Spotlight Poster
MotionBooth: Motion-Aware Customized Text-to-Video Generation
Jianzong Wu · Xiangtai Li · Yanhong Zeng · Jiangning Zhang · Qianyu Zhou · Yining Li · Yunhai Tong · Kai Chen
East Exhibit Hall A-C #1807
{kind=link}
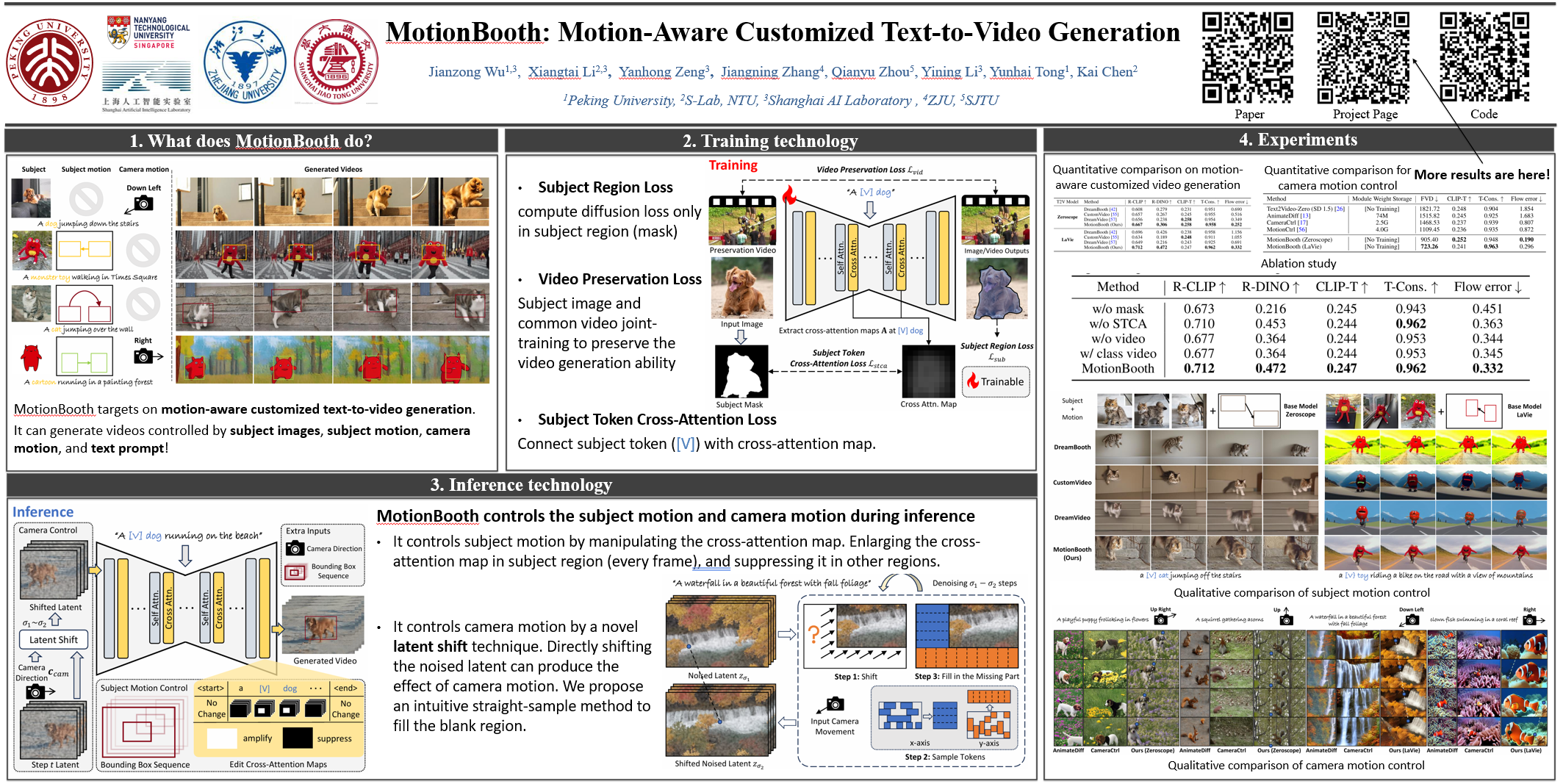
In this work, we present MotionBooth, an innovative framework designed for animating customized subjects with precise control over both object and camera movements. By leveraging a few images of a specific object, we efficiently fine-tune a text-to-video model to capture the object's shape and attributes accurately. Our approach presents subject region loss and video preservation loss to enhance the subject's learning performance, along with a subject token cross-attention loss to integrate the customized subject with motion control signals. Additionally, we propose training-free techniques for managing subject and camera motions during inference. In particular, we utilize cross-attention map manipulation to govern subject motion and introduce a novel latent shift module for camera movement control as well. MotionBooth excels in preserving the appearance of subjects while simultaneously controlling the motions in generated videos. Extensive quantitative and qualitative evaluations demonstrate the superiority and effectiveness of our method. Models and codes will be made publicly available.