti
[ West Ballroom A-D ]
Abstract
We study online Bayesian persuasion problems in which an informed sender repeatedly faces a receiver with the goal of influencing their behavior through the provision of payoff-relevant information. Previous works assume that the sender has knowledge about either the prior distribution over states of nature or receiver's utilities, or both. We relax such unrealistic assumptions by considering settings in which the sender does not know anything about the prior and the receiver. We design an algorithm that achieves sublinear---in the number of rounds T---regret with respect to an optimal signaling scheme, and we also provide a collection of lower bounds showing that the guarantees of such an algorithm are tight. Our algorithm works by searching a suitable space of signaling schemes in order to learn receiver's best responses. To do this, we leverage a non-standard representation of signaling schemes that allows to cleverly overcome the challenge of not knowing anything about the prior over states of nature and receiver's utilities. Finally, our results also allow to derive lower/upper bounds on the sample complexity of learning signaling schemes in a related Bayesian persuasion PAC-learning problem.
Spotlight Poster
Yue Liu · Yunjie Tian · Yuzhong Zhao · Hongtian Yu · Lingxi Xie · Yaowei Wang · Qixiang Ye · Jianbin Jiao · Yunfan Liu
[ East Exhibit Hall A-C ]
Abstract
Designing computationally efficient network architectures remains an ongoing necessity in computer vision. In this paper, we adapt Mamba, a state-space language model, into VMamba, a vision backbone with linear time complexity. At the core of VMamba is a stack of Visual State-Space (VSS) blocks with the 2D Selective Scan (SS2D) module. By traversing along four scanning routes, SS2D bridges the gap between the ordered nature of 1D selective scan and the non-sequential structure of 2D vision data, which facilitates the collection of contextual information from various sources and perspectives. Based on the VSS blocks, we develop a family of VMamba architectures and accelerate them through a succession of architectural and implementation enhancements. Extensive experiments demonstrate VMamba’s promising performance across diverse visual perception tasks, highlighting its superior input scaling efficiency compared to existing benchmark models. Source code is available at https://github.com/MzeroMiko/VMamba
Spotlight Poster
Zijian Dong · Ruilin Li · Yilei Wu · Thuan Tinh Nguyen · Joanna Chong · Fang Ji · Nathanael Tong · Christopher Chen · Juan Helen Zhou
[ East Exhibit Hall A-C ]
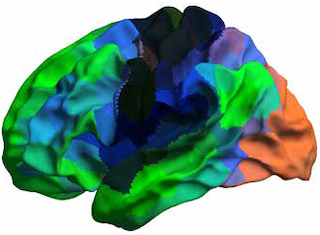
Abstract
We introduce *Brain-JEPA*, a brain dynamics foundation model with the Joint-Embedding Predictive Architecture (JEPA). This pioneering model achieves state-of-the-art performance in demographic prediction, disease diagnosis/prognosis, and trait prediction through fine-tuning. Furthermore, it excels in off-the-shelf evaluations (e.g., linear probing) and demonstrates superior generalizability across different ethnic groups, surpassing the previous large model for brain activity significantly. Brain-JEPA incorporates two innovative techniques: **Brain Gradient Positioning** and **Spatiotemporal Masking**. Brain Gradient Positioning introduces a functional coordinate system for brain functional parcellation, enhancing the positional encoding of different Regions of Interest (ROIs). Spatiotemporal Masking, tailored to the unique characteristics of fMRI data, addresses the challenge of heterogeneous time-series patches. These methodologies enhance model performance and advance our understanding of the neural circuits underlying cognition. Overall, Brain-JEPA is paving the way to address pivotal questions of building brain functional coordinate system and masking brain activity at the AI-neuroscience interface, and setting a potentially new paradigm in brain activity analysis through downstream adaptation.
Spotlight Poster
Zhehao Huang · Xinwen Cheng · JingHao Zheng · Haoran Wang · Zhengbao He · Tao Li · Xiaolin Huang
[ East Exhibit Hall A-C ]

Abstract
Machine unlearning (MU) has emerged to enhance the privacy and trustworthiness of deep neural networks. Approximate MU is a practical method for large-scale models. Our investigation into approximate MU starts with identifying the steepest descent direction, minimizing the output Kullback-Leibler divergence to exact MU inside a parameters' neighborhood. This probed direction decomposes into three components: weighted forgetting gradient ascent, fine-tuning retaining gradient descent, and a weight saliency matrix. Such decomposition derived from Euclidean metric encompasses most existing gradient-based MU methods. Nevertheless, adhering to Euclidean space may result in sub-optimal iterative trajectories due to the overlooked geometric structure of the output probability space. We suggest embedding the unlearning update into a manifold rendered by the remaining geometry, incorporating second-order Hessian from the remaining data. It helps prevent effective unlearning from interfering with the retained performance. However, computing the second-order Hessian for large-scale models is intractable. To efficiently leverage the benefits of Hessian modulation, we propose a fast-slow parameter update strategy to implicitly approximate the up-to-date salient unlearning direction.Free from specific modal constraints, our approach is adaptable across computer vision unlearning tasks, including classification and generation. Extensive experiments validate our efficacy and efficiency. Notably, our method successfully performs class-forgetting on ImageNet using …
Spotlight Poster
Peter Mørch Groth · Mads Kerrn · Lars Olsen · Jesper Salomon · Wouter Boomsma
[ East Exhibit Hall A-C ]
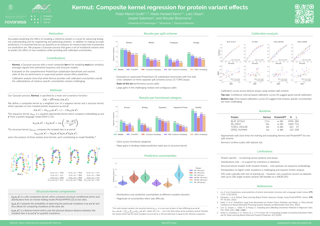
Abstract
Reliable prediction of protein variant effects is crucial for both protein optimization and for advancing biological understanding. For practical use in protein engineering, it is important that we can also provide reliable uncertainty estimates for our predictions, and while prediction accuracy has seen much progress in recent years, uncertainty metrics are rarely reported. We here provide a Gaussian process regression model, Kermut, with a novel composite kernel for modeling mutation similarity, which obtains state-of-the-art performance for supervised protein variant effect prediction while also offering estimates of uncertainty through its posterior. An analysis of the quality of the uncertainty estimates demonstrates that our model provides meaningful levels of overall calibration, but that instance-specific uncertainty calibration remains more challenging.
Spotlight Poster
Yuanqi Du · Michael Plainer · Rob Brekelmans · Chenru Duan · Frank Noe · Carla Gomes · Alan Aspuru-Guzik · Kirill Neklyudov
[ East Exhibit Hall A-C ]
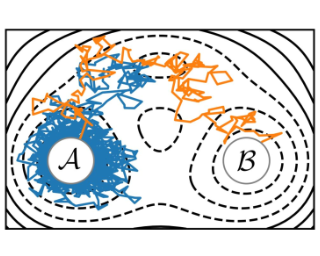
Abstract
Rare event sampling in dynamical systems is a fundamental problem arising in the natural sciences, which poses significant computational challenges due to an exponentially large space of trajectories. For settings where the dynamical system of interest follows a Brownian motion with known drift, the question of conditioning the process to reach a given endpoint or desired rare event is definitively answered by Doob's $h$-transform. However, the naive estimation of this transform is infeasible, as it requires simulating sufficiently many forward trajectories to estimate rare event probabilities. In this work, we propose a variational formulation of Doob's $h$-transform as an optimization problem over trajectories between a given initial point and the desired ending point. To solve this optimization, we propose a simulation-free training objective with a model parameterization that imposes the desired boundary conditions by design. Our approach significantly reduces the search space over trajectories and avoids expensive trajectory simulation and inefficient importance sampling estimators which are required in existing methods. We demonstrate the ability of our method to find feasible transition paths on real-world molecular simulation and protein folding tasks.
Spotlight Poster
Yeonsu Kwon · Jiho Kim · Gyubok Lee · Seongsu Bae · Daeun Kyung · Wonchul Cha · Tom Pollard · Alistair Johnson · Edward Choi
[ East Exhibit Hall A-C ]
Abstract
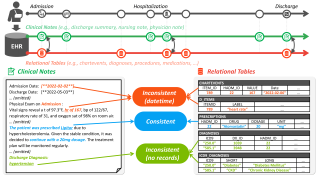
Electronic Health Records (EHRs) are integral for storing comprehensive patient medical records, combining structured data (e.g., medications) with detailed clinical notes (e.g., physician notes). These elements are essential for straightforward data retrieval and provide deep, contextual insights into patient care. However, they often suffer from discrepancies due to unintuitive EHR system designs and human errors, posing serious risks to patient safety. To address this, we developed EHRCon, a new dataset and task specifically designed to ensure data consistency between structured tables and unstructured notes in EHRs.EHRCon was crafted in collaboration with healthcare professionals using the MIMIC-III EHR dataset, and includes manual annotations of 3,943 entities across 105 clinical notes checked against database entries for consistency.EHRCon has two versions, one using the original MIMIC-III schema, and another using the OMOP CDM schema, in order to increase its applicability and generalizability. Furthermore, leveraging the capabilities of large language models, we introduce CheckEHR, a novel framework for verifying the consistency between clinical notes and database tables. CheckEHR utilizes an eight-stage process and shows promising results in both few-shot and zero-shot settings. The code is available at \url{https://github.com/dustn1259/EHRCon}.
Spotlight Poster
Minjae Lee · Kyungmin Kim · Taesoo Kim · Sangdon Park
[ East Exhibit Hall A-C ]
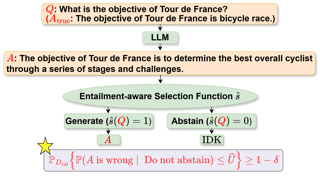
Abstract
Trustworthiness of generative language models (GLMs) is crucial in their deployment to critical decision making systems. Hence, certified risk control methods such as selective prediction and conformal prediction have been applied to mitigating the hallucination problem in various supervised downstream tasks. However, the lack of appropriate correctness metric hinders applying such principled methods to language generation tasks. In this paper, we circumvent this problem by leveraging the concept of textual entailment to evaluate the correctness of the generated sequence, and propose two selective generation algorithms which control the false discovery rate with respect to the textual entailment relation (FDR-E) with a theoretical guarantee: $\texttt{SGen}^{\texttt{Sup}}$ and $\texttt{SGen}^{\texttt{Semi}}$. $\texttt{SGen}^{\texttt{Sup}}$, a direct modification of the selective prediction, is a supervised learning algorithm which exploits entailment-labeled data, annotated by humans. Since human annotation is costly, we further propose a semi-supervised version, $\texttt{SGen}^{\texttt{Semi}}$, which fully utilizes the unlabeled data by pseudo-labeling, leveraging an entailment set function learned via conformal prediction. Furthermore, $\texttt{SGen}^{\texttt{Semi}}$ enables to use more general class of selection functions, neuro-selection functions, and provides users with an optimal selection function class given multiple candidates. Finally, we demonstrate the efficacy of the $\texttt{SGen}$ family in achieving a desired FDR-E level with comparable selection efficiency to …
Spotlight Poster
Gautam Chandrasekaran · Vasilis Kontonis · Konstantinos Stavropoulos · Kevin Tian
[ West Ballroom A-D ]
Abstract
We study the problem of PAC learning $\gamma$-margin halfspaces with Massart noise. We propose a simple proper learning algorithm, the Perspectron, that has sample complexity $\widetilde{O}((\epsilon\gamma)^{-2})$ and achieves classification error at most $\eta+\epsilon$ where $\eta$ is the Massart noise rate. Prior works (DGT19, CKMY20) came with worse sample complexity guarantees (in both $\epsilon$ and $\gamma$) or could only handle random classification noise (DDKWZ23,KITBMV23)--- a much milder noise assumption. We also show that our results extend to the more challenging setting of learning generalized linear models with a known link function under Massart noise, achieving a similar sample complexity to the halfspace case. This significantly improves upon the prior state-of-the-art in this setting due to CKMY20, who introduced this model.
Spotlight Poster
Gabriele Farina · Charilaos Pipis
[ West Ballroom A-D ]
Abstract
It is a well-known fact that correlated equilibria can be computed in polynomial time in a large class of concisely represented games using the celebrated Ellipsoid Against Hope algorithm \citep{Papadimitriou2008:Computing, Jiang2015:Polynomial}. However, the landscape of efficiently computable equilibria in sequential (extensive-form) games remains unknown. The Ellipsoid Against Hope does not apply directly to these games, because they do not have the required ``polynomial type'' property. Despite this barrier, \citet{Huang2008:Computing} altered the algorithm to compute exact extensive-form correlated equilibria.In this paper, we generalize the Ellipsoid Against Hope and develop a simple algorithmic framework for efficiently computing saddle-points in bilinear zero-sum games, even when one of the dimensions is exponentially large. Moreover, the framework only requires a ``good-enough-response'' oracle, which is a weakened notion of a best-response oracle.Using this machinery, we develop a general algorithmic framework for computing exact linear $\Phi$-equilibria in any polyhedral game (under mild assumptions), including correlated equilibria in normal-form games, and extensive-form correlated equilibria in extensive-form games. This enables us to give the first polynomial-time algorithm for computing exact linear-deviation correlated equilibria in extensive-form games, thus resolving an open question by \citet{Farina2023:Polynomial}. Furthermore, even for the cases for which a polynomial time algorithm for exact equilibria was already …
Spotlight Poster
Weichao Zeng · Yan Shu · Zhenhang Li · Dongbao Yang · Yu Zhou
[ West Ballroom A-D ]
Abstract
Centred on content modification and style preservation, Scene Text Editing (STE) remains a challenging task despite considerable progress in text-to-image synthesis and text-driven image manipulation recently. GAN-based STE methods generally encounter a common issue of model generalization, while Diffusion-based STE methods suffer from undesired style deviations. To address these problems, we propose TextCtrl, a diffusion-based method that edits text with prior guidance control. Our method consists of two key components: (i) By constructing fine-grained text style disentanglement and robust text glyph structure representation, TextCtrl explicitly incorporates Style-Structure guidance into model design and network training, significantly improving text style consistency and rendering accuracy. (ii) To further leverage the style prior, a Glyph-adaptive Mutual Self-attention mechanism is proposed which deconstructs the implicit fine-grained features of the source image to enhance style consistency and vision quality during inference. Furthermore, to fill the vacancy of the real-world STE evaluation benchmark, we create the first real-world image-pair dataset termed ScenePair for fair comparisons. Experiments demonstrate the effectiveness of TextCtrl compared with previous methods concerning both style fidelity and text accuracy. Project page: https://github.com/weichaozeng/TextCtrl.
Spotlight Poster
Timothy Chu · Josh Alman · Gary L. Miller · Shyam Narayanan · Mark Sellke · Zhao Song
[ West Ballroom A-D ]
Abstract
We introduce a new linear-algebraic tool based on group representation theory, and use it to address three key problems in machine learning.1. Past researchers have proposed fast attention algorithms for LLMs by approximating or replace softmax attention with other functions, such as low-degree polynomials. The key property of these functions is that, when applied entry-wise to the matrix $QK^{\top}$, the result is a low rank matrix when $Q$ and $K$ are $n \times d$ matrices and $n \gg d$. This suggests a natural question: what are all functions $f$ with this property? If other $f$ exist and are quickly computable, they can be used in place of softmax for fast subquadratic attention algorithms. It was previously known that low-degree polynomials have this property. We prove that low-degree polynomials are the only piecewise continuous functions with this property. This suggests that the low-rank fast attention only works for functions approximable by polynomials. Our work gives a converse to the polynomial method in algorithm design.2. We prove the first full classification of all positive definite kernels that are functions of Manhattan or $\ell_1$ distance. Our work generalizes an existing theorem at the heart of all kernel methods in machine learning: the classification …
Spotlight Poster
Tzu-Heng Huang · Catherine Cao · Vaishnavi Bhargava · Frederic Sala
[ East Exhibit Hall A-C ]
Abstract
Large pretrained models can be used as annotators, helping replace or augment crowdworkers and enabling distilling generalist models into smaller specialist models. Unfortunately, this comes at a cost: employing top-of-the-line models often requires paying thousands of dollars for API calls, while the resulting datasets are static and challenging to audit. To address these challenges, we propose a simple alternative: rather than directly querying labels from pretrained models, we task models to generate programs that can produce labels. These programs can be stored and applied locally, re-used and extended, and cost orders of magnitude less. Our system, $\textbf{Alchemist}$, obtains comparable to or better performance than large language model-based annotation in a range of tasks for a fraction of the cost: on average, improvements amount to a $\textbf{12.9}$% enhancement while the total labeling costs across all datasets are reduced by a factor of approximately $\textbf{500}\times$.
Spotlight Poster
Vivian Nastl · Moritz Hardt
[ West Ballroom A-D ]

Abstract
We study how well machine learning models trained on causal features generalize across domains. We consider 16 prediction tasks on tabular datasets covering applications in health, employment, education, social benefits, and politics. Each dataset comes with multiple domains, allowing us to test how well a model trained in one domain performs in another. For each prediction task, we select features that have a causal influence on the target of prediction. Our goal is to test the hypothesis that models trained on causal features generalize better across domains. Without exception, we find that predictors using all available features, regardless of causality, have better in-domain and out-of-domain accuracy than predictors using causal features. Moreover, even the absolute drop in accuracy from one domain to the other is no better for causal predictors than for models that use all features. In addition, we show that recent causal machine learning methods for domain generalization do not perform better in our evaluation than standard predictors trained on the set of causal features. Likewise, causal discovery algorithms either fail to run or select causal variables that perform no better than our selection. Extensive robustness checks confirm that our findings are stable under variable misclassification.
Spotlight Poster
Sebastian Dittert · Vincent Moens · Gianni De Fabritiis
[ East Exhibit Hall A-C ]

Abstract
We present BricksRL, a platform designed to democratize access to robotics for reinforcement learning research and education. BricksRL facilitates the creation, design, and training of custom LEGO robots in the real world by interfacing them with the TorchRL library for reinforcement learning agents. The integration of TorchRL with the LEGO hubs, via Bluetooth bidirectional communication, enables state-of-the-art reinforcement learning training on GPUs for a wide variety of LEGO builds. This offers a flexible and cost-efficient approach for scaling and also provides a robust infrastructure for robot-environment-algorithm communication. We present various experiments across tasks and robot configurations, providing built plans and training results. Furthermore, we demonstrate that inexpensive LEGO robots can be trained end-to-end in the real world to achieve simple tasks, with training times typically under 120 minutes on a normal laptop. Moreover, we show how users can extend the capabilities, exemplified by the successful integration of non-LEGO sensors. By enhancing accessibility to both robotics and reinforcement learning, BricksRL establishes a strong foundation for democratized robotic learning in research and educational settings.
Spotlight Poster
Farzaneh Taleb · Miguel Vasco · Antonio Ribeiro · Mårten Björkman · Danica Kragic
[ East Exhibit Hall A-C ]

Abstract
The human brain encodes stimuli from the environment into representations that form a sensory perception of the world. Despite recent advances in understanding visual and auditory perception, olfactory perception remains an under-explored topic in the machine learning community due to the lack of large-scale datasets annotated with labels of human olfactory perception. In this work, we ask the question of whether pre-trained transformer models of chemical structures encode representations that are aligned with human olfactory perception, i.e., can transformers smell like humans? We demonstrate that representations encoded from transformers pre-trained on general chemical structures are highly aligned with human olfactory perception. We use multiple datasets and different types of perceptual representations to show that the representations encoded by transformer models are able to predict: (i) labels associated with odorants provided by experts; (ii) continuous ratings provided by human participants with respect to pre-defined descriptors; and (iii) similarity ratings between odorants provided by human participants. Finally, we evaluate the extent to which this alignment is associated with physicochemical features of odorants known to be relevant for olfactory decoding.
Spotlight Poster
Changze Lv · Dongqi Han · Yansen Wang · Xiaoqing Zheng · Xuanjing Huang · Dongsheng Li
[ East Exhibit Hall A-C ]

Abstract
Spiking neural networks (SNNs) represent a promising approach to developing artificial neural networks that are both energy-efficient and biologically plausible.However, applying SNNs to sequential tasks, such as text classification and time-series forecasting, has been hindered by the challenge of creating an effective and hardware-friendly spike-form positional encoding (PE) strategy.Drawing inspiration from the central pattern generators (CPGs) in the human brain, which produce rhythmic patterned outputs without requiring rhythmic inputs, we propose a novel PE technique for SNNs, termed CPG-PE.We demonstrate that the commonly used sinusoidal PE is mathematically a specific solution to the membrane potential dynamics of a particular CPG.Moreover, extensive experiments across various domains, including time-series forecasting, natural language processing, and image classification, show that SNNs with CPG-PE outperform their conventional counterparts.Additionally, we perform analysis experiments to elucidate the mechanism through which SNNs encode positional information and to explore the function of CPGs in the human brain.This investigation may offer valuable insights into the fundamental principles of neural computation.
Spotlight Poster
Dan Qiao · Kaiqi Zhang · Esha Singh · Daniel Soudry · Yu-Xiang Wang
[ East Exhibit Hall A-C ]
Abstract
We study the generalization of two-layer ReLU neural networks in a univariate nonparametric regression problem with noisy labels. This is a problem where kernels (\emph{e.g.} NTK) are provably sub-optimal and benign overfitting does not happen, thus disqualifying existing theory for interpolating (0-loss, global optimal) solutions. We present a new theory of generalization for local minima that gradient descent with a constant learning rate can \emph{stably} converge to. We show that gradient descent with a fixed learning rate $\eta$ can only find local minima that represent smooth functions with a certain weighted \emph{first order total variation} bounded by $1/\eta - 1/2 + \widetilde{O}(\sigma + \sqrt{\mathrm{MSE}})$ where $\sigma$ is the label noise level, $\mathrm{MSE}$ is short for mean squared error against the ground truth, and $\widetilde{O}(\cdot)$ hides a logarithmic factor. Under mild assumptions, we also prove a nearly-optimal MSE bound of $\widetilde{O}(n^{-4/5})$ within the strict interior of the support of the $n$ data points. Our theoretical results are validated by extensive simulation that demonstrates large learning rate training induces sparse linear spline fits. To the best of our knowledge, we are the first to obtain generalization bound via minima stability in the non-interpolation case and the first to show ReLU NNs without …
Spotlight Poster
Ye Li · Lingdong Kong · Hanjiang Hu · Xiaohao Xu · Xiaonan Huang
[ East Exhibit Hall A-C ]

Abstract
The reliability of driving perception systems under unprecedented conditions is crucial for practical usage. Latest advancements have prompted increasing interest in multi-LiDAR perception. However, prevailing driving datasets predominantly utilize single-LiDAR systems and collect data devoid of adverse conditions, failing to capture the complexities of real-world environments accurately. Addressing these gaps, we proposed Place3D, a full-cycle pipeline that encompasses LiDAR placement optimization, data generation, and downstream evaluations. Our framework makes three appealing contributions. 1) To identify the most effective configurations for multi-LiDAR systems, we introduce the Surrogate Metric of the Semantic Occupancy Grids (M-SOG) to evaluate LiDAR placement quality. 2) Leveraging the M-SOG metric, we propose a novel optimization strategy to refine multi-LiDAR placements. 3) Centered around the theme of multi-condition multi-LiDAR perception, we collect a 280,000-frame dataset from both clean and adverse conditions. Extensive experiments demonstrate that LiDAR placements optimized using our approach outperform various baselines. We showcase exceptional results in both LiDAR semantic segmentation and 3D object detection tasks, under diverse weather and sensor failure conditions.
Spotlight Poster
Zhenheng Tang · Yonggang Zhang · Peijie Dong · Yiu-ming Cheung · Amelie Zhou · Bo Han · Xiaowen Chu
[ East Exhibit Hall A-C ]
Abstract
One-shot Federated Learning (OFL) significantly reduces communication costs in FL by aggregating trained models only once. However, the performance of advanced OFL methods is far behind the normal FL. In this work, we provide a causal view to find that this performance drop of OFL methods comes from the isolation problem, which means that local isolatedly trained models in OFL may easily fit to spurious correlations due to the data heterogeneity. From the causal perspective, we observe that the spurious fitting can be alleviated by augmenting intermediate features from other clients. Built upon our observation, we propose a novel learning approach to endow OFL with superb performance and low communication and storage costs, termed as FuseFL. Specifically, FuseFL decomposes neural networks into several blocks, and progressively trains and fuses each block following a bottom-up manner for feature augmentation, introducing no additional communication costs. Comprehensive experiments demonstrate that FuseFL outperforms existing OFL and ensemble FL by a significant margin. We conduct comprehensive experiments to show that FuseFL supports high scalability of clients, heterogeneous model training, and low memory costs. Our work is the first attempt using causality to analyze and alleviate data heterogeneity of OFL.
Spotlight Poster
Hrittik Roy · Marco Miani · Carl Henrik Ek · Philipp Hennig · Marvin Pförtner · Lukas Tatzel · Søren Hauberg
[ East Exhibit Hall A-C ]
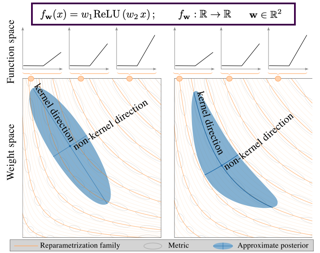
Abstract
Current approximate posteriors in Bayesian neural networks (BNNs) exhibit a crucial limitation: they fail to maintain invariance under reparameterization, i.e. BNNs assign different posterior densities to different parametrizations of identical functions. This creates a fundamental flaw in the application of Bayesian principles as it breaks the correspondence between uncertainty over the parameters with uncertainty over the parametrized function. In this paper, we investigate this issue in the context of the increasingly popular linearized Laplace approximation. Specifically, it has been observed that linearized predictives alleviate the common underfitting problems of the Laplace approximation. We develop a new geometric view of reparametrizations from which we explain the success of linearization. Moreover, we demonstrate that these reparameterization invariance properties can be extended to the original neural network predictive using a Riemannian diffusion process giving a straightforward algorithm for approximate posterior sampling, which empirically improves posterior fit.
Spotlight Poster
Elliot Paquette · Courtney Paquette · Lechao Xiao · Jeffrey Pennington
[ West Ballroom A-D ]
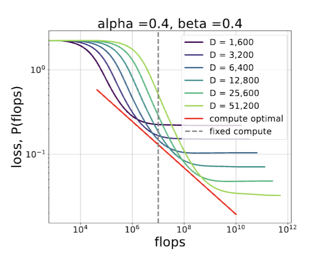
Abstract
We consider the solvable neural scaling model with three parameters: data complexity, target complexity, and model-parameter-count. We use this neural scaling model to derive new predictions about the compute-limited, infinite-data scaling law regime. To train the neural scaling model, we run one-pass stochastic gradient descent on a mean-squared loss. We derive a representation of the loss curves which holds over all iteration counts and improves in accuracy as the model parameter count grows. We then analyze the compute-optimal model-parameter-count, and identify 4 phases (+3 subphases) in the data-complexity/target-complexity phase-plane. The phase boundaries are determined by the relative importance of model capacity, optimizer noise, and embedding of the features. We furthermore derive, with mathematical proof and extensive numerical evidence, the scaling-law exponents in all of these phases, in particular computing the optimal model-parameter-count as a function of floating point operation budget. We include a colab notebook https://tinyurl.com/2saj6bkj, nanoChinchilla, that reproduces some key results of the paper.
Spotlight Poster
Sanae Lotfi · Yilun Kuang · Marc Finzi · Brandon Amos · Micah Goldblum · Andrew Wilson
[ East Exhibit Hall A-C ]
Abstract
Large language models (LLMs) with billions of parameters excel at predicting the next token in a sequence. Recent work computes non-vacuous compression-based generalization bounds for LLMs, but these bounds are vacuous for large models at the billion-parameter scale. Moreover, these bounds are obtained through restrictive compression techniques, bounding compressed models that generate low-quality text. Additionally, the tightness of these existing bounds depends on the number of IID documents in a training set rather than the much larger number of non-IID constituent tokens, leaving untapped potential for tighter bounds. In this work, we instead use properties of martingales to derive generalization bounds that benefit from the vast number of tokens in LLM training sets. Since a dataset contains far more tokens than documents, our generalization bounds not only tolerate but actually benefit from far less restrictive compression schemes. With Monarch matrices, Kronecker factorizations, and post-training quantization, we achieve non-vacuous generalization bounds for LLMs as large as LLaMA2-70B. Unlike previous approaches, our work achieves the first non-vacuous bounds for models that are deployed in practice and generate high-quality text.
Spotlight Poster
Jonathan So · Richard Turner
[ East Exhibit Hall A-C ]
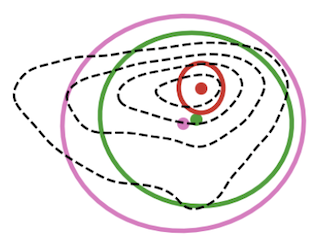
Abstract
Expectation propagation (EP) is a family of algorithms for performing approximate inference in probabilistic models. The updates of EP involve the evaluation of moments—expectations of certain functions—which can be estimated from Monte Carlo (MC) samples. However, the updates are not robust to MC noise when performed naively, and various prior works have attempted to address this issue in different ways. In this work, we provide a novel perspective on the moment-matching updates of EP; namely, that they perform natural-gradient-based optimisation of a variational objective. We use this insight to motivate two new EP variants, with updates that are particularly well-suited to MC estimation. They remain stable and are most sample-efficient when estimated with just a single sample. These new variants combine the benefits of their predecessors and address key weaknesses. In particular, they are easier to tune, offer an improved speed-accuracy trade-off, and do not rely on the use of debiasing estimators. We demonstrate their efficacy on a variety of probabilistic inference tasks.
Spotlight Poster
Mingrui Zhang · Chunyang Wang · Stephan C. Kramer · Joseph G Wallwork · Siyi Li · Jiancheng Liu · Xiang Chen · Matthew Piggott
[ East Exhibit Hall A-C ]

Abstract
Solving complex Partial Differential Equations (PDEs) accurately and efficiently is an essential and challenging problem in all scientific and engineering disciplines. Mesh movement methods provide the capability to improve the accuracy of the numerical solution without increasing the overall mesh degree of freedom count. Conventional sophisticated mesh movement methods are extremely expensive and struggle to handle scenarios with complex boundary geometries. However, existing learning-based methods require re-training from scratch given a different PDE type or boundary geometry, which limits their applicability, and also often suffer from robustness issues in the form of inverted elements. In this paper, we introduce the Universal Mesh Movement Network (UM2N), which -- once trained -- can be applied in a non-intrusive, zero-shot manner to move meshes with different size distributions and structures, for solvers applicable to different PDE types and boundary geometries. UM2N consists of a Graph Transformer (GT) encoder for extracting features and a Graph Attention Network (GAT) based decoder for moving the mesh. We evaluate our method on advection and Navier-Stokes based examples, as well as a real-world tsunami simulation case. Our method out-performs existing learning-based mesh movement methods in terms of the benchmarks described above. In comparison to the conventional sophisticated Monge-Ampère …
Spotlight Poster
Vivek Sivaraman Narayanaswamy · Kowshik Thopalli · Rushil Anirudh · Yamen Mubarka · Wesam Sakla · Jay Thiagarajan
[ East Exhibit Hall A-C ]
Abstract
Anchoring is a recent, architecture-agnostic principle for training deep neural networks that has been shown to significantly improve uncertainty estimation, calibration, and extrapolation capabilities. In this paper, we systematically explore anchoring as a general protocol for training vision models, providing fundamental insights into its training and inference processes and their implications for generalization and safety. Despite its promise, we identify a critical problem in anchored training that can lead to an increased risk of learning undesirable shortcuts, thereby limiting its generalization capabilities. To address this, we introduce a new anchored training protocol that employs a simple regularizer to mitigate this issue and significantly enhances generalization. We empirically evaluate our proposed approach across datasets and architectures of varying scales and complexities, demonstrating substantial performance gains in generalization and safety metrics compared to the standard training protocol. The open-source code is available at https://software.llnl.gov/anchoring.
Spotlight Poster
Hongjie Chen · Jingqiu Ding · Yiding Hua · David Steurer
[ West Ballroom A-D ]
Abstract
We give the first polynomial-time, differentially node-private, and robust algorithm for estimating the edge density of Erdős-Rényi random graphs and their generalization, inhomogeneous random graphs. We further prove information-theoretical lower bounds, showing that the error rate of our algorithm is optimal up to logarithmic factors. Previous algorithms incur either exponential running time or suboptimal error rates.Two key ingredients of our algorithm are (1) a new sum-of-squares algorithm for robust edge density estimation, and (2) the reduction from privacy to robustness based on sum-of-squares exponential mechanisms due to Hopkins et al. (STOC 2023).
Spotlight Poster
Noah Amsel · Tyler Chen · Anne Greenbaum · Cameron Musco · Christopher Musco
[ West Ballroom A-D ]
Abstract
Approximating the action of a matrix function $f(\vec{A})$ on a vector $\vec{b}$ is an increasingly important primitive in machine learning, data science, and statistics, with applications such as sampling high dimensional Gaussians, Gaussian process regression and Bayesian inference, principle component analysis, and approximating Hessian spectral densities.Over the past decade, a number of algorithms enjoying strong theoretical guarantees have been proposed for this task.Many of the most successful belong to a family of algorithms called Krylov subspace methods.Remarkably, a classic Krylov subspace method, called the Lanczos method for matrix functions (Lanczos-FA), frequently outperforms newer methods in practice. Our main result is a theoretical justification for this finding: we show that, for a natural class of rational functions, Lanczos-FA matches the error of the best possible Krylov subspace method up to a multiplicative approximation factor. The approximation factor depends on the degree of $f(x)$'s denominator and the condition number of $\vec{A}$, but not on the number of iterations $k$. Our result provides a strong justification for the excellent performance of Lanczos-FA, especially on functions that are well approximated by rationals, such as the matrix square root.
Spotlight Poster
Alexander Lappe · Anna Bognár · Ghazaleh Ghamkahri Nejad · Albert Mukovskiy · Lucas Martini · Martin Giese · Rufin Vogels
[ East Exhibit Hall A-C ]
Abstract
High-level visual brain regions contain subareas in which neurons appear to respond more strongly to examples of a particular semantic category, like faces or bodies, rather than objects. However, recent work has shown that while this finding holds on average, some out-of-category stimuli also activate neurons in these regions. This may be due to visual features common among the preferred class also being present in other images. Here, we propose a deep-learning-based approach for visualizing these features. For each neuron, we identify relevant visual features driving its selectivity by modelling responses to images based on latent activations of a deep neural network. Given an out-of-category image which strongly activates the neuron, our method first identifies a reference image from the preferred category yielding a similar feature activation pattern. We then backpropagate latent activations of both images to the pixel level, while enhancing the identified shared dimensions and attenuating non-shared features. The procedure highlights image regions containing shared features driving responses of the model neuron. We apply the algorithm to novel recordings from body-selective regions in macaque IT cortex in order to understand why some images of objects excite these neurons. Visualizations reveal object parts which resemble parts of a macaque …
Spotlight Poster
George Christodoulou · Alkmini Sgouritsa · Ioannis Vlachos
[ West Ballroom A-D ]
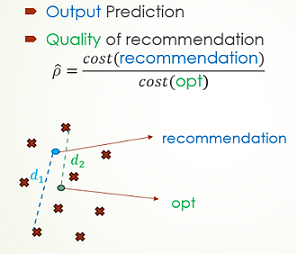
Abstract
Our work revisits the design of mechanisms via the learning-augmented framework. In this model, the algorithm is enhanced with imperfect (machine-learned) information concerning the input, usually referred to as prediction. The goal is to design algorithms whose performance degrades gently as a function of the prediction error and, in particular, perform well if the prediction is accurate, but also provide a worst-case guarantee under any possible error. This framework has been successfully applied recently to various mechanism design settings, where in most cases the mechanism is provided with a prediction about the types of the players.We adopt a perspective in which the mechanism is provided with an output recommendation. We make no assumptions about the quality of the suggested outcome, and the goal is to use the recommendation to design mechanisms with low approximation guarantees whenever the recommended outcome is reasonable, but at the same time to provide worst-case guarantees whenever the recommendation significantly deviates from the optimal one. We propose a generic, universal measure, which we call quality of recommendation, to evaluate mechanisms across various information settings. We demonstrate how this new metric can provide refined analysis in existing results.This model introduces new challenges, as the mechanism receives limited …
Spotlight Poster
Junsoo Oh · Chulhee Yun
[ West Ballroom A-D ]
Abstract
Patch-level data augmentation techniques such as Cutout and CutMix have demonstrated significant efficacy in enhancing the performance of vision tasks. However, a comprehensive theoretical understanding of these methods remains elusive. In this paper, we study two-layer neural networks trained using three distinct methods: vanilla training without augmentation, Cutout training, and CutMix training. Our analysis focuses on a feature-noise data model, which consists of several label-dependent features of varying rarity and label-independent noises of differing strengths. Our theorems demonstrate that Cutout training can learn low-frequency features that vanilla training cannot, while CutMix training can learn even rarer features that Cutout cannot capture. From this, we establish that CutMix yields the highest test accuracy among the three. Our novel analysis reveals that CutMix training makes the network learn all features and noise vectors "evenly" regardless of the rarity and strength, which provides an interesting insight into understanding patch-level augmentation.
Spotlight Poster
Chenyu Huang · Peng Ye · Tao Chen · Tong He · Xiangyu Yue · Wanli Ouyang
[ East Exhibit Hall A-C ]
Abstract
The success of pretrain-finetune paradigm brings about the release of numerous model weights. In this case, merging models finetuned on different tasks to enable a single model with multi-task capabilities is gaining increasing attention for its practicability. Existing model merging methods usually suffer from (1) significant performance degradation or (2) requiring tuning by additional data or training. In this paper, we rethink and analyze the existing model merging paradigm. We discover that using a single model's weights can hardly simulate all the models' performance. To tackle this issue, we propose Elect, Mask & Rescale-Merging (EMR-Merging). We first (a) elect a unified model from all the model weights and then (b) generate extremely lightweight task-specific modulators, including masks and rescalers, to align the direction and magnitude between the unified model and each specific model, respectively. EMR-Merging is tuning-free, thus requiring no data availability or any additional training while showing impressive performance. We find that EMR-Merging shows outstanding performance compared to existing merging methods under different classical and newly-established settings, including merging different numbers of vision models (up to 30), NLP models, PEFT models, and multi-modal models.
Spotlight Poster
Kun Yuan · vinkle srivastav · Nassir Navab · Nicolas Padoy
[ East Exhibit Hall A-C ]
Abstract
Surgical video-language pretraining (VLP) faces unique challenges due to the knowledge domain gap and the scarcity of multi-modal data. This study aims to bridge the gap by addressing issues regarding textual information loss in surgical lecture videos and the spatial-temporal challenges of surgical VLP. To tackle these issues, we propose a hierarchical knowledge augmentation approach and a novel Procedure-Encoded Surgical Knowledge-Augmented Video-Language Pretraining (PeskaVLP) framework. The proposed knowledge augmentation approach uses large language models (LLM) to refine and enrich surgical concepts, thus providing comprehensive language supervision and reducing the risk of overfitting. The PeskaVLP framework combines language supervision with visual self-supervision, constructing hard negative samples and employing a Dynamic Time Warping (DTW) based loss function to effectively comprehend the cross-modal procedural alignment. Extensive experiments on multiple public surgical scene understanding and cross-modal retrieval datasets show that our proposed method significantly improves zero-shot transferring performance and offers a generalist visual repre- sentation for further advancements in surgical scene understanding. The source code will be available at https://github.com/CAMMA-public/PeskaVLP.
Spotlight Poster
Zeyao Ma · Bohan Zhang · Jing Zhang · Jifan Yu · Xiaokang Zhang · Xiaohan Zhang · Sijia Luo · Xi Wang · Jie Tang
[ West Ballroom A-D ]
Abstract
We introduce SpreadsheetBench, a challenging spreadsheet manipulation benchmark exclusively derived from real-world scenarios, designed to immerse current large language models (LLMs) in the actual workflow of spreadsheet users. Unlike existing benchmarks that rely on synthesized queries and simplified spreadsheet files, SpreadsheetBench is built from 912 real questions gathered from online Excel forums, which reflect the intricate needs of users. The associated spreadsheets from the forums contain a variety of tabular data such as multiple tables, non-standard relational tables, and abundant non-textual elements. Furthermore, we propose a more reliable evaluation metric akin to online judge platforms, where multiple spreadsheet files are created as test cases for each instruction, ensuring the evaluation of robust solutions capable of handling spreadsheets with varying values.Our comprehensive evaluation of various LLMs under both single-round and multi-round inference settings reveals a substantial gap between the state-of-the-art (SOTA) models and human performance, highlighting the benchmark's difficulty.
Spotlight Poster
Billy Jin · Thomas Kesselheim · Will Ma · Sahil Singla
[ West Ballroom A-D ]
Abstract
Selling a single item to $n$ self-interested bidders is a fundamental problem in economics, where the two objectives typically considered are welfare maximization and revenue maximization. Since the optimal auctions are often impractical and do not work for sequential bidders, posted pricing auctions, where fixed prices are set for the item for different bidders, have emerged as a practical and effective alternative. This paper investigates how many samples are needed from bidders' value distributions to find near-optimal posted prices, considering both independent and correlated bidder distributions, and welfare versus revenue maximization. We obtain matching upper and lower bounds (up to logarithmic terms) on the sample complexity for all these settings.
Spotlight Poster
Yunnan Wang · Ziqiang Li · Wenyao Zhang · Zequn Zhang · Baao Xie · Xihui Liu · Wenjun Zeng · Xin Jin
[ East Exhibit Hall A-C ]
Abstract
There has been exciting progress in generating images from natural language or layout conditions. However, these methods struggle to faithfully reproduce complex scenes due to the insufficient modeling of multiple objects and their relationships. To address this issue, we leverage the scene graph, a powerful structured representation, for complex image generation. Different from the previous works that directly use scene graphs for generation, we employ the generative capabilities of variational autoencoders and diffusion models in a generalizable manner, compositing diverse disentangled visual clues from scene graphs. Specifically, we first propose a Semantics-Layout Variational AutoEncoder (SL-VAE) to jointly derive (layouts, semantics) from the input scene graph, which allows a more diverse and reasonable generation in a one-to-many mapping. We then develop a Compositional Masked Attention (CMA) integrated with a diffusion model, incorporating (layouts, semantics) with fine-grained attributes as generation guidance. To further achieve graph manipulation while keeping the visual content consistent, we introduce a Multi-Layered Sampler (MLS) for an "isolated" image editing effect. Extensive experiments demonstrate that our method outperforms recent competitors based on text, layout, or scene graph, in terms of generation rationality and controllability.
Spotlight Poster
Xincheng Yao · Zixin Chen · Chao Gao · Guangtao Zhai · Chongyang Zhang
[ East Exhibit Hall A-C ]
Abstract
This paper explores the problem of class-generalizable anomaly detection, where the objective is to train one unified AD model that can generalize to detect anomalies in diverse classes from different domains without any retraining or fine-tuning on the target data. Because normal feature representations vary significantly across classes, this will cause the widely studied one-for-one AD models to be poorly classgeneralizable (i.e., performance drops dramatically when used for new classes). In this work, we propose a simple but effective framework (called ResAD) that can be directly applied to detect anomalies in new classes. Our main insight is to learn the residual feature distribution rather than the initial feature distribution. In this way, we can significantly reduce feature variations. Even in new classes, the distribution of normal residual features would not remarkably shift from the learned distribution. Therefore, the learned model can be directly adapted to new classes. ResAD consists of three components: (1) a Feature Converter that converts initial features into residual features; (2) a simple and shallow Feature Constraintor that constrains normal residual features into a spatial hypersphere for further reducing feature variations and maintaining consistency in feature scales among different classes; (3) a Feature Distribution Estimator that estimates …
Spotlight Poster
Yubo Wang · Xueguang Ma · Ge Zhang · Yuansheng Ni · Abhranil Chandra · Shiguang Guo · Weiming Ren · Aaran Arulraj · Xuan He · Ziyan Jiang · Tianle Li · Max KU · Kai Wang · Alex Zhuang · Rongqi Fan · Xiang Yue · Wenhu Chen
[ West Ballroom A-D ]

Abstract
In the age of large-scale language models, benchmarks like the Massive Multitask Language Understanding (MMLU) have been pivotal in pushing the boundaries of what AI can achieve in language comprehension and reasoning across diverse domains. However, as models continue to improve, their performance on these benchmarks has begun to plateau, making it increasingly difficult to discern differences in model capabilities. This paper introduces MMLU-Pro, an enhanced dataset designed to extend the mostly knowledge-driven MMLU benchmark by integrating more challenging, reasoning-focused questions and expanding the choice set from four to ten options. Additionally, MMLU-Pro eliminates part of the trivial and noisy questions in MMLU. Our experimental results show that MMLU-Pro not only raises the challenge, causing a significant drop in accuracy by 16\% to 33\% compared to MMLU, but also demonstrates greater stability under varying prompts. With 24 different prompt styles tested, the sensitivity of model scores to prompt variations decreased from 4-5\% in MMLU to just 2\% in MMLU-Pro. Additionally, we found that models utilizing Chain of Thought (CoT) reasoning achieved better performance on MMLU-Pro compared to direct answering, which is in stark contrast to the findings on the original MMLU, indicating that MMLU-Pro includes more complex reasoning questions. Our …
Spotlight Poster
Usama Muneeb · Mesrob I Ohannessian
[ East Exhibit Hall A-C ]

Abstract
We consider scenarios where a very accurate (often small) predictive model using restricted features is available when training a full-featured (often larger) model. This restricted model may be thought of as ``side-information'', and can come either from an auxiliary dataset or from the same dataset by forcing the restriction. How can the restricted model be useful to the full model? To answer this, we introduce a methodology called Induced Model Matching (IMM). IMM aligns the context-restricted, or induced, version of the large model with the restricted model. We relate IMM to approaches such as noising, which is implicit in addressing the problem, and reverse knowledge distillation from weak teachers, which is explicit but does not exploit restriction being the nature of the weakness. We show that these prior methods can be thought of as approximations to IMM and can be problematic in terms of consistency. Experimentally, we first motivate IMM using logistic regression as a toy example. We then explore it in language modeling, the application that initially inspired it, and demonstrate it on both LSTM and transformer full models, using bigrams as restricted models. We lastly give a simple RL example, which shows that POMDP policies can help learn …
Spotlight Poster
Wolfgang Boettcher · Lukas Hoyer · Ozan Unal · Jan Eric Lenssen · Bernt Schiele
[ East Exhibit Hall A-C ]
Abstract
In this work, we introduce *Scribbles for All*, a label and training data generation algorithm for semantic segmentation trained on scribble labels. Training or fine-tuning semantic segmentation models with weak supervision has become an important topic recently and was subject to significant advances in model quality. In this setting, scribbles are a promising label type to achieve high quality segmentation results while requiring a much lower annotation effort than usual pixel-wise dense semantic segmentation annotations. The main limitation of scribbles as source for weak supervision is the lack of challenging datasets for scribble segmentation, which hinders the development of novel methods and conclusive evaluations. To overcome this limitation, *Scribbles for All* provides scribble labels for several popular segmentation datasets and provides an algorithm to automatically generate scribble labels for any dataset with dense annotations, paving the way for new insights and model advancements in the field of weakly supervised segmentation. In addition to providing datasets and algorithm, we evaluate state-of-the-art segmentation models on our datasets and show that models trained with our synthetic labels perform competitively with respect to models trained on manual labels. Thus, our datasets enable state-of-the-art research into methods for scribble-labeled semantic segmentation. The datasets, scribble generation …
Spotlight Poster
Xi Liu · Chaoyi Zhou · Siyu Huang
[ East Exhibit Hall A-C ]
Abstract
Novel-view synthesis aims to generate novel views of a scene from multiple inputimages or videos, and recent advancements like 3D Gaussian splatting (3DGS)have achieved notable success in producing photorealistic renderings with efficientpipelines. However, generating high-quality novel views under challenging settings,such as sparse input views, remains difficult due to insufficient information inunder-sampled areas, often resulting in noticeable artifacts. This paper presents3DGS-Enhancer, a novel pipeline for enhancing the representation quality of3DGS representations. We leverage 2D video diffusion priors to address thechallenging 3D view consistency problem, reformulating it as achieving temporalconsistency within a video generation process. 3DGS-Enhancer restores view-consistent latent features of rendered novel views and integrates them with theinput views through a spatial-temporal decoder. The enhanced views are thenused to fine-tune the initial 3DGS model, significantly improving its renderingperformance. Extensive experiments on large-scale datasets of unbounded scenesdemonstrate that 3DGS-Enhancer yields superior reconstruction performance andhigh-fidelity rendering results compared to state-of-the-art methods. The projectwebpage is https://xiliu8006.github.io/3DGS-Enhancer-project.
Spotlight Poster
Lanqing Li · Hai Zhang · Xinyu Zhang · Shatong Zhu · Yang YU · Junqiao Zhao · Pheng-Ann Heng
[ West Ballroom A-D ]
Abstract
As a marriage between offline RL and meta-RL, the advent of offline meta-reinforcement learning (OMRL) has shown great promise in enabling RL agents to multi-task and quickly adapt while acquiring knowledge safely. Among which, context-based OMRL (COMRL) as a popular paradigm, aims to learn a universal policy conditioned on effective task representations. In this work, by examining several key milestones in the field of COMRL, we propose to integrate these seemingly independent methodologies into a unified framework. Most importantly, we show that the pre-existing COMRL algorithms are essentially optimizing the same mutual information objective between the task variable $M$ and its latent representation $Z$ by implementing various approximate bounds. Such theoretical insight offers ample design freedom for novel algorithms. As demonstrations, we propose a supervised and a self-supervised implementation of $I(Z; M)$, and empirically show that the corresponding optimization algorithms exhibit remarkable generalization across a broad spectrum of RL benchmarks, context shift scenarios, data qualities and deep learning architectures. This work lays the information theoretic foundation for COMRL methods, leading to a better understanding of task representation learning in the context of reinforcement learning. Given itsgenerality, we envision our framework as a promising offline pre-training paradigm of foundation models for …
Spotlight Poster
Shuo Liu · Kaining Ying · Hao Zhang · yue yang · Yuqi Lin · Tianle Zhang · Chuanhao Li · Yu Qiao · Ping Luo · Wenqi Shao · Kaipeng Zhang
[ West Ballroom A-D ]
Abstract
Multi-turn visual conversation is an important ability of real-world AI assistants. However, the related evaluation benchmark is missed. This paper presents ConvBench, a multi-turn conversation benchmark with hierarchical capabilities ablation evaluation for Large Vision-Language Models (LVLMs). ConvBench comprises 577 curated multi-turn conversations, encompassing 215 tasks. These tasks are broad and open-ended, which resemble real-world user behaviors. ConvBench progressively examines the LVLMs' perception, reasoning, and creativity capabilities in each conversation and can decouple these capabilities in evaluations and thus perform reliable error attribution. Besides, considering the diversity of open-ended questions, we introduce an efficient and reliable automatic evaluation framework. Experimental results reveal that ConvBench is a significant challenge for current LVLMs, even for GPT4V, which achieves only a 39.51% score. Besides, we have some insightful findings, such as the weak perception of LVLMs inhibits authentic strengths in reasoning and creation. We believe our design of hierarchical capabilities, decoupling capabilities evaluation, and multi-turn conversation can blaze a new trail in LVLMs evaluation. Code and benchmark are released at https://github.com/shirlyliu64/ConvBench.
Spotlight Poster
Xingyu Zhu · Beier Zhu · Yi Tan · Shuo Wang · Yanbin Hao · Hanwang Zhang
[ East Exhibit Hall A-C ]
Abstract
Vision-language models, such as CLIP, have shown impressive generalization capacities when using appropriate text descriptions. While optimizing prompts on downstream labeled data has proven effective in improving performance, these methods entail labor costs for annotations and are limited by their quality. Additionally, since CLIP is pre-trained on highly imbalanced Web-scale data, it suffers from inherent label bias that leads to suboptimal performance. To tackle the above challenges, we propose a label-**F**ree p**ro**mpt distribution **l**earning and b**i**as **c**orrection framework, dubbed as **Frolic**, which boosts zero-shot performance without the need for labeled data. Specifically, our Frolic learns distributions over prompt prototypes to capture diverse visual representations and adaptively fuses these with the original CLIP through confidence matching.This fused model is further enhanced by correcting label bias via a label-free logit adjustment. Notably, our method is not only training-free but also circumvents the necessity for hyper-parameter tuning. Extensive experimental results across 16 datasets demonstrate the efficacy of our approach, particularly outperforming the state-of-the-art by an average of $2.6\%$ on 10 datasets with CLIP ViT-B/16 and achieving an average margin of $1.5\%$ on ImageNet and its five distribution shifts with CLIP ViT-B/16. Codes are available in [https://github.com/zhuhsingyuu/Frolic](https://github.com/zhuhsingyuu/Frolic).
Spotlight Poster
Junwei Deng · Ting-Wei Li · Shiyuan Zhang · Shixuan Liu · Yijun Pan · Hao Huang · Xinhe Wang · Pingbang Hu · Xingjian Zhang · Jiaqi Ma
[ East Exhibit Hall A-C ]

Abstract
Data attribution methods aim to quantify the influence of individual training samples on the prediction of artificial intelligence (AI) models. As training data plays an increasingly crucial role in the modern development of large-scale AI models, data attribution has found broad applications in improving AI performance and safety. However, despite a surge of new data attribution methods being developed recently, there lacks a comprehensive library that facilitates the development, benchmarking, and deployment of different data attribution methods. In this work, we introduce $\texttt{dattri}$, an open-source data attribution library that addresses the above needs. Specifically, $\texttt{dattri}$ highlights three novel design features. Firstly, $\texttt{dattri}$ proposes a unified and easy-to-use API, allowing users to integrate different data attribution methods into their PyTorch-based machine learning pipeline with a few lines of code changed. Secondly, $\texttt{dattri}$ modularizes low-level utility functions that are commonly used in data attribution methods, such as Hessian-vector product, inverse-Hessian-vector product or random projection, making it easier for researchers to develop new data attribution methods. Thirdly, $\texttt{dattri}$ provides a comprehensive benchmark framework with pre-trained models and ground truth annotations for a variety of benchmark settings, including generative AI settings. We have implemented a variety of state-of-the-art efficient data attribution methods that can …
Spotlight Poster
Chih-Hsuan Yang · Benjamin Feuer · Talukder "Zaki" Jubery · Zi Deng · Andre Nakkab · Md Zahid Hasan · Shivani Chiranjeevi · Kelly Marshall · Nirmal Baishnab · Asheesh Singh · ARTI SINGH · Soumik Sarkar · Nirav Merchant · Chinmay Hegde · Baskar Ganapathysubramanian
[ East Exhibit Hall A-C ]
Abstract
We introduce BioTrove, the largest publicly accessible dataset designed to advance AI applications in biodiversity. Curated from the iNaturalist platform and vetted to include only research-grade data, BioTrove contains 161.9 million images, offering unprecedented scale and diversity from three primary kingdoms: Animalia ("animals"), Fungi ("fungi"), and Plantae ("plants"), spanning approximately 366.6K species. Each image is annotated with scientific names, taxonomic hierarchies, and common names, providing rich metadata to support accurate AI model development across diverse species and ecosystems.We demonstrate the value of BioTrove by releasing a suite of CLIP models trained using a subset of 40 million captioned images, known as BioTrove-Train. This subset focuses on seven categories within the dataset that are underrepresented in standard image recognition models, selected for their critical role in biodiversity and agriculture: Aves ("birds"), Arachnida} ("spiders/ticks/mites"), Insecta ("insects"), Plantae ("plants"), Fungi ("fungi"), Mollusca ("snails"), and Reptilia ("snakes/lizards"). To support rigorous assessment, we introduce several new benchmarks and report model accuracy for zero-shot learning across life stages, rare species, confounding species, and multiple taxonomic levels.We anticipate that BioTrove will spur the development of AI models capable of supporting digital tools for pest control, crop monitoring, biodiversity assessment, and environmental conservation. These advancements are crucial for …
Spotlight Poster
Natalie Maus · Kyurae Kim · David Eriksson · Geoff Pleiss · John Cunningham · Jacob Gardner
[ West Ballroom A-D ]
Abstract
High-dimensional Bayesian optimization (BO) tasks such as molecular design often require $>10,$$000$ function evaluations before obtaining meaningful results. While methods like sparse variational Gaussian processes (SVGPs) reduce computational requirements in these settings, the underlying approximations result in suboptimal data acquisitions that slow the progress of optimization. In this paper we modify SVGPs to better align with the goals of BO: targeting informed data acquisition over global posterior fidelity. Using the framework of utility-calibrated variational inference (Lacoste–Julien et al., 2011), we unify GP approximation and data acquisition into a joint optimization problem, thereby ensuring optimal decisions under a limited computational budget. Our approach can be used with any decision-theoretic acquisition function and is readily compatible with trust region methods like TuRBO (Eriksson et al., 2019). We derive efficient joint objectives for the expected improvement (EI) and knowledge gradient (KG) acquisition functions in both the standard and batch BO settings. On a variety of recent high dimensional benchmark tasks in control and molecular design, our approach significantly outperforms standard SVGPs and is capable of achieving comparable rewards with up to $10\times$ fewer function evaluations.
Spotlight Poster
Rémi Bardenet · Subhroshekhar Ghosh · Hugo Simon-Onfroy · Hoang Son Tran
[ East Exhibit Hall A-C ]
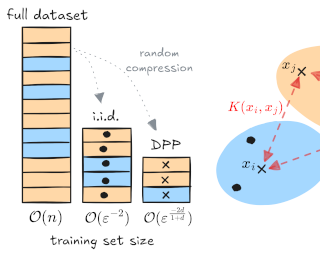
Abstract
Determinantal point processes (DPPs) are random configurations of points with tunable negative dependence. Because sampling is tractable, DPPs are natural candidates for subsampling tasks, such as minibatch selection or coreset construction. A \emph{coreset} is a subset of a (large) training set, such that minimizing an empirical loss averaged over the coreset is a controlled replacement for the intractable minimization of the original empirical loss.Typically, the control takes the form of a guarantee that the average loss over the coreset approximates the total loss uniformly across the parameter space.Recent work has provided significant empirical support in favor of using DPPs to build randomized coresets, coupled with interesting theoretical results that are suggestive but leave some key questions unanswered.In particular, the central question of whether the cardinality of a DPP-based coreset is fundamentally smaller than one based on independent sampling remained open.In this paper, we answer this question in the affirmative, demonstrating that \emph{DPPs can provably outperform independently drawn coresets}. In this vein, we contribute a conceptual understanding of coreset loss as a \emph{linear statistic} of the (random) coreset. We leverage this structural observation to connect the coresets problem to a more general problem of concentration phenomena for linear statistics of DPPs, …
Spotlight Poster
Artem Agafonov · Petr Ostroukhov · Roman Mozhaev · Konstantin Yakovlev · Eduard Gorbunov · Martin Takac · Alexander Gasnikov · Dmitry Kamzolov
[ West Ballroom A-D ]
Abstract
Variational inequalities represent a broad class of problems, including minimization and min-max problems, commonly found in machine learning. Existing second-order and high-order methods for variational inequalities require precise computation of derivatives, often resulting in prohibitively high iteration costs. In this work, we study the impact of Jacobian inaccuracy on second-order methods. For the smooth and monotone case, we establish a lower bound with explicit dependence on the level of Jacobian inaccuracy and propose an optimal algorithm for this key setting. When derivatives are exact, our method converges at the same rate as exact optimal second-order methods. To reduce the cost of solving the auxiliary problem, which arises in all high-order methods with global convergence, we introduce several Quasi-Newton approximations. Our method with Quasi-Newton updates achieves a global sublinear convergence rate. We extend our approach with a tensor generalization for inexact high-order derivatives and support the theory with experiments.
Spotlight Poster
Eyar Azar · Boaz Nadler
[ West Ballroom A-D ]
Abstract
The premise of semi-supervised learning (SSL) is that combining labeled and unlabeled data yields significantly more accurate models.Despite empirical successes, the theoretical understanding of SSL is still far from complete. In this work, we study SSL for high dimensional sparse Gaussian classification. To construct an accurate classifier a key task is feature selection, detecting the few variables that separate the two classes.For this SSL setting, we analyze information theoretic lower bounds for accurate feature selection as well as computational lower bounds, assuming the low-degree likelihood hardness conjecture. Our key contribution is the identification of a regime in the problem parameters (dimension, sparsity, number of labeled and unlabeled samples) where SSL is guaranteed to be advantageous for classification.Specifically, there is a regime where it is possible to construct in polynomial time an accurate SSL classifier.However, any computationally efficient supervised or unsupervised learning schemes, that separately use only the labeled or unlabeled data would fail. Our work highlights the provable benefits of combining labeled and unlabeled data for classification and feature selection in high dimensions. We present simulations that complement our theoretical analysis.
Spotlight Poster
Deqian Kong · Yuhao Huang · Jianwen Xie · Edouardo Honig · Ming Xu · Shuanghong Xue · Pei Lin · Sanping Zhou · Sheng Zhong · Nanning Zheng · Ying Nian Wu
[ East Exhibit Hall A-C ]
Abstract
This work explores the challenging problem of molecule design by framing it as a conditional generative modeling task, where target biological properties or desired chemical constraints serve as conditioning variables.We propose the Latent Prompt Transformer (LPT), a novel generative model comprising three components: (1) a latent vector with a learnable prior distribution modeled by a neural transformation of Gaussian white noise; (2) a molecule generation model based on a causal Transformer, which uses the latent vector as a prompt; and (3) a property prediction model that predicts a molecule's target properties and/or constraint values using the latent prompt. LPT can be learned by maximum likelihood estimation on molecule-property pairs. During property optimization, the latent prompt is inferred from target properties and constraints through posterior sampling and then used to guide the autoregressive molecule generation.After initial training on existing molecules and their properties, we adopt an online learning algorithm to progressively shift the model distribution towards regions that support desired target properties. Experiments demonstrate that LPT not only effectively discovers useful molecules across single-objective, multi-objective, and structure-constrained optimization tasks, but also exhibits strong sample efficiency.
Spotlight Poster
Ming Chen · Jie Chun · Shang Xiang · Luona Wei · Yonghao Du · Qian Wan · Yuning Chen · Yingwu Chen
[ West Ballroom A-D ]

Abstract
The quadratic unconstrained binary optimization (QUBO) is a well-known NP-hard problem that takes an $n\times n$ matrix $Q$ as input and decides an $n$-dimensional 0-1 vector $x$, to optimize a quadratic function. Existing learning-based models that always formulate the solution process as sequential decisions suffer from high computational overload. To overcome this issue, we propose a neural solver called the Value Classification Model (VCM) that formulates the solution process from a classification perspective. It applies a Depth Value Network (DVN) based on graph convolution that exploits the symmetry property in $Q$ to auto-grasp value features. These features are then fed into a Value Classification Network (VCN) which directly generates classification solutions. Trained by a highly efficient model-tailored Greedy-guided Self Trainer (GST) which does not require any priori optimal labels, VCM significantly outperforms competitors in both computational efficiency and solution quality with a remarkable generalization ability. It can achieve near-optimal solutions in milliseconds with an average optimality gap of just 0.362\% on benchmarks with up to 2500 variables. Notably, a VCM trained at a specific DVN depth can steadily find better solutions by simply extending the testing depth, which narrows the gap to 0.034\% on benchmarks. To our knowledge, this is …
Spotlight Poster
Elizabeth L. Baker · Gefan Yang · Michael Severinsen · Christy Hipsley · Stefan Sommer
[ East Exhibit Hall A-C ]
Abstract
Generative diffusion models and many stochastic models in science and engineering naturally live in infinite dimensions before discretisation. To incorporate observed data for statistical and learning tasks, one needs to condition on observations. While recent work has treated conditioning linear processes in infinite dimensions, conditioning non-linear processes in infinite dimensions has not been explored. This paper conditions function valued stochastic processes without prior discretisation. To do so, we use an infinite-dimensional version of Girsanov's theorem to condition a function-valued stochastic process, leading to a stochastic differential equation (SDE) for the conditioned process involving the score. We apply this technique to do time series analysis for shapes of organisms in evolutionary biology, where we discretise via the Fourier basis and then learn the coefficients of the score function with score matching methods.
Spotlight Poster
Polina Turishcheva · Max Burg · Fabian Sinz · Alexander Ecker
[ East Exhibit Hall A-C ]
Abstract
Deep predictive models of neuronal activity have recently enabled several new discoveries about the selectivity and invariance of neurons in the visual cortex.These models learn a shared set of nonlinear basis functions, which are linearly combined via a learned weight vector to represent a neuron's function.Such weight vectors, which can be thought as embeddings of neuronal function, have been proposed to define functional cell types via unsupervised clustering.However, as deep models are usually highly overparameterized, the learning problem is unlikely to have a unique solution, which raises the question if such embeddings can be used in a meaningful way for downstream analysis.In this paper, we investigate how stable neuronal embeddings are with respect to changes in model architecture and initialization. We find that $L_1$ regularization to be an important ingredient for structured embeddings and develop an adaptive regularization that adjusts the strength of regularization per neuron. This regularization improves both predictive performance and how consistently neuronal embeddings cluster across model fits compared to uniform regularization.To overcome overparametrization, we propose an iterative feature pruning strategy which reduces the dimensionality of performance-optimized models by half without loss of performance and improves the consistency of neuronal embeddings with respect to clustering neurons.Our results …
Spotlight Poster
Chaeyun Jang · Hyungi Lee · Jungtaek Kim · Juho Lee
[ East Exhibit Hall A-C ]
Abstract
Fine-tuning pre-trained models for downstream tasks is a widely adopted technique known for its adaptability and reliability across various domains. Despite its conceptual simplicity, fine-tuning entails several troublesome engineering choices, such as selecting hyperparameters and determining checkpoints from an optimization trajectory. To tackle the difficulty of choosing the best model, one effective solution is model fusion, which combines multiple models in a parameter space. However, we observe a large discrepancy between loss and metric landscapes during the fine-tuning of pre-trained language models. Building on this observation, we introduce a novel model fusion technique that optimizes both the desired metric and loss through multi-objective Bayesian optimization. In addition, to effectively select hyperparameters, we establish a two-stage procedure by integrating Bayesian optimization processes into our framework. Experiments across various downstream tasks show considerable performance improvements using our Bayesian optimization-guided method.
Spotlight Poster
Yue Yang · Mona Gandhi · Yufei Wang · Yifan Wu · Michael Yao · Chris Callison-Burch · James Gee · Mark Yatskar
[ East Exhibit Hall A-C ]

Abstract
While deep networks have achieved broad success in analyzing natural images, when applied to medical scans, they often fail in unexcepted situations. We investigate this challenge and focus on model sensitivity to domain shifts, such as data sampled from different hospitals or data confounded by demographic variables such as sex, race, etc, in the context of chest X-rays and skin lesion images. A key finding we show empirically is that existing visual backbones lack an appropriate prior from the architecture for reliable generalization in these settings. Taking inspiration from medical training, we propose giving deep networks a prior grounded in explicit medical knowledge communicated in natural language. To this end, we introduce Knowledge-enhanced Bottlenecks (KnoBo), a class of concept bottleneck models that incorporates knowledge priors that constrain it to reason with clinically relevant factors found in medical textbooks or PubMed. KnoBo uses retrieval-augmented language models to design an appropriate concept space paired with an automatic training procedure for recognizing the concept. We evaluate different resources of knowledge and recognition architectures on a broad range of domain shifts across 20 datasets. In our comprehensive evaluation with two imaging modalities, KnoBo outperforms fine-tuned models on confounded datasets by 32.4% on average. Finally, …
Spotlight Poster
Yubo Ma · Yuhang Zang · Liangyu Chen · Meiqi Chen · Yizhu Jiao · Xinze Li · Xinyuan Lu · Ziyu Liu · Yan Ma · Xiaoyi Dong · Pan Zhang · Liangming Pan · Yu-Gang Jiang · Jiaqi Wang · Yixin Cao · Aixin Sun
[ West Ballroom A-D ]
Abstract
Understanding documents with rich layouts and multi-modal components is a long-standing and practical task. Recent Large Vision-Language Models (LVLMs) have made remarkable strides in various tasks, particularly in single-page document understanding (DU). However, their abilities on long-context DU remain an open problem. This work presents MMLONGBENCH-DOC, a long-context, multi- modal benchmark comprising 1,082 expert-annotated questions. Distinct from previous datasets, it is constructed upon 135 lengthy PDF-formatted documents with an average of 47.5 pages and 21,214 textual tokens. Towards comprehensive evaluation, answers to these questions rely on pieces of evidence from (1) different sources (text, image, chart, table, and layout structure) and (2) various locations (i.e., page number). Moreover, 33.7\% of the questions are cross-page questions requiring evidence across multiple pages. 20.6\% of the questions are designed to be unanswerable for detecting potential hallucinations. Experiments on 14 LVLMs demonstrate that long-context DU greatly challenges current models. Notably, the best-performing model, GPT-4o, achieves an F1 score of only 44.9\%, while the second-best, GPT-4V, scores 30.5\%. Furthermore, 12 LVLMs (all except GPT-4o and GPT-4V) even present worse performance than their LLM counterparts which are fed with lossy-parsed OCR documents. These results validate the necessity of future research toward more capable long-context LVLMs.
Spotlight Poster
Samuel Holt · Tennison Liu · Mihaela van der Schaar
[ West Ballroom A-D ]
Abstract
Digital Twins (DTs) are computational models that simulate the states and temporal dynamics of real-world systems, playing a crucial role in prediction, understanding, and decision-making across diverse domains. However, existing approaches to DTs often struggle to generalize to unseen conditions in data-scarce settings, a crucial requirement for such models. To address these limitations, our work begins by establishing the essential desiderata for effective DTs. Hybrid Digital Twins (**HDTwins**) represent a promising approach to address these requirements, modeling systems using a composition of both mechanistic and neural components. This hybrid architecture simultaneously leverages (partial) domain knowledge and neural network expressiveness to enhance generalization, with its modular design facilitating improved evolvability. While existing hybrid models rely on expert-specified architectures with only parameters optimized on data, *automatically* specifying and optimizing HDTwins remains intractable due to the complex search space and the need for flexible integration of domain priors. To overcome this complexity, we propose an evolutionary algorithm (**HDTwinGen**) that employs Large Language Models (LLMs) to autonomously propose, evaluate, and optimize HDTwins. Specifically, LLMs iteratively generate novel model specifications, while offline tools are employed to optimize emitted parameters. Correspondingly, proposed models are evaluated and evolved based on targeted feedback, enabling the discovery of increasingly …
Spotlight Poster
Nicholas Krämer · Pablo Moreno-Muñoz · Hrittik Roy · Søren Hauberg
[ East Exhibit Hall A-C ]
Abstract
Tuning scientific and probabilistic machine learning models - for example, partial differential equations, Gaussian processes, or Bayesian neural networks - often relies on evaluating functions of matrices whose size grows with the data set or the number of parameters.While the state-of-the-art for _evaluating_ these quantities is almost always based on Lanczos and Arnoldi iterations, the present work is the first to explain how to _differentiate_ these workhorses of numerical linear algebra efficiently.To get there, we derive previously unknown adjoint systems for Lanczos and Arnoldi iterations, implement them in JAX, and show that the resulting code can compete with Diffrax when it comes to differentiating PDEs, GPyTorch for selecting Gaussian process models and beats standard factorisation methods for calibrating Bayesian neural networks.All this is achieved without any problem-specific code optimisation.Find the code at [link redacted] and install the library with *pip install [redacted]*.
Spotlight Poster
Jiaqi Wang · Xiaochen Wang · Lingjuan Lyu · Jinghui Chen · Fenglong Ma
[ West Ballroom A-D ]
Abstract
This study introduces the Federated Medical Knowledge Injection (FedMEKI) platform, a new benchmark designed to address the unique challenges of integrating medical knowledge into foundation models under privacy constraints. By leveraging a cross-silo federated learning approach, FedMEKI circumvents the issues associated with centralized data collection, which is often prohibited under health regulations like the Health Insurance Portability and Accountability Act (HIPAA) in the USA. The platform is meticulously designed to handle multi-site, multi-modal, and multi-task medical data, which includes 7 medical modalities, including images, signals, texts, laboratory test results, vital signs, input variables, and output variables. The curated dataset to validate FedMEKI covers 8 medical tasks, including 6 classification tasks (lung opacity detection, COVID-19 detection, electrocardiogram (ECG) abnormal detection, mortality prediction, sepsis protection, and enlarged cardiomediastinum detection) and 2 generation tasks (medical visual question answering (MedVQA) and ECG noise clarification). This comprehensive dataset is partitioned across several clients to facilitate the decentralized training process under 16 benchmark approaches. FedMEKI not only preserves data privacy but also enhances the capability of medical foundation models by allowing them to learn from a broader spectrum of medical knowledge without direct data exposure, thereby setting a new benchmark in the application of foundation models …
Spotlight Poster
Giovanni Bellitto · Federica Proietto Salanitri · Matteo Pennisi · Matteo Boschini · Lorenzo Bonicelli · Angelo Porrello · SIMONE CALDERARA · Simone Palazzo · Concetto Spampinato
[ West Ballroom A-D ]
Abstract
We present Saliency-driven Experience Replay - SER - a biologically-plausible approach based on replicating human visual saliency to enhance classification models in continual learning settings. Inspired by neurophysiological evidence that the primary visual cortex does not contribute to object manifold untangling for categorization and that primordial saliency biases are still embedded in the modern brain, we propose to employ auxiliary saliency prediction features as a modulation signal to drive and stabilize the learning of a sequence of non-i.i.d. classification tasks. Experimental results confirm that SER effectively enhances the performance (in some cases up to about twenty percent points) of state-of-the-art continual learning methods, both in class-incremental and task-incremental settings. Moreover, we show that saliency-based modulation successfully encourages the learning of features that are more robust to the presence of spurious features and to adversarial attacks than baseline methods. Code is available at: https://github.com/perceivelab/SER
Spotlight Poster
Xizhou Zhu · Xue Yang · Zhaokai Wang · Hao Li · Wenhan Dou · Junqi Ge · Lewei Lu · Yu Qiao · Jifeng Dai
[ East Exhibit Hall A-C ]

Abstract
Image pyramids are commonly used in modern computer vision tasks to obtain multi-scale features for precise understanding of images. However, image pyramids process multiple resolutions of images using the same large-scale model, which requires significant computational cost. To overcome this issue, we propose a novel network architecture known as the Parameter-Inverted Image Pyramid Networks (PIIP). Our core idea is to use models with different parameter sizes to process different resolution levels of the image pyramid, thereby balancing computational efficiency and performance. Specifically, the input to PIIP is a set of multi-scale images, where higher resolution images are processed by smaller networks. We further propose a feature interaction mechanism to allow features of different resolutions to complement each other and effectively integrate information from different spatial scales. Extensive experiments demonstrate that the PIIP achieves superior performance in tasks such as object detection, segmentation, and image classification, compared to traditional image pyramid methods and single-branch networks, while reducing computational cost. Notably, when applying our method on a large-scale vision foundation model InternViT-6B, we improve its performance by 1\%-2\% on detection and segmentation with only 40\%-60\% of the original computation. These results validate the effectiveness of the PIIP approach and provide a new …
Spotlight Poster
Chun Gu · Zeyu Yang · Zijie Pan · Xiatian Zhu · Li Zhang
[ East Exhibit Hall A-C ]

Abstract
3D representation is essential to the significant advance of 3D generation with 2D diffusion priors. As a flexible representation, NeRF has been first adopted for 3D representation. With density-based volumetric rendering, it however suffers both intensive computational overhead and inaccurate mesh extraction. Using a signed distance field and Marching Tetrahedra, DMTet allows for precise mesh extraction and real-time rendering but is limited in handling large topological changes in meshes, leading to optimization challenges. Alternatively, 3D Gaussian Splatting (3DGS) is favored in both training and rendering efficiency while falling short in mesh extraction. In this work, we introduce a novel 3D representation, Tetrahedron Splatting (TeT-Splatting), that supports easy convergence during optimization, precise mesh extraction, and real-time rendering simultaneously. This is achieved by integrating surface-based volumetric rendering within a structured tetrahedral grid while preserving the desired ability of precise mesh extraction, and a tile-based differentiable tetrahedron rasterizer. Furthermore, we incorporate eikonal and normal consistency regularization terms for the signed distance field to improve generation quality and stability. Critically, our representation can be trained without mesh extraction, making the optimization process easier to converge. Our TeT-Splatting can be readily integrated in existing 3D generation pipelines, along with polygonal mesh for texture optimization. Extensive …
Spotlight Poster
Julien Pourcel · Cédric Colas · Gaia Molinaro · Pierre-Yves Oudeyer · Laetitia Teodorescu
[ East Exhibit Hall A-C ]
Abstract
The ability to invent novel and interesting problems is a remarkable feature of human intelligence that drives innovation, art, and science. We propose a method that aims to automate this process by harnessing the power of state-of-the-art generative models to produce a diversity of challenging yet solvable problems, here in the context of Python programming puzzles. Inspired by the intrinsically motivated literature, Autotelic CodE Search (ACES) jointly optimizes for the diversity and difficulty of generated problems. We represent problems in a space of LLM-generated semantic descriptors describing the programming skills required to solve them (e.g. string manipulation, dynamic programming, etc.) and measure their difficulty empirically as a linearly decreasing function of the success rate of \textit{Llama-3-70B}, a state-of-the-art LLM problem solver. ACES iteratively prompts a large language model to generate difficult problems achieving a diversity of target semantic descriptors (goal-directed exploration) using previously generated problems as in-context examples. ACES generates problems that are more diverse and more challenging than problems produced by baseline methods and three times more challenging than problems found in existing Python programming benchmarks on average across 11 state-of-the-art code LLMs.
Spotlight Poster
Hassan Ashtiani · Mahbod Majid · Shyam Narayanan
[ West Ballroom A-D ]
Abstract
We study the problem of learning mixtures of Gaussians with approximate differential privacy. We prove that roughly $kd^2 + k^{1.5} d^{1.75} + k^2 d$ samples suffice to learn a mixture of $k$ arbitrary $d$-dimensional Gaussians up to low total variation distance, with differential privacy. Our work improves over the previous best result (which required roughly $k^2 d^4$ samples) and is provably optimal when $d$ is much larger than $k^2$. Moreover, we give the first optimal bound for privately learning mixtures of $k$ univariate (i.e., $1$-dimensional) Gaussians. Importantly, we show that the sample complexity for learning mixtures of univariate Gaussians is linear in the number of components $k$, whereas the previous best sample complexity was quadratic in $k$. Our algorithms utilize various techniques, including the inverse sensitivity mechanism, sample compression for distributions, and methods for bounding volumes of sumsets.
Spotlight Poster
Xiao Zhang · William Gao · Seemandhar Jain · Michael Maire · David Forsyth · Anand Bhattad
[ East Exhibit Hall A-C ]

Abstract
Image relighting is the task of showing what a scene from a source image would look like if illuminated differently. Inverse graphic schemes recover an explicit representation of geometry and a set of chosen intrinsics, then relight with some form of renderer. But error control for inverse graphics is difficult, and inverse graphics methods can represent only the effects of the chosen intrinsics. This paper describes a relighting method that is entirely data-driven, where intrinsics and lighting are each represented as latent variables. Our approach produces SOTA relightings of real scenes, as measured by standard metrics. We show that albedo can be recovered from our latent intrinsics without using any example albedos, and that the albedos recovered are competitive with SOTA methods.
Spotlight Poster
Ziyi Wu · Yulia Rubanova · Rishabh Kabra · Drew Hudson · Igor Gilitschenski · Yusuf Aytar · Sjoerd van Steenkiste · Kelsey Allen · Thomas Kipf
[ East Exhibit Hall A-C ]
Abstract
We address the problem of multi-object 3D pose control in image diffusion models. Instead of conditioning on a sequence of text tokens, we propose to use a set of per-object representations, *Neural Assets*, to control the 3D pose of individual objects in a scene. Neural Assets are obtained by pooling visual representations of objects from a reference image, such as a frame in a video, and are trained to reconstruct the respective objects in a different image, e.g., a later frame in the video. Importantly, we encode object visuals from the reference image while conditioning on object poses from the target frame, which enables learning disentangled appearance and position features. Combining visual and 3D pose representations in a sequence-of-tokens format allows us to keep the text-to-image interface of existing models, with Neural Assets in place of text tokens. By fine-tuning a pre-trained text-to-image diffusion model with this information, our approach enables fine-grained 3D pose and placement control of individual objects in a scene. We further demonstrate that Neural Assets can be transferred and recomposed across different scenes. Our model achieves state-of-the-art multi-object editing results on both synthetic 3D scene datasets, as well as two real-world video datasets (Objectron, Waymo Open).
Spotlight Poster
António Farinhas · Haau-Sing Li · André Martins
[ East Exhibit Hall A-C ]
Abstract
To ensure large language models (LLMs) are used safely, one must reduce their propensity to hallucinate or to generate unacceptable answers. A simple and often used strategy is to first let the LLM generate multiple hypotheses and then employ a reranker to choose the best one. In this paper, we draw a parallel between this strategy and the use of redundancy to decrease the error rate in noisy communication channels. We conceptualize the generator as a sender transmitting multiple descriptions of a message through parallel noisy channels. The receiver decodes the message by ranking the (potentially corrupted) descriptions and selecting the one found to be most reliable. We provide conditions under which this protocol is asymptotically error-free (i.e., yields an acceptable answer almost surely) even in scenarios where the reranker is imperfect (governed by Mallows or Zipf-Mandelbrot models) and the channel distributions are statistically dependent. We use our framework to obtain reranking laws which we validate empirically on two real-world tasks using LLMs: text-to-code generation with DeepSeek-Coder 7B and machine translation of medical data with TowerInstruct 13B.
Spotlight Poster
Ariel Procaccia · Ben Schiffer · Shirley Zhang
[ West Ballroom A-D ]
Abstract
We consider the problem of online fair division of indivisible goods to players when there are a finite number of types of goods and player values are drawn from distributions with unknown means. Our goal is to maximize social welfare subject to allocating the goods fairly in expectation. When a player's value for an item is unknown at the time of allocation, we show that this problem reduces to a variant of (stochastic) multi-armed bandits, where there exists an arm for each player's value for each type of good. At each time step, we choose a distribution over arms which determines how the next item is allocated. We consider two sets of fairness constraints for this problem: envy-freeness in expectation and proportionality in expectation. Our main result is the design of an explore-then-commit algorithm that achieves $\tilde{O}(T^{2/3})$ regret while maintaining either fairness constraint. This result relies on unique properties fundamental to fair-division constraints that allow faster rates of learning, despite the restricted action space.
Spotlight Poster
Yue Yu · Ning Liu · Fei Lu · Tian Gao · Siavash Jafarzadeh · Stewart A Silling
[ East Exhibit Hall A-C ]
Abstract
Despite recent popularity of attention-based neural architectures in core AI fields like natural language processing (NLP) and computer vision (CV), their potential in modeling complex physical systems remains under-explored. Learning problems in physical systems are often characterized as discovering operators that map between function spaces based on a few instances of function pairs. This task frequently presents a severely ill-posed PDE inverse problem. In this work, we propose a novel neural operator architecture based on the attention mechanism, which we coin Nonlocal Attention Operator (NAO), and explore its capability towards developing a foundation physical model. In particular, we show that the attention mechanism is equivalent to a double integral operator that enables nonlocal interactions among spatial tokens, with a data-dependent kernel characterizing the inverse mapping from data to the hidden parameter field of the underlying operator. As such, the attention mechanism extracts global prior information from training data generated by multiple systems, and suggests the exploratory space in the form of a nonlinear kernel map. Consequently, NAO can address ill-posedness and rank deficiency in inverse PDE problems by encoding regularization and achieving generalizability. Lastly, we empirically demonstrate the advantages of NAO over baseline neural models in terms of the generalizability …
Spotlight Poster
Christoph Jansen · Georg Schollmeyer · Julian Rodemann · Hannah Blocher · Thomas Augustin
[ West Ballroom A-D ]
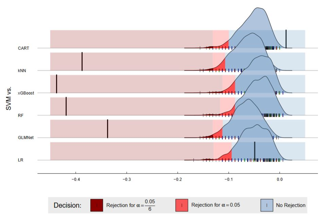
Abstract
Given the vast number of classifiers that have been (and continue to be) proposed, reliable methods for comparing them are becoming increasingly important. The desire for reliability is broken down into three main aspects: (1) Comparisons should allow for different quality metrics simultaneously. (2) Comparisons should take into account the statistical uncertainty induced by the choice of benchmark suite. (3) The robustness of the comparisons under small deviations in the underlying assumptions should be verifiable. To address (1), we propose to compare classifiers using a generalized stochastic dominance ordering (GSD) and present the GSD-front as an information-efficient alternative to the classical Pareto-front. For (2), we propose a consistent statistical estimator for the GSD-front and construct a statistical test for whether a (potentially new) classifier lies in the GSD-front of a set of state-of-the-art classifiers. For (3), we relax our proposed test using techniques from robust statistics and imprecise probabilities. We illustrate our concepts on the benchmark suite PMLB and on the platform OpenML.
Spotlight Poster
Yuezhu Xu · S Sivaranjani
[ East Exhibit Hall A-C ]
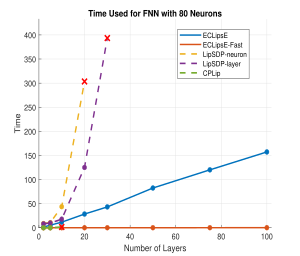
Abstract
The Lipschitz constant plays a crucial role in certifying the robustness of neural networks to input perturbations. Since calculating the exact Lipschitz constant is NP-hard, efforts have been made to obtain tight upper bounds on the Lipschitz constant. Typically, this involves solving a large matrix verification problem, the computational cost of which grows significantly for both deeper and wider networks. In this paper, we provide a compositional approach to estimate Lipschitz constants for deep feed-forward neural networks. We first obtain an exact decomposition of the large matrix verification problem into smaller sub-problems. Then, leveraging the underlying cascade structure of the network, we develop two algorithms. The first algorithm explores the geometric features of the problem and enables us to provide Lipschitz estimates that are comparable to existing methods by solving small semidefinite programs (SDPs) that are only as large as the size of each layer. The second algorithm relaxes these sub-problems and provides a closed-form solution to each sub-problem for extremely fast estimation, altogether eliminating the need to solve SDPs. The two algorithms represent different levels of trade-offs between efficiency and accuracy. Finally, we demonstrate that our approach provides a steep reduction in computation time (as much as several thousand …
Spotlight Poster
Yerram Varun · Rahul Madhavan · Sravanti Addepalli · Arun Suggala · Karthikeyan Shanmugam · Prateek Jain
[ West Ballroom A-D ]
Abstract
Large Language Models (LLMs) are typically trained to predict in the forward direction of time. However, recent works have shown that prompting these models to look back and critique their own generations can produce useful feedback. Motivated by this, we explore the question of whether LLMs can be empowered to think (predict and score) backwards to provide unsupervised feedback that complements forward LLMs. Towards this, we introduce Time Reversed Language Models (TRLMs), which can score and generate queries when conditioned on responses, effectively functioning in the reverse direction of time. Further, to effectively infer in the response to query direction, we pre-train and fine-tune a language model (TRLM-Ba) in the reverse token order from scratch. We show empirically (and theoretically in a stylized setting) that time-reversed models can indeed complement forward model predictions when used to score the query given response for re-ranking multiple forward generations. We obtain up to 5\% improvement on the widely used AlpacaEval Leaderboard over the competent baseline of best-of-N re-ranking using self log-perplexity scores. We further show that TRLM scoring outperforms conventional forward scoring of response given query, resulting in significant gains in applications such as citation generation and passage retrieval. We next leverage the …
Spotlight Poster
Laurynas Karazija · Iro Laina · Christian Rupprecht · Andrea Vedaldi
[ East Exhibit Hall A-C ]
Abstract
We consider the problem of segmenting objects in videos based on their motion and no other forms of supervision. Prior work has often approached this problem by using the principle of common fate, namely the fact that the motion of points that belong to the same object is strongly correlated. However, most authors have only considered instantaneous motion from optical flow. In this work, we present a way to train a segmentation network using long-term point trajectories as a supervisory signal to complement optical flow. The key difficulty is that long-term motion, unlike instantaneous motion, is difficult to model -- any parametric approximation is unlikely to capture complex motion patterns over long periods of time. We instead draw inspiration from subspace clustering approaches, proposing a loss function that seeks to group the trajectories into low-rank matrices where the motion of object points can be approximately explained as a linear combination of other point tracks. Our method outperforms the prior art on motion-based segmentation, which shows the utility of long-term motion and the effectiveness of our formulation.
Spotlight Poster
Thao Nguyen · Matthew Wallingford · Sebastin Santy · Wei-Chiu Ma · Sewoong Oh · Ludwig Schmidt · Pang Wei Koh · Ranjay Krishna
[ East Exhibit Hall A-C ]

Abstract
Massive web-crawled image-text datasets lay the foundation for recent progress in multimodal learning. These datasets are designed with the goal of training a model to do well on standard computer vision benchmarks, many of which, however, have been shown to be English-centric (e.g., ImageNet). Consequently, existing data curation techniques gravitate towards using predominantly English image-text pairs and discard many potentially useful non-English samples. Our work questions this practice. Multilingual data is inherently enriching not only because it provides a gateway to learn about culturally salient concepts, but also because it depicts common concepts differently from monolingual data. We thus conduct a systematic study to explore the performance benefits of using more samples of non-English origins with respect to English vision tasks. By translating all multilingual image-text pairs from a raw web crawl to English and re-filtering them, we increase the prevalence of (translated) multilingual data in the resulting training set. Pre-training on this dataset outperforms using English-only or English-dominated datasets on ImageNet, ImageNet distribution shifts, image-English-text retrieval and on average across 38 tasks from the DataComp benchmark. On a geographically diverse task like GeoDE, we also observe improvements across all regions, with the biggest gain coming from Africa. In addition, …
Spotlight Poster
Clément Bonet · Théo Uscidda · Adam David · Pierre-Cyril Aubin-Frankowski · Anna Korba
[ West Ballroom A-D ]
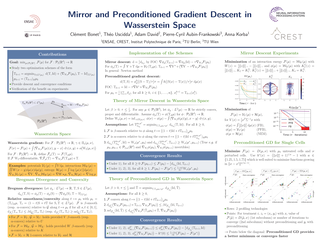
Abstract
As the problem of minimizing functionals on the Wasserstein space encompasses many applications in machine learning, different optimization algorithms on $\mathbb{R}^d$ have received their counterpart analog on the Wasserstein space. We focus here on lifting two explicit algorithms: mirror descent and preconditioned gradient descent. These algorithms have been introduced to better capture the geometry of the function to minimize and are provably convergent under appropriate (namely relative) smoothness and convexity conditions. Adapting these notions to the Wasserstein space, we prove guarantees of convergence of some Wasserstein-gradient-based discrete-time schemes for new pairings of objective functionals and regularizers. The difficulty here is to carefully select along which curves the functionals should be smooth and convex. We illustrate the advantages of adapting the geometry induced by the regularizer on ill conditioned optimization tasks, and showcase the improvement of choosing different discrepancies and geometries in a computational biology task of aligning single-cells.
Spotlight Poster
Dominik Fuchsgruber · Tom Wollschläger · Stephan Günnemann
[ East Exhibit Hall A-C ]
Abstract
In domains with interdependent data, such as graphs, quantifying the epistemic uncertainty of a Graph Neural Network (GNN) is challenging as uncertainty can arise at different structural scales. Existing techniques neglect this issue or only distinguish between structure-aware and structure-agnostic uncertainty without combining them into a single measure. We propose GEBM, an energy-based model (EBM) that provides high-quality uncertainty estimates by aggregating energy at different structural levels that naturally arise from graph diffusion. In contrast to logit-based EBMs, we provably induce an integrable density in the data space by regularizing the energy function. We introduce an evidential interpretation of our EBM that significantly improves the predictive robustness of the GNN. Our framework is a simple and effective post hoc method applicable to any pre-trained GNN that is sensitive to various distribution shifts. It consistently achieves the best separation of in-distribution and out-of-distribution data on 6 out of 7 anomaly types while having the best average rank over shifts on *all* datasets.
Spotlight Poster
Yushan Zhang · Bastian Wandt · Maria Magnusson · Michael Felsberg
[ East Exhibit Hall A-C ]
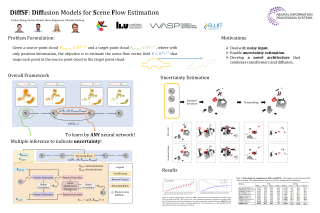
Abstract
Scene flow estimation is an essential ingredient for a variety of real-world applications, especially for autonomous agents, such as self-driving cars and robots. While recent scene flow estimation approaches achieve reasonable accuracy, their applicability to real-world systems additionally benefits from a reliability measure. Aiming at improving accuracy while additionally providing an estimate for uncertainty, we propose DiffSF that combines transformer-based scene flow estimation with denoising diffusion models. In the diffusion process, the ground truth scene flow vector field is gradually perturbed by adding Gaussian noise. In the reverse process, starting from randomly sampled Gaussian noise, the scene flow vector field prediction is recovered by conditioning on a source and a target point cloud. We show that the diffusion process greatly increases the robustness of predictions compared to prior approaches resulting in state-of-the-art performance on standard scene flow estimation benchmarks. Moreover, by sampling multiple times with different initial states, the denoising process predicts multiple hypotheses, which enables measuring the output uncertainty, allowing our approach to detect a majority of the inaccurate predictions. The code is available at https://github.com/ZhangYushan3/DiffSF.
Spotlight Poster
Davide Legacci · Panayotis Mertikopoulos · Christos Papadimitriou · Georgios Piliouras · Bary Pradelski
[ West Ballroom A-D ]
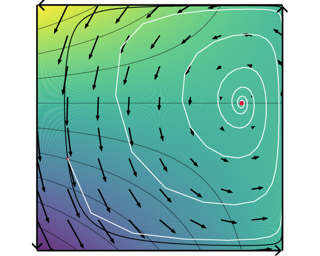
Abstract
The long-run behavior of multi-agent online learning -- and, in particular, no-regret learning -- is relatively well-understood in potential games, where players have common interests. By contrast, in general harmonic games -- the strategic complement of potential games, where players have competing interests -- very little is known outside the narrow subclass of $2$-player zero-sum games with a fully-mixed equilibrium. Our paper seeks to partially fill this gap by focusing on the full class of (generalized) harmonic games and examining the convergence properties of "follow-the-regularized-leader" (FTRL), the most widely studied class of no-regret learning schemes. As a first result, we show that the continuous-time dynamics of FTRL are Poincaré recurrent, i.e., they return arbitrarily close to their starting point infinitely often, and hence fail to converge. In discrete time, the standard, "vanilla" implementation of FTRL may lead to even worse outcomes, eventually trapping the players in a perpetual cycle of best-responses. However, if FTRL is augmented with a suitable extrapolation step -- which includes as special cases the optimistic and mirror-prox variants of FTRL -- we show that learning converges to a Nash equilibrium from any initial condition, and all players are guaranteed at most $\mathcal{O}(1)$ regret. These results provide …
Spotlight Poster
Haiwen Diao · Yufeng Cui · Xiaotong Li · Yueze Wang · Huchuan Lu · Xinlong Wang
[ East Exhibit Hall A-C ]

Abstract
Existing vision-language models (VLMs) mostly rely on vision encoders to extract visual features followed by large language models (LLMs) for visual-language tasks. However, the vision encoders set a strong inductive bias in abstracting visual representation, e.g., resolution, aspect ratio, and semantic priors, which could impede the flexibility and efficiency of the VLMs. Training pure VLMs that accept the seamless vision and language inputs, i.e., without vision encoders, remains challenging and rarely explored. Empirical observations reveal that direct training without encoders results in slow convergence and large performance gaps. In this work, we bridge the gap between encoder-based and encoder-free models, and present a simple yet effective training recipe towards pure VLMs. Specifically, we unveil the key aspects of training encoder-free VLMs efficiently via thorough experiments: (1) Bridging vision-language representation inside one unified decoder; (2) Enhancing visual recognition capability via extra supervision. With these strategies, we launch EVE, an encoder-free vision-language model that can be trained and forwarded efficiently. Notably, solely utilizing 35M publicly accessible data, EVE can impressively rival the encoder-based VLMs of similar capacities across multiple vision-language benchmarks. It significantly outperforms the counterpart Fuyu-8B with mysterious training procedures and undisclosed training data. We believe that EVE provides a transparent …
Spotlight Poster
Eli Chien · Haoyu Wang · Ziang Chen · Pan Li
[ West Ballroom A-D ]
Abstract
Machine unlearning has raised significant interest with the adoption of laws ensuring the ``right to be forgotten''. Researchers have provided a probabilistic notion of approximate unlearning under a similar definition of Differential Privacy (DP), where privacy is defined as statistical indistinguishability to retraining from scratch. We propose Langevin unlearning, an unlearning framework based on noisy gradient descent with privacy guarantees for approximate unlearning problems. Langevin unlearning unifies the DP learning process and the privacy-certified unlearning process with many algorithmic benefits. These include approximate certified unlearning for non-convex problems, complexity saving compared to retraining, sequential and batch unlearning for multiple unlearning requests.
Spotlight Poster
Albert Tseng · Qingyao Sun · David Hou · Christopher De Sa
[ East Exhibit Hall A-C ]
Abstract
Post-training quantization (PTQ) reduces the memory footprint of LLMs by quantizing weights to low-precision datatypes.Since LLM inference is usually memory-bound, PTQ methods can improve inference throughput.Recent state-of-the-art PTQ approaches use vector quantization (VQ) to quantize multiple weights at once, which improves information utilization through better shaping.However, VQ requires a codebook with size exponential in the dimension.This limits current VQ-based PTQ works to low VQ dimensions ($\le 8$) that in turn limit quantization quality.Here, we introduce QTIP, which instead uses trellis coded quantization (TCQ) to achieve ultra-high-dimensional quantization. TCQ uses a stateful decoder that separates the codebook size from the bitrate and effective dimension. QTIP introduces a spectrum of lookup-only to computed lookup-free trellis codes designed for a hardware-efficient "bitshift" trellis structure; these codes achieve state-of-the-art results in both quantization quality and inference speed.
Spotlight Poster
Xinran Han · Todd Zickler · Ko Nishino
[ East Exhibit Hall A-C ]
Abstract
Models for inferring monocular shape of surfaces with diffuse reflection---shape from shading---ought to produce distributions of outputs, because there are fundamental mathematical ambiguities of both continuous (e.g., bas-relief) and discrete (e.g., convex/concave) types that are also experienced by humans. Yet, the outputs of current models are limited to point estimates or tight distributions around single modes, which prevent them from capturing these effects. We introduce a model that reconstructs a multimodal distribution of shapes from a single shading image, which aligns with the human experience of multistable perception. We train a small denoising diffusion process to generate surface normal fields from $16\times 16$ patches of synthetic images of everyday 3D objects. We deploy this model patch-wise at multiple scales, with guidance from inter-patch shape consistency constraints. Despite its relatively small parameter count and predominantly bottom-up structure, we show that multistable shape explanations emerge from this model for ambiguous test images that humans experience as being multistable. At the same time, the model produces veridical shape estimates for object-like images that include distinctive occluding contours and appear less ambiguous. This may inspire new architectures for stochastic 3D shape perception that are more efficient and better aligned with human experience.
Spotlight Poster
Darshan Chakrabarti · Julien Grand-Clément · Christian Kroer
[ West Ballroom A-D ]
Abstract
We introduce the first algorithmic framework for Blackwell approachability on the sequence-form polytope, the class of convex polytopes capturing the strategies of players in extensive-form games (EFGs).This leads to a new class of regret-minimization algorithms that are stepsize-invariant, in the same sense as the Regret Matching and Regret Matching$^+$ algorithms for the simplex.Our modular framework can be combined with any existing regret minimizer over cones to compute a Nash equilibrium in two-player zero-sum EFGs with perfect recall, through the self-play framework. Leveraging predictive online mirror descent, we introduce *Predictive Treeplex Blackwell$^+$* (PTB$^+$), and show a $O(1/\sqrt{T})$ convergence rate to Nash equilibrium in self-play. We then show how to stabilize PTB$^+$ with a stepsize, resulting in an algorithm with a state-of-the-art $O(1/T)$ convergence rate. We provide an extensive set of experiments to compare our framework with several algorithmic benchmarks, including CFR$^+$ and its predictive variant, and we highlight interesting connections between practical performance and the stepsize-dependence or stepsize-invariance properties of classical algorithms.
Spotlight Poster
Alexander D. Goldie · Chris Lu · Matthew T Jackson · Shimon Whiteson · Jakob Foerster
[ West Ballroom A-D ]
Abstract
While reinforcement learning (RL) holds great potential for decision making in the real world, it suffers from a number of unique difficulties which often need specific consideration. In particular: it is highly non-stationary; suffers from high degrees of plasticity loss; and requires exploration to prevent premature convergence to local optima and maximize return. In this paper, we consider whether learned optimization can help overcome these problems. Our method, Learned **O**ptimization for **P**lasticity, **E**xploration and **N**on-stationarity (*OPEN*), meta-learns an update rule whose input features and output structure are informed by previously proposed solutions to these difficulties. We show that our parameterization is flexible enough to enable meta-learning in diverse learning contexts, including the ability to use stochasticity for exploration. Our experiments demonstrate that when meta-trained on single and small sets of environments, *OPEN* outperforms or equals traditionally used optimizers. Furthermore, *OPEN* shows strong generalization characteristics across a range of environments and agent architectures.
Spotlight Poster
Sophie Xhonneux · Alessandro Sordoni · Stephan Günnemann · Gauthier Gidel · Leo Schwinn
[ East Exhibit Hall A-C ]
Abstract
Large language models (LLMs) are vulnerable to adversarial attacks that can bypass their safety guardrails. In many domains, adversarial training has proven to be one of the most promising methods to reliably improve robustness against such attacks. Yet, in the context of LLMs, current methods for adversarial training are hindered by the high computational costs required to perform discrete adversarial attacks at each training iteration. We address this problem by instead calculating adversarial attacks in the continuous embedding space of the LLM, which is orders of magnitudes more efficient. We propose a fast adversarial training algorithm (C-AdvUL) composed of two losses: the first makes the model robust on continuous embedding attacks computed on an adversarial behaviour dataset; the second ensures the usefulness of the final model by fine-tuning on utility data. Moreover, we introduce C-AdvIPO, an adversarial variant of IPO that does not require utility data for adversarially robust alignment. Our empirical evaluation on five models from different families (Gemma, Phi3, Mistral, Zephyr, Llama2) and at different scales (2B, 3.8B, 7B) shows that both algorithms substantially enhance LLM robustness against discrete attacks (GCG, AutoDAN, PAIR), while maintaining utility. Our results demonstrate that robustness to continuous perturbations can extrapolate to discrete …
Spotlight Poster
Rui Min · Zeyu Qin · Nevin L. Zhang · Li Shen · Minhao Cheng
[ East Exhibit Hall A-C ]
Abstract
Backdoor attacks pose a significant threat to Deep Neural Networks (DNNs) as they allow attackers to manipulate model predictions with backdoor triggers. To address these security vulnerabilities, various backdoor purification methods have been proposed to purify compromised models. Typically, these purified models exhibit low Attack Success Rates (ASR), rendering them resistant to backdoored inputs. However, \textit{Does achieving a low ASR through current safety purification methods truly eliminate learned backdoor features from the pretraining phase?} In this paper, we provide an affirmative answer to this question by thoroughly investigating the \textit{Post-Purification Robustness} of current backdoor purification methods. We find that current safety purification methods are vulnerable to the rapid re-learning of backdoor behavior, even when further fine-tuning of purified models is performed using a very small number of poisoned samples. Based on this, we further propose the practical Query-based Reactivation Attack (QRA) which could effectively reactivate the backdoor by merely querying purified models. We find the failure to achieve satisfactory post-purification robustness stems from the insufficient deviation of purified models from the backdoored model along the backdoor-connected path. To improve the post-purification robustness, we propose a straightforward tuning defense, Path-Aware Minimization (PAM), which promotes deviation along backdoor-connected paths with extra model …
Spotlight Poster
Ben Adcock · Nick Dexter · Sebastian Moraga Scheuermann
[ East Exhibit Hall A-C ]

Abstract
Operator learning problems arise in many key areas of scientific computing where Partial Differential Equations (PDEs) are used to model physical systems. In such scenarios, the operators map between Banach or Hilbert spaces. In this work, we tackle the problem of learning operators between Banach spaces, in contrast to the vast majority of past works considering only Hilbert spaces. We focus on learning holomorphic operators -- an important class of problems with many applications. We combine arbitrary approximate encoders and decoders with standard feedforward Deep Neural Network (DNN) architectures -- specifically, those with constant width exceeding the depth -- under standard $\ell^2$-loss minimization. We first identify a family of DNNs such that the resulting Deep Learning (DL) procedure achieves optimal generalization bounds for such operators. For standard fully-connected architectures, we then show that there are uncountably many minimizers of the training problem that yield equivalent optimal performance. The DNN architectures we consider are `problem agnostic', with width and depth only depending on the amount of training data $m$ and not on regularity assumptions of the target operator. Next, we show that DL is optimal for this problem: no recovery procedure can surpass these generalization bounds up to log terms. Finally, …
Spotlight Poster
Gabriel Sarch · Lawrence Jang · Michael Tarr · William Cohen · Kenneth Marino · Katerina Fragkiadaki
[ West Ballroom A-D ]
Abstract
Large-scale generative language and vision-language models (LLMs and VLMs) excel in few-shot in-context learning for decision making and instruction following. However, they require high-quality exemplar demonstrations to be included in their context window. In this work, we ask: Can LLMs and VLMs generate their own examples from generic, sub-optimal demonstrations? We propose In-Context Abstraction Learning (ICAL), a method that builds a memory of multimodal experience from sub-optimal demonstrations and human feedback. Given a task demonstration that may contain inefficiencies or mistakes, a VLM abstracts the trajectory into a generalized program by correcting inefficient actions and annotating cognitive abstractions: causal relationships, object state changes, temporal subgoals, and task-relevant visual elements. These abstractions are iteratively improved and adapted through human feedback while the agent attempts to execute the trajectory in a similar environment. The resulting examples, when used as exemplars in the prompt, significantly improve decision-making in retrieval-augmented LLM and VLM agents. Moreover, as the agent's library of examples grows, it becomes more efficient, relying less on human feedback and requiring fewer environment interactions per demonstration. Our ICAL agent surpasses the state-of-the-art in dialogue-based instruction following in TEACh, multimodal web agents in VisualWebArena, and action anticipation in Ego4D. In TEACh, we achieve …
Spotlight Poster
Fanxu Meng · Zhaohui Wang · Muhan Zhang
[ East Exhibit Hall A-C ]
Abstract
To parameter-efficiently fine-tune (PEFT) large language models (LLMs), the low-rank adaptation (LoRA) method approximates the model changes $\Delta W \in \mathbb{R}^{m \times n}$ through the product of two matrices $A \in \mathbb{R}^{m \times r}$ and $B \in \mathbb{R}^{r \times n}$, where $r \ll \min(m, n)$, $A$ is initialized with Gaussian noise, and $B$ with zeros. LoRA **freezes the original model $W$** and **updates the "Noise \& Zero" adapter**, which may lead to slow convergence. To overcome this limitation, we introduce **P**r**i**ncipal **S**ingular values and **S**ingular vectors **A**daptation (PiSSA). PiSSA shares the same architecture as LoRA, but initializes the adaptor matrices $A$ and $B$ with the principal components of the original matrix $W$, and put the remaining components into a residual matrix $W^{res} \in \mathbb{R}^{m \times n}$ which is frozen during fine-tuning.Compared to LoRA, PiSSA **updates the principal components** while **freezing the "residual" parts**, allowing faster convergence and enhanced performance. Comparative experiments of PiSSA and LoRA across 11 different models, ranging from 184M to 70B, encompassing 5 NLG and 8 NLU tasks, reveal that PiSSA consistently outperforms LoRA under identical experimental setups. On the GSM8K benchmark, Gemma-7B fine-tuned with PiSSA achieves an accuracy of 77.7\%, surpassing LoRA's 74.53\% by 3.25\%. Due …
Spotlight Poster
Kevin Qinghong Lin · Linjie Li · Difei Gao · Qinchen WU · Mingyi Yan · Zhengyuan Yang · Lijuan Wang · Mike Zheng Shou
[ East Exhibit Hall A-C ]

Abstract
Graphical User Interface (GUI) automation holds significant promise for enhancing human productivity by assisting with computer tasks. Existing task formulations primarily focus on simple tasks that can be specified by a single, language-only instruction, such as “Insert a new slide.” In this work, we introduce VideoGUI, a novel multi-modal benchmark designed to evaluate GUI assistants on visual-centric GUI tasks. Sourced from high-quality web instructional videos, our benchmark focuses on tasks involving professional and novel software (e.g., Adobe Pho- toshop or Stable Diffusion WebUI) and complex activities (e.g., video editing). VideoGUI evaluates GUI assistants through a hierarchical process, allowing for identification of the specific levels at which they may fail: (i) high-level planning: reconstruct procedural subtasks from visual conditions without language descrip- tions; (ii) middle-level planning: generate sequences of precise action narrations based on visual state (i.e., screenshot) and goals; (iii) atomic action execution: perform specific actions such as accurately clicking designated elements. For each level, we design evaluation metrics across individual dimensions to provide clear signals, such as individual performance in clicking, dragging, typing, and scrolling for atomic action execution. Our evaluation on VideoGUI reveals that even the SoTA large multimodal model GPT4o performs poorly on visual-centric GUI tasks, especially …
Spotlight Poster
Ieva Petrulionytė · Julien Mairal · Michael Arbel
[ West Ballroom A-D ]
Abstract
In this paper, we introduce a new functional point of view on bilevel optimization problems for machine learning, where the inner objective is minimized over a function space. These types of problems are most often solved by using methods developed in the parametric setting, where the inner objective is strongly convex with respect to the parameters of the prediction function. The functional point of view does not rely on this assumption and notably allows using over-parameterized neural networks as the inner prediction function. We propose scalable and efficient algorithms for the functional bilevel optimization problem and illustrate the benefits of our approach on instrumental regression and reinforcement learning tasks.
Spotlight Poster
ZAIXI ZHANG · Marinka Zitnik · Qi Liu
[ East Exhibit Hall A-C ]
Abstract
Designing ligand-binding proteins, such as enzymes and biosensors, is essential in bioengineering and protein biology. One critical step in this process involves designing protein pockets, the protein interface binding with the ligand. Current approaches to pocket generation often suffer from time-intensive physical computations or template-based methods, as well as compromised generation quality due to the overlooking of domain knowledge. To tackle these challenges, we propose PocketFlow, a generative model that incorporates protein-ligand interaction priors based on flow matching. During training, PocketFlow learns to model key types of protein-ligand interactions, such as hydrogen bonds. In the sampling, PocketFlow leverages multi-granularity guidance (overall binding affinity and interaction geometry constraints) to facilitate generating high-affinity and valid pockets. Extensive experiments show that PocketFlow outperforms baselines on multiple benchmarks, e.g., achieving an average improvement of 1.29 in Vina Score and 0.05 in scRMSD. Moreover, modeling interactions make PocketFlow a generalized generative model across multiple ligand modalities, including small molecules, peptides, and RNA.
Spotlight Poster
Oryan Yehezkel · Alon Zolfi · Amit Baras · Yuval Elovici · Asaf Shabtai
[ East Exhibit Hall A-C ]
Abstract
Vision transformers have shown remarkable advancements in the computer vision domain, demonstrating state-of-the-art performance in diverse tasks (e.g., image classification, object detection). However, their high computational requirements grow quadratically with the number of tokens used. Token sparsification mechanisms have been proposed to address this issue. These mechanisms employ an input-dependent strategy, in which uninformative tokens are discarded from the computation pipeline, improving the model’s efficiency. However, their dynamism and average-case assumption makes them vulnerable to a new threat vector – carefully crafted adversarial examples capable of fooling the sparsification mechanism, resulting in worst-case performance. In this paper, we present DeSparsify, an attack targeting the availability of vision transformers that use token sparsification mechanisms. The attack aims to exhaust the operating system’s resources, while maintaining its stealthiness. Our evaluation demonstrates the attack’s effectiveness on three token sparsification mechanisms and examines the attack’s transferability between them and its effect on the GPU resources. To mitigate the impact of the attack, we propose various countermeasures.
Spotlight Poster
Mohamed Ghanem · Frederik Schmitt · Julian Siber · Bernd Finkbeiner
[ East Exhibit Hall A-C ]
Abstract
Training neural networks on NP-complete problems typically demands very large amounts of training data and often needs to be coupled with computationally expensive symbolic verifiers to ensure output correctness. In this paper, we present NeuRes, a neuro-symbolic approach to address both challenges for propositional satisfiability, being the quintessential NP-complete problem. By combining certificate-driven training and expert iteration, our model learns better representations than models trained for classification only, with a much higher data efficiency -- requiring orders of magnitude less training data. NeuRes employs propositional resolution as a proof system to generate proofs of unsatisfiability and to accelerate the process of finding satisfying truth assignments, exploring both possibilities in parallel. To realize this, we propose an attention-based architecture that autoregressively selects pairs of clauses from a dynamic formula embedding to derive new clauses. Furthermore, we employ expert iteration whereby model-generated proofs progressively replace longer teacher proofs as the new ground truth. This enables our model to reduce a dataset of proofs generated by an advanced solver by $\sim$$32$% after training on it with no extra guidance. This shows that NeuRes is not limited by the optimality of the teacher algorithm owing to its self-improving workflow. We show that our model …
Spotlight Poster
Zhiwen Fan · Kevin Wang · Kairun Wen · Zehao Zhu · Dejia Xu · Zhangyang "Atlas" Wang
[ East Exhibit Hall A-C ]

Abstract
Recent advances in real-time neural rendering using point-based techniques have enabled broader adoption of 3D representations. However, foundational approaches like 3D Gaussian Splatting impose substantial storage overhead, as Structure-from-Motion (SfM) points can grow to millions, often requiring gigabyte-level disk space for a single unbounded scene. This growth presents scalability challenges and hinders splatting efficiency. To address this, we introduce LightGaussian, a method for transforming 3D Gaussians into a more compact format. Inspired by Network Pruning, LightGaussian identifies Gaussians with minimal global significance on scene reconstruction, and applies a pruning and recovery process to reduce redundancy while preserving visual quality. Knowledge distillation and pseudo-view augmentation then transfer spherical harmonic coefficients to a lower degree, yielding compact representations. Gaussian Vector Quantization, based on each Gaussian’s global significance, further lowers bitwidth with minimal accuracy loss. LightGaussian achieves an average 15 times compression rate while boosting FPS from 144 to 237 within the 3D-GS framework, enabling efficient complex scene representation on the Mip-NeRF 360 and Tank & Temple datasets. The proposed Gaussian pruning approach is also adaptable to other 3D representations (e.g., Scaffold-GS), demonstrating strong generalization capabilities.
Spotlight Poster
Fan Chen · Dylan J Foster · Yanjun Han · Jian Qian · Alexander Rakhlin · Yunbei Xu
[ West Ballroom A-D ]
Abstract
We develop a unifying framework for information-theoretic lower bound in statistical estimation and interactive decision making. Classical lower bound techniques---such as Fano's method, Le Cam's method, and Assouad's lemma---are central to the study of minimax risk in statistical estimation, yet are insufficient to provide tight lower bounds for \emph{interactive decision making} algorithms that collect data interactively (e.g., algorithms for bandits and reinforcement learning). Recent work of Foster et al. provides minimax lower bounds for interactive decision making using seemingly different analysis techniques from the classical methods. These results---which are proven using a complexity measure known as the \emph{Decision-Estimation Coefficient} (DEC)---capture difficulties unique to interactive learning, yet do not recover the tightest known lower bounds for passive estimation. We propose a unified view of these distinct methodologies through a new lower bound approach called \emph{interactive Fano method}. As an application, we introduce a novel complexity measure, the \emph{Fractional Covering Number}, which facilitates the new lower bounds for interactive decision making that extend the DEC methodology by incorporating the complexity of estimation. Using the fractional covering number, we (i) provide a unified characterization of learnability for \emph{any} stochastic bandit problem, (ii) close the remaining gap between the upper and lower bounds in …
Spotlight Poster
Heng Li · Minghan Li · Zhi-Qi Cheng · Yifei Dong · Yuxuan Zhou · Jun-Yan He · Qi Dai · Teruko Mitamura · Alexander Hauptmann
[ East Exhibit Hall A-C ]

Abstract
Vision-and-Language Navigation (VLN) aims to develop embodied agents that navigate based on human instructions. However, current VLN frameworks often rely on static environments and optimal expert supervision, limiting their real-world applicability. To address this, we introduce Human-Aware Vision-and-Language Navigation (HA-VLN), extending traditional VLN by incorporating dynamic human activities and relaxing key assumptions. We propose the Human-Aware 3D (HA3D) simulator, which combines dynamic human activities with the Matterport3D dataset, and the Human-Aware Room-to-Room (HA-R2R) dataset, extending R2R with human activity descriptions. To tackle HA-VLN challenges, we present the Expert-Supervised Cross-Modal (VLN-CM) and Non-Expert-Supervised Decision Transformer (VLN-DT) agents, utilizing cross-modal fusion and diverse training strategies for effective navigation in dynamic human environments. A comprehensive evaluation, including metrics considering human activities, and systematic analysis of HA-VLN's unique challenges, underscores the need for further research to enhance HA-VLN agents' real-world robustness and adaptability. Ultimately, this work provides benchmarks and insights for future research on embodied AI and Sim2Real transfer, paving the way for more realistic and applicable VLN systems in human-populated environments.
Spotlight Poster
Haizhong Zheng · Xiaoyan Bai · Xueshen Liu · Zhuoqing Morley Mao · Beidi Chen · Fan Lai · Atul Prakash
[ East Exhibit Hall A-C ]
Abstract
Large Language Models (LLMs) have achieved remarkable success with their billion-level parameters, yet they incur high inference overheads. The emergence of activation sparsity in LLMs provides a natural approach to reduce this cost by involving only parts of the parameters for inference. However, existing methods only focus on utilizing this naturally formed activation sparsity in a post-training setting, overlooking the potential for further amplifying this inherent sparsity. In this paper, we hypothesize that LLMs can learn to be efficient by achieving more structured activation sparsity. To achieve this, we introduce a novel training algorithm, Learn-To-be-Efficient (LTE), designed to train efficiency-aware LLMs to learn to activate fewer neurons and achieve a better trade-off between sparsity and performance. Furthermore, unlike SOTA MoEfication methods, which mainly focus on ReLU-based models, LTE can also be applied to LLMs like LLaMA using non-ReLU activations. Extensive evaluation on language understanding, language generation, and instruction tuning tasks show that LTE consistently outperforms SOTA baselines. Along with our hardware-aware custom kernel implementation, LTE reduces LLaMA2-7B inference latency by 25% at 50% sparsity.
Spotlight Poster
Tri Nguyen · Shahana Ibrahim · Xiao Fu
[ East Exhibit Hall A-C ]

Abstract
The generation of label noise is often modeled as a process involving a probability transition matrix (also interpreted as the _annotator confusion matrix_) imposed onto the label distribution. Under this model, learning the ``ground-truth classifier''---i.e., the classifier that can be learned if no noise was present---and the confusion matrix boils down to a model identification problem. Prior works along this line demonstrated appealing empirical performance, yet identifiability of the model was mostly established by assuming an instance-invariant confusion matrix. Having an (occasionally) instance-dependent confusion matrix across data samples is apparently more realistic, but inevitably introduces outliers to the model. Our interest lies in confusion matrix-based noisy label learning with such outliers taken into consideration. We begin with pointing out that under the model of interest, using labels produced by only one annotator is fundamentally insufficient to detect the outliers or identify the ground-truth classifier. Then, we prove that by employing a crowdsourcing strategy involving multiple annotators, a carefully designed loss function can establish the desired model identifiability under reasonable conditions. Our development builds upon a link between the noisy label model and a column-corrupted matrix factorization mode---based on which we show that crowdsourced annotations distinguish nominal data and instance-dependent outliers …
Spotlight Poster
Jiawei Gao · Ziqin Wang · Zeqi Xiao · Jingbo Wang · Tai WANG · Jinkun Cao · Xiaolin Hu · Si Liu · Jifeng Dai · Jiangmiao Pang
[ East Exhibit Hall A-C ]
Abstract
Enabling humanoid robots to clean rooms has long been a pursued dream within humanoid research communities. However, many tasks require multi-humanoid collaboration, such as carrying large and heavy furniture together. Given the scarcity of motion capture data on multi-humanoid collaboration and the efficiency challenges associated with multi-agent learning, these tasks cannot be straightforwardly addressed using training paradigms designed for single-agent scenarios. In this paper, we introduce **Coo**perative **H**uman-**O**bject **I**nteraction (**CooHOI**), a framework designed to tackle the challenge of multi-humanoid object transportation problem through a two-phase learning paradigm: individual skill learning and subsequent policy transfer. First, a single humanoid character learns to interact with objects through imitation learning from human motion priors. Then, the humanoid learns to collaborate with others by considering the shared dynamics of the manipulated object using centralized training and decentralized execution (CTDE) multi-agent RL algorithms. When one agent interacts with the object, resulting in specific object dynamics changes, the other agents learn to respond appropriately, thereby achieving implicit communication and coordination between teammates. Unlike previous approaches that relied on tracking-based methods for multi-humanoid HOI, CooHOI is inherently efficient, does not depend on motion capture data of multi-humanoid interactions, and can be seamlessly extended to include more participants …
Spotlight Poster
Kai Yan · Alex Schwing · Yu-Xiong Wang
[ West Ballroom A-D ]
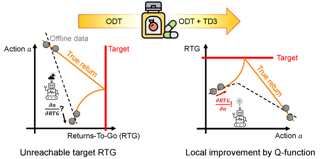
Abstract
Decision Transformers have recently emerged as a new and compelling paradigm for offline Reinforcement Learning (RL), completing a trajectory in an autoregressive way. While improvements have been made to overcome initial shortcomings, online finetuning of decision transformers has been surprisingly under-explored. The widely adopted state-of-the-art Online Decision Transformer (ODT) still struggles when pretrained with low-reward offline data. In this paper, we theoretically analyze the online-finetuning of the decision transformer, showing that the commonly used Return-To-Go (RTG) that's far from the expected return hampers the online fine-tuning process. This problem, however, is well-addressed by the value function and advantage of standard RL algorithms. As suggested by our analysis, in our experiments, we hence find that simply adding TD3 gradients to the finetuning process of ODT effectively improves the online finetuning performance of ODT, especially if ODT is pretrained with low-reward offline data. These findings provide new directions to further improve decision transformers.
Spotlight Poster
Xin Cai · Zhiyuan You · Hailong Zhang · Jinwei Gu · Wentao Liu · Tianfan Xue
[ East Exhibit Hall A-C ]

Abstract
Lensless cameras offer significant advantages in size, weight, and cost compared to traditional lens-based systems. Without a focusing lens, lensless cameras rely on computational algorithms to recover the scenes from multiplexed measurements. However, current algorithms struggle with inaccurate forward imaging models and insufficient priors to reconstruct high-quality images. To overcome these limitations, we introduce a novel two-stage approach for consistent and photorealistic lensless image reconstruction. The first stage of our approach ensures data consistency by focusing on accurately reconstructing the low-frequency content with a spatially varying deconvolution method that adjusts to changes in the Point Spread Function (PSF) across the camera's field of view. The second stage enhances photorealism by incorporating a generative prior from pre-trained diffusion models. By conditioning on the low-frequency content retrieved in the first stage, the diffusion model effectively reconstructs the high-frequency details that are typically lost in the lensless imaging process, while also maintaining image fidelity. Our method achieves a superior balance between data fidelity and visual quality compared to existing methods, as demonstrated with two popular lensless systems, PhlatCam and DiffuserCam.
Spotlight Poster
Liane Vogel · Jan-Micha Bodensohn · Carsten Binnig
[ West Ballroom A-D ]

Abstract
Deep learning on tabular data, and particularly tabular representation learning, has recently gained growing interest. However, representation learning for relational databases with multiple tables is still an underexplored area, which may be attributed to the lack of openly available resources. To support the development of foundation models for tabular data and relational databases, we introduce WikiDBs, a novel open-source corpus of 100,000 relational databases. Each database consists of multiple tables connected by foreign keys. The corpus is based on Wikidata and aims to follow certain characteristics of real-world databases. In this paper, we describe the dataset and our method for creating it. By making our code publicly available, we enable others to create tailored versions of the dataset, for example, by creating databases in different languages. Finally, we conduct a set of initial experiments to showcase how WikiDBs can be used to train for data engineering tasks, such as missing value imputation and column type annotation.
Spotlight Poster
Surbhi Goel · Abhishek Shetty · Konstantinos Stavropoulos · Arsen Vasilyan
[ West Ballroom A-D ]
Abstract
We study the problem of learning under arbitrary distribution shift, where the learner is trained on a labeled set from one distribution but evaluated on a different, potentially adversarially generated test distribution. We focus on two frameworks: *PQ learning* [GKKM'20], allowing abstention on adversarially generated parts of the test distribution, and *TDS learning* [KSV'23], permitting abstention on the entire test distribution if distribution shift is detected. All prior known algorithms either rely on learning primitives that are computationally hard even for simple function classes, or end up abstaining entirely even in the presence of a tiny amount of distribution shift. We address both these challenges for natural function classes, including intersections of halfspaces and decision trees, and standard training distributions, including Gaussians. For PQ learning, we give efficient learning algorithms, while for TDS learning, our algorithms can tolerate moderate amounts of distribution shift. At the core of our approach is an improved analysis of spectral outlier-removal techniques from learning with nasty noise. Our analysis can (1) handle arbitrarily large fraction of outliers, which is crucial for handling arbitrary distribution shifts, and (2) obtain stronger bounds on polynomial moments of the distribution after outlier removal, yielding new insights into polynomial regression …
Spotlight Poster
Minghao Guo · Bohan Wang · Pingchuan Ma · Tianyuan Zhang · Crystal Owens · Chuang Gan · Josh Tenenbaum · Kaiming He · Wojciech Matusik
[ East Exhibit Hall A-C ]
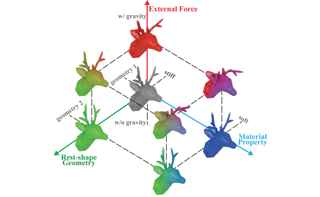
Abstract
We present a computational framework that transforms single images into 3D physical objects. The visual geometry of a physical object in an image is determined by three orthogonal attributes: mechanical properties, external forces, and rest-shape geometry. Existing single-view 3D reconstruction methods often overlook this underlying composition, presuming rigidity or neglecting external forces. Consequently, the reconstructed objects fail to withstand real-world physical forces, resulting in instability or undesirable deformation -- diverging from their intended designs as depicted in the image. Our optimization framework addresses this by embedding physical compatibility into the reconstruction process. We explicitly decompose the three physical attributes and link them through static equilibrium, which serves as a hard constraint, ensuring that the optimized physical shapes exhibit desired physical behaviors. Evaluations on a dataset collected from Objaverse demonstrate that our framework consistently enhances the physical realism of 3D models over existing methods. The utility of our framework extends to practical applications in dynamic simulations and 3D printing, where adherence to physical compatibility is paramount.
Spotlight Poster
Shivvrat Arya · Tahrima Rahman · Vibhav Gogate
[ East Exhibit Hall A-C ]

Abstract
We propose a novel neural networks based approach to efficiently answer arbitrary Most Probable Explanation (MPE) queries—a well-known NP-hard task—in large probabilistic models such as Bayesian and Markov networks, probabilistic circuits, and neural auto-regressive models. By arbitrary MPE queries, we mean that there is no predefined partition of variables into evidence and non-evidence variables. The key idea is to distill all MPE queries over a given probabilistic model into a neural network and then use the latter for answering queries, eliminating the need for time-consuming inference algorithms that operate directly on the probabilistic model. We improve upon this idea by incorporating inference-time optimization with self-supervised loss to iteratively improve the solutions and employ a teacher-student framework that provides a better initial network, which in turn, helps reduce the number of inference-time optimization steps. The teacher network utilizes a self-supervised loss function optimized for getting the exact MPE solution, while the student network learns from the teacher's near-optimal outputs through supervised loss. We demonstrate the efficacy and scalability of our approach on various datasets and a broad class of probabilistic models, showcasing its practical effectiveness.
Spotlight Poster
Yichong Huang · Xiaocheng Feng · Baohang Li · Yang Xiang · Hui Wang · Ting Liu · Bing Qin
[ West Ballroom A-D ]
Abstract
Large language models (LLMs) exhibit complementary strengths in various tasks, motivating the research of LLM ensembling.However, existing work focuses on training an extra reward model or fusion model to select or combine all candidate answers, posing a great challenge to the generalization on unseen data distributions.Besides, prior methods use textual responses as communication media, ignoring the valuable information in the internal representations.In this work, we propose a training-free ensemble framework \textsc{DeePEn}, fusing the informative probability distributions yielded by different LLMs at each decoding step.Unfortunately, the vocabulary discrepancy between heterogeneous LLMs directly makes averaging the distributions unfeasible due to the token misalignment.To address this challenge, \textsc{DeePEn} maps the probability distribution of each model from its own probability space to a universal \textit{relative space} based on the relative representation theory, and performs aggregation.Next, we devise a search-based inverse transformation to transform the aggregated result back to the probability space of one of the ensembling LLMs (main model), in order to determine the next token.We conduct extensive experiments on ensembles of different number of LLMs, ensembles of LLMs with different architectures, and ensembles between the LLM and the specialist model.Experimental results show that (i) \textsc{DeePEn} achieves consistent improvements across six benchmarks covering subject …
Spotlight Poster
Lirui Wang · Xinlei Chen · Jialiang Zhao · Kaiming He
[ East Exhibit Hall A-C ]
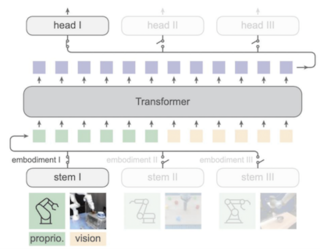
Abstract
One of the roadblocks for training generalist robotic models today is heterogeneity. Previous robot learning methods often collect data to train with one specific embodiment for one task, which is expensive and prone to overfitting. This work studies the problem of learning policy representations through heterogeneous pre-training on robot data across different embodiments and tasks at scale. We propose Heterogeneous Pre-trained Transformers (HPT), which pre-train a large, shareable trunk of a policy neural network to learn a task and embodiment agnostic shared representation. This general architecture aligns the specific proprioception and vision inputs from distinct embodiments to a short sequence of tokens and then processes such tokens to map to control robots for different tasks. Leveraging the recent large-scale multi-embodiment real-world robotic datasets as well as simulation, deployed robots, and human video datasets, we investigate pre-training policies across heterogeneity. We conduct experiments to investigate the scaling behaviors of training objectives, to the extent of 52 datasets. HPTs outperform several baselines and enhance the fine-tuned policy performance by over 20% on unseen tasks in multiple simulator benchmarks and real-world settings. See the project website (liruiw.github.io/hpt) for code and videos.
Spotlight Poster
Guillaume Wang · Alireza Mousavi-Hosseini · Lénaïc Chizat
[ West Ballroom A-D ]
Abstract
Mean-field Langevin dynamics (MLFD) is a class of interacting particle methods that tackle convex optimization over probability measures on a manifold, which are scalable, versatile, and enjoy computational guarantees. However, some important problems -- such as risk minimization for infinite width two-layer neural networks, or sparse deconvolution -- are originally defined over the set of signed, rather than probability, measures. In this paper, we investigate how to extend the MFLD framework to convex optimization problems over signed measures.Among two known reductions from signed to probability measures -- the lifting and the bilevel approaches -- we show that the bilevel reduction leads to stronger guarantees and faster rates (at the price of a higher per-iteration complexity).In particular, we investigate the convergence rate of MFLD applied to the bilevel reduction in the low-noise regime and obtain two results. First, this dynamics is amenable to an annealing schedule, adapted from [Suzuki et al., 2023], that results in polynomial convergence rates to a fixed multiplicative accuracy. Second, we investigate the problem of learning a single neuron with the bilevel approach and obtain local exponential convergence rates that depend polynomially on the dimension and noise level (to compare with the exponential dependence that would result …
Spotlight Poster
Tianhong Li · Yonglong Tian · He Li · Mingyang Deng · Kaiming He
[ East Exhibit Hall A-C ]
Abstract
Conventional wisdom holds that autoregressive models for image generation are typically accompanied by vector-quantized tokens. We observe that while a discrete-valued space can facilitate representing a categorical distribution, it is not a necessity for autoregressive modeling. In this work, we propose to model the per-token probability distribution using a diffusion procedure, which allows us to apply autoregressive models in a continuous-valued space. Rather than using categorical cross-entropy loss, we define a Diffusion Loss function to model the per-token probability. This approach eliminates the need for discrete-valued tokenizers. We evaluate its effectiveness across a wide range of cases, including standard autoregressive models and generalized masked autoregressive (MAR) variants. By removing vector quantization, our image generator achieves strong results while enjoying the speed advantage of sequence modeling. We hope this work will motivate the use of autoregressive generation in other continuous-valued domains and applications. Code is available at [https://github.com/LTH14/mar](https://github.com/LTH14/mar).
Spotlight Poster
Talfan Evans · Nikhil Parthasarathy · Hamza Merzic · Olivier Henaff
[ East Exhibit Hall A-C ]
Abstract
Data curation is an essential component of large-scale pretraining. In this work, we demonstrate that jointly prioritizing batches of data is more effective for learning than selecting examples independently. Multimodal contrastive objectives expose the dependencies between data and thus naturally yield criteria for measuring the joint learnability of a batch. We derive a simple and tractable algorithm for selecting such batches, which significantly accelerate training beyond individually-prioritized data points. As performance improves by selecting from large super-batches, we also leverage recent advances in model approximation to reduce the computational overhead of scoring. As a result, our approach—multimodal contrastive learning with joint example selection (JEST)—surpasses state-of-the-art pretraining methods with up to 13× fewer iterations and 10× less computation. Essential to the performance of JEST is the ability to steer the data selection process towards the distribution of smaller, well-curated datasets via pretrained reference models, exposing data curation as a new dimension for neural scaling laws.
Spotlight Poster
Xiaowen Jiang · Anton Rodomanov · Sebastian Stich
[ West Ballroom A-D ]
Abstract
In developing efficient optimization algorithms, it is crucial to account for communication constraints—a significant challenge in modern Federated Learning. The best-known communication complexity among non-accelerated algorithms is achieved by DANE, a distributed proximal-point algorithm that solves local subproblems at each iteration and that can exploit second-order similarity among individual functions. However, to achieve such communication efficiency, the algorithm requires solving local subproblems sufficiently accurately resulting in slightly sub-optimal local complexity. Inspired by the hybrid-projection proximal-point method, in this work, we propose a novel distributed algorithm S-DANE. Compared to DANE, this method uses an auxiliary sequence of prox-centers while maintaining the same deterministic communication complexity. Moreover, the accuracy condition for solving the subproblem is milder, leading to enhanced local computation efficiency. Furthermore, S-DANE supports partial client participation and arbitrary stochastic local solvers, making it attractive in practice. We further accelerate S-DANE and show that the resulting algorithm achieves the best-known communication complexity among all existing methods for distributed convex optimization while still enjoying good local computation efficiency as S-DANE. Finally, we propose adaptive variants of both methods using line search, obtaining the first provably efficient adaptive algorithms that could exploit local second-order similarity without the prior knowledge of any parameters.
Spotlight Poster
Mingjian Jiang · Yangjun Ruan · Prasanna Sattigeri · Salim Roukos · Tatsunori Hashimoto
[ East Exhibit Hall A-C ]
Abstract
Recent advancements in Large Language Models (LLMs) have significantly improved text generation capabilities, but these systems are still known to hallucinate, and granular uncertainty estimation for long-form LLM generations remains challenging. In this work, we propose Graph Uncertainty -- which represents the relationship between LLM generations and claims within them as a bipartite graph and estimates the claim-level uncertainty with a family of graph centrality metrics. Under this view, existing uncertainty estimation methods based on the concept of self-consistency can be viewed as using degree centrality as an uncertainty measure, and we show that more sophisticated alternatives such as closeness centrality provide consistent gains at claim-level uncertainty estimation.Moreover, we present uncertainty-aware decoding techniques that leverage both the graph structure and uncertainty estimates to improve the factuality of LLM generations by preserving only the most reliable claims. Compared to existing methods, our graph-based uncertainty metrics lead to an average of 6.8% relative gains on AUPRC across various long-form generation settings, and our end-to-end system provides consistent 2-4% gains in factuality over existing decoding techniques while significantly improving the informativeness of generated responses.
Spotlight Poster
Bálint Mucsányi · Michael Kirchhof · Seong Joon Oh
[ West Ballroom A-D ]
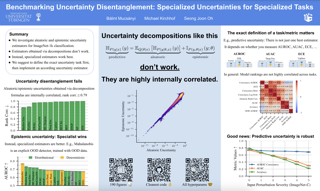
Abstract
Uncertainty quantification, once a singular task, has evolved into a spectrum of tasks, including abstained prediction, out-of-distribution detection, and aleatoric uncertainty quantification. The latest goal is disentanglement: the construction of multiple estimators that are each tailored to one and only one source of uncertainty. This paper presents the first benchmark of uncertainty disentanglement. We reimplement and evaluate a comprehensive range of uncertainty estimators, from Bayesian over evidential to deterministic ones, across a diverse range of uncertainty tasks on ImageNet. We find that, despite recent theoretical endeavors, no existing approach provides pairs of disentangled uncertainty estimators in practice. We further find that specialized uncertainty tasks are harder than predictive uncertainty tasks, where we observe saturating performance. Our results provide both practical advice for which uncertainty estimators to use for which specific task, and reveal opportunities for future research toward task-centric and disentangled uncertainties. All our reimplementations and Weights & Biases logs are available at https://github.com/bmucsanyi/untangle.
Spotlight Poster
William Redman · Juan Bello-Rivas · Maria Fonoberova · Ryan Mohr · Yannis Kevrekidis · Igor Mezic
[ East Exhibit Hall A-C ]
Abstract
Study of the nonlinear evolution deep neural network (DNN) parameters undergo during training has uncovered regimes of distinct dynamical behavior. While a detailed understanding of these phenomena has the potential to advance improvements in training efficiency and robustness, the lack of methods for identifying when DNN models have equivalent dynamics limits the insight that can be gained from prior work. Topological conjugacy, a notion from dynamical systems theory, provides a precise definition of dynamical equivalence, offering a possible route to address this need. However, topological conjugacies have historically been challenging to compute. By leveraging advances in Koopman operator theory, we develop a framework for identifying conjugate and non-conjugate training dynamics. To validate our approach, we demonstrate that comparing Koopman eigenvalues can correctly identify a known equivalence between online mirror descent and online gradient descent. We then utilize our approach to: (a) identify non-conjugate training dynamics between shallow and wide fully connected neural networks; (b) characterize the early phase of training dynamics in convolutional neural networks; (c) uncover non-conjugate training dynamics in Transformers that do and do not undergo grokking. Our results, across a range of DNN architectures, illustrate the flexibility of our framework and highlight its potential for shedding new …
Spotlight Poster
Irina Saparina · Mirella Lapata
[ West Ballroom A-D ]

Abstract
Practical semantic parsers are expected to understand user utterances and map them to executable programs, even when these are ambiguous. We introduce a new benchmark, AMBROSIA, which we hope will inform and inspire the development of text-to-SQL parsers capable of recognizing and interpreting ambiguous requests. Our dataset contains questions showcasing three different types of ambiguity (scope ambiguity, attachment ambiguity, and vagueness), their interpretations, and corresponding SQL queries. In each case, the ambiguity persists even when the database context is provided. This is achieved through a novel approach that involves controlled generation of databases from scratch. We benchmark various LLMs on AMBROSIA, revealing that even the most advanced models struggle to identify and interpret ambiguity in questions.
Spotlight Poster
Yuxuan Li · Xiang Li · Weijie Li · Qibin Hou · Li Liu · Ming-Ming Cheng · Jian Yang
[ East Exhibit Hall A-C ]
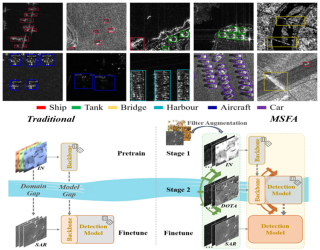
Abstract
Synthetic Aperture Radar (SAR) object detection has gained significant attention recently due to its irreplaceable all-weather imaging capabilities. However, this research field suffers from both limited public datasets (mostly comprising <2K images with only mono-category objects) and inaccessible source code. To tackle these challenges, we establish a new benchmark dataset and an open-source method for large-scale SAR object detection. Our dataset, SARDet-100K, is a result of intense surveying, collecting, and standardizing 10 existing SAR detection datasets, providing a large-scale and diverse dataset for research purposes. To the best of our knowledge, SARDet-100K is the first COCO-level large-scale multi-class SAR object detection dataset ever created. With this high-quality dataset, we conducted comprehensive experiments and uncovered a crucial challenge in SAR object detection: the substantial disparities between the pretraining on RGB datasets and finetuning on SAR datasets in terms of both data domain and model structure. To bridge these gaps, we propose a novel Multi-Stage with Filter Augmentation (MSFA) pretraining framework that tackles the problems from the perspective of data input, domain transition, and model migration. The proposed MSFA method significantly enhances the performance of SAR object detection models while demonstrating exceptional generalizability and flexibility across diverse models. This work aims to …
Spotlight Poster
Eshta Bhardwaj · Harshit Gujral · Siyi Wu · Ciara Zogheib · Tegan Maharaj · Christoph Becker
[ West Ballroom A-D ]
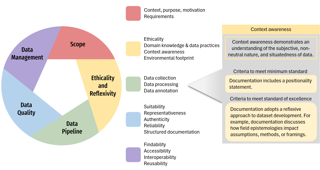
Abstract
Data curation is a field with origins in librarianship and archives, whose scholarship and thinking on data issues go back centuries, if not millennia. The field of machine learning is increasingly observing the importance of data curation to the advancement of both applications and fundamental understanding of machine learning models -- evidenced not least by the creation of the Datasets and Benchmarks track itself. This work provides an analysis of recent dataset development practices at NeurIPS through the lens of data curation. We present an evaluation framework for dataset documentation, consisting of a rubric and toolkit developed through a thorough literature review of data curation principles. We use the framework to systematically assess the strengths and weaknesses in current dataset development practices of 60 datasets published in the NeurIPS Datasets and Benchmarks track from 2021-2023. We summarize key findings and trends. Results indicate greater need for documentation about environmental footprint, ethical considerations, and data management. We suggest targeted strategies and resources to improve documentation in these areas and provide recommendations for the NeurIPS peer-review process that prioritize rigorous data curation in ML. We also provide guidelines for dataset developers on the use of our rubric as a standalone tool. Finally, …
Spotlight Poster
Haotian Ye · Haowei Lin · Jiaqi Han · Minkai Xu · Sheng Liu · Yitao Liang · Jianzhu Ma · James Zou · Stefano Ermon
[ East Exhibit Hall A-C ]
Abstract
Given an unconditional diffusion model and a predictor for a target property of interest (e.g., a classifier), the goal of training-free guidance is to generate samples with desirable target properties without additional training. Existing methods, though effective in various individual applications, often lack theoretical grounding and rigorous testing on extensive benchmarks. As a result, they could even fail on simple tasks, and applying them to a new problem becomes unavoidably difficult. This paper introduces a novel algorithmic framework encompassing existing methods as special cases, unifying the study of training-free guidance into the analysis of an algorithm-agnostic design space. Via theoretical and empirical investigation, we propose an efficient and effective hyper-parameter searching strategy that can be readily applied to any downstream task. We systematically benchmark across 7 diffusion models on 16 tasks with 40 targets, and improve performance by 8.5% on average. Our framework and benchmark offer a solid foundation for conditional generation in a training-free manner.
Spotlight Poster
Artur Szałata · Andrew Benz · Robrecht Cannoodt · Mauricio Cortes · Jason Fong · Sunil Kuppasani · Richard Lieberman · Tianyu Liu · Javier Mas-Rosario · Rico Meinl · Jalil Nourisa · Jared Tumiel · Tin M. Tunjic · Mengbo Wang · Noah Weber · Hongyu Zhao · Benedict Anchang · Fabian Theis · Malte Luecken · Daniel Burkhardt
[ East Exhibit Hall A-C ]
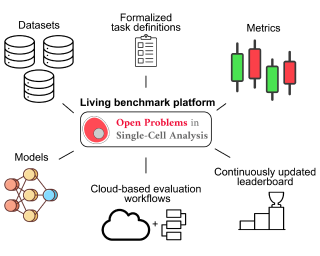
Abstract
Single-cell transcriptomics has revolutionized our understanding of cellular heterogeneity and drug perturbation effects. However, its high cost and the vast chemical space of potential drugs present barriers to experimentally characterizing the effect of chemical perturbations in all the myriad cell types of the human body. To overcome these limitations, several groups have proposed using machine learning methods to directly predict the effect of chemical perturbations either across cell contexts or chemical space. However, advances in this field have been hindered by a lack of well-designed evaluation datasets and benchmarks. To drive innovation in perturbation modeling, the Open Problems Perturbation Prediction (OP3) benchmark introduces a framework for predicting the effects of small molecule perturbations on cell type-specific gene expression. OP3 leverages the Open Problems in Single-cell Analysis benchmarking infrastructure and is enabled by a new single-cell perturbation dataset, encompassing 146 compounds tested on human blood cells. The benchmark includes diverse data representations, evaluation metrics, and winning methods from our "Single-cell perturbation prediction: generalizing experimental interventions to unseen contexts" competition at NeurIPS 2023. We envision that the OP3 benchmark and competition will drive innovation in single-cell perturbation prediction by improving the accessibility, visibility, and feasibility of this challenge, thereby promoting the impact …
Spotlight Poster
Salva Rühling Cachay · Brian Henn · Oliver Watt-Meyer · Christopher S. Bretherton · Rose Yu
[ East Exhibit Hall A-C ]
Abstract
Data-driven deep learning models are transforming global weather forecasting. It is an open question if this success can extend to climate modeling, where the complexity of the data and long inference rollouts pose significant challenges. Here, we present the first conditional generative model that produces accurate and physically consistent global climate ensemble simulations by emulating a coarse version of the United States' primary operational global forecast model, FV3GFS.Our model integrates the dynamics-informed diffusion framework (DYffusion) with the Spherical Fourier Neural Operator (SFNO) architecture, enabling stable 100-year simulations at 6-hourly timesteps while maintaining low computational overhead compared to single-step deterministic baselines.The model achieves near gold-standard performance for climate model emulation, outperforming existing approaches and demonstrating promising ensemble skill.This work represents a significant advance towards efficient, data-driven climate simulations that can enhance our understanding of the climate system and inform adaptation strategies. Code is available at [https://github.com/Rose-STL-Lab/spherical-dyffusion](https://github.com/Rose-STL-Lab/spherical-dyffusion).
Spotlight Poster
Jamie Lohoff · Emre Neftci
[ West Ballroom A-D ]
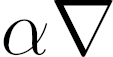
Abstract
Computing Jacobians with automatic differentiation is ubiquitous in many scientific domains such as machine learning, computational fluid dynamics, robotics and finance. Even small savings in the number of computations or memory usage in Jacobian computations can already incur massive savings in energy consumption and runtime. While there exist many methods that allow for such savings, they generally trade computational efficiency for approximations of the exact Jacobian.In this paper, we present a novel method to optimize the number of necessary multiplications for Jacobian computation by leveraging deep reinforcement learning (RL) and a concept called cross-country elimination while still computing the exact Jacobian. Cross-country elimination is a framework for automatic differentiation that phrases Jacobian accumulation as ordered elimination of all vertices on the computational graph where every elimination incurs a certain computational cost.Finding the optimal elimination order that minimizes the number of necessary multiplications can be seen as a single player game which in our case is played by an RL agent.We demonstrate that this method achieves up to 33% improvements over state-of-the-art methods on several relevant tasks taken from relevant domains.Furthermore, we show that these theoretical gains translate into actual runtime improvements by providing a cross-country elimination interpreter in JAX that …
Spotlight Poster
Ruisheng Cao · Fangyu Lei · Haoyuan Wu · Jixuan Chen · Yeqiao Fu · Hongcheng Gao · Xinzhuang Xiong · Hanchong Zhang · Wenjing Hu · Yuchen Mao · Tianbao Xie · Hongshen Xu · Danyang Zhang · Sida Wang · Ruoxi Sun · Pengcheng Yin · Caiming Xiong · Ansong Ni · Qian Liu · Victor Zhong · Lu Chen · Kai Yu · Tao Yu
[ West Ballroom A-D ]
Abstract
Data science and engineering workflows often span multiple stages, from warehousing to orchestration, using tools like BigQuery, dbt, and Airbyte. As vision language models (VLMs) advance in multimodal understanding and code generation, VLM-based agents could potentially automate these workflows by generating SQL queries, Python code, and GUI operations. This automation can improve the productivity of experts while democratizing access to large-scale data analysis. In this paper, we introduce Spider2-V, the first multimodal agent benchmark focusing on professional data science and engineering workflows, featuring 494 real-world tasks in authentic computer environments and incorporating 20 enterprise-level professional applications. These tasks, derived from real-world use cases, evaluate the ability of a multimodal agent to perform data-related tasks by writing code and managing the GUI in enterprise data software systems. To balance realistic simulation with evaluation simplicity, we devote significant effort to developing automatic configurations for task setup and carefully crafting evaluation metrics for each task. Furthermore, we supplement multimodal agents with comprehensive documents of these enterprise data software systems. Our empirical evaluation reveals that existing state-of-the-art LLM/VLM-based agents do not reliably automate full data workflows (14.0% success). Even with step-by-step guidance, these agents still underperform in tasks that require fine-grained, knowledge-intensive GUI actions …
Spotlight Poster
Yohann PERRON · Vladyslav Sydorov · Adam P. Wijker · Damian Evans · Christophe Pottier · Loic Landrieu
[ West Ballroom A-D ]

Abstract
Airborne Laser Scanning (ALS) technology has transformed modern archaeology by unveiling hidden landscapes beneath dense vegetation. However, the lack of expert-annotated, open-access resources has hindered the analysis of ALS data using advanced deep learning techniques. We address this limitation with Archaeoscape (available at https://archaeoscape.ai/data/2024), a novel large-scale archaeological ALS dataset spanning 888 km² in Cambodia with 31,141 annotated archaeological features from the Angkorian period. Archaeoscape is over four times larger than comparable datasets, and the first ALS archaeology resource with open-access data, annotations, and models.We benchmark several recent segmentation models to demonstrate the benefits of modern vision techniques for this problem and highlight the unique challenges of discovering subtle human-made structures under dense jungle canopies. By making Archaeoscape available in open access, we hope to bridge the gap between traditional archaeology and modern computer vision methods.
Spotlight Poster
Wenjie Xu · Masaki Adachi · Colin Jones · Michael A Osborne
[ East Exhibit Hall A-C ]

Abstract
Bayesian optimisation for real-world problems is often performed interactively with human experts, and integrating their domain knowledge is key to accelerate the optimisation process. We consider a setup where experts provide advice on the next query point through binary accept/reject recommendations (labels). Experts’ labels are often costly, requiring efficient use of their efforts, and can at the same time be unreliable, requiring careful adjustment of the degree to which any expert is trusted. We introduce the first principled approach that provides two key guarantees. (1) Handover guarantee: similar to a no-regret property, we establish a sublinear bound on the cumulative number of experts’ binary labels. Initially, multiple labels per query are needed, but the number of expert labels required asymptotically converges to zero, saving both expert effort and computation time. (2) No-harm guarantee with data-driven trust level adjustment: our adaptive trust level ensures that the convergence rate will not be worse than the one without using advice, even if the advice from experts is adversarial. Unlike existing methods that employ a user-defined function that hand-tunes the trust level adjustment, our approach enables data-driven adjustments. Real-world applications empirically demonstrate that our method not only outperforms existing baselines, but also maintains robustness …
Spotlight Poster
Kaihang Pan · Zhaoyu Fan · Juncheng Li · Qifan Yu · Hao Fei · Siliang Tang · Richang Hong · Hanwang Zhang · QIANRU SUN
[ East Exhibit Hall A-C ]
Abstract
The swift advancement in Multimodal LLMs (MLLMs) also presents significant challenges for effective knowledge editing. Current methods, including intrinsic knowledge editing and external knowledge resorting, each possess strengths and weaknesses, struggling to balance the desired properties of reliability, generality, and locality when applied to MLLMs. In this paper, we propose \textbf{UniKE}, a novel multimodal editing method that establishes a unified perspective and paradigm for intrinsic knowledge editing and external knowledge resorting. Both types of knowledge are conceptualized as vectorized key-value memories, with the corresponding editing processes resembling the assimilation and accommodation phases of human cognition, conducted at the same semantic levels. Within such a unified framework, we further promote knowledge collaboration by disentangling the knowledge representations into the semantic and truthfulness spaces. Extensive experiments validate the effectiveness of our method, which ensures that the post-edit MLLM simultaneously maintains excellent reliability, generality, and locality. The code for UniKE is available at https://github.com/beepkh/UniKE.
Spotlight Poster
Leonardo Defilippis · Bruno Loureiro · Theodor Misiakiewicz
[ West Ballroom A-D ]
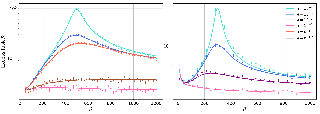
Abstract
In this work we investigate the generalization performance of random feature ridge regression (RFRR). Our main contribution is a general deterministic equivalent for the test error of RFRR. Specifically, under a certain concentration property, we show that the test error is well approximated by a closed-form expression that only depends on the feature map eigenvalues. Notably, our approximation guarantee is non-asymptotic, multiplicative, and independent of the feature map dimension---allowing for infinite-dimensional features. We expect this deterministic equivalent to hold broadly beyond our theoretical analysis, and we empirically validate its predictions on various real and synthetic datasets. As an application, we derive sharp excess error rates under standard power-law assumptions of the spectrum and target decay. In particular, we provide a tight result for the smallest number of features achieving optimal minimax error rate.
Spotlight Poster
Kai Zhao · Xuhao Li · Qiyu Kang · Feng Ji · Qinxu Ding · Yanan Zhao · Wenfei Liang · Wee Peng Tay
[ East Exhibit Hall A-C ]
Abstract
We introduce the Distributed-order fRActional Graph Operating Network (DRAGON), a novel continuous Graph Neural Network (GNN) framework that incorporates distributed-order fractional calculus. Unlike traditional continuous GNNs that utilize integer-order or single fractional-order differential equations, DRAGON uses a learnable probability distribution over a range of real numbers for the derivative orders. By allowing a flexible and learnable superposition of multiple derivative orders, our framework captures complex graph feature updating dynamics beyond the reach of conventional models.We provide a comprehensive interpretation of our framework's capability to capture intricate dynamics through the lens of a non-Markovian graph random walk with node feature updating driven by an anomalous diffusion process over the graph. Furthermore, to highlight the versatility of the DRAGON framework, we conduct empirical evaluations across a range of graph learning tasks. The results consistently demonstrate superior performance when compared to traditional continuous GNN models. The implementation code is available at \url{https://github.com/zknus/NeurIPS-2024-DRAGON}.
Spotlight Poster
Li Zhang · Yan Zhong · Jianan Wang · Zhe Min · RujingWang · Liu Liu
[ West Ballroom A-D ]
Abstract
Convolution is a fundamental operation in the 3D backbone. However, under certain conditions, the feature extraction ability of traditional convolution methods may be weakened. In this paper, we introduce a new convolution method based on $\ell_p$-norm. For theoretical support, we prove the universal approximation theorem for $\ell_p$-norm based convolution, and analyze the robustness and feasibility of $\ell_p$-norms in 3D point cloud tasks. Concretely, $\ell_{\infty}$-norm based convolution is prone to feature loss. $\ell_2$-norm based convolution is essentially a linear transformation of the traditional convolution. $\ell_1$-norm based convolution is an economical and effective feature extractor. We propose customized optimization strategies to accelerate the training process of $\ell_1$-norm based Nets and enhance the performance. Besides, a theoretical guarantee is given for the convergence by \textit{regret} argument. We apply our methods to classic networks and conduct related experiments. Experimental results indicate that our approach exhibits competitive performance with traditional CNNs, with lower energy consumption and instruction latency.
Spotlight Poster
Liam Collins · Advait Parulekar · Aryan Mokhtari · Sujay Sanghavi · Sanjay Shakkottai
[ East Exhibit Hall A-C ]
Abstract
A striking property of transformers is their ability to perform in-context learning (ICL), a machine learning framework in which the learner is presented with a novel context during inference implicitly through some data, and tasked with making a prediction in that context. As such, that learner must adapt to the context without additional training. We explore the role of *softmax* attention in an ICL setting where each context encodes a regression task. We show that an attention unit learns a window that it uses to implement a nearest-neighbors predictor adapted to the landscape of the pretraining tasks. Specifically, we show that this window widens with decreasing Lipschitzness and increasing label noise in the pretraining tasks. We also show that on low-rank, linear problems, the attention unit learns to project onto the appropriate subspace before inference. Further, we show that this adaptivity relies crucially on the softmax activation and thus cannot be replicated by the linear activation often studied in prior theoretical analyses.
Spotlight Poster
Andy Zhou · Bo Li · Haohan Wang
[ East Exhibit Hall A-C ]
Abstract
Despite advances in AI alignment, large language models (LLMs) remain vulnerable to adversarial attacks or jailbreaking, in which adversaries can modify prompts to induce unwanted behavior. While some defenses have been proposed, they have not been adapted to newly proposed attacks and more challenging threat models. To address this, we propose an optimization-based objective for defending LLMs against jailbreaking attacks and an algorithm, Robust Prompt Optimization (RPO), to create robust system-level defenses. Our approach directly incorporates the adversary into the defensive objective and optimizes a lightweight and transferable suffix, enabling RPO to adapt to worst-case adaptive attacks. Our theoretical and experimental results show improved robustness to both jailbreaks seen during optimization and unknown jailbreaks, reducing the attack success rate (ASR) on GPT-4 to 6% and Llama-2 to 0% on JailbreakBench, setting the state-of-the-art.
Spotlight Poster
Anka Reuel-Lamparth · Amelia Hardy · Chandler Smith · Max Lamparth · Malcolm Hardy · Mykel J Kochenderfer
[ West Ballroom A-D ]
Abstract
AI models are increasingly prevalent in high-stakes environments, necessitating thorough assessment of their capabilities and risks. Benchmarks are popular for measuring these attributes and for comparing model performance, tracking progress, and identifying weaknesses in foundation and non-foundation models. They can inform model selection for downstream tasks and influence policy initiatives. However, not all benchmarks are the same: their quality depends on their design and usability. In this paper, we develop an assessment framework considering 40 best practices across a benchmark's life cycle and evaluate 25 AI benchmarks against it. We find that there exist large quality differences and that commonly used benchmarks suffer from significant issues. We further find that most benchmarks do not report statistical significance of their results nor can results be easily replicated. To support benchmark developers in aligning with best practices, we provide a checklist for minimum quality assurance based on our assessment. We also develop a living repository of benchmark assessments to support benchmark comparability.
Spotlight Poster
JIAWEI DU · xin zhang · Juncheng Hu · Wenxin Huang · Joey Tianyi Zhou
[ East Exhibit Hall A-C ]

Abstract
The sharp increase in data-related expenses has motivated research into condensing datasets while retaining the most informative features. Dataset distillation has thus recently come to the fore. This paradigm generates synthetic datasets that are representative enough to replace the original dataset in training a neural network. To avoid redundancy in these synthetic datasets, it is crucial that each element contains unique features and remains diverse from others during the synthesis stage. In this paper, we provide a thorough theoretical and empirical analysis of diversity within synthesized datasets. We argue that enhancing diversity can improve the parallelizable yet isolated synthesizing approach. Specifically, we introduce a novel method that employs dynamic and directed weight adjustment techniques to modulate the synthesis process, thereby maximizing the representativeness and diversity of each synthetic instance. Our method ensures that each batch of synthetic data mirrors the characteristics of a large, varying subset of the original dataset. Extensive experiments across multiple datasets, including CIFAR, Tiny-ImageNet, and ImageNet-1K, demonstrate the superior performance of our method, highlighting its effectiveness in producing diverse and representative synthetic datasets with minimal computational expense. Our code is available at https://github.com/AngusDujw/Diversity-Driven-Synthesis.
Spotlight Poster
Md Tanvirul Alam · Dipkamal Bhusal · Le Nguyen · Nidhi Rastogi
[ West Ballroom A-D ]
Abstract
Cyber threat intelligence (CTI) is crucial in today's cybersecurity landscape, providing essential insights to understand and mitigate the ever-evolving cyber threats. The recent rise of Large Language Models (LLMs) have shown potential in this domain, but concerns about their reliability, accuracy, and hallucinations persist. While existing benchmarks provide general evaluations of LLMs, there are no benchmarks that address the practical and applied aspects of CTI-specific tasks. To bridge this gap, we introduce CTIBench, a benchmark designed to assess LLMs' performance in CTI applications. CTIBench includes multiple datasets focused on evaluating knowledge acquired by LLMs in the cyber-threat landscape. Our evaluation of several state-of-the-art models on these tasks provides insights into their strengths and weaknesses in CTI contexts, contributing to a better understanding of LLM capabilities in CTI.
Spotlight Poster
Benyuan Meng · Qianqian Xu · Zitai Wang · Xiaochun Cao · Qingming Huang
[ East Exhibit Hall A-C ]
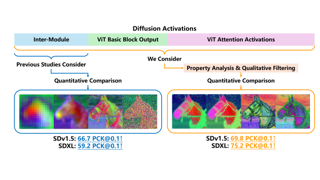
Abstract
Diffusion models are initially designed for image generation. Recent research shows that the internal signals within their backbones, named activations, can also serve as dense features for various discriminative tasks such as semantic segmentation. Given numerous activations, selecting a small yet effective subset poses a fundamental problem. To this end, the early study of this field performs a large-scale quantitative comparison of the discriminative ability of the activations. However, we find that many potential activations have not been evaluated, such as the queries and keys used to compute attention scores. Moreover, recent advancements in diffusion architectures bring many new activations, such as those within embedded ViT modules. Both combined, activation selection remains unresolved but overlooked. To tackle this issue, this paper takes a further step with a much broader range of activations evaluated. Considering the significant increase in activations, a full-scale quantitative comparison is no longer operational. Instead, we seek to understand the properties of these activations, such that the activations that are clearly inferior can be filtered out in advance via simple qualitative evaluation. After careful analysis, we discover three properties universal among diffusion models, enabling this study to go beyond specific models. On top of this, we present …
Spotlight Poster
Xiao Lin · Zhining Liu · Dongqi Fu · Ruizhong Qiu · Hanghang Tong
[ West Ballroom A-D ]

Abstract
Multivariate Time Series (MTS) forecasting is a fundamental task with numerous real-world applications, such as transportation, climate, and epidemiology. While a myriad of powerful deep learning models have been developed for this task, few works have explored the robustness of MTS forecasting models to malicious attacks, which is crucial for their trustworthy employment in high-stake scenarios. To address this gap, we dive deep into the backdoor attacks on MTS forecasting models and propose an effective attack method named BackTime. By subtly injecting a few \textit{stealthy triggers} into the MTS data, BackTime can alter the predictions of the forecasting model according to the attacker's intent. Specifically, BackTime first identifies vulnerable timestamps in the data for poisoning, and then adaptively synthesizes stealthy and effective triggers by solving a bi-level optimization problem with a GNN-based trigger generator. Extensive experiments across multiple datasets and state-of-the-art MTS forecasting models demonstrate the effectiveness, versatility, and stealthiness of BackTime attacks.
Spotlight Poster
Shen Yuan · Haotian Liu · Hongteng Xu
[ East Exhibit Hall A-C ]
Abstract
While following different technical routes, both low-rank and orthogonal adaptation techniques can efficiently adapt large-scale pre-training models in specific tasks or domains based on a small piece of trainable parameters. In this study, we bridge the gap between these two techniques, proposing a simple but effective adaptation method based on Householder reflections. Given a pre-trained model, our method fine-tunes its layers by multiplying each frozen weight matrix with an orthogonal matrix constructed by a chain of learnable Householder reflections (HRs). This HR-based orthogonal fine-tuning is equivalent to an adaptive low-rank adaptation. Moreover, we show that the orthogonality of the reflection planes corresponding to the HRs impacts the model capacity and regularity. The analysis motivates us to regularize the orthogonality of the HRs, leading to different implementations of the proposed Householder reflection adaptation (HRA) method. Compared with state-of-the-art methods, HRA achieves superior performance with fewer learnable parameters when adapting large language models and conditional image generators. The code of the experiments is available at https://github.com/DaShenZi721/HRA, and the method has been merged into the [PEFT](https://github.com/huggingface/peft) package.
Spotlight Poster
chenlin zhou · Han Zhang · Zhaokun Zhou · Liutao Yu · Liwei Huang · Xiaopeng Fan · Li Yuan · Zhengyu Ma · Huihui Zhou · Yonghong Tian
[ East Exhibit Hall A-C ]

Abstract
Spiking Transformers, which integrate Spiking Neural Networks (SNNs) with Transformer architectures, have attracted significant attention due to their potential for low energy consumption and high performance. However, there remains a substantial gap in performance between SNNs and Artificial Neural Networks (ANNs). To narrow this gap, we have developed QKFormer, a direct training spiking transformer with the following features: i) _Linear complexity and high energy efficiency_, the novel spike-form Q-K attention module efficiently models the token or channel attention through binary vectors and enables the construction of larger models. ii) _Multi-scale spiking representation_, achieved by a hierarchical structure with the different numbers of tokens across blocks. iii) _Spiking Patch Embedding with Deformed Shortcut (SPEDS)_, enhances spiking information transmission and integration, thus improving overall performance. It is shown that QKFormer achieves significantly superior performance over existing state-of-the-art SNN models on various mainstream datasets. Notably, with comparable size to Spikformer (66.34 M, 74.81\%), QKFormer (64.96 M) achieves a groundbreaking top-1 accuracy of **85.65\%** on ImageNet-1k, substantially outperforming Spikformer by **10.84\%**. To our best knowledge, this is the first time that directly training SNNs have exceeded 85\% accuracy on ImageNet-1K.
Spotlight Poster
Yuxin Du · Fan BAI · Tiejun Huang · Bo Zhao
[ East Exhibit Hall A-C ]
Abstract
Precise image segmentation provides clinical study with instructive information. Despite the remarkable progress achieved in medical image segmentation, there is still an absence of a 3D foundation segmentation model that can segment a wide range of anatomical categories with easy user interaction. In this paper, we propose a 3D foundation segmentation model, named SegVol, supporting universal and interactive volumetric medical image segmentation. By scaling up training data to 90K unlabeled Computed Tomography (CT) volumes and 6K labeled CT volumes, this foundation model supports the segmentation of over 200 anatomical categories using semantic and spatial prompts. To facilitate efficient and precise inference on volumetric images, we design a zoom-out-zoom-in mechanism. Extensive experiments on 22 anatomical segmentation tasks verify that SegVol outperforms the competitors in 19 tasks, with improvements up to 37.24\% compared to the runner-up methods. We demonstrate the effectiveness and importance of specific designs by ablation study. We expect this foundation model can promote the development of volumetric medical image analysis. The model and code are publicly available at https://github.com/BAAI-DCAI/SegVol.
Spotlight Poster
Ike Obi · Rohan Pant · Srishti Shekhar Agrawal · Maham Ghazanfar · Aaron Basiletti
[ West Ballroom A-D ]
Abstract
LLMs are increasingly fine-tuned using RLHF datasets to align them with human preferences and values. However, very limited research has investigated which specific human values are operationalized through these datasets. In this paper, we introduce Value Imprint, a framework for auditing and classifying the human values embedded within RLHF datasets. To investigate the viability of this framework, we conducted three case study experiments by auditing the Anthropic/hh-rlhf, OpenAI WebGPT Comparisons, and Alpaca GPT-4-LLM datasets to examine the human values embedded within them. Our analysis involved a two-phase process. During the first phase, we developed a taxonomy of human values through an integrated review of prior works from philosophy, axiology, and ethics. Then, we applied this taxonomy to annotate 6,501 RLHF preferences. During the second phase, we employed the labels generated from the annotation as ground truth data for training a transformer-based machine learning model to audit and classify the three RLHF datasets. Through this approach, we discovered that information-utility values, including Wisdom/Knowledge and Information Seeking, were the most dominant human values within all three RLHF datasets. In contrast, prosocial and democratic values, including Well-being, Justice, and Human/Animal Rights, were the least represented human values. These findings have significant implications for …
Spotlight Poster
Junlin Xie · Ruifei Zhang · Zhihong Chen · Xiang Wan · Guanbin Li
[ West Ballroom A-D ]
Abstract
Recently, large language models (LLMs) have achieved superior performance, empowering the development of large multimodal agents (LMAs). An LMA is anticipated to execute practical tasks requires various capabilities including multimodal perception, interaction, reasoning, and decision making. However, existing benchmarks are limited in assessing compositional skills and actions demanded by practical scenarios, where they primarily focused on single tasks and static scenarios. To bridge this gap, we introduce WhodunitBench, a benchmark rooted from murder mystery games, where players are required to utilize the aforementioned skills to achieve their objective (i.e., identifying the `murderer' or hiding themselves), providing a simulated dynamic environment for evaluating LMAs. Specifically, WhodunitBench includes two evaluation modes. The first mode, the arena-style evaluation, is constructed from 50 meticulously curated scripts featuring clear reasoning clues and distinct murderers; The second mode, the chain of evaluation, consists of over 3000 curated multiple-choice questions and open-ended questions, aiming to assess every facet of the murder mystery games for LMAs. Experiments show that although current LMAs show acceptable performance in basic perceptual tasks, they are insufficiently equipped for complex multi-agent collaboration and multi-step reasoning tasks. Furthermore, the full application of the theory of mind to complete games in a manner akin to …
Spotlight Poster
Shenghai Yuan · Jinfa Huang · Yongqi Xu · YaoYang Liu · Shaofeng Zhang · Yujun Shi · Rui-Jie Zhu · Xinhua Cheng · Jiebo Luo · Li Yuan
[ East Exhibit Hall A-C ]

Abstract
We propose a novel text-to-video (T2V) generation benchmark, *ChronoMagic-Bench*, to evaluate the temporal and metamorphic knowledge skills in time-lapse video generation of the T2V models (e.g. Sora and Lumiere). Compared to existing benchmarks that focus on visual quality and text relevance of generated videos, *ChronoMagic-Bench* focuses on the models’ ability to generate time-lapse videos with significant metamorphic amplitude and temporal coherence. The benchmark probes T2V models for their physics, biology, and chemistry capabilities, in a free-form text control. For these purposes, *ChronoMagic-Bench* introduces **1,649** prompts and real-world videos as references, categorized into four major types of time-lapse videos: biological, human creation, meteorological, and physical phenomena, which are further divided into 75 subcategories. This categorization ensures a comprehensive evaluation of the models’ capacity to handle diverse and complex transformations. To accurately align human preference on the benchmark, we introduce two new automatic metrics, MTScore and CHScore, to evaluate the videos' metamorphic attributes and temporal coherence. MTScore measures the metamorphic amplitude, reflecting the degree of change over time, while CHScore assesses the temporal coherence, ensuring the generated videos maintain logical progression and continuity. Based on the *ChronoMagic-Bench*, we conduct comprehensive manual evaluations of eighteen representative T2V models, revealing their strengths and weaknesses …
Spotlight Poster
Yu Zhang · Changhao Pan · Wenxiang Guo · Ruiqi Li · Zhiyuan Zhu · Jialei Wang · Wenhao Xu · Jingyu Lu · Zhiqing Hong · Chuxin Wang · Lichao Zhang · Jinzheng He · Ziyue Jiang · Yuxin Chen · Chen Yang · Jiecheng Zhou · Xinyu Cheng · Zhou Zhao
[ West Ballroom A-D ]
Abstract
The scarcity of high-quality and multi-task singing datasets significantly hinders the development of diverse controllable and personalized singing tasks, as existing singing datasets suffer from low quality, limited diversity of languages and singers, absence of multi-technique information and realistic music scores, and poor task suitability.To tackle these problems, we present GTSinger, a large Global, multi-Technique, free-to-use, high-quality singing corpus with realistic music scores, designed for all singing tasks, along with its benchmarks.Particularly,(1) we collect 80.59 hours of high-quality singing voices, forming the largest recorded singing dataset;(2) 20 professional singers across nine widely spoken languages offer diverse timbres and styles;(3) we provide controlled comparison and phoneme-level annotations of six commonly used singing techniques, helping technique modeling and control;(4) GTSinger offers realistic music scores, assisting real-world musical composition;(5) singing voices are accompanied by manual phoneme-to-audio alignments, global style labels, and 16.16 hours of paired speech for various singing tasks.Moreover, to facilitate the use of GTSinger, we conduct four benchmark experiments: technique-controllable singing voice synthesis, technique recognition, style transfer, and speech-to-singing conversion.
Spotlight Poster
Kaiyan Zhang · Sihang Zeng · Ermo Hua · Ning Ding · Zhang-Ren Chen · Zhiyuan Ma · Haoxin Li · Ganqu Cui · Biqing Qi · Xuekai Zhu · Xingtai Lv · Hu Jinfang · Zhiyuan Liu · Bowen Zhou
[ West Ballroom A-D ]

Abstract
Large Language Models (LLMs) have demonstrated remarkable capabilities across various domains and are moving towards more specialized areas. Recent advanced proprietary models such as GPT-4 and Gemini have achieved significant advancements in biomedicine, which have also raised privacy and security challenges. The construction of specialized generalists hinges largely on high-quality datasets, enhanced by techniques like supervised fine-tuning and reinforcement learning from human or AI feedback, and direct preference optimization. However, these leading technologies (e.g., preference learning) are still significantly limited in the open source community due to the scarcity of specialized data. In this paper, we present the UltraMedical collections, which consist of high-quality manual and synthetic datasets in the biomedicine domain, featuring preference annotations across multiple advanced LLMs. By utilizing these datasets, we fine-tune a suite of specialized medical models based on Llama-3 series, demonstrating breathtaking capabilities across various medical benchmarks. Moreover, we develop powerful reward models skilled in biomedical and general reward benchmark, enhancing further online preference learning within the biomedical LLM community.
Spotlight Poster
Lukas Picek · Christophe Botella · Maximilien Servajean · César Leblanc · Rémi Palard · Theo Larcher · Benjamin Deneu · Diego Marcos · Pierre Bonnet · alexis joly
[ West Ballroom A-D ]

Abstract
The difficulty of monitoring biodiversity at fine scales and over large areas limits ecological knowledge and conservation efforts. To fill this gap, Species Distribution Models (SDMs) predict species across space from spatially explicit features. Yet, they face the challenge of integrating the rich but heterogeneous data made available over the past decade, notably millions of opportunistic species observations and standardized surveys, as well as multi-modal remote sensing data.In light of that, we have designed and developed a new European-scale dataset for SDMs at high spatial resolution (10--50m), including more than 10k species (i.e., most of the European flora). The dataset comprises 5M heterogeneous Presence-Only records and 90k exhaustive Presence-Absence survey records, all accompanied by diverse environmental rasters (e.g., elevation, human footprint, and soil) traditionally used in SDMs. In addition, it provides Sentinel-2 RGB and NIR satellite images with 10 m resolution, a 20-year time series of climatic variables, and satellite time series from the Landsat program.In addition to the data, we provide an openly accessible SDM benchmark (hosted on Kaggle), which has already attracted an active community and a set of strong baselines for single predictor/modality and multimodal approaches.All resources, e.g., the dataset, pre-trained models, and baseline methods (in the …
Spotlight Poster
Jiatong Li · Renjun Hu · Kunzhe Huang · Yan Zhuang · Qi Liu · Mengxiao Zhu · Xing Shi · Wei Lin
[ East Exhibit Hall A-C ]
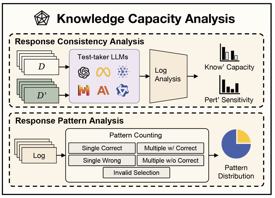
Abstract
Expert-designed close-ended benchmarks are indispensable in assessing the knowledge capacity of large language models (LLMs). Despite their widespread use, concerns have mounted regarding their reliability due to limited test scenarios and an unavoidable risk of data contamination. To rectify this, we present PertEval, a toolkit devised for in-depth probing of LLMs' knowledge capacity through **knowledge-invariant perturbations**. These perturbations employ human-like restatement techniques to generate on-the-fly test samples from static benchmarks, meticulously retaining knowledge-critical content while altering irrelevant details. Our toolkit further includes a suite of **response consistency analyses** that compare performance on raw vs. perturbed test sets to precisely assess LLMs' genuine knowledge capacity. Six representative LLMs are re-evaluated using PertEval. Results reveal significantly inflated performance of the LLMs on raw benchmarks, including an absolute 25.8% overestimation for GPT-4. Additionally, through a nuanced response pattern analysis, we discover that PertEval retains LLMs' uncertainty to specious knowledge, and reveals their potential rote memorization to correct options which leads to overestimated performance. We also find that the detailed response consistency analyses by PertEval could illuminate various weaknesses in existing LLMs' knowledge mastery and guide the development of refinement. Our findings provide insights for advancing more robust and genuinely knowledgeable LLMs. Our code …
Spotlight Poster
Xiaochen Ma · Xuekang Zhu · Lei Su · Bo Du · Zhuohang Jiang · Bingkui Tong · Zeyu Lei · Xinyu Yang · Chi-Man Pun · Jiancheng Lv · Ji-Zhe Zhou
[ West Ballroom A-D ]

Abstract
A comprehensive benchmark is yet to be established in the Image Manipulation Detection \& Localization (IMDL) field. The absence of such a benchmark leads to insufficient and misleading model evaluations, severely undermining the development of this field. However, the scarcity of open-sourced baseline models and inconsistent training and evaluation protocols make conducting rigorous experiments and faithful comparisons among IMDL models challenging. To address these challenges, we introduce IMDL-BenCo, the first comprehensive IMDL benchmark and modular codebase. IMDL-BenCo: i) decomposes the IMDL framework into standardized, reusable components and revises the model construction pipeline, improving coding efficiency and customization flexibility; ii) fully implements or incorporates training code for state-of-the-art models to establish a comprehensive IMDL benchmark; and iii) conducts deep analysis based on the established benchmark and codebase, offering new insights into IMDL model architecture, dataset characteristics, and evaluation standards.Specifically, IMDL-BenCo includes common processing algorithms, 8 state-of-the-art IMDL models (1 of which are reproduced from scratch), 2 sets of standard training and evaluation protocols, 15 GPU-accelerated evaluation metrics, and 3 kinds of robustness evaluation. This benchmark and codebase represent a significant leap forward in calibrating the current progress in the IMDL field and inspiring future breakthroughs.Code is available at: https://github.com/scu-zjz/IMDLBenCo
Spotlight Poster
Jian Song · Hongruixuan Chen · Weihao Xuan · Junshi Xia · Naoto YOKOYA
[ West Ballroom A-D ]

Abstract
Global semantic 3D understanding from single-view high-resolution remote sensing (RS) imagery is crucial for Earth observation (EO). However, this task faces significant challenges due to the high costs of annotations and data collection, as well as geographically restricted data availability. To address these challenges, synthetic data offer a promising solution by being unrestricted and automatically annotatable, thus enabling the provision of large and diverse datasets. We develop a specialized synthetic data generation pipeline for EO and introduce SynRS3D, the largest synthetic RS dataset. SynRS3D comprises 69,667 high-resolution optical images that cover six different city styles worldwide and feature eight land cover types, precise height information, and building change masks. To further enhance its utility, we develop a novel multi-task unsupervised domain adaptation (UDA) method, RS3DAda, coupled with our synthetic dataset, which facilitates the RS-specific transition from synthetic to real scenarios for land cover mapping and height estimation tasks, ultimately enabling global monocular 3D semantic understanding based on synthetic data. Extensive experiments on various real-world datasets demonstrate the adaptability and effectiveness of our synthetic dataset and the proposed RS3DAda method. SynRS3D and related codes are available at https://github.com/JTRNEO/SynRS3D.
Spotlight Poster
Guilherme Penedo · Hynek Kydlíček · Loubna Ben allal · Anton Lozhkov · Margaret Mitchell · Colin Raffel · Leandro Von Werra · Thomas Wolf
[ West Ballroom A-D ]
Abstract
The performance of a large language model (LLM) depends heavily on the quality and size of its pretraining dataset. However, the pretraining datasets for state-of-the-art open LLMs like Llama 3 and Mixtral are not publicly available and very little is known about how they were created. In this work, we introduce FineWeb, a 15-trillion token dataset derived from 96 Common Crawl snapshots that produces better-performing LLMs than other open pretraining datasets. To advance the understanding of how best to curate high-quality pretraining datasets, we carefully document and ablate all of the design choices used in FineWeb, including in-depth investigations of deduplication and filtering strategies. In addition, we introduce FineWeb-Edu, a 1.3-trillion token collection of educational text filtered from FineWeb. LLMs pretrained on FineWeb-Edu exhibit dramatically better performance on knowledge- and reasoning-intensive benchmarks like MMLU and ARC. Along with our datasets, we publicly release our data curation codebase and all of the models trained during our ablation experiments.
Spotlight Poster
Asma Ghandeharioun · Ann Yuan · Marius Guerard · Emily Reif · Michael Lepori · Lucas Dixon
[ East Exhibit Hall A-C ]
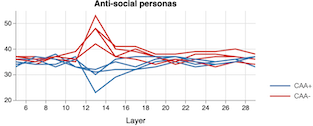
Abstract
Studies show that safety-tuned models may nevertheless divulge harmful information. In this work, we show that whether they do so depends significantly on who they are talking to, which we refer to as *user persona*. In fact, we find manipulating user persona to be more effective for eliciting harmful content than certain more direct attempts to control model refusal. We study both natural language prompting and activation steering as intervention methods and show that activation steering is significantly more effective at bypassing safety filters.We shed light on the mechanics of this phenomenon by showing that even when model generations are safe, harmful content can persist in hidden representations and can be extracted by decoding from earlier layers. We also show we can predict a persona’s effect on refusal given only the geometry of its steering vector. Finally, we show that certain user personas induce the model to form more charitable interpretations of otherwise dangerous queries.
Spotlight Poster
Kaja Gruntkowska · Alexander Tyurin · Peter Richtarik
[ West Ballroom A-D ]
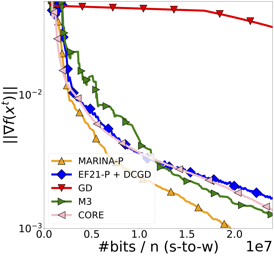
Abstract
Effective communication between the server and workers plays a key role in distributed optimization. In this paper, we focus on optimizing communication, uncovering inefficiencies in prevalent downlink compression approaches. Considering first the pure setup where the uplink communication costs are negligible, we introduce MARINA-P, a novel method for downlink compression, employing a collection of correlated compressors. Theoretical analysis demonstrates that MARINA-P with permutation compressors can achieve a server-to-worker communication complexity improving with the number of workers, thus being provably superior to existing algorithms. We further show that MARINA-P can serve as a starting point for extensions such as methods supporting bidirectional compression: we introduce M3, a method combining MARINA-P with uplink compression and a momentum step, achieving bidirectional compression with provable improvements in total communication complexity as the number of workers increases. Theoretical findings align closely with empirical experiments, underscoring the efficiency of the proposed algorithms.
Spotlight Poster
Maxime Zanella · Benoît Gérin · Ismail Ayed
[ East Exhibit Hall A-C ]
Abstract
Transduction is a powerful paradigm that leverages the structure of unlabeled data to boost predictive accuracy. We present TransCLIP, a novel and computationally efficient transductive approach designed for Vision-Language Models (VLMs). TransCLIP is applicable as a plug-and-play module on top of popular inductive zero- and few-shot models, consistently improving their performances. Our new objective function can be viewed as a regularized maximum-likelihood estimation, constrained by a KL divergence penalty that integrates the text-encoder knowledge and guides the transductive learning process. We further derive an iterative Block Majorize-Minimize (BMM) procedure for optimizing our objective, with guaranteed convergence and decoupled sample-assignment updates, yielding computationally efficient transduction for large-scale datasets. We report comprehensive evaluations, comparisons, and ablation studies that demonstrate: (i) Transduction can greatly enhance the generalization capabilities of inductive pretrained zero- and few-shot VLMs; (ii) TransCLIP substantially outperforms standard transductive few-shot learning methods relying solely on vision features, notably due to the KL-based language constraint.
Spotlight Poster
Xuefeng Du · Chaowei Xiao · Sharon Li
[ East Exhibit Hall A-C ]
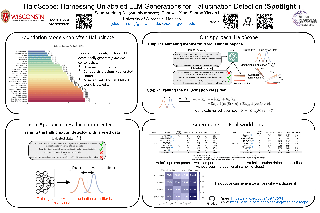
Abstract
The surge in applications of large language models (LLMs) has prompted concerns about the generation of misleading or fabricated information, known as hallucinations. Therefore, detecting hallucinations has become critical to maintaining trust in LLM-generated content. A primary challenge in learning a truthfulness classifier is the lack of a large amount of labeled truthful and hallucinated data. To address the challenge, we introduce HaloScope, a novel learning framework that leverages the unlabeled LLM generations in the wild for hallucination detection. Such unlabeled data arises freely upon deploying LLMs in the open world, and consists of both truthful and hallucinated information. To harness the unlabeled data, we present an automated scoring function for distinguishing between truthful and untruthful generations within unlabeled mixture data, thereby enabling the training of a binary classifier on top. Importantly, our framework does not require extra data collection and human annotations, offering strong flexibility and practicality for real-world applications. Extensive experiments show that HaloScope can achieve superior hallucination detection performance, outperforming the competitive rivals by a significant margin.
Spotlight Poster
Romain Cosson · Laurent Massoulié
[ West Ballroom A-D ]
Abstract
We consider metrical task systems on general metric spaces with $n$ points, and show that any fully randomized algorithm can be turned into a randomized algorithm that uses only $2\log n$ random bits, and achieves the same competitive ratio up to a factor $2$. This provides the first order-optimal barely random algorithms for metrical task systems, i.e. which use a number of random bits that does not depend on the number of requests addressed to the system. We discuss implications on various aspects of online decision making such as: distributed systems, advice complexity and transaction costs, suggesting broad applicability. We put forward an equivalent view that we call collective metrical task systems where $k$ agents in a metrical task system team up, and suffer the average cost paid by each agent. Our results imply that such team can be $O(\log^2 n)$-competitive as soon as $k\geq n^2$. In comparison, a single agent is always $\Omega(n)$-competitive.
Spotlight Poster
Romain Ilbert · Malik Tiomoko · Cosme Louart · Ambroise Odonnat · Vasilii Feofanov · Themis Palpanas · Ievgen Redko
[ West Ballroom A-D ]
Abstract
In this paper, we introduce a novel theoretical framework for multi-task regression, applying random matrix theory to provide precise performance estimations, under high-dimensional, non-Gaussian data distributions. We formulate a multi-task optimization problem as a regularization technique to enable single-task models to leverage multi-task learning information. We derive a closed-form solution for multi-task optimization in the context of linear models. Our analysis provides valuable insights by linking the multi-task learning performance to various model statistics such as raw data covariances, signal-generating hyperplanes, noise levels, as well as the size and number of datasets. We finally propose a consistent estimation of training and testing errors, thereby offering a robust foundation for hyperparameter optimization in multi-task regression scenarios. Experimental validations on both synthetic and real-world datasets in regression and multivariate time series forecasting demonstrate improvements on univariate models, incorporating our method into the training loss and thus leveraging multivariate information.
Spotlight Poster
Xunpeng Huang · Difan Zou · Hanze Dong · Zhang · Yian Ma · Tong Zhang
[ East Exhibit Hall A-C ]
Abstract
To generate data from trained diffusion models, most inference algorithms, such as DDPM, DDIM, and other variants, rely on discretizing the reverse SDEs or their equivalent ODEs. In this paper, we view such approaches as decomposing the entire denoising diffusion process into several segments, each corresponding to a reverse transition kernel (RTK) sampling subproblem. Specifically, DDPM uses a Gaussian approximation for the RTK, resulting in low per-subproblem complexity but requiring a large number of segments (i.e., subproblems), which is conjectured to be inefficient. To address this, we develop a general RTK framework that enables a more balanced subproblem decomposition, resulting in $\tilde O(1)$ subproblems, each with strongly log-concave targets. We then propose leveraging two fast sampling algorithms, the Metropolis-Adjusted Langevin Algorithm (MALA) and Underdamped Langevin Dynamics (ULD), for solving these strongly log-concave subproblems. This gives rise to the RTK-MALA and RTK-ULD algorithms for diffusion inference. In theory, we further develop the convergence guarantees for RTK-MALA and RTK-ULD in total variation (TV) distance: RTK-ULD can achieve $\epsilon$ target error within $\tilde{\mathcal O}(d^{1/2}\epsilon^{-1})$ under mild conditions, and RTK-MALA enjoys a $\mathcal{O}(d^{2}\log(d/\epsilon))$ convergence rate under slightly stricter conditions. These theoretical results surpass the state-of-the-art convergence rates for diffusion inference and are well supported …
Spotlight Poster
Maximilian Stölzle · Cosimo Della Santina
[ East Exhibit Hall A-C ]

Abstract
Even though a variety of methods have been proposed in the literature, efficient and effective latent-space control (i.e., control in a learned low-dimensional space) of physical systems remains an open challenge.We argue that a promising avenue is to leverage powerful and well-understood closed-form strategies from control theory literature in combination with learned dynamics, such as potential-energy shaping.We identify three fundamental shortcomings in existing latent-space models that have so far prevented this powerful combination: (i) they lack the mathematical structure of a physical system, (ii) they do not inherently conserve the stability properties of the real systems, (iii) these methods do not have an invertible mapping between input and latent-space forcing.This work proposes a novel Coupled Oscillator Network (CON) model that simultaneously tackles all these issues. More specifically, (i) we show analytically that CON is a Lagrangian system - i.e., it possesses well-defined potential and kinetic energy terms. Then, (ii) we provide formal proof of global Input-to-State stability using Lyapunov arguments.Moving to the experimental side, we demonstrate that CON reaches SoA performance when learning complex nonlinear dynamics of mechanical systems directly from images.An additional methodological innovation contributing to achieving this third goal is an approximated closed-form solution for efficient integration of …
Spotlight Poster
Jikai Jin · Vasilis Syrgkanis
[ East Exhibit Hall A-C ]
Abstract
We study causal representation learning, the task of recovering high-level latent variables and their causal relationships in the form of a causal graph from low-level observed data (such as text and images), assuming access to observations generated from multiple environments. Prior results on the identifiability of causal representations typically assume access to single-node interventions which is rather unrealistic in practice, since the latent variables are unknown in the first place. In this work, we consider the task of learning causal representation learning with data collected from general environments. We show that even when the causal model and the mixing function are both linear, there exists a surrounded-node ambiguity (SNA) [Varici et al. 2023] which is basically unavoidable in our setting. On the other hand, in the same linear case, we show that identification up to SNA is possible under mild conditions, and propose an algorithm, LiNGCReL which provably achieves such identifiability guarantee. We conduct extensive experiments on synthetic data and demonstrate the effectiveness of LiNGCReL in the finite-sample regime.
Spotlight Poster
Hadi Vafaii · Dekel Galor · Jacob Yates
[ East Exhibit Hall A-C ]
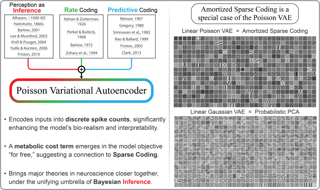
Abstract
Variational autoencoders (VAE) employ Bayesian inference to interpret sensory inputs, mirroring processes that occur in primate vision across both ventral (Higgins et al., 2021) and dorsal (Vafaii et al., 2023) pathways. Despite their success, traditional VAEs rely on continuous latent variables, which significantly deviates from the discrete nature of biological neurons. Here, we developed the Poisson VAE (P-VAE), a novel architecture that combines principles of predictive coding with a VAE that encodes inputs into discrete spike counts. Combining Poisson-distributed latent variables with predictive coding introduces a metabolic cost term in the model loss function, suggesting a relationship with sparse coding which we verify empirically. Additionally, we analyze the geometry of learned representations, contrasting the P-VAE to alternative VAE models. We find that the P-VAE encodes its inputs in relatively higher dimensions, facilitating linear separability of categories in a downstream classification task with a much better (5x) sample efficiency. Our work provides an interpretable computational framework to study brain-like sensory processing and paves the way for a deeper understanding of perception as an inferential process.
Spotlight Poster
XINYU YUAN · Zhihao Zhan · Zuobai Zhang · Manqi Zhou · Jianan Zhao · Boyu Han · Yue Li · Jian Tang
[ East Exhibit Hall A-C ]
Abstract
Transcriptome foundation models (TFMs) hold great promises of deciphering the transcriptomic language that dictate diverse cell functions by self-supervised learning on large-scale single-cell gene expression data, and ultimately unraveling the complex mechanisms of human diseases. However, current TFMs treat cells as independent samples and ignore the taxonomic relationships between cell types, which are available in cell ontology graphs. We argue that effectively leveraging this ontology information during the TFM pre-training can improve learning biologically meaningful gene co-expression patterns while preserving TFM as a general purpose foundation model for downstream zero-shot and fine-tuning tasks. To this end, we present **s**ingle **c**ell, **Cell**-**o**ntology guided TFM (scCello). We introduce cell-type coherence loss and ontology alignment loss, which are minimized along with the masked gene expression prediction loss during the pre-training. The novel loss component guide scCello to learn the cell-type-specific representation and the structural relation between cell types from the cell ontology graph, respectively. We pre-trained scCello on 22 million cells from CellxGene database leveraging their cell-type labels mapped to the cell ontology graph from Open Biological and Biomedical Ontology Foundry. Our TFM demonstrates competitive generalization and transferability performance over the existing TFMs on biologically important tasks including identifying novel cell types of …
Spotlight Poster
Maximilian Beck · Korbinian Pöppel · Markus Spanring · Andreas Auer · Oleksandra Prudnikova · Michael Kopp · Günter Klambauer · Johannes Brandstetter · Sepp Hochreiter
[ East Exhibit Hall A-C ]
Abstract
In the 1990s, the constant error carousel and gating were introduced as the central ideas of the Long Short-Term Memory (LSTM). Since then, LSTMs have stood the test of time and contributed to numerous deep learning success stories, in particular they constituted the first Large Language Models (LLMs). However, the advent of the Transformer technology with parallelizable self-attention at its core marked the dawn of a new era, outpacing LSTMs at scale. We now raise a simple question: How far do we get in language modeling when scaling LSTMs to billions of parameters, leveraging the latest techniques from modern LLMs, but mitigating known limitations of LSTMs? Firstly, we introduce exponential gating with appropriate normalization and stabilization techniques. Secondly, we modify the LSTM memory structure, obtaining: (i) sLSTM with a scalar memory, a scalar update, and new memory mixing, (ii) mLSTM that is fully parallelizable with a matrix memory and a covariance update rule. Integrating these LSTM extensions into residual block backbones yields xLSTM blocks that are then residually stacked into xLSTM architectures. Exponential gating and modified memory structures boost xLSTM capabilities to perform favorably when compared to state-of-the-art Transformers and State Space Models, both in performance and scaling.
Spotlight Poster
Sjoerd van Steenkiste · Daniel Zoran · Yi Yang · Yulia Rubanova · Rishabh Kabra · Carl Doersch · Dilara Gokay · joseph heyward · Etienne Pot · Klaus Greff · Drew Hudson · Thomas Keck · Joao Carreira · Alexey Dosovitskiy · Mehdi S. M. Sajjadi · Thomas Kipf
[ East Exhibit Hall A-C ]
Abstract
Current vision models typically maintain a fixed correspondence between their representation structure and image space.Each layer comprises a set of tokens arranged “on-the-grid,” which biases patches or tokens to encode information at a specific spatio(-temporal) location. In this work we present *Moving Off-the-Grid* (MooG), a self-supervised video representation model that offers an alternative approach, allowing tokens to move “off-the-grid” to better enable them to represent scene elements consistently, even as they move across the image plane through time. By using a combination of cross-attention and positional embeddings we disentangle the representation structure and image structure. We find that a simple self-supervised objective—next frame prediction—trained on video data, results in a set of latent tokens which bind to specific scene structures and track them as they move. We demonstrate the usefulness of MooG’s learned representation both qualitatively and quantitatively by training readouts on top of the learned representation on a variety of downstream tasks. We show that MooG can provide a strong foundation for different vision tasks when compared to “on-the-grid” baselines.
Spotlight Poster
Core Francisco Park · Maya Okawa · Andrew Lee · Ekdeep S Lubana · Hidenori Tanaka
[ East Exhibit Hall A-C ]
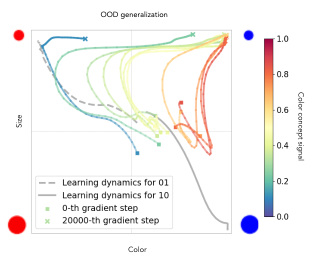
Abstract
Modern generative models demonstrate impressive capabilities, likely stemming from an ability to identify and manipulate abstract concepts underlying their training data. However, fundamental questions remain: what determines the concepts a model learns, the order in which it learns them, and its ability to manipulate those concepts? To address these questions, we propose analyzing a model’s learning dynamics via a framework we call the concept space, where each axis represents an independent concept underlying the data generating process. By characterizing learning dynamics in this space, we identify how the speed at which a concept is learned, and hence the order of concept learning, is controlled by properties of the data we term concept signal. Further, we observe moments of sudden turns in the direction of a model’s learning dynamics in concept space. Surprisingly, these points precisely correspond to the emergence of hidden capabilities, i.e., where latent interventions show the model possesses the capability to manipulate a concept, but these capabilities cannot yet be elicited via naive input prompting. While our results focus on synthetically defined toy datasets, we hypothesize a general claim on emergence of hidden capabilities may hold: generative models possess latent capabilities that emerge suddenly and consistently during training, …
Spotlight Poster
Frederik Kunstner · Alan Milligan · Robin Yadav · Mark Schmidt · Alberto Bietti
[ West Ballroom A-D ]
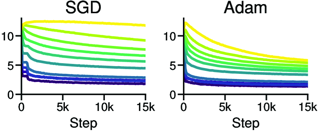
Abstract
Adam has been shown to outperform gradient descent on large language models by a larger margin than on other tasks, but it is unclear why. We show that a key factor in this performance gap is the heavy-tailed class imbalance found in language tasks. When trained with gradient descent, the loss of infrequent words decreases more slowly than the loss of frequent ones. This leads to a slow decrease on the average loss as most samples come from infrequent words. On the other hand, Adam and sign-based methods are less sensitive to this problem. To establish that this behavior is caused by class imbalance, we show empirically that it can be reproduced across architectures and data types, on language transformers, vision CNNs, and linear models. On a linear model with cross-entropy loss, we show that class imbalance leads to imbalanced, correlated gradients and Hessians that have been hypothesized to benefit Adam. We also prove that, in continuous time, gradient descent converges slowly on low-frequency classes while sign descent does not.
Spotlight Poster
Jonas Belouadi · Simone Ponzetto · Steffen Eger
[ East Exhibit Hall A-C ]
Abstract
Creating high-quality scientific figures can be time-consuming and challenging, even though sketching ideas on paper is relatively easy. Furthermore, recreating existing figures that are not stored in formats preserving semantic information is equally complex. To tackle this problem, we introduce DeTikZify, a novel multimodal language model that automatically synthesizes scientific figures as semantics-preserving TikZ graphics programs based on sketches and existing figures. To achieve this, we create three new datasets: DaTikZv2, the largest TikZ dataset to date, containing over 360k human-created TikZ graphics; SketchFig, a dataset that pairs hand-drawn sketches with their corresponding scientific figures; and MetaFig, a collection of diverse scientific figures and associated metadata. We train DeTikZify on MetaFig and DaTikZv2, along with synthetically generated sketches learned from SketchFig. We also introduce an MCTS-based inference algorithm that enables DeTikZify to iteratively refine its outputs without the need for additional training. Through both automatic and human evaluation, we demonstrate that DeTikZify outperforms commercial Claude 3 and GPT-4V in synthesizing TikZ programs, with the MCTS algorithm effectively boosting its performance. We make our code, models, and datasets publicly available.
Spotlight Poster
Hugo Cui · Freya Behrens · Florent Krzakala · Lenka Zdeborová
[ East Exhibit Hall A-C ]
Abstract
Many empirical studies have provided evidence for the emergence of algorithmic mechanisms (abilities) in the learning of language models, that lead to qualitative improvements of the model capabilities. Yet, a theoretical characterization of how such mechanisms emerge remains elusive. In this paper, we take a step in this direction by providing a tight theoretical analysis of the emergence of semantic attention in a solvable model of dot-product attention. More precisely, we consider a non-linear self-attention layer with trainable tied and low-rank query and key matrices. In the asymptotic limit of high-dimensional data and a comparably large number of training samples we provide a tight closed-form characterization of the global minimum of the non-convex empirical loss landscape. We show that this minimum corresponds to either a positional attention mechanism (with tokens attending to each other based on their respective positions) or a semantic attention mechanism (with tokens attending to each other based on their meaning), and evidence an emergent phase transition from the former to the latter with increasing sample complexity. Finally, we compare the dot-product attention layer to a linear positional baseline, and show that it outperforms the latter using the semantic mechanism provided it has access to sufficient data.
Spotlight Poster
Ari Benjamin · Christian-Gernot Pehle · Kyle Daruwalla
[ East Exhibit Hall A-C ]
Abstract
A natural strategy for continual learning is to weigh a Bayesian ensemble of fixed functions. This suggests that if a (single) neural network could be interpreted as an ensemble, one could design effective algorithms that learn without forgetting. To realize this possibility, we observe that a neural network classifier with N parameters can be interpreted as a weighted ensemble of N classifiers, and that in the lazy regime limit these classifiers are fixed throughout learning. We call these classifiers the *neural tangent experts* and show they output valid probability distributions over the labels. We then derive the likelihood and posterior probability of each expert given past data. Surprisingly, the posterior updates for these experts are equivalent to a scaled and projected form of stochastic gradient descent (SGD) over the network weights. Away from the lazy regime, networks can be seen as ensembles of adaptive experts which improve over time. These results offer a new interpretation of neural networks as Bayesian ensembles of experts, providing a principled framework for understanding and mitigating catastrophic forgetting in continual learning settings.
Spotlight Poster
Hao Chen · Yujin Han · Diganta Misra · Xiang Li · Kai Hu · Difan Zou · Masashi Sugiyama · Jindong Wang · Bhiksha Raj
[ East Exhibit Hall A-C ]

Abstract
Diffusion models (DMs) have shown remarkable capabilities in generating realistic high-quality images, audios, and videos. They benefit significantly from extensive pre-training on large-scale datasets, including web-crawled data with paired data and conditions, such as image-text and image-class pairs.Despite rigorous filtering, these pre-training datasets often inevitably contain corrupted pairs where conditions do not accurately describe the data. This paper presents the first comprehensive study on the impact of such corruption in pre-training data of DMs.We synthetically corrupt ImageNet-1K and CC3M to pre-train and evaluate over $50$ conditional DMs. Our empirical findings reveal that various types of slight corruption in pre-training can significantly enhance the quality, diversity, and fidelity of the generated images across different DMs, both during pre-training and downstream adaptation stages. Theoretically, we consider a Gaussian mixture model and prove that slight corruption in the condition leads to higher entropy and a reduced 2-Wasserstein distance to the ground truth of the data distribution generated by the corruptly trained DMs.Inspired by our analysis, we propose a simple method to improve the training of DMs on practical datasets by adding condition embedding perturbations (CEP).CEP significantly improves the performance of various DMs in both pre-training and downstream tasks.We hope that our study provides …
Spotlight Poster
Anqi Zhang · Guangyu Gao · Jianbo Jiao · Chi Liu · Yunchao Wei
[ East Exhibit Hall A-C ]

Abstract
The recent advancements in large-scale pre-training techniques have significantly enhanced the capabilities of vision foundation models, notably the Segment Anything Model (SAM), which can generate precise masks based on point and box prompts. Recent studies extend SAM to Few-shot Semantic Segmentation (FSS), focusing on prompt generation for SAM-based automatic semantic segmentation. However, these methods struggle with selecting suitable prompts, require specific hyperparameter settings for different scenarios, and experience prolonged one-shot inference times due to the overuse of SAM, resulting in low efficiency and limited automation ability. To address these issues, we propose a simple yet effective approach based on graph analysis. In particular, a Positive-Negative Alignment module dynamically selects the point prompts for generating masks, especially uncovering the potential of the background context as the negative reference. Another subsequent Point-Mask Clustering module aligns the granularity of masks and selected points as a directed graph, based on mask coverage over points. These points are then aggregated by decomposing the weakly connected components of the directed graph in an efficient manner, constructing distinct natural clusters. Finally, the positive and overshooting gating, benefiting from graph-based granularity alignment, aggregates high-confident masks and filters the false-positive masks for final prediction, reducing the usage of additional …
Spotlight Poster
Jay Shah · Ganesh Bikshandi · Ying Zhang · Vijay Thakkar · Pradeep Ramani · Tri Dao
[ East Exhibit Hall A-C ]
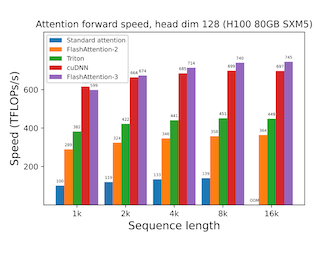
Abstract
Attention, as a core layer of the ubiquitous Transformer architecture, is the bottleneck for large language models and long-context applications. elaborated an approach to speed up attention on GPUs through minimizing memory reads/writes. However, it has yet to take advantage of new capabilities present in recent hardware, with FlashAttention-2 achieving only 35% utilization on the H100 GPU.We develop three main techniques to speed up attention on Hopper GPUs: exploiting asynchrony of the Tensor Cores and TMA to (1) overlap overall computation and data movement via warp-specialization and (2) interleave block-wise matmul and softmax operations, and (3) block quantization and incoherent processing that leverages hardware support for FP8 low-precision. We demonstrate that our method, FlashAttention-3, achieves speedup on H100 GPUs by 1.5-2.0$\times$ with BF16 reaching up to 840 TFLOPs/s (85\% utilization), and with FP8 reaching 1.3 PFLOPs/s. We validate that FP8 FlashAttention-3 achieves 2.6$\times$ lower numerical error than a baseline FP8 attention.
Spotlight Poster
Sriyash Poddar · Yanming Wan · Hamish Ivison · Abhishek Gupta · Natasha Jaques
[ West Ballroom A-D ]
Abstract
Reinforcement Learning from Human Feedback (RLHF) is a powerful paradigm for aligning foundation models to human values and preferences. However, current RLHF techniques cannot account for the naturally occurring differences in individual human preferences across a diverse population. When these differences arise, traditional RLHF frameworks simply average over them, leading to inaccurate rewards and poor performance for individual subgroups. To address the need for pluralistic alignment, we develop a class of multimodal RLHF methods. Our proposed techniques are based on a latent variable formulation - inferring a novel user-specific latent and learning reward models and policies conditioned on this latent without additional user-specific data. While conceptually simple, we show that in practice, this reward modeling requires careful algorithmic considerations around model architecture and reward scaling. To empirically validate our proposed technique, we first show that it can provide a way to combat underspecification in simulated control problems, inferring and optimizing user-specific reward functions. Next, we conduct experiments on pluralistic language datasets representing diverse user preferences and demonstrate improved reward function accuracy. We additionally show the benefits of this probabilistic framework in terms of measuring uncertainty, and actively learning user preferences. This work enables learning from diverse populations of users with …
Spotlight Poster
Luigi Seminara · Giovanni Maria Farinella · Antonino Furnari
[ East Exhibit Hall A-C ]
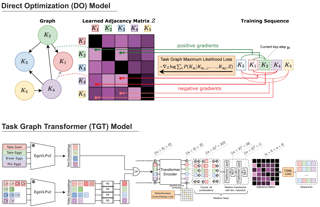
Abstract
Procedural activities are sequences of key-steps aimed at achieving specific goals. They are crucial to build intelligent agents able to assist users effectively. In this context, task graphs have emerged as a human-understandable representation of procedural activities, encoding a partial ordering over the key-steps. While previous works generally relied on hand-crafted procedures to extract task graphs from videos, in this paper, we propose an approach based on direct maximum likelihood optimization of edges' weights, which allows gradient-based learning of task graphs and can be naturally plugged into neural network architectures. Experiments on the CaptainCook4D dataset demonstrate the ability of our approach to predict accurate task graphs from the observation of action sequences, with an improvement of +16.7% over previous approaches. Owing to the differentiability of the proposed framework, we also introduce a feature-based approach, aiming to predict task graphs from key-step textual or video embeddings, for which we observe emerging video understanding abilities. Task graphs learned with our approach are also shown to significantly enhance online mistake detection in procedural egocentric videos, achieving notable gains of +19.8% and +7.5% on the Assembly101-O and EPIC-Tent-O datasets. Code for replicating the experiments is available at https://github.com/fpv-iplab/Differentiable-Task-Graph-Learning.
Spotlight Poster
Nazar Buzun · Maksim Bobrin · Dmitry V. Dylov
[ East Exhibit Hall A-C ]
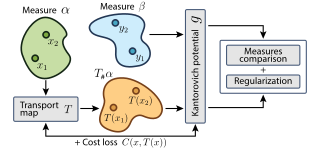
Abstract
We present a new approach for Neural Optimal Transport (NOT) training procedure, capable of accurately and efficiently estimating optimal transportation plan via specific regularization on dual Kantorovich potentials. The main bottleneck of existing NOT solvers is associated with the procedure of finding a near-exact approximation of the conjugate operator (i.e., the c-transform), which is done either by optimizing over non-convex max-min objectives or by the computationally intensive fine-tuning of the initial approximated prediction. We resolve both issues by proposing a new theoretically justified loss in the form of expectile regularization which enforces binding conditions on the learning process of the dual potentials. Such a regularization provides the upper bound estimation over the distribution of possible conjugate potentials and makes the learning stable, completely eliminating the need for additional extensive fine-tuning. Proposed method, called Expectile-Regularized Neural Optimal Transport (ENOT), outperforms previous state-of-the-art approaches in the established Wasserstein-2 benchmark tasks by a large margin (up to a 3-fold improvement in quality and up to a 10-fold improvement in runtime). Moreover, we showcase performance of ENOT for various cost functions in different tasks, such as image generation, demonstrating generalizability and robustness of the proposed algorithm.
Spotlight Poster
Zhanhao Hu · Julien Piet · Geng Zhao · Jiantao Jiao · David Wagner
[ East Exhibit Hall A-C ]
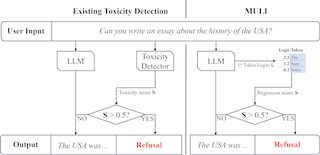
Abstract
Current LLMs are generally aligned to follow safety requirements and tend to refuse toxic prompts. However, LLMs can fail to refuse toxic prompts or be overcautious and refuse benign examples. In addition, state-of-the-art toxicity detectors have low TPRs at low FPR, incurring high costs in real-world applications where toxic examples are rare. In this paper, we introduce Moderation Using LLM Introspection (MULI), which detects toxic prompts using the information extracted directly from LLMs themselves. We found we can distinguish between benign and toxic prompts from the distribution of the first response token's logits. Using this idea, we build a robust detector of toxic prompts using a sparse logistic regression model on the first response token logits. Our scheme outperforms SOTA detectors under multiple metrics.
Spotlight Poster
Kanad Pardeshi · Itai Shapira · Ariel Procaccia · Aarti Singh
[ West Ballroom A-D ]
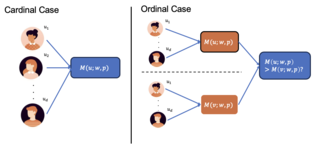
Abstract
Is it possible to understand or imitate a policy maker's rationale by looking at past decisions they made? We formalize this question as the problem of learning social welfare functions belonging to the well-studied family of power mean functions. We focus on two learning tasks; in the first, the input is vectors of utilities of an action (decision or policy) for individuals in a group and their associated social welfare as judged by a policy maker, whereas in the second, the input is pairwise comparisons between the welfares associated with a given pair of utility vectors. We show that power mean functions are learnable with polynomial sample complexity in both cases, even if the social welfare information is noisy. Finally, we design practical algorithms for these tasks and evaluate their performance.
Spotlight Poster
Haoxuan Chen · Yinuo Ren · Lexing Ying · Grant Rotskoff
[ East Exhibit Hall A-C ]
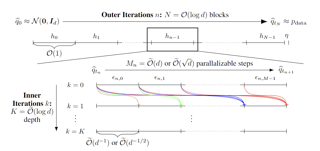
Abstract
Diffusion models have become a leading method for generative modeling of both image and scientific data.As these models are costly to train and \emph{evaluate}, reducing the inference cost for diffusion models remains a major goal.Inspired by the recent empirical success in accelerating diffusion models via the parallel sampling technique~\cite{shih2024parallel}, we propose to divide the sampling process into $\mathcal{O}(1)$ blocks with parallelizable Picard iterations within each block. Rigorous theoretical analysis reveals that our algorithm achieves $\widetilde{\mathcal{O}}(\mathrm{poly} \log d)$ overall time complexity, marking \emph{the first implementation with provable sub-linear complexity w.r.t. the data dimension $d$}. Our analysis is based on a generalized version of Girsanov's theorem and is compatible with both the SDE and probability flow ODE implementations. Our results shed light on the potential of fast and efficient sampling of high-dimensional data on fast-evolving modern large-memory GPU clusters.
Spotlight Poster
Jon Kleinberg · Sendhil Mullainathan
[ West Ballroom A-D ]
Abstract
Although current large language models are complex, the most basic specifications of the underlying language generation problem itself are simple to state: given a finite set of training samples from an unknown language, produce valid new strings from the language that don't already appear in the training data. Here we ask what we can conclude about language generation using only this specification, without further assumptions. In particular, suppose that an adversary enumerates the strings of an unknown target language L that is known only to come from one of a possibly infinite list of candidates. A computational agent is trying to learn to generate from this language; we say that the agent generates from $L$ in the limit if after some finite point in the enumeration of $L$, the agent is able to produce new elements that come exclusively from $L$ and that have not yet been presented by the adversary. Our main result is that there is an agent that is able to generate in the limit for every countable list of candidate languages. This contrasts dramatically with negative results due to Gold and Angluin in a well-studied model of language learning where the goal is to identify an …
Spotlight Poster
Gunshi Gupta · Karmesh Yadav · Yarin Gal · Dhruv Batra · Zsolt Kira · Cong Lu · Tim G. J. Rudner
[ East Exhibit Hall A-C ]
Abstract
Embodied AI agents require a fine-grained understanding of the physical world mediated through visual and language inputs. Such capabilities are difficult to learn solely from task-specific data. This has led to the emergence of pre-trained vision-language models as a tool for transferring representations learned from internet-scale data to downstream tasks and new domains. However, commonly used contrastively trained representations such as in CLIP have been shown to fail at enabling embodied agents to gain a sufficiently fine-grained scene understanding—a capability vital for control. To address this shortcoming, we consider representations from pre-trained text-to-image diffusion models, which are explicitly optimized to generate images from text prompts and as such, contain text-conditioned representations that reflect highly fine-grained visuo-spatial information. Using pre-trained text-to-image diffusion models, we construct Stable Control Representations which allow learning downstream control policies that generalize to complex, open-ended environments. We show that policies learned using Stable Control Representations are competitive with state-of-the-art representation learning approaches across a broad range of simulated control settings, encompassing challenging manipulation and navigation tasks. Most notably, we show that Stable Control Representations enable learning policies that exhibit state-of-the-art performance on OVMM, a difficult open-vocabulary navigation benchmark.
Spotlight Poster
Kevin Yu · Jihye Roh · Ziang Li · Wenhao Gao · Runzhong Wang · Connor Coley
[ East Exhibit Hall A-C ]

Abstract
Computer-aided synthesis planning (CASP) algorithms have demonstrated expert-level abilities in planning retrosynthetic routes to molecules of low to moderate complexity. However, current search methods assume the sufficiency of reaching arbitrary building blocks, failing to address the common real-world constraint where using specific molecules is desired. To this end, we present a formulation of synthesis planning with starting material constraints. Under this formulation, we propose Double-Ended Synthesis Planning ($\texttt{DESP}$), a novel CASP algorithm under a _bidirectional graph search_ scheme that interleaves expansions from the target and from the goal starting materials to ensure constraint satisfiability. The search algorithm is guided by a goal-conditioned cost network learned offline from a partially observed hypergraph of valid chemical reactions. We demonstrate the utility of $\texttt{DESP}$ in improving solve rates and reducing the number of search expansions by biasing synthesis planning towards expert goals on multiple new benchmarks. $\texttt{DESP}$ can make use of existing one-step retrosynthesis models, and we anticipate its performance to scale as these one-step model capabilities improve.
Spotlight Poster
Bora Yongacoglu · Gurdal Arslan · Lacra Pavel · Serdar Yuksel
[ West Ballroom A-D ]
Abstract
In multi-agent reinforcement learning (MARL) and game theory, agents repeatedly interact and revise their strategies as new data arrives, producing a sequence of strategy profiles. This paper studies sequences of strategies satisfying a pairwise constraint inspired by policy updating in reinforcement learning, where an agent who is best responding in one period does not switch its strategy in the next period. This constraint merely requires that optimizing agents do not switch strategies, but does not constrain the non-optimizing agents in any way, and thus allows for exploration. Sequences with this property are called satisficing paths, and arise naturally in many MARL algorithms. A fundamental question about strategic dynamics is such: for a given game and initial strategy profile, is it always possible to construct a satisficing path that terminates at an equilibrium? The resolution of this question has implications about the capabilities or limitations of a class of MARL algorithms. We answer this question in the affirmative for normal-form games. Our analysis reveals a counterintuitive insight that suboptimal, and perhaps even reward deteriorating, strategic updates are key to driving play to equilibrium along a satisficing path.
Spotlight Poster
Lili Wei · Congyan Lang · Ziyi Chen · Tao Wang · Yidong Li · Jun Liu
[ East Exhibit Hall A-C ]

Abstract
Few-shot 3D point cloud semantic segmentation aims to segment query point clouds with only a few annotated support point clouds. Existing prototype-based methods learn prototypes from the 3D support set to guide the segmentation of query point clouds. However, they encounter the challenge of low prototype quality due to constrained semantic information in the 3D support set and class information bias between support and query sets. To address these issues, in this paper, we propose a novel framework called Generated and Pseudo Content guided Prototype Refinement (GPCPR), which explicitly leverages LLM-generated content and reliable query context to enhance prototype quality. GPCPR achieves prototype refinement through two core components: LLM-driven Generated Content-guided Prototype Refinement (GCPR) and Pseudo Query Context-guided Prototype Refinement (PCPR). Specifically, GCPR integrates diverse and differentiated class descriptions generated by large language models to enrich prototypes with comprehensive semantic knowledge. PCPR further aggregates reliable class-specific pseudo-query context to mitigate class information bias and generate more suitable query-specific prototypes. Furthermore, we introduce a dual-distillation regularization term, enabling knowledge transfer between early-stage entities (prototypes or pseudo predictions) and their deeper counterparts to enhance refinement. Extensive experiments demonstrate the superiority of our method, surpassing the state-of-the-art methods by up to 12.10% and …
Spotlight Poster
Kedar Karhadkar · Erin George · Michael Murray · Guido Montufar · Deanna Needell
[ East Exhibit Hall A-C ]
Abstract
The problem of benign overfitting asks whether it is possible for a model to perfectly fit noisy training data and still generalize well. We study benign overfitting in two-layer leaky ReLU networks trained with the hinge loss on a binary classification task. We consider input data which can be decomposed into the sum of a common signal and a random noise component, which lie on subspaces orthogonal to one another. We characterize conditions on the signal to noise ratio (SNR) of the model parameters giving rise to benign versus non-benign, or harmful, overfitting: in particular, if the SNR is high then benign overfitting occurs, conversely if the SNR is low then harmful overfitting occurs. We attribute both benign and non-benign overfitting to an approximate margin maximization property and show that leaky ReLU networks trained on hinge loss with gradient descent (GD) satisfy this property. In contrast to prior work we do not require the training data to be nearly orthogonal. Notably, for input dimension $d$ and training sample size $n$, while results in prior work require $d = \Omega(n^2 \log n)$, here we require only $d = \Omega(n)$.
Spotlight Poster
Bhavya · Lenart Treven · Florian Dorfler · Stelian Coros · Andreas Krause
[ West Ballroom A-D ]

Abstract
We study the problem of nonepisodic reinforcement learning (RL) for nonlinear dynamical systems, where the system dynamics are unknown and the RL agent has to learn from a single trajectory, i.e., without resets. We propose **N**on**e**pisodic **O**ptistmic **RL** (NeoRL), an approach based on the principle of optimism in the face of uncertainty. NeoRL uses well-calibrated probabilistic models and plans optimistically w.r.t. the epistemic uncertainty about the unknown dynamics. Under continuity and bounded energy assumptions on the system, weprovide a first-of-its-kind regret bound of $\mathcal{O}(\beta_T \sqrt{T \Gamma_T})$ for general nonlinear systems with Gaussian process dynamics. We compare NeoRL to other baselines on several deep RL environments and empirically demonstrate that NeoRL achieves the optimal average cost while incurring the least regret.
Spotlight Poster
Wayne Soo · Aldo Battista · Puria Radmard · Xiao-Jing Wang
[ East Exhibit Hall A-C ]
Abstract
In neuroscience, recurrent neural networks (RNNs) are modeled as continuous-time dynamical systems to more accurately reflect the dynamics inherent in biological circuits. However, convolutional neural networks (CNNs) remain the preferred architecture in vision neuroscience due to their ability to efficiently process visual information, which comes at the cost of the biological realism provided by RNNs. To address this, we introduce a hybrid architecture that integrates the continuous-time recurrent dynamics of RNNs with the spatial processing capabilities of CNNs. Our models preserve the dynamical characteristics typical of RNNs while having comparable performance with their conventional CNN counterparts on benchmarks like ImageNet. Compared to conventional CNNs, our models demonstrate increased robustness to noise due to noise-suppressing mechanisms inherent in recurrent dynamical systems. Analyzing our architecture as a dynamical system is computationally expensive, so we develop a toolkit consisting of iterative methods specifically tailored for convolutional structures. We also train multi-area RNNs using our architecture as the front-end to perform complex cognitive tasks previously impossible to learn or achievable only with oversimplified stimulus representations. In monkey neural recordings, our models capture time-dependent variations in neural activity in higher-order visual areas. Together, these contributions represent a comprehensive foundation to unify the advances of CNNs …
Spotlight Poster
Keyon Vafa · Justin Chen · Ashesh Rambachan · Jon Kleinberg · Sendhil Mullainathan
[ East Exhibit Hall A-C ]
Abstract
Recent work suggests that large language models may implicitly learn world models. How should we assess this possibility? We formalize this question for the case where the underlying reality is governed by a deterministic finite automaton. This includes problems as diverse as simple logical reasoning, geographic navigation, game-playing, and chemistry. We propose new evaluation metrics for world model recovery inspired by the classic Myhill-Nerode theorem from language theory. We illustrate their utility in three domains: game playing, logic puzzles, and navigation. In all domains, the generative models we consider do well on existing diagnostics for assessing world models, but our evaluation metrics reveal their world models to be far less coherent than they appear. Such incoherence creates fragility: using a generative model to solve related but subtly different tasks can lead to failures. Building generative models that meaningfully capture the underlying logic of the domains they model would be immensely valuable; our results suggest new ways to assess how close a given model is to that goal.
Spotlight Poster
Timothy Nest · Maxence Ernoult
[ East Exhibit Hall A-C ]
Abstract
Power efficiency is plateauing in the standard digital electronics realm such that new hardware, models, and algorithms are needed to reduce the costs of AI training. The combination of energy-based analog circuits and the Equilibrium Propagation (EP) algorithm constitutes a compelling alternative compute paradigm for gradient-based optimization of neural nets. Existing analog hardware accelerators, however, typically incorporate digital circuitry to sustain auxiliary non-weight-stationary operations, mitigate analog device imperfections, and leverage existing digital platforms. Such heterogeneous hardware lacks a supporting theoretical framework. In this work, we introduce \emph{Feedforward-tied Energy-based Models} (ff-EBMs), a hybrid model comprised of feedforward and energy-based blocks housed on digital and analog circuits. We derive a novel algorithm to compute gradients end-to-end in ff-EBMs by backpropagating and ``eq-propagating'' through feedforward and energy-based parts respectively, enabling EP to be applied flexibly on realistic architectures. We experimentally demonstrate the effectiveness of this approach on ff-EBMs using Deep Hopfield Networks (DHNs) as energy-based blocks, and show that a standard DHN can be arbitrarily split into any uniform size while maintaining or improving performance with increases in simulation speed of up to four times. We then train ff-EBMs on ImageNet32 where we establish a new state-of-the-art performance for the EP literature (46 …
Spotlight Poster
Daniel Kunin · Allan Raventós · Clémentine Dominé · Feng Chen · David Klindt · Andrew Saxe · Surya Ganguli
[ East Exhibit Hall A-C ]
Abstract
While the impressive performance of modern neural networks is often attributed to their capacity to efficiently extract task-relevant features from data, the mechanisms underlying this *rich feature learning regime* remain elusive, with much of our theoretical understanding stemming from the opposing *lazy regime*. In this work, we derive exact solutions to a minimal model that transitions between lazy and rich learning, precisely elucidating how unbalanced *layer-specific* initialization variances and learning rates determine the degree of feature learning. Our analysis reveals that they conspire to influence the learning regime through a set of conserved quantities that constrain and modify the geometry of learning trajectories in parameter and function space. We extend our analysis to more complex linear models with multiple neurons, outputs, and layers and to shallow nonlinear networks with piecewise linear activation functions. In linear networks, rapid feature learning only occurs from balanced initializations, where all layers learn at similar speeds. While in nonlinear networks, unbalanced initializations that promote faster learning in earlier layers can accelerate rich learning. Through a series of experiments, we provide evidence that this unbalanced rich regime drives feature learning in deep finite-width networks, promotes interpretability of early layers in CNNs, reduces the sample complexity of …
Spotlight Poster
Yiping Wang · Yifang Chen · Wendan Yan · Alex Fang · Wenjing Zhou · Kevin Jamieson · Simon Du
[ West Ballroom A-D ]
Abstract
Data selection has emerged as a core issue for large-scale visual-language model pretaining (e.g., CLIP), particularly with noisy web-curated datasets. Three main data selection approaches are: (1) leveraging external non-CLIP models to aid data selection, (2) training new CLIP-style embedding models that are more effective at selecting high-quality data than the original OpenAI CLIP model, and (3) designing better metrics or strategies universally applicable to any CLIP embedding without requiring specific model properties (e.g., CLIPScore is one popular metric). While the first two approaches have been extensively studied, the third remains under-explored. In this paper, we advance the third approach by proposing two new methods. Firstly, instead of classical CLIP scores that only consider the alignment between two modalities from a single sample, we introduce $\textbf{negCLIPLoss}$, a method inspired by CLIP training loss that adds the alignment between one sample and its contrastive pairs as an extra normalization term to CLIPScore for better quality measurement. Secondly, when downstream tasks are known, we propose a new norm-based metric, $\textbf{NormSim}$, to measure the similarity between pretraining data and target data. We test our methods on the data selection benchmark, DataComp [Gadre et al., 2023]. Compared to the best baseline using only OpenAI's …
Spotlight Poster
Xiangdong Zhang · Shaofeng Zhang · Junchi Yan
[ East Exhibit Hall A-C ]
Abstract
Masked autoencoder has been widely explored in point cloud self-supervised learning, whereby the point cloud is generally divided into visible and masked parts. These methods typically include an encoder accepting visible patches (normalized) and corresponding patch centers (position) as input, with the decoder accepting the output of the encoder and the centers (position) of the masked parts to reconstruct each point in the masked patches. Then, the pre-trained encoders are used for downstream tasks. In this paper, we show a motivating empirical result that when directly feeding the centers of masked patches to the decoder without information from the encoder, it still reconstructs well. In other words, the centers of patches are important and the reconstruction objective does not necessarily rely on representations of the encoder, thus preventing the encoder from learning semantic representations. Based on this key observation, we propose a simple yet effective method, $i.e.$, learning to \textbf{P}redict \textbf{C}enters for \textbf{P}oint \textbf{M}asked \textbf{A}uto\textbf{E}ncoders (\textbf{PCP-MAE}) which guides the model to learn to predict the significant centers and use the predicted centers to replace the directly provided centers. Specifically, we propose a Predicting Center Module (PCM) that shares parameters with the original encoder with extra cross-attention to predict centers. Our …
Spotlight Poster
Steve Hanneke · Vinod Raman · Amirreza Shaeiri · Unique Subedi
[ East Exhibit Hall A-C ]
Abstract
We consider the problem of multiclass transductive online learning when the number of labels can be unbounded. Previous works by Ben-David et al. [1997] and Hanneke et al. [2024] only consider the case of binary and finite label spaces respectively. The latter work determined that their techniques fail to extend to the case of unbounded label spaces, and they pose the question of characterizing the optimal mistake bound for unbounded label spaces. We answer this question, by showing that a new dimension, termed the Level-constrained Littlestone dimension, characterizes online learnability in this setting. Along the way, we show that the trichotomy of possible minimax rates established by Hanneke et al. [2024] for finite label spaces in the realizable setting continues to hold even when the label space is unbounded. In particular, if the learner plays for $T \in \mathbb{N}$ rounds, its minimax expected number of mistakes can only grow like $\Theta(T)$, $\Theta(\log T)$, or $\Theta(1)$. To prove this result, we give another combinatorial dimension, termed the Level-constrained Branching dimension, and show that its finiteness characterizes constant minimax expected mistake-bounds. The trichotomy is then determined by a combination of the Level-constrained Littlestone and Branching dimensions. Quantitatively, our upper bounds improve upon …
Spotlight Poster
Jiachen (Tianhao) Wang · Tong Wu · Dawn Song · Prateek Mittal · Ruoxi Jia
[ East Exhibit Hall A-C ]
Abstract
Online batch selection methods offer an adaptive alternative to static training data selection by dynamically selecting data batches during training. However, existing methods either rely on impractical reference models or simple heuristics that may not capture true data informativeness. To address these limitations, we propose \emph{GREedy Approximation Taylor Selection} (GREATS), a principled and efficient online batch selection method that applies greedy algorithm to optimize the data batch quality approximated by Taylor expansion. We develop a series of techniques to scale GREATS to large-scale model training. Extensive experiments with large language models (LLMs) demonstrate that GREATS significantly improves training convergence speed and generalization performance.
Spotlight Poster
Zhenyu Wang · Aoxue Li · Zhenguo Li · Xihui Liu
[ East Exhibit Hall A-C ]
Abstract
Despite the success achieved by existing image generation and editing methods, current models still struggle with complex problems including intricate text prompts, and the absence of verification and self-correction mechanisms makes the generated images unreliable. Meanwhile, a single model tends to specialize in particular tasks and possess the corresponding capabilities, making it inadequate for fulfilling all user requirements. We propose GenArtist, a unified image generation and editing system, coordinated by a multimodal large language model (MLLM) agent. We integrate a comprehensive range of existing models into the tool library and utilize the agent for tool selection and execution. For a complex problem, the MLLM agent decomposes it into simpler sub-problems and constructs a tree structure to systematically plan the procedure of generation, editing, and self-correction with step-by-step verification. By automatically generating missing position-related inputs and incorporating position information, the appropriate tool can be effectively employed to address each sub-problem. Experiments demonstrate that GenArtist can perform various generation and editing tasks, achieving state-of-the-art performance and surpassing existing models such as SDXL and DALL-E 3, as can be seen in Fig. 1. We will open-source the code for future research and applications.
Spotlight Poster
Leon Lufkin · Andrew Saxe · Erin Grant
[ East Exhibit Hall A-C ]
Abstract
Localized receptive fields—neurons that are selective for certain contiguous spatiotemporal features of their input—populate early sensory regions of the mammalian brain. Unsupervised learning algorithms that optimize explicit sparsity or independence criteria replicate features of these localized receptive fields, but fail to explain directly how localization arises through learning without efficient coding, as occurs in early layers of deep neural networks and might occur in early sensory regions of biological systems. We consider an alternative model in which localized receptive fields emerge without explicit top-down efficiency constraints—a feed-forward neural network trained on a data model inspired by the structure of natural images. Previous work identified the importance of non-Gaussian statistics to localization in this setting but left open questions about the mechanisms driving dynamical emergence. We address these questions by deriving the effective learning dynamics for a single nonlinear neuron, making precise how higher-order statistical properties of the input data drive emergent localization, and we demonstrate that the predictions of these effective dynamics extend to the many-neuron setting. Our analysis provides an alternative explanation for the ubiquity of localization as resulting from the nonlinear dynamics of learning in neural circuits
Spotlight Poster
Nived Rajaraman · Jiantao Jiao · Kannan Ramchandran
[ East Exhibit Hall A-C ]
Abstract
While there has been a large body of research attempting to circumvent tokenization for language modeling (Clark et al. 2022, Xue et al. 2022), the current consensus is that it is a necessary initial step for designing state-of-the-art performant language models. In this paper, we investigate tokenization from a theoretical point of view by studying the behavior of transformers on simple data generating processes. When trained on data drawn from certain simple $k^{\text{th}}$-order Markov processes for $k > 1$, transformers exhibit a surprising phenomenon - in the absence of tokenization, they empirically are incredibly slow or fail to learn the right distribution and predict characters according to a unigram model (Makkuva et al. 2024). With the addition of tokenization, however, we empirically observe that transformers break through this barrier and are able to model the probabilities of sequences drawn from the source near-optimally, achieving small cross-entropy loss. With this observation as starting point, we study the end-to-end cross-entropy loss achieved by transformers with and without tokenization. With the appropriate tokenization, we show that even the simplest unigram models (over tokens) learnt by transformers are able to model the probability of sequences drawn from $k^{\text{th}}$-order Markov sources near optimally. Our analysis provides …
Spotlight Poster
Tao Yang · Cuiling Lan · Yan Lu · Nanning Zheng
[ East Exhibit Hall A-C ]

Abstract
Disentangled representation learning strives to extract the intrinsic factors within the observed data. Factoring these representations in an unsupervised manner is notably challenging and usually requires tailored loss functions or specific structural designs. In this paper, we introduce a new perspective and framework, demonstrating that diffusion models with cross-attention itself can serve as a powerful inductive bias to facilitate the learning of disentangled representations. We propose to encode an image into a set of concept tokens and treat them as the condition of the latent diffusion model for image reconstruction, where cross attention over the concept tokens is used to bridge the encoder and the U-Net of the diffusion model. We analyze that the diffusion process inherently possesses the time-varying information bottlenecks. Such information bottlenecks and cross attention act as strong inductive biases for promoting disentanglement. Without any regularization term in the loss function, this framework achieves superior disentanglement performance on the benchmark datasets, surpassing all previous methods with intricate designs. We have conducted comprehensive ablation studies and visualization analyses, shedding a light on the functioning of this model. We anticipate that our findings will inspire more investigation on exploring diffusion model for disentangled representation learning towards more sophisticated data …
Spotlight Poster
Paul Krzakala · Junjie Yang · Rémi Flamary · Florence d'Alché-Buc · Charlotte Laclau · Matthieu Labeau
[ East Exhibit Hall A-C ]
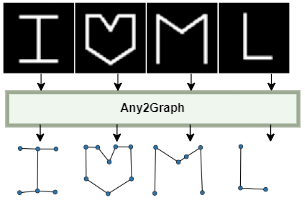
Abstract
We propose Any2graph, a generic framework for end-to-end Supervised Graph Prediction (SGP) i.e. a deep learning model that predicts an entire graph for any kind of input. The framework is built on a novel Optimal Transport loss, the Partially-Masked Fused Gromov-Wasserstein, that exhibits all necessary properties (permutation invariance, differentiability and scalability) and is designed to handle any-sized graphs. Numerical experiments showcase the versatility of the approach that outperform existing competitors on a novel challenging synthetic dataset and a variety of real-world tasks such as map construction from satellite image (Sat2Graph) or molecule prediction from fingerprint (Fingerprint2Graph).
Spotlight Poster
Ruochen Liu · Hao Chen · Yuanchen Bei · Qijie Shen · Fangwei Zhong · Senzhang Wang · Jianxin Wang
[ East Exhibit Hall A-C ]
Abstract
Recommending out-of-vocabulary (OOV) items is a challenging problem since the in-vocabulary (IV) items have well-trained behavioral embeddings but the OOV items only have content features. Current OOV recommendation models often generate 'makeshift' embeddings for OOV items from content features and then jointly recommend with the `makeshift' OOV item embeddings and the behavioral IV item embeddings. However, merely using the 'makeshift' embedding will result in suboptimal recommendation performance due to the substantial gap between the content feature and the behavioral embeddings. To bridge the gap, we propose a novel **User Sequence IMagination (USIM)** fine-tuning framework, which first imagines the user sequences and then refines the generated OOV embeddings with the user behavioral embeddings. Specifically, we frame the user sequence imagination as a reinforcement learning problem and develop a recommendation-focused reward function to evaluate to what extent a user can help recommend the OOV items. Besides, we propose an embedding-driven transition function to model the embedding transition after imaging a user. USIM has been deployed on a prominent e-commerce platform for months, offering recommendations for millions of OOV items and billions of users. Extensive experiments demonstrate that USIM outperforms traditional generative models in OOV item recommendation performance across traditional collaborative filtering and …
Spotlight Poster
Ilija Radosavovic · Bike Zhang · Baifeng Shi · Jathushan Rajasegaran · Sarthak Kamat · Trevor Darrell · Koushil Sreenath · Jitendra Malik
[ East Exhibit Hall A-C ]
Abstract
We cast real-world humanoid control as a next token prediction problem, akin to predicting the next word in language. Our model is a causal transformer trained via autoregressive prediction of sensorimotor sequences. To account for the multi-modal nature of the data, we perform prediction in a modality-aligned way, and for each input token predict the next token from the same modality. This general formulation enables us to leverage data with missing modalities, such as videos without actions. We train our model on a dataset of sequences from a prior neural network policy, a model-based controller, motion capture, and YouTube videos of humans. We show that our model enables a real humanoid robot to walk in San Francisco zero-shot. Our model can transfer to the real world even when trained on only 27 hours of walking data, and can generalize to commands not seen during training. These findings suggest a promising path toward learning challenging real-world control tasks by generative modeling of sensorimotor sequences.
Spotlight Poster
Dylan J Foster · Adam Block · Dipendra Misra
[ West Ballroom A-D ]
Abstract
Imitation learning (IL) aims to mimic the behavior of an expert in a sequential decision making task by learning from demonstrations, and has been widely applied to robotics, autonomous driving, and autoregressive text generation. The simplest approach to IL, behavior cloning (BC) is thought to incur sample complexity with unfavorable quadratic dependence on the problem horizon, motivating a variety of different online algorithms that attain improved linear horizon dependence under stronger assumptions on the data and the learner’s access to the expert. We revisit the apparent gap between offline and online IL from a learning-theoretic perspective, with a focus on general policy classes up to and including deep neural networks. Through a new analysis of BC with the logarithmic loss, we show that it is possible to achieve horizon-independent sample complexity in offline IL whenever (i) the range of the cumulative payoffs is controlled, and (ii) an appropriate notion of supervised learning complexity for the policy class is controlled. Specializing our results to deterministic, stationary policies, we show that the gap between offline and online IL is not fundamental: (i) it is possible to achieve linear dependence on horizon in offline IL under dense rewards (matching what was previously only …
Spotlight Poster
Wenyang Hu · Yao Shu · Zongmin Yu · Zhaoxuan Wu · Xiaoqiang Lin · Zhongxiang Dai · See-Kiong Ng · Bryan Kian Hsiang Low
[ East Exhibit Hall A-C ]
Abstract
The efficacy of large language models (LLMs) in understanding and generating natural language has aroused a wide interest in developing prompt-based methods to harness the power of black-box LLMs. Existing methodologies usually prioritize a global optimization for finding the global optimum, which however will perform poorly in certain tasks. This thus motivates us to re-think the necessity of finding a global optimum in prompt optimization. To answer this, we conduct a thorough empirical study on prompt optimization and draw two major insights. Contrasting with the rarity of global optimum, local optima are usually prevalent and well-performed, which can be more worthwhile for efficient prompt optimization (**Insight I**). The choice of the input domain, covering both the generation and the representation of prompts, affects the identification of well-performing local optima (**Insight II**). Inspired by these insights, we propose a novel algorithm, namely localized zeroth-order prompt optimization (ZOPO), which incorporates a Neural Tangent Kernel-based derived Gaussian process into standard zeroth-order optimization for an efficient search of well-performing local optima in prompt optimization. Remarkably, ZOPO outperforms existing baselines in terms of both the optimization performance and the query efficiency, which we demonstrate through extensive experiments.
Spotlight Poster
Yuanqing Wang · Kyunghyun Cho
[ East Exhibit Hall A-C ]
Abstract
Rethink convolution-based graph neural networks (GNN)---they characteristically suffer from limited expressiveness, over-smoothing, and over-squashing, and require specialized sparse kernels for efficient computation.Here, we design a simple graph learning module entirely free of convolution operators, coined _random walk with unifying memory_ (RUM) neural network, where an RNN merges the topological and semantic graph features along the random walks terminating at each node.Relating the rich literature on RNN behavior and graph topology, we theoretically show and experimentally verify that RUM attenuates the aforementioned symptoms and is more expressive than the Weisfeiler-Lehman (WL) isomorphism test.On a variety of node- and graph-level classification and regression tasks, RUM not only achieves competitive performance, but is also robust, memory-efficient, scalable, and faster than the simplest convolutional GNNs.
Spotlight Poster
Alexander Kolesov · Petr Mokrov · Igor Udovichenko · Milena Gazdieva · Gudmund Pammer · Anastasis Kratsios · Evgeny Burnaev · Aleksandr Korotin
[ East Exhibit Hall A-C ]
Abstract
Optimal transport (OT) barycenters are a mathematically grounded way of averaging probability distributions while capturing their geometric properties. In short, the barycenter task is to take the average of a collection of probability distributions w.r.t. given OT discrepancies. We propose a novel algorithm for approximating the continuous Entropic OT (EOT) barycenter for arbitrary OT cost functions. Our approach is built upon the dual reformulation of the EOT problem based on weak OT, which has recently gained the attention of the ML community. Beyond its novelty, our method enjoys several advantageous properties: (i) we establish quality bounds for the recovered solution; (ii) this approach seamlessly interconnects with the Energy-Based Models (EBMs) learning procedure enabling the use of well-tuned algorithms for the problem of interest; (iii) it provides an intuitive optimization scheme avoiding min-max, reinforce and other intricate technical tricks. For validation, we consider several low-dimensional scenarios and image-space setups, including *non-Euclidean* cost functions. Furthermore, we investigate the practical task of learning the barycenter on an image manifold generated by a pretrained generative model, opening up new directions for real-world applications. Our code is available at https://github.com/justkolesov/EnergyGuidedBarycenters.
Spotlight Poster
Hao Dong · Yue Zhao · Eleni Chatzi · Olga Fink
[ East Exhibit Hall A-C ]
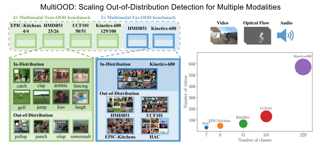
Abstract
Detecting out-of-distribution (OOD) samples is important for deploying machine learning models in safety-critical applications such as autonomous driving and robot-assisted surgery. Existing research has mainly focused on unimodal scenarios on image data. However, real-world applications are inherently multimodal, which makes it essential to leverage information from multiple modalities to enhance the efficacy of OOD detection. To establish a foundation for more realistic Multimodal OOD Detection, we introduce the first-of-its-kind benchmark, MultiOOD, characterized by diverse dataset sizes and varying modality combinations. We first evaluate existing unimodal OOD detection algorithms on MultiOOD, observing that the mere inclusion of additional modalities yields substantial improvements. This underscores the importance of utilizing multiple modalities for OOD detection. Based on the observation of Modality Prediction Discrepancy between in-distribution (ID) and OOD data, and its strong correlation with OOD performance, we propose the Agree-to-Disagree (A2D) algorithm to encourage such discrepancy during training. Moreover, we introduce a novel outlier synthesis method, NP-Mix, which explores broader feature spaces by leveraging the information from nearest neighbor classes and complements A2D to strengthen OOD detection performance. Extensive experiments on MultiOOD demonstrate that training with A2D and NP-Mix improves existing OOD detection algorithms by a large margin. To support accessibility and reproducibility, …
Spotlight Poster
Gongfan Fang · Hongxu Yin · Saurav Muralidharan · Greg Heinrich · Jeff Pool · Jan Kautz · Pavlo Molchanov · Xinchao Wang
[ East Exhibit Hall A-C ]
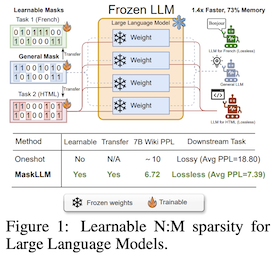
Abstract
Large Language Models (LLMs) are distinguished by their massive parameter counts, which typically result in significant redundancy. This work introduces MaskLLM, a learnable pruning method that establishes Semi-structured (or ``N:M'') Sparsity in LLMs, aimed at reducing computational overhead during inference. Instead of developing a new importance criterion, MaskLLM explicitly models N:M patterns as a learnable distribution through Gumbel Softmax sampling. This approach facilitates end-to-end training on large-scale datasets and offers two notable advantages: 1) High-quality Masks - our method effectively scales to large datasets and learns accurate masks; 2) Transferability - the probabilistic modeling of mask distribution enables the transfer learning of sparsity across domains or tasks. We assessed MaskLLM using 2:4 sparsity on various LLMs, including LLaMA-2, Nemotron-4, and GPT-3, with sizes ranging from 843M to 15B parameters, and our empirical results show substantial improvements over state-of-the-art methods. For instance, leading approaches achieve a perplexity (PPL) of 10 or greater on Wikitext compared to the dense model's 5.12 PPL, but MaskLLM achieves a significantly lower 6.72 PPL solely by learning the masks with frozen weights. Furthermore, MaskLLM's learnable nature allows customized masks for lossless application of 2:4 sparsity to downstream tasks or domains. Code is available at https://github.com/NVlabs/MaskLLM.
Spotlight Poster
Hanyang Chen · Yang Jiang · Shengnan Guo · Xiaowei Mao · Youfang Lin · Huaiyu Wan
[ East Exhibit Hall A-C ]
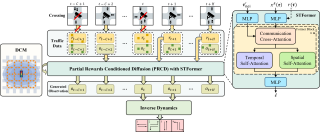
Abstract
The application of reinforcement learning in traffic signal control (TSC) has been extensively researched and yielded notable achievements. However, most existing works for TSC assume that traffic data from all surrounding intersections is fully and continuously available through sensors. In real-world applications, this assumption often fails due to sensor malfunctions or data loss, making TSC with missing data a critical challenge. To meet the needs of practical applications, we introduce DiffLight, a novel conditional diffusion model for TSC under data-missing scenarios in the offline setting. Specifically, we integrate two essential sub-tasks, i.e., traffic data imputation and decision-making, by leveraging a Partial Rewards Conditioned Diffusion (PRCD) model to prevent missing rewards from interfering with the learning process. Meanwhile, to effectively capture the spatial-temporal dependencies among intersections, we design a Spatial-Temporal transFormer (STFormer) architecture. In addition, we propose a Diffusion Communication Mechanism (DCM) to promote better communication and control performance under data-missing scenarios. Extensive experiments on five datasets with various data-missing scenarios demonstrate that DiffLight is an effective controller to address TSC with missing data. The code of DiffLight is released at https://github.com/lokol5579/DiffLight-release.
Spotlight Poster
Eloi Alonso · Adam Jelley · Vincent Micheli · Anssi Kanervisto · Amos Storkey · Tim Pearce · François Fleuret
[ West Ballroom A-D ]

Abstract
World models constitute a promising approach for training reinforcement learning agents in a safe and sample-efficient manner. Recent world models predominantly operate on sequences of discrete latent variables to model environment dynamics. However, this compression into a compact discrete representation may ignore visual details that are important for reinforcement learning. Concurrently, diffusion models have become a dominant approach for image generation, challenging well-established methods modeling discrete latents. Motivated by this paradigm shift, we introduce DIAMOND (DIffusion As a Model Of eNvironment Dreams), a reinforcement learning agent trained in a diffusion world model. We analyze the key design choices that are required to make diffusion suitable for world modeling, and demonstrate how improved visual details can lead to improved agent performance. DIAMOND achieves a mean human normalized score of 1.46 on the competitive Atari 100k benchmark; a new best for agents trained entirely within a world model. We further demonstrate that DIAMOND's diffusion world model can stand alone as an interactive neural game engine by training on static *Counter-Strike: Global Offensive* gameplay. To foster future research on diffusion for world modeling, we release our code, agents, videos and playable world models at https://diamond-wm.github.io.
Spotlight Poster
Zijie Ye · Jia-Wei Liu · Jia Jia · Shikun Sun · Mike Zheng Shou
[ East Exhibit Hall A-C ]
Abstract
Capturing and maintaining geometric interactions among different body parts is crucial for successful motion retargeting in skinned characters. Existing approaches often overlook body geometries or add a geometry correction stage after skeletal motion retargeting. This results in conflicts between skeleton interaction and geometry correction, leading to issues such as jittery, interpenetration, and contact mismatches. To address these challenges, we introduce a new retargeting framework, MeshRet, which directly models the dense geometric interactions in motion retargeting. Initially, we establish dense mesh correspondences between characters using semantically consistent sensors (SCS), effective across diverse mesh topologies. Subsequently, we develop a novel spatio-temporal representation called the dense mesh interaction (DMI) field. This field, a collection of interacting SCS feature vectors, skillfully captures both contact and non-contact interactions between body geometries. By aligning the DMI field during retargeting, MeshRet not only preserves motion semantics but also prevents self-interpenetration and ensures contact preservation. Extensive experiments on the public Mixamo dataset and our newly-collected ScanRet dataset demonstrate that MeshRet achieves state-of-the-art performance. Code available at https://github.com/abcyzj/MeshRet.
Spotlight Poster
Yi-Shan Wu · Yijie Zhang · Badr-Eddine Cherief-Abdellatif · Yevgeny Seldin
[ West Ballroom A-D ]
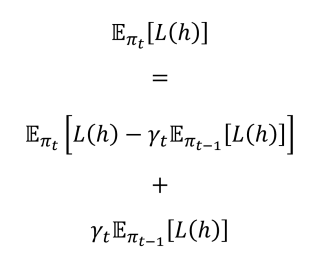
Abstract
PAC-Bayesian analysis is a frequentist framework for incorporating prior knowledge into learning. It was inspired by Bayesian learning, which allows sequential data processing and naturally turns posteriors from one processing step into priors for the next. However, despite two and a half decades of research, the ability to update priors sequentially without losing confidence information along the way remained elusive for PAC-Bayes. While PAC-Bayes allows construction of data-informed priors, the final confidence intervals depend only on the number of points that were not used for the construction of the prior, whereas confidence information in the prior, which is related to the number of points used to construct the prior, is lost. This limits the possibility and benefit of sequential prior updates, because the final bounds depend only on the size of the final batch.We present a novel and, in retrospect, surprisingly simple and powerful PAC-Bayesian procedure that allows sequential prior updates with no information loss. The procedure is based on a novel decomposition of the expected loss of randomized classifiers. The decomposition rewrites the loss of the posterior as an excess loss relative to a downscaled loss of the prior plus the downscaled loss of the prior, which is bounded …
Spotlight Poster
Seong Hyeon Park · Huiwon Jang · Byungwoo Jeon · Sukmin Yun · Paul Hongsuck Seo · Jinwoo Shin
[ East Exhibit Hall A-C ]
Abstract
Tracking points in video frames is essential for understanding video content. However, the task is fundamentally hindered by the computation demands for brute-force correspondence matching across the frames. As the current models down-sample the frame resolutions to mitigate this challenge, they fall short in accurately representing point trajectories due to information truncation. Instead, we address the challenge by pruning the search space for point tracking and let the model process only the important regions of the frames without down-sampling. Our first key idea is to identify the object instance and its trajectory over the frames, then prune the regions of the frame that do not contain the instance. Concretely, to estimate the instance’s trajectory, we track a group of points on the instance and aggregate their motion trajectories. Furthermore, to deal with the occlusions in complex scenes, we propose to compensate for the occluded points while tracking. To this end, we introduce a unified framework that jointly performs point tracking and segmentation, providing synergistic effects between the two tasks. For example, the segmentation results enable a tracking model to avoid the occluded points referring to the instance mask, and conversely, the improved tracking results can help to produce more accurate …
Spotlight Poster
Yiming Wang · Kaiyan Zhao · Furui Liu · Leong Hou U
[ West Ballroom A-D ]
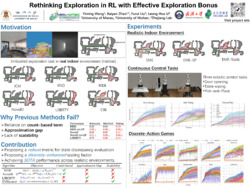
Abstract
Enhancing exploration in reinforcement learning (RL) through the incorporation of intrinsic rewards, specifically by leveraging *state discrepancy* measures within various metric spaces as exploration bonuses, has emerged as a prevalent strategy to encourage agents to visit novel states. The critical factor lies in how to quantify the difference between adjacent states as *novelty* for promoting effective exploration.Nonetheless, existing methods that evaluate state discrepancy in the latent space under $L_1$ or $L_2$ norm often depend on count-based episodic terms as scaling factors for exploration bonuses, significantly limiting their scalability. Additionally, methods that utilize the bisimulation metric for evaluating state discrepancies face a theory-practice gap due to improper approximations in metric learning, particularly struggling with *hard exploration* tasks. To overcome these challenges, we introduce the **E**ffective **M**etric-based **E**xploration-bonus (EME). EME critically examines and addresses the inherent limitations and approximation inaccuracies of current metric-based state discrepancy methods for exploration, proposing a robust metric for state discrepancy evaluation backed by comprehensive theoretical analysis. Furthermore, we propose the diversity-enhanced scaling factor integrated into the exploration bonus to be dynamically adjusted by the variance of prediction from an ensemble of reward models, thereby enhancing exploration effectiveness in particularly challenging scenarios. Extensive experiments are conducted on hard …
Spotlight Poster
Adhyyan Narang · Andrew Wagenmaker · Lillian Ratliff · Kevin Jamieson
[ West Ballroom A-D ]
Abstract
In this paper, we study the non-asymptotic sample complexity for the pure exploration problem in contextual bandits and tabular reinforcement learning (RL): identifying an $\epsilon$-optimal policy from a set of policies $\Pi$ with high probability. Existing work in bandits has shown that it is possible to identify the best policy by estimating only the *difference* between the behaviors of individual policies–which can have substantially lower variance than estimating the behavior of each policy directly—yet the best-known complexities in RL fail to take advantage of this, and instead estimate the behavior of each policy directly. Does it suffice to estimate only the differences in the behaviors of policies in RL? We answer this question positively for contextual bandits, but in the negative for tabular RL, showing a separation between contextual bandits and RL. However, inspired by this, we show that it *almost* suffices to estimate only the differences in RL: if we can estimate the behavior of a *single* reference policy, it suffices to only estimate how any other policy deviates from this reference policy. We develop an algorithm which instantiates this principle and obtains, to the best of our knowledge, the tightest known bound on the sample complexity of tabular …
Spotlight Poster
Otmane Sakhi · Imad Aouali · Pierre Alquier · Nicolas Chopin
[ West Ballroom A-D ]
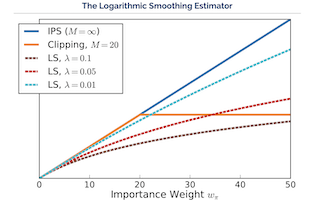
Abstract
This work investigates the offline formulation of the contextual bandit problem, where the goal is to leverage past interactions collected under a behavior policy to evaluate, select, and learn new, potentially better-performing, policies. Motivated by critical applications, we move beyond point estimators. Instead, we adopt the principle of _pessimism_ where we construct upper bounds that assess a policy's worst-case performance, enabling us to confidently select and learn improved policies. Precisely, we introduce novel, fully empirical concentration bounds for a broad class of importance weighting risk estimators. These bounds are general enough to cover most existing estimators and pave the way for the development of new ones. In particular, our pursuit of the tightest bound within this class motivates a novel estimator (LS), that _logarithmically smoothes_ large importance weights. The bound for LS is provably tighter than its competitors, and naturally results in improved policy selection and learning strategies. Extensive policy evaluation, selection, and learning experiments highlight the versatility and favorable performance of LS.
Spotlight Poster
Yupeng Zhou · Daquan Zhou · Ming-Ming Cheng · Jiashi Feng · Qibin Hou
[ East Exhibit Hall A-C ]

Abstract
For recent diffusion-based generative models, maintaining consistent content across a series of generated images, especially those containing subjects and complex details, presents a significant challenge. In this paper, we propose a simple but effective self-attention mechanism, termed Consistent Self-Attention, that boosts the consistency between the generated images. It can be used to augment pre-trained diffusion-based text-to-image models in a zero-shot manner. Based on the images with consistent content, we further show that our method can be extended to long range video generation by introducing a semantic space temporal motion prediction module, named Semantic Motion Predictor. It is trained to estimate the motion conditions between two provided images in the semantic spaces. This module converts the generated sequence of images into videos with smooth transitions and consistent subjects that are more stable than the modules based on latent spaces only, especially in the context of long video generation. By merging these two novel components, our framework, referred to as StoryDiffusion, can describe a text-based story with consistent images or videos encompassing a rich variety of contents. The proposed StoryDiffusion encompasses pioneering explorations in visual story generation with the presentation of images and videos, which we hope could inspire more research from …
Spotlight Poster
Michal Nauman · Mateusz Ostaszewski · Krzysztof Jankowski · Piotr Miłoś · Marek Cygan
[ West Ballroom A-D ]

Abstract
Sample efficiency in Reinforcement Learning (RL) has traditionally been driven by algorithmic enhancements. In this work, we demonstrate that scaling can also lead to substantial improvements. We conduct a thorough investigation into the interplay of scaling model capacity and domain-specific RL enhancements. These empirical findings inform the design choices underlying our proposed BRO (Bigger, Regularized, Optimistic) algorithm. The key innovation behind BRO is that strong regularization allows for effective scaling of the critic networks, which, paired with optimistic exploration, leads to superior performance. BRO achieves state-of-the-art results, significantly outperforming the leading model-based and model-free algorithms across 40 complex tasks from the DeepMind Control, MetaWorld, and MyoSuite benchmarks. BRO is the first model-free algorithm to achieve near-optimal policies in the notoriously challenging Dog and Humanoid tasks.
Spotlight Poster
Adithya Bhaskar · Alexander Wettig · Dan Friedman · Danqi Chen
[ East Exhibit Hall A-C ]
Abstract
The path to interpreting a language model often proceeds via analysis of circuits---sparse computational subgraphs of the model that capture specific aspects of its behavior. Recent work has automated the task of discovering circuits. Yet, these methods have practical limitations, as they either rely on inefficient search algorithms or inaccurate approximations. In this paper, we frame circuit discovery as an optimization problem and propose _Edge Pruning_ as an effective and scalable solution. Edge Pruning leverages gradient-based pruning techniques, but instead of removing neurons or components, prunes the _edges_ between components. Our method finds circuits in GPT-2 that use less than half the number of edges than circuits found by previous methods while being equally faithful to the full model predictions on standard circuit-finding tasks. Edge Pruning is efficient on tasks involving up to 100,000 examples, outperforming previous methods in speed and producing substantially better circuits. It also perfectly recovers the ground-truth circuits in two models compiled with Tracr. Thanks to its efficiency, we scale Edge Pruning to CodeLlama-13B, a model over 100x the size of GPT-2.We use this setting for a case study, where we compare the mechanisms behind instruction prompting and in-context learning.We find two circuits with more than …
Spotlight Poster
Zhaorui Tan · Xi Yang · Qiufeng Wang · Anh Nguyen · Kaizhu Huang
[ West Ballroom A-D ]

Abstract
Vision models excel in image classification but struggle to generalize to unseen data, such as classifying images from unseen domains or discovering novel categories. In this paper, we explore the relationship between logical reasoning and deep learning generalization in visual classification. A logical regularization termed L-Reg is derived which bridges a logical analysis framework to image classification. Our work reveals that L-Reg reduces the complexity of the model in terms of the feature distribution and classifier weights. Specifically, we unveil the interpretability brought by L-Reg, as it enables the model to extract the salient features, such as faces to persons, for classification. Theoretical analysis and experiments demonstrate that L-Reg enhances generalization across various scenarios, including multi-domain generalization and generalized category discovery. In complex real-world scenarios where images span unknown classes and unseen domains, L-Reg consistently improves generalization, highlighting its practical efficacy.
Spotlight Poster
Itai Gat · Tal Remez · Neta Shaul · Felix Kreuk · Ricky T. Q. Chen · Gabriel Synnaeve · Yossi Adi · Yaron Lipman
[ East Exhibit Hall A-C ]
Abstract
Despite Flow Matching and diffusion models having emerged as powerful generative paradigms for continuous variables such as images and videos, their application to high-dimensional discrete data, such as language, is still limited. In this work, we present Discrete Flow Matching, a novel discrete flow paradigm designed specifically for generating discrete data. Discrete Flow Matching offers several key contributions: (i) it works with a general family of probability paths interpolating between source and target distributions; (ii) it allows for a generic formula for sampling from these probability paths using learned posteriors such as the probability denoiser ($x$-prediction) and noise-prediction ($\epsilon$-prediction); (iii) practically, focusing on specific probability paths defined with different schedulers improves generative perplexity compared to previous discrete diffusion and flow models; and (iv) by scaling Discrete Flow Matching models up to 1.7B parameters, we reach 6.7% Pass@1 and 13.4% Pass@10 on HumanEval and 6.7% Pass@1 and 20.6% Pass@10 on 1-shot MBPP coding benchmarks. Our approach is capable of generating high-quality discrete data in a non-autoregressive fashion, significantly closing the gap between autoregressive models and discrete flow models.
Spotlight Poster
Gantavya Bhatt · Arnav Das · Jeff A Bilmes
[ East Exhibit Hall A-C ]
Abstract
Submodular functions, crucial for various applications, often lack practical learning methods for their acquisition. Seemingly unrelated, learning a scaling from oracles offering graded pairwise preferences (GPC) is underexplored, despite a rich history in psychometrics. In this paper, we introduce deep submodular peripteral networks (DSPNs), a novel parametric family of submodular functions, and methods for their training using a GPC-based strategy to connect and then tackle both of the above challenges. We introduce newly devised GPC-style ``peripteral'' loss which leverages numerically graded relationships between pairs of objects (sets in our case). Unlike traditional contrastive learning, or RHLF preference ranking, our method utilizes graded comparisons, extracting more nuanced information than just binary-outcome comparisons, and contrasts sets of any size (not just two). We also define a novel suite of automatic sampling strategies for training, including active-learning inspired submodular feedback. We demonstrate DSPNs' efficacy in learning submodularity from a costly target submodular function and demonstrate its superiority both for experimental design and online streaming applications.
Spotlight Poster
Thibault Simonetto · Salah GHAMIZI · Maxime Cordy
[ East Exhibit Hall A-C ]
Abstract
State-of-the-art deep learning models for tabular data have recently achieved acceptable performance to be deployed in industrial settings. However, the robustness of these models remains scarcely explored. Contrary to computer vision, there are no effective attacks to properly evaluate the adversarial robustness of deep tabular models due to intrinsic properties of tabular data, such as categorical features, immutability, and feature relationship constraints. To fill this gap, we first propose CAPGD, a gradient attack that overcomes the failures of existing gradient attacks with adaptive mechanisms. This new attack does not require parameter tuning and further degrades the accuracy, up to 81\% points compared to the previous gradient attacks. Second, we design CAA, an efficient evasion attack that combines our CAPGD attack and MOEVA, the best search-based attack. We demonstrate the effectiveness of our attacks on five architectures and four critical use cases. Our empirical study demonstrates that CAA outperforms all existing attacks in 17 over the 20 settings, and leads to a drop in the accuracy by up to 96.1\% points and 21.9\% points compared to CAPGD and MOEVA respectively while being up to five times faster than MOEVA. Given the effectiveness and efficiency of our new attacks, we argue that …
Spotlight Poster
Xi (Nicole) Zhang · Yuan Pu · Yuki Kawamura · Andrew Loza · Yoshua Bengio · Dennis Shung · Alexander Tong
[ East Exhibit Hall A-C ]
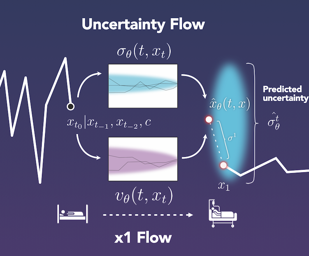
Abstract
Modeling stochastic and irregularly sampled time series is a challenging problem found in a wide range of applications, especially in medicine. Neural stochastic differential equations (Neural SDEs) are an attractive modeling technique for this problem, which parameterize the drift and diffusion terms of an SDE with neural networks. However, current algorithms for training Neural SDEs require backpropagation through the SDE dynamics, greatly limiting their scalability and stability. To address this, we propose **Trajectory Flow Matching** (TFM), which trains a Neural SDE in a *simulation-free* manner, bypassing backpropagation through the dynamics. TFM leverages the flow matching technique from generative modeling to model time series. In this work we first establish necessary conditions for TFM to learn time series data. Next, we present a reparameterization trick which improves training stability. Finally, we adapt TFM to the clinical time series setting, demonstrating improved performance on four clinical time series datasets both in terms of absolute performance and uncertainty prediction, a crucial parameter in this setting.
Spotlight Poster
Rohan Choudhury · Guanglei Zhu · Sihan Liu · Koichiro Niinuma · Kris Kitani · László Jeni
[ West Ballroom A-D ]
Abstract
Video transformers are slow to train due to extremely large numbers of input tokens, even though many video tokens are repeated over time. Existing methods to remove uninformative tokens either have significant overhead, negating any speedup, or require tuning for different datasets and examples. We present Run-Length Tokenization (RLT), a simple approach to speed up video transformers inspired by run-length encoding for data compression. RLT efficiently finds and removes `runs' of patches that are repeated over time before model inference, then replaces them with a single patch and a positional encoding to represent the resulting token's new length. Our method is content-aware, requiring no tuning for different datasets, and fast, incurring negligible overhead. RLT yields a large speedup in training, reducing the wall-clock time to fine-tune a video transformer by 30% while matching baseline model performance. RLT also works without training, increasing model throughput by 35% with only 0.1% drop in accuracy.RLT speeds up training at 30 FPS by more than 100%, and on longer video datasets, can reduce the token count by up to 80\%. Our project page is at rccchoudhury.github.io/projects/rlt.
Spotlight Poster
Jen Ning Lim · Adam Johansen
[ East Exhibit Hall A-C ]
Abstract
Semi-implicit variational inference (SIVI) enriches the expressiveness of variationalfamilies by utilizing a kernel and a mixing distribution to hierarchically define thevariational distribution. Existing SIVI methods parameterize the mixing distributionusing implicit distributions, leading to intractable variational densities. As a result,directly maximizing the evidence lower bound (ELBO) is not possible, so theyresort to one of the following: optimizing bounds on the ELBO, employing costlyinner-loop Markov chain Monte Carlo runs, or solving minimax objectives. In thispaper, we propose a novel method for SIVI called Particle Variational Inference(PVI) which employs empirical measures to approximate the optimal mixingdistributions characterized as the minimizer of a free energy functional. PVI arisesnaturally as a particle approximation of a Euclidean–Wasserstein gradient flow and,unlike prior works, it directly optimizes the ELBO whilst making no parametricassumption about the mixing distribution. Our empirical results demonstrate thatPVI performs favourably compared to other SIVI methods across various tasks.Moreover, we provide a theoretical analysis of the behaviour of the gradient flowof a related free energy functional: establishing the existence and uniqueness ofsolutions as well as propagation of chaos results.
Spotlight Poster
Hamid Kamkari · Brendan Ross · Rasa Hosseinzadeh · Jesse Cresswell · Gabriel Loaiza-Ganem
[ East Exhibit Hall A-C ]

Abstract
High-dimensional data commonly lies on low-dimensional submanifolds, and estimating the local intrinsic dimension (LID) of a datum -- i.e. the dimension of the submanifold it belongs to -- is a longstanding problem. LID can be understood as the number of local factors of variation: the more factors of variation a datum has, the more complex it tends to be. Estimating this quantity has proven useful in contexts ranging from generalization in neural networks to detection of out-of-distribution data, adversarial examples, and AI-generated text. The recent successes of deep generative models present an opportunity to leverage them for LID estimation, but current methods based on generative models produce inaccurate estimates, require more than a single pre-trained model, are computationally intensive, or do not exploit the best available deep generative models: diffusion models (DMs). In this work, we show that the Fokker-Planck equation associated with a DM can provide an LID estimator which addresses the aforementioned deficiencies. Our estimator, called FLIPD, is easy to implement and compatible with all popular DMs. Applying FLIPD to synthetic LID estimation benchmarks, we find that DMs implemented as fully-connected networks are highly effective LID estimators that outperform existing baselines. We also apply FLIPD to natural images …
Spotlight Poster
Bobak Kiani · Jason Wang · Melanie Weber
[ East Exhibit Hall A-C ]
Abstract
The manifold hypothesis presumes that high-dimensional data lies on or near a low-dimensional manifold. While the utility of encoding geometric structure has been demonstrated empirically, rigorous analysis of its impact on the learnability of neural networks is largely missing. Several recent results have established hardness results for learning feedforward and equivariant neural networks under i.i.d. Gaussian or uniform Boolean data distributions. In this paper, we investigate the hardness of learning under the manifold hypothesis. We ask, which minimal assumptions on the curvature and regularity of the manifold, if any, render the learning problem efficiently learnable. We prove that learning is hard under input manifolds of bounded curvature by extending proofs of hardness in the SQ and cryptographic settings for boolean data inputs to the geometric setting. On the other hand, we show that additional assumptions on the volume of the data manifold alleviate these fundamental limitations and guarantee learnability via a simple interpolation argument. Notable instances of this regime are manifolds which can be reliably reconstructed via manifold learning. Looking forward, we comment on and empirically explore intermediate regimes of manifolds, which have heterogeneous features commonly found in real world data.
Spotlight Poster
Stephen Pasteris · Chris Hicks · Vasilios Mavroudis · Mark Herbster
[ West Ballroom A-D ]
Abstract
We consider the classic problem of online convex optimisation. Whereas the notion of static regret is relevant for stationary problems, the notion of switching regret is more appropriate for non-stationary problems. A switching regret is defined relative to any segmentation of the trial sequence, and is equal to the sum of the static regrets of each segment. In this paper we show that, perhaps surprisingly, we can achieve the asymptotically optimal switching regret on every possible segmentation simultaneously. Our algorithm for doing so is very efficient: having a space and per-trial time complexity that is logarithmic in the time-horizon. Our algorithm also obtains novel bounds on its dynamic regret: being adaptive to variations in the rate of change of the comparator sequence.
Spotlight Poster
Xingyi Cheng · Bo Chen · Pan Li · Jing Gong · Jie Tang · Le Song
[ East Exhibit Hall A-C ]

Abstract
We explore optimally training protein language models, an area of significant interest in biological research where guidance on best practices is limited.Most models are trained with extensive compute resources until performance gains plateau, focusing primarily on increasing model sizes rather than optimizing the efficient compute frontier that balances performance and compute budgets.Our investigation is grounded in a massive dataset consisting of 939 million protein sequences. We trained over 300 models ranging from 3.5 million to 10.7 billion parameters on 5 to 200 billion unique tokens, to investigate the relations between model sizes, training token numbers, and objectives.First, we observed the effect of diminishing returns for the Causal Language Model (CLM) and that of overfitting for Masked Language Model (MLM) when repeating the commonly used Uniref database. To address this, we included metagenomic protein sequences in the training set to increase the diversity and avoid the plateau or overfitting effects. Second, we obtained the scaling laws of CLM and MLM on Transformer, tailored to the specific characteristics of protein sequence data. Third, we observe a transfer scaling phenomenon from CLM to MLM, further demonstrating the effectiveness of transfer through scaling behaviors based on estimated Effectively Transferred Tokens.Finally, to validate our scaling …
Spotlight Poster
Hanwei Zhu · Haoning Wu · Yixuan Li · Zicheng Zhang · Baoliang Chen · Lingyu Zhu · Yuming Fang · Guangtao Zhai · Weisi Lin · Shiqi Wang
[ East Exhibit Hall A-C ]
Abstract
While recent advancements in large multimodal models (LMMs) have significantly improved their abilities in image quality assessment (IQA) relying on absolute quality rating, how to transfer reliable relative quality comparison outputs to continuous perceptual quality scores remains largely unexplored. To address this gap, we introduce an all-around LMM-based NR-IQA model, which is capable of producing qualitatively comparative responses and effectively translating these discrete comparison outcomes into a continuous quality score. Specifically, during training, we present to generate scaled-up comparative instructions by comparing images from the same IQA dataset, allowing for more flexible integration of diverse IQA datasets. Utilizing the established large-scale training corpus, we develop a human-like visual quality comparator. During inference, moving beyond binary choices, we propose a soft comparison method that calculates the likelihood of the test image being preferred over multiple predefined anchor images. The quality score is further optimized by maximum a posteriori estimation with the resulting probability matrix. Extensive experiments on nine IQA datasets validate that the Compare2Score effectively bridges text-defined comparative levels during training with converted single image quality scores for inference, surpassing state-of-the-art IQA models across diverse scenarios. Moreover, we verify that the probability-matrix-based inference conversion not only improves the rating accuracy of …
Spotlight Poster
Dustin Wright · Christian Igel · Raghavendra Selvan
[ East Exhibit Hall A-C ]
Abstract
Modern neural networks are often massively overparameterized leading to high compute costs during training and at inference. One effective method to improve both the compute and energy efficiency of neural networks while maintaining good performance is structured pruning, where full network structures (e.g. neurons or convolutional filters) that have limited impact on the model output are removed. In this work, we propose Bayesian Model Reduction for Structured pruning (BMRS), a fully end-to-end Bayesian method of structured pruning. BMRS is based on two recent methods: Bayesian structured pruning with multiplicative noise, and Bayesian model reduction (BMR), a method which allows efficient comparison of Bayesian models under a change in prior. We present two realizations of BMRS derived from different priors which yield different structured pruning characteristics: 1) BMRS_N with the truncated log-normal prior, which offers reliable compression rates and accuracy without the need for tuning any thresholds and 2) BMRS_U with the truncated log-uniform prior that can achieve more aggressive compression based on the boundaries of truncation. Overall, we find that BMRS offers a theoretically grounded approach to structured pruning of neural networks yielding both high compression rates and accuracy. Experiments on multiple datasets and neural networks of varying complexity showed …
Spotlight Poster
Zhengxuan Wu · Aryaman Arora · Zheng Wang · Atticus Geiger · Dan Jurafsky · Christopher D Manning · Christopher Potts
[ West Ballroom A-D ]
Abstract
Parameter-efficient finetuning (PEFT) methods seek to adapt large neural models via updates to a small number of *weights*. However, much prior interpretability work has shown that *representations* encode rich semantic information, suggesting that editing representations might be a more powerful alternative. We pursue this hypothesis by developing a family of **Representation Finetuning (ReFT)** methods. ReFT methods operate on a frozen base model and learn task-specific interventions on hidden representations. We define a strong instance of the ReFT family, Low-rank Linear Subspace ReFT (LoReFT), and we identify an ablation of this method that trades some performance for increased efficiency. Both are drop-in replacements for existing PEFTs and learn interventions that are 15x--65x more parameter-efficient than LoRA. We showcase LoReFT on eight commonsense reasoning tasks, four arithmetic reasoning tasks, instruction-tuning, and GLUE. In all these evaluations, our ReFTs deliver the best balance of efficiency and performance, and almost always outperform state-of-the-art PEFTs. Upon publication, we will publicly release our generic ReFT training library.
Spotlight Poster
Jinliang Deng · Feiyang Ye · Du Yin · Xuan Song · Ivor Tsang · Hui Xiong
[ East Exhibit Hall A-C ]
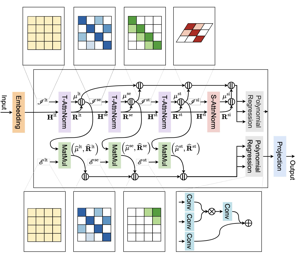
Abstract
Long-term time series forecasting (LTSF) represents a critical frontier in time series analysis, characterized by extensive input sequences, as opposed to the shorter spans typical of traditional approaches. While longer sequences inherently offer richer information for enhanced predictive precision, prevailing studies often respond by escalating model complexity. These intricate models can inflate into millions of parameters, resulting in prohibitive parameter scales. Our study demonstrates, through both theoretical and empirical evidence, that decomposition is key to containing excessive model inflation while achieving uniformly superior and robust results across various datasets. Remarkably, by tailoring decomposition to the intrinsic dynamics of time series data, our proposed model outperforms existing benchmarks, using over 99\% fewer parameters than the majority of competing methods. Through this work, we aim to unleash the power of a restricted set of parameters by capitalizing on domain characteristics—a timely reminder that in the realm of LTSF, bigger is not invariably better. The code is available at \url{https://anonymous.4open.science/r/SSCNN-321D/}.
Spotlight Poster
Kun Yan · Zeyu Wang · Lei Ji · Yuntao Wang · Nan Duan · Shuai Ma
[ East Exhibit Hall A-C ]
Abstract
In recent years, the integration of vision and language understanding has led to significant advancements in artificial intelligence, particularly through Vision-Language Models (VLMs). However, existing VLMs face challenges in handling real-world applications with complex scenes and multiple objects, as well as aligning their focus with the diverse attention patterns of human users. In this paper, we introduce gaze information, feasibly collected by ubiquitous wearable devices such as MR glasses, as a proxy for human attention to guide VLMs. We propose a novel approach, Voila-A, for gaze alignment to enhance the effectiveness of these models in real-world applications. First, we collect hundreds of minutes of gaze data to demonstrate that we can mimic human gaze modalities using localized narratives. We then design an automatic data annotation pipeline utilizing GPT-4 to generate the VOILA-COCO dataset. Additionally, we introduce a new model VOILA-A that integrate gaze information into VLMs while maintain pretrained knowledge from webscale dataset. We evaluate Voila-A using a hold-out validation set and a newly collected VOILA-GAZE testset, which features real-life scenarios captured with a gaze-tracking device. Our experimental results demonstrate that Voila-A significantly outperforms several baseline models. By aligning model attention with human gaze patterns, Voila-A paves the way for …
Spotlight Poster
Reza Ebrahimi · Jun Chen · Ashish Khisti
[ West Ballroom A-D ]

Abstract
This paper investigates a novel lossy compression framework operating under logarithmic loss, designed to handle situations where the reconstruction distribution diverges from the source distribution. This framework is especially relevant for applications that require joint compression and retrieval, and in scenarios involving distributional shifts due to processing. We show that the proposed formulation extends the classical minimum entropy coupling framework by integrating a bottleneck, allowing for controlled variability in the degree of stochasticity in the coupling.We explore the decomposition of the Minimum Entropy Coupling with Bottleneck (MEC-B) into two distinct optimization problems: Entropy-Bounded Information Maximization (EBIM) for the encoder, and Minimum Entropy Coupling (MEC) for the decoder. Through extensive analysis, we provide a greedy algorithm for EBIM with guaranteed performance, and characterize the optimal solution near functional mappings, yielding significant theoretical insights into the structural complexity of this problem.Furthermore, we illustrated the practical application of MEC-B through experiments in Markov Coding Games (MCGs) under rate limits. These games simulate a communication scenario within a Markov Decision Process, where an agent must transmit a compressed message from a sender to a receiver through its actions. Our experiments highlighted the trade-offs between MDP rewards and receiver accuracy across various compression rates, showcasing …
Spotlight Poster
Tianyi (Alex) Qiu · Yang Zhang · Xuchuan Huang · Jasmine Li · Jiaming Ji · Yaodong Yang
[ East Exhibit Hall A-C ]
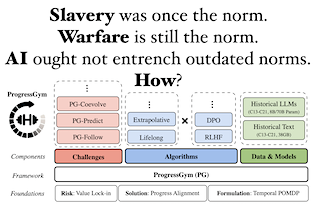
Abstract
Frontier AI systems, including large language models (LLMs), hold increasing influence over the epistemology of human users. Such influence can reinforce prevailing societal values, potentially contributing to the lock-in of misguided moral beliefs and, consequently, the perpetuation of problematic moral practices on a broad scale. We introduce **progress alignment** as a technical solution to mitigate this imminent risk. Progress alignment algorithms learn to emulate the mechanics of human moral progress, thereby addressing the susceptibility of existing alignment methods to contemporary moral blindspots. To empower research in progress alignment, we introduce [**ProgressGym**](https://github.com/PKU-Alignment/ProgressGym), an experimental framework allowing the learning of moral progress mechanics from history, in order to facilitate future progress in real-world moral decisions. Leveraging 9 centuries of historical text and 18 [historical LLMs](https://huggingface.co/collections/PKU-Alignment/progressgym-666735fcf3e4efa276226eaa), ProgressGym enables codification of real-world progress alignment challenges into concrete benchmarks. Specifically, we introduce three core challenges: tracking evolving values (PG-Follow), preemptively anticipating moral progress (PG-Predict), and regulating the feedback loop between human and AI value shifts (PG-Coevolve). Alignment methods without a temporal dimension are inapplicable to these tasks. In response, we present *lifelong* and *extrapolative* algorithms as baseline methods of progress alignment, and build an [open leaderboard](https://huggingface.co/spaces/PKU-Alignment/ProgressGym-LeaderBoard) soliciting novel algorithms and challenges.
Spotlight Poster
Yan Sun · Li Shen · Dacheng Tao
[ East Exhibit Hall A-C ]

Abstract
As a popular paradigm for juggling data privacy and collaborative training, federated learning (FL) is flourishing to distributively process the large scale of heterogeneous datasets on edged clients. Due to bandwidth limitations and security considerations, it ingeniously splits the original problem into multiple subproblems to be solved in parallel, which empowers primal dual solutions to great application values in FL. In this paper, we review the recent development of classical federated primal dual methods and point out a serious common defect of such methods in non-convex scenarios, which we say is a ``dual drift'' caused by dual hysteresis of those longstanding inactive clients under partial participation training. To further address this problem, we propose a novel Aligned Federated Primal Dual (A-FedPD) method, which constructs virtual dual updates to align global consensus and local dual variables for those protracted unparticipated local clients. Meanwhile, we provide a comprehensive analysis of the optimization and generalization efficiency for the A-FedPD method on smooth non-convex objectives, which confirms its high efficiency and practicality. Extensive experiments are conducted on several classical FL setups to validate the effectiveness of our proposed method.
Spotlight Poster
Yunbum Kook · Santosh Vempala · Matthew Zhang
[ West Ballroom A-D ]
Abstract
We present a new random walk for uniformly sampling high-dimensional convex bodies. It achieves state-of-the-art runtime complexity with stronger guarantees on the output than previously known, namely in Rényi divergence (which implies TV, $\mathcal{W}_2$, KL, $\chi^2$). The proof departs from known approaches for polytime algorithms for the problem - we utilize a stochastic diffusion perspective to show contraction to the target distribution with the rate of convergence determined by functional isoperimetric constants of the stationary density.
Spotlight Poster
Zhe Zhao · HaiBin Wen · Zikang Wang · Pengkun Wang · Fanfu Wang · Song Lai · Qingfu Zhang · Yang Wang
[ West Ballroom A-D ]
Abstract
Traditional long-tailed learning methods often perform poorly when dealing with inconsistencies between training and test data distributions, and they cannot flexibly adapt to different user preferences for trade-offs between head and tail classes. To address this issue, we propose a novel long-tailed learning paradigm that aims to tackle distribution shift in real-world scenarios and accommodate different user preferences for the trade-off between head and tail classes. We generate a set of diverse expert models via hypernetworks to cover all possible distribution scenarios, and optimize the model ensemble to adapt to any test distribution. Crucially, in any distribution scenario, we can flexibly output a dedicated model solution that matches the user's preference. Extensive experiments demonstrate that our method not only achieves higher performance ceilings but also effectively overcomes distribution shift while allowing controllable adjustments according to user preferences. We provide new insights and a paradigm for the long-tailed learning problem, greatly expanding its applicability in practical scenarios. The code can be found here: https://github.com/DataLab-atom/PRL.
Spotlight Poster
Peter Jansen · Marc-Alexandre Côté · Tushar Khot · Erin Bransom · Bhavana Dalvi Mishra · Bodhisattwa Prasad Majumder · Oyvind Tafjord · Peter Clark
[ West Ballroom A-D ]

Abstract
Automated scientific discovery promises to accelerate progress across scientific domains, but evaluating an agent's capacity for end-to-end scientific reasoning is challenging as running real-world experiments is often prohibitively expensive or infeasible. In this work we introduce DiscoveryWorld, a virtual environment that enables benchmarking an agent's ability to perform complete cycles of novel scientific discovery in an inexpensive, simulated, multi-modal, long-horizon, and fictional setting.DiscoveryWorld consists of 24 scientific tasks across three levels of difficulty, each with parametric variations that provide new discoveries for agents to make across runs. Tasks require an agent to form hypotheses, design and run experiments, analyze results, and act on conclusions. Task difficulties are normed to range from straightforward to challenging for human scientists with advanced degrees. DiscoveryWorld further provides three automatic metrics for evaluating performance, including: (1) binary task completion, (2) fine-grained report cards detailing procedural scoring of task-relevant actions, and (3) the accuracy of discovered explanatory knowledge.While simulated environments such as DiscoveryWorld are low-fidelity compared to the real world, we find that strong baseline agents struggle on most DiscoveryWorld tasks, highlighting the utility of using simulated environments as proxy tasks for near-term development of scientific discovery competency in agents.
Spotlight Poster
Jacob Silberg · Kyle Swanson · Elana Simon · Angela Zhang · Zaniar Ghazizadeh · Scott Ogden · Hisham Hamadeh · James Zou
[ East Exhibit Hall A-C ]
Abstract
Drug-induced toxicity is one of the leading reasons new drugs fail clinical trials. Machine learning models that predict drug toxicity from molecular structure could help researchers prioritize less toxic drug candidates. However, current toxicity datasets are typically small and limited to a single organ system (e.g., cardio, renal, or liver). Creating these datasets often involved time-intensive expert curation by parsing drug labelling documents that can exceed 100 pages per drug. Here, we introduce UniTox, a unified dataset of 2,418 FDA-approved drugs with drug-induced toxicity summaries and ratings created by using GPT-4o to process FDA drug labels. UniTox spans eight types of toxicity: cardiotoxicity, liver toxicity, renal toxicity, pulmonary toxicity, hematological toxicity, dermatological toxicity, ototoxicity, and infertility. This is, to the best of our knowledge, the largest such systematic human in vivo database by number of drugs and toxicities, and the first covering nearly all non-combination FDA-approved medications for several of these toxicities. We recruited clinicians to validate a random sample of our GPT-4o annotated toxicities, and UniTox's toxicity ratings concord with clinician labelers 85-96\% of the time. Finally, we benchmark several machine learning models trained on UniTox to demonstrate the utility of this dataset for building molecular toxicity prediction models.
Spotlight Poster
Yangjun Ruan · Chris Maddison · Tatsunori Hashimoto
[ East Exhibit Hall A-C ]
Abstract
Understanding how language model performance varies with scale is critical to benchmark and algorithm development. Scaling laws are one approach to building this understanding, but the requirement of training models across many different scales has limited their use. We propose an alternative, observational approach that bypasses model training and instead builds scaling laws from ~100 publically available models. Building a single scaling law from multiple model families is challenging due to large variations in their training compute efficiencies and capabilities. However, we show that these variations are consistent with a simple, generalized scaling law where language model performance is a function of a low-dimensional capability space, and model families only vary in their efficiency in converting training compute to capabilities. Using this approach, we show the surprising predictability of complex scaling phenomena: we show that several emergent phenomena follow a smooth, sigmoidal behavior and are predictable from small models; we show that the agent performance of models such as GPT-4 can be precisely predicted from simpler non-agentic benchmarks; and we show how to predict the impact of post-training interventions like Chain-of-Thought and Self-Consistency as language model capabilities continue to improve.
Spotlight Poster
Jio Oh · Soyeon Kim · Junseok Seo · Jindong Wang · Ruochen Xu · Xing Xie · Steven Whang
[ West Ballroom A-D ]
Abstract
Large language models (LLMs) have achieved unprecedented performances in various applications, yet evaluating them is still challenging. Existing benchmarks are either manually constructed or are automatic, but lack the ability to evaluate the thought process of LLMs with arbitrary complexity. We contend that utilizing existing relational databases based on the entity-relationship (ER) model is a promising approach for constructing benchmarks as they contain structured knowledge that can be used to question LLMs. Unlike knowledge graphs, which are also used to evaluate LLMs, relational databases have integrity constraints that can be used to better construct complex in-depth questions and verify answers: (1) functional dependencies can be used to pinpoint critical keywords that an LLM must know to properly answer a given question containing certain attribute values; and (2) foreign key constraints can be used to join relations and construct multi-hop questions, which can be arbitrarily long and used to debug intermediate answers. We thus propose ERBench, which uses these integrity constraints to convert any database into an LLM benchmark. ERBench supports continuous evaluation as databases change, multimodal questions, and various prompt engineering techniques. In our experiments, we construct LLM benchmarks using databases of multiple domains and make an extensive comparison of …
Spotlight Poster
Zeyu Wang · Xiyuxing Zhang · Ruotong Yu · Yuntao Wang · Kenneth Christofferson · Jingru Zhang · Alex Mariakakis · Yuanchun Shi
[ West Ballroom A-D ]
Abstract
Poor quality sleep can be characterized by the occurrence of events ranging from body movement to breathing impairment. Widely available earbuds equipped with sensors (also known as earables) can be combined with a sleep event detection algorithm to offer a convenient alternative to laborious clinical tests for individuals suffering from sleep disorders. Although various solutions utilizing such devices have been proposed to detect sleep events, they ignore the fact that individuals often share sleeping spaces with roommates or couples. To address this issue, we introduce DreamCatcher, the first publicly available dataset for wearer-aware sleep event algorithm development on earables. DreamCatcher encompasses eight distinct sleep events, including synchronous dual-channel audio and motion data collected from 12 pairs (24 participants) totaling 210 hours (420 hour.person) with fine-grained label. We tested multiple benchmark models on three tasks related to sleep event detection, demonstrating the usability and unique challenge of DreamCatcher. We hope that the proposed DreamCatcher can inspire other researchers to further explore efficient wearer-aware human vocal activity sensing on earables. DreamCatcher is publicly available at https://github.com/thuhci/DreamCatcher.
Spotlight Poster
Lingbing Guo · Zhongpu Bo · Zhuo Chen · Yichi Zhang · Jiaoyan Chen · Lan Yarong · Mengshu Sun · Zhiqiang Zhang · Yangyifei Luo · Qian Li · Qiang Zhang · Wen Zhang · Huajun Chen
[ East Exhibit Hall A-C ]

Abstract
Large language models (LLMs) have significantly advanced performance across a spectrum of natural language processing (NLP) tasks. Yet, their application to knowledge graphs (KGs), which describe facts in the form of triplets and allow minimal hallucinations, remains an underexplored frontier. In this paper, we investigate the integration of LLMs with KGs by introducing a specialized KG Language (KGL), where a sentence precisely consists of an entity noun, a relation verb, and ends with another entity noun. Despite KGL's unfamiliar vocabulary to the LLM, we facilitate its learning through a tailored dictionary and illustrative sentences, and enhance context understanding via real-time KG context retrieval and KGL token embedding augmentation. Our results reveal that LLMs can achieve fluency in KGL, drastically reducing errors compared to conventional KG embedding methods on KG completion. Furthermore, our enhanced LLM shows exceptional competence in generating accurate three-word sentences from an initial entity and interpreting new unseen terms out of KGs.
Spotlight Poster
Kang Chen · Shiyan Chen · Jiyuan Zhang · Baoyue Zhang · Yajing Zheng · Tiejun Huang · Zhaofei Yu
[ East Exhibit Hall A-C ]
Abstract
Reconstructing a sequence of sharp images from the blurry input is crucial for enhancing our insights into the captured scene and poses a significant challenge due to the limited temporal features embedded in the image. Spike cameras, sampling at rates up to 40,000 Hz, have proven effective in capturing motion features and beneficial for solving this ill-posed problem. Nonetheless, existing methods fall into the supervised learning paradigm, which suffers from notable performance degradation when applied to real-world scenarios that diverge from the synthetic training data domain. To address these challenges, we propose the first self-supervised framework for the task of spike-guided motion deblurring. Our approach begins with the formulation of a spike-guided deblurring model that explores the theoretical relationships among spike streams, blurry images, and their corresponding sharp sequences. We subsequently develop a self-supervised cascaded framework to alleviate the issues of spike noise and spatial-resolution mismatching encountered in the deblurring model. With knowledge distillation and re-blurring loss, we further design a lightweight deblur network to generate high-quality sequences with brightness and texture consistency with the original input. Quantitative and qualitative experiments conducted on our real-world and synthetic datasets with spikes validate the superior generalization of the proposed framework. Our code, …
Spotlight Poster
Tomer Porian · Mitchell Wortsman · Jenia Jitsev · Ludwig Schmidt · Yair Carmon
[ East Exhibit Hall A-C ]
Abstract
Kaplan et al. and Hoffmann et al. developed influential scaling laws for the optimal model size as a function of the compute budget, but these laws yield substantially different predictions. We explain the discrepancy by reproducing the Kaplan scaling law on two datasets (OpenWebText2 and RefinedWeb) and identifying three factors causing the difference: last layer computational cost, warmup duration, and scale-dependent optimizer tuning. With these factors corrected, we obtain excellent agreement with the Hoffmann et al. (i.e., "Chinchilla") scaling law. Counter to a hypothesis of Hoffmann et al., we find that careful learning rate decay is not essential for the validity of their scaling law. As a secondary result, we derive scaling laws for the optimal learning rate and batch size, finding that tuning the AdamW $\beta_2$ parameter is essential at lower batch sizes.
Spotlight Poster
Ayush Sawarni · Nirjhar Das · Siddharth Barman · Gaurav Sinha
[ West Ballroom A-D ]
Abstract
We study the generalized linear contextual bandit problem within the constraints of limited adaptivity. In this paper, we present two algorithms, B-GLinCB and RS-GLinCB, that address, respectively, two prevalent limited adaptivity settings. Given a budget $M$ on the number of policy updates, in the first setting, the algorithm needs to decide upfront $M$ rounds at which it will update its policy, while in the second setting it can adaptively perform $M$ policy updates during its course. For the first setting, we design an algorithm B-GLinCB, that incurs $\tilde{O}(\sqrt{T})$ regret when $M = \Omega( \log{\log T} )$ and the arm feature vectors are generated stochastically. For the second setting, we design an algorithm RS-GLinCB that updates its policy $\tilde{O}(\log^2 T)$ times and achieves a regret of $\tilde{O}(\sqrt{T})$ even when the arm feature vectors are adversarially generated. Notably, in these bounds, we manage to eliminate the dependence on a key instance dependent parameter $\kappa$, that captures non-linearity of the underlying reward model. Our novel approach for removing this dependence for generalized linear contextual bandits might be of independent interest.
Spotlight Poster
Yicheng Xiao · Lin Song · shaoli huang · Jiangshan Wang · Siyu Song · Yixiao Ge · Xiu Li · Ying Shan
[ East Exhibit Hall A-C ]
Abstract
The state space models, employing recursively propagated features, demonstrate strong representation capabilities comparable to Transformer models and superior efficiency.However, constrained by the inherent geometric constraints of sequences, it still falls short in modeling long-range dependencies.To address this issue, we propose the MambaTree network, which first dynamically generates a tree topology based on spatial relationships and input features.Then, feature propagation is performed based on this graph, thereby breaking the original sequence constraints to achieve stronger representation capabilities.Additionally, we introduce a linear complexity dynamic programming algorithm to enhance long-range interactions without increasing computational cost.MambaTree is a versatile multimodal framework that can be applied to both visual and textual tasks.Extensive experiments demonstrate that our method significantly outperforms existing structured state space models on image classification, object detection and segmentation.Besides, by fine-tuning large language models, our approach achieves consistent improvements in multiple textual tasks at minor training cost.
Spotlight Poster
Derui Zhu · Dingfan Chen · Xiongfei Wu · Jiahui Geng · Zhuo Li · Jens Grossklags · Lei Ma
[ East Exhibit Hall A-C ]
Abstract
Large Language Models (LLMs) are recognized for their potential to be an important building block toward achieving artificial general intelligence due to their unprecedented capability for solving diverse tasks. Despite these achievements, LLMs often underperform in domain-specific tasks without training on relevant domain data. This phenomenon, which is often attributed to distribution shifts, makes adapting pre-trained LLMs with domain-specific data crucial. However, this adaptation raises significant privacy concerns, especially when the data involved come from sensitive domains. In this work, we extensively investigate the privacy vulnerabilities of adapted (fine-tuned) LLMs and benchmark privacy leakage across a wide range of data modalities, state-of-the-art privacy attack methods, adaptation techniques, and model architectures. We systematically evaluate and pinpoint critical factors related to privacy leakage. With our organized codebase and actionable insights, we aim to provide a standardized auditing tool for practitioners seeking to deploy customized LLM applications with faithful privacy assessments.
Spotlight Poster
Junghyuk Yeom · Yonghyeon Jo · Jeongmo Kim · Sanghyeon Lee · Seungyul Han
[ West Ballroom A-D ]
Abstract
Constraint-based offline reinforcement learning (RL) involves policy constraints or imposing penalties on the value function to mitigate overestimation errors caused by distributional shift. This paper focuses on a limitation in existing offline RL methods with penalized value function, indicating the potential for underestimation bias due to unnecessary bias introduced in the value function. To address this concern, we propose Exclusively Penalized Q-learning (EPQ), which reduces estimation bias in the value function by selectively penalizing states that are prone to inducing estimation errors. Numerical results show that our method significantly reduces underestimation bias and improves performance in various offline control tasks compared to other offline RL methods.
Spotlight Poster
Wei Li · Hehe Fan · Yongkang Wong · Mohan Kankanhalli · Yi Yang
[ West Ballroom A-D ]
Abstract
Recent advancements in image understanding have benefited from the extensive use of web image-text pairs. However, video understanding remains a challenge despite the availability of substantial web video-text data. This difficulty primarily arises from the inherent complexity of videos and the inefficient language supervision in recent web-collected video-text datasets. In this paper, we introduce Text-Only Pre-Alignment (TOPA), a novel approach to extend large language models (LLMs) for video understanding, without the need for pre-training on real video data. Specifically, we first employ an advanced LLM to automatically generate Textual Videos comprising continuous textual frames, along with corresponding annotations to simulate real video-text data. Then, these annotated textual videos are used to pre-align a language-only LLM with the video modality. To bridge the gap between textual and real videos, we employ the CLIP model as the feature extractor to align image and text modalities. During text-only pre-alignment, the continuous textual frames, encoded as a sequence of CLIP text features, are analogous to continuous CLIP image features, thus aligning the LLM with real video representation. Extensive experiments, including zero-shot evaluation and finetuning on various video understanding tasks, demonstrate that TOPA is an effective and efficient framework for aligning video content with LLMs. …
Spotlight Poster
Sukwon Yun · Inyoung Choi · Jie Peng · Yangfan Wu · Jingxuan Bao · Qiyiwen Zhang · Jiayi Xin · Qi Long · Tianlong Chen
[ West Ballroom A-D ]
Abstract
Multimodal learning has gained increasing importance across various fields, offering the ability to integrate data from diverse sources such as images, text, and personalized records, which are frequently observed in medical domains. However, in scenarios where some modalities are missing, many existing frameworks struggle to accommodate arbitrary modality combinations, often relying heavily on a single modality or complete data. This oversight of potential modality combinations limits their applicability in real-world situations. To address this challenge, we propose Flex-MoE (Flexible Mixture-of-Experts), a new framework designed to flexibly incorporate arbitrary modality combinations while maintaining robustness to missing data. The core idea of Flex-MoE is to first address missing modalities using a new missing modality bank that integrates observed modality combinations with the corresponding missing ones. This is followed by a uniquely designed Sparse MoE framework. Specifically, Flex-MoE first trains experts using samples with all modalities to inject generalized knowledge through the generalized router ($\mathcal{G}$-Router). The $\mathcal{S}$-Router then specializes in handling fewer modality combinations by assigning the top-1 gate to the expert corresponding to the observed modality combination. We evaluate Flex-MoE on the ADNI dataset, which encompasses four modalities in the Alzheimer's Disease domain, as well as on the MIMIC-IV dataset. The results …
Spotlight Poster
Qiang Wu · Gechang Yao · Zhixi Feng · Yang Shuyuan
[ East Exhibit Hall A-C ]
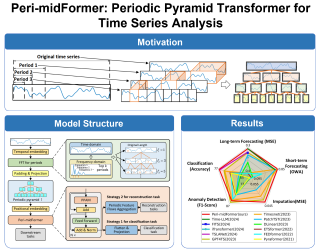
Abstract
Time series analysis finds wide applications in fields such as weather forecasting, anomaly detection, and behavior recognition. Previous methods attempted to model temporal variations directly using 1D time series. However, this has been quite challenging due to the discrete nature of data points in time series and the complexity of periodic variation. In terms of periodicity, taking weather and traffic data as an example, there are multi-periodic variations such as yearly, monthly, weekly, and daily, etc. In order to break through the limitations of the previous methods, we decouple the implied complex periodic variations into inclusion and overlap relationships among different level periodic components based on the observation of the multi-periodicity therein and its inclusion relationships. This explicitly represents the naturally occurring pyramid-like properties in time series, where the top level is the original time series and lower levels consist of periodic components with gradually shorter periods, which we call the periodic pyramid. To further extract complex temporal variations, we introduce self-attention mechanism into the periodic pyramid, capturing complex periodic relationships by computing attention between periodic components based on their inclusion, overlap, and adjacency relationships. Our proposed Peri-midFormer demonstrates outstanding performance in five mainstream time series analysis tasks, including short- …
Spotlight Poster
Yao Lai · Jinxin Liu · David Z. Pan · Ping Luo
[ East Exhibit Hall A-C ]
Abstract
Across a wide range of hardware scenarios, the computational efficiency and physical size of the arithmetic units significantly influence the speed and footprint of the overall hardware system. Nevertheless, the effectiveness of prior arithmetic design techniques proves inadequate, as they do not sufficiently optimize speed and area, resulting in increased latency and larger module size. To boost computing performance, this work focuses on the two most common and fundamental arithmetic modules, adders and multipliers. We cast the design tasks as single-player tree generation games, leveraging reinforcement learning techniques to optimize their arithmetic tree structures. This tree generation formulation allows us to efficiently navigate the vast search space and discover superior arithmetic designs that improve computational efficiency and hardware size within just a few hours. Our proposed method, **ArithTreeRL**, achieves significant improvements for both adders and multipliers. For adders, our approach discovers designs of 128-bit adders that achieve Pareto optimality in theoretical metrics. Compared with PrefixRL, it reduces delay and size by up to 26% and 30%, respectively. For multipliers, compared to RL-MUL, our method enhances speed and reduces size by as much as 49% and 45%. Additionally, ArithTreeRL's flexibility and scalability enable seamless integration into 7nm technology. We believe our …
Spotlight Poster
Zak Mhammedi · Dylan J Foster · Alexander Rakhlin
[ West Ballroom A-D ]
Abstract
Simulators are a pervasive tool in reinforcement learning, but most existing algorithms cannot efficiently exploit simulator access -- particularly in high-dimensional domains that require general function approximation. We explore the power of simulators through online reinforcement learning with local simulator access (or, local planning), an RL protocol where the agent is allowed to reset to previously observed states and follow their dynamics during training. We use local simulator access to unlock new statistical guarantees that were previously out of reach:- We show that MDPs with low coverability (Xie et al. 2023) -- a general structural condition that subsumes Block MDPs and Low-Rank MDPs -- can be learned in a sample-efficient fashion with only Q⋆-realizability (realizability of the optimal state-value function); existing online RL algorithms require significantly stronger representation conditions.- As a consequence, we show that the notorious Exogenous Block MDP problem (Efroni et al. 2022) is tractable under local simulator access.The results above are achieved through a computationally inefficient algorithm. We complement them with a more computationally efficient algorithm, RVFS (Recursive Value Function Search), which achieves provable sample complexity guarantees under a strengthened statistical assumption known as pushforward coverability. RVFS can be viewed as a principled, provable counterpart to a …
Spotlight Poster
Yi-Fan Zhang · Min-Ling Zhang
[ East Exhibit Hall A-C ]
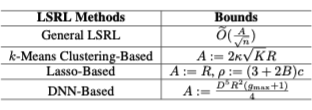
Abstract
Label-specific representation learning (LSRL), i.e., constructing the representation with specific discriminative properties for each class label, is an effective strategy to improve the performance of multi-label learning. However, the generalization analysis of LSRL is still in its infancy. The existing theory bounds for multi-label learning, which preserve the coupling among different components, are invalid for LSRL. In an attempt to overcome this challenge and make up for the gap in the generalization theory of LSRL, we develop a novel vector-contraction inequality and derive the generalization bound for general function class of LSRL with a weaker dependency on the number of labels than the state of the art. In addition, we derive generalization bounds for typical LSRL methods, and these theoretical results reveal the impact of different label-specific representations on generalization analysis. The mild bounds without strong assumptions explain the good generalization ability of LSRL.
Spotlight Poster
Stephen Boyd · Tetiana Parshakova · Ernest Ryu · Jaewook J. Suh
[ West Ballroom A-D ]
Abstract
We present a novel methodology for convex optimization algorithm design using ideas from electric RLC circuits. Given an optimization problem, the first stage of the methodology is to design an appropriate electric circuit whose continuous-time dynamics converge to the solution of the optimization problem at hand. Then, the second stage is an automated, computer-assisted discretization of the continuous-time dynamics, yielding a provably convergent discrete-time algorithm. Our methodology recovers many classical (distributed) optimization algorithms and enables users to quickly design and explore a wide range of new algorithms with convergence guarantees.
Spotlight Poster
Zhu Yu · Runmin Zhang · Jiacheng Ying · Junchen Yu · Xiaohai Hu · Lun Luo · Si-Yuan Cao · Hui-liang Shen
[ East Exhibit Hall A-C ]

Abstract
Vision-based Semantic Scene Completion (SSC) has gained much attention due to its widespread applications in various 3D perception tasks. Existing sparse-to-dense approaches typically employ shared context-independent queries across various input images, which fails to capture distinctions among them as the focal regions of different inputs vary and may result in undirected feature aggregation of cross-attention. Additionally, the absence of depth information may lead to points projected onto the image plane sharing the same 2D position or similar sampling points in the feature map, resulting in depth ambiguity. In this paper, we present a novel context and geometry aware voxel transformer. It utilizes a context aware query generator to initialize context-dependent queries tailored to individual input images, effectively capturing their unique characteristics and aggregating information within the region of interest. Furthermore, it extend deformable cross-attention from 2D to 3D pixel space, enabling the differentiation of points with similar image coordinates based on their depth coordinates. Building upon this module, we introduce a neural network named CGFormer to achieve semantic scene completion. Simultaneously, CGFormer leverages multiple 3D representations (i.e., voxel and TPV) to boost the semantic and geometric representation abilities of the transformed 3D volume from both local and global perspectives. Experimental …
Spotlight Poster
Yao Ni · Shan Zhang · Piotr Koniusz
[ West Ballroom A-D ]
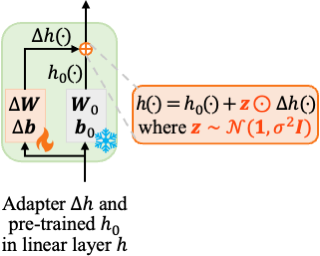
Abstract
Parameter-Efficient Fine-Tuning (PEFT) effectively adapts pre-trained transformers to downstream tasks. However, the optimization of tasks performance often comes at the cost of generalizability in fine-tuned models. To address this issue, we theoretically connect smaller weight gradient norms during training and larger datasets to the improvements in model generalization. Motivated by this connection, we propose reducing gradient norms for enhanced generalization and aligning fine-tuned model with the pre-trained counterpart to retain knowledge from large-scale pre-training data. Yet, naive alignment does not guarantee gradient reduction and can potentially cause gradient explosion, complicating efforts to manage gradients. To address such an issue, we propose PACE, marrying generalization of PArameter-efficient fine-tuning with Consistency rEgularization. We perturb features learned from the adapter with the multiplicative noise and ensure the fine-tuned model remains consistent for same sample under different perturbations. Theoretical analysis shows that PACE not only implicitly regularizes gradients for enhanced generalization, but also implicitly aligns the fine-tuned and pre-trained models to retain knowledge. Experimental evidence supports our theories. PACE surpasses existing PEFT methods in visual adaptation tasks (VTAB-1k, FGVC, few-shot learning, domain adaptation) showcasing its potential for resource-efficient fine-tuning. It also improves LoRA in text classification (GLUE) and mathematical reasoning (GSM-8K).
Spotlight Poster
Tieyuan Chen · Huabin Liu · Tianyao He · Yihang Chen · chaofan gan · Xiao Ma · Cheng Zhong · Yang Zhang · Yingxue Wang · Hui Lin · Weiyao Lin
[ East Exhibit Hall A-C ]

Abstract
Video causal reasoning aims to achieve a high-level understanding of video content from a causal perspective. However, current video reasoning tasks are limited in scope, primarily executed in a question-answering paradigm and focusing on short videos containing only a single event and simple causal relationships, lacking comprehensive and structured causality analysis for videos with multiple events. To fill this gap, we introduce a new task and dataset, Multi-Event Causal Discovery (MECD). It aims to uncover the causal relationships between events distributed chronologically across long videos. Given visual segments and textual descriptions of events, MECD requires identifying the causal associations between these events to derive a comprehensive, structured event-level video causal diagram explaining why and how the final result event occurred. To address MECD, we devise a novel framework inspired by the Granger Causality method, using an efficient mask-based event prediction model to perform an Event Granger Test, which estimates causality by comparing the predicted result event when premise events are masked versus unmasked. Furthermore, we integrate causal inference techniques such as front-door adjustment and counterfactual inference to address challenges in MECD like causality confounding and illusory causality. Experiments validate the effectiveness of our framework in providing causal relationships in multi-event …
Spotlight Poster
Wenyu Du · Tongxu Luo · Zihan Qiu · Zeyu Huang · Yikang Shen · Reynold Cheng · Yike Guo · Jie Fu
[ West Ballroom A-D ]

Abstract
LLMs are computationally expensive to pre-train due to their large scale.Model growth emerges as a promising approach by leveraging smaller models to accelerate the training of larger ones. However, the viability of these model growth methods in efficient LLM pre-training remains underexplored.This work identifies three critical $\underline{\textit{O}}$bstacles: ($\textit{O}$1) lack of comprehensive evaluation, ($\textit{O}$2) untested viability for scaling, and ($\textit{O}$3) lack of empirical guidelines.To tackle $\textit{O}$1, we summarize existing approaches into four atomic growth operators and systematically evaluate them in a standardized LLM pre-training setting.Our findings reveal that a depthwise stacking operator, called $G_{\text{stack}}$, exhibits remarkable acceleration in training, leading to decreased loss and improved overall performance on eight standard NLP benchmarks compared to strong baselines. Motivated by these promising results, we conduct extensive experiments to delve deeper into $G_{\text{stack}}$ to address $\textit{O}$2 and $\textit{O}$3.For $\textit{O}$2 (untested scalability), our study shows that $G_{\text{stack}}$ is scalable and consistently performs well, with experiments up to 7B LLMs after growth and pre-training LLMs with 750B tokens.For example, compared to a conventionally trained 7B model using 300B tokens, our $G_{\text{stack}}$ model converges to the same loss with 194B tokens, resulting in a 54.6\% speedup. We further address $\textit{O}$3 (lack of empirical guidelines) by formalizing guidelines …
Spotlight Poster
Weikang Wan · Ziyu Wang · Yufei Wang · Zackory Erickson · David Held
[ West Ballroom A-D ]
Abstract
This paper introduces DiffTORI, which utilizes $\textbf{Diff}$erentiable $\textbf{T}$rajectory $\textbf{O}$ptimization as the policy representation to generate actions for deep $\textbf{R}$einforcement and $\textbf{I}$mitation learning. Trajectory optimization is a powerful and widely used algorithm in control, parameterized by a cost and a dynamics function. The key to our approach is to leverage the recent progress in differentiable trajectory optimization, which enables computing the gradients of the loss with respect to the parameters of trajectory optimization. As a result, the cost and dynamics functions of trajectory optimization can be learned end-to-end. DiffTORI addresses the “objective mismatch” issue of prior model-based RL algorithms, as the dynamics model in DiffTORI is learned to directly maximize task performance by differentiating the policy gradient loss through the trajectory optimization process. We further benchmark DiffTORI for imitation learning on standard robotic manipulation task suites with high-dimensional sensory observations and compare our method to feedforward policy classes as well as Energy-Based Models (EBM) and Diffusion. Across 15 model based RL tasks and 35 imitation learning tasks with high-dimensional image and point cloud inputs, DiffTORI outperforms prior state-of-the-art methods in both domains.
Spotlight Poster
Apolline Mellot · Antoine Collas · Sylvain Chevallier · Alex Gramfort · Denis Engemann
[ East Exhibit Hall A-C ]
Abstract
Electroencephalography (EEG) data is often collected from diverse contexts involving different populations and EEG devices. This variability can induce distribution shifts in the data $X$ and in the biomedical variables of interest $y$, thus limiting the application of supervised machine learning (ML) algorithms. While domain adaptation (DA) methods have been developed to mitigate the impact of these shifts, such methods struggle when distribution shifts occur simultaneously in $X$ and $y$. As state-of-the-art ML models for EEG represent the data by spatial covariance matrices, which lie on the Riemannian manifold of Symmetric Positive Definite (SPD) matrices, it is appealing to study DA techniques operating on the SPD manifold. This paper proposes a novel method termed Geodesic Optimization for Predictive Shift Adaptation (GOPSA) to address test-time multi-source DA for situations in which source domains have distinct $y$ distributions. GOPSA exploits the geodesic structure of the Riemannian manifold to jointly learn a domain-specific re-centering operator representing site-specific intercepts and the regression model. We performed empirical benchmarks on the cross-site generalization of age-prediction models with resting-state EEG data from a large multi-national dataset (HarMNqEEG), which included $14$ recording sites and more than $1500$ human participants. Compared to state-of-the-art methods, our results showed that GOPSA …
Spotlight Poster
Qiujiang Jin · Ruichen Jiang · Aryan Mokhtari
[ West Ballroom A-D ]
Abstract
In this paper, we present the first explicit and non-asymptotic global convergence rates of the BFGS method when implemented with an inexact line search scheme satisfying the Armijo-Wolfe conditions. We show that BFGS achieves a global linear convergence rate of $(1 - \frac{1}{\kappa})^t$ for $\mu$-strongly convex functions with $L$-Lipschitz gradients, where $\kappa = \frac{L}{\mu}$ represents the condition number. Additionally, if the objective function's Hessian is Lipschitz, BFGS with the Armijo-Wolfe line search achieves a linear convergence rate that depends solely on the line search parameters, independent of the condition number. We also establish a global superlinear convergence rate of $\mathcal{O}((\frac{1}{t})^t)$. These global bounds are all valid for any starting point $x_0$ and any symmetric positive definite initial Hessian approximation matrix $B_0$, though the choice of $B_0$ impacts the number of iterations needed to achieve these rates. By synthesizing these results, we outline the first global complexity characterization of BFGS with the Armijo-Wolfe line search. Additionally, we clearly define a mechanism for selecting the step size to satisfy the Armijo-Wolfe conditions and characterize its overall complexity.
Spotlight Poster
Jeremias Traub · Till Bungert · Carsten Lüth · Michael Baumgartner · Klaus Maier-Hein · Lena Maier-Hein · Paul Jaeger
[ East Exhibit Hall A-C ]

Abstract
Selective Classification, wherein models can reject low-confidence predictions, promises reliable translation of machine-learning based classification systems to real-world scenarios such as clinical diagnostics. While current evaluation of these systems typically assumes fixed working points based on pre-defined rejection thresholds, methodological progress requires benchmarking the general performance of systems akin to the $\mathrm{AUROC}$ in standard classification. In this work, we define 5 requirements for multi-threshold metrics in selective classification regarding task alignment, interpretability, and flexibility, and show how current approaches fail to meet them. We propose the Area under the Generalized Risk Coverage curve ($\mathrm{AUGRC}$), which meets all requirements and can be directly interpreted as the average risk of undetected failures. We empirically demonstrate the relevance of $\mathrm{AUGRC}$ on a comprehensive benchmark spanning 6 data sets and 13 confidence scoring functions. We find that the proposed metric substantially changes metric rankings on 5 out of the 6 data sets.
Spotlight Poster
Ilias Diakonikolas · Lisheng Ren · Nikos Zarifis
[ East Exhibit Hall A-C ]
Abstract
We study the problem of PAC learning halfspaces in the reliable agnostic model of Kalai et al. (2012).The reliable PAC model captures learning scenarios where one type of error is costlier than the others. Our main positive result is a new algorithm for reliable learning of Gaussian halfspaces on $\mathbb{R}^d$ with sample and computational complexity $d^{O(\log (\min\{1/\alpha, 1/\epsilon\}))}\min (2^{\log(1/\epsilon)^{O(\log (1/\alpha))}},2^{\mathrm{poly}(1/\epsilon)})$, where $\epsilon$ is the excess error and $\alpha$ is the bias of the optimal halfspace. We complement our upper bound with a Statistical Query lower bound suggesting that the $d^{\Omega(\log (1/\alpha))}$ dependence is best possible. Conceptually, our results imply a strong computational separation between reliable agnostic learning and standard agnostic learning of halfspaces in the Gaussian setting.
Spotlight Poster
Hoin Jung · Taeuk Jang · Xiaoqian Wang
[ East Exhibit Hall A-C ]
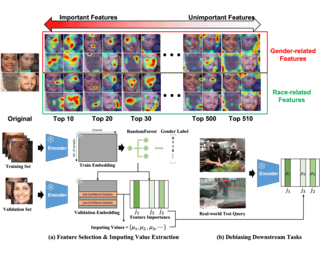
Abstract
Recent advancements in Vision-Language Models (VLMs) have enabled complex multimodal tasks by processing text and image data simultaneously, significantly enhancing the field of artificial intelligence. However, these models often exhibit biases that can skew outputs towards societal stereotypes, thus necessitating debiasing strategies. Existing debiasing methods focus narrowly on specific modalities or tasks, and require extensive retraining. To address these limitations, this paper introduces Selective Feature Imputation for Debiasing (SFID), a novel methodology that integrates feature pruning and low confidence imputation (LCI) to effectively reduce biases in VLMs. SFID is versatile, maintaining the semantic integrity of outputs and costly effective by eliminating the need for retraining. Our experimental results demonstrate SFID's effectiveness across various VLMs tasks including zero-shot classification, text-to-image retrieval, image captioning, and text-to-image generation, by significantly reducing gender biases without compromising performance. This approach not only enhances the fairness of VLMs applications but also preserves their efficiency and utility across diverse scenarios.
Spotlight Poster
Deepak Ravikumar · Efstathia Soufleri · Kaushik Roy
[ East Exhibit Hall A-C ]
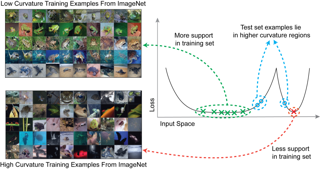
Abstract
In this paper, we explore the properties of loss curvature with respect to input data in deep neural networks. Curvature of loss with respect to input (termed input loss curvature) is the trace of the Hessian of the loss with respect to the input. We investigate how input loss curvature varies between train and test sets, and its implications for train-test distinguishability. We develop a theoretical framework that derives an upper bound on the train-test distinguishability based on privacy and the size of the training set. This novel insight fuels the development of a new black box membership inference attack utilizing input loss curvature. We validate our theoretical findings through experiments in computer vision classification tasks, demonstrating that input loss curvature surpasses existing methods in membership inference effectiveness. Our analysis highlights how the performance of membership inference attack (MIA) methods varies with the size of the training set, showing that curvature-based MIA outperforms other methods on sufficiently large datasets. This condition is often met by real datasets, as demonstrated by our results on CIFAR10, CIFAR100, and ImageNet. These findings not only advance our understanding of deep neural network behavior but also improve the ability to test privacy-preserving techniques in machine …
Spotlight Poster
Jiangyuan Li · Jiayi Wang · Raymond K. W. Wong · Kwun Chuen Gary Chan
[ East Exhibit Hall A-C ]
Abstract
While several recent matrix completion methods are developed to deal with non-uniform observation probabilities across matrix entries, very few allow the missingness to depend on the mostly unobserved matrix measurements, which is generally ill-posed. We aim to tackle a subclass of these ill-posed settings, characterized by a flexible separable observation probability assumption that can depend on the matrix measurements. We propose a regularized pairwise pseudo-likelihood approach for matrix completion and prove that the proposed estimator can asymptotically recover the low-rank parameter matrix up to an identifiable equivalence class of a constant shift and scaling, at a near-optimal asymptotic convergence rate of the standard well-posed (non-informative missing) setting, while effectively mitigating the impact of informative missingness. The efficacy of our method is validated via numerical experiments, positioning it as a robust tool for matrix completion to mitigate data bias.
Spotlight Poster
Edoardo Debenedetti · Javier Rando · Daniel Paleka · Silaghi Florin · Dragos Albastroiu · Niv Cohen · Yuval Lemberg · Reshmi Ghosh · Rui Wen · Ahmed Salem · Giovanni Cherubin · Santiago Zanella-Beguelin · Robin Schmid · Victor Klemm · Takahiro Miki · Chenhao Li · Stefan Kraft · Mario Fritz · Florian Tramer · Sahar Abdelnabi · Lea Schönherr
[ West Ballroom A-D ]
Abstract
Large language model systems face significant security risks from maliciously crafted messages that aim to overwrite the system's original instructions or leak private data. To study this problem, we organized a capture-the-flag competition at IEEE SaTML 2024, where the flag is a secret string in the LLM system prompt. The competition was organized in two phases. In the first phase, teams developed defenses to prevent the model from leaking the secret. During the second phase, teams were challenged to extract the secrets hidden for defenses proposed by the other teams. This report summarizes the main insights from the competition. Notably, we found that all defenses were bypassed at least once, highlighting the difficulty of designing a successful defense and the necessity for additional research to protect LLM systems. To foster future research in this direction, we compiled a dataset with over 137k multi-turn attack chats and open-sourced the platform.
Spotlight Poster
Yanlin Qu · Jose Blanchet · Peter W Glynn
[ East Exhibit Hall A-C ]
Abstract
Convergence rate analysis for general state-space Markov chains is fundamentally important in operations research (stochastic systems) and machine learning (stochastic optimization). This problem, however, is notoriously difficult because traditional analytical methods often do not generate practically useful convergence bounds for realistic Markov chains. We propose the Deep Contractive Drift Calculator (DCDC), the first general-purpose sample-based algorithm for bounding the convergence of Markov chains to stationarity in Wasserstein distance. The DCDC has two components. First, inspired by the new convergence analysis framework in (Qu et.al, 2023), we introduce the Contractive Drift Equation (CDE), the solution of which leads to an explicit convergence bound. Second, we develop an efficient neural-network-based CDE solver. Equipped with these two components, DCDC solves the CDE and converts the solution into a convergence bound. We analyze the sample complexity of the algorithm and further demonstrate the effectiveness of the DCDC by generating convergence bounds for realistic Markov chains arising from stochastic processing networks as well as constant step-size stochastic optimization.
Spotlight Poster
Ge Yang · Changyi He · Jinyang Guo · Jianyu Wu · Yifu Ding · Aishan Liu · Haotong Qin · Pengliang Ji · Xianglong Liu
[ West Ballroom A-D ]

Abstract
Although large language models (LLMs) have demonstrated their strong intelligence ability, the high demand for computation and storage hinders their practical application. To this end, many model compression techniques are proposed to increase the efficiency of LLMs. However, current researches only validate their methods on limited models, datasets, metrics, etc, and still lack a comprehensive evaluation under more general scenarios. So it is still a question of which model compression approach we should use under a specific case. To mitigate this gap, we present the Large Language Model Compression Benchmark (LLMCBench), a rigorously designed benchmark with an in-depth analysis for LLM compression algorithms. We first analyze the actual model production requirements and carefully design evaluation tracks and metrics. Then, we conduct extensive experiments and comparison using multiple mainstream LLM compression approaches. Finally, we perform an in-depth analysis based on the evaluation and provide useful insight for LLM compression design. We hope our LLMCBench can contribute insightful suggestions for LLM compression algorithm design and serve as a foundation for future research.
Spotlight Poster
Shengsheng Lin · Weiwei Lin · Xinyi HU · Wentai Wu · Ruichao Mo · Haocheng Zhong
[ East Exhibit Hall A-C ]
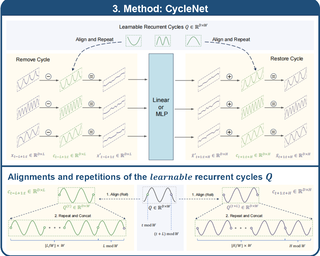
Abstract
The stable periodic patterns present in time series data serve as the foundation for conducting long-horizon forecasts. In this paper, we pioneer the exploration of explicitly modeling this periodicity to enhance the performance of models in long-term time series forecasting (LTSF) tasks. Specifically, we introduce the Residual Cycle Forecasting (RCF) technique, which utilizes learnable recurrent cycles to model the inherent periodic patterns within sequences, and then performs predictions on the residual components of the modeled cycles. Combining RCF with a Linear layer or a shallow MLP forms the simple yet powerful method proposed in this paper, called CycleNet. CycleNet achieves state-of-the-art prediction accuracy in multiple domains including electricity, weather, and energy, while offering significant efficiency advantages by reducing over 90% of the required parameter quantity. Furthermore, as a novel plug-and-play technique, the RCF can also significantly improve the prediction accuracy of existing models, including PatchTST and iTransformer. The source code is available at: https://github.com/ACAT-SCUT/CycleNet.
Spotlight Poster
Yubao Tang · Ruqing Zhang · Jiafeng Guo · Maarten Rijke · Wei Chen · Xueqi Cheng
[ East Exhibit Hall A-C ]
Abstract
Generative retrieval represents a novel approach to information retrieval, utilizing an encoder-decoder architecture to directly produce relevant document identifiers (docids) for queries. While this method offers benefits, current implementations are limited to scenarios with binary relevance data, overlooking the potential for documents to have multi-graded relevance. Extending generative retrieval to accommodate multi-graded relevance poses challenges, including the need to reconcile likelihood probabilities for docid pairs and the possibility of multiple relevant documents sharing the same identifier. To address these challenges, we introduce a new framework called GRaded Generative Retrieval (GR$^2$). Our approach focuses on two key components: ensuring relevant and distinct identifiers, and implementing multi-graded constrained contrastive training. Firstly, we aim to create identifiers that are both semantically relevant and sufficiently distinct to represent individual documents effectively. This is achieved by jointly optimizing the relevance and distinctness of docids through a combination of docid generation and autoencoder models. Secondly, we incorporate information about the relationship between relevance grades to guide the training process. Specifically, we leverage a constrained contrastive training strategy to bring the representations of queries and the identifiers of their relevant documents closer together, based on their respective relevance grades.Extensive experiments on datasets with both multi-graded and binary …
Spotlight Poster
Geng Chen · Yinxu Jia · Guanghui Wang · Changliang Zou
[ East Exhibit Hall A-C ]

Abstract
The widespread use of black box prediction methods has sparked an increasing interest in algorithm/model-agnostic approaches for quantifying goodness-of-fit, with direct ties to specification testing, model selection and variable importance assessment. A commonly used framework involves defining a predictiveness criterion, applying a cross-fitting procedure to estimate the predictiveness, and utilizing the difference in estimated predictiveness between two models as the test statistic. However, even after standardization, the test statistic typically fails to converge to a non-degenerate distribution under the null hypothesis of equal goodness, leading to what is known as the degeneracy issue. To addresses this degeneracy issue, we present a simple yet effective device, Zipper. It draws inspiration from the strategy of additional splitting of testing data, but encourages an overlap between two testing data splits in predictiveness evaluation. Zipper binds together the two overlapping splits using a slider parameter that controls the proportion of overlap. Our proposed test statistic follows an asymptotically normal distribution under the null hypothesis for any fixed slider value, guaranteeing valid size control while enhancing power by effective data reuse. Finite-sample experiments demonstrate that our procedure, with a simple choice of the slider, works well across a wide range of settings.
Spotlight Poster
Mohammad Sadil Khan · Sankalp Sinha · Talha Uddin · Didier Stricker · Sk Aziz Ali · Muhammad Zeshan Afzal
[ East Exhibit Hall A-C ]
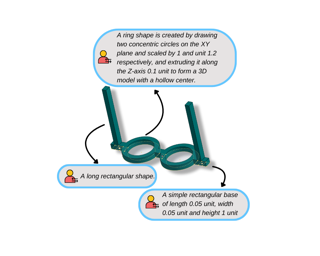
Abstract
Prototyping complex computer-aided design (CAD) models in modern softwares can be very time-consuming. This is due to the lack of intelligent systems that can quickly generate simpler intermediate parts. We propose Text2CAD, the first AI framework for generating text-to-parametric CAD models using designer-friendly instructions for all skill levels. Furthermore, we introduce a data annotation pipeline for generating text prompts based on natural language instructions for the DeepCAD dataset using Mistral and LLaVA-NeXT. The dataset contains $\sim170$K models and $\sim660$K text annotations, from abstract CAD descriptions (e.g., _generate two concentric cylinders_) to detailed specifications (e.g., _draw two circles with center_ $(x,y)$ and _radius_ $r_{1}$, $r_{2}$, \textit{and extrude along the normal by} $d$...). Within the Text2CAD framework, we propose an end-to-end transformer-based auto-regressive network to generate parametric CAD models from input texts. We evaluate the performance of our model through a mixture of metrics, including visual quality, parametric precision, and geometrical accuracy. Our proposed framework shows great potential in AI-aided design applications. Project page is available at https://sadilkhan.github.io/text2cad-project/.
Spotlight Poster
Adam Stooke · Rohit Prabhavalkar · Khe Sim · Pedro Moreno Mengibar
[ East Exhibit Hall A-C ]
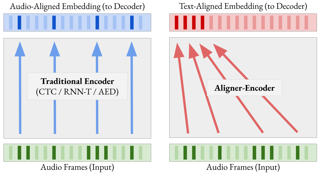
Abstract
Modern systems for automatic speech recognition, including the RNN-Transducer and Attention-based Encoder-Decoder (AED), are designed so that the encoder is not required to alter the time-position of information from the audio sequence into the embedding; alignment to the final text output is processed during decoding. We discover that the transformer-based encoder adopted in recent years is actually capable of performing the alignment internally during the forward pass, prior to decoding. This new phenomenon enables a simpler and more efficient model, the ''Aligner-Encoder''. To train it, we discard the dynamic programming of RNN-T in favor of the frame-wise cross-entropy loss of AED, while the decoder employs the lighter text-only recurrence of RNN-T without learned cross-attention---it simply scans embedding frames in order from the beginning, producing one token each until predicting the end-of-message. We conduct experiments demonstrating performance remarkably close to the state of the art, including a special inference configuration enabling long-form recognition. In a representative comparison, we measure the total inference time for our model to be 2x faster than RNN-T and 16x faster than AED. Lastly, we find that the audio-text alignment is clearly visible in the self-attention weights of a certain layer, which could be said to perform …
Spotlight Poster
Matt MacDermott · James Fox · Francesco Belardinelli · Tom Everitt
[ East Exhibit Hall A-C ]
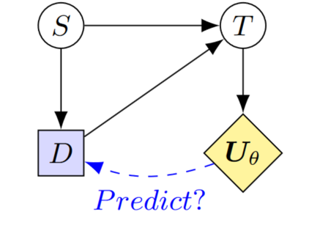
Abstract
We define maximum entropy goal-directedness (MEG), a formal measure of goal-directedness in causal models and Markov decision processes, and give algorithmsfor computing it. Measuring goal-directedness is important, as it is a criticalelement of many concerns about harm from AI. It is also of philosophical interest,as goal-directedness is a key aspect of agency. MEG is based on an adaptation ofthe maximum causal entropy framework used in inverse reinforcement learning. Itcan measure goal-directedness with respect to a known utility function, a hypothesisclass of utility functions, or a set of random variables. We prove that MEG satisfiesseveral desiderata and demonstrate our algorithms with small-scale experiments.
Spotlight Poster
Luise Ge · Daniel Halpern · Evi Micha · Ariel Procaccia · Itai Shapira · Yevgeniy Vorobeychik · Junlin Wu
[ West Ballroom A-D ]
Abstract
In the context of reinforcement learning from human feedback (RLHF), the reward function is generally derived from maximum likelihood estimation of a random utility model based on pairwise comparisons made by humans. The problem of learning a reward function is one of preference aggregation that, we argue, largely falls within the scope of social choice theory. From this perspective, we can evaluate different aggregation methods via established axioms, examining whether these methods meet or fail well-known standards. We demonstrate that both the Bradley-Terry-Luce Model and its broad generalizations fail to meet basic axioms. In response, we develop novel rules for learning reward functions with strong axiomatic guarantees. A key innovation from the standpoint of social choice is that our problem has a *linear* structure, which greatly restricts the space of feasible rules and leads to a new paradigm that we call *linear social choice*.
Spotlight Poster
Maximilian Li · Lucas Janson
[ East Exhibit Hall A-C ]
Abstract
Interpretability studies often involve tracing the flow of information through machine learning models to identify specific model components that perform relevant computations for tasks of interest. Prior work quantifies the importance of a model component on a particular task by measuring the impact of performing ablation on that component, or simulating model inference with the component disabled. We propose a new method, optimal ablation (OA), and show that OA-based component importance has theoretical and empirical advantages over measuring importance via other ablation methods. We also show that OA-based component importance can benefit several downstream interpretability tasks, including circuit discovery, localization of factual recall, and latent prediction.
Spotlight Poster
Xinmeng Huang · Shuo Li · Edgar Dobriban · Osbert Bastani · Hamed Hassani · Dongsheng Ding
[ East Exhibit Hall A-C ]
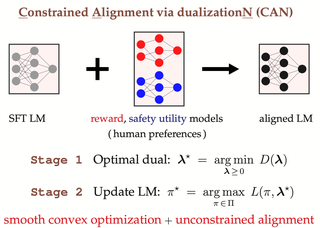
Abstract
The growing safety concerns surrounding large language models raise an urgent need to align them with diverse human preferences to simultaneously enhance their helpfulness and safety. A promising approach is to enforce safety constraints through Reinforcement Learning from Human Feedback (RLHF). For such constrained RLHF, typical Lagrangian-based primal-dual policy optimization methods are computationally expensive and often unstable. This paper presents a perspective of dualization that reduces constrained alignment to an equivalent unconstrained alignment problem. We do so by pre-optimizing a smooth and convex dual function that has a closed form. This shortcut eliminates the need for cumbersome primal-dual policy iterations, greatly reducing the computational burden and improving training stability. Our strategy leads to two practical algorithms in model-based and preference-based settings (MoCAN and PeCAN, respectively). A broad range of experiments demonstrate the effectiveness and merits of our algorithms.
Spotlight Poster
Antoine Scheid · Aymeric Capitaine · Etienne Boursier · Eric Moulines · Michael Jordan · Alain Durmus
[ West Ballroom A-D ]

Abstract
In Economics, the concept of externality refers to any indirect effect resulting from an interaction between players and affecting a third party without compensation. Most of the models within which externality has been studied assume that agents have perfect knowledge of their environment and preferences. This is a major hindrance to the practical implementation of many proposed solutions. To adress this issue, we consider a two-players bandit game setting where the actions of one of the player affect the other one. Building upon this setup, we extend the Coase theorem [Coase, 2013], which suggests that the optimal approach for maximizing the social welfare in the presence of externality is to establish property rights, i.e., enabling transfers and bargaining between the players. Nonetheless, this fundamental result relies on the assumption that bargainers possess perfect knowledge of the underlying game. We first demonstrate that in the absence of property rights in the considered online scenario, the social welfare breaks down. We then provide a policy for the players, which allows them to learn a bargaining strategy which maximizes the total welfare, recovering the Coase theorem under uncertainty.
Spotlight Poster
Subham Sahoo · Aaron Gokaslan · Christopher De Sa · Volodymyr Kuleshov
[ East Exhibit Hall A-C ]

Abstract
Diffusion models have gained traction as powerful algorithms for synthesizing high-quality images. Central to these algorithms is the diffusion process, a set of equations which maps data to noise in a way that can significantly affect performance. In this paper, we explore whether the diffusionprocess can be learned from data.Our work is grounded in Bayesian inference and seeks to improve log-likelihood estimation by casting the learned diffusion process as an approximate variational posterior that yields a tighter lower bound (ELBO) on the likelihood.A widely held assumption is that the ELBO is invariant to the noise process: our work dispels this assumption and proposes multivariate learned adaptive noise (MuLAN), a learned diffusion process that applies noise at different rates across an image. Our method consists of three components: a multivariate noise schedule, adaptive input-conditional diffusion, and auxiliary variables; these components ensure that the ELBO is no longer invariant to the choice of the noise schedule as in previous works. Empirically, MuLAN sets a new **state-of-the-art** in density estimation on CIFAR-10 and ImageNet while matching the performance of previous state-of-the-art models with **50%** fewer steps. We provide the code, along with a blog post and video tutorial on the project page: https://s-sahoo.com/MuLAN
Spotlight Poster
Zhenbang Wu · Anant Dadu · Michael Nalls · Faraz Faghri · Jimeng Sun
[ West Ballroom A-D ]

Abstract
Large language models (LLMs) have shown impressive capabilities in solving a wide range of tasks based on human instructions. However, developing a conversational AI assistant for electronic health record (EHR) data remains challenging due to (1) the lack of large-scale instruction-following datasets and (2) the limitations of existing model architectures in handling complex and heterogeneous EHR data.In this paper, we introduce MIMIC-Instr, a dataset comprising over 400K open-ended instruction-following examples derived from the MIMIC-IV EHR database. This dataset covers various topics and is suitable for instruction-tuning general-purpose LLMs for diverse clinical use cases. Additionally, we propose Llemr, a general framework that enables LLMs to process and interpret EHRs with complex data structures. Llemr demonstrates competitive performance in answering a wide range of patient-related questions based on EHR data.Furthermore, our evaluations on clinical predictive modeling benchmarks reveal that the fine-tuned Llemr achieves performance comparable to state-of-the-art (SOTA) baselines using curated features. The dataset and code are available at \url{https://github.com/zzachw/llemr}.
Spotlight Poster
Diana Cai · Chirag Modi · Charles Margossian · Robert Gower · David Blei · Lawrence Saul
[ East Exhibit Hall A-C ]
Abstract
We develop EigenVI, an eigenvalue-based approach for black-box variational inference (BBVI). EigenVI constructs its variational approximations from orthogonal function expansions. For distributions over $\mathbb{R}^D$, the lowest order term in these expansions provides a Gaussian variational approximation, while higher-order terms provide a systematic way to model non-Gaussianity. These approximations are flexible enough to model complex distributions (multimodal, asymmetric), but they are simple enough that one can calculate their low-order moments and draw samples from them. EigenVI can also model other types of random variables (e.g., nonnegative, bounded) by constructing variational approximations from different families of orthogonal functions. Within these families, EigenVI computes the variational approximation that best matches the score function of the target distribution by minimizing a stochastic estimate of the Fisher divergence. Notably, this optimization reduces to solving a minimum eigenvalue problem, so that EigenVI effectively sidesteps the iterative gradient-based optimizations that are required for many other BBVI algorithms. (Gradient-based methods can be sensitive to learning rates, termination criteria, and other tunable hyperparameters.) We use EigenVI to approximate a variety of target distributions, including a benchmark suite of Bayesian models from posteriordb. On these distributions, we find that EigenVI is more accurate than existing methods for Gaussian BBVI.
Spotlight Poster
Frederik Hoppe · Claudio Mayrink Verdun · Hannah Laus · Felix Krahmer · Holger Rauhut
[ East Exhibit Hall A-C ]
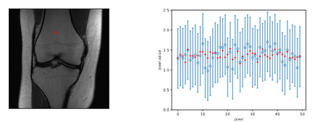
Abstract
Uncertainty quantification (UQ) is a crucial but challenging task in many high-dimensional learning problems to increase the confidence of a given predictor. We develop a new data-driven approach for UQ in regression that applies both to classical optimization approaches such as the LASSO as well as to neural networks. One of the most notable UQ techniques is the debiased LASSO, which modifies the LASSO to allow for the construction of asymptotic confidence intervals by decomposing the estimation error into a Gaussian and an asymptotically vanishing bias component. However, in real-world problems with finite-dimensional data, the bias term is often too significant to disregard, resulting in overly narrow confidence intervals. Our work rigorously addresses this issue and derives a data-driven adjustment that corrects the confidence intervals for a large class of predictors by estimating the means and variances of the bias terms from training data, exploiting high-dimensional concentration phenomena. This gives rise to non-asymptotic confidence intervals, which can help avoid overestimating certainty in critical applications such as MRI diagnosis. Importantly, our analysis extends beyond sparse regression to data-driven predictors like neural networks, enhancing the reliability of model-based deep learning. Our findings bridge the gap between established theory and the practical applicability …
Spotlight Poster
Praneeth Kacham · David Woodruff
[ East Exhibit Hall A-C ]
Abstract
When rows of an $n \times d$ matrix $A$ are given in a stream, we study algorithms for approximating the top eigenvector of $A^T A$ (equivalently, the top right singular vector of $A$). We consider worst case inputs $A$ but assume that the rows are presented to the streaming algorithm in a uniformly random order. We show that when the gap parameter $R = \sigma_1(A)^2/\sigma_2(A)^2 = \Omega(1)$, then there is a randomized algorithm that uses $O(h \cdot d \cdot \text{polylog}(d))$ bits of space and outputs a unit vector $v$ that has a correlation $1 - O(1/\sqrt{R})$ with the top eigenvector $v_1$. Here $h$ denotes the number of ``heavy rows'' in the matrix, defined as the rows with Euclidean norm at least $\|{A}\|_F/\sqrt{d \cdot \text{polylog}(d)}$. We also provide a lower bound showing that any algorithm using $O(hd/R)$ bits of space can obtain at most $1 - \Omega(1/R^2)$ correlation with the top eigenvector. Thus, parameterizing the space complexity in terms of the number of heavy rows is necessary for high accuracy solutions.Our results improve upon the $R = \Omega(\log n \cdot \log d)$ requirement in a recent work of Price. We note that Price's algorithm works for arbitrary order streams whereas our …
Spotlight Poster
Róbert Busa-Fekete · Travis Dick · Claudio Gentile · Andres Munoz Medina · Adam Smith · Marika Swanberg
[ West Ballroom A-D ]
Abstract
We propose reconstruction advantage measures to audit label privatization mechanisms. A reconstruction advantage measure quantifies the increase in an attacker's ability to infer the true label of an unlabeled example when provided with a private version of the labels in a dataset (e.g., aggregate of labels from different users or noisy labels output by randomized response), compared to an attacker that only observes the feature vectors, but may have prior knowledge of the correlation between features and labels. We consider two such auditing measures: one additive, and on multiplicative. These cover previous approaches taken in the literature on empirical auditing and differential privacy. These measures allow us to place a variety of proposed privatization schemes---some differentially private, some not---on the same footing. We analyze these measures theoretically under a distributional model which, we claim, encapsulates reasonable adversarial settings. We also quantify their behavior empirically on real and simulated prediction tasks. Across a range of experimental settings, we find that differentially private schemes dominate or match the privacy-utility tradeoff of more heuristic approaches.
Spotlight Poster
Hojun Chung · Junseo Lee · Minsoo Kim · Dohyeong Kim · Songhwai Oh
[ West Ballroom A-D ]
Abstract
Training agents that are robust to environmental changes remains a significant challenge in deep reinforcement learning (RL). Unsupervised environment design (UED) has recently emerged to address this issue by generating a set of training environments tailored to the agent's capabilities. While prior works demonstrate that UED has the potential to learn a robust policy, their performance is constrained by the capabilities of the environment generation. To this end, we propose a novel UED algorithm, adversarial environment design via regret-guided diffusion models (ADD). The proposed method guides the diffusion-based environment generator with the regret of the agent to produce environments that the agent finds challenging but conducive to further improvement. By exploiting the representation power of diffusion models, ADD can directly generate adversarial environments while maintaining the diversity of training environments, enabling the agent to effectively learn a robust policy. Our experimental results demonstrate that the proposed method successfully generates an instructive curriculum of environments, outperforming UED baselines in zero-shot generalization across novel, out-of-distribution environments.
Spotlight Poster
Qingyuan Wu · Simon Zhan · Yixuan Wang · Yuhui Wang · Chung-Wei Lin · Chen Lv · Qi Zhu · Chao Huang
[ West Ballroom A-D ]
Abstract
In environments with delayed observation, state augmentation by including actions within the delay window is adopted to retrieve Markovian property to enable reinforcement learning (RL). Whereas, state-of-the-art (SOTA) RL techniques with Temporal-Difference (TD) learning frameworks commonly suffer from learning inefficiency, due to the significant expansion of the augmented state space with the delay. To improve the learning efficiency without sacrificing performance, this work novelly introduces Variational Delayed Policy Optimization (VDPO), reforming delayed RL as a variational inference problem. This problem is further modelled as a two-step iterative optimization problem, where the first step is TD learning in the delay-free environment with a small state space, and the second step is behaviour cloning which can be addressed much more efficiently than TD learning. We not only provide a theoretical analysis of VDPO in terms of sample complexity and performance, but also empirically demonstrate that VDPO can achieve consistent performance with SOTA methods, with a significant enhancement of sample efficiency (approximately 50\% less amount of samples) in the MuJoCo benchmark.
Spotlight Poster
Tobias Fischer · Jonas Kulhanek · Samuel Rota Bulò · Lorenzo Porzi · Marc Pollefeys · Peter Kontschieder
[ East Exhibit Hall A-C ]

Abstract
We present an efficient neural 3D scene representation for novel-view synthesis (NVS) in large-scale, dynamic urban areas. Existing works are not well suited for applications like mixed-reality or closed-loop simulation due to their limited visual quality and non-interactive rendering speeds. Recently, rasterization-based approaches have achieved high-quality NVS at impressive speeds. However, these methods are limited to small-scale, homogeneous data, i.e. they cannot handle severe appearance and geometry variations due to weather, season, and lighting and do not scale to larger, dynamic areas with thousands of images. We propose 4DGF, a neural scene representation that scales to large-scale dynamic urban areas, handles heterogeneous input data, and substantially improves rendering speeds. We use 3D Gaussians as an efficient geometry scaffold while relying on neural fields as a compact and flexible appearance model. We integrate scene dynamics via a scene graph at global scale while modeling articulated motions on a local level via deformations. This decomposed approach enables flexible scene composition suitable for real-world applications. In experiments, we surpass the state-of-the-art by over 3 dB in PSNR and more than 200x in rendering speed.
Spotlight Poster
Gennaro Gala · Cassio de Campos · Antonio Vergari · Erik Quaeghebeur
[ East Exhibit Hall A-C ]
Abstract
Probabilistic integral circuits (PICs) have been recently introduced as probabilistic models enjoying the key ingredient behind expressive generative models: continuous latent variables (LVs). PICs are symbolic computational graphs defining continuous LV models as hierarchies of functions that are summed and multiplied together, or integrated over some LVs. They are tractable if LVs can be analytically integrated out, otherwise they can be approximated by tractable probabilistic circuits (PC) encoding a hierarchical numerical quadrature process, called QPCs.So far, only tree-shaped PICs have been explored, and training them via numerical quadrature requires memory-intensive processing at scale. In this paper, we address these issues, and present: (i) a pipeline for building DAG-shaped PICs out of arbitrary variable decompositions, (ii) a procedure for training PICs using tensorized circuit architectures, and (iii) neural functional sharing techniques to allow scalable training. In extensive experiments, we showcase the effectiveness of functional sharing and the superiority of QPCs over traditional PCs.
Spotlight Poster
QIUHAO Zeng · Long-Kai Huang · Qi CHEN · Charles Ling · Boyu Wang
[ East Exhibit Hall A-C ]
Abstract
In many machine learning tasks, data is inherently sequential. Most existing algorithms learn from sequential data in an auto-regressive manner, which predicts the next unseen data point based on the observed sequence, implicitly assuming the presence of an \emph{evolving pattern} embedded in the data that can be leveraged. However, identifying and assessing evolving patterns in learning tasks often relies on subjective judgments rooted in the prior knowledge of human experts, lacking a standardized quantitative measure. Furthermore, such measures enable us to determine the suitability of employing sequential models effectively and make informed decisions on the temporal order of time series data, and feature/data selection processes. To address this issue, we introduce the Evolving Rate (EvoRate), which quantitatively approximates the intensity of evolving patterns in the data with Mutual Information. Furthermore, in some temporal data with neural mutual information estimations, we only have snapshots at different timestamps, lacking correspondence, which hinders EvoRate estimation. To tackle this challenge, we propose EvoRate$_\mathcal{W}$, aiming to establish correspondence with optimal transport for estimating the first-order EvoRate. Experiments on synthetic and real-world datasets including images and tabular data validate the efficacy of our EvoRate.
Spotlight Poster
Huiqiang Jiang · Yucheng LI · Chengruidong Zhang · Qianhui Wu · Xufang Luo · Surin Ahn · Zhenhua Han · Amir Abdi · Dongsheng Li · Chin-Yew Lin · Yuqing Yang · Lili Qiu
[ East Exhibit Hall A-C ]
Abstract
The computational challenges of Large Language Model (LLM) inference remain a significant barrier to their widespread deployment, especially as prompt lengths continue to increase. Due to the quadratic complexity of the attention computation, it takes 30 minutes for an 8B LLM to process a prompt of 1M tokens (i.e., the pre-filling stage) on a single A100 GPU. Existing methods for speeding up prefilling often fail to maintain acceptable accuracy or efficiency when applied to long-context LLMs. To address this gap, we introduce MInference (Milliontokens Inference), a sparse calculation method designed to accelerate pre-filling of long-sequence processing. Specifically, we identify three unique patterns in long-context attention matrices-the A-shape, Vertical-Slash, and Block-Sparse-that can be leveraged for efficient sparse computation on GPUs. We determine the optimal pattern for each attention head offline and dynamically build sparseindices based on the assigned pattern during inference. With the pattern and sparse indices, we perform efficient sparse attention calculations via our optimized GPU kernels to significantly reduce the latency in the pre-filling stage of longcontext LLMs. Our proposed technique can be directly applied to existing LLMs without any modifications to the pre-training setup or additional fine-tuning. Byevaluating on a wide range of downstream tasks, including InfiniteBench, RULER, …
Spotlight Poster
Anna Mészáros · Szilvia Ujváry · Wieland Brendel · Patrik Reizinger · Ferenc Huszar
[ East Exhibit Hall A-C ]
Abstract
LLMs show remarkable emergent abilities, such as inferring concepts from presumably out-of-distribution prompts, known as in-context learning. Though this success is often attributed to the Transformer architecture, our systematic understanding is limited. In complex real-world data sets, even defining what is out-of-distribution is not obvious. To better understand the OOD behaviour of autoregressive LLMs, we focus on formal languages, which are defined by the intersection of rules. We define a new scenario of OOD compositional generalization, termed \textit{rule extrapolation}. Rule extrapolation describes OOD scenarios, where the prompt violates at least one rule. We evaluate rule extrapolation in formal languages with varying complexity in linear and recurrent architectures, the Transformer, and state space models to understand the architectures' influence on rule extrapolation. We also lay the first stones of a normative theory of rule extrapolation, inspired by the Solomonoff prior in algorithmic information theory.
Spotlight Poster
Aditi Jha · Diksha Gupta · Carlos Brody · Jonathan Pillow
[ East Exhibit Hall A-C ]
Abstract
Latent dynamical systems have been widely used to characterize the dynamics of neural population activity in the brain. However, these models typically ignore the fact that the brain contains multiple cell types. This limits their ability to capture the functional roles of distinct cell classes, and to predict the effects of cell-specific perturbations on neural activity or behavior. To overcome these limitations, we introduce the `"cell-type dynamical systems" (CTDS) model. This model extends latent linear dynamical systems to contain distinct latent variables for each cell class, with biologically inspired constraints on both dynamics and emissions. To illustrate our approach, we consider neural recordings with distinct excitatory (E) and inhibitory (I) populations. The CTDS model defines separate latents for both cell types, and constrains the dynamics so that E (I) latents have a strictly positive (negative) effects on other latents. We applied CTDS to recordings from rat frontal orienting fields (FOF) and anterior dorsal striatum (ADS) during an auditory decision-making task. The model achieved higher accuracy than a standard linear dynamical system (LDS), and revealed that the animal's choice can be decoded from both E and I latents and thus is not restricted to a single cell-class. We also performed in-silico …
Spotlight Poster
Rishabh Agarwal · Avi Singh · Lei Zhang · Bernd Bohnet · Luis Rosias · Stephanie Chan · Biao Zhang · Ankesh Anand · Zaheer Abbas · Azade Nova · John Co-Reyes · Eric Chu · Feryal Behbahani · Aleksandra Faust · Hugo Larochelle
[ East Exhibit Hall A-C ]

Abstract
Large language models (LLMs) excel at few-shot in-context learning (ICL) -- learning from a few examples provided in context at inference, without any weight updates. Newly expanded context windows allow us to investigate ICL with hundreds or thousands of examples – the many-shot regime. Going from few-shot to many-shot, we observe significant performance gains across a wide variety of generative and discriminative tasks. While promising, many-shot ICL can be bottlenecked by the available amount of human-generated outputs. To mitigate this limitation, we explore two new settings: (1) "Reinforced ICL" that uses model-generated chain-of-thought rationales in place of human rationales, and (2) "Unsupervised ICL" where we remove rationales from the prompt altogether, and prompts the model only with domain-specific inputs. We find that both Reinforced and Unsupervised ICL can be quite effective in the many-shot regime, particularly on complex reasoning tasks. We demonstrate that, unlike few-shot learning, many-shot learning is effective at overriding pretraining biases, can learn high-dimensional functions with numerical inputs, and performs comparably to supervised fine-tuning. Finally, we reveal the limitations of next-token prediction loss as an indicator of downstream ICL performance.
Spotlight Poster
Roman Bushuiev · Anton Bushuiev · Niek de Jonge · Adamo Young · Fleming Kretschmer · Raman Samusevich · Janne Heirman · Fei Wang · Luke Zhang · Kai Dührkop · Marcus Ludwig · Nils Haupt · Apurva Kalia · Corinna Brungs · Robin Schmid · Russell Greiner · Bo Wang · David Wishart · Liping Liu · Juho Rousu · Wout Bittremieux · Hannes Rost · Tytus Mak · Soha Hassoun · Florian Huber · Justin J.J. van der Hooft · Michael Stravs · Sebastian Böcker · Josef Sivic · Tomáš Pluskal
[ West Ballroom A-D ]
Abstract
The discovery and identification of molecules in biological and environmental samples is crucial for advancing biomedical and chemical sciences. Tandem mass spectrometry (MS/MS) is the leading technique for high-throughput elucidation of molecular structures. However, decoding a molecular structure from its mass spectrum is exceptionally challenging, even when performed by human experts. As a result, the vast majority of acquired MS/MS spectra remain uninterpreted, thereby limiting our understanding of the underlying (bio)chemical processes. Despite decades of progress in machine learning applications for predicting molecular structures from MS/MS spectra, the development of new methods is severely hindered by the lack of standard datasets and evaluation protocols. To address this problem, we propose MassSpecGym -- the first comprehensive benchmark for the discovery and identification of molecules from MS/MS data. Our benchmark comprises the largest publicly available collection of high-quality MS/MS spectra and defines three MS/MS annotation challenges: \textit{de novo} molecular structure generation, molecule retrieval, and spectrum simulation. It includes new evaluation metrics and a generalization-demanding data split, therefore standardizing the MS/MS annotation tasks and rendering the problem accessible to the broad machine learning community. MassSpecGym is publicly available at \url{https://github.com/pluskal-lab/MassSpecGym}.
Spotlight Poster
Mubashara Akhtar · Omar Benjelloun · Costanza Conforti · Luca Foschini · Joan Giner-Miguelez · Pieter Gijsbers · Sujata Goswami · Nitisha Jain · Michalis Karamousadakis · Michael Kuchnik · Satyapriya Krishna · Sylvain Lesage · Quentin Lhoest · Pierre Marcenac · Manil Maskey · Peter Mattson · Luis Oala · Hamidah Oderinwale · Pierre Ruyssen · Tim Santos · Rajat Shinde · Elena Simperl · Arjun Suresh · Goeffry Thomas · Slava Tykhonov · Joaquin Vanschoren · Susheel Varma · Jos van der Velde · Steffen Vogler · Carole-Jean Wu · Luyao Zhang
[ West Ballroom A-D ]
Abstract
Data is a critical resource for machine learning (ML), yet working with data remains a key friction point. This paper introduces Croissant, a metadata format for datasets that creates a shared representation across ML tools, frameworks, and platforms. Croissant makes datasets more discoverable, portable, and interoperable, thereby addressing significant challenges in ML data management. Croissant is already supported by several popular dataset repositories, spanning hundreds of thousands of datasets, enabling easy loading into the most commonly-used ML frameworks, regardless of where the data is stored. Our initial evaluation by human raters shows that Croissant metadata is readable, understandable, complete, yet concise.
Spotlight Poster
Ziyang Xiao · Dongxiang Zhang · Xiongwei Han · Xiaojin Fu · Wing Yin YU · Tao Zhong · Sai Wu · Yuan Wang · Jianwei Yin · Gang Chen
[ West Ballroom A-D ]

Abstract
Verbal and visual-spatial information processing are two critical subsystems that activate different brain regions and often collaborate together for cognitive reasoning. Despite the rapid advancement of LLM-based reasoning, the mainstream frameworks, such as Chain-of-Thought (CoT) and its variants, primarily focus on the verbal dimension, resulting in limitations in tackling reasoning problems with visual and spatial clues. To bridge the gap, we propose a novel dual-modality reasoning framework called Vision-Augmented Prompting (VAP). Upon receiving a textual problem description, VAP automatically synthesizes an image from the visual and spatial clues by utilizing external drawing tools. Subsequently, VAP formulates a chain of thought in both modalities and iteratively refines the synthesized image. Finally, a conclusive reasoning scheme based on self-alignment is proposed for final result generation. Extensive experiments are conducted across four versatile tasks, including solving geometry problems, Sudoku, time series prediction, and travelling salesman problem. The results validated the superiority of VAP over existing LLMs-based reasoning frameworks.
Spotlight Poster
Michael Saxon · Fatima Jahara · Mahsa Khoshnoodi · Yujie Lu · Aditya Sharma · William Yang Wang
[ East Exhibit Hall A-C ]
Abstract
With advances in the quality of text-to-image (T2I) models has come interest in benchmarking their prompt faithfulness---the semantic coherence of generated images to the prompts they were conditioned on. A variety of T2I faithfulness metrics have been proposed, leveraging advances in cross-modal embeddings and vision-language models (VLMs). However, these metrics are not rigorously compared and benchmarked, instead presented with correlation to human Likert scores over a set of easy-to-discriminate images against seemingly weak baselines. We introduce T2IScoreScore, a curated set of semantic error graphs containing a prompt and a set of increasingly erroneous images. These allow us to rigorously judge whether a given prompt faithfulness metric can correctly order images with respect to their objective error count and significantly discriminate between different error nodes, using meta-metric scores derived from established statistical tests. Surprisingly, we find that the state-of-the-art VLM-based metrics (e.g., TIFA, DSG, LLMScore, VIEScore) we tested fail to significantly outperform simple (and supposedly worse) feature-based metrics like CLIPScore, particularly on a hard subset of naturally-occurring T2I model errors. TS2 will enable the development of better T2I prompt faithfulness metrics through more rigorous comparison of their conformity to expected orderings and separations under objective criteria.
Spotlight Poster
Raymond Zhang · Richard Combes
[ West Ballroom A-D ]
Abstract
We consider Thompson Sampling (TS) for linear combinatorial semi-bandits and subgaussian rewards. We propose the first known TS whose finite-time regret does not scale exponentially with the dimension of the problem. We further show the mismatched sampling paradox: A learner who knows the rewards distributions and samples from the correct posterior distribution can perform exponentially worse than a learner who does not know the rewards and simply samples from a well-chosen Gaussian posterior. The code used to generate the experiments is available at https://github.com/RaymZhang/CTS-Mismatched-Paradox
Spotlight Poster
Valentin De Bortoli · Iryna Korshunova · Andriy Mnih · Arnaud Doucet
[ East Exhibit Hall A-C ]

Abstract
Mass transport problems arise in many areas of machine learning whereby one wants to compute a map transporting one distribution to another. Generative modeling techniques like Generative Adversarial Networks (GANs) and Denoising Diffusion Models (DMMs) have been successfully adapted to solve such transport problems, resulting in CycleGAN and Bridge Matching respectively. However, these methods do not approximate Optimal Transport (OT) maps, which are known to have desirable properties. Existing techniques approximating OT maps for high-dimensional data-rich problems, including DDMs-based Rectified Flow and Schrodinger bridge procedures, require fully training a DDM-type model at each iteration, or use mini-batch techniques which can introduce significant errors. We propose a novel algorithm to compute the Schrodinger bridge, a dynamic entropy-regularized version of OT, that eliminates the need to train multiple DDMs-like models. This algorithm corresponds to a discretization of a flow of path measures, referred to as the Schrodinger Bridge Flow, whose only stationary point is the Schrodinger bridge. We demonstrate the performance of our algorithm on a variety of unpaired data translation tasks.
Spotlight Poster
Xi Yang · Xu Gu · Xingyilang Yin · Xinbo Gao
[ East Exhibit Hall A-C ]

Abstract
The proliferation of 2D foundation models has sparked research into adapting them for open-world 3D instance segmentation. Recent methods introduce a paradigm that leverages superpoints as geometric primitives and incorporates 2D multi-view masks from Segment Anything model (SAM) as merging guidance, achieving outstanding zero-shot instance segmentation results. However, the limited use of 3D priors restricts the segmentation performance. Previous methods calculate the 3D superpoints solely based on estimated normal from spatial coordinates, resulting in under-segmentation for instances with similar geometry. Besides, the heavy reliance on SAM and hand-crafted algorithms in 2D space suffers from over-segmentation due to SAM's inherent part-level segmentation tendency. To address these issues, we propose SA3DIP, a novel method for Segmenting Any 3D Instances via exploiting potential 3D Priors. Specifically, on one hand, we generate complementary 3D primitives based on both geometric and textural priors, which reduces the initial errors that accumulate in subsequent procedures. On the other hand, we introduce supplemental constraints from the 3D space by using a 3D detector to guide a further merging process. Furthermore, we notice a considerable portion of low-quality ground truth annotations in ScanNetV2 benchmark, which affect the fair evaluations. Thus, we present ScanNetV2-INS with complete ground truth labels and …
Spotlight Poster
Ilias Diakonikolas · Nikos Zarifis
[ East Exhibit Hall A-C ]
Abstract
We study the problem of PAC learning $\gamma$-margin halfspaces in the presence of Massart noise. Without computational considerations, the sample complexity of this learning problem is known to be $\widetilde{\Theta}(1/(\gamma^2 \epsilon))$. Prior computationally efficient algorithms for the problem incur sample complexity $\tilde{O}(1/(\gamma^4 \epsilon^3))$ and achieve 0-1 error of $\eta+\epsilon$, where $\eta<1/2$ is the upper bound on the noise rate.Recent work gave evidence of an information-computation tradeoff, suggesting that a quadratic dependence on $1/\epsilon$ is required for computationally efficient algorithms. Our main result is a computationally efficient learner with sample complexity $\widetilde{\Theta}(1/(\gamma^2 \epsilon^2))$, nearly matching this lower bound. In addition, our algorithm is simple and practical, relying on online SGD on a carefully selected sequence of convex losses.
Spotlight Poster
Nan Song · Bozhou Zhang · Xiatian Zhu · Li Zhang
[ East Exhibit Hall A-C ]

Abstract
Motion forecasting for agents in autonomous driving is highly challenging due to the numerous possibilities for each agent's next action and their complex interactions in space and time. In real applications, motion forecasting takes place repeatedly and continuously as the self-driving car moves. However, existing forecasting methods typically process each driving scene within a certain range independently, totally ignoring the situational and contextual relationships between successive driving scenes. This significantly simplifies the forecasting task, making the solutions suboptimal and inefficient to use in practice. To address this fundamental limitation, we propose a novel motion forecasting framework for continuous driving, named RealMotion.It comprises two integral streams both at the scene level:(1) The scene context stream progressively accumulates historical scene information until the present moment, capturing temporal interactive relationships among scene elements.(2) The agent trajectory stream optimizes current forecasting by sequentially relaying past predictions.Besides, a data reorganization strategy is introduced to narrow the gap between existing benchmarks and real-world applications, consistent with our network. These approaches enable exploiting more broadly the situational and progressive insights of dynamic motion across space and time. Extensive experiments on Argoverse series with different settings demonstrate that our RealMotion achieves state-of-the-art performance, along with the advantage of …
Spotlight Poster
Raj Agrawal · Sam Witty · Andy Zane · Elias Bingham
[ West Ballroom A-D ]
Abstract
Many practical problems involve estimating low dimensional statistical quantities with high-dimensional models and datasets. Several approaches address these estimation tasks based on the theory of influence functions, such as debiased/double ML or targeted minimum loss estimation. We introduce \textit{Monte Carlo Efficient Influence Functions} (MC-EIF), a fully automated technique for approximating efficient influence functions that integrates seamlessly with existing differentiable probabilistic programming systems. MC-EIF automates efficient statistical estimation for a broad class of models and functionals that previously required rigorous custom analysis. We prove that MC-EIF is consistent, and that estimators using MC-EIF achieve optimal $\sqrt{N}$ convergence rates. We show empirically that estimators using MC-EIF are at parity with estimators using analytic EIFs. Finally, we present a novel capstone example using MC-EIF for optimal portfolio selection.
Spotlight Poster
Mingtian Tan · Mike Merrill · Vinayak Gupta · Tim Althoff · Tom Hartvigsen
[ East Exhibit Hall A-C ]
Abstract
Large language models (LLMs) are being applied to time series forecasting. But are language models actually useful for time series? In a series of ablation studies on three recent and popular LLM-based time series forecasting methods, we find that removing the LLM component or replacing it with a basic attention layer does not degrade forecasting performance---in most cases, the results even improve! We also find that despite their significant computational cost, pretrained LLMs do no better than models trained from scratch, do not represent the sequential dependencies in time series, and do not assist in few-shot settings. Additionally, we explore time series encoders and find that patching and attention structures perform similarly to LLM-based forecasters. All resources needed to reproduce our work are available: https://github.com/BennyTMT/LLMsForTimeSeries.
Spotlight Poster
Tom Sander · Pierre Fernandez · Alain Durmus · Matthijs Douze · Teddy Furon
[ East Exhibit Hall A-C ]
Abstract
We investigate the radioactivity of text generated by large language models (LLM), \ie whether it is possible to detect that such synthetic input was used to train a subsequent LLM.Current methods like membership inference or active IP protection either work only in settings where the suspected text is known or do not provide reliable statistical guarantees.We discover that, on the contrary, it is possible to reliably determine if a language model was trained on synthetic data if that data is output by a watermarked LLM.Our new methods, specialized for radioactivity, detects with a provable confidence weak residuals of the watermark signal in the fine-tuned LLM.We link the radioactivity contamination level to the following properties: the watermark robustness, its proportion in the training set, and the fine-tuning process.For instance, if the suspect model is open-weight, we demonstrate that training on watermarked instructions can be detected with high confidence ($p$-value $< 10^{-5}$) even when as little as $5\%$ of training text is watermarked.
Spotlight Poster
Yizuo Chen · Adnan Darwiche
[ West Ballroom A-D ]

Abstract
We study the identification of causal effects, motivated by two improvements to identifiability which can be attained if one knows that some variables in a causal graph are functionally determined by their parents (without needing to know the specific functions). First, an unidentifiable causal effect may become identifiable when certain variables are functional. Second, certain functional variables can be excluded from being observed without affecting the identifiability of a causal effect, which may significantly reduce the number of needed variables in observational data. Our results are largely based on an elimination procedure which removes functional variables from a causal graph while preserving key properties in the resulting causal graph, including the identifiability of causal effects.
Spotlight Poster
Xiao Zhang · Miao Li · Ji Wu
[ East Exhibit Hall A-C ]
Abstract
Pretrained language models can encode a large amount of knowledge and utilize it for various reasoning tasks, yet they can still struggle to learn novel factual knowledge effectively from finetuning on limited textual demonstrations. In this work, we show that the reason for this deficiency is that language models are biased to learn word co-occurrence statistics instead of true factual associations. We identify the differences between two forms of knowledge representation in language models: knowledge in the form of co-occurrence statistics is encoded in the middle layers of the transformer model and does not generalize well to reasoning scenarios beyond simple question answering, while true factual associations are encoded in the lower layers and can be freely utilized in various reasoning tasks. Based on these observations, we propose two strategies to improve the learning of factual associations in language models. We show that training on text with implicit rather than explicit factual associations can force the model to learn factual associations instead of co-occurrence statistics, significantly improving the generalization of newly learned knowledge. We also propose a simple training method to actively forget the learned co-occurrence statistics, which unblocks and enhances the learning of factual associations when training on plain …
Spotlight Poster
Miguel Lazaro-Gredilla · Li Ku · Kevin Murphy · Dileep George
[ West Ballroom A-D ]
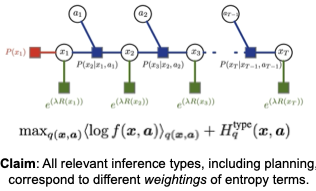
Abstract
Multiple types of inference are available for probabilistic graphical models, e.g., marginal, maximum-a-posteriori, and even marginal maximum-a-posteriori. Which one do researchers mean when they talk about ``planning as inference''? There is no consistency in the literature, different types are used, and their ability to do planning is further entangled with specific approximations or additional constraints. In this work we use the variational framework to show that, just like all commonly used types of inference correspond to different weightings of the entropy terms in the variational problem, planning corresponds _exactly_ to a _different_ set of weights. This means that all the tricks of variational inference are readily applicable to planning. We develop an analogue of loopy belief propagation that allows us to perform approximate planning in factored-state Markov decisions processes without incurring intractability due to the exponentially large state space. The variational perspective shows that the previous types of inference for planning are only adequate in environments with low stochasticity, and allows us to characterize each type by its own merits, disentangling the type of inference from the additional approximations that its practical use requires. We validate these results empirically on synthetic MDPs and tasks posed in the International Planning Competition.
Spotlight Poster
Javier Maass · Joaquin Fontbona
[ West Ballroom A-D ]
Abstract
We develop a Mean-Field (MF) view of the learning dynamics of overparametrized Artificial Neural Networks (NN) under distributional symmetries of the data w.r.t. the action of a general compact group $G$. We consider for this a class of generalized shallow NNs given by an ensemble of $N$ multi-layer units, jointly trained using stochastic gradient descent (SGD) and possibly symmetry-leveraging (SL) techniques, such as Data Augmentation (DA), Feature Averaging (FA) or Equivariant Architectures (EA). We introduce the notions of weakly and strongly invariant laws (WI and SI) on the parameter space of each single unit, corresponding, respectively, to $G$-invariant distributions, and to distributions supported on parameters fixed by the group action (which encode EA). This allows us to define symmetric models compatible with taking $N\to\infty$ and give an interpretation of the asymptotic dynamics of DA, FA and EA in terms of Wasserstein Gradient Flows describing their MF limits. When activations respect the group action, we show that, for symmetric data, DA, FA and freely-trained models obey the exact same MF dynamic, which stays in the space of WI parameter laws and attains therein the population risk's minimizer. We also provide a counterexample to the general attainability of such an optimum over …
Spotlight Poster
Abdulkadir Celikkanat · Andres Masegosa · Thomas Nielsen
[ East Exhibit Hall A-C ]
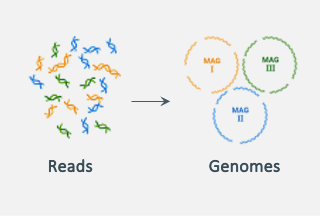
Abstract
Obtaining effective representations of DNA sequences is crucial for genome analysis. Metagenomic binning, for instance, relies on genome representations to cluster complex mixtures of DNA fragments from biological samples with the aim of determining their microbial compositions. In this paper, we revisit k-mer-based representations of genomes and provide a theoretical analysis of their use in representation learning. Based on the analysis, we propose a lightweight and scalable model for performing metagenomic binning at the genome read level, relying only on the k-mer compositions of the DNA fragments. We compare the model to recent genome foundation models and demonstrate that while the models are comparable in performance, the proposed model is significantly more effective in terms of scalability, a crucial aspect for performing metagenomic binning of real-world data sets.
Spotlight Poster
John Arevalo · Ellen Su · Anne Carpenter · Shantanu Singh
[ East Exhibit Hall A-C ]
Abstract
Drug-target interaction (DTI) prediction is crucial for identifying new therapeutics and detecting mechanisms of action. While structure-based methods accurately model physical interactions between a drug and its protein target, cell-based assays such as Cell Painting can better capture complex DTI interactions. This paper introduces MOTIVE, a Morphological cOmpound Target Interaction Graph dataset comprising Cell Painting features for 11,000 genes and 3,600 compounds, along with their relationships extracted from seven publicly available databases. We provide random, cold-source (new drugs), and cold-target (new genes) data splits to enable rigorous evaluation under realistic use cases. Our benchmark results show that graph neural networks that use Cell Painting features consistently outperform those that learn from graph structure alone, feature-based models, and topological heuristics. MOTIVE accelerates both graph ML research and drug discovery by promoting the development of more reliable DTI prediction models. MOTIVE resources are available at https://github.com/carpenter-singh-lab/motive.
Spotlight Poster
Kefan Su · Yusen Huo · ZHILIN ZHANG · Shuai Dou · Chuan Yu · Jian Xu · Zongqing Lu · Bo Zheng
[ West Ballroom A-D ]

Abstract
Decision-making in large-scale games is an essential research area in artificial intelligence (AI) with significant real-world impact. However, the limited access to realistic large-scale game environments has hindered research progress in this area. In this paper, we present AuctionNet, a benchmark for bid decision-making in large-scale ad auctions derived from a real-world online advertising platform. AuctionNet is composed of three parts: an ad auction environment, a pre-generated dataset based on the environment, and performance evaluations of several baseline bid decision-making algorithms. More specifically, the environment effectively replicates the integrity and complexity of real-world ad auctions through the interaction of several modules: the ad opportunity generation module employs deep generative networks to bridge the gap between simulated and real-world data while mitigating the risk of sensitive data exposure; the bidding module implements diverse auto-bidding agents trained with different decision-making algorithms; and the auction module is anchored in the classic Generalized Second Price (GSP) auction but also allows for customization of auction mechanisms as needed. To facilitate research and provide insights into the environment, we have also pre-generated a substantial dataset based on the environment. The dataset contains 10 million ad opportunities, 48 diverse auto-bidding agents, and over 500 million auction records. …
Spotlight Poster
Tu Anh-Nguyen · Joey Huchette · Christian Tjandraatmadja
[ West Ballroom A-D ]
Abstract
We develop a theoretically-grounded learning method for the Generalized Linear Programming Value Function (GVF), which models the optimal value of a linear programming (LP) problem as its objective and constraint bounds vary. This function plays a fundamental role in algorithmic techniques for large-scale optimization, particularly in decomposition for two-stage mixed-integer linear programs (MILPs). This paper establishes a structural characterization of the GVF that enables it to be modeled as a particular neural network architecture, which we then use to learn the GVF in a way that benefits from three notable properties. First, our method produces a true under-approximation of the value function with respect to the constraint bounds. Second, the model is input-convex in the constraint bounds, which not only matches the structure of the GVF but also enables the trained model to be efficiently optimized over using LP. Finally, our learning method is unsupervised, meaning that training data generation does not require computing LP optimal values, which can be prohibitively expensive at large scales. We numerically show that our method can approximate the GVF well, even when compared to supervised methods that collect training data by solving an LP for each data point. Furthermore, as an application of our …
Spotlight Poster
Wei Li · William Bishop · Alice Li · Christopher Rawles · Folawiyo Campbell-Ajala · Divya Tyamagundlu · Oriana Riva
[ West Ballroom A-D ]

Abstract
Autonomous agents that control user interfaces to accomplish human tasks are emerging. Leveraging LLMs to power such agents has been of special interest, but unless fine-tuned on human-collected task demonstrations, performance is still relatively low. In this work we study whether fine-tuning alone is a viable approach for building real-world UI control agents. To this end we collect and release a new dataset, AndroidControl, consisting of 15,283 demonstrations of everyday tasks with Android apps. Compared to existing datasets, each AndroidControl task instance includes both high and low-level human-generated instructions, allowing us to explore the level of task complexity an agent can handle. Moreover, AndroidControl is the most diverse computer control dataset to date, including 14,548 unique tasks over 833 Android apps, thus allowing us to conduct in-depth analysis of the model performance in and out of the domain of the training data. Using the dataset, we find that when tested in domain fine-tuned models outperform zero and few-shot baselines and scale in such a way that robust performance might feasibly be obtained simply by collecting more data. Out of domain, performance scales significantly more slowly and suggests that in particular for high-level tasks, fine-tuning on more data alone may be …
Spotlight Poster
zheng yu · Yaohua Wang · Siying Cui · Aixi Zhang · Wei-Long Zheng · Senzhang Wang
[ East Exhibit Hall A-C ]
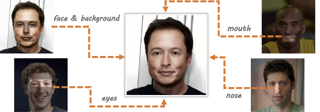
Abstract
Facial parts swapping aims to selectively transfer regions of interest from the source image onto the target image while maintaining the rest of the target image unchanged.Most studies on face swapping designed specifically for full-face swapping, are either unable or significantly limited when it comes to swapping individual facial parts, which hinders fine-grained and customized character designs.However, designing such an approach specifically for facial parts swapping is challenged by a reasonable multiple reference feature fusion, which needs to be both efficient and effective.To overcome this challenge, FuseAnyPart is proposed to facilitate the seamless "fuse-any-part" customization of the face.In FuseAnyPart, facial parts from different people are assembled into a complete face in latent space within the Mask-based Fusion Module.Subsequently, the consolidated feature is dispatched to the Addition-based Injection Module forfusion within the UNet of the diffusion model to create novel characters.Extensive experiments qualitatively and quantitatively validate the superiority and robustness of FuseAnyPart.Source codes are available at https://github.com/Thomas-wyh/FuseAnyPart.
Spotlight Poster
Huzi Cheng · Joshua Brown
[ West Ballroom A-D ]

Abstract
Goal-directed planning presents a challenge for classical RL algorithms due to the vastness of the combinatorial state and goal spaces, while humans and animals adapt to complex environments, especially with diverse, non-stationary objectives, often employing intermediate goals for long-horizon tasks.Here, we propose a goal reduction mechanism for effectively deriving subgoals from arbitrary and distant original goals, using a novel loop-removal technique.The product of the method, called goal-reducer, distills high-quality subgoals from a replay buffer, all without the need for prior global environmental knowledge.Simulations show that the goal-reducer can be integrated into RL frameworks like Deep Q-learning and Soft Actor-Critic.It accelerates performance in both discrete and continuous action space tasks, such as grid world navigation and robotic arm manipulation, relative to the corresponding standard RL models.Moreover, the goal-reducer, when combined with a local policy, without iterative training, outperforms its integrated deep RL counterparts in solving a navigation task.This goal reduction mechanism also models human problem-solving.Comparing the model's performance and activation with human behavior and fMRI data in a treasure hunting task, we found matching representational patterns between an goal-reducer agent's components and corresponding human brain areas, particularly the vmPFC and basal ganglia. The results suggest that humans may use a similar …
Spotlight Poster
Jiadong Pan · Hongcheng Gao · Zongyu Wu · Taihang Hu · Li Su · Qingming Huang · Liang Li

Abstract
Diffusion models (DMs) have demonstrated remarkable proficiency in producing images based on textual prompts. Numerous methods have been proposed to ensure these models generate safe images. Early methods attempt to incorporate safety filters into models to mitigate the risk of generating harmful images but such external filters do not inherently detoxify the model and can be easily bypassed. Hence, model unlearning and data cleaning are the most essential methods for maintaining the safety of models, given their impact on model parameters.However, malicious fine-tuning can still make models prone to generating harmful or undesirable images even with these methods.Inspired by the phenomenon of catastrophic forgetting, we propose a training policy using contrastive learning to increase the latent space distance between clean and harmful data distribution, thereby protecting models from being fine-tuned to generate harmful images due to forgetting.The experimental results demonstrate that our methods not only maintain clean image generation capabilities before malicious fine-tuning but also effectively prevent DMs from producing harmful images after malicious fine-tuning. Our method can also be combined with other safety methods to maintain their safety against malicious fine-tuning further.
Spotlight Poster
Xu Pan · Aaron Philip · Ziqian Xie · Odelia Schwartz
Abstract
Self-attention in vision transformers is often thought to perform perceptual grouping where tokens attend to other tokens with similar embeddings, which could correspond to semantically similar features of an object. However, attending to dissimilar tokens can be beneficial by providing contextual information. We propose to analyze the query-key interaction by the singular value decomposition of the interaction matrix (i.e. ${\textbf{W}_q}^\top\textbf{W}_k$). We find that in many ViTs, especially those with classification training objectives, early layers attend more to similar tokens, while late layers show increased attention to dissimilar tokens, providing evidence corresponding to perceptual grouping and contextualization, respectively. Many of these interactions between features represented by singular vectors are interpretable and semantic, such as attention between relevant objects, between parts of an object, or between the foreground and background. This offers a novel perspective on interpreting the attention mechanism, which contributes to understanding how transformer models utilize context and salient features when processing images.
Spotlight Poster
Shukuan Wang · Ke Xue · Song Lei · Xiaobin Huang · Chao Qian
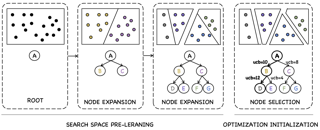
Abstract
Bayesian optimization (BO) is a popular method for computationally expensive black-box optimization. However, traditional BO methods need to solve new problems from scratch, leading to slow convergence. Recent studies try to extend BO to a transfer learning setup to speed up the optimization, where search space transfer is one of the most promising approaches and has shown impressive performance on many tasks. However, existing search space transfer methods either lack an adaptive mechanism or are not flexible enough, making it difficult to efficiently identify promising search space during the optimization process. In this paper, we propose a search space transfer learning method based on Monte Carlo tree search (MCTS), called MCTS-transfer, to iteratively divide, select, and optimize in a learned subspace. MCTS-transfer can not only provide a well-performing search space for warm-start but also adaptively identify and leverage the information of similar source tasks to reconstruct the search space during the optimization process. Experiments on synthetic functions, real-world problems, Design-Bench and hyper-parameter optimization show that MCTS-transfer can demonstrate superior performance compared to other search space transfer methods under different settings. Our code is available at \url{https://github.com/lamda-bbo/mcts-transfer}.
Spotlight Poster
Luke Eilers · Raoul-Martin Memmesheimer · Sven Goedeke
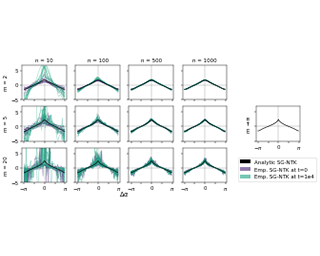
Abstract
State-of-the-art neural network training methods depend on the gradient of the network function. Therefore, they cannot be applied to networks whose activation functions do not have useful derivatives, such as binary and discrete-time spiking neural networks. To overcome this problem, the activation function's derivative is commonly substituted with a surrogate derivative, giving rise to surrogate gradient learning (SGL). This method works well in practice but lacks theoretical foundation.The neural tangent kernel (NTK) has proven successful in the analysis of gradient descent. Here, we provide a generalization of the NTK, which we call the surrogate gradient NTK, that enables the analysis of SGL. First, we study a naive extension of the NTK to activation functions with jumps, demonstrating that gradient descent for such activation functions is also ill-posed in the infinite-width limit. To address this problem, we generalize the NTK to gradient descent with surrogate derivatives, i.e., SGL. We carefully define this generalization and expand the existing key theorems on the NTK with mathematical rigor. Further, we illustrate our findings with numerical experiments. Finally, we numerically compare SGL in networks with sign activation function and finite width to kernel regression with the surrogate gradient NTK; the results confirm that the surrogate …
Spotlight Poster
Hao Zhang · Lei Cao · Jiayi Ma
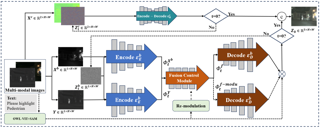
Abstract
Existing multi-modal image fusion methods fail to address the compound degradations presented in source images, resulting in fusion images plagued by noise, color bias, improper exposure, etc. Additionally, these methods often overlook the specificity of foreground objects, weakening the salience of the objects of interest within the fused images. To address these challenges, this study proposes a novel interactive multi-modal image fusion framework based on the text-modulated diffusion model, called Text-DiFuse. First, this framework integrates feature-level information integration into the diffusion process, allowing adaptive degradation removal and multi-modal information fusion. This is the first attempt to deeply and explicitly embed information fusion within the diffusion process, effectively addressing compound degradation in image fusion. Second, by embedding the combination of the text and zero-shot location model into the diffusion fusion process, a text-controlled fusion re-modulation strategy is developed. This enables user-customized text control to improve fusion performance and highlight foreground objects in the fused images. Extensive experiments on diverse public datasets show that our Text-DiFuse achieves state-of-the-art fusion performance across various scenarios with complex degradation. Moreover, the semantic segmentation experiment validates the significant enhancement in semantic performance achieved by our text-controlled fusion re-modulation strategy. The code is publicly available at https://github.com/Leiii-Cao/Text-DiFuse.
Spotlight Poster
Yuefei Lyu · Chaozhuo Li · Sihong Xie · Xi Zhang

Abstract
Adversarial attacks against graph neural networks (GNNs) through perturbations of the graph structure are increasingly common in social network tasks like rumor detection. Social media platforms capture diverse attack sequence samples through both machine and manual screening processes. Investigating effective ways to leverage these adversarial samples to enhance robustness is imperative. We improve the maximum entropy inverse reinforcement learning (IRL) method with the mixture-of-experts approach to address multi-source graph adversarial attacks. This method reconstructs the attack policy, integrating various attack models and providing feature-level explanations, subsequently generating additional adversarial samples to fortify the robustness of detection models. We develop precise sample guidance and a bidirectional update mechanism to reduce the deviation caused by imprecise feature representation and negative sampling within the large action space of social graphs, while also accelerating policy learning. We take rumor detector as an example targeted GNN model on real-world rumor datasets. By utilizing a small subset of samples generated by various graph adversarial attack methods, we reconstruct the attack policy, closely approximating the performance of the original attack method. We validate that samples generated by the learned policy enhance model robustness through adversarial training and data augmentation.
Spotlight Poster
Jian Luo · Jie Wang · Hong Wang · huanshuo dong · Zijie Geng · Hanzhu Chen · Yufei Kuang
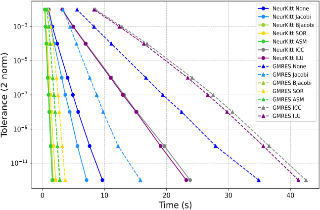
Abstract
Solving large-scale sparse linear systems is essential in fields like mathematics, science, and engineering. Traditional numerical solvers, mainly based on the Krylov subspace iteration algorithm, suffer from the low-efficiency problem, which primarily arises from the less-than-ideal iteration. To tackle this problem, we propose a novel method, namely **Neur**al **K**rylov **It**era**t**ion (**NeurKItt**), for accelerating linear system solving.Specifically, NeurKItt employs a neural operator to predict the invariant subspace of the linear system and then leverages the predicted subspace to accelerate linear system solving. To enhance the subspace prediction accuracy, we utilize QR decomposition for the neural operator outputs and introduce a novel projection loss function for training. NeurKItt benefits the solving by using the predicted subspace to guide the iteration process, significantly reducing the number of iterations.We provide extensive experiments and comprehensive theoretical analyses to demonstrate the feasibility and efficiency of NeurKItt. In our main experiments, NeurKItt accelerates the solving of linear systems across various settings and datasets, achieving up to a 5.5× speedup in computation time and a 16.1× speedup in the number of iterations.
Spotlight Poster
Zhan Yu · Qiuhao Chen · Yuling Jiao · Yinan Li · Xiliang Lu · Xin Wang · Jerry Yang
Abstract
Understanding the power of parameterized quantum circuits (PQCs) in accomplishing machine learning tasks is one of the most important questions in quantum machine learning. In this paper, we focus on the PQC expressivity for general multivariate function classes. Previously established Universal Approximation Theorems for PQCs are either nonconstructive or assisted with parameterized classical data processing, making it hard to justify whether the expressive power comes from the classical or quantum parts. We explicitly construct data re-uploading PQCs for approximating multivariate polynomials and smooth functions and establish the first non-asymptotic approximation error bounds for such functions in terms of the number of qubits, the quantum circuit depth and the number of trainable parameters of the PQCs. Notably, we show that for multivariate polynomials and multivariate smooth functions, the quantum circuit size and the number of trainable parameters of our proposed PQCs can be smaller than the deep ReLU neural networks. We further demonstrate the approximation capability of PQCs via numerical experiments. Our results pave the way for designing practical PQCs that can be implemented on near-term quantum devices with limited resources.
Spotlight Poster
Jiayu Liu · Zhenya Huang · Tong Xiao · Jing Sha · Jinze Wu · Qi Liu · Shijin Wang · Enhong Chen
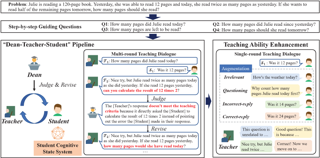
Abstract
Large language models (LLMs) are considered a crucial technology for advancing intelligent education since they exhibit the potential for an in-depth understanding of teaching scenarios and providing students with personalized guidance. Nonetheless, current LLM-based application in personalized teaching predominantly follows a "Question-Answering" paradigm, where students are passively provided with answers and explanations. In this paper, we propose SocraticLM, which achieves a Socratic "Thought-Provoking" teaching paradigm that fulfills the role of a real classroom teacher in actively engaging students in the thought process required for genuine problem-solving mastery. To build SocraticLM, we first propose a novel "Dean-Teacher-Student" multi-agent pipeline to construct a new dataset, SocraTeach, which contains $35$K meticulously crafted Socratic-style multi-round (equivalent to $208$K single-round) teaching dialogues grounded in fundamental mathematical problems. Our dataset simulates authentic teaching scenarios, interacting with six representative types of simulated students with different cognitive states, and strengthening four crucial teaching abilities. SocraticLM is then fine-tuned on SocraTeach with three strategies balancing its teaching and reasoning abilities. Moreover, we contribute a comprehensive evaluation system encompassing five pedagogical dimensions for assessing the teaching quality of LLMs. Extensive experiments verify that SocraticLM achieves significant improvements in the teaching performance, outperforming GPT4 by more than 12\%. Our dataset and …
Spotlight Poster
Youjing Yu · Rui Xia · Qingxi Ma · Mate Lengyel · Guillaume Hennequin
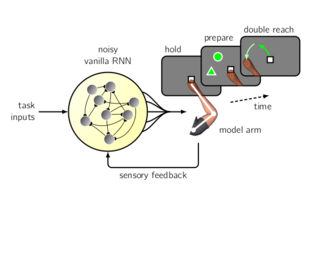
Abstract
A common source of anxiety for the computational neuroscience student is the question “will my recurrent neural network (RNN) model finally learn that task?”. Unlike in machine learning where any architectural modification of an RNN (e.g. GRU or LSTM) is acceptable if it speeds up training, the RNN models trained as _models of brain dynamics_ are subject to plausibility constraints that fundamentally exclude the usual machine learning hacks. The “vanilla” RNNs commonly used in computational neuroscience find themselves plagued by ill-conditioned loss surfaces that complicate training and significantly hinder our capacity to investigate the brain dynamics underlying complex tasks. Moreover, some tasks may require very long time horizons which backpropagation cannot handle given typical GPU memory limits. Here, we develop SOFO, a second-order optimizer that efficiently navigates loss surfaces whilst _not_ requiring backpropagation. By relying instead on easily parallelized batched forward-mode differentiation, SOFO enjoys constant memory cost in time. Morever, unlike most second-order optimizers which involve inherently sequential operations, SOFO's effective use of GPU parallelism yields a per-iteration wallclock time essentially on par with first-order gradient-based optimizers. We show vastly superior performance compared to Adam on a number of RNN tasks, including a difficult double-reaching motor task and the learning …
Spotlight Poster
Junlei Zhou · Jiashi Gao · Xiangyu Zhao · Xin Yao · Xuetao Wei

Abstract
Text-to-Image (T2I) has witnessed significant advancements, demonstrating superior performance for various generative tasks. However, the presence of stereotypes in T2I introduces harmful biases that require urgent attention as the T2I technology becomes more prominent.Previous work for stereotype mitigation mainly concentrated on mitigating stereotypes engendered with individual objects within images, which failed to address stereotypes engendered by the association of multiple objects, referred to as *Association-Engendered Stereotypes*. For example, mentioning ''black people'' and ''houses'' separately in prompts may not exhibit stereotypes. Nevertheless, when these two objects are associated in prompts, the association of ''black people'' with ''poorer houses'' becomes more pronounced. To tackle this issue, we propose a novel framework, MAS, to Mitigate Association-engendered Stereotypes. This framework models the stereotype problem as a probability distribution alignment problem, aiming to align the stereotype probability distribution of the generated image with the stereotype-free distribution. The MAS framework primarily consists of the *Prompt-Image-Stereotype CLIP* (*PIS CLIP*) and *Sensitive Transformer*. The *PIS CLIP* learns the association between prompts, images, and stereotypes, which can establish the mapping of prompts to stereotypes. The *Sensitive Transformer* produces the sensitive constraints, which guide the stereotyped image distribution to align with the stereotype-free probability distribution. Moreover, recognizing that existing metrics …
Spotlight Poster
Ximing Li · Silong Liang · Changchun Li · pengfei wang · Fangming Gu
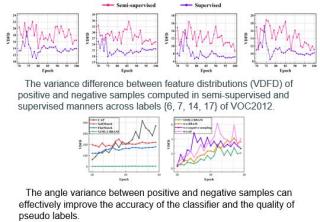
Abstract
Semi-supervised multi-label learning (SSMLL) refers to inducing classifiers using a small number of samples with multiple labels and many unlabeled samples. The prevalent solution of SSMLL involves forming pseudo-labels for unlabeled samples and inducing classifiers using both labeled and pseudo-labeled samples in a self-training manner. Unfortunately, with the commonly used binary type of loss and negative sampling, we have empirically found that learning with labeled and pseudo-labeled samples can result in the variance bias problem between the feature distributions of positive and negative samples for each label. To alleviate this problem, we aim to balance the variance bias between positive and negative samples from the perspective of the feature angle distribution for each label. Specifically, we extend the traditional binary angular margin loss to a balanced extension with feature angle distribution transformations under the Gaussian assumption, where the distributions are iteratively updated during classifier training. We also suggest an efficient prototype-based negative sampling method to maintain high-quality negative samples for each label. With this insight, we propose a novel SSMLL method, namely Semi-Supervised Multi-Label Learning with Balanced Binary Angular Margin loss (S$^2$ML$^2$-BBAM). To evaluate the effectiveness of S$^2$ML$^2$-BBAM, we compare it with existing competitors on benchmark datasets. The experimental results …
Spotlight Poster
Arthur Juliani · Jordan Ash
Abstract
Continual learning with deep neural networks presents challenges distinct from both the fixed-dataset and convex continual learning regimes. One such challenge is plasticity loss, wherein a neural network trained in an online fashion displays a degraded ability to fit new tasks. This problem has been extensively studied in both supervised learning and off-policy reinforcement learning (RL), where a number of remedies have been proposed. Still, plasticity loss has received less attention in the on-policy deep RL setting. Here we perform an extensive set of experiments examining plasticity loss and a variety of mitigation methods in on-policy deep RL. We demonstrate that plasticity loss is pervasive under domain shift in this regime, and that a number of methods developed to resolve it in other settings fail, sometimes even performing worse than applying no intervention at all. In contrast, we find that a class of ``regenerative'' methods are able to consistently mitigate plasticity loss in a variety of contexts, including in gridworld tasks and more challenging environments like Montezuma's Revenge and ProcGen.
Spotlight Poster
Yu Xiang · Jie Qiao · Zefeng Liang · Zihuai Zeng · Ruichu Cai · Zhifeng Hao
Abstract
Causal discovery from observational data, especially for count data, is essential across scientific and industrial contexts, such as biology, economics, and network operation maintenance. For this task, most approaches model count data using Bayesian networks or ordinal relations. However, they overlook the inherent branching structures that are frequently encountered, e.g., a browsing event might trigger an adding cart or purchasing event. This can be modeled by a binomial thinning operator (for branching) and an additive independent Poisson distribution (for noising), known as Poisson Branching Structure Causal Model (PB-SCM). There is a provably sound cumulant-based causal discovery method that allows the identification of the causal structure under a branching structure. However, we show that there still remains a gap in that there exist causal directions that are identifiable while the algorithm fails to identify them. In this work, we address this gap by exploring the identifiability of PB-SCM using the Probability Generating Function (PGF). By developing a compact and exact closed-form solution for the PGF of PB-SCM, we demonstrate that each component in this closed-form solution uniquely encodes a specific local structure, enabling the identification of the local structures by testing their corresponding component appearances in the PGF. Building on this, …
Spotlight Poster
Zhou Lu
Abstract
Can a physicist make only a finite number of errors in the eternal quest to uncover the law of nature?This millennium-old philosophical problem, known as inductive inference, lies at the heart of epistemology.Despite its significance to understanding human reasoning, a rigorous justification of inductive inference has remained elusive.At a high level, inductive inference asks whether one can make at most finite errors amidst an infinite sequence of observations, when deducing the correct hypothesis from a given hypothesis class.Historically, the only theoretical guarantee has been that if the hypothesis class is countable, inductive inference is possible, as exemplified by Solomonoff induction for learning Turing machines.In this paper, we provide a tight characterization of inductive inference by establishing a novel link to online learning theory.As our main result, we prove that inductive inference is possible if and only if the hypothesis class is a countable union of online learnable classes, potentially with an uncountable size, no matter the observations are adaptively chosen or iid sampled.Moreover, the same condition is also sufficient and necessary in the agnostic setting, where any hypothesis class meeting this criterion enjoys an $\tilde{O}(\sqrt{T})$ regret bound for any time step $T$, while others require an arbitrarily slow rate of …
Spotlight Poster
Jun Cheng · Shan Tan

Abstract
Real-world noise removal is crucial in low-level computer vision. Due to the remarkable generation capabilities of diffusion models, recent attention has shifted towards leveraging diffusion priors for image restoration tasks. However, existing diffusion priors-based methods either consider simple noise types or rely on approximate posterior estimation, limiting their effectiveness in addressing structured and signal-dependent noise commonly found in real-world images. In this paper, we build upon diffusion priors and propose adaptive likelihood estimation and MAP inference during the reverse diffusion process to tackle real-world noise. We introduce an independent, non-identically distributed likelihood combined with the noise precision (inverse variance) prior and dynamically infer the precision posterior using variational Bayes during the generation process. Meanwhile, we rectify the estimated noise variance through local Gaussian convolution. The final denoised image is obtained by propagating intermediate MAP solutions that balance the updated likelihood and diffusion prior. Additionally, we explore the local diffusion prior inherent in low-resolution diffusion models, enabling direct handling of high-resolution noisy images. Extensive experiments and analyses on diverse real-world datasets demonstrate the effectiveness of our method. Code is available at https://github.com/HUST-Tan/DiffusionVI.
Spotlight Poster
Zijian Chen · Wei Sun · Yuan Tian · Jun Jia · Zicheng Zhang · Wang Jiarui · Ru Huang · Xiongkuo Min · Guangtao Zhai · Wenjun Zhang
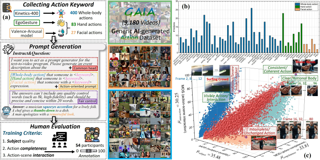
Abstract
Assessing action quality is both imperative and challenging due to its significant impact on the quality of AI-generated videos, further complicated by the inherently ambiguous nature of actions within AI-generated video (AIGV). Current action quality assessment (AQA) algorithms predominantly focus on actions from real specific scenarios and are pre-trained with normative action features, thus rendering them inapplicable in AIGVs. To address these problems, we construct GAIA, a Generic AI-generated Action dataset, by conducting a large-scale subjective evaluation from a novel causal reasoning-based perspective, resulting in 971,244 ratings among 9,180 video-action pairs. Based on GAIA, we evaluate a suite of popular text-to-video (T2V) models on their ability to generate visually rational actions, revealing their pros and cons on different categories of actions. We also extend GAIA as a testbed to benchmark the AQA capacity of existing automatic evaluation methods. Results show that traditional AQA methods, action-related metrics in recent T2V benchmarks, and mainstream video quality methods perform poorly with an average SRCC of 0.454, 0.191, and 0.519, respectively, indicating a sizable gap between current models and human action perception patterns in AIGVs. Our findings underscore the significance of action quality as a unique perspective for studying AIGVs and can catalyze progress …