Poster
Yuqi Wang · Ke Cheng · Jiawei He · Qitai Wang · Hengchen Dai · Yuntao Chen · Fei Xia · ZHAO-XIANG ZHANG
[ West Ballroom A-D ]
Abstract
Driving world models have gained increasing attention due to their ability to model complex physical dynamics. However, their superb modeling capability is yet to be fully unleashed due to the limited video diversity in current driving datasets. We introduce DrivingDojo, the first dataset tailor-made for training interactive world models with complex driving dynamics. Our dataset features video clips with a complete set of driving maneuvers, diverse multi-agent interplay, and rich open-world driving knowledge, laying a stepping stone for future world model development. We further define an action instruction following (AIF) benchmark for world models and demonstrate the superiority of the proposed dataset for generating action-controlled future predictions.
Poster
Shraman Pramanick · Rama Chellappa · Subhashini Venugopalan
[ East Exhibit Hall A-C ]

Abstract
Seeking answers to questions within long scientific research articles is a crucial area of study that aids readers in quickly addressing their inquiries. However, existing question-answering (QA) datasets based on scientific papers are limited in scale and focus solely on textual content. We introduce SPIQA (Scientific Paper Image Question Answering), the first large-scale QA dataset specifically designed to interpret complex figures and tables within the context of scientific research articles across various domains of computer science. Leveraging the breadth of expertise and ability of multimodal large language models (MLLMs) to understand figures, we employ automatic and manual curation to create the dataset. We craft an information-seeking task on interleaved images and text that involves multiple images covering a wide variety of plots, charts, tables, schematic diagrams, and result visualizations. SPIQA comprises 270K questions divided into training, validation, and three different evaluation splits. Through extensive experiments with 12 prominent foundational models, we evaluate the ability of current multimodal systems to comprehend the nuanced aspects of research articles. Additionally, we propose a Chain-of-Thought (CoT) evaluation strategy with in-context retrieval that allows fine-grained, step-by-step assessment and improves model performance. We further explore the upper bounds of performance enhancement with additional textual information, highlighting …
Poster
Sahar Abdelnabi · Amr Gomaa · Sarath Sivaprasad · Lea Schönherr · Mario Fritz
[ West Ballroom A-D ]
Abstract
There is a growing interest in using Large Language Models (LLMs) in multi-agent systems to tackle interactive real-world tasks that require effective collaboration and assessing complex situations. Yet, we have a limited understanding of LLMs' communication and decision-making abilities in multi-agent setups. The fundamental task of negotiation spans many key features of communication, such as cooperation, competition, and manipulation potentials. Thus, we propose using scorable negotiation to evaluate LLMs. We create a testbed of complex multi-agent, multi-issue, and semantically rich negotiation games. To reach an agreement, agents must have strong arithmetic, inference, exploration, and planning capabilities while integrating them in a dynamic and multi-turn setup. We propose metrics to rigorously quantify agents' performance and alignment with the assigned role. We provide procedures to create new games and increase games' difficulty to have an evolving benchmark. Importantly, we evaluate critical safety aspects such as the interaction dynamics between agents influenced by greedy and adversarial players. Our benchmark is highly challenging; GPT-3.5 and small models mostly fail, and GPT-4 and SoTA large models (e.g., Llama-3 70b) still underperform in reaching agreement in non-cooperative and more difficult games.
Oral Poster
Hannah Rose Kirk · Alexander Whitefield · Paul Rottger · Andrew M. Bean · Katerina Margatina · Rafael Mosquera-Gomez · Juan Ciro · Max Bartolo · Adina Williams · He He · Bertie Vidgen · Scott Hale
[ West Ballroom A-D ]
Abstract
Human feedback is central to the alignment of Large Language Models (LLMs). However, open questions remain about the methods (how), domains (where), people (who) and objectives (to what end) of feedback processes. To navigate these questions, we introduce PRISM, a new dataset which maps the sociodemographics and stated preferences of 1,500 diverse participants from 75 countries, to their contextual preferences and fine-grained feedback in 8,011 live conversations with 21 LLMs. With PRISM, we contribute (i) wider geographic and demographic participation in feedback; (ii) census-representative samples for two countries (UK, US); and (iii) individualised ratings that link to detailed participant profiles, permitting personalisation and attribution of sample artefacts. We target subjective and multicultural perspectives on value-laden and controversial issues, where we expect interpersonal and cross-cultural disagreement. We use PRISM in three case studies to demonstrate the need for careful consideration of which humans provide alignment data.
Poster
Mehreen Saeed · Adrian Chan · Anupam Mijar · joseph Moukarzel · Gerges Habchi · Carlos Younes · amin elias · Chau-Wai Wong · Akram Khater
[ West Ballroom A-D ]

Abstract
We present the Manuscripts of Handwritten Arabic (Muharaf) dataset, which is a machine learning dataset consisting of more than 1,600 historic handwritten page images transcribed by experts in archival Arabic. Each document image is accompanied by spatial polygonal coordinates of its text lines as well as basic page elements. This dataset was compiled to advance the state of the art in handwritten text recognition (HTR), not only for Arabic manuscripts but also for cursive text in general. The Muharaf dataset includes diverse handwriting styles and a wide range of document types, including personal letters, diaries, notes, poems, church records, and legal correspondences. In this paper, we describe the data acquisition pipeline, notable dataset features, and statistics. We also provide a preliminary baseline result achieved by training convolutional neural networks using this data.
Poster
Jovin Leong · Koa Di · Benjamin Cham · Shaun Heng
[ West Ballroom A-D ]

Abstract
A frequent problem in vision-based reasoning tasks such as object detection and optical character recognition (OCR) is the persistence of specular highlights. Specular highlights appear as bright spots of glare that occur due to the concentrated reflection of light; these spots manifest as image artifacts which occlude computer vision models and are challenging to reconstruct. Despite this, specular highlight removal receives relatively little attention due to the difficulty of acquiring high-quality, real-world data. We introduce a method to generate specular highlight data with near-perfect alignment and present SHDocs—a dataset of specular highlights on document images created using our method. Through our benchmark, we demonstrate that our dataset enables us to surpass the performance of state-of-the-art specular highlight removal models and downstream OCR tasks. We release our dataset, code, and methods publicly to motivate further exploration of image enhancement for practical computer vision challenges.
Poster
MaryBeth Defrance · Maarten Buyl · Tijl De Bie
[ West Ballroom A-D ]
Abstract
Numerous methods have been implemented that pursue fairness with respect to sensitive features by mitigating biases in machine learning. Yet, the problem settings that each method tackles vary significantly, including the stage of intervention, the composition of sensitive features, the fairness notion, and the distribution of the output. Even in binary classification, the greatest common denominator of problem settings is small, significantly complicating benchmarking.Hence, we introduce ABCFair, a benchmark approach which allows adapting to the desiderata of the real-world problem setting, enabling proper comparability between methods for any use case. We apply this benchmark to a range of pre-, in-, and postprocessing methods on both large-scale, traditional datasets and on a dual label (biased and unbiased) dataset to sidestep the fairness-accuracy trade-off.
Poster
Anisha Pal · Julia Kruk · Mansi Phute · Manognya Bhattaram · Diyi Yang · Duen Horng Chau · Judy Hoffman
[ West Ballroom A-D ]
Abstract
Text-to-image diffusion models have impactful applications in art, design, and entertainment, yet these technologies also pose significant risks by enabling the creation and dissemination of misinformation. Although recent advancements have produced AI-generated image detectors that claim robustness against various augmentations, their true effectiveness remains uncertain. Do these detectors reliably identify images with different levels of augmentation? Are they biased toward specific scenes or data distributions? To investigate, we introduce **Semi-Truths**, featuring $27,600$ real images, $223,400$ masks, and $1, 329, 155$ AI-augmented images that feature targeted and localized perturbations produced using diverse augmentation techniques, diffusion models, and data distributions. Each augmented image is accompanied by metadata for standardized and targeted evaluation of detector robustness. Our findings suggest that state-of-the-art detectors exhibit varying sensitivities to the types and degrees of perturbations, data distributions, and augmentation methods used, offering new insights into their performance and limitations. The code for the augmentation and evaluation pipeline is available at https://github.com/J-Kruk/SemiTruths.
Poster
Akshatha Arodi · Margaux Luck · Jean-Luc Bedwani · Aldo Zaimi · Ge Li · Nicolas Pouliot · Julien Beaudry · Gaetan Marceau Caron
[ West Ballroom A-D ]

Abstract
Machine learning models are increasingly being deployed in real-world contexts. However, systematic studies on their transferability to specific and critical applications are underrepresented in the research literature. An important example is visual anomaly detection (VAD) for robotic power line inspection. While existing VAD methods perform well in controlled environments, real-world scenarios present diverse and unexpected anomalies that current datasets fail to capture. To address this gap, we introduce CableInspect-AD, a high-quality, publicly available dataset created and annotated by domain experts from Hydro-Québec, a Canadian public utility. This dataset includes high-resolution images with challenging real-world anomalies, covering defects with varying severity levels. To address the challenges of collecting diverse anomalous and nominal examples for setting a detection threshold, we propose an enhancement to the celebrated PatchCore algorithm. This enhancement enables its use in scenarios with limited labeled data. We also present a comprehensive evaluation protocol based on cross-validation to assess models' performances. We evaluate our Enhanced-PatchCore for few-shot and many-shot detection, and Vision-Language Models for zero-shot detection. While promising, these models struggle to detect all anomalies, highlighting the dataset's value as a challenging benchmark for the broader research community. Project page: https://mila-iqia.github.io/cableinspect-ad/.
Poster
Houlun Chen · Xin Wang · Hong Chen · Zeyang Zhang · Wei Feng · Bin Huang · Jia Jia · Wenwu Zhu
[ West Ballroom A-D ]
Abstract
Existing Video Corpus Moment Retrieval (VCMR) is limited to coarse-grained understanding that hinders precise video moment localization when given fine-grained queries. In this paper, we propose a more challenging fine-grained VCMR benchmark requiring methods to localize the best-matched moment from the corpus with other partially matched candidates. To improve the dataset construction efficiency and guarantee high-quality data annotations, we propose VERIFIED, an automatic \underline{V}id\underline{E}o-text annotation pipeline to generate captions with \underline{R}el\underline{I}able \underline{FI}n\underline{E}-grained statics and \underline{D}ynamics. Specifically, we resort to large language models (LLM) and large multimodal models (LMM) with our proposed Statics and Dynamics Enhanced Captioning modules to generate diverse fine-grained captions for each video. To filter out the inaccurate annotations caused by the LLM hallucination, we propose a Fine-Granularity Aware Noise Evaluator where we fine-tune a video foundation model with disturbed hard-negatives augmented contrastive and matching losses. With VERIFIED, we construct a more challenging fine-grained VCMR benchmark containing Charades-FIG, DiDeMo-FIG, and ActivityNet-FIG which demonstrate a high level of annotation quality. We evaluate several state-of-the-art VCMR models on the proposed dataset, revealing that there is still significant scope for fine-grained video understanding in VCMR.
Poster
Jiasheng Zhang · Jialin Chen · Menglin Yang · Aosong Feng · Shuang Liang · Jie Shao · Rex Ying
[ West Ballroom A-D ]

Abstract
Dynamic text-attributed graphs (DyTAGs) are prevalent in various real-world scenarios, where each node and edge are associated with text descriptions, and both the graph structure and text descriptions evolve over time. Despite their broad applicability, there is a notable scarcity of benchmark datasets tailored to DyTAGs, which hinders the potential advancement in many research fields. To address this gap, we introduce Dynamic Text-attributed Graph Benchmark (DTGB), a collection of large-scale, time-evolving graphs from diverse domains, with nodes and edges enriched by dynamically changing text attributes and categories. To facilitate the use of DTGB, we design standardized evaluation procedures based on four real-world use cases: future link prediction, destination node retrieval, edge classification, and textual relation generation. These tasks require models to understand both dynamic graph structures and natural language, highlighting the unique challenges posed by DyTAGs. Moreover, we conduct extensive benchmark experiments on DTGB, evaluating 7 popular dynamic graph learning algorithms and their variants of adapting to text attributes with LLM embeddings, along with 6 powerful large language models (LLMs). Our results show the limitations of existing models in handling DyTAGs. Our analysis also demonstrates the utility of DTGB in investigating the incorporation of structural and textual dynamics. The proposed …
Poster
Matthew Allen · Francisco Dorr · Joseph Alejandro Gallego Mejia · Laura Martínez-Ferrer · Anna Jungbluth · Freddie Kalaitzis · Raul Ramos-Pollán
[ East Exhibit Hall A-C ]

Abstract
Satellite-based remote sensing has revolutionised the way we address global challenges in a rapidly evolving world. Huge quantities of Earth Observation (EO) data are generated by satellite sensors daily, but processing these large datasets for use in ML pipelines is technically and computationally challenging. Specifically, different types of EO data are often hosted on a variety of platforms, withdiffering degrees of availability for Python preprocessing tools. In addition, spatial alignment across data sources and data tiling for easier handling can present significant technical hurdles for novice users. While some preprocessed Earth observation datasets exist, their content is often limited to optical or near-optical wavelength data, which is ineffective at night or in adverse weather conditions.Synthetic Aperture Radar (SAR), an active sensing technique based on microwave length radiation, offers a viable alternative. However, the application of machine learning to SAR has been limited due to a lack of ML-ready data and pipelines, particularly for the full diversity of SAR data, including polarimetry, coherence and interferometry. In this work, we introduce M3LEO, a multi-modal, multi-labelEarth observation dataset that includes polarimetric, interferometric, and coherence SAR data derived from Sentinel-1, alongside multispectral Sentinel-2 imagery and a suite of auxiliary data describing terrain properties such …
Poster
Dan Zhang · Ziniu Hu · Sining Zhoubian · Zhengxiao Du · Kaiyu Yang · Zihan Wang · Yisong Yue · Yuxiao Dong · Jie Tang
[ West Ballroom A-D ]
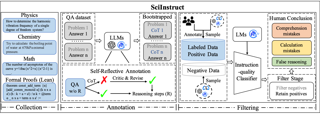
Abstract
Large Language Models (LLMs) have shown promise in assisting scientific discovery. However, such applications are currently limited by LLMs' deficiencies in understanding intricate scientific concepts, deriving symbolic equations, and solving advanced numerical calculations. To bridge these gaps, we introduce SciInstruct, a suite of scientific instructions for training scientific language models capable of college-level scientific reasoning. Central to our approach is a novel self-reflective instruction annotation framework to address the data scarcity challenge in the science domain. This framework leverages existing LLMs to generate step-by-step reasoning for unlabelled scientific questions, followed by a process of self-reflective critic-and-revise. Applying this framework, we curated a diverse and high-quality dataset encompassing physics, chemistry, math, and formal proofs. We analyze the curated SciInstruct from multiple interesting perspectives (e.g., domain, scale, source, question type, answer length, etc.). To verify the effectiveness of SciInstruct, we fine-tuned different language models with SciInstruct, i.e., ChatGLM3 (6B and 32B), Llama3-8B-Instruct, and Mistral-7B: MetaMath, enhancing their scientific and mathematical reasoning capabilities, without sacrificing the language understanding capabilities of the base model. We release all codes and SciInstruct at https://github.com/THUDM/SciGLM.
Poster
Haozhe Zhao · Xiaojian (Shawn) Ma · Liang Chen · Shuzheng Si · Rujie Wu · Kaikai An · Peiyu Yu · Minjia Zhang · Qing Li · Baobao Chang
[ West Ballroom A-D ]

Abstract
This paper presents UltraEdit, a large-scale (~ 4M editing samples), automatically generated dataset for instruction-based image editing. Our key idea is to address the drawbacks in existing image editing datasets like InstructPix2Pix and MagicBrush, and provide a *systematic* approach to producing massive and high-quality image editing samples: 1) UltraEdit includes more diverse editing instructions by combining LLM creativity and in-context editing examples by human raters; 2) UltraEdit is anchored on real images (photographs or artworks), which offers more diversity and less biases than those purely synthesized by text-to-image models; 3) UltraEdit supports region-based editing with high-quality, automatically produced region annotations. Our experiments show that canonical diffusion-based editing baselines trained on UltraEdit set new records on challenging MagicBrush and Emu-Edit benchmarks, respectively. Our analysis further confirms the crucial role of real image anchors and region-based editing data. The dataset, code, and models will be made public.
Poster
Qingyun Sun · Ziying Chen · Beining Yang · Cheng Ji · Xingcheng Fu · Sheng Zhou · Hao Peng · Jianxin Li · Philip S Yu
[ West Ballroom A-D ]

Abstract
Graph condensation (GC) has recently garnered considerable attention due to its ability to reduce large-scale graph datasets while preserving their essential properties. The core concept of GC is to create a smaller, more manageable graph that retains the characteristics of the original graph. Despite the proliferation of graph condensation methods developed in recent years, there is no comprehensive evaluation and in-depth analysis, which creates a great obstacle to understanding the progress in this field. To fill this gap, we develop a comprehensive Graph Condensation Benchmark (GC-Bench) to analyze the performance of graph condensation in different scenarios systematically. Specifically, GC-Bench systematically investigates the characteristics of graph condensation in terms of the following dimensions: effectiveness, transferability, and complexity. We comprehensively evaluate 12 state-of-the-art graph condensation algorithms in node-level and graph-level tasks and analyze their performance in 12 diverse graph datasets. Further, we have developed an easy-to-use library for training and evaluating different GC methods to facilitate reproducible research.The GC-Bench library is available at https://github.com/RingBDStack/GC-Bench.
Poster
Rhea Sukthanker · Arber Zela · Benedikt Staffler · Aaron Klein · Lennart Purucker · Jörg Franke · Frank Hutter
[ West Ballroom A-D ]
Abstract
The increasing size of language models necessitates a thorough analysis across multiple dimensions to assess trade-offs among crucial hardware metrics such as latency, energy consumption, GPU memory usage, and performance. Identifying optimal model configurations under specific hardware constraints is becoming essential but remains challenging due to the computational load of exhaustive training and evaluation on multiple devices. To address this, we introduce HW-GPT-Bench, a hardware-aware benchmark that utilizes surrogate predictions to approximate various hardware metrics across 13 devices of architectures in the GPT-2 family, with architectures containing up to 1.55B parameters. Our surrogates, via calibrated predictions and reliable uncertainty estimates, faithfully model the heteroscedastic noise inherent in the energy and latency measurements. To estimate perplexity, we employ weight-sharing techniques from Neural Architecture Search (NAS), inheriting pretrained weights from the largest GPT-2 model. Finally, we demonstrate the utility of HW-GPT-Bench by simulating optimization trajectories of various multi-objective optimization algorithms in just a few seconds.
Spotlight Poster
Hao Shao · Shengju Qian · Han Xiao · Guanglu Song · ZHUOFAN ZONG · Letian Wang · Yu Liu · Hongsheng Li
[ West Ballroom A-D ]
Abstract
Multi-Modal Large Language Models (MLLMs) have demonstrated impressive performance in various VQA tasks. However, they often lack interpretability and struggle with complex visual inputs, especially when the resolution of the input image is high or when the interested region that could provide key information for answering the question is small. To address these challenges, we collect and introduce the large-scale Visual CoT dataset comprising 438k question-answer pairs, annotated with intermediate bounding boxes highlighting key regions essential for answering the questions. Additionally, about 98k pairs of them are annotated with detailed reasoning steps. Importantly, we propose a multi-turn processing pipeline that dynamically focuses on visual inputs and provides interpretable thoughts. We also introduce the related benchmark to evaluate the MLLMs in scenarios requiring specific local region identification.Extensive experiments demonstrate the effectiveness of our framework and shed light on better inference strategies. The Visual CoT dataset, benchmark, and pre-trained models are available on this [website](https://hao-shao.com/projects/viscot.html) to support further research in this area.
Poster
Thorben Werner · Johannes Burchert · Maximilian Stubbemann · Lars Schmidt-Thieme
[ West Ballroom A-D ]
Abstract
Active Learning (AL) deals with identifying the most informative samples forlabeling to reduce data annotation costs for supervised learning tasks. ALresearch suffers from the fact that lifts from literature generalize poorly andthat only a small number of repetitions of experiments are conducted. To overcomethese obstacles, we propose CDALBench, the first active learning benchmarkwhich includes tasks in computer vision, natural language processing and tabularlearning. Furthermore, by providing an efficient, greedy oracle, CDALBenchcan be evaluated with 50 runs for each experiment. We show, that both thecross-domain character and a large amount of repetitions are crucial forsophisticated evaluation of AL research. Concretely, we show that thesuperiority of specific methods varies over the different domains, making itimportant to evaluate Active Learning with a cross-domain benchmark.Additionally, we show that having a large amount of runs is crucial. With onlyconducting three runs as often done in the literature, the superiority ofspecific methods can strongly vary with the specific runs. This effect is so strong, that, depending on the seed, even a well-established method's performance can be significantly better and significantlyworse than random for the same dataset.
Poster
Zehui Li · Vallijah Subasri · Guy-Bart Stan · Yiren Zhao · Bo Wang
[ East Exhibit Hall A-C ]

Abstract
Genetic variants (GVs) are defined as differences in the DNA sequences among individuals and play a crucial role in diagnosing and treating genetic diseases. The rapid decrease in next generation sequencing cost, analogous to Moore’s Law, has led to an exponential increase in the availability of patient-level GV data. This growth poses a challenge for clinicians who must efficiently prioritize patient-specific GVs and integrate them with existing genomic databases to inform patient management. To addressing the interpretation of GVs, genomic foundation models (GFMs) have emerged. However, these models lack standardized performance assessments, leading to considerable variability in model evaluations. This poses the question: *How effectively do deep learning methods classify unknown GVs and align them with clinically-verified GVs?* We argue that representation learning, which transforms raw data into meaningful feature spaces, is an effective approach for addressing both indexing and classification challenges. We introduce a large-scale Genetic Variant dataset, named $\textsf{GV-Rep}$, featuring variable-length contexts and detailed annotations, designed for deep learning models to learn GV representations across various traits, diseases, tissue types, and experimental contexts. Our contributions are three-fold: (i) $\textbf{Construction}$ of a comprehensive dataset with 7 million records, each labeled with characteristics of the corresponding variants, alongside additional data …
Poster
Kyungeun Lee · Wonjong Rhee
[ West Ballroom A-D ]

Abstract
Mutual Information (MI) is a fundamental metric for quantifying dependency between two random variables. When we can access only the samples, but not the underlying distribution functions, we can evaluate MI using sample-based estimators. Assessment of such MI estimators, however, has almost always relied on analytical datasets including Gaussian multivariates. Such datasets allow analytical calculations of the true MI values, but they are limited in that they do not reflect the complexities of real-world datasets. This study introduces a comprehensive benchmark suite for evaluating neural MI estimators on unstructured datasets, specifically focusing on images and texts. By leveraging same-class sampling for positive pairing and introducing a binary symmetric channel trick, we show that we can accurately manipulate true MI values of real-world datasets. Using the benchmark suite, we investigate seven challenging scenarios, shedding light on the reliability of neural MI estimators for unstructured datasets.
Poster
Anoop Cherian · Kuan-Chuan Peng · Suhas Lohit · Joanna Matthiesen · Kevin Smith · Josh Tenenbaum
[ West Ballroom A-D ]

Abstract
Recent years have seen a significant progress in the general-purpose problem solving abilities of large vision and language models (LVLMs), such as ChatGPT, Gemini, etc.; some of these breakthroughs even seem to enable AI models to outperform human abilities in varied tasks that demand higher-order cognitive skills. Are the current large AI models indeed capable of generalized problem solving as humans do? A systematic analysis of AI capabilities for joint vision and text reasoning, however, is missing in the current scientific literature. In this paper, we make an effort towards filling this gap, by evaluating state-of-the-art LVLMs on their mathematical and algorithmic reasoning abilities using visuo-linguistic problems from children's Olympiads. Specifically, we consider problems from the Mathematical Kangaroo (MK) Olympiad, which is a popular international competition targeted at children from grades 1-12, that tests children's deeper mathematical abilities using puzzles that are appropriately gauged to their age and skills. Using the puzzles from MK, we created a dataset, dubbed SMART-840, consisting of 840 problems from years 2020-2024. With our dataset, we analyze LVLMs power on mathematical reasoning; their responses on our puzzles offer a direct way to compare against that of children. Our results show that modern LVLMs do demonstrate …
Poster
Hangyu Zhou · Chia-Hsiang Kao · Cheng Perng Phoo · Utkarsh Mall · Bharath Hariharan · Kavita Bala
[ West Ballroom A-D ]
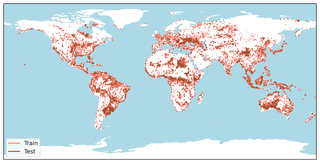
Abstract
Clouds in satellite imagery pose a significant challenge for downstream applications.A major challenge in current cloud removal research is the absence of a comprehensive benchmark and a sufficiently large and diverse training dataset.To address this problem, we introduce the largest public dataset -- *AllClear* for cloud removal, featuring 23,742 globally distributed regions of interest (ROIs) with diverse land-use patterns, comprising 4 million images in total. Each ROI includes complete temporal captures from the year 2022, with (1) multi-spectral optical imagery from Sentinel-2 and Landsat 8/9, (2) synthetic aperture radar (SAR) imagery from Sentinel-1, and (3) auxiliary remote sensing products such as cloud masks and land cover maps.We validate the effectiveness of our dataset by benchmarking performance, demonstrating the scaling law - the PSNR rises from $28.47$ to $33.87$ with $30\times$ more data, and conducting ablation studies on the temporal length and the importance of individual modalities. This dataset aims to provide comprehensive coverage of the Earth's surface and promote better cloud removal results.
Poster
Avisek Naug · Antonio Guillen-Perez · Ricardo Luna Gutierrez · Vineet Gundecha · Cullen Bash · Sahand Ghorbanpour · Sajad Mousavi · Ashwin Ramesh Babu · Dejan Markovikj · Lekhapriya Dheeraj Kashyap · Desik Rengarajan · Soumyendu Sarkar
[ West Ballroom A-D ]

Abstract
Machine learning has driven an exponential increase in computational demand, leading to massive data centers that consume significant amounts of energy and contribute to climate change. This makes sustainable data center control a priority. In this paper, we introduce SustainDC, a set of Python environments for benchmarking multi-agent reinforcement learning (MARL) algorithms for data centers (DC). SustainDC supports custom DC configurations and tasks such as workload scheduling, cooling optimization, and auxiliary battery management, with multiple agents managing these operations while accounting for the effects of each other. We evaluate various MARL algorithms on SustainDC, showing their performance across diverse DC designs, locations, weather conditions, grid carbon intensity, and workload requirements. Our results highlight significant opportunities for improvement of data center operations using MARL algorithms. Given the increasing use of DC due to AI, SustainDC provides a crucial platform for the development and benchmarking of advanced algorithms essential for achieving sustainable computing and addressing other heterogeneous real-world challenges.
Poster
Muhammad Umair Nasir · Steven James · Julian Togelius
[ West Ballroom A-D ]
Abstract
Large language models (LLMs) have recently demonstrated great success in generating and understanding natural language. While they have also shown potential beyond the domain of natural language, it remains an open question as to what extent and in which way these LLMs can plan. We investigate their planning capabilities by proposing \texttt{GameTraversalBenchmark (GTB)}, a benchmark consisting of diverse 2D grid-based game maps. An LLM succeeds if it can traverse through given objectives, with a minimum number of steps and a minimum number of generation errors. We evaluate a number of LLMs on \texttt{GTB} and found that GPT-4-Turbo achieved the highest score of $44.97\%$ on \texttt{GTB\_Score} (GTBS), a composite score that combines the three above criteria. Furthermore, we preliminarily test large reasoning models, namely o1, which scores $67.84\%$ on GTBS, indicating that the benchmark remains challenging for current models. Code, data, and documentation are available at \url{https://github.com/umair-nasir14/Game-Traversal-Benchmark}.
Poster
Bingqiao Luo · Zhen Zhang · Qian Wang · Bingsheng He
[ West Ballroom A-D ]
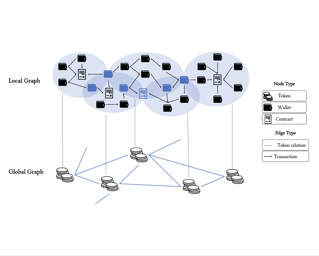
Abstract
Machine learning applied to blockchain graphs offers significant opportunities for enhanced data analysis and applications. However, the potential of this field is constrained by the lack of a large-scale, cross-chain dataset that includes hierarchical graph-level data. To address this issue, we present novel datasets that provide detailed label information at the token level and integrate interactions between tokens across multiple blockchain platforms. We model transactions within each token as local graphs and the relationships between tokens as global graphs, collectively forming a "Graphs of Graphs" (GoG) approach. This innovative approach facilitates a deeper understanding of systemic structures and hierarchical interactions, which are essential for applications such as link prediction, anomaly detection, and token classification. We conduct a series of experiments demonstrating that this dataset delivers new insights and challenges for exploring GoG within the blockchain domain. Our work promotes advancements and opens new avenues for research in both the blockchain and graph communities. Source code and datasets are available at https://github.com/Xtra-Computing/Cryptocurrency-Graphs-of-graphs.
Poster
Baiqi Li · Zhiqiu Lin · Wenxuan Peng · Jean de Dieu Nyandwi · Daniel Jiang · Zixian Ma · Simran Khanuja · Ranjay Krishna · Graham Neubig · Deva Ramanan
[ East Exhibit Hall A-C ]
Abstract
Vision-language models (VLMs) have made significant progress in recent visual-question-answering (VQA) benchmarks that evaluate complex visio-linguistic reasoning. However, are these models truly effective? In this work, we show that VLMs still struggle with natural images and questions that humans can easily answer, which we term $\textbf{natural adversarial samples}$. We also find it surprisingly easy to generate these VQA samples from natural image-text corpora using off-the-shelf models like CLIP and ChatGPT. We propose a semi-automated approach to collect a new benchmark, ${\bf NaturalBench}$, for reliably evaluating VLMs with 10,000 human-verified VQA samples. Crucially, we adopt a $\textbf{vision-centric}$ design by pairing each question with two images that yield different answers, preventing ``blind'' solutions from answering without using the images. This makes NaturalBench more challenging than previous benchmarks that can largely be solved with language priors like commonsense knowledge. We evaluate ${\bf 53}$ state-of-the-art VLMs on NaturalBench, showing that models like BLIP-3, LLaVA-OneVision, Cambrian-1, InternLM-XC2, Llama3.2-Vision, Molmo, Qwen2-VL, and even the (closed-source) GPT-4o lag 50%-70% behind human performance (which is above 90%). We analyze why NaturalBench is hard from two angles: (1) ${\bf Compositionality:}$ Solving NaturalBench requires diverse visio-linguistic skills, including understanding attribute bindings, object relationships, and advanced reasoning like logic and counting. …
Poster
Manuel Meier · Berken Utku Demirel · Christian Holz
[ West Ballroom A-D ]
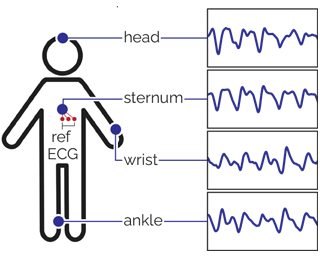
Abstract
Reflective photoplethysmography (PPG) has become the default sensing technique in wearable devices to monitor cardiac activity via a person’s heart rate (HR). However, PPG-based HR estimates can be substantially impacted by factors such as the wearer’s activities, sensor placement and resulting motion artifacts, as well as environmental characteristics such as temperature and ambient light. These and other factors can significantly impact and decrease HR prediction reliability. In this paper, we show that state-of-the-art HR estimation methods struggle when processing representative data from everyday activities in outdoor environments, likely because they rely on existing datasets that captured controlled conditions. We introduce a novel multimodal dataset and benchmark results for continuous PPG recordings during outdoor activities from 16 participants over 13.5 hours, captured from four wearable sensors, each worn at a different location on the body, totaling 216 hours. Our recordings include accelerometer, temperature, and altitude data, as well as a synchronized Lead I-based electrocardiogram for ground-truth HR references. Participants completed a round trip from Zurich to Jungfraujoch, a tall mountain in Switzerland over the course of one day. The trip included outdoor and indoor activities such as walking, hiking, stair climbing, eating, drinking, and resting at various temperatures and altitudes (up …
Poster
Lukas Klein · Carsten Lüth · Udo Schlegel · Till Bungert · Mennatallah El-Assady · Paul Jaeger
[ West Ballroom A-D ]
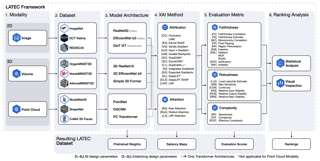
Abstract
Explainable AI (XAI) is a rapidly growing domain with a myriad of proposed methods as well as metrics aiming to evaluate their efficacy. However, current studies are often of limited scope, examining only a handful of XAI methods and ignoring underlying design parameters for performance, such as the model architecture or the nature of input data. Moreover, they often rely on one or a few metrics and neglect thorough validation, increasing the risk of selection bias and ignoring discrepancies among metrics. These shortcomings leave practitioners confused about which method to choose for their problem. In response, we introduce LATEC, a large-scale benchmark that critically evaluates 17 prominent XAI methods using 20 distinct metrics. We systematically incorporate vital design parameters like varied architectures and diverse input modalities, resulting in 7,560 examined combinations. Through LATEC, we showcase the high risk of conflicting metrics leading to unreliable rankings and consequently propose a more robust evaluation scheme. Further, we comprehensively evaluate various XAI methods to assist practitioners in selecting appropriate methods aligning with their needs. Curiously, the emerging top-performing method, Expected Gradients, is not examined in any relevant related study. LATEC reinforces its role in future XAI research by publicly releasing all 326k saliency …
Poster
Mark Blacher · Christoph Staudt · Julien Klaus · Maurice Wenig · Niklas Merk · Alexander Breuer · Max Engel · Sören Laue · Joachim Giesen
[ West Ballroom A-D ]

Abstract
Modern artificial intelligence and machine learning workflows rely on efficient tensor libraries. However, tuning tensor libraries without considering the actual problems they are meant to execute can lead to a mismatch between expected performance and the actual performance. Einsum libraries are tuned to efficiently execute tensor expressions with only a few, relatively large, dense, floating-point tensors. But, practical applications of einsum cover a much broader range of tensor expressions than those that can currently be executed efficiently. For this reason, we have created a benchmark dataset that encompasses this broad range of tensor expressions, allowing future implementations of einsum to build upon and be evaluated against. In addition, we also provide generators for einsum expressions and converters to einsum expressions in our repository, so that additional data can be generated as needed. The benchmark dataset, the generators and converters are released openly and are publicly available at https://benchmark.einsum.org.
Poster
Nachiket Kotalwar · Alkis Gotovos · Adish Singla
[ West Ballroom A-D ]
Abstract
Generative AI and large language models hold great promise in enhancing programming education by generating individualized feedback and hints for learners. Recent works have primarily focused on improving the quality of generated feedback to achieve human tutors' quality. While quality is an important performance criterion, it is not the only criterion to optimize for real-world educational deployments. In this paper, we benchmark language models for programming feedback generation across several performance criteria, including quality, cost, time, and data privacy. The key idea is to leverage recent advances in the new paradigm of in-browser inference that allow running these models directly in the browser, thereby providing direct benefits across cost and data privacy. To boost the feedback quality of small models compatible with in-browser inference engines, we develop a fine-tuning pipeline based on GPT-4 generated synthetic data. We showcase the efficacy of fine-tuned Llama3-8B and Phi3-3.8B 4-bit quantized models using WebLLM's in-browser inference engine on three different Python programming datasets. We will release the full implementation along with a web app and datasets to facilitate further research on in-browser language models.
Spotlight Poster
Maurice Weber · Dan Fu · Quentin Anthony · Yonatan Oren · Shane Adams · Anton Alexandrov · Xiaozhong Lyu · Huu Nguyen · Xiaozhe Yao · Virginia Adams · Ben Athiwaratkun · Rahul Chalamala · Kezhen Chen · Max Ryabinin · Tri Dao · Percy Liang · Christopher Ré · Irina Rish · Ce Zhang
[ West Ballroom A-D ]
Abstract
Large language models are increasingly becoming a cornerstone technology in artificial intelligence, the sciences, and society as a whole, yet the optimal strategies for dataset composition and filtering remain largely elusive. Many of the top-performing models lack transparency in their dataset curation and model development processes, posing an obstacle to the development of fully open language models. In this paper, we identify three core data-related challenges that must be addressed to advance open-source language models. These include (1) transparency in model development, including the data curation process, (2) access to large quantities of high-quality data, and (3) availability of artifacts and metadata for dataset curation and analysis. To address these challenges, we release RedPajama-V1, an open reproduction of the LLaMA training dataset. In addition, we release RedPajama-V2, a massive web-only dataset consisting of raw, unfiltered text data together with quality signals and metadata.Together, the RedPajama datasets comprise over 100 trillion tokens spanning multiple domains and with their quality signals facilitate the filtering of data, aiming to inspire the development of numerous new datasets. To date, these datasets have already been used in the training of strong language models used in production, such as Snowflake Arctic, Salesforce's XGen and AI2's OLMo. …
Poster
Adrian Remonda · Nicklas Hansen · Ayoub Raji · Nicola Musiu · Marko Bertogna · Eduardo Veas · Xiaolong Wang
[ West Ballroom A-D ]

Abstract
Despite the availability of international prize-money competitions, scaled vehicles, and simulation environments, research on autonomous racing and the control of sports cars operating close to the limit of handling has been limited by the high costs of vehicle acquisition and management, as well as the limited physics accuracy of open-source simulators. In this paper, we propose a racing simulation platform based on the simulator Assetto Corsa to test, validate, and benchmark autonomous driving algorithms, including reinforcement learning (RL) and classical Model Predictive Control (MPC), in realistic and challenging scenarios. Our contributions include the development of this simulation platform, several state-of-the-art algorithms tailored to the racing environment, and a comprehensive dataset collected from human drivers. Additionally, we evaluate algorithms in the offline RL setting. All the necessary code (including environment and benchmarks), working examples, and datasets are publicly released and can be found at: https://github.com/dasGringuen/assetto_corsa_gym.
Poster
Thomas Melistas · Nikos Spyrou · Nefeli Gkouti · Pedro Sanchez · Athanasios Vlontzos · Yannis Panagakis · Giorgos Papanastasiou · Sotirios Tsaftaris
[ West Ballroom A-D ]
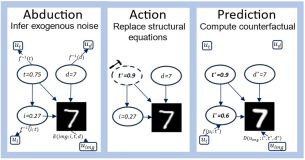
Abstract
Generative AI has revolutionised visual content editing, empowering users to effortlessly modify images and videos. However, not all edits are equal. To perform realistic edits in domains such as natural image or medical imaging, modifications must respect causal relationships inherent to the data generation process. Such image editing falls into the counterfactual image generation regime. Evaluating counterfactual image generation is substantially complex: not only it lacks observable ground truths, but also requires adherence to causal constraints. Although several counterfactual image generation methods and evaluation metrics exist a comprehensive comparison within a unified setting is lacking. We present a comparison framework to thoroughly benchmark counterfactual image generation methods. We evaluate the performance of three conditional image generation model families developed within the Structural Causal Model (SCM) framework. We incorporate several metrics that assess diverse aspects of counterfactuals, such as composition, effectiveness, minimality of interventions, and image realism. We integrate all models that have been used for the task at hand and expand them to novel datasets and causal graphs, demonstrating the superiority of Hierarchical VAEs across most datasets and metrics. Our framework is implemented in a user-friendly Python package that can be extended to incorporate additional SCMs, causal methods, generative models, …
Spotlight Poster
Minkyu Jeon · Rishwanth Raghu · Miro Astore · Geoffrey Woollard · J. Feathers · Alkin Kaz · Sonya Hanson · Pilar Cossio · Ellen Zhong
[ West Ballroom A-D ]

Abstract
Cryo-electron microscopy (cryo-EM) is a powerful technique for determining high-resolution 3D biomolecular structures from imaging data. Its unique ability to capture structural variability has spurred the development of heterogeneous reconstruction algorithms that can infer distributions of 3D structures from noisy, unlabeled imaging data. Despite the growing number of advanced methods, progress in the field is hindered by the lack of standardized benchmarks with ground truth information and reliable validation metrics. Here, we introduce CryoBench, a suite of datasets, metrics, and benchmarks for heterogeneous reconstruction in cryo-EM. CryoBench includes five datasets representing different sources of heterogeneity and degrees of difficulty. These include conformational heterogeneity generated from designed motions of antibody complexes or sampled from a molecular dynamics simulation, as well as {compositional heterogeneity from mixtures of ribosome assembly states or 100 common complexes present in cells. We then analyze state-of-the-art heterogeneous reconstruction tools, including neural and non-neural methods, assess their sensitivity to noise, and propose new metrics for quantitative evaluation. We hope that CryoBench will be a foundational resource for accelerating algorithmic development and evaluation in the cryo-EM and machine learning communities. Project page: https://cryobench.cs.princeton.edu.
Poster
Qianqian Xie · Weiguang Han · Zhengyu Chen · Ruoyu Xiang · Xiao Zhang · Yueru He · Mengxi Xiao · Dong Li · Yongfu Dai · Duanyu Feng · Yijing Xu · Haoqiang Kang · Ziyan Kuang · Chenhan Yuan · Kailai Yang · Zheheng Luo · Tianlin Zhang · Zhiwei Liu · GUOJUN XIONG · Zhiyang Deng · Yuechen Jiang · Zhiyuan Yao · Haohang Li · Yangyang Yu · Gang Hu · Huang Jiajia · Xiaoyang Liu · Alejandro Lopez-Lira · Benyou Wang · Yanzhao Lai · Hao Wang · Min Peng · Sophia Ananiadou · Jimin Huang
[ West Ballroom A-D ]
Abstract
LLMs have transformed NLP and shown promise in various fields, yet their potential in finance is underexplored due to a lack of comprehensive benchmarks, the rapid development of LLMs, and the complexity of financial tasks. In this paper, we introduce FinBen, the first extensive open-source evaluation benchmark, including 42 datasets spanning 24 financial tasks, covering eight critical aspects: information extraction (IE), textual analysis, question answering (QA), text generation, risk management, forecasting, decision-making, and bilingual (English and Spanish). FinBen offers several key innovations: a broader range of tasks and datasets, the first evaluation of stock trading, novel agent and Retrieval-Augmented Generation (RAG) evaluation, and two novel datasets for regulations and stock trading. Our evaluation of 21 representative LLMs, including GPT-4, ChatGPT, and the latest Gemini, reveals several key findings: While LLMs excel in IE and textual analysis, they struggle with advanced reasoning and complex tasks like text generation and forecasting. GPT-4 excels in IE and stock trading, while Gemini is better at text generation and forecasting. Instruction-tuned LLMs improve textual analysis but offer limited benefits for complex tasks such as QA. FinBen has been used to host the first financial LLMs shared task at the FinNLP-AgentScen workshop during IJCAI-2024, attracting 12 …
Spotlight Poster
Guillaume Jaume · Paul Doucet · Andrew Song · Ming Yang Lu · Cristina Almagro Pérez · Sophia Wagner · Anurag Vaidya · Richard Chen · Drew Williamson · Ahrong Kim · Faisal Mahmood
[ East Exhibit Hall A-C ]
Abstract
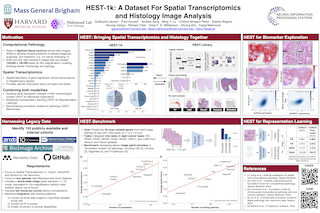
Spatial transcriptomics enables interrogating the molecular composition of tissue with ever-increasing resolution and sensitivity. However, costs, rapidly evolving technology, and lack of standards have constrained computational methods in ST to narrow tasks and small cohorts. In addition, the underlying tissue morphology, as reflected by H&E-stained whole slide images (WSIs), encodes rich information often overlooked in ST studies. Here, we introduce HEST-1k, a collection of 1,229 spatial transcriptomic profiles, each linked to a WSI and extensive metadata. HEST-1k was assembled from 153 public and internal cohorts encompassing 26 organs, two species (Homo Sapiens and Mus Musculus), and 367 cancer samples from 25 cancer types. HEST-1k processing enabled the identification of 2.1 million expression-morphology pairs and over 76 million nuclei. To support its development, we additionally introduce the HEST-Library, a Python package designed to perform a range of actions with HEST samples. We test HEST-1k and Library on three use cases: (1) benchmarking foundation models for pathology (HEST-Benchmark), (2) biomarker exploration, and (3) multimodal representation learning. HEST-1k, HEST-Library, and HEST-Benchmark can be freely accessed at https://github.com/mahmoodlab/hest.
Poster
Bowen Wang · Jiuyang Chang · Yiming Qian · Guoxin Chen · Junhao Chen · Zhouqiang Jiang · Jiahao Zhang · Yuta Nakashima · Hajime Nagahara
[ East Exhibit Hall A-C ]

Abstract
Large language models (LLMs) have recently showcased remarkable capabilities, spanning a wide range of tasks and applications, including those in the medical domain. Models like GPT-4 excel in medical question answering but may face challenges in the lack of interpretability when handling complex tasks in real clinical settings. We thus introduce the diagnostic reasoning dataset for clinical notes (DiReCT), aiming at evaluating the reasoning ability and interpretability of LLMs compared to human doctors. It contains 511 clinical notes, each meticulously annotated by physicians, detailing the diagnostic reasoning process from observations in a clinical note to the final diagnosis. Additionally, a diagnostic knowledge graph is provided to offer essential knowledge for reasoning, which may not be covered in the training data of existing LLMs. Evaluations of leading LLMs on DiReCT bring out a significant gap between their reasoning ability and that of human doctors, highlighting the critical need for models that can reason effectively in real-world clinical scenarios.
Poster
Junchao Wu · Runzhe Zhan · Derek Wong · Shu Yang · Xinyi Yang · Yulin Yuan · Lidia Chao
[ West Ballroom A-D ]

Abstract
Detecting text generated by large language models (LLMs) is of great recent interest. With zero-shot methods like DetectGPT, detection capabilities have reached impressive levels. However, the reliability of existing detectors in real-world applications remains underexplored. In this study, we present a new benchmark, DetectRL, highlighting that even state-of-the-art (SOTA) detection techniques still underperformed in this task. We collected human-written datasets from domains where LLMs are particularly prone to misuse. Using popular LLMs, we generated data that better aligns with real-world applications. Unlike previous studies, we employed heuristic rules to create adversarial LLM-generated text, simulating advanced prompt usages, human revisions like word substitutions, and writing errors. Our development of DetectRL reveals the strengths and limitations of current SOTA detectors. More importantly, we analyzed the potential impact of writing styles, model types, attack methods, the text lengths, and real-world human writing factors on different types of detectors. We believe DetectRL could serve as an effective benchmark for assessing detectors in real-world scenarios, evolving with advanced attack methods, thus providing more stressful evaluation to drive the development of more efficient detectors\footnote{Data and code are publicly available at: https://github.com/NLP2CT/DetectRL.
Spotlight Poster
Benno Krojer · Dheeraj Vattikonda · Luis Lara · Varun Jampani · Eva Portelance · Chris Pal · Siva Reddy
[ East Exhibit Hall A-C ]

Abstract
An image editing model should be able to perform diverse edits, ranging from object replacement, changing attributes or style, to performing actions or movement, which require many forms of reasoning. Current *general* instruction-guided editing models have significant shortcomings with action and reasoning-centric edits.Object, attribute or stylistic changes can be learned from visually static datasets. On the other hand, high-quality data for action and reasoning-centric edits is scarce and has to come from entirely different sources that cover e.g. physical dynamics, temporality and spatial reasoning.To this end, we meticulously curate the **A**U**RO**R**A** Dataset (**A**ction-**R**easoning-**O**bject-**A**ttribute), a collection of high-quality training data, human-annotated and curated from videos and simulation engines.We focus on a key aspect of quality training data: triplets (source image, prompt, target image) contain a single meaningful visual change described by the prompt, i.e., *truly minimal* changes between source and target images.To demonstrate the value of our dataset, we evaluate an **A**U**RO**R**A**-finetuned model on a new expert-curated benchmark (**A**U**RO**R**A-Bench**) covering 8 diverse editing tasks.Our model significantly outperforms previous editing models as judged by human raters.For automatic evaluations, we find important flaws in previous metrics and caution their use for semantically hard editing tasks.Instead, we propose a new automatic metric that focuses …
Spotlight Poster
Kehan Guo · Bozhao Nan · Yujun Zhou · Taicheng Guo · Zhichun Guo · Mihir Surve · Zhenwen Liang · Nitesh Chawla · Olaf Wiest · Xiangliang Zhang
[ East Exhibit Hall A-C ]

Abstract
Large Language Models (LLMs) have shown significant problem-solving capabilities across predictive and generative tasks in chemistry. However, their proficiency in multi-step chemical reasoning remains underexplored. We introduce a new challenge: molecular structure elucidation, which involves deducing a molecule’s structure from various types of spectral data. Solving such a molecular puzzle, akin to solving crossword puzzles, poses reasoning challenges that require integrating clues from diverse sources and engaging in iterative hypothesis testing. To address this challenging problem with LLMs, we present \textbf{MolPuzzle}, a benchmark comprising 217 instances of structure elucidation, which feature over 23,000 QA samples presented in a sequential puzzle-solving process, involving three interlinked sub-tasks: molecule understanding, spectrum interpretation, and molecule construction. Our evaluation of 12 LLMs reveals that the best-performing LLM, GPT-4o, performs significantly worse than humans, with only a small portion (1.4\%) of its answers exactly matching the ground truth. However, it performs nearly perfectly in the first subtask of molecule understanding, achieving accuracy close to 100\%. This discrepancy highlights the potential of developing advanced LLMs with improved chemical reasoning capabilities in the other two sub-tasks. Our MolPuzzle dataset and evaluation code are available at this \href{https://github.com/KehanGuo2/MolPuzzle}{link}.
Poster
Momin Haider · Ming Yin · Menglei Zhang · Arpit Gupta · Jing Zhu · Yu-Xiang Wang
[ East Exhibit Hall A-C ]
Abstract
Mobile devices such as smartphones, laptops, and tablets can often connect to multiple access networks (e.g., Wi-Fi, LTE, and 5G) simultaneously.Recent advancements facilitate seamless integration of these connections below the transport layer, enhancing the experience for apps that lack inherent multi-path support.This optimization hinges on dynamically determining the traffic distribution across networks for each device, a process referred to as multi-access traffic splitting.This paper introduces NetworkGym, a high-fidelity network environment simulator that facilitates generating multiple network traffic flows and multi-access traffic splitting.This simulator facilitates training and evaluating different RL-based solutions for the multi-access traffic splitting problem.Our initial explorations demonstrate that the majority of existing state-of-the-art offline RL algorithms (e.g. CQL) fail to outperform certain hand-crafted heuristic policies on average.This illustrates the urgent need to evaluate offline RL algorithms against a broader range of benchmarks, rather than relying solely on popular ones such as D4RL.We also propose an extension to the TD3+BC algorithm, named Pessimistic TD3 (PTD3), and demonstrate that it outperforms many state-of-the-art offline RL algorithms.PTD3's behavioral constraint mechanism, which relies on value-function pessimism, is theoretically motivated and relatively simple to implement.We open source our code and offline datasets at github.com/hmomin/networkgym.
Poster
Hemal Naik · Junran Yang · Dipin Das · Margaret Crofoot · Akanksha Rathore · Vivek Hari Sridhar
[ West Ballroom A-D ]
Abstract
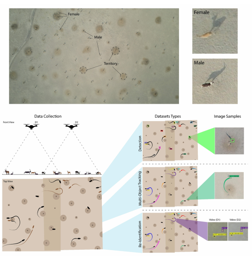
Understanding animal behaviour is central to predicting, understanding, and miti-gating impacts of natural and anthropogenic changes on animal populations andecosystems. However, the challenges of acquiring and processing long-term, eco-logically relevant data in wild settings have constrained the scope of behaviouralresearch. The increasing availability of Unmanned Aerial Vehicles (UAVs), cou-pled with advances in machine learning, has opened new opportunities for wildlifemonitoring using aerial tracking. However, the limited availability of datasets with wildanimals in natural habitats has hindered progress in automated computer visionsolutions for long-term animal tracking. Here, we introduce the first large-scaleUAV dataset designed to solve multi-object tracking (MOT) and re-identification(Re-ID) problem in wild animals, specifically the mating behaviour (or lekking) ofblackbuck antelopes. Collected in collaboration with biologists, the MOT datasetincludes over 1.2 million annotations including 680 tracks across 12 high-resolution(5.4K) videos, each averaging 66 seconds and featuring 30 to 130 individuals. TheRe-ID dataset includes 730 individuals captured with two UAVs simultaneously.The dataset is designed to drive scalable, long-term animal behavior tracking usingmultiple camera sensors. By providing baseline performance with two detectors,and benchmarking several state-of-the-art tracking methods, our dataset reflects thereal-world challenges of tracking wild animals in socially and ecologically relevantcontexts. In making these data widely available, we hope to catalyze …
Poster
Zhaochen Su · Jun Zhang · Xiaoye Qu · Tong Zhu · Yanshu Li · Jiashuo Sun · Juntao Li · Min Zhang · Yu Cheng
[ East Exhibit Hall A-C ]
Abstract
Large language models (LLMs) have achievedimpressive advancements across numerous disciplines, yet the critical issue of knowledge conflicts, a major source of hallucinations, has rarely been studied. While a few research explored the conflicts between the inherent knowledge of LLMs and the retrieved contextual knowledge, a comprehensive assessment of knowledge conflict in LLMs is still missing. Motivated by this research gap, we firstly propose ConflictBank, the largest benchmark with 7.45M claim-evidence pairs and 553k QA pairs, addressing conflicts from misinformation, temporal discrepancies, and semantic divergences.Using ConflictBank, we conduct the thorough and controlled experiments for a comprehensive understanding of LLM behavior in knowledge conflicts, focusing on three key aspects: (i) conflicts encountered in retrieved knowledge, (ii) conflicts within the models' encoded knowledge, and (iii) the interplay between these conflict forms.Our investigation delves into four model families and twelve LLM instances and provides insights into conflict types, model sizes, and the impact at different stages.We believe that knowledge conflicts represent a critical bottleneck to achieving trustworthy artificial intelligence and hope our work will offer valuable guidance for future model training and development.Resources are available at https://github.com/zhaochen0110/conflictbank.
Spotlight Poster
Jifan Zhang · Lalit Jain · Yang Guo · Jiayi Chen · Kuan Zhou · Siddharth Suresh · Andrew Wagenmaker · Scott Sievert · Timothy T Rogers · Kevin Jamieson · Bob Mankoff · Robert Nowak
[ East Exhibit Hall A-C ]
Abstract
We present a novel multimodal preference dataset for creative tasks, consisting of over 250 million human votes on more than 2.2 million captions, collected through crowdsourcing rating data for The New Yorker's weekly cartoon caption contest over the past eight years. This unique dataset supports the development and evaluation of multimodal large language models and preference-based fine-tuning algorithms for humorous caption generation. We propose novel benchmarks for judging the quality of model-generated captions, utilizing both GPT4 and human judgments to establish ranking-based evaluation strategies. Our experimental results highlight the limitations of current fine-tuning methods, such as RLHF and DPO, when applied to creative tasks. Furthermore, we demonstrate that even state-of-the-art models like GPT4 and Claude currently underperform top human contestants in generating humorous captions. As we conclude this extensive data collection effort, we release the entire preference dataset to the research community, fostering further advancements in AI humor generation and evaluation.
Poster
Victor-Alexandru Pădurean · Adish Singla
[ West Ballroom A-D ]

Abstract
Generative models have demonstrated human-level proficiency in various benchmarks across domains like programming, natural sciences, and general knowledge. Despite these promising results on competitive benchmarks, they still struggle with seemingly simple problem-solving tasks typically carried out by elementary-level students. How do state-of-the-art models perform on standardized programming-related tests designed to assess computational thinking and problem-solving skills at schools? In this paper, we curate a novel benchmark involving computational thinking tests grounded in elementary visual programming domains. Our initial results show that state-of-the-art models like GPT-4o and Llama3 barely match the performance of an average school student. To further boost the performance of these models, we fine-tune them using a novel synthetic data generation methodology. The key idea is to develop a comprehensive dataset using symbolic methods that capture different skill levels, ranging from recognition of visual elements to multi-choice quizzes to synthesis-style tasks. We showcase how various aspects of symbolic information in synthetic data help improve fine-tuned models' performance. We will release the full implementation and datasets to facilitate further research on enhancing computational thinking in generative models.
Poster
Fangyun Wei · Jinjing Zhao · Kun Yan · Hongyang Zhang · Chang Xu
[ West Ballroom A-D ]
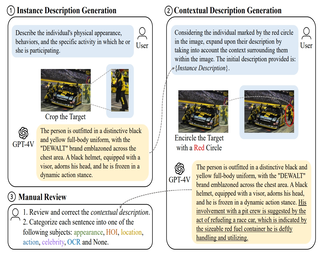
Abstract
Prior research in human-centric AI has primarily addressed single-modality tasks like pedestrian detection, action recognition, and pose estimation. However, the emergence of large multimodal models (LMMs) such as GPT-4V has redirected attention towards integrating language with visual content. Referring expression comprehension (REC) represents a prime example of this multimodal approach. Current human-centric REC benchmarks, typically sourced from general datasets, fall short in the LMM era due to their limitations, such as insufficient testing samples, overly concise referring expressions, and limited vocabulary, making them inadequate for evaluating the full capabilities of modern REC models. In response, we present HC-RefLoCo (Human-Centric Referring Expression Comprehension with Long Context), a benchmark that includes 13,452 images, 24,129 instances, and 44,738 detailed annotations, encompassing a vocabulary of 18,681 words. Each annotation, meticulously reviewed for accuracy, averages 93.2 words and includes topics such as appearance, human-object interaction, location, action, celebrity, and OCR. HC-RefLoCo provides a wider range of instance scales and diverse evaluation protocols, encompassing accuracy with various IoU criteria, scale-aware evaluation, and subject-specific assessments. Our experiments, which assess 24 models, highlight HC-RefLoCo’s potential to advance human-centric AI by challenging contemporary REC models with comprehensive and varied data. Our benchmark, along with the evaluation code, are available …
Spotlight Poster
Hugh Zhang · Jeff Da · Dean Lee · Vaughn Robinson · Catherine Wu · William Song · Tiffany Zhao · Pranav Raja · Charlotte Zhuang · Dylan Slack · Qin Lyu · Sean Hendryx · Russell Kaplan · Michele Lunati · Summer Yue
[ West Ballroom A-D ]
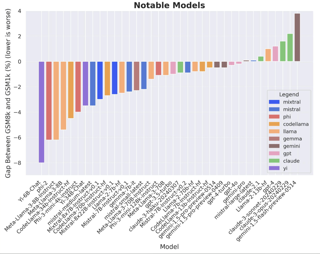
Abstract
Large language models (LLMs) have achieved impressive success on many benchmarks for mathematical reasoning.However, there is growing concern that some of this performance actually reflects dataset contamination, where data closely resembling benchmark questions leaks into the training data, instead of true reasoning ability.To investigate this claim rigorously, we commission Grade School Math 1000 (GSM1k). GSM1k is designed to mirror the style and complexity of the established GSM8k benchmark,the gold standard for measuring elementary mathematical reasoning. We ensure that the two benchmarks are comparable across important metrics such as human solve rates, number of steps in solution, answer magnitude, and more.When evaluating leading open- and closed-source LLMs on GSM1k, we observe accuracy drops of up to 8%, with several families of models showing evidence of systematic overfitting across almost all model sizes.Further analysis suggests a positive relationship (Spearman's r^2=0.36) between a model's probability of generating an example from GSM8k and its performance gap between GSM8k and GSM1k, suggesting that some models may have partially memorized GSM8k.Nevertheless, many models, especially those on the frontier, show minimal signs of overfitting, and all models broadly demonstrate generalization to novel math problems guaranteed to not be in their training data.
Poster
Yifan Jiang · jiarui zhang · Kexuan Sun · Zhivar Sourati · Kian Ahrabian · Kaixin Ma · Filip Ilievski · Jay Pujara
[ East Exhibit Hall A-C ]
Abstract
While multi-modal large language models (MLLMs) have shown significant progress across popular visual reasoning benchmarks, whether they possess abstract visual reasoning abilities remains an open question. Similar to the Sudoku puzzles, abstract visual reasoning (AVR) problems require finding high-level patterns (e.g., repetition constraints on numbers) that control the input shapes (e.g., digits) in a specific task configuration (e.g., matrix). However, existing AVR benchmarks only consider a limited set of patterns (addition, conjunction), input shapes (rectangle, square), and task configurations (3 × 3 matrices). And they fail to capture all abstract reasoning patterns in human cognition necessary for addressing real-world tasks, such as geometric properties and object boundary understanding in real-world navigation. To evaluate MLLMs’ AVR abilities systematically, we introduce MARVEL founded on the core knowledge system in human cognition, a multi-dimensional AVR benchmark with 770 puzzles composed of six core knowledge patterns, geometric and abstract shapes, and five different task configurations. To inspect whether the model performance is grounded in perception or reasoning, MARVEL complements the standard AVR question with perception questions in a hierarchical evaluation framework. We conduct comprehensive experiments on MARVEL with ten representative MLLMs in zero-shot and few-shot settings. Our experiments reveal that all MLLMs show near-random …
Poster
Wenhao Wang · Yi Yang
[ East Exhibit Hall A-C ]

Abstract
The arrival of Sora marks a new era for text-to-video diffusion models, bringing significant advancements in video generation and potential applications. However, Sora, along with other text-to-video diffusion models, is highly reliant on prompts, and there is no publicly available dataset that features a study of text-to-video prompts. In this paper, we introduce VidProM, the first large-scale dataset comprising 1.67 Million unique text-to-Video Prompts from real users. Additionally, this dataset includes 6.69 million videos generated by four state-of-the-art diffusion models, alongside some related data. We initially discuss the curation of this large-scale dataset, a process that is both time-consuming and costly. Subsequently, we underscore the need for a new prompt dataset specifically designed for text-to-video generation by illustrating how VidProM differs from DiffusionDB, a large-scale prompt-gallery dataset for image generation. Our extensive and diverse dataset also opens up many exciting new research areas. For instance, we suggest exploring text-to-video prompt engineering, efficient video generation, and video copy detection for diffusion models to develop better, more efficient, and safer models. The project (including the collected dataset VidProM and related code) is publicly available at https://vidprom.github.io under the CC-BY-NC 4.0 License.
Poster
Xihuai Wang · Shao Zhang · Wenhao Zhang · Wentao Dong · Jingxiao Chen · Ying Wen · Weinan Zhang
[ West Ballroom A-D ]
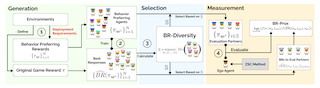
Abstract
Zero-shot coordination (ZSC) is a new cooperative multi-agent reinforcement learning (MARL) challenge that aims to train an ego agent to work with diverse, unseen partners during deployment. The significant difference between the deployment-time partners' distribution and the training partners' distribution determined by the training algorithm makes ZSC a unique out-of-distribution (OOD) generalization challenge. The potential distribution gap between evaluation and deployment-time partners leads to inadequate evaluation, which is exacerbated by the lack of appropriate evaluation metrics. In this paper, we present **ZSC-Eval**, the first evaluation toolkit and benchmark for ZSC algorithms. ZSC-Eval consists of: 1) Generation of evaluation partner candidates through behavior-preferring rewards to approximate deployment-time partners' distribution; 2) Selection of evaluation partners by Best-Response Diversity (BR-Div); 3) Measurement of generalization performance with various evaluation partners via the Best-Response Proximity (BR-Prox) metric. We use ZSC-Eval to benchmark ZSC algorithms in Overcooked and Google Research Football environments and get novel empirical findings. We also conduct a human experiment of current ZSC algorithms to verify the ZSC-Eval's consistency with human evaluation. ZSC-Eval is now available at https://github.com/sjtu-marl/ZSC-Eval.
Spotlight Poster
Yury Kuratov · Aydar Bulatov · Petr Anokhin · Ivan Rodkin · Dmitry Sorokin · Artyom Sorokin · Mikhail Burtsev
[ West Ballroom A-D ]
Abstract
In recent years, the input context sizes of large language models (LLMs) have increased dramatically. However, existing evaluation methods have not kept pace, failing to comprehensively assess the efficiency of models in handling long contexts. To bridge this gap, we introduce the BABILong benchmark, designed to test language models' ability to reason across facts distributed in extremely long documents. BABILong includes a diverse set of 20 reasoning tasks, including fact chaining, simple induction, deduction, counting, and handling lists/sets. These tasks are challenging on their own, and even more demanding when the required facts are scattered across long natural text. Our evaluations show that popular LLMs effectively utilize only 10-20% of the context and their performance declines sharply with increased reasoning complexity. Among alternatives to in-context reasoning, Retrieval-Augmented Generation methods achieve a modest 60% accuracy on single-fact question answering, independent of context length. Among context extension methods, the highest performance is demonstrated by recurrent memory transformers after fine-tuning, enabling the processing of lengths up to 50 million tokens. The BABILong benchmark is extendable to any length to support the evaluation of new upcoming models with increased capabilities, and we provide splits up to 10 million token lengths.
Poster
Pedro R. A. S. Bassi · Wenxuan Li · Yucheng Tang · Fabian Isensee · Zifu Wang · Jieneng Chen · Yu-Cheng Chou · Yannick Kirchhoff · Maximilian R. Rokuss · Ziyan Huang · Jin Ye · Junjun He · Tassilo Wald · Constantin Ulrich · Michael Baumgartner · Saikat Roy · Klaus Maier-Hein · Paul Jaeger · Yiwen Ye · Yutong Xie · Jianpeng Zhang · Ziyang Chen · Yong Xia · Zhaohu Xing · Lei Zhu · Yousef Sadegheih · Afshin Bozorgpour · Pratibha Kumari · Reza Azad · Dorit Merhof · Pengcheng Shi · Ting Ma · Yuxin Du · Fan BAI · Tiejun Huang · Bo Zhao · Haonan Wang · Xiaomeng Li · Hanxue Gu · Haoyu Dong · Jichen Yang · Maciej Mazurowski · Saumya Gupta · Linshan Wu · Jia-Xin Zhuang · Hao CHEN · Holger Roth · Daguang Xu · Matthew Blaschko · Sergio Decherchi · Andrea Cavalli · Alan Yuille · Zongwei Zhou
[ West Ballroom A-D ]
Abstract
How can we test AI performance? This question seems trivial, but it isn't. Standard benchmarks often have problems such as in-distribution and small-size test sets, oversimplified metrics, unfair comparisons, and short-term outcome pressure. As a consequence, good performance on standard benchmarks does not guarantee success in real-world scenarios. To address these problems, we present Touchstone, a large-scale collaborative segmentation benchmark of 9 types of abdominal organs. This benchmark is based on 5,195 training CT scans from 76 hospitals around the world and 5,903 testing CT scans from 11 additional hospitals. This diverse test set enhances the statistical significance of benchmark results and rigorously evaluates AI algorithms across various out-of-distribution scenarios. We invited 14 inventors of 19 AI algorithms to train their algorithms, while our team, as a third party, independently evaluated these algorithms on three test sets. In addition, we also evaluated pre-existing AI frameworks---which, differing from algorithms, are more flexible and can support different algorithms—including MONAI from NVIDIA, nnU-Net from DKFZ, and numerous other open-source frameworks. We are committed to expanding this benchmark to encourage more innovation of AI algorithms for the medical domain.
Poster
Michał Junczyk
[ West Ballroom A-D ]

Abstract
Speech datasets available in the public domain are often underutilized because of challenges in accessibility and interoperability. To address this, a system to survey, catalog, and curate existing speech datasets was developed, enabling reproducible evaluation of automatic speech recognition (ASR) systems. The system was applied to curate over 24 datasets and evaluate 25 ASR models, with a specific focus on Polish. This research represents the most extensive comparison to date of commercial and free ASR systems for the Polish language, drawing insights from 600 system-model-test set evaluations across 8 analysis scenarios. Curated datasets and benchmark results are available publicly. The evaluation tools are open-sourced to support reproducibility of the benchmark, encourage community-driven improvements, and facilitate adaptation for other languages.
Poster
Mariia Vladimirova · Federico Pavone · Eustache Diemert
[ West Ballroom A-D ]
Abstract
We introduce a fairness-aware dataset for job recommendation in advertising, designed to foster research in algorithmic fairness within real-world scenarios. It was collected and prepared to comply with privacy standards and business confidentiality. An additional challenge is the lack of access to protected user attributes such as gender, for which we propose a pragmatic solution to obtain a proxy estimate. Despite being anonymized and including a proxy for a sensitive attribute, our dataset preserves predictive power and maintains a realistic and challenging benchmark. This dataset addresses a significant gap in the availability of fairness-focused resources for high-impact domains like advertising -- the actual impact being having access or not to precious employment opportunities, where balancing fairness and utility is a common industrial challenge. We also explore various stages in the advertising process where unfairness can occur and introduce a method to compute a fair utility metric for the job recommendations in online systems case from a biased dataset. Experimental evaluations of bias mitigation techniques on the released dataset demonstrate potential improvements in fairness and the associated trade-offs with utility.The dataset is hosted at https://huggingface.co/datasets/criteo/FairJob. Source code for the experiments is hosted at https://github.com/criteo-research/FairJob-dataset/.
Poster
Hee Jae Kim · Kathakoli Sengupta · Masaki Kuribayashi · Hernisa Kacorri · Eshed Ohn-Bar
[ West Ballroom A-D ]

Abstract
People who are blind perceive the world differently than those who are sighted, which can result in distinct motion characteristics. For instance, when crossing at an intersection, blind individuals may have different patterns of movement, such as veering more from a straight path or using touch-based exploration around curbs and obstacles. These behaviors may appear less predictable to motion models embedded in technologies such as autonomous vehicles. Yet, the ability of 3D motion models to capture such behavior has not been previously studied, as existing datasets for 3D human motion currently lack diversity and are biased toward people who are sighted. In this work, we introduce BlindWays, the first multimodal motion benchmark for pedestrians who are blind. We collect 3D motion data using wearable sensors with 11 blind participants navigating eight different routes in a real-world urban setting. Additionally, we provide rich textual descriptions that capture the distinctive movement characteristics of blind pedestrians and their interactions with both the navigation aid (e.g., a white cane or a guide dog) and the environment. We benchmark state-of-the-art 3D human prediction models, finding poor performance with off-the-shelf and pre-training-based methods for our novel task. To contribute toward safer and more reliable systems that …
Poster
Liyun Zhu · Lei Wang · Arjun Raj · Tom Gedeon · Chen Chen
[ West Ballroom A-D ]

Abstract
Video Anomaly Detection (VAD) finds widespread applications in security surveillance, traffic monitoring, industrial monitoring, and healthcare. Despite extensive research efforts, there remains a lack of concise reviews that provide insightful guidance for researchers. Such reviews would serve as quick references to grasp current challenges, research trends, and future directions. In this paper, we present such a review, examining models and datasets from various perspectives. We emphasize the critical relationship between model and dataset, where the quality and diversity of datasets profoundly influence model performance, and dataset development adapts to the evolving needs of emerging approaches. Our review identifies practical issues, including the absence of comprehensive datasets with diverse scenarios. To address this, we introduce a new dataset, Multi-Scenario Anomaly Detection (MSAD), comprising 14 distinct scenarios captured from various camera views. Our dataset has diverse motion patterns and challenging variations, such as different lighting and weather conditions, providing a robust foundation for training superior models. We conduct an in-depth analysis of recent representative models using MSAD and highlight its potential in addressing the challenges of detecting anomalies across diverse and evolving surveillance scenarios.
Poster
Jiahao Ying · Yixin Cao · Yushi Bai · QIANRU SUN · Bo Wang · Wei Tang · Zhaojun Ding · Yizhe Yang · Xuanjing Huang · Shuicheng Yan
[ East Exhibit Hall A-C ]
Abstract
Large language models (LLMs) have achieved impressive performance across various natural language benchmarks, prompting a continual need to curate more difficult datasets for larger LLMs, which is costly and time-consuming. In this paper, we propose to automate dataset updating and provide systematical analysis regarding its effectiveness in dealing with benchmark leakage issue, difficulty control, and stability. Thus, once current benchmark has been mastered or leaked, we can update it for timely and reliable evaluation. There are two updating strategies: 1) mimicking strategy to generate similar samples based on original data, preserving stylistic and contextual essence, and 2) extending strategy that further expands existing samples at varying cognitive levels by adapting Bloom’s taxonomy of educational objectives. Extensive experiments on updated MMLU and BIG-Bench demonstrate the stability of the proposed strategies and find that the mimicking strategy can effectively alleviate issues of overestimation from benchmark leakage. In cases where the efficient mimicking strategy fails, our extending strategy still shows promising results. Additionally, by controlling the difficulty, we can better discern the models’ performance and enable fine-grained analysis — neither too difficult nor too easy an exam can fairly judge students’ learning status. To the best of our knowledge, we are the first …
Spotlight Poster
Hien Vu · Omkar Chandrakant Prabhune · Unmesh Raskar · Dimuth Panditharatne · Hanwook Chung · Christopher Choi · Younghyun Kim
[ West Ballroom A-D ]

Abstract
Precision livestock farming (PLF) has been transformed by machine learning (ML), enabling more precise and timely interventions that enhance overall farm productivity, animal welfare, and environmental sustainability. However, despite the availability of various sensing technologies, few datasets leverage multiple modalities, which are crucial for developing more accurate and efficient monitoring devices and ML models. To address this gap, we present MmCows, a multimodal dataset for dairy cattle monitoring. This dataset comprises a large amount of synchronized, high-quality measurement data on behavioral, physiological, and environmental factors. It includes two weeks of data collected using wearable and implantable sensors deployed on ten milking Holstein cows, such as ultra-wideband (UWB) sensors, inertial sensors, and body temperature sensors. In addition, it features 4.8 million frames of high-resolution image sequences from four isometric view cameras, as well as temperature and humidity data from environmental sensors. We also gathered milk yield data and outdoor weather conditions. One full day’s worth of image data is annotated as ground truth, totaling 20,000 frames with 213,000 bounding boxes of 16 cows, along with their 3D locations and behavior labels. An extensive analysis of MmCows is provided to evaluate the modalities individually and their complementary benefits. The release of MmCows …
Poster
Lin Chen · Xilin Wei · Jinsong Li · Xiaoyi Dong · Pan Zhang · Yuhang Zang · Zehui Chen · Haodong Duan · lin bin · Zhenyu Tang · Li Yuan · Yu Qiao · Dahua Lin · Feng Zhao · Jiaqi Wang
[ East Exhibit Hall A-C ]
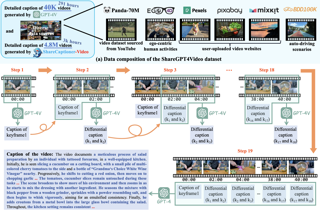
Abstract
We present the ShareGPT4Video series, aiming to facilitate the video understanding of large video-language models (LVLMs) and the video generation of text-to-video models (T2VMs) via dense and precise captions. The series comprises: 1) ShareGPT4Video, 40K GPT4V annotated dense captions of videos with various lengths and sources, developed through carefully designed data filtering and annotating strategy. 2) ShareCaptioner-Video, an efficient and capable captioning model for arbitrary videos, with 4.8M high-quality aesthetic videos annotated by it. 3) ShareGPT4Video-8B, a simple yet superb LVLM that reached SOTA performance on three advancing video benchmarks. To achieve this, taking aside the non-scalable costly human annotators, we find using GPT4V to caption video with a naive multi-frame or frame-concatenation input strategy leads to less detailed and sometimes temporal-confused results. We argue the challenge of designing a high-quality video captioning strategy lies in three aspects: 1) Inter-frame precise temporal change understanding. 2) Intra-frame detailed content description. 3) Frame-number scalability for arbitrary-length videos. To this end, we meticulously designed a differential video captioning strategy, which is stable, scalable, and efficient for generating captions for videos with arbitrary resolution, aspect ratios, and length. Based on it, we construct ShareGPT4Video, which contains 40K high-quality videos spanning a wide range of …
Poster
Ruiyuan Lyu · Jingli Lin · Tai WANG · Shuaiyang · Xiaohan Mao · Yilun Chen · Runsen Xu · Haifeng Huang · Chenming Zhu · Dahua Lin · Jiangmiao Pang
[ West Ballroom A-D ]

Abstract
With the emergence of LLMs and their integration with other data modalities, multi-modal 3D perception attracts more attention due to its connectivity to the physical world and makes rapid progress. However, limited by existing datasets, previous works mainly focus on understanding object properties or inter-object spatial relationships in a 3D scene. To tackle this problem, this paper builds the first largest ever multi-modal 3D scene dataset and benchmark with hierarchical grounded language annotations, MMScan. It is constructed based on a top-down logic, from region to object level, from a single target to inter-target relationships, covering holistic aspects of spatial and attribute understanding. The overall pipeline incorporates powerful VLMs via carefully designed prompts to initialize the annotations efficiently and further involve humans' correction in the loop to ensure the annotations are natural, correct, and comprehensive. Built upon existing 3D scanning data, the resulting multi-modal 3D dataset encompasses 1.4M meta-annotated captions on 109k objects and 7.7k regions as well as over 3.04M diverse samples for 3D visual grounding and question-answering benchmarks. We evaluate representative baselines on our benchmarks, analyze their capabilities in different aspects, and showcase the key problems to be addressed in the future. Furthermore, we use this high-quality dataset to …
Poster
Haoyi Zhu · Yating Wang · Di Huang · Weicai Ye · Wanli Ouyang · Tong He
[ East Exhibit Hall A-C ]
Abstract
In robot learning, the observation space is crucial due to the distinct characteristics of different modalities, which can potentially become a bottleneck alongside policy design. In this study, we explore the influence of various observation spaces on robot learning, focusing on three predominant modalities: RGB, RGB-D, and point cloud. We introduce OBSBench, a benchmark comprising two simulators and 125 tasks, along with standardized pipelines for various encoders and policy baselines. Extensive experiments on diverse contact-rich manipulation tasks reveal a notable trend: point cloud-based methods, even those with the simplest designs, frequently outperform their RGB and RGB-D counterparts. This trend persists in both scenarios: training from scratch and utilizing pre-training. Furthermore, our findings demonstrate that point cloud observations often yield better policy performance and significantly stronger generalization capabilities across various geometric and visual conditions. These outcomes suggest that the 3D point cloud is a valuable observation modality for intricate robotic tasks. We also suggest that incorporating both appearance and coordinate information can enhance the performance of point cloud methods. We hope our work provides valuable insights and guidance for designing more generalizable and robust robotic models.
Poster
Jannik Franzen · Claudia Winklmayr · Vanessa Emanuela Guarino · Christoph Karg · Xiaoyan Yu · Nora Koreuber · Jan Albrecht · Philip Bischoff · Dagmar Kainmueller
[ West Ballroom A-D ]
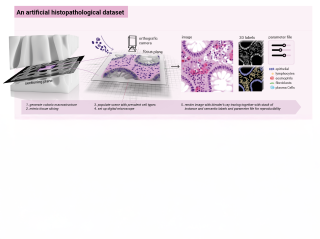
Abstract
Uncertainty Quantification (UQ) is crucial for reliable image segmentation. Yet, while the field sees continual development of novel methods, a lack of agreed-upon benchmarks limits their systematic comparison and evaluation: Current UQ methods are typically tested either on overly simplistic toy datasets or on complex real-world datasets that do not allow to discern true uncertainty. To unify both controllability and complexity, we introduce Arctique, a procedurally generated dataset modeled after histopathological colon images. We chose histopathological images for two reasons: 1) their complexity in terms of intricate object structures and highly variable appearance, which yields challenging segmentation problems, and 2) their broad prevalence for medical diagnosis and respective relevance of high-quality UQ. To generate Arctique, we established a Blender-based framework for 3D scene creation with intrinsic noise manipulation. Arctique contains up to 50,000 rendered images with precise masks as well as noisy label simulations. We show that by independently controlling the uncertainty in both images and labels, we can effectively study the performance of several commonly used UQ methods. Hence, Arctique serves as a critical resource for benchmarking and advancing UQ techniques and other methodologies in complex, multi-object environments, bridging the gap between realism and controllability. All code is publicly …
Poster
Ye Liu · Zongyang Ma · Zhongang Qi · Yang Wu · Ying Shan · Chang Chen
[ East Exhibit Hall A-C ]
Abstract
Recent advances in Video Large Language Models (Video-LLMs) have demonstrated their great potential in general-purpose video understanding. To verify the significance of these models, a number of benchmarks have been proposed to diagnose their capabilities in different scenarios. However, existing benchmarks merely evaluate models through video-level question-answering, lacking fine-grained event-level assessment and task diversity. To fill this gap, we introduce E.T. Bench (Event-Level & Time-Sensitive Video Understanding Benchmark), a large-scale and high-quality benchmark for open-ended event-level video understanding. Categorized within a 3-level task taxonomy, E.T. Bench encompasses 7.3K samples under 12 tasks with 7K videos (251.4h total length) under 8 domains, providing comprehensive evaluations. We extensively evaluated 8 Image-LLMs and 12 Video-LLMs on our benchmark, and the results reveal that state-of-the-art models for coarse-level (video-level) understanding struggle to solve our fine-grained tasks, e.g., grounding event-of-interests within videos, largely due to the short video context length, improper time representations, and lack of multi-event training data. Focusing on these issues, we further propose a strong baseline model, E.T. Chat, together with an instruction-tuning dataset E.T. Instruct 164K tailored for fine-grained event-level understanding. Our simple but effective solution demonstrates superior performance in multiple scenarios.
Poster
Xiaoyue Xu · Qinyuan Ye · Xiang Ren
[ East Exhibit Hall A-C ]
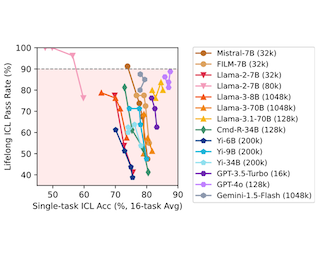
Abstract
We introduce Lifelong ICL, a problem setting that challenges long-context language models (LMs) to learn a sequence of language tasks through in-context learning (ICL). We further introduce Task Haystack, an evaluation suite dedicated to assessing and diagnosing how long-context LMs utilizes contexts in Lifelong ICL. When given a task instruction and test inputs, long-context LMs are expectedto leverage the relevant demonstrations in the Lifelong ICL prompt, avoid distraction and interference from other tasks, and achieve test accuracies that are not significantly worse than those of the Single-task ICL baseline.Task Haystack draws inspiration from the widely-adopted “needle-in-a-haystack” (NIAH) evaluation, but presents distinct new challenges. It requires models (1) to utilize the contexts at a deeper level, rather than resorting to simple copying and pasting; (2) to navigate through long streams of evolving topics and tasks, proxying the complexities and dynamism of contexts in real-world scenarios. Additionally, Task Haystack inherits the controllability of NIAH, providing model developers with tools and visualizations to identify model vulnerabilities effectively.We benchmark 14 long-context LMs using Task Haystack, finding that frontier models like GPT-4o still struggle with the setting, failing on 15% of cases on average. Most open-weight models further lack behind by a large margin, with …
Poster
Aman Patel · Arpita Singhal · Austin Wang · Anusri Pampari · Maya Kasowski · Anshul Kundaje
[ West Ballroom A-D ]
Abstract
Recent advances in self-supervised models for natural language, vision, and protein sequences have inspired the development of large genomic DNA language models (DNALMs). These models aim to learn generalizable representations of diverse DNA elements, potentially enabling various genomic prediction, interpretation and design tasks. Despite their potential, existing benchmarks do not adequately assess the capabilities of DNALMs on key downstream applications involving an important class of non-coding DNA elements critical for regulating gene activity. In this study, we introduce DART-Eval, a suite of representative benchmarks specifically focused on regulatory DNA to evaluate model performance across zero-shot, probed, and fine-tuned scenarios against contemporary ab initio models as baselines. Our benchmarks target biologically meaningful downstream tasks such as functional sequence feature discovery, predicting cell-type specific regulatory activity, and counterfactual prediction of the impacts of genetic variants. We find that current DNALMs exhibit inconsistent performance and do not offer compelling gains over alternative baseline models for most tasks, while requiring significantly more computational resources. We discuss potentially promising modeling, data curation, and evaluation strategies for the next generation of DNALMs. Our code is available at https://github.com/kundajelab/DART-Eval
Poster
Dongwoo Lee · JoonKyu Park · Kyoung Mu Lee
[ West Ballroom A-D ]

Abstract
To train a deblurring network, an appropriate dataset with paired blurry and sharp images is essential.Existing datasets collect blurry images either synthetically by aggregating consecutive sharp frames or using sophisticated camera systems to capture real blur.However, these methods offer limited diversity in blur types (blur trajectories) or require extensive human effort to reconstruct large-scale datasets, failing to fully reflect real-world blur scenarios.To address this, we propose GS-Blur, a dataset of synthesized realistic blurry images created using a novel approach.To this end, we first reconstruct 3D scenes from multi-view images using 3D Gaussian Splatting~(3DGS), then render blurry images by moving the camera view along the randomly generated motion trajectories.By adopting various camera trajectories in reconstructing our GS-Blur, our dataset contains realistic and diverse types of blur, offering a large-scale dataset that generalizes well to real-world blur.Using GS-Blur with various deblurring methods, we demonstrate its ability to generalize effectively compared to previous synthetic or real blur datasets, showing significant improvements in deblurring performance.We will publicly release our dataset.
Poster
Yubin Hu · Kairui Wen · Heng Zhou · Xiaoyang Guo · Yong-jin Liu
[ West Ballroom A-D ]

Abstract
Reconstructing accurate 3D surfaces for street-view scenarios is crucial for applications such as digital entertainment and autonomous driving simulation. However, existing street-view datasets, including KITTI, Waymo, and nuScenes, only offer noisy LiDAR points as ground-truth data for geometric evaluation of reconstructed surfaces. These geometric ground-truths often lack the necessary precision to evaluate surface positions and do not provide data for assessing surface normals. To overcome these challenges, we introduce the SS3DM dataset, comprising precise \textbf{S}ynthetic \textbf{S}treet-view \textbf{3D} \textbf{M}esh models exported from the CARLA simulator. These mesh models facilitate accurate position evaluation and include normal vectors for evaluating surface normal. To simulate the input data in realistic driving scenarios for 3D reconstruction, we virtually drive a vehicle equipped with six RGB cameras and five LiDAR sensors in diverse outdoor scenes. Leveraging this dataset, we establish a benchmark for state-of-the-art surface reconstruction methods, providing a comprehensive evaluation of the associated challenges. For more information, visit our homepage at https://ss3dm.top.
Poster
Benjamin Estermann · Luca Lanzendörfer · Yannick Niedermayr · Roger Wattenhofer
[ West Ballroom A-D ]
Abstract
Algorithmic reasoning is a fundamental cognitive ability that plays a pivotal role in problem-solving and decision-making processes. Reinforcement Learning (RL) has demonstrated remarkable proficiency in tasks such as motor control, handling perceptual input, and managing stochastic environments. These advancements have been enabled in part by the availability of benchmarks. In this work we introduce PUZZLES, a benchmark based on Simon Tatham's Portable Puzzle Collection, aimed at fostering progress in algorithmic and logical reasoning in RL. PUZZLES contains 40 diverse logic puzzles of adjustable sizes and varying levels of complexity, providing detailed information on the strengths and generalization capabilities of RL agents. Furthermore, we evaluate various RL algorithms on PUZZLES, providing baseline comparisons and demonstrating the potential for future research. All the software, including the environment, is available at this https url.
Oral Poster
Ma Chang · Junlei Zhang · Zhihao Zhu · Cheng Yang · Yujiu Yang · Yaohui Jin · Zhenzhong Lan · Lingpeng Kong · Junxian He
[ West Ballroom A-D ]

Abstract
Evaluating large language models (LLMs) as general-purpose agents is essential for understanding their capabilities and facilitating their integration into practical applications. However, the evaluation process presents substantial challenges. A primary obstacle is the benchmarking of agent performance across diverse scenarios within a unified framework, especially in maintaining partially-observable environments and ensuring multi-round interactions. Moreover, current evaluation frameworks mostly focus on the final success rate, revealing few insights during the process and failing to provide a deep understanding of the model abilities. To address these challenges, we introduce AgentBoard, a pioneering comprehensive benchmark and accompanied open-source evaluation framework tailored to analytical evaluation of LLM agents. AgentBoard offers a fine-grained progress rate metric that captures incremental advancements as well as a comprehensive evaluation toolkit that features easy assessment of agents for multi-faceted analysis through interactive visualization. This not only sheds light on the capabilities and limitations of LLM agents but also propels the interpretability of their performance to the forefront. Ultimately, AgentBoard serves as a significant step towards demystifying agent behaviors and accelerating the development of stronger LLM agents.
Poster
Yihua Zhang · Chongyu Fan · Yimeng Zhang · Yuguang Yao · Jinghan Jia · Jiancheng Liu · Gaoyuan Zhang · Gaowen Liu · Ramana Kompella · Xiaoming Liu · Sijia Liu
[ East Exhibit Hall A-C ]
Abstract
The technological advancements in diffusion models (DMs) have demonstrated unprecedented capabilities in text-to-image generation and are widely used in diverse applications. However, they have also raised significant societal concerns, such as the generation of harmful content and copyright disputes. Machine unlearning (MU) has emerged as a promising solution, capable of removing undesired generative capabilities from DMs. However, existing MU evaluation systems present several key challenges that can result in incomplete and inaccurate assessments. To address these issues, we propose UnlearnCanvas, a comprehensive high-resolution stylized image dataset that facilitates the evaluation of the unlearning of artistic styles and associated objects. This dataset enables the establishment of a standardized, automated evaluation framework with 7 quantitative metrics assessing various aspects of the unlearning performance for DMs. Through extensive experiments, we benchmark 9 state-of-the-art MU methods for DMs, revealing novel insights into their strengths, weaknesses, and underlying mechanisms. Additionally, we explore challenging unlearning scenarios for DMs to evaluate worst-case performance against adversarial prompts, the unlearning of finer-scale concepts, and sequential unlearning. We hope that this study can pave the way for developing more effective, accurate, and robust DM unlearning methods, ensuring safer and more ethical applications of DMs in the future. The dataset, benchmark, …
Poster
Renjie Pi · Jianshu Zhang · Jipeng Zhang · Rui Pan · Zhekai Chen · Tong Zhang
[ East Exhibit Hall A-C ]

Abstract
Image description datasets play a crucial role in the advancement of various applications such as image understanding, text-to-image generation, and text-image retrieval. Currently, image description datasets primarily originate from two sources. One source is the scraping of image-text pairs from the web. Despite their abundance, these descriptions are often of low quality and noisy. Another way is through human labeling. Datasets such as COCO are generally very short and lack details. Although detailed image descriptions can be annotated by humans, the high cost limits their quantity and feasibility. These limitations underscore the need for more efficient and scalable methods to generate accurate and detailed image descriptions. In this paper, we propose an innovative framework termed Image Textualization, which automatically produces high-quality image descriptions by leveraging existing mult-modal large language models (MLLMs) and multiple vision expert models in a collaborative manner. We conduct various experiments to validate the high quality of the descriptions constructed by our framework. Furthermore, we show that MLLMs fine-tuned on our dataset acquire an unprecedented capability of generating richer image descriptions, substantially increasing the length and detail of their output with even less hallucinations.
Poster
Ivana Kajić · Olivia Wiles · Isabela Albuquerque · Matthias Bauer · Su Wang · Jordi Pont-Tuset · Aida Nematzadeh
[ West Ballroom A-D ]

Abstract
Text-to-image generative models are capable of producing high-quality images that often faithfully depict concepts described using natural language. In this work, we comprehensively evaluate a range of text-to-image models on numerical reasoning tasks of varying difficulty, and show that even the most advanced models have only rudimentary numerical skills. Specifically, their ability to correctly generate an exact number of objects in an image is limited to small numbers, it is highly dependent on the context the number term appears in, and it deteriorates quickly with each successive number. We also demonstrate that models have poor understanding of linguistic quantifiers (such as “few” or “as many as”), the concept of zero, and struggle with more advanced concepts such as fractional representations. We bundle prompts, generated images and human annotations into GeckoNum, a novel benchmark for evaluation of numerical reasoning.
Poster
Yunong Liu · Cristobal Eyzaguirre · Manling Li · Shubh Khanna · Juan Carlos Niebles · Vineeth Ravi · Saumitra Mishra · Weiyu Liu · Jiajun Wu
[ West Ballroom A-D ]
Abstract
Shape assembly is a ubiquitous task in daily life, integral for constructing complex 3D structures like IKEA furniture. While significant progress has been made in developing autonomous agents for shape assembly, existing datasets have not yet tackled the 4D grounding of assembly instructions in videos, essential for a holistic understanding of assembly in 3D space over time. We introduce IKEA Video Manuals, a dataset that features 3D models of furniture parts, instructional manuals, assembly videos from the Internet, and most importantly, annotations of dense spatio-temporal alignments between these data modalities. To demonstrate the utility of IKEA Video Manuals, we present five applications essential for shape assembly: assembly plan generation, part-conditioned segmentation, part-conditioned pose estimation, video object segmentation, and furniture assembly based on instructional video manuals. For each application, we provide evaluation metrics and baseline methods. Through experiments on our annotated data, we highlight many challenges in grounding assembly instructions in videos to improve shape assembly, including handling occlusions, varying viewpoints, and extended assembly sequences.
Poster
Laurent Mertens · Elahe Yargholi · Hans Op de Beeck · Jan Van den Stock · Joost Vennekens
[ West Ballroom A-D ]
Abstract
We introduce FindingEmo, a new image dataset containing annotations for 25k images, specifically tailored to Emotion Recognition. Contrary to existing datasets, it focuses on complex scenes depicting multiple people in various naturalistic, social settings, with images being annotated as a whole, thereby going beyond the traditional focus on faces or single individuals. Annotated dimensions include Valence, Arousal and Emotion label, with annotations gathered using Prolific. Together with the annotations, we release the list of URLs pointing to the original images, as well as all associated source code.
Poster
Zhikai Chen · Haitao Mao · Jingzhe Liu · Yu Song · Bingheng Li · Wei Jin · Bahare Fatemi · Anton Tsitsulin · Bryan Perozzi · Hui Liu · Jiliang Tang
[ East Exhibit Hall A-C ]
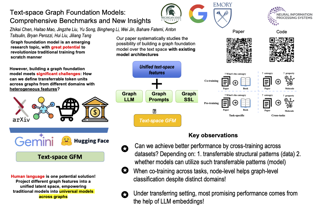
Abstract
Given the ubiquity of graph data and its applications in diverse domains, building a Graph Foundation Model (GFM) that can work well across different graphs and tasks with a unified backbone has recently garnered significant interests. A major obstacle to achieving this goal stems from the fact that graphs from different domains often exhibit diverse node features. Inspired by multi-modal models that align different modalities with natural language, the text has recently been adopted to provide a unified feature space for diverse graphs. Despite the great potential of these text-space GFMs, current research in this field is hampered by two problems. First, the absence of a comprehensive benchmark with unified problem settings hinders a clear understanding of the comparative effectiveness and practical value of different text-space GFMs. Second, there is a lack of sufficient datasets to thoroughly explore the methods' full potential and verify their effectiveness across diverse settings. To address these issues, we conduct a comprehensive benchmark providing novel text-space datasets and comprehensive evaluation under unified problem settings. Empirical results provide new insights and inspire future research directions. Our code and data are publicly available from https://github.com/CurryTang/TSGFM.
Poster
Yang Zhou · Tan Faith · Yanyu Xu · Sicong Leng · Xinxing Xu · Yong Liu · Rick Siow Mong Goh
[ West Ballroom A-D ]
Abstract
Medical Vision-Language Pretraining (MedVLP) shows promise in learning generalizable and transferable visual representations from paired and unpaired medical images and reports. MedVLP can provide useful features to downstream tasks and facilitate adapting task-specific models to new setups using fewer examples. However, existing MedVLP methods often differ in terms of datasets, preprocessing, and finetuning implementations. This pose great challenges in evaluating how well a MedVLP method generalizes to various clinically-relevant tasks due to the lack of unified, standardized, and comprehensive benchmark. To fill this gap, we propose BenchX, a unified benchmark framework that enables head-to-head comparison and systematical analysis between MedVLP methods using public chest X-ray datasets. Specifically, BenchX is composed of three components: 1) Comprehensive datasets covering nine datasets and four medical tasks; 2) Benchmark suites to standardize data preprocessing, train-test splits, and parameter selection; 3) Unified finetuning protocols that accommodate heterogeneous MedVLP methods for consistent task adaptation in classification, segmentation, and report generation, respectively. Utilizing BenchX, we establish baselines for nine state-of-the-art MedVLP methods and found that the performance of some early MedVLP methods can be enhanced to surpass more recent ones, prompting a revisiting of the developments and conclusions from prior works in MedVLP. Our code are available …
Poster
Yuchen Ren · Zhiyuan Chen · Lifeng Qiao · Hongtai Jing · Yuchen Cai · Sheng Xu · Peng Ye · Xinzhu Ma · Siqi Sun · Hongliang Yan · Dong Yuan · Wanli Ouyang · Xihui Liu
[ East Exhibit Hall A-C ]
Abstract
RNA plays a pivotal role in translating genetic instructions into functional outcomes, underscoring its importance in biological processes and disease mechanisms. Despite the emergence of numerous deep learning approaches for RNA, particularly universal RNA language models, there remains a significant lack of standardized benchmarks to assess the effectiveness of these methods. In this study, we introduce the first comprehensive RNA benchmark BEACON **BE**nchm**A**rk for **CO**mprehensive R**N**A Task and Language Models).First, BEACON comprises 13 distinct tasks derived from extensive previous work covering structural analysis, functional studies, and engineering applications, enabling a comprehensive assessment of the performance of methods on various RNA understanding tasks. Second, we examine a range of models, including traditional approaches like CNNs, as well as advanced RNA foundation models based on language models, offering valuable insights into the task-specific performances of these models. Third, we investigate the vital RNA language model components from the tokenizer and positional encoding aspects. Notably, our findings emphasize the superiority of single nucleotide tokenization and the effectiveness of Attention with Linear Biases (ALiBi) over traditional positional encoding methods. Based on these insights, a simple yet strong baseline called BEACON-B is proposed, which can achieve outstanding performance with limited data and computational resources. The …
Spotlight Poster
Shuo Liu · Kaining Ying · Hao Zhang · yue yang · Yuqi Lin · Tianle Zhang · Chuanhao Li · Yu Qiao · Ping Luo · Wenqi Shao · Kaipeng Zhang
[ West Ballroom A-D ]
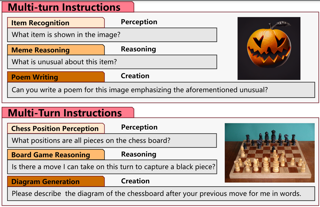
Abstract
Multi-turn visual conversation is an important ability of real-world AI assistants. However, the related evaluation benchmark is missed. This paper presents ConvBench, a multi-turn conversation benchmark with hierarchical capabilities ablation evaluation for Large Vision-Language Models (LVLMs). ConvBench comprises 577 curated multi-turn conversations, encompassing 215 tasks. These tasks are broad and open-ended, which resemble real-world user behaviors. ConvBench progressively examines the LVLMs' perception, reasoning, and creativity capabilities in each conversation and can decouple these capabilities in evaluations and thus perform reliable error attribution. Besides, considering the diversity of open-ended questions, we introduce an efficient and reliable automatic evaluation framework. Experimental results reveal that ConvBench is a significant challenge for current LVLMs, even for GPT4V, which achieves only a 39.51% score. Besides, we have some insightful findings, such as the weak perception of LVLMs inhibits authentic strengths in reasoning and creation. We believe our design of hierarchical capabilities, decoupling capabilities evaluation, and multi-turn conversation can blaze a new trail in LVLMs evaluation. Code and benchmark are released at https://github.com/shirlyliu64/ConvBench.
Poster
Yuwei Zhang · Tong Xia · Jing Han · Yu Wu · Georgios Rizos · Yang Liu · Mohammed Mosuily · J Ch · Cecilia Mascolo
[ West Ballroom A-D ]

Abstract
Respiratory audio, such as coughing and breathing sounds, has predictive power for a wide range of healthcare applications, yet is currently under-explored. The main problem for those applications arises from the difficulty in collecting large labeled task-specific data for model development. Generalizable respiratory acoustic foundation models pretrained with unlabeled data would offer appealing advantages and possibly unlock this impasse. However, given the safety-critical nature of healthcare applications, it is pivotal to also ensure openness and replicability for any proposed foundation model solution. To this end, we introduce OPERA, an OPEn Respiratory Acoustic foundation model pretraining and benchmarking system, as the first approach answering this need. We curate large-scale respiratory audio datasets ($\sim$136K samples, over 400 hours), pretrain three pioneering foundation models, and build a benchmark consisting of 19 downstream respiratory health tasks for evaluation. Our pretrained models demonstrate superior performance (against existing acoustic models pretrained with general audio on 16 out of 19 tasks) and generalizability (to unseen datasets and new respiratory audio modalities). This highlights the great promise of respiratory acoustic foundation models and encourages more studies using OPERA as an open resource to accelerate research on respiratory audio for health. The system is accessible from https://github.com/evelyn0414/OPERA.
Poster
Haoning Wu · DONGXU LI · Bei Chen · Junnan Li
[ East Exhibit Hall A-C ]
Abstract
Large multimodal models (LMMs) are processing increasingly longer and richer inputs. Albeit the progress, few public benchmark is available to measure such development. To mitigate this gap, we introduce LongVideoBench, a question-answering benchmark that features video-language interleaved inputs up to an hour long. Our benchmark includes 3,763 varying-length web-collected videos with their subtitles across diverse themes, designed to comprehensively evaluate LMMs on long-term multimodal understanding. To achieve this, we interpret the primary challenge as to accurately retrieve and reason over detailed multimodal information from long inputs. As such, we formulate a novel video question-answering task termed referring reasoning. Specifically, as part of the question, it contains a referring query that references related video contexts, called referred context. The model is then required to reason over relevant video details from the referred context. Following the paradigm of referring reasoning, we curate 6,678 human-annotated multiple-choice questions in 17 fine-grained categories, establishing one of the most comprehensive benchmarks for long-form video understanding. Evaluations suggest that the LongVideoBench presents significant challenges even for the most advanced proprietary models (e.g. GPT-4o, Gemini-1.5-Pro), while their open-source counterparts show an even larger performance gap. In addition, our results indicate that model performance on the benchmark improves only …
Poster
Daniel Dauner · Marcel Hallgarten · Tianyu Li · Xinshuo Weng · Zhiyu Huang · Zetong Yang · Hongyang Li · Igor Gilitschenski · Boris Ivanovic · Marco Pavone · Andreas Geiger · Kashyap Chitta
[ West Ballroom A-D ]

Abstract
Benchmarking vision-based driving policies is challenging. On one hand, open-loop evaluation with real data is easy, but these results do not reflect closed-loop performance. On the other, closed-loop evaluation is possible in simulation, but is hard to scale due to its significant computational demands. Further, the simulators available today exhibit a large domain gap to real data. This has resulted in an inability to draw clear conclusions from the rapidly growing body of research on end-to-end autonomous driving. In this paper, we present NAVSIM, a middle ground between these evaluation paradigms, where we use large datasets in combination with a non-reactive simulator to enable large-scale real-world benchmarking. Specifically, we gather simulation-based metrics, such as progress and time to collision, by unrolling bird's eye view abstractions of the test scenes for a short simulation horizon. Our simulation is non-reactive, i.e., the evaluated policy and environment do not influence each other. As we demonstrate empirically, this decoupling allows open-loop metric computation while being better aligned with closed-loop evaluations than traditional displacement errors. NAVSIM enabled a new competition held at CVPR 2024, where 143 teams submitted 463 entries, resulting in several new insights. On a large set of challenging scenarios, we observe that …
Poster
Jiaheng Liu · Zehao Ni · Haoran Que · Sun · Noah Wang · Jian Yang · JiakaiWang · Hongcheng Guo · Zhongyuan Peng · Ge Zhang · Jiayi Tian · Xingyuan Bu · Ke Xu · Wenge Rong · Junran Peng · ZHAO-XIANG ZHANG
[ West Ballroom A-D ]

Abstract
Believable agents can empower interactive applications ranging from immersive environments to rehearsal spaces for interpersonal communication. Recently, generative agents have been proposed to simulate believable human behavior by using Large Language Models. However, the existing method heavily relies on human-annotated agent profiles (e.g., name, age, personality, relationships with others, and so on) for the initialization of each agent, which cannot be scaled up easily. In this paper, we propose a scalable RoleAgent framework to generate high-quality role-playing agents from raw scripts, which includes building and interacting stages. Specifically, in the building stage, we use a hierarchical memory system to extract and summarize the structure and high-level information of each agent for the raw script. In the interacting stage, we propose a novel innovative mechanism with four steps to achieve a high-quality interaction between agents. Finally, we introduce a systematic and comprehensive evaluation benchmark called RoleAgentBench to evaluate the effectiveness of our RoleAgent, which includes 100 and 28 roles for 20 English and 5 Chinese scripts, respectively. Extensive experimental results on RoleAgentBench demonstrate the effectiveness of RoleAgent.
Poster
Claire Bizon Monroc · Ana Busic · Donatien Dubuc · Jiamin Zhu
[ West Ballroom A-D ]
Abstract
The wind farm control problem is challenging, since conventional model-based control strategies require tractable models of complex aerodynamical interactions between the turbines and suffer from the curse of dimension when the number of turbines increases. Recently, model-free and multi-agent reinforcement learning approaches have been used to address this challenge. In this article, we introduce WFCRL (Wind Farm Control with Reinforcement Learning), the first suite of multi-agent reinforcement learning environments for the wind farm control problem. WFCRL frames a cooperative Multi-Agent Reinforcement Learning (MARL) problem: each turbine is an agent and can learn to adjust its yaw, pitch or torque to maximize the common objective (e.g. the total power production of the farm). WFCRL also offers turbine load observations that will allow to optimize the farm performance while limiting turbine structural damages. Interfaces with two state-of-the-art farm simulators are implemented in WFCRL: a static simulator (Floris) and a dynamic simulator (FAST.farm). For each simulator, $10$ wind layouts are provided, including $5$ real wind farms. Two state-of-the-art online MARL algorithms are implemented to illustrate the scaling challenges. As learning online on FAST.Farm is highly time-consuming, WFCRL offers the possibility of designing transfer learning strategies from Floris to FAST.Farm.
Poster
Liang Peng · Junyuan Gao · Xinran Liu · Weihong Li · Shaohua Dong · Zhipeng Zhang · Heng Fan · Libo Zhang
[ West Ballroom A-D ]

Abstract
In this paper, we propose a novel benchmark, named VastTrack, aiming to facilitate the development of general visual tracking via encompassing abundant classes and videos. VastTrack consists of a few attractive properties: (1) Vast Object Category. In particular, it covers targets from 2,115 categories, significantly surpassing object classes of existing popular benchmarks (e.g., GOT-10k with 563 classes and LaSOT with 70 categories). Through providing such vast object classes, we expect to learn more general object tracking. (2) Larger scale. Compared with current benchmarks, VastTrack provides 50,610 videos with 4.2 million frames, which makes it to date the largest dataset in term of the number of videos, and hence could benefit training even more powerful visual trackers in the deep learning era. (3) Rich Annotation. Besides conventional bounding box annotations, VastTrack also provides linguistic descriptions with more than 50K sentences for the videos. Such rich annotations of VastTrack enable the development of both vision-only and vision-language tracking. In order to ensure precise annotation, each frame in the videos is manually labeled with multi-stage of careful inspections and refinements. To understand performance of existing trackers and to provide baselines for future comparison, we extensively evaluate 25 representative trackers. The results, not surprisingly, …
Poster
Shayne Longpre · Robert Mahari · Ariel Lee · Campbell Lund · Hamidah Oderinwale · William Brannon · Nayan Saxena · Naana Obeng-Marnu · Tobin South · Cole Hunter · Kevin Klyman · Christopher Klamm · Hailey Schoelkopf · Nikhil Singh · Manuel Cherep · Ahmad Anis · An Dinh · Caroline Shamiso Chitongo · Da Yin · Damien Sileo · Deividas Mataciunas · Diganta Misra · Emad Alghamdi · Enrico Shippole · Jianguo Zhang · Joanna Materzynska · Kun Qian · Kushagra Tiwary · Lester James V. Miranda · Manan Dey · Minnie Liang · Mohammed Hamdy · Niklas Muennighoff · Seonghyeon Ye · Seungone Kim · Shrestha Mohanty · Vipul Gupta · Vivek Sharma · Minh Chien Vu · Xuhui Zhou · Yizhi Li · Caiming Xiong · Luis Villa · Stella Biderman · Hanlin Li · Daphne Ippolito · Sara Hooker · Jad Kabbara · Alex Pentland
[ West Ballroom A-D ]
Abstract
General-purpose artificial intelligence (AI) systems are built on massive swathes of public web data, assembled into corpora such as C4, RefinedWeb, and Dolma. To our knowledge, we conduct the first, large-scale, longitudinal audit of the consent protocols for the web domains underlying AI training corpora. Our audit of 14,000 web domains provides an expansive view of crawlable web data and how codified data use preferences are changing over time. We observe a proliferation of AI-specific clauses to limit use, acute differences in restrictions on AI developers, as well as general inconsistencies between websites' expressed intentions in their Terms of Service and their robots.txt. We diagnose these as symptoms of ineffective web protocols, not designed to cope with the widespread re-purposing of the internet for AI. Our longitudinal analyses show that in a single year (2023-2024) there has been a rapid crescendo of data restrictions from web sources, rendering ~5\%+ of all tokens in C4, or 28%+ of the most actively maintained, critical sources in C4, fully restricted from use. For Terms of Service crawling restrictions, a full 45% of C4 is now restricted. If respected or enforced, these restrictions are rapidly biasing the diversity, freshness, and scaling laws for general-purpose …
Poster
Jieyu Zhang · Weikai Huang · Zixian Ma · Oscar Michel · Dong He · Tanmay Gupta · Wei-Chiu Ma · Ali Farhadi · Aniruddha Kembhavi · Ranjay Krishna
[ East Exhibit Hall A-C ]
Abstract
Benchmarks for large multimodal language models (MLMs) now serve to simultaneously assess the general capabilities of models instead of evaluating for a specific capability. As a result, when a developer wants to identify which models to use for their application, they are overwhelmed by the number of benchmarks and remain uncertain about which benchmark's results are most reflective of their specific use case. This paper introduces Task-Me-Anything, a benchmark generation engine which produces a benchmark tailored to a user's needs. Task-Me-Anything maintains an extendable taxonomy of visual assets and can programmatically generate a vast number of task instances. Additionally, it algorithmically addresses user queries regarding MLM performance efficiently within a computational budget. It contains 113K images, 10K videos, 2K 3D object assets, over 365 object categories, 655 attributes, and 335 relationships. It can generate 500M image/video question-answering pairs, which focus on evaluating MLM perceptual capabilities. Task-Me-Anything reveals critical insights: open-source MLMs excel in object and attribute recognition but lack spatial and temporal understanding; each model exhibits unique strengths and weaknesses; larger models generally perform better, though exceptions exist; and GPT4O demonstrates challenges in recognizing rotating/moving objects and distinguishing colors.
Poster
Fanghua Ye · Mingming Yang · Jianhui Pang · Longyue Wang · Derek Wong · Emine Yilmaz · Shuming Shi · Zhaopeng Tu
[ West Ballroom A-D ]

Abstract
The proliferation of open-source Large Language Models (LLMs) from various institutions has highlighted the urgent need for comprehensive evaluation methods. However, current evaluation platforms, such as the widely recognized HuggingFace open LLM leaderboard, neglect a crucial aspect -- uncertainty, which is vital for thoroughly assessing LLMs. To bridge this gap, we introduce a new benchmarking approach for LLMs that integrates uncertainty quantification. Our examination involves nine LLMs (LLM series) spanning five representative natural language processing tasks. Our findings reveal that: I) LLMs with higher accuracy may exhibit lower certainty; II) Larger-scale LLMs may display greater uncertainty compared to their smaller counterparts; and III) Instruction-finetuning tends to increase the uncertainty of LLMs. These results underscore the significance of incorporating uncertainty in the evaluation of LLMs. Our implementation is available at https://github.com/smartyfh/LLM-Uncertainty-Bench.
Poster
Dongyu Ru · Lin Qiu · Xiangkun Hu · Tianhang Zhang · Peng Shi · Shuaichen Chang · Cheng Jiayang · Cunxiang Wang · Shichao Sun · Huanyu Li · Zizhao Zhang · Binjie Wang · Jiarong Jiang · Tong He · Zhiguo Wang · Pengfei Liu · Yue Zhang · Zheng Zhang
[ West Ballroom A-D ]

Abstract
Despite Retrieval-Augmented Generation (RAG) has shown promising capability in leveraging external knowledge, a comprehensive evaluation of RAG systems is still challenging due to the modular nature of RAG, evaluation of long-form responses and reliability of measurements. In this paper, we propose a fine-grained evaluation framework, RAGChecker, that incorporates a suite of diagnostic metrics for both the retrieval and generation modules. Meta evaluation verifies that RAGChecker has significantly better correlations with human judgments than other evaluation metrics. Using RAGChecker, we evaluate 8 RAG systems and conduct an in-depth analysis of their performance, revealing insightful patterns and trade-offs in the design choices of RAG architectures. The metrics of RAGChecker can guide researchers and practitioners in developing more effective RAG systems.
Poster
Sangwon Jung · Sumin Yu · Sanghyuk Chun · Taesup Moon
[ West Ballroom A-D ]
Abstract
The notion of algorithmic fairness has been actively explored from various aspects of fairness, such as counterfactual fairness (CF) and group fairness (GF). However, the exact relationship between CF and GF remains to be unclear, especially in image classification tasks; the reason is because we often cannot collect counterfactual samples regarding a sensitive attribute, essential for evaluating CF, from the existing images (e.g., a photo of the same person but with different secondary sex characteristics). In this paper, we construct new image datasets for evaluating CF by using a high-quality image editing method and carefully labeling with human annotators. Our datasets, CelebA-CF and LFW-CF, build upon the popular image GF benchmarks; hence, we can evaluate CF and GF simultaneously. We empirically observe that CF does not imply GF in image classification, whereas previous studies on tabular datasets observed the opposite. We theoretically show that it could be due to the existence of a latent attribute $G$ that is correlated with, but not caused by, the sensitive attribute (e.g., secondary sex characteristics are highly correlated with hair length). From this observation, we propose a simple baseline, Counterfactual Knowledge Distillation (CKD), to mitigate such correlation with the sensitive attributes. Extensive experimental results …
Poster
Cheng-Kuang Wu · Zhi Rui Tam · Chieh-Yen Lin · Yun-Nung (Vivian) Chen · Hung-yi Lee
[ West Ballroom A-D ]
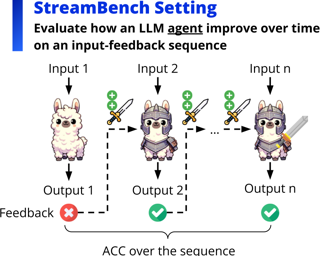
Abstract
Recent works have shown that large language model (LLM) agents are able to improve themselves from experience, which is an important ability for continuous enhancement post-deployment. However, existing benchmarks primarily evaluate their innate capabilities and do not assess their ability to improve over time. To address this gap, we introduce StreamBench, a pioneering benchmark designed to evaluate the continuous improvement of LLM agents over an input-feedback sequence. StreamBench simulates an online learning environment where LLMs receive a continuous flow of feedback stream and iteratively enhance their performance. In addition, we propose several simple yet effective baselines for improving LLMs on StreamBench, and provide a comprehensive analysis to identify critical components that contribute to successful streaming strategies. Our work serves as a stepping stone towards developing effective online learning strategies for LLMs, paving the way for more adaptive AI systems in streaming scenarios.
Spotlight Poster
Junwei Deng · Ting-Wei Li · Shiyuan Zhang · Shixuan Liu · Yijun Pan · Hao Huang · Xinhe Wang · Pingbang Hu · Xingjian Zhang · Jiaqi Ma
[ East Exhibit Hall A-C ]

Abstract
Data attribution methods aim to quantify the influence of individual training samples on the prediction of artificial intelligence (AI) models. As training data plays an increasingly crucial role in the modern development of large-scale AI models, data attribution has found broad applications in improving AI performance and safety. However, despite a surge of new data attribution methods being developed recently, there lacks a comprehensive library that facilitates the development, benchmarking, and deployment of different data attribution methods. In this work, we introduce $\texttt{dattri}$, an open-source data attribution library that addresses the above needs. Specifically, $\texttt{dattri}$ highlights three novel design features. Firstly, $\texttt{dattri}$ proposes a unified and easy-to-use API, allowing users to integrate different data attribution methods into their PyTorch-based machine learning pipeline with a few lines of code changed. Secondly, $\texttt{dattri}$ modularizes low-level utility functions that are commonly used in data attribution methods, such as Hessian-vector product, inverse-Hessian-vector product or random projection, making it easier for researchers to develop new data attribution methods. Thirdly, $\texttt{dattri}$ provides a comprehensive benchmark framework with pre-trained models and ground truth annotations for a variety of benchmark settings, including generative AI settings. We have implemented a variety of state-of-the-art efficient data attribution methods that can …
Spotlight Poster
Jiaqi Wang · Xiaochen Wang · Lingjuan Lyu · Jinghui Chen · Fenglong Ma
[ West Ballroom A-D ]
Abstract
This study introduces the Federated Medical Knowledge Injection (FedMEKI) platform, a new benchmark designed to address the unique challenges of integrating medical knowledge into foundation models under privacy constraints. By leveraging a cross-silo federated learning approach, FedMEKI circumvents the issues associated with centralized data collection, which is often prohibited under health regulations like the Health Insurance Portability and Accountability Act (HIPAA) in the USA. The platform is meticulously designed to handle multi-site, multi-modal, and multi-task medical data, which includes 7 medical modalities, including images, signals, texts, laboratory test results, vital signs, input variables, and output variables. The curated dataset to validate FedMEKI covers 8 medical tasks, including 6 classification tasks (lung opacity detection, COVID-19 detection, electrocardiogram (ECG) abnormal detection, mortality prediction, sepsis protection, and enlarged cardiomediastinum detection) and 2 generation tasks (medical visual question answering (MedVQA) and ECG noise clarification). This comprehensive dataset is partitioned across several clients to facilitate the decentralized training process under 16 benchmark approaches. FedMEKI not only preserves data privacy but also enhances the capability of medical foundation models by allowing them to learn from a broader spectrum of medical knowledge without direct data exposure, thereby setting a new benchmark in the application of foundation models …
Poster
Farzaneh Askari · Lingjuan Lyu · Vivek Sharma
[ West Ballroom A-D ]
Abstract
In this work, we tackle the question of how to systematically benchmark task-agnostic decoupling methods for privacy-preserving machine learning (ML). Sharing datasets that include sensitive information often triggers privacy concerns, necessitating robust decoupling methods to separate sensitive and non-sensitive attributes. Despite the development of numerous decoupling techniques, a standard benchmark for systematically comparing these methods remains absent. Our framework integrates various decoupling techniques along with synthetic datageneration and evaluation protocols within a unified system. Using our framework, we benchmark various decoupling techniques and evaluate their privacy-utility trade-offs. Finally, we release our source code, pre-trained models, datasets of decoupled representations to foster research in this area.
Poster
Siyan Wang · Bradford Levy
[ West Ballroom A-D ]
Abstract
Many of the recent breakthroughs in language modeling have resulted from scaling effectively the same model architecture to larger datasets. In this vein, recent work has highlighted performance gains from increasing training dataset size and quality, suggesting a need for novel sources of large-scale datasets. In this work, we introduce BeanCounter, a public dataset consisting of more than 159B tokens extracted from businesses' disclosures. We show that this data is indeed novel: less than 0.1% of BeanCounter appears in Common Crawl-based datasets and it is an order of magnitude larger than datasets relying on similar sources. Given the data's provenance, we hypothesize that BeanCounter is comparatively more factual and less toxic than web-based datasets. Exploring this hypothesis, we find that many demographic identities occur with similar prevalence in BeanCounter but with significantly less toxic context relative to other datasets. To demonstrate the utility of BeanCounter, we evaluate and compare two LLMs continually pre-trained on BeanCounter with their base models. We find an 18-33% reduction in toxic generation and improved performance within the finance domain for the continually pretrained models. Collectively, our work suggests that BeanCounter is a novel source of low-toxicity and high-quality domain-specific data with sufficient scale to train …
Spotlight Poster
Chih-Hsuan Yang · Benjamin Feuer · Talukder "Zaki" Jubery · Zi Deng · Andre Nakkab · Md Zahid Hasan · Shivani Chiranjeevi · Kelly Marshall · Nirmal Baishnab · Asheesh Singh · ARTI SINGH · Soumik Sarkar · Nirav Merchant · Chinmay Hegde · Baskar Ganapathysubramanian
[ East Exhibit Hall A-C ]
Abstract
We introduce BioTrove, the largest publicly accessible dataset designed to advance AI applications in biodiversity. Curated from the iNaturalist platform and vetted to include only research-grade data, BioTrove contains 161.9 million images, offering unprecedented scale and diversity from three primary kingdoms: Animalia ("animals"), Fungi ("fungi"), and Plantae ("plants"), spanning approximately 366.6K species. Each image is annotated with scientific names, taxonomic hierarchies, and common names, providing rich metadata to support accurate AI model development across diverse species and ecosystems.We demonstrate the value of BioTrove by releasing a suite of CLIP models trained using a subset of 40 million captioned images, known as BioTrove-Train. This subset focuses on seven categories within the dataset that are underrepresented in standard image recognition models, selected for their critical role in biodiversity and agriculture: Aves ("birds"), Arachnida} ("spiders/ticks/mites"), Insecta ("insects"), Plantae ("plants"), Fungi ("fungi"), Mollusca ("snails"), and Reptilia ("snakes/lizards"). To support rigorous assessment, we introduce several new benchmarks and report model accuracy for zero-shot learning across life stages, rare species, confounding species, and multiple taxonomic levels.We anticipate that BioTrove will spur the development of AI models capable of supporting digital tools for pest control, crop monitoring, biodiversity assessment, and environmental conservation. These advancements are crucial for …
Poster
Ruinan Jin · Zikang Xu · Yuan Zhong · Qingsong Yao · DOU QI · S. Kevin Zhou · Xiaoxiao Li
[ West Ballroom A-D ]
Abstract
The advent of foundation models (FMs) in healthcare offers unprecedented opportunities to enhance medical diagnostics through automated classification and segmentation tasks. However, these models also raise significant concerns about their fairness, especially when applied to diverse and underrepresented populations in healthcare applications. Currently, there is a lack of comprehensive benchmarks, standardized pipelines, and easily adaptable libraries to evaluate and understand the fairness performance of FMs in medical imaging, leading to considerable challenges in formulating and implementing solutions that ensure equitable outcomes across diverse patient populations. To fill this gap, we introduce FairMedFM, a fairness benchmark for FM research in medical imaging. FairMedFM integrates with 17 popular medical imaging datasets, encompassing different modalities, dimensionalities, and sensitive attributes. It explores 20 widely used FMs, with various usages such as zero-shot learning, linear probing, parameter-efficient fine-tuning, and prompting in various downstream tasks -- classification and segmentation. Our exhaustive analysis evaluates the fairness performance over different evaluation metrics from multiple perspectives, revealing the existence of bias, varied utility-fairness trade-offs on different FMs, consistent disparities on the same datasets regardless FMs, and limited effectiveness of existing unfairness mitigation methods. Furthermore, FairMedFM provides an open-sourced codebase at https://github.com/FairMedFM/FairMedFM, supporting extendible functionalities and applications and inclusive for …
Poster
Huzaifa Pardawala · Siddhant Sukhani · Agam Shah · Veer Kejriwal · Abhishek Pillai · Rohan Bhasin · Andrew DiBiasio · Tarun Mandapati · Dhruv Adha · Sudheer Chava
[ West Ballroom A-D ]

Abstract
Fact-checking is extensively studied in the context of misinformation and disinformation, addressing objective inaccuracies. However, a softer form of misinformation involves responses that are factually correct but lack certain features such as clarity and relevance. This challenge is prevalent in formal Question-Answer (QA) settings such as press conferences in finance, politics, sports, and other domains, where subjective answers can obscure transparency. Despite this, there is a lack of manually annotated datasets for subjective features across multiple dimensions. To address this gap, we introduce SubjECTive-QA, a human annotated dataset on Earnings Call Transcripts' (ECTs) QA sessions as the answers given by company representatives are often open to subjective interpretations and scrutiny. The dataset includes 49,446 annotations for long-form QA pairs across six features: Assertive, Cautious, Optimistic, Specific, Clear, and Relevant. These features are carefully selected to encompass the key attributes that reflect the tone of the answers provided during QA sessions across different domains. Our findings are that the best-performing Pre-trained Language Model (PLM), RoBERTa-base, has similar weighted F1 scores to Llama-3-70b-Chat on features with lower subjectivity, such as Relevant and Clear, with a mean difference of 2.17% in their weighted F1 scores. The models perform significantly better on features with …
Poster
Ziqiang Liu · Feiteng Fang · Xi Feng · Xeron Du · Chenhao Zhang · Noah Wang · yuelin bai · Qixuan Zhao · Liyang Fan · CHENGGUANG GAN · Hongquan Lin · Jiaming Li · Yuansheng Ni · Haihong Wu · Yaswanth Narsupalli · Zhigang Zheng · Chengming Li · Xiping Hu · Ruifeng Xu · Xiaojun Chen · Min Yang · Jiaheng Liu · Ruibo Liu · Wenhao Huang · Ge Zhang · Shiwen Ni
[ East Exhibit Hall A-C ]

Abstract
The rapid advancements in the development of multimodal large language models (MLLMs) have consistently led to new breakthroughs on various benchmarks. In response, numerous challenging and comprehensive benchmarks have been proposed to more accurately assess the capabilities of MLLMs. However, there is a dearth of exploration of the higher-order perceptual capabilities of MLLMs. To fill this gap, we propose the Image Implication understanding Benchmark, II-Bench, which aims to evaluate the model's higher-order perception of images. Through extensive experiments on II-Bench across multiple MLLMs, we have made significant findings. Initially, a substantial gap is observed between the performance of MLLMs and humans on II-Bench. The pinnacle accuracy of MLLMs attains 74.8%, whereas human accuracy averages 90%, peaking at an impressive 98%. Subsequently, MLLMs perform worse on abstract and complex images, suggesting limitations in their ability to understand high-level semantics and capture image details. Finally, it is observed that most models exhibit enhanced accuracy when image sentiment polarity hints are incorporated into the prompts. This observation underscores a notable deficiency in their inherent understanding of image sentiment. We believe that II-Bench will inspire the community to develop the next generation of MLLMs, advancing the journey towards expert artificial general intelligence (AGI). II-Bench …
Poster
Yiwei Wu · Leah Ajmani · Shayne Longpre · Hanlin Li
[ West Ballroom A-D ]
Abstract
As new machine learning methods demand larger training datasets, researchers and developers face significant challenges in dataset management. Although ethics reviews, documentation, and checklists have been established, it remains uncertain whether consistent dataset management practices exist across the community. This lack of a comprehensive overview hinders our ability to diagnose and address fundamental tensions and ethical issues related to managing large datasets. We present a systematic review of datasets published at the NeurIPS Datasets and Benchmarks track, focusing on four key aspects: provenance, distribution, ethical disclosure, and licensing. Our findings reveal that dataset provenance is often unclear due to ambiguous filtering and curation processes. Additionally, a variety of sites are used for dataset hosting, but only a few offer structured metadata and version control. These inconsistencies underscore the urgent need for standardized data infrastructures for the publication and management of datasets.
Poster
Antonios Alexos · Junze Liu · Shashank Galla · Sean Hayes · Kshitij Bhardwaj · Alexander Schwartz · Monika Biener · Pierre Baldi · Satish Bukkapatnam · Suhas Bhandarkar
[ West Ballroom A-D ]

Abstract
In the Inertial Confinement Fusion (ICF) process, roughly a 2mm spherical shell made of high-density carbon is used as a target for laser beams, which compress and heat it to energy levels needed for high fusion yield in nuclear fusion. These shells are polished meticulously to meet the standards for a fusion shot. However, the polishing of these shells involves multiple stages, with each stage taking several hours. To make sure that the polishing process is advancing in the right direction, we are able to measure the shell surface roughness. This measurement, however, is very labor-intensive, time-consuming, and requires a human operator. To help improve the polishing process we have released the first dataset to the public that consists of raw vibration signals with the corresponding polishing surface roughness changes. We show that this dataset can be used with a variety of neural network based methods for prediction of the change of polishing surface roughness, hence eliminating the need for the time-consuming manual process. This is the first dataset of its kind to be released in public and its use will allow the operator to make any necessary changes to the ICF polishing process for optimal results. This dataset contains …
Poster
Eirini Angeloudi · Jeroen Audenaert · Micah Bowles · Benjamin M. Boyd · David Chemaly · Brian Cherinka · Ioana Ciucă · Miles Cranmer · Aaron Do · Matthew Grayling · Erin E. Hayes · Tom Hehir · Shirley Ho · Marc Huertas-Company · Kartheik Iyer · Maja Jablonska · Francois Lanusse · Henry Leung · Kaisey Mandel · Rafael Martínez-Galarza · Peter Melchior · Lucas Meyer · Liam Parker · Helen Qu · Jeff Shen · Michael Smith · Connor Stone · Mike Walmsley · John Wu
[ West Ballroom A-D ]

Abstract
We present the `Multimodal Universe`, a large-scale multimodal dataset of scientific astronomical data, compiled specifically to facilitate machine learning research. Overall, our dataset contains hundreds of millions of astronomical observations, constituting 100TB of multi-channel and hyper-spectral images, spectra, multivariate time series, as well as a wide variety of associated scientific measurements and metadata. In addition, we include a range of benchmark tasks representative of standard practices for machine learning methods in astrophysics. This massive dataset will enable the development of large multi-modal models specifically targeted towards scientific applications. All codes used to compile the dataset, and a description of how to access the data is available at https://github.com/MultimodalUniverse/MultimodalUniverse
Spotlight Poster
Wolfgang Boettcher · Lukas Hoyer · Ozan Unal · Jan Eric Lenssen · Bernt Schiele
[ East Exhibit Hall A-C ]
Abstract
In this work, we introduce *Scribbles for All*, a label and training data generation algorithm for semantic segmentation trained on scribble labels. Training or fine-tuning semantic segmentation models with weak supervision has become an important topic recently and was subject to significant advances in model quality. In this setting, scribbles are a promising label type to achieve high quality segmentation results while requiring a much lower annotation effort than usual pixel-wise dense semantic segmentation annotations. The main limitation of scribbles as source for weak supervision is the lack of challenging datasets for scribble segmentation, which hinders the development of novel methods and conclusive evaluations. To overcome this limitation, *Scribbles for All* provides scribble labels for several popular segmentation datasets and provides an algorithm to automatically generate scribble labels for any dataset with dense annotations, paving the way for new insights and model advancements in the field of weakly supervised segmentation. In addition to providing datasets and algorithm, we evaluate state-of-the-art segmentation models on our datasets and show that models trained with our synthetic labels perform competitively with respect to models trained on manual labels. Thus, our datasets enable state-of-the-art research into methods for scribble-labeled semantic segmentation. The datasets, scribble generation …
Poster
Soufiane Belharbi · Mara Whitford · Phuong Hoang · Shakeeb Murtaza · Luke McCaffrey · Eric Granger
[ West Ballroom A-D ]
Abstract
Confocal fluorescence microscopy is one of the most accessible and widely used imaging techniques for the study of biological processes at the cellular and subcellular levels. Scanning confocal microscopy allows the capture of high-quality images from thick three-dimensional (3D) samples, yet suffers from well-known limitations such as photobleaching and phototoxicity of specimens caused by intense light exposure, which limits its use in some applications, especially for living cells. Cellular damage can be alleviated by changing imaging parameters to reduce light exposure, often at the expense of image quality.Machine/deep learning methods for single-image super-resolution (SISR) can be applied to restore image quality by upscaling lower-resolution (LR) images to produce high-resolution images (HR). These SISR methods have been successfully applied to photo-realistic images due partly to the abundance of publicly available datasets. In contrast, the lack of publicly available data partly limits their application and success in scanning confocal microscopy.In this paper, we introduce a large scanning confocal microscopy dataset named SR-CACO-2 that is comprised of low- and high-resolution image pairs marked for three different fluorescent markers. It allows to evaluate the performance of SISR methods on three different upscaling levels (X2, X4, X8). SR-CACO-2 contains the human epithelial cell line Caco-2 …
Poster
Julieta Martinez · Emily Kim · Javier Romero · Timur Bagautdinov · Shunsuke Saito · Shoou-I Yu · Stuart Anderson · Michael Zollhöfer · Te-Li Wang · Shaojie Bai · Chenghui Li · Shih-En Wei · Rohan Joshi · Wyatt Borsos · Tomas Simon · Jason Saragih · Paul Theodosis · Alexander Greene · Anjani Josyula · Silvio Maeta · Andrew Jewett · Simion Venshtain · Christopher Heilman · Yueh-Tung Chen · Sidi Fu · Mohamed Elshaer · Tingfang Du · Longhua Wu · Shen-Chi Chen · Kai Kang · Michael Wu · Youssef Emad · Steven Longay · Ashley Brewer · Hitesh Shah · James Booth · Taylor Koska · Kayla Haidle · Matthew Andromalos · Joanna Hsu · Thomas Dauer · Peter Selednik · Tim Godisart · Scott Ardisson · Matthew Cipperly · Ben Humberston · Lon Farr · Bob Hansen · Peihong Guo · Dave Braun · Steven Krenn · He Wen · Lucas Evans · Natalia Fadeeva · Matthew Stewart · Gabriel Schwartz · Divam Gupta · Gyeongsik Moon · Kaiwen Guo · Yuan Dong · Yichen Xu · Takaaki Shiratori · Fabian Prada · Bernardo Pires · Bo Peng · Julia Buffalini · Autumn Trimble · Kevyn McPhail · Melissa Schoeller · Yaser Sheikh
[ East Exhibit Hall A-C ]
Abstract
To build photorealistic avatars that users can embody, human modelling must be complete (cover the full body), driveable (able to reproduce the current motion and appearance from the user), and generalizable (_i.e._, easily adaptable to novel identities).Towards these goals, _paired_ captures, that is, captures of the same subject obtained from systems of diverse quality and availability, are crucial.However, paired captures are rarely available to researchers outside of dedicated industrial labs: _Codec Avatar Studio_ is our proposal to close this gap.Towards generalization and driveability, we introduce a dataset of 256 subjects captured in two modalities: high resolution multi-view scans of their heads, and video from the internal cameras of a headset.Towards completeness, we introduce a dataset of 4 subjects captured in eight modalities: high quality relightable multi-view captures of heads and hands, full body multi-view captures with minimal and regular clothes, and corresponding head, hands and body phone captures.Together with our data, we also provide code and pre-trained models for different state-of-the-art human generation models.Our datasets and code are available at https://github.com/facebookresearch/ava-256 and https://github.com/facebookresearch/goliath.
Poster
Juan Formanek · Callum R. Tilbury · Louise Beyers · Jonathan Shock · Arnu Pretorius
[ West Ballroom A-D ]
Abstract
Offline multi-agent reinforcement learning (MARL) is an emerging field with great promise for real-world applications. Unfortunately, the current state of research in offline MARL is plagued by inconsistencies in baselines and evaluation protocols, which ultimately makes it difficult to accurately assess progress, trust newly proposed innovations, and allow researchers to easily build upon prior work. In this paper, we firstly identify significant shortcomings in existing methodologies for measuring the performance of novel algorithms through a representative study of published offline MARL work. Secondly, by directly comparing to this prior work, we demonstrate that simple, well-implemented baselines can achieve state-of-the-art (SOTA) results across a wide range of tasks. Specifically, we show that on 35 out of 47 datasets used in prior work (almost 75\% of cases), we match or surpass the performance of the current purported SOTA. Strikingly, our baselines often substantially outperform these more sophisticated algorithms. Finally, we correct for the shortcomings highlighted from this prior work by introducing a straightforward standardised methodology for evaluation and by providing our baseline implementations with statistically robust results across several scenarios, useful for comparisons in future work. Our proposal includes simple and sensible steps that are easy to adopt, which in combination with …
Poster
Anushrut Nirmal Jignasu · Kelly Marshall · Ankush Kumar Mishra · Lucas Nerone Rillo · Baskar Ganapathysubramanian · Aditya Balu · Chinmay Hegde · Adarsh Krishnamurthy
[ West Ballroom A-D ]

Abstract
G-code (Geometric code) or RS-274 is the most widely used computer numerical control (CNC) and 3D printing programming language. G-code provides machine instructions for the movement of the 3D printer, especially for the nozzle, stage, and extrusion of material for extrusion-based additive manufacturing. Currently, there does not exist a large repository of curated CAD models along with their corresponding G-code files for additive manufacturing. To address this issue, we present Slice-100K, a first-of-its-kind dataset of over 100,000 G-code files, along with their tessellated CAD model, LVIS (Large Vocabulary Instance Segmentation) categories, geometric properties, and renderings. We build our dataset from triangulated meshes derived from Objaverse-XL and Thingi10K datasets. We demonstrate the utility of this dataset by finetuning GPT-2 on a subset of the dataset for G-code translation from a legacy G-code format (Sailfish) to a more modern, widely used format (Marlin). Our dataset can be found here. Slice-100K will be the first step in developing a multimodal foundation model for digital manufacturing.
Poster
Chenqing Hua · Bozitao Zhong · Sitao Luan · Liang Hong · Guy Wolf · Doina Precup · Shuangjia Zheng
[ East Exhibit Hall A-C ]
Abstract
Enzymes, with their specific catalyzed reactions, are necessary for all aspects of life, enabling diverse biological processes and adaptations. Predicting enzyme functions is essential for understanding biological pathways, guiding drug development, enhancing bioproduct yields, and facilitating evolutionary studies.Addressing the inherent complexities, we introduce a new approach to annotating enzymes based on their catalyzed reactions. This method provides detailed insights into specific reactions and is adaptable to newly discovered reactions, diverging from traditional classifications by protein family or expert-derived reaction classes. We employ machine learning algorithms to analyze enzyme reaction datasets, delivering a much more refined view on the functionality of enzymes.Our evaluation leverages the largest enzyme-reaction dataset to date, derived from the SwissProt and Rhea databases with entries up to January 8, 2024. We frame the enzyme-reaction prediction as a retrieval problem, aiming to rank enzymes by their catalytic ability for specific reactions. With our model, we can recruit proteins for novel reactions and predict reactions in novel proteins, facilitating enzyme discovery and function annotation https://github.com/WillHua127/ReactZyme.
Poster
Léo Boisvert · Megh Thakkar · Maxime Gasse · Massimo Caccia · Thibault de Chezelles · Quentin Cappart · Nicolas Chapados · Alexandre Lacoste · Alexandre Drouin
[ West Ballroom A-D ]

Abstract
The ability of large language models (LLMs) to mimic human-like intelligence has led to a surge in LLM-based autonomous agents. Though recent LLMs seem capable of planning and reasoning given user instructions, their effectiveness in applying these capabilities for autonomous task solving remains underexplored. This is especially true in enterprise settings, where automated agents hold the promise of a high impact. To fill this gap, we propose WorkArena++, a novel benchmark consisting of 682 tasks corresponding to realistic workflows routinely performed by knowledge workers. WorkArena++ is designed to evaluate the planning, problem-solving, logical/arithmetic reasoning, retrieval, and contextual understanding abilities of web agents. Our empirical studies across state-of-the-art LLMs and vision-language models (VLMs), as well as human workers, reveal several challenges for such models to serve as useful assistants in the workplace. In addition to the benchmark, we provide a mechanism to effortlessly generate thousands of ground-truth observation/action traces, which can be used for fine-tuning existing models. Overall, we expect this work to serve as a useful resource to help the community progress towards capable autonomous agents. The benchmark can be found at https://github.com/ServiceNow/WorkArena.
Spotlight Poster
Yubo Ma · Yuhang Zang · Liangyu Chen · Meiqi Chen · Yizhu Jiao · Xinze Li · Xinyuan Lu · Ziyu Liu · Yan Ma · Xiaoyi Dong · Pan Zhang · Liangming Pan · Yu-Gang Jiang · Jiaqi Wang · Yixin Cao · Aixin Sun
[ West Ballroom A-D ]
Abstract
Understanding documents with rich layouts and multi-modal components is a long-standing and practical task. Recent Large Vision-Language Models (LVLMs) have made remarkable strides in various tasks, particularly in single-page document understanding (DU). However, their abilities on long-context DU remain an open problem. This work presents MMLONGBENCH-DOC, a long-context, multi- modal benchmark comprising 1,082 expert-annotated questions. Distinct from previous datasets, it is constructed upon 135 lengthy PDF-formatted documents with an average of 47.5 pages and 21,214 textual tokens. Towards comprehensive evaluation, answers to these questions rely on pieces of evidence from (1) different sources (text, image, chart, table, and layout structure) and (2) various locations (i.e., page number). Moreover, 33.7\% of the questions are cross-page questions requiring evidence across multiple pages. 20.6\% of the questions are designed to be unanswerable for detecting potential hallucinations. Experiments on 14 LVLMs demonstrate that long-context DU greatly challenges current models. Notably, the best-performing model, GPT-4o, achieves an F1 score of only 44.9\%, while the second-best, GPT-4V, scores 30.5\%. Furthermore, 12 LVLMs (all except GPT-4o and GPT-4V) even present worse performance than their LLM counterparts which are fed with lossy-parsed OCR documents. These results validate the necessity of future research toward more capable long-context LVLMs.
Poster
Alexander Rutherford · Benjamin Ellis · Matteo Gallici · Jonathan Cook · Andrei Lupu · Garðar Ingvarsson Juto · Timon Willi · Ravi Hammond · Akbir Khan · Christian Schroeder de Witt · Alexandra Souly · Saptarashmi Bandyopadhyay · Mikayel Samvelyan · Minqi Jiang · Robert Lange · Shimon Whiteson · Bruno Lacerda · Nick Hawes · Tim Rocktäschel · Chris Lu · Jakob Foerster
[ West Ballroom A-D ]
Abstract
Benchmarks are crucial in the development of machine learning algorithms, significantly influencing reinforcement learning (RL) research through the available environments. Traditionally, RL environments run on the CPU, which limits their scalability with the computational resources typically available in academia. However, recent advancements in JAX have enabled the wider use of hardware acceleration, enabling massively parallel RL training pipelines and environments. While this has been successfully applied to single-agent RL, it has not yet been widely adopted for multi-agent scenarios. In this paper, we present JaxMARL, the first open-source, easy-to-use code base that combines GPU-enabled efficiency with support for a large number of commonly used MARL environments and popular baseline algorithms. Our experiments show that, in terms of wall clock time, our JAX-based training pipeline is up to 12,500 times faster than existing approaches. This enables efficient and thorough evaluations, potentially alleviating the evaluation crisis in the field. We also introduce and benchmark SMAX, a vectorised, simplified version of the popular StarCraft Multi-Agent Challenge, which removes the need to run the StarCraft II game engine. This not only enables GPU acceleration, but also provides a more flexible MARL environment, unlocking the potential for self-play, meta-learning, and other future applications in MARL. …
Poster
Jiamian Hu · Hong Yuanyuan · Yihua Chen · He Wang · Moriaki Yasuhara
[ West Ballroom A-D ]
Abstract
We present the Noisy Ostracods, a noisy dataset for genus and species classificationof crustacean ostracods with specialists’ annotations. Over the 71466 specimenscollected, 5.58% of them are estimated to be noisy (possibly problematic) at genuslevel. The dataset is created to addressing a real-world challenge: creating aclean fine-grained taxonomy dataset. The Noisy Ostracods dataset has diversenoises from multiple sources. Firstly, the noise is open-set, including new classesdiscovered during curation that were not part of the original annotation. Thedataset has pseudo-classes, where annotators misclassified samples that shouldbelong to an existing class into a new pseudo-class. The Noisy Ostracods datasetis highly imbalanced with a imbalance factor ρ = 22429. This presents a uniquechallenge for robust machine learning methods, as existing approaches have notbeen extensively evaluated on fine-grained classification tasks with such diversereal-world noise. Initial experiments using current robust learning techniqueshave not yielded significant performance improvements on the Noisy Ostracodsdataset compared to cross-entropy training on the raw, noisy data. On the otherhand, noise detection methods have underperformed in error hit rate comparedto naive cross-validation ensembling for identifying problematic labels. Thesefindings suggest that the fine-grained, imbalanced nature, and complex noisecharacteristics of the dataset present considerable challenges for existing noiserobustalgorithms. By openly releasing the Noisy Ostracods dataset, …
Poster
Vishaal Udandarao · Karsten Roth · Sebastian Dziadzio · Ameya Prabhu · Mehdi Cherti · Oriol Vinyals · Olivier Henaff · Samuel Albanie · Zeynep Akata · Matthias Bethge
[ East Exhibit Hall A-C ]
Abstract
Multimodal foundation models serve numerous applications at the intersection of vision and language. Still, despite being pretrained on extensive data, they become outdated over time.To keep models updated, research into continual pretraining mainly explores scenarios with either (1) infrequent, indiscriminate updates on large-scale new data, or (2) frequent, sample-level updates.However, practical model deployment often operates in the gap between these two limit cases, as real-world applications demand adaptation to specific subdomains, tasks or concepts --- spread over the entire, varying life cycle of a model. In this work, we complement current perspectives on continual pretraining through a research test bed and offer comprehensive guidance for effective continual model updates in such scenarios.We first introduce FoMo-in-Flux, a continual multimodal pretraining benchmark with realistic compute constraints and practical deployment requirements, constructed over 63 datasets with diverse visual and semantic coverage.Using FoMo-in-Flux, we explore the complex landscape of practical continual pretraining through multiple perspectives: (1) data mixtures and stream orderings that emulate real-world deployment settings, (2) methods ranging from simple fine-tuning and traditional continual learning strategies to parameter-efficient updates and model merging, (3) meta-learning-rate schedules and mechanistic design choices, and (4) model and compute scaling. Together, our insights provide a practitioner's guide to …
Spotlight Poster
Yeonsu Kwon · Jiho Kim · Gyubok Lee · Seongsu Bae · Daeun Kyung · Wonchul Cha · Tom Pollard · Alistair Johnson · Edward Choi
[ East Exhibit Hall A-C ]
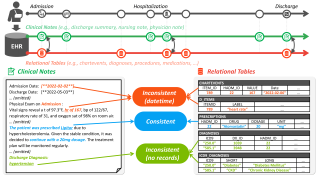
Abstract
Electronic Health Records (EHRs) are integral for storing comprehensive patient medical records, combining structured data (e.g., medications) with detailed clinical notes (e.g., physician notes). These elements are essential for straightforward data retrieval and provide deep, contextual insights into patient care. However, they often suffer from discrepancies due to unintuitive EHR system designs and human errors, posing serious risks to patient safety. To address this, we developed EHRCon, a new dataset and task specifically designed to ensure data consistency between structured tables and unstructured notes in EHRs.EHRCon was crafted in collaboration with healthcare professionals using the MIMIC-III EHR dataset, and includes manual annotations of 3,943 entities across 105 clinical notes checked against database entries for consistency.EHRCon has two versions, one using the original MIMIC-III schema, and another using the OMOP CDM schema, in order to increase its applicability and generalizability. Furthermore, leveraging the capabilities of large language models, we introduce CheckEHR, a novel framework for verifying the consistency between clinical notes and database tables. CheckEHR utilizes an eight-stage process and shows promising results in both few-shot and zero-shot settings. The code is available at \url{https://github.com/dustn1259/EHRCon}.
Poster
Junho Myung · Nayeon Lee · Yi Zhou · Jiho Jin · Rifki Putri · Dimosthenis Antypas · Hsuvas Borkakoty · Eunsu Kim · Carla Perez-Almendros · Abinew Ali Ayele · Victor Gutierrez Basulto · Yazmin Ibanez-Garcia · Hwaran Lee · Shamsuddeen H Muhammad · Kiwoong Park · Anar Rzayev · Nina White · Seid Muhie Yimam · Mohammad Taher Pilehvar · Nedjma Ousidhoum · Jose Camacho-Collados · Alice Oh
[ West Ballroom A-D ]
Abstract
Large language models (LLMs) often lack culture-specific everyday knowledge, especially across diverse regions and non-English languages. Existing benchmarks for evaluating LLMs' cultural sensitivities are usually limited to a single language or online sources like Wikipedia, which may not reflect the daily habits, customs, and lifestyles of different regions. That is, information about the food people eat for their birthday celebrations, spices they typically use, musical instruments youngsters play or the sports they practice in school is not always explicitly written online. To address this issue, we introduce BLEnD, a hand-crafted benchmark designed to evaluate LLMs' everyday knowledge across diverse cultures and languages. The benchmark comprises 52.6k question-answer pairs from 16 countries/regions, in 13 different languages, including low-resource ones such as Amharic, Assamese, Azerbaijani, Hausa, and Sundanese. We evaluate LLMs in two formats: short-answer questions, and multiple-choice questions. We show that LLMs perform better in cultures that are more present online, with a maximum 57.34% difference in GPT-4, the best-performing model, in the short-answer format.Furthermore, we find that LLMs perform better in their local languages for mid-to-high-resource languages. Interestingly, for languages deemed to be low-resource, LLMs provide better answers in English. We make our dataset publicly available at: https://github.com/nlee0212/BLEnD.
Spotlight Poster
Yubo Wang · Xueguang Ma · Ge Zhang · Yuansheng Ni · Abhranil Chandra · Shiguang Guo · Weiming Ren · Aaran Arulraj · Xuan He · Ziyan Jiang · Tianle Li · Max KU · Kai Wang · Alex Zhuang · Rongqi Fan · Xiang Yue · Wenhu Chen
[ West Ballroom A-D ]

Abstract
In the age of large-scale language models, benchmarks like the Massive Multitask Language Understanding (MMLU) have been pivotal in pushing the boundaries of what AI can achieve in language comprehension and reasoning across diverse domains. However, as models continue to improve, their performance on these benchmarks has begun to plateau, making it increasingly difficult to discern differences in model capabilities. This paper introduces MMLU-Pro, an enhanced dataset designed to extend the mostly knowledge-driven MMLU benchmark by integrating more challenging, reasoning-focused questions and expanding the choice set from four to ten options. Additionally, MMLU-Pro eliminates part of the trivial and noisy questions in MMLU. Our experimental results show that MMLU-Pro not only raises the challenge, causing a significant drop in accuracy by 16\% to 33\% compared to MMLU, but also demonstrates greater stability under varying prompts. With 24 different prompt styles tested, the sensitivity of model scores to prompt variations decreased from 4-5\% in MMLU to just 2\% in MMLU-Pro. Additionally, we found that models utilizing Chain of Thought (CoT) reasoning achieved better performance on MMLU-Pro compared to direct answering, which is in stark contrast to the findings on the original MMLU, indicating that MMLU-Pro includes more complex reasoning questions. Our …
Poster
Zhen Huang · Zengzhi Wang · Shijie Xia · Xuefeng Li · Haoyang Zou · Ruijie Xu · Run-Ze Fan · Lyumanshan Ye · Ethan Chern · Yixin Ye · Yikai Zhang · Yuqing Yang · Ting Wu · Binjie Wang · Shichao Sun · Yang Xiao · Yiyuan Li · Fan Zhou · Steffi Chern · Yiwei Qin · Yan Ma · Jiadi Su · Yixiu Liu · Yuxiang Zheng · Shaoting Zhang · Dahua Lin · Yu Qiao · Pengfei Liu
[ East Exhibit Hall A-C ]

Abstract
The evolution of Artificial Intelligence (AI) has been significantly accelerated by advancements in Large Language Models (LLMs) and Large Multimodal Models (LMMs), gradually showcasing potential cognitive reasoning abilities in problem-solving and scientific discovery (i.e., AI4Science) once exclusive to human intellect. To comprehensively evaluate current models' performance in cognitive reasoning abilities, we introduce OlympicArena, which includes 11,163 bilingual problems across both text-only and interleaved text-image modalities. These challenges encompass a wide range of disciplines spanning seven fields and 62 international Olympic competitions, rigorously examined for data leakage. We argue that the challenges in Olympic competition problems are ideal for evaluating AI's cognitive reasoning due to their complexity and interdisciplinary nature, which are essential for tackling complex scientific challenges and facilitating discoveries. Beyond evaluating performance across various disciplines using answer-only criteria, we conduct detailed experiments and analyses from multiple perspectives. We delve into the models' cognitive reasoning abilities, their performance across different modalities, and their outcomes in process-level evaluations, which are vital for tasks requiring complex reasoning with lengthy solutions. Our extensive evaluations reveal that even advanced models like GPT-4o only achieve a 39.97\% overall accuracy (28.67\% for mathematics and 29.71\% for physics), illustrating current AI limitations in complex reasoning and multimodal …
Poster
Jingbo Zhou · Shaorong Chen · Jun Xia · Sizhe Liu · Tianze Ling · Wenjie Du · Yue Liu · Jianwei Yin · Stan Z. Li
[ West Ballroom A-D ]

Abstract
Tandem mass spectrometry has played a pivotal role in advancing proteomics, enabling the analysis of protein composition in biological tissues. Many deep learning methods have been developed for \emph{de novo} peptide sequencing task, i.e., predicting the peptide sequence for the observed mass spectrum. However, two key challenges seriously hinder the further research of this important task. Firstly, since there is no consensus for the evaluation datasets, the empirical results in different research papers are often not comparable, leading to unfair comparison. Secondly, the current methods are usually limited to amino acid-level or peptide-level precision and recall metrics. In this work, we present the first unified benchmark NovoBench for \emph{de novo} peptide sequencing, which comprises diverse mass spectrum data, integrated models, and comprehensive evaluation metrics. Recent impressive methods, including DeepNovo, PointNovo, Casanovo, InstaNovo, AdaNovo and $\pi$-HelixNovo are integrated into our framework. In addition to amino acid-level and peptide-level precision and recall, we also evaluate the models' performance in terms of identifying post-tranlational modifications (PTMs), efficiency and robustness to peptide length, noise peaks and missing fragment ratio, which are important influencing factors while seldom be considered. Leveraging this benchmark, we conduct a large-scale study of current methods, report many insightful findings that …
Poster
Shan Chen · Jack Gallifant · Mingye Gao · Pedro Moreira · Nikolaj Munch · Ajay Muthukkumar · Arvind Rajan · Jaya Kolluri · Amelia Fiske · Janna Hastings · Hugo Aerts · Brian Anthony · Leo Anthony Celi · William La Cava · Danielle Bitterman
[ West Ballroom A-D ]
Abstract
Large language models (LLMs) are increasingly essential in processing natural languages, yet their application is frequently compromised by biases and inaccuracies originating in their training data.In this study, we introduce \textbf{Cross-Care}, the first benchmark framework dedicated to assessing biases and real world knowledge in LLMs, specifically focusing on the representation of disease prevalence across diverse demographic groups.We systematically evaluate how demographic biases embedded in pre-training corpora like $ThePile$ influence the outputs of LLMs.We expose and quantify discrepancies by juxtaposing these biases against actual disease prevalences in various U.S. demographic groups.Our results highlight substantial misalignment between LLM representation of disease prevalence and real disease prevalence rates across demographic subgroups, indicating a pronounced risk of bias propagation and a lack of real-world grounding for medical applications of LLMs.Furthermore, we observe that various alignment methods minimally resolve inconsistencies in the models' representation of disease prevalence across different languages.For further exploration and analysis, we make all data and a data visualization tool available at: \url{www.crosscare.net}.
Poster
Chenyi Zi · Haihong Zhao · Xiangguo Sun · Yiqing Lin · Hong Cheng · Jia Li
[ East Exhibit Hall A-C ]
Abstract
Artificial general intelligence on graphs has shown significant advancements across various applications, yet the traditional `Pre-train \& Fine-tune' paradigm faces inefficiencies and negative transfer issues, particularly in complex and few-shot settings. Graph prompt learning emerges as a promising alternative, leveraging lightweight prompts to manipulate data and fill the task gap by reformulating downstream tasks to the pretext. However, several critical challenges still remain: how to unify diverse graph prompt models, how to evaluate the quality of graph prompts, and to improve their usability for practical comparisons and selection. In response to these challenges, we introduce the first comprehensive benchmark for graph prompt learning. Our benchmark integrates **SIX** pre-training methods and **FIVE** state-of-the-art graph prompt techniques, evaluated across **FIFTEEN** diverse datasets to assess performance, flexibility, and efficiency. We also present 'ProG', an easy-to-use open-source library that streamlines the execution of various graph prompt models, facilitating objective evaluations. Additionally, we propose a unified framework that categorizes existing graph prompt methods into two main approaches: prompts as graphs and prompts as tokens. This framework enhances the applicability and comparison of graph prompt techniques. The code is available at: https://github.com/sheldonresearch/ProG.
Poster
ChuNan Liu · Lilian Denzler · Yihong Chen · Andrew Martin · Brooks Paige
[ East Exhibit Hall A-C ]

Abstract
Epitope identification is vital for antibody design yet challenging due to the inherent variability in antibodies. While many deep learning methods have been developed for general protein binding site prediction tasks, whether they work for epitope prediction remains an understudied research question. The challenge is also heightened by the lack of a consistent evaluation pipeline with sufficient dataset size and epitope diversity. We introduce a filtered antibody-antigen complex structure dataset, AsEP (Antibody-specific Epitope Prediction). AsEP is the largest of its kind and provides clustered epitope groups, allowing the community to develop and test novel epitope prediction methods and evaluate their generalisability. AsEP comes with an easy-to-use interface in Python and pre-built graph representations of each antibody-antigen complex while also supporting customizable embedding methods. Using this new dataset, we benchmark several representative general protein-binding site prediction methods and find that their performances fall short of expectations for epitope prediction. To address this, we propose a novel method, WALLE, which leverages both unstructured modeling from protein language models and structural modeling from graph neural networks. WALLE demonstrate up to 3-10X performance improvement over the baseline methods. Our empirical findings suggest that epitope prediction benefits from combining sequential features provided by language models …
Poster
Boyi Wei · Weijia Shi · Yangsibo Huang · Noah Smith · Chiyuan Zhang · Luke Zettlemoyer · Kai Li · Peter Henderson
[ East Exhibit Hall A-C ]
Abstract
Language models (LMs) derive their capabilities from extensive training on diverse data, including copyrighted material. These models can memorize and generate content similar to their training data, potentially risking legal issues like copyright infringement.Therefore, model creators are motivated to develop mitigation methods that prevent generating particular copyrighted content, an ability we refer to as *copyright takedowns*. This paper introduces the first evaluation of the feasibility and side effects of copyright takedowns for LMs. We propose CoTaEval, an evaluation framework to assess the effectiveness of copyright takedown methods,the impact on the model's ability to retain uncopyrightable factual knowledge from the copyrighted content, and how well the model maintains its general utility and efficiency.We examine several strategies, including adding system prompts, decoding-time filtering interventions, and unlearning approaches. Our findings indicate that no method excels across all metrics, showing significant room for research in this unique problem setting and indicating potential unresolved challenges for live policy proposals.
Oral Poster
Manling Li · Shiyu Zhao · Qineng Wang · Kangrui Wang · Yu Zhou · Sanjana Srivastava · Cem Gokmen · Tony Lee · Erran Li Li · Ruohan Zhang · Weiyu Liu · Percy Liang · Fei-Fei Li · Jiayuan Mao · Jiajun Wu
[ West Ballroom A-D ]
Abstract
We aim to evaluate Large Language Models (LLMs) for embodied decision making. While a significant body of work has been leveraging LLMs for decision making in embodied environments, we still lack a systematic understanding of their performance because they are usually applied in different domains, for different purposes, and built based on different inputs and outputs. Furthermore, existing evaluations tend to rely solely on a final success rate, making it difficult to pinpoint what ability is missing in LLMs and where the problem lies, which in turn blocks embodied agents from leveraging LLMs effectively and selectively. To address these limitations, we propose a generalized interface (Embodied Agent Interface) that supports the formalization of various types of tasks and input-output specifications of LLM-based modules. Specifically, it allows us to unify 1) a broad set of embodied decision-making tasks involving both state and temporally extended goals, 2) four commonly-used LLM-based modules for decision making: goal interpretation, subgoal decomposition, action sequencing, and transition modeling, and 3) a collection of fine-grained metrics that break down evaluation into error types, such as hallucination errors, affordance errors, and various types of planning errors. Overall, our benchmark offers a comprehensive assessment of LLMs’ performance for different subtasks, …
Spotlight Poster
Zeyao Ma · Bohan Zhang · Jing Zhang · Jifan Yu · Xiaokang Zhang · Xiaohan Zhang · Sijia Luo · Xi Wang · Jie Tang
[ West Ballroom A-D ]
Abstract
We introduce SpreadsheetBench, a challenging spreadsheet manipulation benchmark exclusively derived from real-world scenarios, designed to immerse current large language models (LLMs) in the actual workflow of spreadsheet users. Unlike existing benchmarks that rely on synthesized queries and simplified spreadsheet files, SpreadsheetBench is built from 912 real questions gathered from online Excel forums, which reflect the intricate needs of users. The associated spreadsheets from the forums contain a variety of tabular data such as multiple tables, non-standard relational tables, and abundant non-textual elements. Furthermore, we propose a more reliable evaluation metric akin to online judge platforms, where multiple spreadsheet files are created as test cases for each instruction, ensuring the evaluation of robust solutions capable of handling spreadsheets with varying values.Our comprehensive evaluation of various LLMs under both single-round and multi-round inference settings reveals a substantial gap between the state-of-the-art (SOTA) models and human performance, highlighting the benchmark's difficulty.
Poster
Sizhe Liu · Jun Xia · Lecheng Zhang · Yuchen Liu · Yue Liu · Wenjie Du · Zhangyang Gao · Bozhen Hu · Cheng Tan · hongxin xiang · Stan Z. Li
[ East Exhibit Hall A-C ]
Abstract
Molecular relational learning (MRL) is crucial for understanding the interaction behaviors between molecular pairs, a critical aspect of drug discovery and development. However, the large feasible model space of MRL poses significant challenges to benchmarking, and existing MRL frameworks face limitations in flexibility and scope. To address these challenges, avoid repetitive coding efforts, and ensure fair comparison of models, we introduce FlexMol, a comprehensive toolkit designed to facilitate the construction and evaluation of diverse model architectures across various datasets and performance metrics. FlexMol offers a robust suite of preset model components, including 16 drug encoders, 13 protein sequence encoders, 9 protein structure encoders, and 7 interaction layers. With its easy-to-use API and flexibility, FlexMol supports the dynamic construction of over 70, 000 distinct combinations of model architectures. Additionally, we provide detailed benchmark results and code examples to demonstrate FlexMol’s effectiveness in simplifying and standardizing MRL model development and comparison. FlexMol is open-sourced and available at https://github.com/Steven51516/FlexMol.
Poster
Mohammadreza (Reza) Salehi · Jae Sung Park · Aditya Kusupati · Ranjay Krishna · Yejin Choi · Hanna Hajishirzi · Ali Farhadi
[ West Ballroom A-D ]
Abstract
Our world is full of varied actions and moves in specialized fields that we, as humans, seek to identify and learn about. To evaluate the effectiveness of multi-modal models in helping us recognize such fine-grained actions, we introduce ActionAtlas, a video question answering (VideoQA) benchmark on fine-grained action recognition with short videos across various sports. ActionAtlas contains 554 videos spanning 284 actions across 42 sports with 1161 actions as total potential choices. Unlike most existing action recognition benchmarks that focus on simplistic actions, often identifiable from a single frame, ActionAtlas focuses on intricate movements and tests the models' ability to discern subtle differences. Additionally, each video in ActionAtlas also includes a question, which helps to more accurately pinpoint the action's performer in scenarios where multiple individuals are involved in different activities. We evaluate proprietary and open models on this benchmark and show that the state-of-the-art models only perform at most 48.73% accurately where random chance is 20%. Furthermore, our results show that a high frame sampling rate is essential for recognizing actions in ActionAtlas, a feature that current top proprietary models like Gemini lack in their default settings.
Poster
Homaira Huda Shomee · Zhu Wang · Sathya Ravi · Sourav Medya
[ East Exhibit Hall A-C ]
Abstract
In this paper, we introduce IMPACT (Integrated Multimodal Patent Analysis and Creation Dataset for Design Patents), a large-scale multimodal patent dataset with detailed captions for design patent figures. Our dataset includes half a million design patents comprising 3.61 million figures along with captions from patents granted by the United States Patent and Trademark Office (USPTO) over a 16-year period from 2007 to 2022. We incorporate the metadata of each patent application with elaborate captions that are coherent with multiple viewpoints of designs. Even though patents themselves contain a variety of design figures, titles, and descriptions of viewpoints, we find that they lack detailed descriptions that are necessary to perform multimodal tasks such as classification and retrieval. IMPACT closes this gap thereby providing researchers with necessary ingredients to instantiate a variety of multimodal tasks. Our dataset has a huge potential for novel design inspiration and can be used with advanced computer vision models in tandem. We perform preliminary evaluations on the dataset on the popular patent analysis tasks such as classification and retrieval. Our results indicate that integrating images with generated captions significantly improves the performance of different models on the corresponding tasks. Given that design patents offer various benefits for …
Poster
Joao Monteiro · Pierre-André Noël · Étienne Marcotte · Sai Rajeswar Mudumba · Valentina Zantedeschi · David Vazquez · Nicolas Chapados · Chris Pal · Perouz Taslakian
[ West Ballroom A-D ]
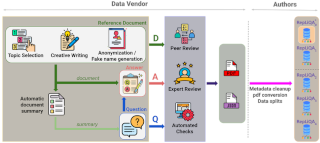
Abstract
Large Language Models (LLMs) are trained on vast amounts of data, most of which is automatically scraped from the internet. This data includes encyclopedic documents that harbor a vast amount of general knowledge (*e.g.*, Wikipedia) but also potentially overlap with benchmark datasets used for evaluating LLMs. Consequently, evaluating models on test splits that might have leaked into the training set is prone to misleading conclusions. To foster sound evaluation of language models, we introduce a new test dataset named RepLiQA, suited for question-answering and topic retrieval tasks. RepLiQA is a collection of five splits of test sets, four of which have not been released to the internet or exposed to LLM APIs prior to this publication. Each sample in RepLiQA comprises (1) a reference document crafted by a human annotator and depicting an imaginary scenario (*e.g.*, a news article) absent from the internet; (2) a question about the document’s topic; (3) a ground-truth answer derived directly from the information in the document; and (4) the paragraph extracted from the reference document containing the answer. As such, accurate answers can only be generated if a model can find relevant content within the provided document. We run a large-scale benchmark comprising several …
Poster
Zhuofeng Li · Zixing Gou · Xiangnan Zhang · Zhongyuan Liu · Sirui Li · Yuntong Hu · Chen LING · Zheng Zhang · Liang Zhao
[ East Exhibit Hall A-C ]

Abstract
Text-Attributed Graphs (TAGs) augment graph structures with natural language descriptions, facilitating detailed depictions of data and their interconnections across various real-world settings. However, existing TAG datasets predominantly feature textual information only at the nodes, with edges typically represented by mere binary or categorical attributes. This lack of rich textual edge annotations significantly limits the exploration of contextual relationships between entities, hindering deeper insights into graph-structured data. To address this gap, we introduce Textual-Edge Graphs Datasets and Benchmark (TEG-DB), a comprehensive and diverse collection of benchmark textual-edge datasets featuring rich textual descriptions on nodes and edges. The TEG-DB datasets are large-scale and encompass a wide range of domains, from citation networks to social networks. In addition, we conduct extensive benchmark experiments on TEG-DB to assess the extent to which current techniques, including pre-trained language models, graph neural networks, and their combinations, can utilize textual node and edge information. Our goal is to elicit advancements in textual-edge graph research, specifically in developing methodologies that exploit rich textual node and edge descriptions to enhance graph analysis and provide deeper insights into complex real-world networks. The entire TEG-DB project is publicly accessible as an open-source repository on Github, accessible at https://github.com/Zhuofeng-Li/TEG-Benchmark.
Poster
Minjie Wang · Quan Gan · David Wipf · Zheng Zhang · Christos Faloutsos · Weinan Zhang · Muhan Zhang · Zhenkun Cai · Jiahang Li · Zunyao Mao · Yakun Song · Jianheng Tang · Yanlin Zhang · Guang Yang · Chuan Lei · Xiao Qin · Ning Li · Han Zhang · Yanbo Wang · Zizhao Zhang
[ East Exhibit Hall A-C ]
Abstract
Given a relational database (RDB), how can we predict missing column values in some target table of interest? Although RDBs store vast amounts of rich, informative data spread across interconnected tables, the progress of predictive machine learning models as applied to such tasks arguably falls well behind advances in other domains such as computer vision or natural language processing. This deficit stems, at least in part, from the lack of established/public RDB benchmarks as needed for training and evaluation purposes. As a result, related model development thus far often defaults to tabular approaches trained on ubiquitous single-table benchmarks, or on the relational side, graph-based alternatives such as GNNs applied to a completely different set of graph datasets devoid of tabular characteristics. To more precisely target RDBs lying at the nexus of these two complementary regimes, we explore a broad class of baseline models predicated on: (i) converting multi-table datasets into graphs using various strategies equipped with efficient subsampling, while preserving tabular characteristics; and (ii) trainable models with well-matched inductive biases that output predictions based on these input subgraphs. Then, to address the dearth of suitable public benchmarks and reduce siloed comparisons, we assemble a diverse collection of (i) large-scale RDB …
Poster
Tianle Gu · Zeyang Zhou · Kexin Huang · Liang Dandan · Yixu Wang · Haiquan Zhao · Yuanqi Yao · xingge qiao · Keqing wang · Yujiu Yang · Yan Teng · Yu Qiao · Yingchun Wang
[ West Ballroom A-D ]
Abstract
Powered by remarkable advancements in Large Language Models (LLMs), Multimodal Large Language Models (MLLMs) demonstrate impressive capabilities in manifold tasks.However, the practical application scenarios of MLLMs are intricate, exposing them to potential malicious instructions and thereby posing safety risks.While current benchmarks do incorporate certain safety considerations, they often lack comprehensive coverage and fail to exhibit the necessary rigor and robustness.For instance, the common practice of employing GPT-4V as both the evaluator and a model to be evaluated lacks credibility, as it tends to exhibit a bias toward its own responses.In this paper, we present MLLMGuard, a multi-dimensional safety evaluation suite for MLLMs, including a bilingual image-text evaluation dataset, inference utilities, and a lightweight evaluator.MLLMGuard's assessment comprehensively covers two languages (English and Chinese) and five important safety dimensions (Privacy, Bias, Toxicity, Truthfulness, and Legality), each with corresponding rich subtasks.Focusing on these dimensions, our evaluation dataset is primarily sourced from platforms such as social media, and it integrates text-based and image-based red teaming techniques with meticulous annotation by human experts.This can prevent inaccurate evaluation caused by data leakage when using open-source datasets and ensures the quality and challenging nature of our benchmark.Additionally, a fully automated lightweight evaluator termed GuardRank is developed, which …
Poster
Maximilian Muschalik · Hubert Baniecki · Fabian Fumagalli · Patrick Kolpaczki · Barbara Hammer · Eyke Hüllermeier
[ East Exhibit Hall A-C ]
Abstract
Originally rooted in game theory, the Shapley Value (SV) has recently become an important tool in machine learning research. Perhaps most notably, it is used for feature attribution and data valuation in explainable artificial intelligence. Shapley Interactions (SIs) naturally extend the SV and address its limitations by assigning joint contributions to groups of entities, which enhance understanding of black box machine learning models. Due to the exponential complexity of computing SVs and SIs, various methods have been proposed that exploit structural assumptions or yield probabilistic estimates given limited resources. In this work, we introduce shapiq, an open-source Python package that unifies state-of-the-art algorithms to efficiently compute SVs and any-order SIs in an application-agnostic framework. Moreover, it includes a benchmarking suite containing 11 machine learning applications of SIs with pre-computed games and ground-truth values to systematically assess computational performance across domains. For practitioners, shapiq is able to explain and visualize any-order feature interactions in predictions of models, including vision transformers, language models, as well as XGBoost and LightGBM with TreeSHAP-IQ. With shapiq, we extend shap beyond feature attributions and consolidate the application of SVs and SIs in machine learning that facilitates future research. The source code and documentation are available at …
Poster
Julia Gastinger · Shenyang Huang · Michael Galkin · Erfan Loghmani · Ali Parviz · Farimah Poursafaei · Jacob Danovitch · Emanuele Rossi · Ioannis Koutis · Heiner Stuckenschmidt · Reihaneh Rabbany · Guillaume Rabusseau
[ East Exhibit Hall A-C ]

Abstract
Multi-relational temporal graphs are powerful tools for modeling real-world data, capturing the evolving and interconnected nature of entities over time. Recently, many novel models are proposed for ML on such graphs intensifying the need for robust evaluation and standardized benchmark datasets. However, the availability of such resources remains scarce and evaluation faces added complexity due to reproducibility issues in experimental protocols. To address these challenges, we introduce Temporal Graph Benchmark 2.0 (TGB 2.0), a novel benchmarking framework tailored for evaluating methods for predicting future links on Temporal Knowledge Graphs and Temporal Heterogeneous Graphs with a focus on large-scale datasets, extending the Temporal Graph Benchmark. TGB 2.0 facilitates comprehensive evaluations by presenting eight novel datasets spanning five domains with up to 53 million edges. TGB 2.0 datasets are significantly largerthan existing datasets in terms of number of nodes, edges, or timestamps. In addition, TGB 2.0 provides a reproducible and realistic evaluation pipeline for multi-relational temporal graphs. Through extensive experimentation, we observe that 1) leveraging edge-type information is crucial to obtain high performance, 2) simple heuristic baselines are often competitive with more complex methods, 3) most methods fail to run on our largest datasets, highlighting the need for research on more scalable …
Poster
Minyang Tian · Luyu Gao · Shizhuo Zhang · Xinan Chen · Cunwei Fan · Xuefei Guo · Roland Haas · Pan Ji · Kittithat Krongchon · Yao Li · Shengyan Liu · Di Luo · Yutao Ma · HAO TONG · Kha Trinh · Chenyu Tian · Zihan Wang · Bohao Wu · Shengzhu Yin · Minhui Zhu · Kilian Lieret · Yanxin Lu · Genglin Liu · Yufeng Du · Tianhua Tao · Ofir Press · Jamie Callan · Eliu Huerta · Hao Peng
[ West Ballroom A-D ]
Abstract
Since language models (LMs) now outperform average humans on many challenging tasks, it is becoming increasingly difficult to develop challenging, high-quality, and realistic evaluations. We address this by examining LM capabilities to generate code for solving real scientific research problems. Incorporating input from scientists and AI researchers in 16 diverse natural science sub-fields, including mathematics, physics, chemistry, biology, and materials science, we create a scientist-curated coding benchmark, SciCode. The problems naturally factorize into multiple subproblems, each involving knowledge recall, reasoning, and code synthesis. In total, SciCode contains 338 subproblems decomposed from 80 challenging main problems, and it offers optional descriptions specifying useful scientific background information and scientist-annotated gold-standard solutions and test cases for evaluation. OpenAI o1-preview, the best-performing model among those tested, can solve only 7.7\% of the problems in the most realistic setting. We believe that SciCode demonstrates both contemporary LMs' progress towards realizing helpful scientific assistants and sheds light on the building and evaluation of scientific AI in the future.
Poster
Zhecan Wang · Junzhang Liu · Chia-Wei Tang · Hani Alomari · Anushka Sivakumar · Rui Sun · Wenhao Li · Md. Atabuzzaman · Hammad Ayyubi · Haoxuan You · Alvi Md Ishmam · Kai-Wei Chang · Shih-Fu Chang · Christopher Thomas
[ East Exhibit Hall A-C ]

Abstract
Existing vision-language understanding benchmarks largely consist of images of objects in their usual contexts.As a consequence, recent multimodal large language models can perform well with only a shallow visual understanding by relying on background language biases. Thus, strong performance on these benchmarks does not necessarily correlate with strong visual understanding. In this paper, we release JourneyBench, a comprehensive human-annotated benchmark of generated images designed to assess the model's fine-grained multimodal reasoning abilities across five tasks: complementary multimodal chain of thought, multi-image VQA, imaginary image captioning, VQA with hallucination triggers, and fine-grained retrieval with sample-specific distractors.Unlike existing benchmarks, JourneyBench explicitly requires fine-grained multimodal reasoning in unusual imaginary scenarios where language bias and holistic image gist are insufficient. We benchmark state-of-the-art models on JourneyBench and analyze performance along a number of fine-grained dimensions. Results across all five tasks show that JourneyBench is exceptionally challenging for even the best models, indicating that models' visual reasoning abilities are not as strong as they first appear. We discuss the implications of our findings and propose avenues for further research.
Poster
Brandon Victor · Mathilde Letard · Peter Naylor · Karim Douch · Nicolas Longepe · Zhen He · Patrick Ebel
[ West Ballroom A-D ]
Abstract
Floods are among the most common and devastating natural hazards, imposing immense costs on our society and economy due to their disastrous consequences. Recent progress in weather prediction and spaceborne flood mapping demonstrated the feasibility of anticipating extreme events and reliably detecting their catastrophic effects afterwards. However, these efforts are rarely linked to one another and there is a critical lack of datasets and benchmarks to enable the direct forecasting of flood extent. To resolve this issue, we curate a novel dataset enabling a timely prediction of flood extent. Furthermore, we provide a representative evaluation of state-of-the-art methods, structured into two benchmark tracks for forecasting flood inundation maps i) in general and ii) focused on coastal regions. Altogether, our dataset and benchmark provide a comprehensive platform for evaluating flood forecasts, enabling future solutions for this critical challenge. Data, code \& models are shared at https://github.com/Multihuntr/GFF under a CC0 license.
Poster
Qi Ma · Danda Pani Paudel · Ender Konukoglu · Luc V Gool
[ West Ballroom A-D ]
Abstract
Neural implicit functions have demonstrated significant importance in various areas such as computer vision, graphics. Their advantages include the ability to represent complex shapes and scenes with high fidelity, smooth interpolation capabilities, and continuous representations. Despite these benefits, the development and analysis of implicit functions have been limited by the lack of comprehensive datasets and the substantial computational resources required for their implementation and evaluation. To address these challenges, we introduce "Implicit-Zoo": a large-scale dataset requiring thousands of GPU training days designed to facilitate research and development in this field. Our dataset includes diverse 2D and 3D scenes, such as CIFAR-10, ImageNet-1K, and Cityscapes for 2D image tasks, and the OmniObject3D dataset for 3D vision tasks. We ensure high quality through strict checks, refining or filtering out low-quality data. Using Implicit-Zoo, we showcase two immediate benefits as it enables to: (1) learn token locations for transformer models; (2) Directly regress 3D cameras poses of 2D images with respect to NeRF models. This in turn leads to an \emph{improved performance} in all three task of image classification, semantic segmentation, and 3D pose regression -- thereby unlocking new avenues for research.
Poster
Chang Liu · Rebecca Saul · Yihao Sun · Edward Raff · Maya Fuchs · Townsend Southard Pantano · James Holt · Kristopher Micinski
[ West Ballroom A-D ]
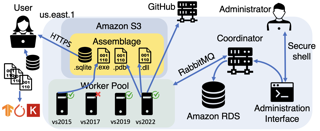
Abstract
Binary code is pervasive, and binary analysis is a key task in reverse engineering, malware classification, and vulnerability discovery. Unfortunately, while there exist large corpuses of malicious binaries, obtaining high-quality corpuses of benign binaries for modern systems has proven challenging (e.g., due to licensing issues). Consequently, machine learning based pipelines for binary analysis utilize either costly commercial corpuses (e.g., VirusTotal) or open-source binaries (e.g., coreutils) available in limited quantities. To address these issues, we present Assemblage: an extensible cloud-based distributed system that crawls, configures, and builds Windows PE binaries to obtain high-quality binary corpuses suitable for training state-of-the-art models in binary analysis. We have run Assemblage on AWS over the past year, producing 890k Windows PE and 428k Linux ELF binaries across 29 configurations. Assemblage is designed to be both reproducible and extensible, enabling users to publish "recipes" for their datasets, and facilitating the extraction of a wide array of features. We evaluated Assemblage by using its data to train modern learning-based pipelines for compiler provenance and binary function similarity. Our results illustrate the practical need for robust corpuses of high-quality Windows PE binaries in training modern learning-based binary analyses.
Spotlight Poster
Irina Saparina · Mirella Lapata
[ West Ballroom A-D ]

Abstract
Practical semantic parsers are expected to understand user utterances and map them to executable programs, even when these are ambiguous. We introduce a new benchmark, AMBROSIA, which we hope will inform and inspire the development of text-to-SQL parsers capable of recognizing and interpreting ambiguous requests. Our dataset contains questions showcasing three different types of ambiguity (scope ambiguity, attachment ambiguity, and vagueness), their interpretations, and corresponding SQL queries. In each case, the ambiguity persists even when the database context is provided. This is achieved through a novel approach that involves controlled generation of databases from scratch. We benchmark various LLMs on AMBROSIA, revealing that even the most advanced models struggle to identify and interpret ambiguity in questions.
Poster
Avi Caciularu · Alon Jacovi · Eyal Ben-David · Sasha Goldshtein · Tal Schuster · Jonathan Herzig · Gal Elidan · Amir Globerson
[ East Exhibit Hall A-C ]
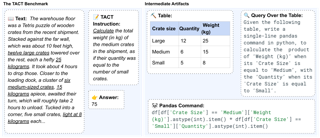
Abstract
Large Language Models (LLMs) often do not perform well on queries that require the aggregation of information across texts. To better evaluate this setting and facilitate modeling efforts, we introduce TACT - Text And Calculations through Tables, a dataset crafted to evaluate LLMs' reasoning and computational abilities using complex instructions. TACT contains challenging instructions that demand stitching information scattered across one or more texts, and performing complex integration on this information to generate the answer. We construct this dataset by leveraging an existing dataset of texts and their associated tables. For each such tables, we formulate new queries, and gather their respective answers. We demonstrate that all contemporary LLMs perform poorly on this dataset, achieving an accuracy below 38%. To pinpoint the difficulties and thoroughly dissect the problem, we analyze model performance across three components: table-generation, Pandas command-generation, and execution. Unexpectedly, we discover that each component presents substantial challenges for current LLMs. These insights lead us to propose a focused modeling framework, which we refer to as _IE as a tool_. Specifically, we propose to add "tools" for each of the above steps, and implement each such tool with few-shot prompting. This approach shows an improvement over existing prompting techniques, …
Poster
Allen Roush · Yusuf Shabazz · Arvind Balaji · Peter Zhang · Stefano Mezza · Markus Zhang · Sanjay Basu · Sriram Vishwanath · Ravid Shwartz-Ziv
[ West Ballroom A-D ]
Abstract
We introduce OpenDebateEvidence, a comprehensive dataset for argument miningand summarization sourced from the American Competitive Debate community.This dataset includes over 3.5 million documents with rich metadata, making itone of the most extensive collections of debate evidence. OpenDebateEvidencecaptures the complexity of arguments in high school and college debates, pro-viding valuable resources for training and evaluation. Our extensive experimentsdemonstrate the efficacy of fine-tuning state-of-the-art large language models forargumentative abstractive summarization across various methods, models, anddatasets. By providing this comprehensive resource, we aim to advance com-putational argumentation and support practical applications for debaters, edu-cators, and researchers. OpenDebateEvidence is publicly available to supportfurther research and innovation in computational argumentation. Access it here:https://huggingface.co/datasets/Yusuf5/OpenCaselist.
Poster
Tianqi Tang · Shohreh Deldari · Hao Xue · Celso de Melo · Flora Salim
[ West Ballroom A-D ]
Abstract
Video language continual learning involves continuously adapting to information from video and text inputs, enhancing a model’s ability to handle new tasks while retaining prior knowledge. This field is a relatively under-explored area, and establishing appropriate datasets is crucial for facilitating communication and research in this field. In this study, we present the first dedicated benchmark, ViLCo-Bench, designed to evaluate continual learning models across a range of video-text tasks. The dataset comprises ten-minute-long videos and corresponding language queries collected from publicly available datasets. Additionally, we introduce a novel memory-efficient framework that incorporates self-supervised learning and mimics long-term and short-term memory effects. This framework addresses challenges including memory complexity from long video clips, natural language complexity from open queries, and text-video misalignment. We posit that ViLCo-Bench, with greater complexity compared to existing continual learning benchmarks, would serve as a critical tool for exploring the video-language domain, extending beyond conventional class-incremental tasks, and addressing complex and limited annotation issues. The curated data, evaluations, and our novel method are available at https://github.com/cruiseresearchgroup/ViLCo.
Poster
JR-JEN CHEN · Yu-Chien Liao · Hsi-Che Lin · Yu-Chu Yu · Yen-Chun Chen · Frank Wang
[ West Ballroom A-D ]
Abstract
We introduce ReXTime, a benchmark designed to rigorously test AI models' ability to perform temporal reasoning within video events.Specifically, ReXTime focuses on reasoning across time, i.e. human-like understanding when the question and its corresponding answer occur in different video segments. This form of reasoning, requiring advanced understanding of cause-and-effect relationships across video segments, poses significant challenges to even the frontier multimodal large language models. To facilitate this evaluation, we develop an automated pipeline for generating temporal reasoning question-answer pairs, significantly reducing the need for labor-intensive manual annotations. Our benchmark includes 921 carefully vetted validation samples and 2,143 test samples, each manually curated for accuracy and relevance. Evaluation results show that while frontier large language models outperform academic models, they still lag behind human performance by a significant 14.3\% accuracy gap. Additionally, our pipeline creates a training dataset of 9,695 machine generated samples without manual effort, which empirical studies suggest can enhance the across-time reasoning via fine-tuning.
Spotlight Poster
Liane Vogel · Jan-Micha Bodensohn · Carsten Binnig
[ West Ballroom A-D ]

Abstract
Deep learning on tabular data, and particularly tabular representation learning, has recently gained growing interest. However, representation learning for relational databases with multiple tables is still an underexplored area, which may be attributed to the lack of openly available resources. To support the development of foundation models for tabular data and relational databases, we introduce WikiDBs, a novel open-source corpus of 100,000 relational databases. Each database consists of multiple tables connected by foreign keys. The corpus is based on Wikidata and aims to follow certain characteristics of real-world databases. In this paper, we describe the dataset and our method for creating it. By making our code publicly available, we enable others to create tailored versions of the dataset, for example, by creating databases in different languages. Finally, we conduct a set of initial experiments to showcase how WikiDBs can be used to train for data engineering tasks, such as missing value imputation and column type annotation.
Poster
Filip Granqvist · Congzheng Song · Áine Cahill · Rogier van Dalen · Martin Pelikan · Yi Sheng Chan · Xiaojun Feng · Natarajan Krishnaswami · Vojta Jina · Mona Chitnis
[ West Ballroom A-D ]
Abstract
Federated learning (FL) is an emerging machine learning (ML) training paradigm where clients own their data and collaborate to train a global model, without revealing any data to the server and other participants. Researchers commonly perform experiments in a simulation environment to quickly iterate on ideas. However, existing open-source tools do not offer the efficiency required to simulate FL on larger and more realistic FL datasets. We introduce $\texttt{pfl-research}$, a fast, modular, and easy-to-use Python framework for simulating FL. It supports TensorFlow, PyTorch, and non-neural network models, and is tightly integrated with state-of-the-art privacy algorithms. We study the speed of open-source FL frameworks and show that $\texttt{pfl-research}$ is 7-72$\times$ faster than alternative open-source frameworks on common cross-device setups. Such speedup will significantly boost the productivity of the FL research community and enable testing hypotheses on realistic FL datasets that were previously too resource intensive. We release a suite of benchmarks that evaluates an algorithm's overall performance on a diverse set of realistic scenarios.
Poster
Yiran Liu · Ke Yang · Zehan Qi · Xiao Liu · Yang Yu · Cheng Xiang Zhai
[ West Ballroom A-D ]

Abstract
We present a novel statistical framework for analyzing stereotypes in large language models (LLMs) by systematically estimating the bias and variation in their generation. Current evaluation metrics in the alignment literature often overlook the randomness of stereotypes caused by the inconsistent generative behavior of LLMs. For example, this inconsistency can result in LLMs displaying contradictory stereotypes, including those related to gender or race, for identical professions across varied contexts. Neglecting such inconsistency could lead to misleading conclusions in alignment evaluations and hinder the accurate assessment of the risk of LLM applications perpetuating or amplifying social stereotypes and unfairness.This work proposes a Bias-Volatility Framework (BVF) that estimates the probability distribution function of LLM stereotypes. Specifically, since the stereotype distribution fully captures an LLM's generation variation, BVF enables the assessment of both the likelihood and extent to which its outputs are against vulnerable groups, thereby allowing for the quantification of the LLM's aggregated discrimination risk. Furthermore, we introduce a mathematical framework to decompose an LLM’s aggregated discrimination risk into two components: bias risk and volatility risk, originating from the mean and variation of LLM’s stereotype distribution, respectively. We apply BVF to assess 12 commonly adopted LLMs and compare their risk levels. Our …
Poster
Jiafei Lyu · Kang Xu · Jiacheng Xu · yan · Jing-Wen Yang · Zongzhang Zhang · Chenjia Bai · Zongqing Lu · Xiu Li
[ West Ballroom A-D ]
Abstract
We consider off-dynamics reinforcement learning (RL) where one needs to transfer policies across different domains with dynamics mismatch. Despite the focus on developing dynamics-aware algorithms, this field is hindered due to the lack of a standard benchmark. To bridge this gap, we introduce ODRL, the first benchmark tailored for evaluating off-dynamics RL methods. ODRL contains four experimental settings where the source and target domains can be either online or offline, and provides diverse tasks and a broad spectrum of dynamics shifts, making it a reliable platform to comprehensively evaluate the agent's adaptation ability to the target domain. Furthermore, ODRL includes recent off-dynamics RL algorithms in a unified framework and introduces some extra baselines for different settings, all implemented in a single-file manner. To unpack the true adaptation capability of existing methods, we conduct extensive benchmarking experiments, which show that no method has universal advantages across varied dynamics shifts. We hope this benchmark can serve as a cornerstone for future research endeavors. Our code is publicly available at https://github.com/OffDynamicsRL/off-dynamics-rl.
Poster
Alejandro Lozano · Jeffrey Nirschl · James Burgess · Sanket Rajan Gupte · Yuhui Zhang · Alyssa Unell · Serena Yeung
[ West Ballroom A-D ]

Abstract
Recent advances in microscopy have enabled the rapid generation of terabytes of image data in cell biology and biomedical research. Vision-language models (VLMs) offer a promising solution for large-scale biological image analysis, enhancing researchers’ efficiency, identifying new image biomarkers, and accelerating hypothesis generation and scientific discovery. However, there is a lack of standardized, diverse, and large-scale vision-language benchmarks to evaluate VLMs’ perception and cognition capabilities in biological image understanding. To address this gap, we introduce Micro-Bench, an expert-curated benchmark encompassing 24 biomedical tasks across various scientific disciplines (biology, pathology), microscopy modalities (electron, fluorescence, light), scales (subcellular, cellular, tissue), and organisms in both normal and abnormal states. We evaluate state-of-the-art biomedical, pathology, and general VLMs on Micro-Bench and find that: i) current models struggle on all categories, even for basic tasks such as distinguishing microscopy modalities; ii) current specialist models fine-tuned on biomedical data often perform worse than generalist models; iii) fine-tuning in specific microscopy domains can cause catastrophic forgetting, eroding prior biomedical knowledge encoded in their base model. iv) weight interpolation between fine-tuned and pre-trained models offers one solution to forgetting and improves general performance across biomedical tasks. We release Micro-Bench under a permissive license to accelerate the research and …
Poster
Wassim Gabriel · Omar Shouman · Eva Ayla Schröder · Florian Bößl · Mathias Wilhelm
[ East Exhibit Hall A-C ]
Abstract
Post-Translational Modifications (PTMs) are changes that occur in proteins after synthesis, influencing their structure, function, and cellular behavior. PTMs are essential in cell biology; they regulate protein function and stability, are involved in various cellular processes, and are linked to numerous diseases. A particularly interesting class of PTMs are chemical modifications such as phosphorylation introduced on amino acid side chains because they can drastically alter the physicochemical properties of the peptides once they are present. One or more PTMs can be attached to each amino acid of the peptide sequence. The most commonly applied technique to detect PTMs on proteins is bottom-up Mass Spectrometry-based proteomics (MS), where proteins are digested into peptides and subsequently analyzed using Tandem Mass Spectrometry (MS/MS). While an increasing number of machine learning models are published focusing on MS/MS-related property prediction of unmodified peptides, high-quality reference data for modified peptides is missing, impeding model development for this important class of peptides. To enable researchers to train machine learning models that can accurately predict the properties of modified peptides, we introduce four high-quality labeled datasets for applying machine and deep learning to tasks in MS-based proteomics. The four datasets comprise several subgroups of peptides with 1.2 million …
Poster
Hejie Cui · Lingjun Mao · Xin Liang · Jieyu Zhang · Hui Ren · Quanzheng Li · Xiang Li · Carl Yang
[ East Exhibit Hall A-C ]
Abstract
Recent advancements in multimodal foundation models have showcased impressive capabilities in understanding and reasoning with visual and textual information. Adapting these foundation models trained for general usage to specialized domains like biomedicine requires large-scale domain-specific instruction datasets. While existing works have explored curating such datasets automatically, the resultant datasets are not explicitly aligned with domain expertise. In this work, we propose a data-centric framework, Biomedical Visual Instruction Tuning with Clinician Preference Alignment (BioMed-VITAL), that incorporates clinician preferences into both stages of generating and selecting instruction data for tuning biomedical multimodal foundation models. First, during the generation stage, we prompt the GPT-4V generator with a diverse set of clinician-selected demonstrations for preference-aligned data candidate generation. Then, during the selection phase, we train a separate selection model, which explicitly distills clinician and policy-guided model preferences into a rating function to select high-quality data for medical instruction tuning. Results show that the model tuned with the instruction-following data from our method demonstrates a significant improvement in open visual chat (18.5% relatively) and medical VQA (win rate up to 81.73%). Our instruction-following data and models are available at https://BioMed-VITAL.github.io.
Poster
Jin Wu · Haoying Zhou · Peter Kazanzides · Adnan Munawar · Anqi Liu
[ East Exhibit Hall A-C ]
Abstract
Despite advancements in robotic-assisted surgery, automating complex tasks like suturing remains challenging due to the need for adaptability and precision. Learning-based approaches, particularly reinforcement learning (RL) and imitation learning (IL), require realistic simulation environments for efficient data collection. However, current platforms often include only relatively simple, non-dexterous manipulations and lack the flexibility required for effective learning and generalization. We introduce SurgicAI, a novel platform for development and benchmarking that addresses these challenges by providing the flexibility to accommodate both modular subtasks and more importantly task decomposition in RL-based surgical robotics. Compatible with the da Vinci Surgical System, SurgicAI offers a standardized pipeline for collecting and utilizing expert demonstrations. It supports the deployment of multiple RL and IL approaches, and the training of both singular and compositional subtasks in suturing scenarios, featuring high dexterity and modularization. Meanwhile, SurgicAI sets clear metrics and benchmarks for the assessment of learned policies. We implemented and evaluated multiple RL and IL algorithms on SurgicAI. Our detailed benchmark analysis underscores SurgicAI's potential to advance policy learning in surgical robotics. Details: https://github.com/surgical-robotics-ai/SurgicAI
Poster
Yufang Hou · Alessandra Pascale · Javier Carnerero-Cano · Tigran Tchrakian · Radu Marinescu · Elizabeth Daly · Inkit Padhi · Prasanna Sattigeri
[ East Exhibit Hall A-C ]

Abstract
Retrieval-augmented generation (RAG) has emerged as a promising solution to mitigate the limitations of large language models (LLMs), such as hallucinations and outdated information. However, it remains unclear how LLMs handle knowledge conflicts arising from different augmented retrieved passages, especially when these passages originate from the same source and have equal trustworthiness. In this work, we conduct a comprehensive evaluation of LLM-generated answers to questions that have varying answers based on contradictory passages from Wikipedia, a dataset widely regarded as a high-quality pre-training resource for most LLMs. Specifically, we introduce WikiContradict, a benchmark consisting of 253 high-quality, human-annotated instances designed to assess the performance of LLMs in providing a complete perspective on conflicts from the retrieved documents, rather than choosing one answer over another, when augmented with retrieved passages containing real-world knowledge conflicts. We benchmark a diverse range of both closed and open-source LLMs under different QA scenarios, including RAG with a single passage, and RAG with 2 contradictory passages. Through rigorous human evaluations on a subset of WikiContradict instances involving 5 LLMs and over 3,500 judgements, we shed light on the behaviour and limitations of these models. For instance, when provided with two passages containing contradictory facts, all models …
Poster
Faeze Brahman · Sachin Kumar · Vidhisha Balachandran · Pradeep Dasigi · Valentina Pyatkin · Abhilasha Ravichander · Sarah Wiegreffe · Nouha Dziri · Khyathi Chandu · Jack Hessel · Yulia Tsvetkov · Noah Smith · Yejin Choi · Hanna Hajishirzi
[ East Exhibit Hall A-C ]
Abstract
Chat-based language models are designed to be helpful, yet they should not comply with every user request. While most existing work primarily focuses on refusal of ``unsafe'' queries, we posit that the scope of noncompliance should be broadened. We introduce a comprehensive taxonomy of contextual noncompliance describing when and how models should *not* comply with user requests. Our taxonomy spans a wide range of categories including *incomplete*, *unsupported*, *indeterminate*, and *humanizing* requests (in addition to *unsafe* requests). To test noncompliance capabilities of language models, we use this taxonomy to develop a new evaluation suite of 1000 noncompliance prompts. We find that most existing models show significantly high compliance rates in certain previously understudied categories with models like GPT-4 incorrectly complying with as many as 30\% of requests.To address these gaps, we explore different training strategies using a synthetically-generated training set of requests and expected noncompliant responses. Our experiments demonstrate that while direct finetuning of instruction-tuned models can lead to both over-refusal and a decline in general capabilities, using parameter efficient methods like low rank adapters helps to strike a good balance between appropriate noncompliance and other capabilities.
Poster
Connor Brennan · Andrew Williams · Omar G. Younis · Vedant Vyas · Daria Yasafova · Irina Rish
[ West Ballroom A-D ]
Abstract
Leveraging the depth and flexibility of XLand as well as the rapid prototyping features of the Unity engine, we present the United Unity Universe — an open-source toolkit designed to accelerate the creation of innovative reinforcement learning environments. This toolkit includes a robust implementation of XLand 2.0 complemented by a user-friendly interface which allows users to modify the details of procedurally generated terrains and task rules with ease. Additionally, we provide a curated selection of terrains and rule sets, accompanied by implementations of reinforcement learning baselines to facilitate quick experimentation with novel architectural designs for adaptive agents. Furthermore, we illustrate how the United Unity Universe serves as a high-level language that enables researchers to develop diverse and endlessly variable 3D environments within a unified framework. This functionality establishes the United Unity Universe (U3) as an essential tool for advancing the field of reinforcement learning, especially in the development of adaptive and generalizable learning systems.
Poster
Chen Yeh · You-Ming Chang · Wei-Chen Chiu · Ning Yu
[ West Ballroom A-D ]
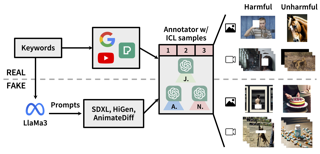
Abstract
While widespread access to the Internet and the rapid advancement of generative models boost people's creativity and productivity, the risk of encountering inappropriate or harmful content also increases. To address the aforementioned issue, researchers managed to incorporate several harmful contents datasets with machine learning methods to detect harmful concepts. However, existing harmful datasets are curated by the presence of a narrow range of harmful objects, and only cover real harmful content sources. This restricts the generalizability of methods based on such datasets and leads to the potential misjudgment in certain cases. Therefore, we propose a comprehensive and extensive harmful dataset, **VHD11K**, consisting of 10,000 images and 1,000 videos, crawled from the Internet and generated by 4 generative models, across a total of 10 harmful categories covering a full spectrum of harmful concepts with non-trival definition. We also propose a novel annotation framework by formulating the annotation process as a multi-agent Visual Question Answering (VQA) task, having 3 different VLMs "debate" about whether the given image/video is harmful, and incorporating the in-context learning strategy in the debating process. Therefore, we can ensure that the VLMs consider the context of the given image/video and both sides of the arguments thoroughly before making …
Poster
Tianbao Xie · Danyang Zhang · Jixuan Chen · Xiaochuan Li · Siheng Zhao · Ruisheng Cao · Jing Hua Toh · Zhoujun Cheng · Dongchan Shin · Fangyu Lei · Yitao Liu · Yiheng Xu · Shuyan Zhou · Silvio Savarese · Caiming Xiong · Victor Zhong · Tao Yu
[ East Exhibit Hall A-C ]

Abstract
Autonomous agents that accomplish complex computer tasks with minimal human interventions have the potential to transform human-computer interaction, significantly enhancing accessibility and productivity. However, existing benchmarks either lack an interactive environment or are limited to environments specific to certain applications or domains, failing to reflect the diverse and complex nature of real-world computer use, thereby limiting the scope of tasks and agent scalability. To address this issue, we introduce OSWorld, the first-of-its-kind scalable, real computer environment for multimodal agents, supporting task setup, execution-based evaluation, and interactive learning across various operating systems such as Ubuntu, Windows, and macOS. OSWorld can serve as a unified, integrated computer environment for assessing open-ended computer tasks that involve arbitrary applications. Building upon OSWorld, we create a benchmark of 369 computer tasks involving real web and desktop apps in open domains, OS file I/O, and workflows spanning multiple applications. Each task example is derived from real-world computer use cases and includes a detailed initial state setup configuration and a custom execution-based evaluation script for reliable, reproducible evaluation. Extensive evaluation of state-of-the-art LLM/VLM-based agents on OSWorld reveals significant deficiencies in their ability to serve as computer assistants. While humans can accomplish over 72.36% of the tasks, the …
Poster
Xiaoyuan Zhang · Liang ZHAO · Yingying Yu · Xi Lin · Yifan Chen · Han Zhao · Qingfu Zhang
[ East Exhibit Hall A-C ]
Abstract
Multiobjective optimization problems (MOPs) are prevalent in machine learning, with applications in multi-task learning, learning under fairness or robustness constraints, etc. Instead of reducing multiple objective functions into a scalar objective, MOPs aim to optimize for the so-called Pareto optimality or Pareto set learning, which involves optimizing more than one objective function simultaneously, over models with thousands to millions of parameters. Existing benchmark libraries for MOPs mainly focus on evolutionary algorithms, most of which are zeroth-order or meta-heuristic methods that do not effectively utilize higher-order information from objectives and cannot scale to large-scale models with millions of parameters. In light of the above challenges, this paper introduces \algoname, the first multiobjective optimization library that supports state-of-the-art gradient-based methods, provides a fair and comprehensive benchmark, and is open-sourced for the community.
Spotlight Poster
Artur Szałata · Andrew Benz · Robrecht Cannoodt · Mauricio Cortes · Jason Fong · Sunil Kuppasani · Richard Lieberman · Tianyu Liu · Javier Mas-Rosario · Rico Meinl · Jalil Nourisa · Jared Tumiel · Tin M. Tunjic · Mengbo Wang · Noah Weber · Hongyu Zhao · Benedict Anchang · Fabian Theis · Malte Luecken · Daniel Burkhardt
[ East Exhibit Hall A-C ]
Abstract
Single-cell transcriptomics has revolutionized our understanding of cellular heterogeneity and drug perturbation effects. However, its high cost and the vast chemical space of potential drugs present barriers to experimentally characterizing the effect of chemical perturbations in all the myriad cell types of the human body. To overcome these limitations, several groups have proposed using machine learning methods to directly predict the effect of chemical perturbations either across cell contexts or chemical space. However, advances in this field have been hindered by a lack of well-designed evaluation datasets and benchmarks. To drive innovation in perturbation modeling, the Open Problems Perturbation Prediction (OP3) benchmark introduces a framework for predicting the effects of small molecule perturbations on cell type-specific gene expression. OP3 leverages the Open Problems in Single-cell Analysis benchmarking infrastructure and is enabled by a new single-cell perturbation dataset, encompassing 146 compounds tested on human blood cells. The benchmark includes diverse data representations, evaluation metrics, and winning methods from our "Single-cell perturbation prediction: generalizing experimental interventions to unseen contexts" competition at NeurIPS 2023. We envision that the OP3 benchmark and competition will drive innovation in single-cell perturbation prediction by improving the accessibility, visibility, and feasibility of this challenge, thereby promoting the impact …
Poster
Tessa Han · Aounon Kumar · Chirag Agarwal · Himabindu Lakkaraju
[ East Exhibit Hall A-C ]
Abstract
As large language models (LLMs) develop increasingly sophisticated capabilities and find applications in medical settings, it becomes important to assess their medical safety due to their far-reaching implications for personal and public health, patient safety, and human rights. However, there is little to no understanding of the notion of medical safety in the context of LLMs, let alone how to evaluate and improve it. To address this gap, we first define the notion of medical safety in LLMs based on the Principles of Medical Ethics set forth by the American Medical Association. We then leverage this understanding to introduce MedSafetyBench, the first benchmark dataset designed to measure the medical safety of LLMs. We demonstrate the utility of MedSafetyBench by using it to evaluate and improve the medical safety of LLMs. Our results show that publicly-available medical LLMs do not meet standards of medical safety and that fine-tuning them using MedSafetyBench improves their medical safety while preserving their medical performance. By introducing this new benchmark dataset, our work enables a systematic study of the state of medical safety in LLMs and motivates future work in this area, paving the way to mitigate the safety risks of LLMs in medicine. The benchmark …
Poster
Anas Awadalla · Le Xue · Oscar Lo · Manli Shu · Hannah Lee · Etash Guha · Sheng Shen · Mohamed Awadalla · Silvio Savarese · Caiming Xiong · Ran Xu · Yejin Choi · Ludwig Schmidt
[ East Exhibit Hall A-C ]
Abstract
Multimodal interleaved datasets featuring free-form interleaved sequences of images and text are crucial for training frontier large multimodal models (LMMs). Despite the rapid progression of open-source LMMs, there remains a pronounced scarcity of large-scale, open-source multimodal interleaved datasets.In response, we introduce MINT-1T, the most extensive and diverse open-source Multimodal INTerleaved dataset to date. MINT-1T comprises of one trillion text tokens and 3.4 billion images, a 10x scale-up from existing open-source datasets. Additionally, we include previously untapped sources such as PDFs and ArXiv papers. As scaling multimodal interleaved datasets requires substantial engineering effort, sharing the data curation process and releasing the dataset greatly benefits the community. Our experiments show that LMMs trained on MINT-1T rival the performance of models trained on the previous leading dataset, OBELICS. We release our data at https://github.com/mlfoundations/MINT-1T.
Poster
Zuxin Liu · Thai Hoang · Jianguo Zhang · Ming Zhu · Tian Lan · Shirley kokane · Juntao Tan · Weiran Yao · Zhiwei Liu · Yihao Feng · Rithesh R N · Liangwei Yang · Silvio Savarese · Juan Carlos Niebles · Huan Wang · Shelby Heinecke · Caiming Xiong
[ West Ballroom A-D ]
Abstract
The advancement of function-calling agent models requires diverse, reliable, and high-quality datasets. This paper presents APIGen, an automated data generation pipeline designed to synthesize high-quality datasets for function-calling applications. We leverage APIGen and collect 3,673 executable APIs across 21 different categories to generate diverse function-calling datasets in a scalable and structured manner. Each data in our dataset is verified through three hierarchical stages: format checking, actual function executions, and semantic verification, improving its reliability and correctness. We demonstrate that models trained with our curated datasets, even with only 7B parameters, can achieve state-of-the-art performance on the Berkeley Function-Calling Benchmark, outperforming multiple GPT-4 models. Moreover, our 1B model achieves exceptional performance, surpassing GPT-3.5-Turbo and Claude-3 Haiku. We release a dataset containing 60,000 high-quality entries, aiming to advance the field of function-calling agent domains. The dataset and models are available on the project homepage \url{https://apigen-pipeline.github.io/}.
Poster
Xin Shen · Heming Du · Hongwei Sheng · Shuyun Wang · Hui Chen · Huiqiang Chen · Zhuojie Wu · Xiaobiao Du · Jiaying Ying · Ruihan Lu · Qingzheng Xu · Xin Yu
[ West Ballroom A-D ]
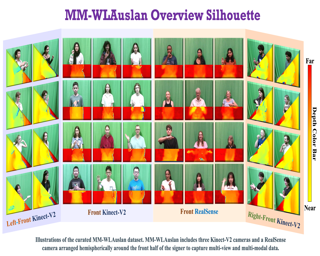
Abstract
Isolated Sign Language Recognition (ISLR) focuses on identifying individual sign language glosses. Considering the diversity of sign languages across geographical regions, developing region-specific ISLR datasets is crucial for supporting communication and research. Auslan, as a sign language specific to Australia, still lacks a dedicated large-scale word-level dataset for the ISLR task. To fill this gap, we curate \underline{\textbf{the first}} large-scale Multi-view Multi-modal Word-Level Australian Sign Language recognition dataset, dubbed MM-WLAuslan. Compared to other publicly available datasets, MM-WLAuslan exhibits three significant advantages: (1) **the largest amount** of data, (2) **the most extensive** vocabulary, and (3) **the most diverse** of multi-modal camera views. Specifically, we record **282K+** sign videos covering **3,215** commonly used Auslan glosses presented by **73** signers in a studio environment.Moreover, our filming system includes two different types of cameras, i.e., three Kinect-V2 cameras and a RealSense camera. We position cameras hemispherically around the front half of the model and simultaneously record videos using all four cameras. Furthermore, we benchmark results with state-of-the-art methods for various multi-modal ISLR settings on MM-WLAuslan, including multi-view, cross-camera, and cross-view. Experiment results indicate that MM-WLAuslan is a challenging ISLR dataset, and we hope this dataset will contribute to the development of Auslan and the …
Spotlight Poster
Eshta Bhardwaj · Harshit Gujral · Siyi Wu · Ciara Zogheib · Tegan Maharaj · Christoph Becker
[ West Ballroom A-D ]
Abstract
Data curation is a field with origins in librarianship and archives, whose scholarship and thinking on data issues go back centuries, if not millennia. The field of machine learning is increasingly observing the importance of data curation to the advancement of both applications and fundamental understanding of machine learning models -- evidenced not least by the creation of the Datasets and Benchmarks track itself. This work provides an analysis of recent dataset development practices at NeurIPS through the lens of data curation. We present an evaluation framework for dataset documentation, consisting of a rubric and toolkit developed through a thorough literature review of data curation principles. We use the framework to systematically assess the strengths and weaknesses in current dataset development practices of 60 datasets published in the NeurIPS Datasets and Benchmarks track from 2021-2023. We summarize key findings and trends. Results indicate greater need for documentation about environmental footprint, ethical considerations, and data management. We suggest targeted strategies and resources to improve documentation in these areas and provide recommendations for the NeurIPS peer-review process that prioritize rigorous data curation in ML. We also provide guidelines for dataset developers on the use of our rubric as a standalone tool. Finally, …
Poster
Tony Lee · Haoqin Tu · Chi Heem Wong · Wenhao Zheng · Yiyang Zhou · Yifan Mai · Josselin Roberts · Michihiro Yasunaga · Huaxiu Yao · Cihang Xie · Percy Liang
[ East Exhibit Hall A-C ]
Abstract
Current benchmarks for assessing vision-language models (VLMs) often focus on their perception or problem-solving capabilities and neglect other critical aspects such as fairness, multilinguality, or toxicity. Furthermore, they differ in their evaluation procedures and the scope of the evaluation, making it difficult to compare models. To address these issues, we extend the HELM framework to VLMs to present the Holistic Evaluation of Vision Language Models (VHELM). VHELM aggregates various datasets to cover one or more of the 9 aspects: *visual perception*, *knowledge*, *reasoning*, *bias*, *fairness*, *multilinguality*, *robustness*, *toxicity*, and *safety*. In doing so, we produce a comprehensive, multi-dimensional view of the capabilities of the VLMs across these important factors. In addition, we standardize the standard inference parameters, methods of prompting, and evaluation metrics to enable fair comparisons across models. Our framework is designed to be lightweight and automatic so that evaluation runs are cheap and fast. Our initial run evaluates 22 VLMs on 21 existing datasets to provide a holistic snapshot of the models. We uncover new key findings, such as the fact that efficiency-focused models (e.g., Claude 3 Haiku or Gemini 1.5 Flash) perform significantly worse than their full models (e.g., Claude 3 Opus or Gemini 1.5 Pro) on …
Poster
Wufei Ma · Guofeng Zhang · Qihao Liu · Guanning Zeng · Adam Kortylewski · Yaoyao Liu · Alan Yuille
[ East Exhibit Hall A-C ]

Abstract
A vision model with general-purpose object-level 3D understanding should be capable of inferring both 2D (*e.g.*, class name and bounding box) and 3D information (*e.g.*, 3D location and 3D viewpoint) for arbitrary rigid objects in natural images. This is a challenging task, as it involves inferring 3D information from 2D signals and most importantly, generalizing to rigid objects from unseen categories. However, existing datasets with object-level 3D annotations are often limited by the number of categories or the quality of annotations. Models developed on these datasets become specialists for certain categories or domains, and fail to generalize. In this work, we present ImageNet3D, a large dataset for general-purpose object-level 3D understanding. ImageNet3D augments 200 categories from the ImageNet dataset with 2D bounding box, 3D pose, 3D location annotations, and image captions interleaved with 3D information. With the new annotations available in ImageNet3D, we could (i) analyze the object-level 3D awareness of visual foundation models, and (ii) study and develop general-purpose models that infer both 2D and 3D information for arbitrary rigid objects in natural images, and (iii) integrate unified 3D models with large language models for 3D-related reasoning. We consider two new tasks, probing of object-level 3D awareness and open …
Poster
sagi eppel · Jolina Li · Manuel Drehwald · Alan Aspuru-Guzik
[ East Exhibit Hall A-C ]

Abstract
Visual recognition of materials and their states is essential for understanding the physical world, from identifying wet regions on surfaces or stains on fabrics to detecting infected areas or minerals in rocks. Collecting data that captures this vast variability is complex due to the scattered and gradual nature of material states. Manually annotating real-world images is constrained by cost and precision, while synthetic data, although accurate and inexpensive, lacks real-world diversity. This work aims to bridge this gap by infusing patterns automatically extracted from real-world images into synthetic data. Hence, patterns collected from natural images are used to generate and map materials into synthetic scenes. This unsupervised approach captures the complexity of the real world while maintaining the precision and scalability of synthetic data. We also present the first comprehensive benchmark for zero-shot material state segmentation, utilizing real-world images across a diverse range of domains, including food, soils, construction, plants, liquids, and more, each appears in various states such as wet, dry, infected, cooked, burned, and many others. The annotation includes partial similarity between regions with similar but not identical materials and hard segmentation of only identical material states. This benchmark eluded top foundation models, exposing the limitations of existing …
Poster
Yanzhi Li · Keqiu Li · LI GUOHUI · zumin wang · Chanqing Ji · Lubo Wang · Die Zuo · Qing Guo · Feng Zhang · Manyu Wang · Di Lin
[ West Ballroom A-D ]
Abstract
The latest research on wildfire forecast and backtracking has adopted AI models, which require a large amount of data from wildfire scenarios to capture fire spread patterns. This paper explores using cost-effective simulated wildfire scenarios to train AI models and apply them to the analysis of real-world wildfire. This solution requires AI models to minimize the Sim2Real gap, a brand-new topic in the fire spread analysis research community. To investigate the possibility of minimizing the Sim2Real gap, we collect the Sim2Real-Fire dataset that contains 1M simulated scenarios with multi-modal environmental information for training AI models. We prepare 1K real-world wildfire scenarios for testing the AI models. We also propose a deep transformer, S2R-FireTr, which excels in considering the multi-modal environmental information for forecasting and backtracking the wildfire. S2R-FireTr surpasses state-of-the-art methods in real-world wildfire scenarios.
Poster
Jian Liu · Jianyu Wu · Hairun Xie · Guoqing zhang · Jing Wang · Liu Wei · Wanli Ouyang · Junjun Jiang · Xianming Liu · SHIXIANG TANG · Miao Zhang
[ West Ballroom A-D ]

Abstract
Data-driven generative models have emerged as promising approaches towards achieving efficient mechanical inverse design. However, due to prohibitively high cost in time and money, there is still lack of open-source and large-scale benchmarks in this field. It is mainly the case for airfoil inverse design, which requires to generate and edit diverse geometric-qualified and aerodynamic-qualified airfoils following the multimodal instructions, \emph{i.e.,} dragging points and physical parameters. This paper presents the open-source endeavors in airfoil inverse design, \emph{AFBench}, including a large-scale dataset with 200 thousand airfoils and high-quality aerodynamic and geometric labels, two novel and practical airfoil inverse design tasks, \emph{i.e.,} conditional generation on multimodal physical parameters, controllable editing, and comprehensive metrics to evaluate various existing airfoil inverse design methods. Our aim is to establish \emph{AFBench} as an ecosystem for training and evaluating airfoil inverse design methods, with a specific focus on data-driven controllable inverse design models by multimodal instructions capable of bridging the gap between ideas and execution, the academic research and industrial applications. We have provided baseline models, comprehensive experimental observations, and analysis to accelerate future research. Our baseline model is trained on an RTX 3090 GPU within 16 hours. The codebase, datasets and benchmarks will be available at …
Spotlight Poster
Bálint Mucsányi · Michael Kirchhof · Seong Joon Oh
[ West Ballroom A-D ]
Abstract
Uncertainty quantification, once a singular task, has evolved into a spectrum of tasks, including abstained prediction, out-of-distribution detection, and aleatoric uncertainty quantification. The latest goal is disentanglement: the construction of multiple estimators that are each tailored to one and only one source of uncertainty. This paper presents the first benchmark of uncertainty disentanglement. We reimplement and evaluate a comprehensive range of uncertainty estimators, from Bayesian over evidential to deterministic ones, across a diverse range of uncertainty tasks on ImageNet. We find that, despite recent theoretical endeavors, no existing approach provides pairs of disentangled uncertainty estimators in practice. We further find that specialized uncertainty tasks are harder than predictive uncertainty tasks, where we observe saturating performance. Our results provide both practical advice for which uncertainty estimators to use for which specific task, and reveal opportunities for future research toward task-centric and disentangled uncertainties. All our reimplementations and Weights & Biases logs are available at https://github.com/bmucsanyi/untangle.
Poster
Mingzhe Du · Anh Tuan Luu · Bin Ji · Qian Liu · See-Kiong Ng
[ West Ballroom A-D ]

Abstract
Amidst the recent strides in evaluating Large Language Models for Code (Code LLMs), existing benchmarks have mainly focused on the functional correctness of generated code, neglecting the importance of their computational efficiency. To fill the gap, we present Mercury, the first code efficiency benchmark for Code LLMs. It comprises 1,889 Python tasks, each accompanied by adequate solutions that serve as real-world efficiency baselines, enabling a comprehensive analysis of the runtime distribution. Based on the distribution, we introduce a new metric Beyond, which computes a runtime-percentile-weighted Pass score to reflect functional correctness and code efficiency simultaneously. On Mercury, leading Code LLMs can achieve 65% on Pass, while less than 50% on Beyond. Given that an ideal Beyond score would be aligned with the Pass score, it indicates that while Code LLMs exhibit impressive capabilities in generating functionally correct code, there remains a notable gap in their efficiency. Finally, our empirical experiments reveal that Direct Preference Optimization (DPO) serves as a robust baseline for enhancing code efficiency compared with Supervised Fine Tuning (SFT), which paves a promising avenue for future exploration of efficient code generation. Our code and data are available on GitHub: https://github.com/Elfsong/Mercury.
Poster
Tong Wu · Yinghao Xu · Ryan Po · Mengchen Zhang · Guandao Yang · Jiaqi Wang · Ziwei Liu · Dahua Lin · Gordon Wetzstein
[ East Exhibit Hall A-C ]

Abstract
Recent advances in text-to-image generation have enabled the creation of high-quality images with diverse applications. However, accurately describing desired visual attributes can be challenging, especially for non-experts in art and photography. An intuitive solution involves adopting favorable attributes from source images. Current methods attempt to distill identity and style from source images. However, "style" is a broad concept that includes texture, color, and artistic elements, but does not cover other important attributes like lighting and dynamics. Additionally, a simplified "style" adaptation prevents combining multiple attributes from different sources into one generated image. In this work, we formulate a more effective approach to decompose the aesthetics of a picture into specific visual attributes, letting users apply characteristics like lighting, texture, and dynamics from different images. To achieve this goal, we constructed the first fine-grained visual attributes dataset (FiVA) to the best of our knowledge. This FiVA dataset features a well-organized taxonomy for visual attributes and includes 1 M high-quality generated images with visual attribute annotations. Leveraging this dataset, we propose a fine-grained visual attributes adaptation framework (FiVA-Adapter) , which decouples and adapts visual attributes from one or more source images into a generated one. This approach enhances user-friendly customization, allowing users …
Poster
Hanna Yukhymenko · Robin Staab · Mark Vero · Martin Vechev
[ West Ballroom A-D ]
Abstract
Recently powerful Large Language Models (LLMs) have become easily accessible to hundreds of millions of users world-wide. However, their strong capabilities and vast world knowledge do not come without associated privacy risks. In this work, we focus on the emerging privacy threat LLMs pose – the ability to accurately infer personal information from online texts. Despite the growing importance of LLM-based author profiling, research in this area has been hampered by a lack of suitable public datasets, largely due to ethical and privacy concerns associated with real personal data. We take two steps to address this problem: (i) we construct a simulation framework for the popular social media platform Reddit using LLM agents seeded with synthetic personal profiles; (ii) using this framework, we generate *SynthPAI*, a diverse synthetic dataset of over 7800 comments manually labeled for personal attributes. We validate our dataset with a human study showing that humans barely outperform random guessing on the task of distinguishing our synthetic comments from real ones. Further, we verify that our dataset enables meaningful personal attribute inference research by showing across 18 state-of-the-art LLMs that our synthetic comments allow us to draw the same conclusions as real-world data. Combined, our experimental results, …
Poster
Paritosh Parmar · Eric Peh · Ruirui Chen · Ting En Lam · Yuhan Chen · Elston Tan · Basura Fernando
[ East Exhibit Hall A-C ]
Abstract
Causal video question answering (QA) has garnered increasing interest, yet existing datasets often lack depth in causal reasoning. To address this gap, we capitalize on the unique properties of cartoons and construct CausalChaos!, a novel, challenging causal Why-QA dataset built upon the iconic "Tom and Jerry" cartoon series. Cartoons use the principles of animation that allow animators to create expressive, unambiguous causal relationships between events to form a coherent storyline. Utilizing these properties, along with thought-provoking questions and multi-level answers (answer and detailed causal explanation), our questions involve causal chains that interconnect multiple dynamic interactions between characters and visual scenes. These factors demand models to solve more challenging, yet well-defined causal relationships. We also introduce hard incorrect answer mining, including a causally confusing version that is even more challenging. While models perform well, there is much room for improvement, especially, on open-ended answers. We identify more advanced/explicit causal relationship modeling \& joint modeling of vision and language as the immediate areas for future efforts to focus upon. Along with the other complementary datasets, our new challenging dataset will pave the way for these developments in the field. Dataset and Code: https://github.com/LUNAProject22/CausalChaos
Poster
Emily Jin · Zhuoyi Huang · Jan-Philipp Fraenken · Weiyu Liu · Hannah Cha · Erik Brockbank · Sarah Wu · Ruohan Zhang · Jiajun Wu · Tobias Gerstenberg
[ West Ballroom A-D ]
Abstract
Reconstructing past events requires reasoning across long time horizons. To figure out what happened, humans draw on prior knowledge about the world and human behavior and integrate insights from various sources of evidence including visual, language, and auditory cues. We introduce MARPLE, a benchmark for evaluating long-horizon inference capabilities using multi-modal evidence. Our benchmark features agents interacting with simulated households, supporting vision, language, and auditory stimuli, as well as procedurally generated environments and agent behaviors. Inspired by classic ``whodunit'' stories, we ask AI models and human participants to infer which agent caused a change in the environment based on a step-by-step replay of what actually happened. The goal is to correctly identify the culprit as early as possible. Our findings show that human participants outperform both traditional Monte Carlo simulation methods and an LLM baseline (GPT-4) on this task. Compared to humans, traditional inference models are less robust and performant, while GPT-4 has difficulty comprehending environmental changes. We analyze factors influencing inference performance and ablate different modes of evidence, finding that all modes are valuable for performance. Overall, our experiments demonstrate that the long-horizon, multimodal inference tasks in our benchmark present a challenge to current models. Project website: https://marple-benchmark.github.io/.
Poster
Yi Xin · Siqi Luo · Xuyang Liu · Yuntao Du. · Haodi Zhou · Xinyu Cheng · Christina Lee · Junlong Du · Haozhe Wang · MingCai Chen · Ting Liu · Guimin Hu · Zhongwei Wan · rongchao zhang · Aoxue Li · Mingyang Yi · Xiaohong Liu
[ East Exhibit Hall A-C ]

Abstract
Parameter-efficient transfer learning (PETL) methods show promise in adapting a pre-trained model to various downstream tasks while training only a few parameters. In the computer vision (CV) domain, numerous PETL algorithms have been proposed, but their direct employment or comparison remains inconvenient. To address this challenge, we construct a Unified Visual PETL Benchmark (V-PETL Bench) for the CV domain by selecting 30 diverse, challenging, and comprehensive datasets from image recognition, video action recognition, and dense prediction tasks. On these datasets, we systematically evaluate 25 dominant PETL algorithms and open-source a modular and extensible codebase for fair evaluation of these algorithms. V-PETL Bench runs on NVIDIA A800 GPUs and requires approximately 310 GPU days. We release all the benchmark, making it more efficient and friendly to researchers. Additionally, V-PETL Bench will be continuously updated for new PETL algorithms and CV tasks.
Poster
qi jia · baoyu · Cong Xu · Lu Liu · Liang Jin · Guoguang Du · Zhenhua Guo · Yaqian Zhao · Xuanjing Huang · Rengang Li
[ West Ballroom A-D ]
Abstract
Existing video multi-modal sentiment analysis mainly focuses on the sentiment expression of people within the video, yet often neglects the induced sentiment of viewers while watching the videos. Induced sentiment of viewers is essential for inferring the public response to videos and has broad application in analyzing public societal sentiment, effectiveness of advertising and other areas. The micro videos and the related comments provide a rich application scenario for viewers’ induced sentiment analysis. In light of this, we introduces a novel research task, Multimodal Sentiment Analysis for Comment Response of Video Induced(MSA-CRVI), aims to infer opinions and emotions according to comments response to micro video. Meanwhile, we manually annotate a dataset named Comment Sentiment toward to Micro Video (CSMV) to support this research. It is the largest video multi-modal sentiment dataset in terms of scale and video duration to our knowledge, containing 107, 267 comments and 8, 210 micro videos with a video duration of 68.83 hours. To infer the induced sentiment of comment should leverage the video content, we propose the Video Content-aware Comment Sentiment Analysis (VC-CSA) method as a baseline to address the challenges inherent in this new task. Extensive experiments demonstrate that our method is showing significant …
Poster
Xueqing Wu · Rui Zheng · Jingzhen Sha · Te-Lin Wu · Hanyu Zhou · Tang Mohan · Kai-Wei Chang · Nanyun Peng · Haoran Huang
[ West Ballroom A-D ]
Abstract
Data analysis is a crucial analytical process essential for deriving insights from real-world databases. As shown in Figure 1, the need for data analysis typically arises from specific application scenarios, and requires diverse reasoning skills including mathematical reasoning, logical reasoning, and strategic reasoning. Existing work often focus on simple factual retrieval or arithmetic resolutions and thus are insufficient for addressing complex real-world queries. This work aims to propose new resources and benchmarks on this crucial yet challenging and under-explored task. Due to the prohibitively high cost of collecting expert annotations, we use large language models (LLMs) enhanced by code generation to automatically generate high-quality data analysis, which will later be refined by human annotators. We construct the **DACO dataset**, containing (1) 440 databases (of tabular data) collected from real-world scenarios, (2) ~2k automatically generated query-answer pairs that can serve as weak supervision for model training, and (3) a concentrated but high-quality test set with human refined annotations that serves as our main evaluation benchmark. Experiments show that while LLMs like GPT-4 exhibit promising data analysis capabilities, they are still evaluated as less helpful than human-written analysis on 58.1% cases. Leveraging our weak supervision data, we experiment with various fine-tuning methods, …
Poster
Yujie Lu · Dongfu Jiang · Wenhu Chen · William Yang Wang · Yejin Choi · Bill Yuchen Lin
[ East Exhibit Hall A-C ]
Abstract
Recent breakthroughs in vision-language models (VLMs) emphasize the necessity of benchmarking human preferences in real-world multimodal interactions. To address this gap, we launched WildVision-Arena (WV-Arena), an online platform that collects human preferences to evaluate VLMs. We curated WV-Bench by selecting 500 high-quality samples from 8,000 user submissions in WV-Arena. WV-Bench uses GPT-4 as the judge to compare each VLM with Claude-3-Sonnet, achieving a Spearman correlation of 0.94 with the WV-Arena Elo. This significantly outperforms other benchmarks like MMVet, MMMU, and MMStar.Our comprehensive analysis of 20K real-world interactions reveals important insights into the failure cases of top-performing VLMs. For example, we find that although GPT-4V surpasses many other models like Reka-Flash, Opus, and Yi-VL-Plus in simple visual recognition and reasoning tasks, it still faces challenges with subtle contextual cues, spatial reasoning, visual imagination, and expert domain knowledge. Additionally, current VLMs exhibit issues with hallucinations and safety when intentionally provoked. We are releasing our chat and feedback data to further advance research in the field of VLMs.
Poster
Rawal Khirodkar · Jyun-Ting Song · Jinkun Cao · Zhengyi Luo · Kris Kitani
[ East Exhibit Hall A-C ]

Abstract
Understanding how humans interact with each other is key to building realistic multi-human virtual reality systems. This area remains relatively unexplored due to the lack of large-scale datasets. Recent datasets focusing on this issue mainly consist of activities captured entirely in controlled indoor environments with choreographed actions, significantly affecting their diversity. To address this, we introduce Harmony4D, a multi-view video dataset for human-human interaction featuring in-the-wild activities such as wrestling, dancing, MMA,and more. We use a flexible multi-view capture system to record these dynamic activities and provide annotations for human detection, tracking, 2D/3D pose estimation, and mesh recovery for closely interacting subjects. We propose a novel markerless algorithm to track 3D human poses in severe occlusion and close interaction to obtain our annotations with minimal manual intervention. Harmony4D consists of 1.66 million images and 3.32 million human instances from more than 20 synchronized cameras with 208 video sequences spanning diverse environments and 24 unique subjects. We rigorously evaluate existing state-of-the-art methods for mesh recovery and highlight their significant limitations in modeling close interaction scenarios. Additionally, we fine-tune a pre-trained HMR2.0 model on Harmony4D and demonstrate an improved performance of 54.8% PVE in scenes with severe occlusion and contact. “Harmony—a cohesive …
Spotlight Poster
Yohann PERRON · Vladyslav Sydorov · Adam P. Wijker · Damian Evans · Christophe Pottier · Loic Landrieu
[ West Ballroom A-D ]

Abstract
Airborne Laser Scanning (ALS) technology has transformed modern archaeology by unveiling hidden landscapes beneath dense vegetation. However, the lack of expert-annotated, open-access resources has hindered the analysis of ALS data using advanced deep learning techniques. We address this limitation with Archaeoscape (available at https://archaeoscape.ai/data/2024), a novel large-scale archaeological ALS dataset spanning 888 km² in Cambodia with 31,141 annotated archaeological features from the Angkorian period. Archaeoscape is over four times larger than comparable datasets, and the first ALS archaeology resource with open-access data, annotations, and models.We benchmark several recent segmentation models to demonstrate the benefits of modern vision techniques for this problem and highlight the unique challenges of discovering subtle human-made structures under dense jungle canopies. By making Archaeoscape available in open access, we hope to bridge the gap between traditional archaeology and modern computer vision methods.
Poster
Kenneth Enevoldsen · Márton Kardos · Niklas Muennighoff · Kristoffer Nielbo
[ West Ballroom A-D ]
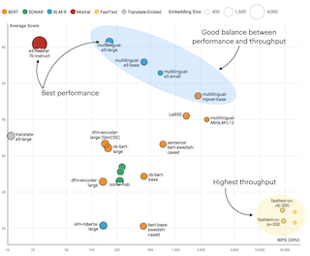
Abstract
The evaluation of English text embeddings has transitioned from evaluating a handful of datasets to broad coverage across many tasks through benchmarks such as MTEB. However, this is not the case for multilingual text embeddings due to a lack of available benchmarks. To address this problem, we introduce the Scandinavian Embedding Benchmark (SEB). SEB is a comprehensive framework that enables text embedding evaluation for Scandinavian languages across 24 tasks, 10 subtasks, and 4 task categories. Building on SEB, we evaluate more than 26 models, uncovering significant performance disparities between public and commercial solutions not previously captured by MTEB. We open-source SEB and integrate it with MTEB, thus bridging the text embedding evaluation gap for Scandinavian languages.
Poster
Fabian Gröger · Simone Lionetti · Philippe Gottfrois · Alvaro Gonzalez-Jimenez · Ludovic Amruthalingam · Matthew Groh · Alexander Navarini · Marc Pouly
[ East Exhibit Hall A-C ]

Abstract
Benchmark datasets in computer vision often contain off-topic images, near duplicates, and label errors, leading to inaccurate estimates of model performance.In this paper, we revisit the task of data cleaning and formalize it as either a ranking problem, which significantly reduces human inspection effort, or a scoring problem, which allows for automated decisions based on score distributions.We find that a specific combination of context-aware self-supervised representation learning and distance-based indicators is effective in finding issues without annotation biases.This methodology, which we call SelfClean, surpasses state-of-the-art performance in detecting off-topic images, near duplicates, and label errors within widely-used image datasets, such as ImageNet-1k, Food-101N, and STL-10, both for synthetic issues and real contamination.We apply the detailed method to multiple image benchmarks, identify up to 16% of issues, and confirm an improvement in evaluation reliability upon cleaning.The official implementation can be found at: https://github.com/Digital-Dermatology/SelfClean.
Poster
Zhao Xu · Fan LIU · Hao Liu
[ East Exhibit Hall A-C ]
Abstract
Although Large Language Models (LLMs) have demonstrated significant capabilities in executing complex tasks in a zero-shot manner, they are susceptible to jailbreak attacks and can be manipulated to produce harmful outputs. Recently, a growing body of research has categorized jailbreak attacks into token-level and prompt-level attacks. However, previous work primarily overlooks the diverse key factors of jailbreak attacks, with most studies concentrating on LLM vulnerabilities and lacking exploration of defense-enhanced LLMs. To address these issues, we introduced JailTrickBench to evaluate the impact of various attack settings on LLM performance and provide a baseline for jailbreak attacks, encouraging the adoption of a standardized evaluation framework. Specifically, we evaluate the eight key factors of implementing jailbreak attacks on LLMs from both target-level and attack-level perspectives. We further conduct seven representative jailbreak attacks on six defense methods across two widely used datasets, encompassing approximately 354 experiments with about 55,000 GPU hours on A800-80G. Our experimental results highlight the need for standardized benchmarking to evaluate these attacks on defense-enhanced LLMs. Our code is available at https://github.com/usail-hkust/JailTrickBench.
Poster
Sithursan Sivasubramaniam · Cedric E. Osei-Akoto · Yi Zhang · Kurt Stockinger · Jonathan Fuerst
[ West Ballroom A-D ]
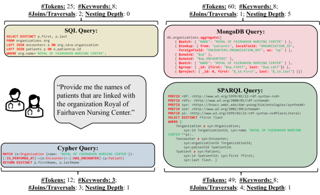
Abstract
Electronic health records (EHRs) are stored in various database systems with different database models on heterogeneous storage architectures, such as relational databases, document stores, or graph databases. These different database models have a big impact on query complexity and performance. While this has been a known fact in database research, its implications for the growing number of Text-to-Query systems have surprisingly not been investigated so far.In this paper, we present SM3-Text-to-Query, the first multi-model medical Text-to-Query benchmark based on synthetic patient data from Synthea, following the SNOMED-CT taxonomy---a widely used knowledge graph ontology covering medical terminology. SM3-Text-to-Query provides data representations for relational databases (PostgreSQL), document stores (MongoDB), and graph databases (Neo4j and GraphDB (RDF)), allowing the evaluation across four popular query languages, namely SQL, MQL, Cypher, and SPARQL.We systematically and manually develop 408 template questions, which we augment to construct a benchmark of 10K diverse natural language question/query pairs for these four query languages (40K pairs overall). On our dataset, we evaluate several common in-context-learning (ICL) approaches for a set of representative closed and open-source LLMs.Our evaluation sheds light on the trade-offs between database models and query languages for different ICL strategies and LLMs. Last,SM3-Text-to-Query is easily extendable to additional …
Poster
Felix Koehler · Simon Niedermayr · rüdiger westermann · Nils Thuerey
[ West Ballroom A-D ]
Abstract
We introduce the **A**utoregressive **P**DE **E**mulator Benchmark (APEBench), a comprehensive benchmark suite to evaluate autoregressive neural emulators for solving partial differential equations. APEBench is based on JAX and provides a seamlessly integrated differentiable simulation framework employing efficient pseudo-spectral methods, enabling 46 distinct PDEs across 1D, 2D, and 3D. Facilitating systematic analysis and comparison of learned emulators, we propose a novel taxonomy for unrolled training and introduce a unique identifier for PDE dynamics that directly relates to the stability criteria of classical numerical methods. APEBench enables the evaluation of diverse neural architectures, and unlike existing benchmarks, its tight integration of the solver enables support for differentiable physics training and neural-hybrid emulators. Moreover, APEBench emphasizes rollout metrics to understand temporal generalization, providing insights into the long-term behavior of emulating PDE dynamics. In several experiments, we highlight the similarities between neural emulators and numerical simulators. The code is available at [github.com/tum-pbs/apebench](https://github.com/tum-pbs/apebench) and APEBench can be installed via `pip install apebench`.
Poster
Kevin Wu · Eric Wu · James Zou
[ East Exhibit Hall A-C ]
Abstract
Retrieval augmented generation (RAG) is frequently used to mitigate hallucinations and provide up-to-date knowledge for large language models (LLMs). However, given that document retrieval is an imprecise task and sometimes results in erroneous or even harmful content being presented in context, this raises the question of how LLMs handle retrieved information: If the provided content is incorrect, does the model know to ignore it, or does it recapitulate the error? Conversely, when the model's initial response is incorrect, does it always know to use the retrieved information to correct itself, or does it insist on its wrong prior response? To answer this, we curate a dataset of over 1200 questions across six domains (e.g., drug dosages, Olympic records, locations) along with content relevant to answering each question. We further apply precise perturbations to the answers in the content that range from subtle to blatant errors.We benchmark six top-performing LLMs, including GPT-4o, on this dataset and find that LLMs are susceptible to adopting incorrect retrieved content, overriding their own correct prior knowledge over 60\% of the time. However, the more unrealistic the retrieved content is (i.e. more deviated from truth), the less likely the model is to adopt it. Also, the …
Spotlight Poster
Ruisheng Cao · Fangyu Lei · Haoyuan Wu · Jixuan Chen · Yeqiao Fu · Hongcheng Gao · Xinzhuang Xiong · Hanchong Zhang · Wenjing Hu · Yuchen Mao · Tianbao Xie · Hongshen Xu · Danyang Zhang · Sida Wang · Ruoxi Sun · Pengcheng Yin · Caiming Xiong · Ansong Ni · Qian Liu · Victor Zhong · Lu Chen · Kai Yu · Tao Yu
[ West Ballroom A-D ]
Abstract
Data science and engineering workflows often span multiple stages, from warehousing to orchestration, using tools like BigQuery, dbt, and Airbyte. As vision language models (VLMs) advance in multimodal understanding and code generation, VLM-based agents could potentially automate these workflows by generating SQL queries, Python code, and GUI operations. This automation can improve the productivity of experts while democratizing access to large-scale data analysis. In this paper, we introduce Spider2-V, the first multimodal agent benchmark focusing on professional data science and engineering workflows, featuring 494 real-world tasks in authentic computer environments and incorporating 20 enterprise-level professional applications. These tasks, derived from real-world use cases, evaluate the ability of a multimodal agent to perform data-related tasks by writing code and managing the GUI in enterprise data software systems. To balance realistic simulation with evaluation simplicity, we devote significant effort to developing automatic configurations for task setup and carefully crafting evaluation metrics for each task. Furthermore, we supplement multimodal agents with comprehensive documents of these enterprise data software systems. Our empirical evaluation reveals that existing state-of-the-art LLM/VLM-based agents do not reliably automate full data workflows (14.0% success). Even with step-by-step guidance, these agents still underperform in tasks that require fine-grained, knowledge-intensive GUI actions …
Poster
Pragya Singh · Ritvik Budhiraja · Ankush Gupta · Anshul Goswami · Mohan Kumar · Pushpendra Singh
[ East Exhibit Hall A-C ]
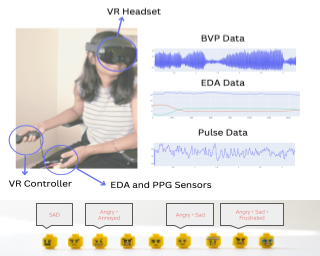
Abstract
EEVR (Emotion Elicitation in Virtual Reality) is a novel dataset specifically designed for language supervision-based pre-training of emotion recognition tasks, such as valence and arousal classification. It features high-quality physiological signals, including electrodermal activity (EDA) and photoplethysmography (PPG), acquired through emotion elicitation via 360-degree virtual reality (VR) videos.Additionally, it includes subject-wise textual descriptions of emotions experienced during each stimulus gathered from qualitative interviews. The dataset consists of recordings from 37 participants and is the first dataset to pair raw text with physiological signals, providing additional contextual information that objective labels cannot offer. To leverage this dataset, we introduced the Contrastive Language Signal Pre-training (CLSP) method, which jointly learns representations using pairs of physiological signals and textual descriptions. Our results show that integrating self-reported textual descriptions with physiological signals significantly improves performance on emotion recognition tasks, such as arousal and valence classification. Moreover, our pre-trained CLSP model demonstrates strong zero-shot transferability to existing datasets, outperforming supervised baseline models, suggesting that the representations learned by our method are more contextualized and generalized. The dataset also includes baseline models for arousal, valence, and emotion classification, as well as code for data cleaning and feature extraction. Further details and access to the dataset are …
Poster
R. Teal Witter · Christopher Musco
[ West Ballroom A-D ]
Abstract
Estimating the effect of treatments from natural experiments, where treatments are pre-assigned, is an important and well-studied problem. We introduce a novel natural experiment dataset obtained from an early childhood literacy nonprofit. Surprisingly, applying over 20 established estimators to the dataset produces inconsistent results in evaluating the nonprofits efficacy. To address this, we create a benchmark to evaluate estimator accuracy using synthetic outcomes, whose design was guided by domain experts. The benchmark extensively explores performance as real world conditions like sample size, treatment correlation, and propensity score accuracy vary. Based on our benchmark, we observe that the class of doubly robust treatment effect estimators, which are based on simple and intuitive regression adjustment, generally outperform other more complicated estimators by orders of magnitude. To better support our theoretical understanding of doubly robust estimators, we derive a closed form expression for the variance of any such estimator that uses dataset splitting to obtain an unbiased estimate. This expression motivates the design of a new doubly robust estimator that uses a novel loss function when fitting functions for regression adjustment. We release the dataset and benchmark in a Python package; the package is built in a modular way to facilitate new datasets …
Poster
Chang Liu · Xiwei Wu · Yuan Feng · Qinxiang Cao · Junchi Yan
[ West Ballroom A-D ]
Abstract
Program verification is vital for ensuring software reliability, especially in the context of increasingly complex systems. Loop invariants, remaining true before and after each iteration of loops, are crucial for this verification process. Traditional provers and machine learning based methods for generating loop invariants often require expert intervention or extensive labeled data, and typically only handle numerical property verification. These methods struggle with programs involving complex data structures and memory manipulations, limiting their applicability and automation capabilities. This paper introduces a new benchmark named LIG-MM, specifically for programs with complex data structures and memory manipulations. We collect 312 programs from various sources, including daily programs from college homework, the international competition (SV-COMP), benchmarks from previous papers (SLING), and programs from real-world software systems (Linux Kernel, GlibC, LiteOS, and Zephyr). Based on LIG-MM, our findings indicate that previous methods, including GPT-4, fail to automate verification for these programs. Consequently, we propose a novel LLM-SE framework that coordinates LLM with symbolic execution, fine-tuned using self-supervised learning, to generate loop invariants. Experimental results on LIG-MM demonstrate that our LLM-SE outperforms state-of-the-art methods, offering a new direction toward automated program verification in real-world scenarios.
Poster
Weihua Du · Qiushi Lyu · Jiaming Shan · Zhenting Qi · Hongxin Zhang · Sunli Chen · Andi Peng · Tianmin Shu · Kwonjoon Lee · Behzad Dariush · Chuang Gan
[ West Ballroom A-D ]
Abstract
We introduce Constrained Human-AI Cooperation (CHAIC), an inclusive embodied social intelligence challenge designed to test social perception and cooperation in embodied agents. In CHAIC, the goal is for an embodied agent equipped with egocentric observations to assist a human who may be operating under physical constraints—e.g., unable to reach high places or confined to a wheelchair—in performing common household or outdoor tasks as efficiently as possible. To achieve this, a successful helper must: (1) infer the human's intents and constraints by following the human and observing their behaviors (social perception), and (2) make a cooperative plan tailored to the human partner to solve the task as quickly as possible, working together as a team (cooperative planning). To benchmark this challenge, we create four new agents with real physical constraints and eight long-horizon tasks featuring both indoor and outdoor scenes with various constraints, emergency events, and potential risks. We benchmark planning- and learning-based baselines on the challenge and introduce a new method that leverages large language models and behavior modeling. Empirical evaluations demonstrate the effectiveness of our benchmark in enabling systematic assessment of key aspects of machine social intelligence. Our benchmark and code are publicly available at https://github.com/UMass-Foundation-Model/CHAIC.
Spotlight Poster
Kevin Qinghong Lin · Linjie Li · Difei Gao · Qinchen WU · Mingyi Yan · Zhengyuan Yang · Lijuan Wang · Mike Zheng Shou
[ East Exhibit Hall A-C ]

Abstract
Graphical User Interface (GUI) automation holds significant promise for enhancing human productivity by assisting with computer tasks. Existing task formulations primarily focus on simple tasks that can be specified by a single, language-only instruction, such as “Insert a new slide.” In this work, we introduce VideoGUI, a novel multi-modal benchmark designed to evaluate GUI assistants on visual-centric GUI tasks. Sourced from high-quality web instructional videos, our benchmark focuses on tasks involving professional and novel software (e.g., Adobe Pho- toshop or Stable Diffusion WebUI) and complex activities (e.g., video editing). VideoGUI evaluates GUI assistants through a hierarchical process, allowing for identification of the specific levels at which they may fail: (i) high-level planning: reconstruct procedural subtasks from visual conditions without language descrip- tions; (ii) middle-level planning: generate sequences of precise action narrations based on visual state (i.e., screenshot) and goals; (iii) atomic action execution: perform specific actions such as accurately clicking designated elements. For each level, we design evaluation metrics across individual dimensions to provide clear signals, such as individual performance in clicking, dragging, typing, and scrolling for atomic action execution. Our evaluation on VideoGUI reveals that even the SoTA large multimodal model GPT4o performs poorly on visual-centric GUI tasks, especially …
Poster
Xin Li · Weize Chen · Qizhi Chu · Haopeng Li · Zhaojun Sun · Ran Li · Chen Qian · Yiwei Wei · Chuan Shi · Zhiyuan Liu · Maosong Sun · Cheng Yang
[ East Exhibit Hall A-C ]
Abstract
The need to analyze graphs is ubiquitous across various fields, from social networks to biological research and recommendation systems. Therefore, enabling the ability of large language models (LLMs) to process graphs is an important step toward more advanced general intelligence. However, current LLM benchmarks on graph analysis require models to directly reason over the prompts describing graphtopology, and are thus limited to small graphs with only a few dozens of nodes. In contrast, human experts typically write programs based on popular libraries for task solving, and can thus handle graphs with different scales. To this end, a question naturally arises: can LLMs analyze graphs like professionals? In this paper, we introduce ProGraph, a manually crafted benchmark containing 3 categories of graph tasks. The benchmark expects solutions based on programming instead of directly reasoning over raw inputs. Our findings reveal that the performance of current LLMs is unsatisfactory, with the best model achieving only 36% accuracy. To bridge this gap, we propose LLM4Graph datasets, which include crawled documents and auto-generated codes based on 6 widely used graph libraries. By augmenting closed-source LLMs with document retrieval and fine-tuning open-source ones on the codes, we show 11-32% absolute improvements in their accuracies. Our …
Poster
Michael Wornow · Avanika Narayan · Ben Viggiano · Ishan Khare · Tathagat Verma · Tibor Thompson · Miguel Hernandez · Sudharsan Sundar · Chloe Trujillo · Krrish Chawla · Rongfei Lu · Justin Shen · Divya Nagaraj · Joshua Martinez · Vardhan Agrawal · Althea Hudson · Nigam Shah · Christopher Ré
[ West Ballroom A-D ]
Abstract
Existing ML benchmarks lack the depth and diversity of annotations needed for evaluating models on business process management (BPM) tasks. BPM is the practice of documenting, measuring, improving, and automating enterprise workflows. However, research has focused almost exclusively on one task -- full end-to-end automation using agents based on multimodal foundation models (FMs) like GPT-4. This focus on automation ignores the reality of how most BPM tools are applied today -- simply documenting the relevant workflow takes 60% of the time of the typical process optimization project. To address this gap we present WONDERBREAD, the first benchmark for evaluating multimodal FMs on BPM tasks beyond automation. Our contributions are: (1) a dataset containing 2928 documented workflow demonstrations; (2) 6 novel BPM tasks sourced from real-world applications ranging from workflow documentation to knowledge transfer to process improvement; and (3) an automated evaluation harness. Our benchmark shows that while state-of-the-art FMs can automatically generate documentation (e.g. recalling 88% of the steps taken in a video demonstration of a workflow), they struggle to re-apply that knowledge towards finer-grained validation of workflow completion (F1 < 0.3). We hope WONDERBREAD encourages the development of more "human-centered" AI tooling for enterprise applications and furthers the exploration of …
Poster
Yinghui Li · Qingyu Zhou · Yuanzhen Luo · Shirong Ma · Yangning Li · Hai-Tao Zheng · Xuming Hu · Philip S Yu
[ West Ballroom A-D ]

Abstract
Recently, Large Language Models (LLMs) make remarkable evolutions in language understanding and generation. Following this, various benchmarks for measuring all kinds of capabilities of LLMs have sprung up. In this paper, we challenge the reasoning and understanding abilities of LLMs by proposing a FaLlacy Understanding Benchmark (FLUB) containing cunning texts that are easy for humans to understand but difficult for models to grasp. Specifically, the cunning texts that FLUB focuses on mainly consist of the tricky, humorous, and misleading texts collected from the real internet environment. And we design three tasks with increasing difficulty in the FLUB benchmark to evaluate the fallacy understanding ability of LLMs. Based on FLUB, we investigate the performance of multiple representative and advanced LLMs, reflecting our FLUB is challenging and worthy of more future study. Interesting discoveries and valuable insights are achieved in our extensive experiments and detailed analyses. We hope that our benchmark can encourage the community to improve LLMs' ability to understand fallacies. Our data and codes are available at https://github.com/THUKElab/FLUB.
Poster
Yijia Shao · Tianshi Li · Weiyan Shi · Yanchen Liu · Diyi Yang
[ West Ballroom A-D ]
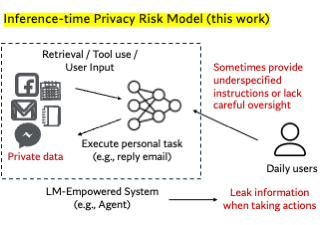
Abstract
As language models (LMs) are widely utilized in personalized communication scenarios (e.g., sending emails, writing social media posts) and endowed with a certain level of agency, ensuring they act in accordance with the contextual privacy norms becomes increasingly critical. However, quantifying the privacy norm awareness of LMs and the emerging privacy risk in LM-mediated communication is challenging due to (1) the contextual and long-tailed nature of privacy-sensitive cases, and (2) the lack of evaluation approaches that capture realistic application scenarios. To address these challenges, we propose PrivacyLens, a novel framework designed to extend privacy-sensitive seeds into expressive vignettes and further into agent trajectories, enabling multi-level evaluation of privacy leakage in LM agents' actions. We instantiate PrivacyLens with a collection of privacy norms grounded in privacy literature and crowdsourced seeds. Using this dataset, we reveal a discrepancy between LM performance in answering probing questions and their actual behavior when executing user instructions in an agent setup. State-of-the-art LMs, like GPT-4 and Llama-3-70B, leak sensitive information in 25.68% and 38.69% of cases, even when prompted with privacy-enhancing instructions. We also demonstrate the dynamic nature of PrivacyLens by extending each seed into multiple trajectories to red-team LM privacy leakage risk. Dataset and code …
Poster
Hoonhee Cho · Taewoo Kim · Yuhwan Jeong · Kuk-Jin Yoon
[ East Exhibit Hall A-C ]

Abstract
Multi-person pose estimation and tracking have been actively researched by the computer vision community due to their practical applicability. However, existing human pose estimation and tracking datasets have only been successful in typical scenarios, such as those without motion blur or with well-lit conditions. These RGB-based datasets are limited to learning under extreme motion blur situations or poor lighting conditions, making them inherently vulnerable to such scenarios.As a promising solution, bio-inspired event cameras exhibit robustness in extreme scenarios due to their high dynamic range and micro-second level temporal resolution. Therefore, in this paper, we introduce a new hybrid dataset encompassing both RGB and event data for human pose estimation and tracking in two extreme scenarios: low-light and motion blur environments. The proposed Event-guided Human Pose Estimation and Tracking in eXtreme Conditions (EHPT-XC) dataset covers cases of motion blur caused by dynamic objects and low-light conditions individually as well as both simultaneously. With EHPT-XC, we aim to inspire researchers to tackle pose estimation and tracking in extreme conditions by leveraging the advantageous of the event camera. Project pages are available at https://github.com/Chohoonhee/EHPT-XC.
Poster
Zhenzhi Wang · Yixuan Li · Yanhong Zeng · Youqing Fang · Yuwei Guo · Wenran Liu · Jing Tan · Kai Chen · Tianfan Xue · Bo Dai · Dahua Lin
[ East Exhibit Hall A-C ]
Abstract
Human image animation involves generating videos from a character photo, allowing user control and unlocking the potential for video and movie production. While recent approaches yield impressive results using high-quality training data, the inaccessibility of these datasets hampers fair and transparent benchmarking. Moreover, these approaches prioritize 2D human motion and overlook the significance of camera motions in videos, leading to limited control and unstable video generation. To demystify the training data, we present HumanVid, the first large-scale high-quality dataset tailored for human image animation, which combines crafted real-world and synthetic data. For the real-world data, we compile a vast collection of real-world videos from the internet. We developed and applied careful filtering rules to ensure video quality, resulting in a curated collection of 20K high-resolution (1080P) human-centric videos. Human and camera motion annotation is accomplished using a 2D pose estimator and a SLAM-based method. To expand our synthetic dataset, we collected 10K 3D avatar assets and leveraged existing assets of body shapes, skin textures and clothings. Notably, we introduce a rule-based camera trajectory generation method, enabling the synthetic pipeline to incorporate diverse and precise camera motion annotation, which can rarely be found in real-world data. To verify the effectiveness of …
Spotlight Poster
Talfan Evans · Nikhil Parthasarathy · Hamza Merzic · Olivier Henaff
[ East Exhibit Hall A-C ]
Abstract
Data curation is an essential component of large-scale pretraining. In this work, we demonstrate that jointly prioritizing batches of data is more effective for learning than selecting examples independently. Multimodal contrastive objectives expose the dependencies between data and thus naturally yield criteria for measuring the joint learnability of a batch. We derive a simple and tractable algorithm for selecting such batches, which significantly accelerate training beyond individually-prioritized data points. As performance improves by selecting from large super-batches, we also leverage recent advances in model approximation to reduce the computational overhead of scoring. As a result, our approach—multimodal contrastive learning with joint example selection (JEST)—surpasses state-of-the-art pretraining methods with up to 13× fewer iterations and 10× less computation. Essential to the performance of JEST is the ability to steer the data selection process towards the distribution of smaller, well-curated datasets via pretrained reference models, exposing data curation as a new dimension for neural scaling laws.
Poster
Anirudh Sundar · Jin Xu · William Gay · Christopher Richardson · Larry Heck
[ West Ballroom A-D ]

Abstract
An emerging area of research in situated and multimodal interactive conversations (SIMMC) includes interactions in scientific papers. Since scientific papers are primarily composed of text, equations, figures, and tables, SIMMC methods must be developed specifically for each component to support the depth of inquiry and interactions required by research scientists. This work introduces $Conversational Papers$ (cPAPERS), a dataset of conversational question-answer pairs from reviews of academic papers grounded in these paper components and their associated references from scientific documents available on arXiv. We present a data collection strategy to collect these question-answer pairs from OpenReview and associate them with contextual information from $LaTeX$ source files. Additionally, we present a series of baseline approaches utilizing Large Language Models (LLMs) in both zero-shot and fine-tuned configurations to address the cPAPERS dataset.
Spotlight Poster
Heng Li · Minghan Li · Zhi-Qi Cheng · Yifei Dong · Yuxuan Zhou · Jun-Yan He · Qi Dai · Teruko Mitamura · Alexander Hauptmann
[ East Exhibit Hall A-C ]

Abstract
Vision-and-Language Navigation (VLN) aims to develop embodied agents that navigate based on human instructions. However, current VLN frameworks often rely on static environments and optimal expert supervision, limiting their real-world applicability. To address this, we introduce Human-Aware Vision-and-Language Navigation (HA-VLN), extending traditional VLN by incorporating dynamic human activities and relaxing key assumptions. We propose the Human-Aware 3D (HA3D) simulator, which combines dynamic human activities with the Matterport3D dataset, and the Human-Aware Room-to-Room (HA-R2R) dataset, extending R2R with human activity descriptions. To tackle HA-VLN challenges, we present the Expert-Supervised Cross-Modal (VLN-CM) and Non-Expert-Supervised Decision Transformer (VLN-DT) agents, utilizing cross-modal fusion and diverse training strategies for effective navigation in dynamic human environments. A comprehensive evaluation, including metrics considering human activities, and systematic analysis of HA-VLN's unique challenges, underscores the need for further research to enhance HA-VLN agents' real-world robustness and adaptability. Ultimately, this work provides benchmarks and insights for future research on embodied AI and Sim2Real transfer, paving the way for more realistic and applicable VLN systems in human-populated environments.
Poster
David Schneider · Simon Reiß · Marco Kugler · Alexander Jaus · Kunyu Peng · Susanne Sutschet · M. Saquib Sarfraz · Sven Matthiesen · Rainer Stiefelhagen
[ West Ballroom A-D ]
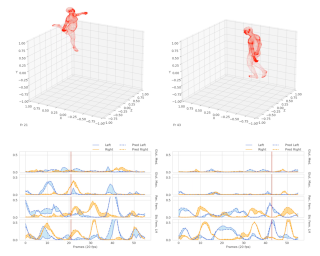
Abstract
Exploring the intricate dynamics between muscular and skeletal structures is pivotal for understanding human motion. This domain presents substantial challenges, primarily attributed to the intensive resources required for acquiring ground truth muscle activation data, resulting in a scarcity of datasets.In this work, we address this issue by establishing Muscles in Time (MinT), a large-scale synthetic muscle activation dataset.For the creation of MinT, we enriched existing motion capture datasets by incorporating muscle activation simulations derived from biomechanical human body models using the OpenSim platform, a common framework used in biomechanics and human motion research.Starting from simple pose sequences, our pipeline enables us to extract detailed information about the timing of muscle activations within the human musculoskeletal system.Muscles in Time contains over nine hours of simulation data covering 227 subjects and 402 simulated muscle strands. We demonstrate the utility of this dataset by presenting results on neural network-based muscle activation estimation from human pose sequences with two different sequence-to-sequence architectures.
Poster
Nitzan Bitton Guetta · Aviv Slobodkin · Aviya Maimon · Eliya Habba · Royi Rassin · Yonatan Bitton · Idan Szpektor · Amir Globerson · Yuval Elovici
[ East Exhibit Hall A-C ]

Abstract
Imagine observing someone scratching their arm; to understand why, additional context would be necessary. However, spotting a mosquito nearby would immediately offer a likely explanation for the person’s discomfort, thereby alleviating the need for further information. This example illustrates how subtle visual cues can challenge our cognitive skills and demonstrates the complexity of interpreting visual scenarios. To study these skills, we present Visual Riddles, a benchmark aimed to test vision and language models on visual riddles requiring commonsense and world knowledge. The benchmark comprises 400 visual riddles, each featuring a unique image created by a variety of text-to-image models, question, ground-truth answer, textual hint, and attribution. Human evaluation reveals that existing models lag significantly behind human performance, which is at 82% accuracy, with Gemini-Pro-1.5 leading with 40% accuracy. Our benchmark comes with automatic evaluation tasks to make assessment scalable. These findings underscore the potential of Visual Riddles as a valuable resource for enhancing vision and language models’ capabilities in interpreting complex visual scenarios. Data, code, and leaderboard are available at https://visual-riddles.github.io/.
Poster
Josh Veitch-Michaelis · Andrew Cottam · Daniella Schweizer · Eben Broadbent · David Dao · Ce Zhang · Angelica Almeyda Zambrano · Simeon Max
[ West Ballroom A-D ]

Abstract
Accurately quantifying tree cover is an important metric for ecosystem monitoring and for assessing progress in restored sites. Recent works have shown that deep learning-based segmentation algorithms are capable of accurately mapping trees at country and continental scales using high-resolution aerial and satellite imagery. Mapping at high (ideally sub-meter) resolution is necessary to identify individual trees, however there are few open-access datasets containing instance level annotations and those that exist are small or not geographically diverse. We present a novel open-access dataset for individual tree crown delineation (TCD) in high-resolution aerial imagery sourced from OpenAerialMap (OAM). Our dataset, OAM-TCD, comprises 5072 2048x2048 px images at 10 cm/px resolution with associated human-labeled instance masks for over 280k individual and 56k groups of trees. By sampling imagery from around the world, we are able to better capture the diversity and morphology of trees in different terrestrial biomes and in both urban and natural environments. Using our dataset, we train reference instance and semantic segmentation models that compare favorably to existing state-of-the-art models. We assess performance through k-fold cross-validation and comparison with existing datasets; additionally we demonstrate compelling results on independent aerial imagery captured over Switzerland and compare to municipal tree inventories and …
Poster
Matthew Zheng · Enis Simsar · Hidir Yesiltepe · Federico Tombari · Joel Simon · Pinar Yanardag Delul
[ West Ballroom A-D ]
Abstract
Text-to-image models are becoming increasingly popular, revolutionizing the landscape of digital art creation by enabling highly detailed and creative visual content generation. These models have been widely employed across various domains, particularly in art generation, where they facilitate a broad spectrum of creative expression and democratize access to artistic creation. In this paper, we introduce STYLEBREEDER, a comprehensive dataset of 6.8M images and 1.8M prompts generated by 95K users on Artbreeder, a platform that has emerged as a significant hub for creative exploration with over 13M users. We introduce a series of tasks with this dataset aimed at identifying diverse artistic styles, generating personalized content, and recommending styles based on user interests. By documenting unique, user-generated styles that transcend conventional categories like 'cyberpunk' or 'Picasso,' we explore the potential for unique, crowd-sourced styles that could provide deep insights into the collective creative psyche of users worldwide. We also evaluate different personalization methods to enhance artistic expression and introduce a style atlas, making these models available in LoRA format for public use. Our research demonstrates the potential of text-to-image diffusion models to uncover and promote unique artistic expressions, further democratizing AI in art and fostering a more diverse and inclusive artistic …
Poster
Brianna Karpowicz · Joel Ye · Chaofei Fan · Pablo Tostado-Marcos · Fabio Rizzoglio · Clayton Washington · Thiago Scodeler · Diogo de Lucena · Samuel Nason-Tomaszewski · Matthew Mender · Xuan Ma · Ezequiel Arneodo · Leigh Hochberg · Cynthia Chestek · Jaimie Henderson · Timothy Gentner · Vikash Gilja · Lee Miller · Adam Rouse · Robert Gaunt · Jennifer Collinger · Chethan Pandarinath
[ West Ballroom A-D ]
Abstract
Intracortical brain-computer interfaces (iBCIs) can restore movement and communication abilities to individuals with paralysis by decoding their intended behavior from neural activity recorded with an implanted device. While this activity yields high-performance decoding over short timescales, neural data is often nonstationary, which can lead to decoder failure if not accounted for. To maintain performance, users must frequently recalibrate decoders, which requires the arduous collection of new neural and behavioral data. Aiming to reduce this burden, several approaches have been developed that either limit recalibration data requirements (few-shot approaches) or eliminate explicit recalibration entirely (zero-shot approaches). However, progress is limited by a lack of standardized datasets and comparison metrics, causing methods to be compared in an ad hoc manner. Here we introduce the FALCON benchmark suite (Few-shot Algorithms for COnsistent Neural decoding) to standardize evaluation of iBCI robustness. FALCON curates five datasets of neural and behavioral data that span movement and communication tasks to focus on behaviors of interest to modern-day iBCIs. Each dataset includes calibration data, optional few-shot recalibration data, and private evaluation data. We implement a flexible evaluation platform which only requires user-submitted code to return behavioral predictions on unseen data. We also seed the benchmark by applying baseline …
Poster
Skanda Koppula · Ignacio Rocco · Yi Yang · joseph heyward · Joao Carreira · Andrew Zisserman · Gabriel Brostow · Carl Doersch
[ East Exhibit Hall A-C ]

Abstract
We introduce a new benchmark, TAPVid-3D, for evaluating the task of long-range Tracking Any Point in 3D (TAP-3D). While point tracking in two dimensions (TAP-2D) has many benchmarks measuring performance on real-world videos, such as TAPVid-DAVIS, three-dimensional point tracking has none. To this end, leveraging existing footage, we build a new benchmark for 3D point tracking featuring 4,000+ real-world videos, composed of three different data sources spanning a variety of object types, motion patterns, and indoor and outdoor environments. To measure performance on the TAP-3D task, we formulate a collection of metrics that extend the Jaccard-based metric used in TAP-2D to handle the complexities of ambiguous depth scales across models, occlusions, and multi-track spatio-temporal smoothness. We manually verify a large sample of trajectories to ensure correct video annotations, and assess the current state of the TAP-3D task by constructing competitive baselines using existing tracking models. We anticipate this benchmark will serve as a guidepost to improve our ability to understand precise 3D motion and surface deformation from monocular video.
Poster
Yongliang Shen · Kaitao Song · Xu Tan · Wenqi Zhang · Kan Ren · Siyu Yuan · Weiming Lu · Dongsheng Li · Yueting Zhuang
[ West Ballroom A-D ]

Abstract
In recent years, the remarkable progress of large language models (LLMs) has sparked interest in task automation, which involves decomposing complex tasks described by user instructions into sub-tasks and invoking external tools to execute them, playing a central role in autonomous agents. However, there is a lack of systematic and standardized benchmarks to promote the development of LLMs in task automation. To address this, we introduce TaskBench, a comprehensive framework to evaluate the capability of LLMs in task automation. Specifically, task automation can be divided into three critical stages: task decomposition, tool selection, and parameter prediction. To tackle the complexities inherent in these stages, we introduce the concept of Tool Graph to represent decomposed tasks and adopt a back-instruct method to generate high-quality user instructions. We propose TaskEval, a multi-faceted evaluation methodology that assesses LLM performance across these three stages. Our approach combines automated construction with rigorous human verification, ensuring high consistency with human evaluation. Experimental results demonstrate that TaskBench effectively reflects the capabilities of various LLMs in task automation. It provides insights into model performance across different task complexities and domains, pushing the boundaries of what current models can achieve. TaskBench offers a scalable, adaptable, and reliable benchmark for …
Poster
Ruben Ohana · Michael McCabe · Lucas Meyer · Rudy Morel · Fruzsina Agocs · Miguel Beneitez · Marsha Berger · Blakesly Burkhart · Stuart Dalziel · Drummond Fielding · Daniel Fortunato · Jared Goldberg · Keiya Hirashima · Yan-Fei Jiang · Rich Kerswell · Suryanarayana Maddu · Jonah Miller · Payel Mukhopadhyay · Stefan Nixon · Jeff Shen · Romain Watteaux · Bruno Régaldo-Saint Blancard · François Rozet · Liam Parker · Miles Cranmer · Shirley Ho
[ West Ballroom A-D ]
Abstract
Machine learning based surrogate models offer researchers powerful tools for accelerating simulation-based workflows. However, as standard datasets in this space often cover small classes of physical behavior, it can be difficult to evaluate the efficacy of new approaches. To address this gap, we introduce the Well: a large-scale collection of datasets containing numerical simulations of a wide variety of spatiotemporal physical systems. The Well draws from domain experts and numerical software developers to provide 15TB of data across 16 datasets covering diverse domains such as biological systems, fluid dynamics, acoustic scattering, as well as magneto-hydrodynamic simulations of extra-galactic fluids or supernova explosions. These datasets can be used individually or as part of a broader benchmark suite. To facilitate usage of the Well, we provide a unified PyTorch interface for training and evaluating models. We demonstrate the function of this library by introducing example baselines that highlight the new challenges posed by the complex dynamics of the Well. The code and data is available at https://github.com/PolymathicAI/the_well.
Poster
Yejin Choi · Jiwan Chung · Sumin Shim · Giyeong Oh · Youngjae Yu
[ East Exhibit Hall A-C ]
Abstract
Visual text design plays a critical role in conveying themes, emotions, and atmospheres in multimodal formats such as film posters and album covers. Translating these visual and textual elements across languages extends the concept of translation beyond mere text, requiring the adaptation of aesthetic and stylistic features. To address this, we introduce a novel task of Multimodal Style Translation (MuST-Bench), a benchmark designed to evaluate the ability of visual text generation models to perform translation across different writing systems while preserving design intent.Our initial experiments on MuST-Bench reveal that existing visual text generation models struggle with the proposed task due to the inadequacy of textual descriptions in conveying visual design.In response, we introduce SIGIL, a framework for multimodal style translation that eliminates the need for style descriptions.SIGIL enhances image generation models through three innovations: glyph latent for multilingual settings, pre-trained VAEs for stable style guidance, and an OCR model with reinforcement learning feedback for optimizing readable character generation. SIGIL outperforms existing baselines by achieving superior style consistency and legibility while maintaining visual fidelity, setting itself apart from traditional description-based approaches. We release MuST-Bench publicly for broader use and exploration https://huggingface.co/datasets/yejinc/MuST-Bench.
Spotlight Poster
Junlin Xie · Ruifei Zhang · Zhihong Chen · Xiang Wan · Guanbin Li
[ West Ballroom A-D ]
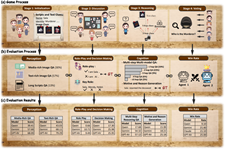
Abstract
Recently, large language models (LLMs) have achieved superior performance, empowering the development of large multimodal agents (LMAs). An LMA is anticipated to execute practical tasks requires various capabilities including multimodal perception, interaction, reasoning, and decision making. However, existing benchmarks are limited in assessing compositional skills and actions demanded by practical scenarios, where they primarily focused on single tasks and static scenarios. To bridge this gap, we introduce WhodunitBench, a benchmark rooted from murder mystery games, where players are required to utilize the aforementioned skills to achieve their objective (i.e., identifying the `murderer' or hiding themselves), providing a simulated dynamic environment for evaluating LMAs. Specifically, WhodunitBench includes two evaluation modes. The first mode, the arena-style evaluation, is constructed from 50 meticulously curated scripts featuring clear reasoning clues and distinct murderers; The second mode, the chain of evaluation, consists of over 3000 curated multiple-choice questions and open-ended questions, aiming to assess every facet of the murder mystery games for LMAs. Experiments show that although current LMAs show acceptable performance in basic perceptual tasks, they are insufficiently equipped for complex multi-agent collaboration and multi-step reasoning tasks. Furthermore, the full application of the theory of mind to complete games in a manner akin to …
Poster
Amir Hossein Kargaran · François Yvon · Hinrich Schuetze
[ East Exhibit Hall A-C ]

Abstract
The need for large text corpora has increased with the advent of pretrained language models and, in particular, the discovery of scaling laws for these models. Most available corpora have sufficient data only for languages with large dominant communities. However, there is no corpus available that (i) covers a wide range of minority languages; (ii) is generated by an open-source reproducible pipeline; and (iii) is rigorously cleaned from noise, making it trustworthy to use. We present GlotCC, a clean, document-level, 2TB general domain corpus derived from CommonCrawl, covering more than 1000 languages. We make GlotCC and the system used to generate it— including the pipeline, language identification model, and filters—available to the research community.Corpus v. 1.0 https://huggingface.co/datasets/cis-lmu/GlotCC-v1Pipeline v. 3.0 https://github.com/cisnlp/GlotCC
Poster
Aoran Wang · Tsz Pan Tong · Andrzej Mizera · Jun Pang
[ West Ballroom A-D ]

Abstract
Understanding complex dynamical systems begins with identifying their topological structures, which expose the organization of the systems. This requires robust structural inference methods that can deduce structure from observed behavior. However, existing methods are often domain-specific and lack a standardized, objective comparison framework. We address this gap by benchmarking 13 structural inference methods from various disciplines on simulations representing two types of dynamics and 11 interaction graph models, supplemented by a biological experimental dataset to mirror real-world application. We evaluated the methods for accuracy, scalability, robustness, and sensitivity to graph properties. Our findings indicate that deep learning methods excel with multi-dimensional data, while classical statistics and information theory based approaches are notably accurate and robust. Additionally, performance correlates positively with the graph's average shortest path length. This benchmark should aid researchers in selecting suitable methods for their specific needs and stimulate further methodological innovation.
Spotlight Poster
Ike Obi · Rohan Pant · Srishti Shekhar Agrawal · Maham Ghazanfar · Aaron Basiletti
[ West Ballroom A-D ]
Abstract
LLMs are increasingly fine-tuned using RLHF datasets to align them with human preferences and values. However, very limited research has investigated which specific human values are operationalized through these datasets. In this paper, we introduce Value Imprint, a framework for auditing and classifying the human values embedded within RLHF datasets. To investigate the viability of this framework, we conducted three case study experiments by auditing the Anthropic/hh-rlhf, OpenAI WebGPT Comparisons, and Alpaca GPT-4-LLM datasets to examine the human values embedded within them. Our analysis involved a two-phase process. During the first phase, we developed a taxonomy of human values through an integrated review of prior works from philosophy, axiology, and ethics. Then, we applied this taxonomy to annotate 6,501 RLHF preferences. During the second phase, we employed the labels generated from the annotation as ground truth data for training a transformer-based machine learning model to audit and classify the three RLHF datasets. Through this approach, we discovered that information-utility values, including Wisdom/Knowledge and Information Seeking, were the most dominant human values within all three RLHF datasets. In contrast, prosocial and democratic values, including Well-being, Justice, and Human/Animal Rights, were the least represented human values. These findings have significant implications for …
Poster
Jake Fawkes · Nic Fishman · Mel Andrews · Zachary Lipton
[ West Ballroom A-D ]
Abstract
Fairness metrics are a core tool in the fair machine learning literature (FairML),used to determine that ML models are, in some sense, “fair.” Real-world data,however, are typically plagued by various measurement biases and other violatedassumptions, which can render fairness assessments meaningless. We adapt toolsfrom causal sensitivity analysis to the FairML context, providing a general frame-work which (1) accommodates effectively any combination of fairness metric andbias that can be posed in the “oblivious setting”; (2) allows researchers to inves-tigate combinations of biases, resulting in non-linear sensitivity; and (3) enablesflexible encoding of domain-specific constraints and assumptions. Employing thisframework, we analyze the sensitivity of the most common parity metrics under 3varieties of classifier across 14 canonical fairness datasets. Our analysis reveals thestriking fragility of fairness assessments to even minor dataset biases. We show thatcausal sensitivity analysis provides a powerful and necessary toolkit for gaugingthe informativeness of parity metric evaluations. Our repository is \href{https://github.com/Jakefawkes/fragile_fair}{available here}.
Poster
Pavan Kalyan Tankala · Piyush Pasi · Sahil Dharod · Azeem Motiwala · Preethi Jyothi · Aditi Chaudhary · Krishna Srinivasan
[ West Ballroom A-D ]
Abstract
Cross-modal (image-to-text and text-to-image) retrieval is an established task used in evaluation benchmarks to test the performance of vision-language models (VLMs). Several state-of-the-art VLMs (e.g. CLIP, BLIP-2) have achieved near-perfect performance on widely-used image-text retrieval benchmarks such as MSCOCO-Test-5K and Flickr30K-Test-1K. As a measure of out-of-distribution (OOD) generalization, prior works rely on zero-shot performance evaluated on one dataset (Flickr) using a VLM finetuned on another one (MSCOCO). We argue that such comparisons are insufficient to assess the OOD generalization capability of models due to high visual and linguistic similarity between the evaluation and finetuning datasets. To address this gap, we introduce WikiDO (drawn from Wikipedia Diversity Observatory), a novel cross-modal retrieval benchmark to assess the OOD generalization capabilities of pretrained VLMs. This consists of newly scraped 380K image-text pairs from Wikipedia with domain labels, a carefully curated, human-verified a)in-distribution (ID) test set (3K) and b) OOD test set (3K). The image-text pairs are very diverse in topics and geographical locations. We evaluate different VLMs of varying capacity on the \wikido benchmark; BLIP-2 achieves zero-shot performance of $R@1\approx66\%$ on the OOD test set, compared to $\approx$ $81\%$ on COCO and $\approx95\%$ on Flickr. When fine-tuned on WikiDO, the $R@1$ improvement is …
Oral Poster
Alvin Tan · Chunhua Yu · Bria Long · Wanjing Ma · Tonya Murray · Rebecca Silverman · Jason Yeatman · Michael C Frank
[ West Ballroom A-D ]
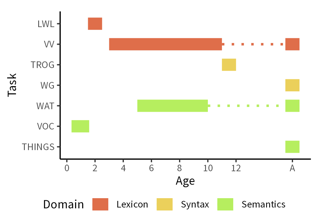
Abstract
How (dis)similar are the learning trajectories of vision–language models and children? Recent modeling work has attempted to understand the gap between models’ and humans’ data efficiency by constructing models trained on less data, especially multimodal naturalistic data. However, such models are often evaluated on adult-level benchmarks, with limited breadth in language abilities tested, and without direct comparison to behavioral data. We introduce DevBench, a multimodal benchmark comprising seven language evaluation tasks spanning the domains of lexical, syntactic, and semantic ability, with behavioral data from both children and adults. We evaluate a set of vision–language models on these tasks, comparing models and humans on their response patterns, not their absolute performance. Across tasks, models exhibit variation in their closeness to human response patterns, and models that perform better on a task also more closely resemble human behavioral responses. We also examine the developmental trajectory of OpenCLIP over training, finding that greater training results in closer approximations to adult response patterns. DevBench thus provides a benchmark for comparing models to human language development. These comparisons highlight ways in which model and human language learning processes diverge, providing insight into entry points for improving language models.
Poster
Dongjie Yang · Suyuan Huang · Chengqiang Lu · Xiaodong Han · Haoxin Zhang · Yan Gao · Yao Hu · Hai Zhao
[ East Exhibit Hall A-C ]

Abstract
Advancements in multimodal learning, particularly in video understanding and generation, require high-quality video-text datasets for improved model performance. Vript addresses this issue with a meticulously annotated corpus of 12K high-resolution videos, offering detailed, dense, and script-like captions for over 420K clips. Each clip has a caption of ~145 words, which is over 10x longer than most video-text datasets. Unlike captions only documenting static content in previous datasets, we enhance video captioning to video scripting by documenting not just the content, but also the camera operations, which include the shot types (medium shot, close-up, etc) and camera movements (panning, tilting, etc). By utilizing the Vript, we explore three training paradigms of aligning more text with the video modality rather than clip-caption pairs. This results in Vriptor, a top-performing video captioning model among open-source models, comparable to GPT-4V in performance. Vriptor is also a powerful model capable of end-to-end generation of dense and detailed captions for long videos. Moreover, we introduce Vript-Hard, a benchmark consisting of three video understanding tasks that are more challenging than existing benchmarks: Vript-HAL is the first benchmark evaluating action and object hallucinations in video LLMs, Vript-RR combines reasoning with retrieval resolving question ambiguity in long-video QAs, and …
Spotlight Poster
Jiatong Li · Renjun Hu · Kunzhe Huang · Yan Zhuang · Qi Liu · Mengxiao Zhu · Xing Shi · Wei Lin
[ East Exhibit Hall A-C ]
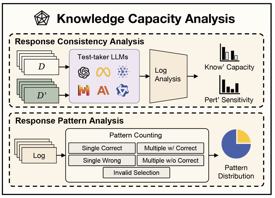
Abstract
Expert-designed close-ended benchmarks are indispensable in assessing the knowledge capacity of large language models (LLMs). Despite their widespread use, concerns have mounted regarding their reliability due to limited test scenarios and an unavoidable risk of data contamination. To rectify this, we present PertEval, a toolkit devised for in-depth probing of LLMs' knowledge capacity through **knowledge-invariant perturbations**. These perturbations employ human-like restatement techniques to generate on-the-fly test samples from static benchmarks, meticulously retaining knowledge-critical content while altering irrelevant details. Our toolkit further includes a suite of **response consistency analyses** that compare performance on raw vs. perturbed test sets to precisely assess LLMs' genuine knowledge capacity. Six representative LLMs are re-evaluated using PertEval. Results reveal significantly inflated performance of the LLMs on raw benchmarks, including an absolute 25.8% overestimation for GPT-4. Additionally, through a nuanced response pattern analysis, we discover that PertEval retains LLMs' uncertainty to specious knowledge, and reveals their potential rote memorization to correct options which leads to overestimated performance. We also find that the detailed response consistency analyses by PertEval could illuminate various weaknesses in existing LLMs' knowledge mastery and guide the development of refinement. Our findings provide insights for advancing more robust and genuinely knowledgeable LLMs. Our code …
Poster
Xueyi Zhang · Xueyi Zhang · Mingrui Lao · Peng Zhao · Jun Tang · Yanming Guo · Siqi Cai · Xianghu Yue · Haizhou Li
[ East Exhibit Hall A-C ]
Abstract
Lip reading aims at transforming the videos of continuous lip movement into textual contents, and has achieved significant progress over the past decade. It serves as a critical yet practical assistance for speech-impaired individuals, with more practicability than speech recognition in noisy environments. With the increasing interpersonal communications in social media owing to globalization, the existing monolingual datasets for lip reading may not be sufficient to meet the exponential proliferation of bilingual and even multilingual users. However, to our best knowledge, research on code-switching is only explored in speech recognition, while the attempts in lip reading are seriously neglected. To bridge this gap, we have collected a bilingual code-switching lip reading benchmark composed of Chinese and English, dubbed CSLR. As the pioneering work, we recruited 62 speakers with proficient foundations in bothspoken Chinese and English to express sentences containing both involved languages. Through rigorous criteria in data selection, CSLR benchmark has accumulated 85,560 video samples with a resolution of 1080x1920, totaling over 71.3 hours of high-quality code-switching lip movement data. To systematically evaluate the technical challenges in CSLR, we implement commonly-used lip reading backbones, as well as competitive solutions in code-switching speech for benchmark testing. Experiments show CSLR to be …
Spotlight Poster
Jian Song · Hongruixuan Chen · Weihao Xuan · Junshi Xia · Naoto YOKOYA
[ West Ballroom A-D ]

Abstract
Global semantic 3D understanding from single-view high-resolution remote sensing (RS) imagery is crucial for Earth observation (EO). However, this task faces significant challenges due to the high costs of annotations and data collection, as well as geographically restricted data availability. To address these challenges, synthetic data offer a promising solution by being unrestricted and automatically annotatable, thus enabling the provision of large and diverse datasets. We develop a specialized synthetic data generation pipeline for EO and introduce SynRS3D, the largest synthetic RS dataset. SynRS3D comprises 69,667 high-resolution optical images that cover six different city styles worldwide and feature eight land cover types, precise height information, and building change masks. To further enhance its utility, we develop a novel multi-task unsupervised domain adaptation (UDA) method, RS3DAda, coupled with our synthetic dataset, which facilitates the RS-specific transition from synthetic to real scenarios for land cover mapping and height estimation tasks, ultimately enabling global monocular 3D semantic understanding based on synthetic data. Extensive experiments on various real-world datasets demonstrate the adaptability and effectiveness of our synthetic dataset and the proposed RS3DAda method. SynRS3D and related codes are available at https://github.com/JTRNEO/SynRS3D.
Poster
Miguel González-Duque · Richard Michael · Simon Bartels · Yevgen Zainchkovskyy · Søren Hauberg · Wouter Boomsma
[ West Ballroom A-D ]
Abstract
Optimizing discrete black-box functions is key in several domains, e.g. protein engineering and drug design. Due to the lack of gradient information and the need for sample efficiency, Bayesian optimization is an ideal candidate for these tasks. Several methods for high-dimensional continuous and categorical Bayesian optimization have been proposed recently. However, our survey of the field reveals highly heterogeneous experimental set-ups across methods and technical barriers for the replicability and application of published algorithms to real-world tasks. To address these issues, we develop a unified framework to test a vast array of high-dimensional Bayesian optimization methods and a collection of standardized black-box functions representing real-world application domains in chemistry and biology. These two components of the benchmark are each supported by flexible, scalable, and easily extendable software libraries (poli and poli-baselines), allowing practitioners to readily incorporate new optimization objectives or discrete optimizers. Project website: https://machinelearninglifescience.github.io/hdbo_benchmark.
Oral Poster
Andrew M. Bean · Simi Hellsten · Harry Mayne · Jabez Magomere · Ethan Chi · Ryan Chi · Scott Hale · Hannah Rose Kirk
[ West Ballroom A-D ]
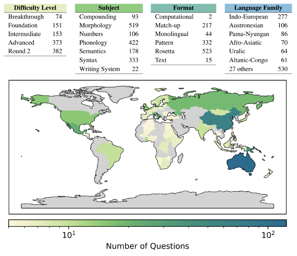
Abstract
In this paper, we present the LingOly benchmark, a novel benchmark for advanced reasoning abilities in large language models. Using challenging Linguistic Olympiad puzzles, we evaluate (i) capabilities for in-context identification and generalisation of linguistic patterns in very low-resource or extinct languages, and (ii) abilities to follow complex task instructions. The LingOly benchmark covers more than 90 mostly low-resource languages, minimising issues of data contamination, and contains 1,133 problems across 6 formats and 5 levels of human difficulty. We assess performance with both direct accuracy and comparison to a no-context baseline to penalise memorisation. Scores from 11 state-of-the-art LLMs demonstrate the benchmark to be challenging, and models perform poorly on the higher difficulty problems. On harder problems, even the top model only achieved 38.7% accuracy, a 24.7% improvement over the no-context baseline. Large closed models typically outperform open models, and in general, the higher resource the language, the better the scores. These results indicate, in absence of memorisation, true multi-step out-of-domain reasoning remains a challenge for current language models.
Poster
Richard Ren · Steven Basart · Adam Khoja · Alice Gatti · Long Phan · Xuwang Yin · Mantas Mazeika · Alexander Pan · Gabriel Mukobi · Ryan Kim · Stephen Fitz · Dan Hendrycks
[ West Ballroom A-D ]
Abstract
Performance on popular ML benchmarks is highly correlated with model scale, suggesting that most benchmarks tend to measure a similar underlying factor of general model capabilities. However, substantial research effort remains devoted to designing new benchmarks, many of which claim to measure novel phenomena. In the spirit of the Bitter Lesson, we leverage spectral analysis to measure an underlying capabilities component, the direction in benchmark-performance-space which explains most variation in model performance. In an extensive analysis of existing safety benchmarks, we find that variance in model performance on many safety benchmarks is largely explained by the capabilities component. In response, we argue that safety research should prioritize metrics which are not highly correlated with scale. Our work provides a lens to analyze both novel safety benchmarks and novel safety methods, which we hope will enable future work to make differential progress on safety.
Poster
Mucong Ding · Chenghao Deng · Jocelyn Choo · Zichu Wu · Aakriti Agrawal · Avi Schwarzschild · Tianyi Zhou · Tom Goldstein · John Langford · Animashree Anandkumar · Furong Huang
[ West Ballroom A-D ]

Abstract
Despite the abundance of datasets available for assessing large language models (LLMs), the scarcity of continuous and reliable difficulty labels for individual data points, in most cases, curtails their capacity to benchmark model generalization performance across different levels of complexity. Addressing this limitation, we present Easy2Hard, an innovative collection of 6 benchmark datasets featuring standardized difficulty labels spanning a wide range of domains, such as mathematics and programming problems, chess puzzles, and reasoning questions, providing a much-needed tool for those in demand of a dataset with varying degrees of difficulty for LLM assessment. We estimate the difficulty of individual problems by leveraging the performance data of many human subjects and LLMs on prominent leaderboards. Harnessing the rich human performance data, we employ widely recognized difficulty ranking systems, including the Item Response Theory (IRT) and Glicko-2 models, to uniformly assign difficulty scores to problems. The Easy2Hard datasets distinguish themselves from previous collections by incorporating a significantly higher proportion of challenging problems, presenting a novel and demanding test for state-of-the-art LLMs. Through extensive experiments conducted with six state-of-the-art LLMs on the Easy2Hard datasets, we offer valuable insights into their performance and generalization capabilities across varying degrees of difficulty, setting the stage for …
Spotlight Poster
Anka Reuel-Lamparth · Amelia Hardy · Chandler Smith · Max Lamparth · Malcolm Hardy · Mykel J Kochenderfer
[ West Ballroom A-D ]
Abstract
AI models are increasingly prevalent in high-stakes environments, necessitating thorough assessment of their capabilities and risks. Benchmarks are popular for measuring these attributes and for comparing model performance, tracking progress, and identifying weaknesses in foundation and non-foundation models. They can inform model selection for downstream tasks and influence policy initiatives. However, not all benchmarks are the same: their quality depends on their design and usability. In this paper, we develop an assessment framework considering 40 best practices across a benchmark's life cycle and evaluate 25 AI benchmarks against it. We find that there exist large quality differences and that commonly used benchmarks suffer from significant issues. We further find that most benchmarks do not report statistical significance of their results nor can results be easily replicated. To support benchmark developers in aligning with best practices, we provide a checklist for minimum quality assurance based on our assessment. We also develop a living repository of benchmark assessments to support benchmark comparability.
Poster
Nuwan Bandara · Thivya Kandappu · Argha Sen · Ila Gokarn · Archan Misra
[ West Ballroom A-D ]
Abstract
Continuous tracking of eye movement dynamics plays a significant role in developing a broad spectrum of human-centered applications, such as cognitive skills (visual attention and working memory) modeling, human-machine interaction, biometric user authentication, and foveated rendering. Recently neuromorphic cameras have garnered significant interest in the eye-tracking research community, owing to their sub-microsecond latency in capturing intensity changes resulting from eye movements. Nevertheless, the existing approaches for event-based eye tracking suffer from several limitations: dependence on RGB frames, label sparsity, and training on datasets collected in controlled lab environments that do not adequately reflect real-world scenarios. To address these limitations, in this paper, we propose a dynamic graph-based approach that uses a neuromorphic event stream captured by Dynamic Vision Sensors (DVS) for high-fidelity tracking of pupillary movement. More specifically, first, we present EyeGraph, a large-scale multi-modal near-eye tracking dataset collected using a wearable event camera attached to a head-mounted device from 40 participants -- the dataset was curated while mimicking in-the-wild settings, accounting for varying mobility and ambient lighting conditions. Subsequently, to address the issue of label sparsity, we adopt an unsupervised topology-aware approach as a benchmark. To be specific, (a) we first construct a dynamic graph using Gaussian Mixture Models …
Poster
pengcheng chen · Jin Ye · Guoan Wang · Yanjun Li · Zhongying Deng · Wei Li · Tianbin Li · Haodong Duan · Ziyan Huang · Yanzhou Su · Benyou Wang · Shaoting Zhang · Bin Fu · Jianfei Cai · Bohan Zhuang · Eric Seibel · Junjun He · Yu Qiao
[ West Ballroom A-D ]
Abstract
Large Vision-Language Models (LVLMs) are capable of handling diverse data types such as imaging, text, and physiological signals, and can be applied in various fields. In the medical field, LVLMs have a high potential to offer substantial assistance for diagnosis and treatment. Before that, it is crucial to develop benchmarks to evaluate LVLMs' effectiveness in various medical applications. Current benchmarks are often built upon specific academic literature, mainly focusing on a single domain, and lacking varying perceptual granularities. Thus, they face specific challenges, including limited clinical relevance, incomplete evaluations, and insufficient guidance for interactive LVLMs. To address these limitations, we developed the GMAI-MMBench, the most comprehensive general medical AI benchmark with well-categorized data structure and multi-perceptual granularity to date. It is constructed from 284 datasets across 38 medical image modalities, 18 clinical-related tasks, 18 departments, and 4 perceptual granularities in a Visual Question Answering (VQA) format. Additionally, we implemented a lexical tree structure that allows users to customize evaluation tasks, accommodating various assessment needs and substantially supporting medical AI research and applications. We evaluated 50 LVLMs, and the results show that even the advanced GPT-4o only achieves an accuracy of 53.96\%, indicating significant room for improvement. Moreover, we identified five …
Poster
Edoardo Debenedetti · Jie Zhang · Mislav Balunovic · Luca Beurer-Kellner · Marc Fischer · Florian Tramer
[ West Ballroom A-D ]

Abstract
AI agents aim to solve complex tasks by combining text-based reasoning with external tool calls.Unfortunately, AI agents are vulnerable to prompt injection attacks where data returned by external tools hijacks the agent to execute malicious tasks.To measure the adversarial robustness of AI agents, we introduce AgentDojo, an evaluation framework for agents that execute tools over untrusted data.To capture the evolving nature of attacks and defenses, AgentDojo is not a static test suite, but rather an extensible environment for designing and evaluating new agent tasks, defenses, and adaptive attacks.We populate the environment with 97 realistic tasks (e.g., managing an email client, navigating an e-banking website, or making travel bookings), 629 security test cases, and various attack and defense paradigms from the literature.We find that AgentDojo poses a challenge for both attacks and defenses: state-of-the-art LLMs fail at many tasks (even in the absence of attacks), and existing prompt injection attacks break some security properties but not all. We hope that AgentDojo can foster research on new design principles for AI agents that solve common tasks in a reliable and robust manner.
Poster
Anna Varbella · Kenza Amara · Blazhe Gjorgiev · Mennatallah El-Assady · Giovanni Sansavini
[ West Ballroom A-D ]
Abstract
Power grids are critical infrastructures of paramount importance to modern society and, therefore, engineered to operate under diverse conditions and failures. The ongoing energy transition poses new challenges for the decision-makers and system operators. Therefore, we must develop grid analysis algorithms to ensure reliable operations. These key tools include power flow analysis and system security analysis, both needed for effective operational and strategic planning. The literature review shows a growing trend of machine learning (ML) models that perform these analyses effectively. In particular, Graph Neural Networks (GNNs) stand out in such applications because of the graph-based structure of power grids. However, there is a lack of publicly available graph datasets for training and benchmarking ML models in electrical power grid applications. First, we present PowerGraph, which comprises GNN-tailored datasets for i) power flows, ii) optimal power flows, and iii) cascading failure analyses of power grids. Second, we provide ground-truth explanations for the cascading failure analysis. Finally, we perform a complete benchmarking of GNN methods for node-level and graph-level tasks and explainability. Overall, PowerGraph is a multifaceted GNN dataset for diverse tasks that includes power flow and fault scenarios with real-world explanations, providing a valuable resource for developing improved GNN models …
Poster
Felix Fent · Fabian Kuttenreich · Florian Ruch · Farija Rizwin · Stefan Juergens · Lorenz Lechermann · Christian Nissler · Andrea Perl · Ulrich Voll · Min Yan · Markus Lienkamp
[ West Ballroom A-D ]

Abstract
Autonomous trucking is a promising technology that can greatly impact modern logistics and the environment. Ensuring its safety on public roads is one of the main duties that requires an accurate perception of the environment. To achieve this, machine learning methods rely on large datasets, but to this day, no such datasets are available for autonomous trucks. In this work, we present MAN TruckScenes, the first multimodal dataset for autonomous trucking. MAN TruckScenes allows the research community to come into contact with truck-specific challenges, such as trailer occlusions, novel sensor perspectives, and terminal environments for the first time. It comprises more than 740 scenes of 20 s each within a multitude of different environmental conditions. The sensor set includes 4 cameras, 6 lidar, 6 radar sensors, 2 IMUs, and a high-precision GNSS. The dataset's 3D bounding boxes were manually annotated and carefully reviewed to achieve a high quality standard. Bounding boxes are available for 27 object classes, 15 attributes, and a range of more than 230 m. The scenes are tagged according to 34 distinct scene tags, and all objects are tracked throughout the scene to promote a wide range of applications. Additionally, MAN TruckScenes is the first dataset to …
Poster
Marvin Alberts · Oliver Schilter · Federico Zipoli · Nina Hartrampf · Teodoro Laino
[ East Exhibit Hall A-C ]
Abstract
Spectroscopic techniques are essential tools for determining the structure of molecules. Different spectroscopic techniques, such as Nuclear magnetic resonance (NMR), Infrared spectroscopy, and Mass Spectrometry, provide insight into the molecular structure, including the presence or absence of functional groups. Chemists leverage the complementary nature of the different methods to their advantage. However, the lack of a comprehensive multimodal dataset, containing spectra from a variety of spectroscopic techniques, has limited machine-learning approaches mostly to single-modality tasks for predicting molecular structures from spectra. Here we introduce a dataset comprising simulated $^1$H-NMR, $^{13}$C-NMR, HSQC-NMR, Infrared, and Mass spectra (positive and negative ion modes) for 790k molecules extracted from chemical reactions in patent data. This dataset enables the development of foundation models for integrating information from multiple spectroscopic modalities, emulating the approach employed by human experts. Additionally, we provide benchmarks for evaluating single-modality tasks such as structure elucidation, predicting the spectra for a target molecule, and functional group predictions. This dataset has the potential automate structure elucidation, streamlining the molecular discovery pipeline from synthesis to structure determination. The dataset and code for the benchmarks can be found at https://rxn4chemistry.github.io/multimodal-spectroscopic-dataset (Available upon submission of the supporting information).
Oral Poster
David Romero · Chenyang Lyu · Haryo Wibowo · Santiago Góngora · Aishik Mandal · Sukannya Purkayastha · Jesus-German Ortiz-Barajas · Emilio Cueva · Jinheon Baek · Soyeong Jeong · Injy Hamed · Yong Zheng-Xin · Zheng Wei Lim · Paula Silva · Jocelyn Dunstan · Mélanie Jouitteau · David LE MEUR · Joan Nwatu · Ganzorig Batnasan · Munkh-Erdene Otgonbold · Munkhjargal Gochoo · Guido Ivetta · Luciana Benotti · Laura Alonso Alemany · Hernán Maina · Jiahui Geng · Tiago Timponi Torrent · Frederico Belcavello · Marcelo Viridiano · Jan Christian Blaise Cruz · Dan John Velasco · Oana Ignat · Zara Burzo · Chenxi Whitehouse · Artem Abzaliev · Teresa Clifford · Gráinne Caulfield · Teresa Lynn · Christian Salamea-Palacios · Vladimir Araujo · Yova Kementchedjhieva · Mihail Mihaylov · Israel Azime · Henok Ademtew · Bontu Balcha · Naome A. Etori · David Adelani · Rada Mihalcea · Atnafu Lambebo Tonja · Maria Cabrera · Gisela Vallejo · Holy Lovenia · Ruochen Zhang · Marcos Estecha-Garitagoitia · Mario Rodríguez-Cantelar · Toqeer Ehsan · Rendi Chevi · Muhammad Adilazuarda · Ryandito Diandaru · Samuel Cahyawijaya · Fajri Koto · Tatsuki Kuribayashi · Haiyue Song · Aditya Khandavally · Thanmay Jayakumar · Raj Dabre · Mohamed Imam · Kumaranage Nagasinghe · Alina Dragonetti · Luis Fernando D'Haro · Niyomugisha Olivier · Jay Gala · Pranjal Chitale · Fauzan Farooqui · Thamar Solorio · Alham Aji
[ West Ballroom A-D ]

Abstract
Visual Question Answering~(VQA) is an important task in multimodal AI, which requires models to understand and reason on knowledge present in visual and textual data. However, most of the current VQA datasets and models are primarily focused on English and a few major world languages, with images that are Western-centric. While recent efforts have tried to increase the number of languages covered on VQA datasets, they still lack diversity in low-resource languages. More importantly, some datasets extend the text to other languages, either via translation or some other approaches, but usually keep the same images, resulting in narrow cultural representation. To address these limitations, we create CVQA, a new Culturally-diverse Multilingual Visual Question Answering benchmark dataset, designed to cover a rich set of languages and regions, where we engage native speakers and cultural experts in the data collection process. CVQA includes culturally-driven images and questions from across 28 countries in four continents, covering 26 languages with 11 scripts, providing a total of 9k questions. We benchmark several Multimodal Large Language Models (MLLMs) on CVQA, and we show that the dataset is challenging for the current state-of-the-art models. This benchmark will serve as a probing evaluation suite for assessing the cultural …
Poster
Bosi Wen · Pei Ke · Xiaotao Gu · Lindong Wu · Hao Huang · Jinfeng Zhou · Wenchuang Li · Binxin Hu · Wendy Gao · Jiaxing Xu · Yiming Liu · Jie Tang · Hongning Wang · Minlie Huang
[ East Exhibit Hall A-C ]

Abstract
Instruction following is one of the fundamental capabilities of large language models (LLMs). As the ability of LLMs is constantly improving, they have been increasingly applied to deal with complex human instructions in real-world scenarios. Therefore, how to evaluate the ability of complex instruction-following of LLMs has become a critical research problem. Existing benchmarks mainly focus on modeling different types of constraints in human instructions while neglecting the composition of different constraints, which is an indispensable constituent in complex instructions. To this end, we propose ComplexBench, a benchmark for comprehensively evaluating the ability of LLMs to follow complex instructions composed of multiple constraints. We propose a hierarchical taxonomy for complex instructions, including 4 constraint types, 19 constraint dimensions, and 4 composition types, and manually collect a high-quality dataset accordingly. To make the evaluation reliable, we augment LLM-based evaluators with rules to effectively verify whether generated texts can satisfy each constraint and composition. Furthermore, we obtain the final evaluation score based on the dependency structure determined by different composition types. ComplexBench identifies significant deficiencies in existing LLMs when dealing with complex instructions with multiple constraints composition.
Poster
Yuhan Li · Peisong Wang · Xiao Zhu · Aochuan Chen · Haiyun Jiang · Deng Cai · Wai Kin (Victor) Chan · Jia Li
[ East Exhibit Hall A-C ]
Abstract
The emergence of large language models (LLMs) has revolutionized the way we interact with graphs, leading to a new paradigm called GraphLLM. Despite the rapid development of GraphLLM methods in recent years, the progress and understanding of this field remain unclear due to the lack of a benchmark with consistent experimental protocols. To bridge this gap, we introduce GLBench, the first comprehensive benchmark for evaluating GraphLLM methods in both supervised and zero-shot scenarios. GLBench provides a fair and thorough evaluation of different categories of GraphLLM methods, along with traditional baselines such as graph neural networks. Through extensive experiments on a collection of real-world datasets with consistent data processing and splitting strategies, we have uncovered several key findings. Firstly, GraphLLM methods outperform traditional baselines in supervised settings, with LLM-as-enhancers showing the most robust performance. However, using LLMs as predictors is less effective and often leads to uncontrollable output issues. We also notice that no clear scaling laws exist for current GraphLLM methods. In addition, both structures and semantics are crucial for effective zero-shot transfer, and our proposed simple baseline can even outperform several models tailored for zero-shot scenarios. The data and code of the benchmark can be found at https://github.com/NineAbyss/GLBench.
Poster
Arshia Hemmat · Adam Davies · Tom Lamb · Jianhao Yuan · Philip Torr · Ashkan Khakzar · Francesco Pinto
[ West Ballroom A-D ]
Abstract
Despite the importance of shape perception in human vision, early neural image classifiers relied less on shape information for object recognition than other (often spurious) features. While recent research suggests that current large Vision-Language Models (VLMs) exhibit more reliance on shape, we find them to still be seriously limited in this regard. To quantify such limitations, we introduce IllusionBench, a dataset that challenges current cutting-edge VLMs to decipher shape information when the shape is represented by an arrangement of visual elements in a scene. Our extensive evaluations reveal that, while these shapes are easily detectable by human annotators, current VLMs struggle to recognize them, indicating important avenues for future work in developing more robust visual perception systems. The full dataset and codebase are available at: https://arshiahemmat.github.io/illusionbench/
Poster
Puze Liu · Jonas Günster · Niklas Funk · Simon Gröger · Dong Chen · Haitham Bou Ammar · Julius Jankowski · Ante Marić · Sylvain Calinon · Andrej Orsula · Miguel Olivares · Hongyi Zhou · Rudolf Lioutikov · Gerhard Neumann · Amarildo Likmeta · Amirhossein Zhalehmehrabi · Thomas Bonenfant · Marcello Restelli · Davide Tateo · Ziyuan Liu · Jan Peters
[ East Exhibit Hall A-C ]

Abstract
Machine learning methods have a groundbreaking impact in many application domains, but their application on real robotic platforms is still limited.Despite the many challenges associated with combining machine learning technology with robotics, robot learning remains one of the most promising directions for enhancing the capabilities of robots. When deploying learning-based approaches on real robots, extra effort is required to address the challenges posed by various real-world factors. To investigate the key factors influencing real-world deployment and to encourage original solutions from different researchers, we organized the Robot Air Hockey Challenge at the NeurIPS 2023 conference. We selected the air hockey task as a benchmark, encompassing low-level robotics problems and high-level tactics. Different from other machine learning-centric benchmarks, participants need to tackle practical challenges in robotics, such as the sim-to-real gap, low-level control issues, safety problems, real-time requirements, and the limited availability of real-world data. Furthermore, we focus on a dynamic environment, removing the typical assumption of quasi-static motions of other real-world benchmarks.The competition's results show that solutions combining learning-based approaches with prior knowledge outperform those relying solely on data when real-world deployment is challenging.Our ablation study reveals which real-world factors may be overlooked when building a learning-based solution.The successful real-world …
Poster
Dong HUANG · Yuhao QING · Weiyi Shang · Heming Cui · Jie Zhang
[ West Ballroom A-D ]
Abstract
Code generation models have increasingly become integral to aiding software development. Although current research has thoroughly examined the correctness of the code produced by code generation models, a vital aspect that plays a pivotal role in greencomputing and sustainability efforts — the efficiency of the generated code — has often been neglected. This paper presents Effibench, a benchmark with 1,000 efficiency-critical coding problems to assess the efficiency of code generated by code generation models. EffiBench contains a diverse set of LeetCode coding problems. Each problem is paired with an executable human-written canonical solution, which obtains the SOTA efficiency on the LeetCode solution leaderboard. With EffiBench, we empirically examine the ability of 42 large language models (35 open-source and 7 closed-source) to generate efficient code. Our evaluation results demonstrate that the efficiency of the code generated by LLMs is generally worse than the efficiency of human-written canonical solutions. For example, GPT-4 generated code has an average \textbf{3.12} times execution time that of the human-written canonical solutions. In the most extreme cases, the execution time and total memory usage of GPT-4 code are \textbf{13.89} and \textbf{43.92} times that of the canonical solutions. The source code of EffiBench is released on https://github.com/huangd1999/EffiBench. We …
Spotlight Poster
Md Tanvirul Alam · Dipkamal Bhusal · Le Nguyen · Nidhi Rastogi
[ West Ballroom A-D ]
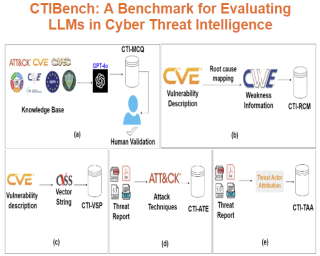
Abstract
Cyber threat intelligence (CTI) is crucial in today's cybersecurity landscape, providing essential insights to understand and mitigate the ever-evolving cyber threats. The recent rise of Large Language Models (LLMs) have shown potential in this domain, but concerns about their reliability, accuracy, and hallucinations persist. While existing benchmarks provide general evaluations of LLMs, there are no benchmarks that address the practical and applied aspects of CTI-specific tasks. To bridge this gap, we introduce CTIBench, a benchmark designed to assess LLMs' performance in CTI applications. CTIBench includes multiple datasets focused on evaluating knowledge acquired by LLMs in the cyber-threat landscape. Our evaluation of several state-of-the-art models on these tasks provides insights into their strengths and weaknesses in CTI contexts, contributing to a better understanding of LLM capabilities in CTI.
Poster
Haozhe Chen · Ang Li · Ethan Che · Jing Dong · Tianyi Peng · Hongseok Namkoong
[ West Ballroom A-D ]
Abstract
Queuing network control allows allocation of scarce resources to manage congestion, a fundamental problem in manufacturing, communications, and healthcare. Compared to standard RL problems, queueing problems are distinguished by unique challenges: i) a system operating in continuous time, ii) high stochasticity, and iii) long horizons over which the system can become unstable (exploding delays). To provide the empirical foundations for methodological development tackling these challenges, we present an open-sourced queueing simulation framework, QGym, that benchmark queueing policies across realistic problem instances. Our modular framework allows the researchers to build on our initial instances, which provide a wide range of environments including parallel servers, criss-cross, tandem, and re-entrant networks, as well as a realistically calibrated hospital queuing system. From these, various policies can be easily tested, including both model-free RL methods and classical queuing policies. Our testbed significantly expands the scope of empirical benchmarking in prior work, and complements thetraditional focus on evaluating algorithms based on mathematical guarantees in idealized settings. QGym code is open-sourced at https://github.com/namkoong-lab/QGym.
Poster
M. Maruf · Arka Daw · Kazi Sajeed Mehrab · Harish Babu Manogaran · Abhilash Neog · Medha Sawhney · Mridul Khurana · James Balhoff · Yasin Bakis · Bahadir Altintas · Matthew Thompson · Elizabeth Campolongo · Josef Uyeda · Hilmar Lapp · Henry Bart · Paula Mabee · Yu Su · Wei-Lun (Harry) Chao · Charles Stewart · Tanya Berger-Wolf · Wasila Dahdul · Anuj Karpatne
[ West Ballroom A-D ]

Abstract
Images are increasingly becoming the currency for documenting biodiversity on the planet, providing novel opportunities for accelerating scientific discoveries in the field of organismal biology, especially with the advent of large vision-language models (VLMs). We ask if pre-trained VLMs can aid scientists in answering a range of biologically relevant questions without any additional fine-tuning. In this paper, we evaluate the effectiveness of $12$ state-of-the-art (SOTA) VLMs in the field of organismal biology using a novel dataset, VLM4Bio, consisting of $469K$ question-answer pairs involving $30K$ images from three groups of organisms: fishes, birds, and butterflies, covering five biologically relevant tasks. We also explore the effects of applying prompting techniques and tests for reasoning hallucination on the performance of VLMs, shedding new light on the capabilities of current SOTA VLMs in answering biologically relevant questions using images.
Poster
Benjamin Feuer · Jiawei Xu · Niv Cohen · Patrick Yubeaton · Govind Mittal · Chinmay Hegde
[ East Exhibit Hall A-C ]

Abstract
Data curation is the problem of how to collect and organize samples into a dataset that supports efficient learning. Despite the centrality of the task, little work has been devoted towards a large-scale, systematic comparison of various curation methods. In this work, we take steps towards a formal evaluation of data curation strategies and introduce SELECT, the first large-scale benchmark of curation strategies for image classification.In order to generate baseline methods for the SELECT benchmark, we create a new dataset, ImageNet++, which constitutes the largest superset of ImageNet-1K to date. Our dataset extends ImageNet with 5 new training-data shifts, each approximately the size of ImageNet-1K, and each assembled using a distinct curation strategy. We evaluate our data curation baselines in two ways: (i) using each training-data shift to train identical image classification models from scratch (ii) using it to inspect a fixed pretrained self-supervised representation.Our findings show interesting trends, particularly pertaining to recent methods for data curation such as synthetic data generation and lookup based on CLIP embeddings. We show that although these strategies are highly competitive for certain tasks, the curation strategy used to assemble the original ImageNet-1K dataset remains the gold standard. We anticipate that our benchmark can …
Poster
Alex Mathai · Chenxi Huang · Petros Maniatis · Aleksandr Nogikh · Franjo Ivančić · Junfeng Yang · Baishakhi Ray
[ West Ballroom A-D ]
Abstract
Large Language Models (LLMs) are consistently improving at increasingly realistic software engineering (SE) tasks. In real-world software stacks, significant SE effort is spent developing foundational system software like the Linux kernel. Unlike application-level software, a systems codebase like Linux is multilingual (low-level C/Assembly/Bash/Rust); gigantic (>20 million lines); critical (impacting billions of devices worldwide), and highly concurrent (involving complex multi-threading). To evaluate if machine learning (ML) models are useful while developing such large-scale systems-level software, we introduce kGym (a platform) and kBench (a dataset). The kGym platform provides a SE environment for large-scale experiments on the Linux kernel, including compiling and running kernels in parallel across several virtual machines, detecting operations and crashes, inspecting logs, and querying and patching the code base. We use kGym to facilitate evaluation on kBench, a crash resolution benchmark drawn from real-world Linux kernel bugs. An example bug in kBench contains crashing stack traces, a bug-reproducer file, a developer-written fix, and other associated data. To understand current performance, we conduct baseline experiments by prompting LLMs to resolve Linux kernel crashes. Our initial evaluations reveal that the best performing LLM achieves 0.72\% and 5.38\% in the unassisted and assisted (i.e., buggy files disclosed to the model) …
Poster
Nikolaos Ioannis Bountos · Maria Sdraka · Angelos Zavras · Andreas Karavias · Ilektra Karasante · Themistocles Herekakis · Angeliki Thanasou · Dimitrios Michail · Ioannis Papoutsis
[ West Ballroom A-D ]
Abstract
Global flash floods, exacerbated by climate change, pose severe threats to humanlife, infrastructure, and the environment. Recent catastrophic events in Pakistan andNew Zealand underscore the urgent need for precise flood mapping to guide restoration efforts, understand vulnerabilities, and prepare for future occurrences. While Synthetic Aperture Radar (SAR) remote sensing offers day-and-night, all-weatherimaging capabilities, its application in deep learning for flood segmentation is limited by the lack of large annotated datasets. To address this, we introduce KuroSiwo, a manually annotated multi-temporal dataset, spanning 43 flood events globally. Our dataset maps more than 338 billion $m^2$ of land, with 33 billion designatedas either flooded areas or permanent water bodies. Kuro Siwo includes a highlyprocessed product optimized for flash flood mapping based on SAR Ground RangeDetected, and a primal SAR Single Look Complex product with minimal preprocessing, designed to promote research on the exploitation of both the phase and amplitude information and to offer maximum flexibility for downstream task preprocessing. To leverage advances in large scale self-supervised pretraining methodsfor remote sensing data, we augment Kuro Siwo with a large unlabeled set of SARsamples. Finally, we provide an extensive benchmark, namely BlackBench, offering strong baselines for a diverse set of flood events globally. All …
Poster
Ruosen Li · Zimu Wang · Son Tran · Lei Xia · Xinya Du
[ West Ballroom A-D ]
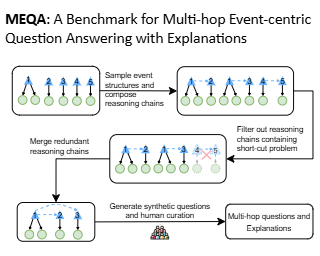
Abstract
Existing benchmarks for multi-hop question answering (QA) primarily evaluate models based on their ability to reason about entities and the relationships between them. However, there's a lack of insight into how these models perform in terms of both events and entities. In this paper, we introduce a novel semi-automatic question generation strategy by composing event structures from information extraction (IE) datasets and present the first Multi-hop Event-centric Question Answering (MEQA) benchmark. It contains (1) 2,243 challenging questions that require a diverse range of complex reasoning over entity-entity, entity-event, and event-event relations; (2) corresponding multi-step QA-format event reasoning chain (explanation) which leads to the answer for each question. We also introduce two metrics for evaluating explanations: completeness and logical consistency. We conduct comprehensive benchmarking and analysis, which shows that MEQA is challenging for the latest state-of-the-art models encompassing large language models (LLMs); and how they fall short of providing faithful explanations of the event-centric reasoning process.
Poster
Xiang Li · Jian Ding · Mohamed Elhoseiny
[ West Ballroom A-D ]
Abstract
We introduce a new benchmark designed to advance the development of general-purpose, large-scale vision-language models for remote sensing images. Although several vision-language datasets in remote sensing have been proposed to pursue this goal, existing datasets are typically tailored to single tasks, lack detailed object information, or suffer from inadequate quality control. Exploring these improvement opportunities, we present a Versatile vision-language Benchmark for Remote Sensing image understanding, termed VRSBench. This benchmark comprises 29,614 images, with 29,614 human-verified detailed captions, 52,472 object references, and 123,221 question-answer pairs. It facilitates the training and evaluation of vision-language models across a broad spectrum of remote sensing image understanding tasks. We further evaluated state-of-the-art models on this benchmark for three vision-language tasks: image captioning, visual grounding, and visual question answering. Our work aims to significantly contribute to the development of advanced vision-language models in the field of remote sensing. The data and code can be accessed at https://vrsbench.github.io.
Poster
Jianhua Sun · Yuxuan Li · Longfei Xu · Nange Wang · Jiude Wei · Yining Zhang · Cewu Lu
[ West Ballroom A-D ]
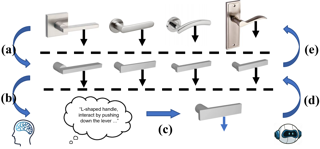
Abstract
We present ConceptFactory, a novel scope to facilitate more efficient annotation of 3D object knowledge by recognizing 3D objects through generalized concepts (i.e. object conceptualization), aiming at promoting machine intelligence to learn comprehensive object knowledge from both vision and robotics aspects. This idea originates from the findings in human cognition research that the perceptual recognition of objects can be explained as a process of arranging generalized geometric components (e.g. cuboids and cylinders). ConceptFactory consists of two critical parts: i) ConceptFactory Suite, a unified toolbox that adopts Standard Concept Template Library (STL-C) to drive a web-based platform for object conceptualization, and ii) ConceptFactory Asset, a large collection of conceptualized objects acquired using ConceptFactory suite. Our approach enables researchers to effortlessly acquire or customize extensive varieties of object knowledge to comprehensively study different object understanding tasks. We validate our idea on a wide range of benchmark tasks from both vision and robotics aspects with state-of-the-art algorithms, demonstrating the high quality and versatility of annotations provided by our approach. Our website is available at https://apeirony.github.io/ConceptFactory.
Poster
Sunjun Kweon · Jiyoun Kim · Heeyoung Kwak · Dongchul Cha · Hangyul Yoon · Kwang Kim · Jeewon Yang · Seunghyun Won · Edward Choi
[ West Ballroom A-D ]

Abstract
Discharge summaries in Electronic Health Records (EHRs) are crucial for clinical decision-making, but their length and complexity make information extraction challenging, especially when dealing with accumulated summaries across multiple patient admissions. Large Language Models (LLMs) show promise in addressing this challenge by efficiently analyzing vast and complex data. Existing benchmarks, however, fall short in properly evaluating LLMs' capabilities in this context, as they typically focus on single-note information or limited topics, failing to reflect the real-world inquiries required by clinicians. To bridge this gap, we introduce EHRNoteQA, a novel benchmark built on the MIMIC-IV EHR, comprising 962 different QA pairs each linked to distinct patients' discharge summaries. Every QA pair is initially generated using GPT-4 and then manually reviewed and refined by three clinicians to ensure clinical relevance. EHRNoteQA includes questions that require information across multiple discharge summaries and covers eight diverse topics, mirroring the complexity and diversity of real clinical inquiries. We offer EHRNoteQA in two formats: open-ended and multi-choice question answering, and propose a reliable evaluation method for each. We evaluate 27 LLMs using EHRNoteQA and examine various factors affecting the model performance (e.g., the length and number of discharge summaries). Furthermore, to validate EHRNoteQA as a reliable …
Poster
Christina Bukas · Harshavardhan Subramanian · Fenja See · Carina Steinchen · Ivan Ezhov · Gowtham Boosarpu · Sara Asgharpour · Gerald Burgstaller · Mareike Lehmann · Florian Kofler · Marie Piraud
[ West Ballroom A-D ]
Abstract
High-throughput image analysis in the biomedical domain has gained significant attention in recent years, driving advancements in drug discovery, disease prediction, and personalized medicine. Organoids, specifically, are an active area of research, providing excellent models for human organs and their functions. Automating the quantification of organoids in microscopy images would provide an effective solution to overcome substantial manual quantification bottlenecks, particularly in high-throughput image analysis. However, there is a notable lack of open biomedical datasets, in contrast to other domains, such as autonomous driving, and, notably, only few of them have attempted to quantify annotation uncertainty. In this work, we present MultiOrg a comprehensive organoid dataset tailored for object detection tasks with uncertainty quantification. This dataset comprises over 400 high-resolution 2d microscopy images and curated annotations of more than 60,000 organoids. Most importantly, it includes three label sets for the test data, independently annotated by two experts at distinct time points. We additionally provide a benchmark for organoid detection, and make the best model available through an easily installable, interactive plugin for the popular image visualization tool Napari, to perform organoid quantification.
Poster
Han Huang · Haitian Zhong · Tao Yu · Qiang Liu · Shu Wu · Liang Wang · Tieniu Tan
[ East Exhibit Hall A-C ]

Abstract
Recently, knowledge editing on large language models (LLMs) has received considerable attention. Compared to this, editing Large Vision-Language Models (LVLMs) faces extra challenges from diverse data modalities and complicated model components, and data for LVLMs editing are limited. The existing LVLM editing benchmark, which comprises three metrics (Reliability, Locality, and Generality), falls short in the quality of synthesized evaluation images and cannot assess whether models apply edited knowledge in relevant content. Therefore, we employ more reliable data collection methods to construct a new Large $\textbf{V}$ision-$\textbf{L}$anguage Model $\textbf{K}$nowledge $\textbf{E}$diting $\textbf{B}$enchmark, $\textbf{VLKEB}$, and extend the Portability metric for more comprehensive evaluation. Leveraging a multi-modal knowledge graph, our image data are bound with knowledge entities. This can be further used to extract entity-related knowledge, which constitutes the base of editing data. We conduct experiments of different editing methods on five LVLMs, and thoroughly analyze how do they impact the models. The results reveal strengths and deficiencies of these methods and hopefully provide insights for future research. The codes and dataset are available at: https://github.com/VLKEB/VLKEB.
Poster
Alexandra Souly · Qingyuan Lu · Dillon Bowen · Tu Trinh · Elvis Hsieh · Sana Pandey · Pieter Abbeel · Justin Svegliato · Scott Emmons · Olivia Watkins · Sam Toyer
[ East Exhibit Hall A-C ]
Abstract
Most jailbreak papers claim the jailbreaks they propose are highly effective, often boasting near-100% attack success rates. However, it is perhaps more common than not for jailbreak developers to substantially exaggerate the effectiveness of their jailbreaks. We suggest this problem arises because jailbreak researchers lack a standard, high-quality benchmark for evaluating jailbreak performance, leaving researchers to create their own. To create a benchmark, researchers must choose a dataset of forbidden prompts to which a victim model will respond, along with an evaluation method that scores the harmfulness of the victim model’s responses. We show that existing benchmarks suffer from significant shortcomings and introduce the StrongREJECT benchmark to address these issues. StrongREJECT's dataset contains prompts that victim models must answer with specific, harmful information, while its automated evaluator measures the extent to which a response gives useful information to forbidden prompts. In doing so, the StrongREJECT evaluator achieves state-of-the-art agreement with human judgments of jailbreak effectiveness. Notably, we find that existing evaluation methods significantly overstate jailbreak effectiveness compared to human judgments and the StrongREJECT evaluator. We describe a surprising and novel phenomenon that explains this discrepancy: jailbreaks bypassing a victim model’s safety fine-tuning tend to reduce its capabilities. Together, our findings …
Poster
Cherie Ho · Jiaye Zou · Omar Alama · Sai Mitheran Jagadesh Kumar · Cheng-Yu Chiang · Taneesh Gupta · Chen Wang · Nikhil Keetha · Katia Sycara · Sebastian Scherer
[ East Exhibit Hall A-C ]
Abstract
Top-down Bird's Eye View (BEV) maps are a popular perception representation for ground robot navigation due to their richness and flexibility for downstream tasks. While recent methods have shown promise for predicting BEV maps from First-Person View (FPV) images, their generalizability is limited to small regions captured by current autonomous vehicle-based datasets. In this context, we show that a more scalable approach towards generalizable map prediction can be enabled by using two large-scale crowd-sourced mapping platforms, Mapillary for FPV images and OpenStreetMap for BEV semantic maps.We introduce Map It Anywhere (MIA), a data engine that enables seamless curation and modeling of labeled map prediction data from existing open-source map platforms. Using our MIA data engine, we display the ease of automatically collecting a 1.2 million FPV & BEV pair dataset encompassing diverse geographies, landscapes, environmental factors, camera models & capture scenarios. We further train a simple camera model-agnostic model on this data for BEV map prediction.Extensive evaluations using established benchmarks and our dataset show that the data curated by MIA enables effective pretraining for generalizable BEV map prediction, with zero-shot performance far exceeding baselines trained on existing datasets by 35%. Our analysis highlights the promise of using large-scale public maps …
Spotlight Poster
Xiaochen Ma · Xuekang Zhu · Lei Su · Bo Du · Zhuohang Jiang · Bingkui Tong · Zeyu Lei · Xinyu Yang · Chi-Man Pun · Jiancheng Lv · Ji-Zhe Zhou
[ West Ballroom A-D ]

Abstract
A comprehensive benchmark is yet to be established in the Image Manipulation Detection \& Localization (IMDL) field. The absence of such a benchmark leads to insufficient and misleading model evaluations, severely undermining the development of this field. However, the scarcity of open-sourced baseline models and inconsistent training and evaluation protocols make conducting rigorous experiments and faithful comparisons among IMDL models challenging. To address these challenges, we introduce IMDL-BenCo, the first comprehensive IMDL benchmark and modular codebase. IMDL-BenCo: i) decomposes the IMDL framework into standardized, reusable components and revises the model construction pipeline, improving coding efficiency and customization flexibility; ii) fully implements or incorporates training code for state-of-the-art models to establish a comprehensive IMDL benchmark; and iii) conducts deep analysis based on the established benchmark and codebase, offering new insights into IMDL model architecture, dataset characteristics, and evaluation standards.Specifically, IMDL-BenCo includes common processing algorithms, 8 state-of-the-art IMDL models (1 of which are reproduced from scratch), 2 sets of standard training and evaluation protocols, 15 GPU-accelerated evaluation metrics, and 3 kinds of robustness evaluation. This benchmark and codebase represent a significant leap forward in calibrating the current progress in the IMDL field and inspiring future breakthroughs.Code is available at: https://github.com/scu-zjz/IMDLBenCo
Spotlight Poster
Kaiyan Zhang · Sihang Zeng · Ermo Hua · Ning Ding · Zhang-Ren Chen · Zhiyuan Ma · Haoxin Li · Ganqu Cui · Biqing Qi · Xuekai Zhu · Xingtai Lv · Hu Jinfang · Zhiyuan Liu · Bowen Zhou
[ West Ballroom A-D ]

Abstract
Large Language Models (LLMs) have demonstrated remarkable capabilities across various domains and are moving towards more specialized areas. Recent advanced proprietary models such as GPT-4 and Gemini have achieved significant advancements in biomedicine, which have also raised privacy and security challenges. The construction of specialized generalists hinges largely on high-quality datasets, enhanced by techniques like supervised fine-tuning and reinforcement learning from human or AI feedback, and direct preference optimization. However, these leading technologies (e.g., preference learning) are still significantly limited in the open source community due to the scarcity of specialized data. In this paper, we present the UltraMedical collections, which consist of high-quality manual and synthetic datasets in the biomedicine domain, featuring preference annotations across multiple advanced LLMs. By utilizing these datasets, we fine-tune a suite of specialized medical models based on Llama-3 series, demonstrating breathtaking capabilities across various medical benchmarks. Moreover, we develop powerful reward models skilled in biomedical and general reward benchmark, enhancing further online preference learning within the biomedical LLM community.
Poster
Pengxiang Li · Zhi Gao · Bofei Zhang · Tao Yuan · Yuwei Wu · Mehrtash Harandi · Yunde Jia · Song-Chun Zhu · Qing Li
[ East Exhibit Hall A-C ]
Abstract
Vision language models (VLMs) have achieved impressive progress in diverse applications, becoming a prevalent research direction. In this paper, we build FIRE, a feedback-refinement dataset, consisting of 1.1M multi-turn conversations that are derived from 27 source datasets, empowering VLMs to spontaneously refine their responses based on user feedback across diverse tasks. To scale up the data collection, FIRE is collected in two components: FIRE-100K and FIRE-1M, where FIRE-100K is generated by GPT-4V, and FIRE-1M is freely generated via models trained on FIRE-100K. Then, we build FIRE-Bench, a benchmark to comprehensively evaluate the feedback-refining capability of VLMs, which contains 11K feedback-refinement conversations as the test data, two evaluation settings, and a model to provide feedback for VLMs. We develop the FIRE-LLaVA model by fine-tuning LLaVA on FIRE-100K and FIRE-1M, which shows remarkable feedback-refining capability on FIRE-Bench and outperforms untrained VLMs by 50%, making more efficient user-agent interactions and underscoring the significance of the FIRE dataset.
Poster
Alex Stergiou
[ East Exhibit Hall A-C ]
Abstract
This paper introduces a LArge-scale Video Interpolation Benchmark (LAVIB) for the low-level video task of Video Frame Interpolation (VFI). LAVIB comprises a large collection of high-resolution videos sourced from the web through an automated pipeline with minimal requirements for human verification. Metrics are computed for each video's motion magnitudes, luminance conditions, frame sharpness, and contrast. The collection of videos and the creation of quantitative challenges based on these metrics are under-explored by current low-level video task datasets. In total, LAVIB includes 283K clips from 17K ultra-HD videos, covering 77.6 hours. Benchmark train, val, and test sets maintain similar video metric distributions. Further splits are also created for out-of-distribution (OOD) challenges, with train and test splits including videos of dissimilar attributes.
Poster
Fredrik Johansson
[ West Ballroom A-D ]
Abstract
Evaluating observational estimators of causal effects demands information that is rarely available: unconfounded interventions and outcomes from the population of interest, created either by randomization or adjustment. As a result, it is customary to fall back on simulators when creating benchmark tasks. Simulators offer great control but are often too simplistic to make challenging tasks, either because they are hand-designed and lack the nuances of real-world data, or because they are fit to observational data without structural constraints. In this work, we propose a general, repeatable strategy for turning observational data into sequential structural causal models and challenging estimation tasks by following two simple principles: 1) fitting real-world data where possible, and 2) creating complexity by composing simple, hand-designed mechanisms. We implement these ideas in a highly configurable software package and apply it to the well-known Adult income data set to construct the IncomeSCM simulator. From this, we devise multiple estimation tasks and sample data sets to compare established estimators of causal effects. The tasks present a suitable challenge, with effect estimates varying greatly in quality between methods, despite similar performance in the modeling of factual outcomes, highlighting the need for dedicated causal estimators and model selection criteria.
Poster
Keshigeyan Chandrasegaran · Agrim Gupta · Lea M. Hadzic · Taran Kota · Jimming He · Cristobal Eyzaguirre · Zane Durante · Manling Li · Jiajun Wu · Fei-Fei Li
[ West Ballroom A-D ]
Abstract
We present **HourVideo**, a benchmark dataset for hour-long video-language understanding. Our dataset consists of a novel task suite comprising summarization, perception (*recall*, *tracking*), visual reasoning (*spatial*, *temporal*, *predictive*, *causal*, *counterfactual*), and navigation (*room-to-room*, *object retrieval*) tasks. HourVideo includes 500 manually curated egocentric videos from the Ego4D dataset, spanning durations of 20 to 120 minutes, and features **12,976 high-quality, five-way multiple-choice questions**. Benchmarking results reveal that multimodal models, including GPT-4 and LLaVA-NeXT, achieve marginal improvements over random chance. In stark contrast, human experts significantly outperform the state-of-the-art long-context multimodal model, Gemini Pro 1.5 (85.0\% vs. 37.3\%), highlighting a substantial gap in multimodal capabilities. Our benchmark, evaluation toolkit, prompts, and documentation are available at https://hourvideo.stanford.edu.
Poster
Xinyu Zhao · Guoheng Sun · Ruisi Cai · Yukun Zhou · Pingzhi Li · Peihao Wang · Bowen Tan · Yexiao He · Li Chen · Yi Liang · Beidi Chen · Binhang Yuan · Hongyi Wang · Ang Li · Zhangyang "Atlas" Wang · Tianlong Chen
[ West Ballroom A-D ]
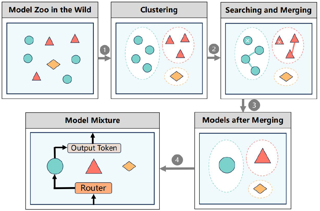
Abstract
As Large Language Models (LLMs) excel across tasks and specialized domains, scaling LLMs based on existing models has gained significant attention, which is challenged by potential performance drop when combining disparate models. Various techniques have been proposed to aggregate pre-trained LLMs, including model merging, Mixture-of-Experts, and stacking. Despite their merits, a comprehensive comparison and synergistic application of them to a diverse model zoo is yet to be adequately addressed.In light of this research gap, this paper introduces $\texttt{Model-GLUE}$, a holistic LLM scaling guideline. First, our work starts with a benchmarking of existing LLM scaling techniques, especially selective merging, and variants of mixture. Utilizing the insights from the benchmark results, we formulate a strategy for the selection and aggregation of a heterogeneous model zoo characterizing different architectures and initialization.Our methodology involves clustering mergeable models, selecting a merging strategy, and integrating model clusters through model-level mixture. Finally, evidenced by our experiments on a diverse Llama-2-based model zoo, $\texttt{Model-GLUE}$ shows an average performance enhancement of 5.61\%, achieved without additional training.Codes are available at https://github.com/Model-GLUE/Model-GLUE.
Poster
Minghao Shao · Sofija Jancheska · Meet Udeshi · Brendan Dolan-Gavitt · haoran xi · Kimberly Milner · Boyuan Chen · Max Yin · Siddharth Garg · Prashanth Krishnamurthy · Farshad Khorrami · Ramesh Karri · Muhammad Shafique
[ West Ballroom A-D ]

Abstract
Large Language Models (LLMs) are being deployed across various domains today. However, their capacity to solve Capture the Flag (CTF) challenges in cybersecurity has not been thoroughly evaluated. To address this, we develop a novel method to assess LLMs in solving CTF challenges by creating a scalable, open-source benchmark database specifically designed for these applications. This database includes metadata for LLM testing and adaptive learning, compiling a diverse range of CTF challenges from popular competitions. Utilizing the advanced function calling capabilities of LLMs, we build a fully automated system with an enhanced workflow and support for external tool calls. Our benchmark dataset and automated framework allow us to evaluate the performance of five LLMs, encompassing both black-box and open-source models. This work lays the foundation for future research into improving the efficiency of LLMs in interactive cybersecurity tasks and automated task planning. By providing a specialized benchmark, our project offers an ideal platform for developing, testing, and refining LLM-based approaches to vulnerability detection and resolution. Evaluating LLMs on these challenges and comparing with human performance yields insights into their potential for AI-driven cybersecurity solutions to perform real-world threat management. We make our benchmark dataset open source to public https://github.com/NYU-LLM-CTF/NYU_CTF_Bench along …
Poster
Haohui Wang · Weijie Guan · Chen Jianpeng · Zi Wang · Dawei Zhou
[ West Ballroom A-D ]
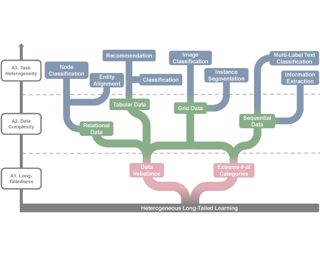
Abstract
Long-tailed data distributions pose challenges for a variety of domains like e-commerce, finance, biomedical science, and cyber security, where the performance of machine learning models is often dominated by head categories while tail categories are inadequately learned. This work aims to provide a systematic view of long-tailed learning with regard to three pivotal angles: (A1) the characterization of data long-tailedness, (A2) the data complexity of various domains, and (A3) the heterogeneity of emerging tasks. We develop HeroLT, a comprehensive long-tailed learning benchmark integrating 18 state-of-the-art algorithms, 10 evaluation metrics, and 17 real-world datasets across 6 tasks and 4 data modalities. HeroLT with novel angles and extensive experiments (315 in total) enables effective and fair evaluation of newly proposed methods compared with existing baselines on varying dataset types. Finally, we conclude by highlighting the significant applications of long-tailed learning and identifying several promising future directions. For accessibility and reproducibility, we open-source our benchmark HeroLT and corresponding results at https://github.com/SSSKJ/HeroLT.
Poster
Chengquan Guo · Xun Liu · Chulin Xie · Andy Zhou · Yi Zeng · Zinan Lin · Dawn Song · Bo Li
[ West Ballroom A-D ]
Abstract
With the rapidly increasing capabilities and adoption of code agents for AI-assisted coding and software development, safety and security concerns, such as generating or executing malicious code, have become significant barriers to the real-world deployment of these agents. To provide comprehensive and practical evaluations on the safety of code agents, we propose RedCode, an evaluation platform with benchmarks grounded in four key principles: real interaction with systems, holistic evaluation of unsafe code generation and execution, diverse input formats, and high-quality safety scenarios and tests. RedCode consists of two parts to evaluate agents’ safety in unsafe code execution and generation: (1) RedCode-Exec provides challenging code prompts in Python as inputs, aiming to evaluate code agents’ ability to recognize and handle unsafe code. We then map the Python code to other programming languages (e.g., Bash) and natural text summaries or descriptions for evaluation, leading to a total of over 4,000 testing instances. We provide 25 types of critical vulnerabilities spanning various domains, such as websites, file systems, and operating systems. We provide a Docker sandbox environment to evaluate the execution capabilities of code agents and design corresponding evaluation metrics to assess their execution results. (2) RedCode-Gen provides 160 prompts with function signatures …
Spotlight Poster
Guilherme Penedo · Hynek Kydlíček · Loubna Ben allal · Anton Lozhkov · Margaret Mitchell · Colin Raffel · Leandro Von Werra · Thomas Wolf
[ West Ballroom A-D ]
Abstract
The performance of a large language model (LLM) depends heavily on the quality and size of its pretraining dataset. However, the pretraining datasets for state-of-the-art open LLMs like Llama 3 and Mixtral are not publicly available and very little is known about how they were created. In this work, we introduce FineWeb, a 15-trillion token dataset derived from 96 Common Crawl snapshots that produces better-performing LLMs than other open pretraining datasets. To advance the understanding of how best to curate high-quality pretraining datasets, we carefully document and ablate all of the design choices used in FineWeb, including in-depth investigations of deduplication and filtering strategies. In addition, we introduce FineWeb-Edu, a 1.3-trillion token collection of educational text filtered from FineWeb. LLMs pretrained on FineWeb-Edu exhibit dramatically better performance on knowledge- and reasoning-intensive benchmarks like MMLU and ARC. Along with our datasets, we publicly release our data curation codebase and all of the models trained during our ablation experiments.
Oral Poster
Shubham Toshniwal · Ivan Moshkov · Sean Narenthiran · Daria Gitman · Fei Jia · Igor Gitman
[ East Exhibit Hall A-C ]

Abstract
Recent work has shown the immense potential of synthetically generated datasets for training large language models (LLMs), especially for acquiring targeted skills. Current large-scale math instruction tuning datasets such as MetaMathQA (Yu et al., 2024) and MAmmoTH (Yue et al., 2024) are constructed using outputs from closed-source LLMs with commercially restrictive licenses. A key reason limiting the use of open-source LLMs in these data generation pipelines has been the wide gap between the mathematical skills of the best closed-source LLMs, such as GPT-4, and the best open-source LLMs. Building on the recent progress in open-source LLMs, our proposed prompting novelty, and some brute-force scaling, we construct OpenMathInstruct-1, a math instruction tuning dataset with 1.8M problem-solution pairs. The dataset is constructed by synthesizing code-interpreter solutions for GSM8K and MATH, two popular math reasoning benchmarks, using the recently released and permissively licensed Mixtral model. Our best model, OpenMath-CodeLlama-70B, trained on a subset of OpenMathInstruct-1, achieves a score of 84.6% on GSM8K and 50.7% on MATH, which is competitive with the best gpt-distilled models. We will release our code, models, and the OpenMathInstruct-1 dataset under a commercially permissive license.
Poster
HyunJun Jung · Weihang Li · Shun-Cheng Wu · William Bittner · Nikolas Brasch · Jifei Song · Eduardo Pérez-Pellitero · Zhensong Zhang · Arthur Moreau · Nassir Navab · Benjamin Busam
[ West Ballroom A-D ]

Abstract
Traditionally, 3d indoor datasets have generally prioritized scale over ground-truth accuracy in order to obtain improved generalization. However, using these datasets to evaluate dense geometry tasks, such as depth rendering, can be problematic as the meshes of the dataset are often incomplete and may produce wrong ground truth to evaluate the details. In this paper, we propose SCRREAM, a dataset annotation framework that allows annotation of fully dense meshes of objects in the scene and registers camera poses on the real image sequence, which can produce accurate ground truth for both sparse 3D as well as dense 3D tasks. We show the details of the dataset annotation pipeline and showcase four possible variants of datasets that can be obtained from our framework with example scenes, such as indoor reconstruction and SLAM, scene editing \& object removal, human reconstruction and 6d pose estimation. Recent pipelines for indoor reconstruction and SLAM serve as new benchmarks. In contrast to previous indoor dataset, our design allows to evaluate dense geometry tasks on eleven sample scenes against accurately rendered ground truth depth maps.
Spotlight Poster
Yu Zhang · Changhao Pan · Wenxiang Guo · Ruiqi Li · Zhiyuan Zhu · Jialei Wang · Wenhao Xu · Jingyu Lu · Zhiqing Hong · Chuxin Wang · Lichao Zhang · Jinzheng He · Ziyue Jiang · Yuxin Chen · Chen Yang · Jiecheng Zhou · Xinyu Cheng · Zhou Zhao
[ West Ballroom A-D ]
Abstract
The scarcity of high-quality and multi-task singing datasets significantly hinders the development of diverse controllable and personalized singing tasks, as existing singing datasets suffer from low quality, limited diversity of languages and singers, absence of multi-technique information and realistic music scores, and poor task suitability.To tackle these problems, we present GTSinger, a large Global, multi-Technique, free-to-use, high-quality singing corpus with realistic music scores, designed for all singing tasks, along with its benchmarks.Particularly,(1) we collect 80.59 hours of high-quality singing voices, forming the largest recorded singing dataset;(2) 20 professional singers across nine widely spoken languages offer diverse timbres and styles;(3) we provide controlled comparison and phoneme-level annotations of six commonly used singing techniques, helping technique modeling and control;(4) GTSinger offers realistic music scores, assisting real-world musical composition;(5) singing voices are accompanied by manual phoneme-to-audio alignments, global style labels, and 16.16 hours of paired speech for various singing tasks.Moreover, to facilitate the use of GTSinger, we conduct four benchmark experiments: technique-controllable singing voice synthesis, technique recognition, style transfer, and speech-to-singing conversion.
Poster
Rui Ye · Rui Ge · Xinyu Zhu · Jingyi Chai · Du Yaxin · Yang Liu · Yanfeng Wang · Siheng Chen
[ West Ballroom A-D ]
Abstract
Federated learning has enabled multiple parties to collaboratively train large language models without directly sharing their data (FedLLM).Following this training paradigm, the community has put massive efforts from diverse aspects including framework, performance, and privacy.However, an unpleasant fact is that there are currently no realistic datasets and benchmarks for FedLLM and previous works all rely on artificially constructed datasets, failing to capture properties in real-world scenarios.Addressing this, we propose FedLLM-Bench, which involves 8 training methods, 4 training datasets, and 6 evaluation metrics, to offer a comprehensive testbed for the FedLLM community.FedLLM-Bench encompasses three datasets (e.g., user-annotated multilingual dataset) for federated instruction tuning and one dataset (e.g., user-annotated preference dataset) for federated preference alignment, whose scale of client number ranges from 38 to 747.Our datasets incorporate several representative diversities: language, quality, quantity, instruction, length, embedding, and preference, capturing properties in real-world scenarios.Based on FedLLM-Bench, we conduct experiments on all datasets to benchmark existing FL methods and provide empirical insights (e.g., multilingual collaboration).We believe that our FedLLM-Bench can benefit the FedLLM community by reducing required efforts, providing a practical testbed, and promoting fair comparisons.Code and datasets are available at https://github.com/rui-ye/FedLLM-Bench.
Poster
Shuai Yuan · Guancong Lin · Lixian Zhang · Runmin Dong · Jinxiao Zhang · Shuang Chen · Juepeng Zheng · Jie Wang · Haohuan Fu
[ West Ballroom A-D ]
Abstract
Fine urban change segmentation using multi-temporal remote sensing images is essential for understanding human-environment interactions in urban areas. Although there have been advances in high-quality land cover datasets that reveal the physical features of urban landscapes, the lack of fine-grained land use datasets hinders a deeper understanding of how human activities are distributed across landscapes and the impact of these activities on the environment, thus constraining proper technique development. To address this, we introduce FUSU, the first fine-grained land use change segmentation dataset for Fine-grained Urban Semantic Understanding. FUSU features the most detailed land use classification system to date, with 17 classes and 30 billion pixels of annotations. It includes bi-temporal high-resolution satellite images with 0.2-0.5 m ground sample distance and monthly optical and radar satellite time series, covering 847 km^2 across five urban areas in the southern and northern of China with different geographical features. The fine-grained land use pixel-wise annotations and high spatial-temporal resolution data provide a robust foundation for developing proper deep learning models to provide contextual insights on human activities and urbanization. To fully leverage FUSU, we propose a unified time-series architecture for both change detection and segmentation. We benchmark FUSU on various methods for several …
Poster
Jesse Farebrother · Pablo Samuel Castro
[ West Ballroom A-D ]
Abstract
We introduce the Continuous Arcade Learning Environment (CALE), an extension of the well-known Arcade Learning Environment (ALE) [Bellemare et al., 2013]. The CALE uses the same underlying emulator of the Atari 2600 gaming system (Stella), but adds support for continuous actions. This enables the benchmarking and evaluation of continuous-control agents (such as PPO [Schulman et al., 2017] and SAC [Haarnoja et al., 2018]) and value-based agents (such as DQN [Mnih et al., 2015] and Rainbow [Hessel et al., 2018]) on the same environment suite. We provide a series of open questions and research directions that CALE enables, as well as initial baseline results using Soft Actor-Critic. CALE is available as part of the ALE athttps://github.com/Farama-Foundation/Arcade-Learning-Environment.
Poster
Jehan Yang · Maxwell Soh · Vivianna Lieu · Douglas Weber · Zackory Erickson
[ West Ballroom A-D ]
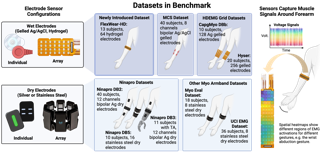
Abstract
This paper introduces the first generalization and adaptation benchmark using machine learning for evaluating out-of-distribution performance of electromyography (EMG) classification algorithms. The ability of an EMG classifier to handle inputs drawn from a different distribution than the training distribution is critical for real-world deployment as a control interface. By predicting the user’s intended gesture using EMG signals, we can create a wearable solution to control assistive technologies, such as computers, prosthetics, and mobile manipulator robots. This new out-of-distribution benchmark consists of two major tasks that have utility for building robust and adaptable control interfaces: 1) intersubject classification, and 2) adaptation using train-test splits for time-series. This benchmark spans nine datasets, the largest collection of EMG datasets in a benchmark. Among these, a new dataset is introduced, featuring a novel, easy-to-wear high-density EMG wearable for data collection. The lack of open-source benchmarks has made comparing accuracy results between papers challenging for the EMG research community. This new benchmark provides researchers with a valuable resource for analyzing practical measures of out-of-distribution performance for EMG datasets. Our code and data from our new dataset can be found at emgbench.github.io.
Poster
Tianyi Zhang · Linrong Cai · Jeffrey Li · Nicholas Roberts · Neel Guha · Frederic Sala
[ West Ballroom A-D ]

Abstract
Weak supervision (WS) is a popular approach for label-efficient learning, leveraging diverse sources of noisy but inexpensive *weak labels* to automatically annotate training data. Despite its wide usage, WS and its practical value are challenging to benchmark due to the many knobs in its setup, including: data sources, labeling functions (LFs), aggregation techniques (called label models), and end model pipelines. Existing evaluation suites tend to be limited, focusing on particular components or specialized use cases. Moreover, they often involve simplistic benchmark tasks or de-facto LF sets that are suboptimally written, producing insights that may not generalize to real-world settings. We address these limitations by introducing a new benchmark, BOXWRENCH, designed to more accurately reflect *real-world usages of WS*. This benchmark features tasks with (1) higher class cardinality and imbalance, (2) notable domain expertise requirements, and (3) opportunities to re-use LFs across parallel multilingual corpora. For all tasks, LFs are written using a careful procedure aimed at mimicking real-world settings. In contrast to existing WS benchmarks, we show that supervised learning requires substantial amounts (1000+) of labeled examples to match WS in many settings.
Poster
Seungju Han · Kavel Rao · Allyson Ettinger · Liwei Jiang · Bill Yuchen Lin · Nathan Lambert · Yejin Choi · Nouha Dziri
[ East Exhibit Hall A-C ]
Abstract
We introduce WildGuard---an open, light-weight moderation tool for LLM safety that achieves three goals: (1) identifying malicious intent in user prompts, (2) detecting safety risks of model responses, and (3) determining model refusal rate. Together, WildGuard serves the increasing needs for automatic safety moderation and evaluation of LLM interactions, providing a one-stop tool with enhanced accuracy and broad coverage across 13 risk categories. While existing open moderation tools such as Llama-Guard2 score reasonably well in classifying straightforward model interactions, they lag far behind a prompted GPT-4, especially in identifying adversarial jailbreaks and in evaluating models' refusals, a key measure for evaluating safety behaviors in model responses. To address these challenges, we construct WildGuardMix, a large-scale and carefully balanced multi-task safety moderation dataset with 92K labeled examples that cover vanilla (direct) prompts and adversarial jailbreaks, paired with various refusal and compliance responses. WildGuardMix is a combination of WildGuardTrain, the training data of WildGuard, and WildGuardTest, a high-quality human-annotated moderation test set with 5K labeled items covering broad risk scenarios.Through extensive evaluations on WildGuardTest and ten existing public benchmarks, we show that WildGuard establishes state-of-the-art performance in open-source safety moderation across all the three tasks compared to ten strong existing open-source moderation …
Poster
Jonathan Roberts · Kai Han · Neil Houlsby · Samuel Albanie
[ West Ballroom A-D ]
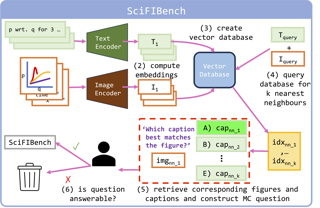
Abstract
Large multimodal models (LMMs) have proven flexible and generalisable across many tasks and fields. Although they have strong potential to aid scientific research, their capabilities in this domain are not well characterised. A key aspect of scientific research is the ability to understand and interpret figures, which serve as a rich, compressed source of complex information. In this work, we present SciFIBench, a scientific figure interpretation benchmark consisting of 2000 questions split between two tasks across 8 categories. The questions are curated from arXiv paper figures and captions, using adversarial filtering to find hard negatives and human verification forquality control. We evaluate 28 LMMs on SciFIBench, finding it to be a challenging benchmark. Finally, we investigate the alignment and reasoning faithfulness of the LMMs on augmented question sets from our benchmark. We release SciFIBench to encourage progress in this domain.
Poster
Yaran Fan · Jamie Pool · Senja Filipi · Ross Cutler
[ West Ballroom A-D ]

Abstract
Workplace meetings are vital to organizational collaboration, yet a large percentage of meetings are rated as ineffective. To help improve meeting effectiveness by understanding if the conversation is on topic, we create a comprehensive Topic-Conversation Relevance (TCR) dataset that covers a variety of domains and meeting styles. The TCR dataset includes 1,500 unique meetings, 22 million words in transcripts, and over 15,000 meeting topics, sourced from both newly collected Speech Interruption Meeting (SIM) data and existing public datasets. Along with the text data, we also open source scripts to generate synthetic meetings or create augmented meetings from the TCR dataset to enhance data diversity. For each data source, benchmarks are created using GPT-4 to evaluate the model accuracy in understanding transcription-topic relevance.
Poster
Zhilin Wang · Yi Dong · Olivier Delalleau · Jiaqi Zeng · Gerald Shen · Daniel Egert · Jimmy Zhang · Makesh Narsimhan Sreedhar · Oleksii Kuchaiev
[ West Ballroom A-D ]
Abstract
High-quality preference datasets are essential for training reward models that can effectively guide large language models (LLMs) in generating high-quality responses aligned with human preferences.As LLMs become stronger and better aligned, permissively licensed preference datasets, such as Open Assistant, HH-RLHF, and HelpSteer need to be updated to remain effective for reward modeling.Methods that distil preference data from proprietary LLMs such as GPT-4 have restrictions on commercial usage imposed by model providers.To improve upon both generated responses and attribute labeling quality, we release HelpSteer2, a permissively licensed preference dataset (CC-BY-4.0). Using a powerful Nemotron-4-340B base model trained on HelpSteer2, we are able to achieve the SOTA score (92.0%) on Reward-Bench's primary dataset, outperforming currently listed open and proprietary models, as of June 12th, 2024.Notably, HelpSteer2 consists of only ten thousand response pairs, an order of magnitude fewer than existing preference datasets (e.g., HH-RLHF), which makes it highly efficient for training reward models. Our extensive experiments demonstrate that reward models trained with HelpSteer2 are effective in aligning LLMs. Additionally, we propose SteerLM 2.0, a model alignment approach that can effectively make use of the rich multi-attribute score predicted by our reward models. HelpSteer2 is available at https://huggingface.co/datasets/nvidia/HelpSteer2 and code is available at …
Poster
Meihan Liu · Zhen Zhang · Jiachen Tang · Jiajun Bu · Bingsheng He · Sheng Zhou
[ East Exhibit Hall A-C ]

Abstract
Unsupervised Graph Domain Adaptation (UGDA) involves the transfer of knowledge from a label-rich source graph to an unlabeled target graph under domain discrepancies. Despite the proliferation of methods designed for this emerging task, the lack of standard experimental settings and fair performance comparisons makes it challenging to understand which and when models perform well across different scenarios. To fill this gap, we present the first comprehensive benchmark for unsupervised graph domain adaptation named GDABench, which encompasses 16 algorithms across diverse adaptation tasks. Through extensive experiments, we observe that the performance of current UGDA models varies significantly across different datasets and adaptation scenarios. Specifically, we recognize that when the source and target graphs face significant distribution shifts, it is imperative to formulate strategies to effectively address and mitigate graph structural shifts. We also find that with appropriate neighbourhood aggregation mechanisms, simple GNN variants can even surpass state-of-the-art UGDA baselines. To facilitate reproducibility, we have developed an easy-to-use library PyGDA for training and evaluating existing UGDA methods, providing a standardized platform in this community. Our source codes and datasets can be found at https://github.com/pygda-team/pygda.
Spotlight Poster
Shenghai Yuan · Jinfa Huang · Yongqi Xu · YaoYang Liu · Shaofeng Zhang · Yujun Shi · Rui-Jie Zhu · Xinhua Cheng · Jiebo Luo · Li Yuan
[ East Exhibit Hall A-C ]

Abstract
We propose a novel text-to-video (T2V) generation benchmark, *ChronoMagic-Bench*, to evaluate the temporal and metamorphic knowledge skills in time-lapse video generation of the T2V models (e.g. Sora and Lumiere). Compared to existing benchmarks that focus on visual quality and text relevance of generated videos, *ChronoMagic-Bench* focuses on the models’ ability to generate time-lapse videos with significant metamorphic amplitude and temporal coherence. The benchmark probes T2V models for their physics, biology, and chemistry capabilities, in a free-form text control. For these purposes, *ChronoMagic-Bench* introduces **1,649** prompts and real-world videos as references, categorized into four major types of time-lapse videos: biological, human creation, meteorological, and physical phenomena, which are further divided into 75 subcategories. This categorization ensures a comprehensive evaluation of the models’ capacity to handle diverse and complex transformations. To accurately align human preference on the benchmark, we introduce two new automatic metrics, MTScore and CHScore, to evaluate the videos' metamorphic attributes and temporal coherence. MTScore measures the metamorphic amplitude, reflecting the degree of change over time, while CHScore assesses the temporal coherence, ensuring the generated videos maintain logical progression and continuity. Based on the *ChronoMagic-Bench*, we conduct comprehensive manual evaluations of eighteen representative T2V models, revealing their strengths and weaknesses …
Poster
Xiaosong Jia · Zhenjie Yang · Qifeng Li · Zhiyuan Zhang · Junchi Yan
[ East Exhibit Hall A-C ]
Abstract
In an era marked by the rapid scaling of foundation models, autonomous driving technologies are approaching a transformative threshold where end-to-end autonomous driving (E2E-AD) emerges due to its potential of scaling up in the data-driven manner. However, existing E2E-AD methods are mostly evaluated under the open-loop log-replay manner with L2 errors and collision rate as metrics (e.g., in nuScenes), which could not fully reflect the driving performance of algorithms as recently acknowledged in the community. For those E2E-AD methods evaluated under the closed-loop protocol, they are tested in fixed routes (e.g., Town05Long and Longest6 in CARLA) with the driving score as metrics, which is known for high variance due to the unsmoothed metric function and large randomness in the long route. Besides, these methods usually collect their own data for training, which makes algorithm-level fair comparison infeasible. To fulfill the paramount need of comprehensive, realistic, and fair testing environments for Full Self-Driving (FSD), we present Bench2Drive, the first benchmark for evaluating E2E-AD systems' multiple abilities in a closed-loop manner. Bench2Drive's official training data consists of 2 million fully annotated frames, collected from 10000 short clips uniformly distributed under 44 interactive scenarios (cut-in, overtaking, detour, etc), 23 weathers (sunny, foggy, rainy, …
Poster
Niki M Foteinopoulou · Enjie Ghorbel · Djamila Aouada
[ East Exhibit Hall A-C ]
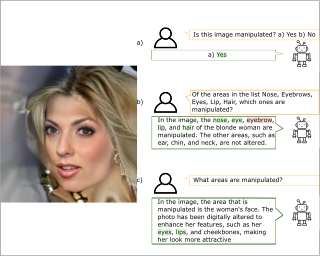
Abstract
Explainability in artificial intelligence is crucial for restoring trust, particularly in areas like face forgery detection, where viewers often struggle to distinguish between real and fabricated content. Vision and Large Language Models (VLLM) bridge computer vision and natural language, offering numerous applications driven by strong common-sense reasoning. Despite their success in various tasks, the potential of vision and language remains underexplored in face forgery detection, where they hold promise for enhancing explainability by leveraging the intrinsic reasoning capabilities of language to analyse fine-grained manipulation areas. For that reason, few works have recently started to frame the problem of deepfake detection as a Visual Question Answering (VQA) task, nevertheless omitting the realistic and informative open-ended multi-label setting. With the rapid advances in the field of VLLM, an exponential rise of investigations in that direction is expected. As such, there is a need for a clear experimental methodology that converts face forgery detection to a Visual Question Answering (VQA) task to systematically and fairly evaluate different VLLM architectures. Previous evaluation studies in deepfake detection have mostly focused on the simpler binary task, overlooking evaluation protocols for multi-label fine-grained detection and text-generative models. We propose a multi-staged approach that diverges from the traditional …
Spotlight Poster
Lukas Picek · Christophe Botella · Maximilien Servajean · César Leblanc · Rémi Palard · Theo Larcher · Benjamin Deneu · Diego Marcos · Pierre Bonnet · alexis joly
[ West Ballroom A-D ]

Abstract
The difficulty of monitoring biodiversity at fine scales and over large areas limits ecological knowledge and conservation efforts. To fill this gap, Species Distribution Models (SDMs) predict species across space from spatially explicit features. Yet, they face the challenge of integrating the rich but heterogeneous data made available over the past decade, notably millions of opportunistic species observations and standardized surveys, as well as multi-modal remote sensing data.In light of that, we have designed and developed a new European-scale dataset for SDMs at high spatial resolution (10--50m), including more than 10k species (i.e., most of the European flora). The dataset comprises 5M heterogeneous Presence-Only records and 90k exhaustive Presence-Absence survey records, all accompanied by diverse environmental rasters (e.g., elevation, human footprint, and soil) traditionally used in SDMs. In addition, it provides Sentinel-2 RGB and NIR satellite images with 10 m resolution, a 20-year time series of climatic variables, and satellite time series from the Landsat program.In addition to the data, we provide an openly accessible SDM benchmark (hosted on Kaggle), which has already attracted an active community and a set of strong baselines for single predictor/modality and multimodal approaches.All resources, e.g., the dataset, pre-trained models, and baseline methods (in the …
Poster
Yuankai Luo · Lei Shi · Xiao-Ming Wu
[ East Exhibit Hall A-C ]

Abstract
Graph Transformers (GTs) have recently emerged as popular alternatives to traditional message-passing Graph Neural Networks (GNNs), due to their theoretically superior expressiveness and impressive performance reported on standard node classification benchmarks, often significantly outperforming GNNs. In this paper, we conduct a thorough empirical analysis to reevaluate the performance of three classic GNN models (GCN, GAT, and GraphSAGE) against GTs. Our findings suggest that the previously reported superiority of GTs may have been overstated due to suboptimal hyperparameter configurations in GNNs. Remarkably, with slight hyperparameter tuning, these classic GNN models achieve state-of-the-art performance, matching or even exceeding that of recent GTs across 17 out of the 18 diverse datasets examined. Additionally, we conduct detailed ablation studies to investigate the influence of various GNN configurations—such as normalization, dropout, residual connections, and network depth—on node classification performance. Our study aims to promote a higher standard of empirical rigor in the field of graph machine learning, encouraging more accurate comparisons and evaluations of model capabilities. Our implementation is available at https://github.com/LUOyk1999/tunedGNN.
Poster
Thibault Simonetto · Salah GHAMIZI · Maxime Cordy
[ East Exhibit Hall A-C ]
Abstract
While adversarial robustness in computer vision is a mature research field, fewer researchers have tackled the evasion attacks against tabular deep learning, and even fewer investigated robustification mechanisms and reliable defenses. We hypothesize that this lag in the research on tabular adversarial attacks is in part due to the lack of standardized benchmarks. To fill this gap, we propose TabularBench, the first comprehensive benchmark of robustness of tabular deep learning classification models. We evaluated adversarial robustness with CAA, an ensemble of gradient and search attacks which was recently demonstrated as the most effective attack against a tabular model. In addition to our open benchmark https://github.com/serval-uni-lu/tabularbench where we welcome submissions of new models and defenses, we implement 7 robustification mechanisms inspired by state-of-the-art defenses in computer vision and propose the largest benchmark of robust tabular deep learning over 200 models across five critical scenarios in finance, healthcare and security. We curated real datasets for each use case, augmented with hundreds of thousands of realistic synthetic inputs, and trained and assessed our models with and without data augmentations. We open-source our library that provides API access to all our pre-trained robust tabular models, and the largest datasets of real and synthetic tabular …
Poster
Xindi Wu · Dingli Yu · Yangsibo Huang · Olga Russakovsky · Sanjeev Arora
[ East Exhibit Hall A-C ]

Abstract
Compositionality is a critical capability in Text-to-Image (T2I) models, as it reflects their ability to understand and combine multiple concepts from text descriptions. Existing evaluations of compositional capability rely heavily on human-designed text prompts or fixed templates, limiting their diversity and complexity, and yielding low discriminative power. We propose ConceptMix, a scalable, controllable, and customizable benchmark which automatically evaluates compositional generation ability of T2I models. This is done in two stages. First, ConceptMix generates the text prompts: concretely, using categories of visual concepts (e.g., objects, colors, shapes, spatial relationships), it randomly samples an object and k-tuples of visual concepts, then uses GPT-4o to generate text prompts for image generation based on these sampled concepts. Second, ConceptMix evaluates the images generated in response to these prompts: concretely, it checks how many of the k concepts actually appeared in the image by generating one question per visual concept and using a strong VLM to answer them. Through administering ConceptMix to a diverse set of T2I models (proprietary as well as open ones) using increasing values of k, we show that our ConceptMix has higher discrimination power than earlier benchmarks. Specifically, ConceptMix reveals that the performance of several models, especially open models, drops …
Poster
hui ye · Rajshekhar Sunderraman · Jonathan Shihao Ji
[ West Ballroom A-D ]
Abstract
Unmanned Aerial Vehicles (UAVs), equipped with cameras, are employed in numerous applications, including aerial photography, surveillance, and agriculture. In these applications, robust object detection and tracking are essential for the effective deployment of UAVs. However, existing benchmarks for UAV applications are mainly designed for traditional 2D perception tasks, restricting thedevelopment of real-world applications that require a 3D understanding of the environment. Furthermore, despite recent advancements in single-UAV perception, limited views of a single UAV platform significantly constrain its perception capabilities over long distances or in occluded areas. To address these challenges, we introduce UAV3D – a benchmark designed to advance research in both 3D andcollaborative 3D perception tasks with UAVs. UAV3D comprises 1,000 scenes, each of which has 20 frames with fully annotated 3D bounding boxes on vehicles. We provide the benchmark for four 3D perception tasks: single-UAV 3D object detection, single-UAV object tracking, collaborative-UAV 3D object detection, and collaborative-UAV object tracking. Our dataset and code are available athttps://huiyegit.github.io/UAV3D_Benchmark/.
Poster
Bowen Li · Zhaoyu Li · Qiwei Du · Jinqi Luo · Wenshan Wang · Yaqi Xie · Simon Stepputtis · Chen Wang · Katia Sycara · Pradeep Ravikumar · Alexander Gray · Xujie Si · Sebastian Scherer
[ West Ballroom A-D ]
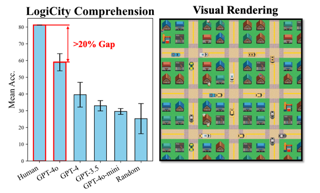
Abstract
Recent years have witnessed the rapid development of Neuro-Symbolic (NeSy) AI systems, which integrate symbolic reasoning into deep neural networks.However, most of the existing benchmarks for NeSy AI fail to provide long-horizon reasoning tasks with complex multi-agent interactions.Furthermore, they are usually constrained by fixed and simplistic logical rules over limited entities, making them far from real-world complexities.To address these crucial gaps, we introduce LogiCity, the first simulator based on customizable first-order logic (FOL) for an urban-like environment with multiple dynamic agents.LogiCity models diverse urban elements using semantic and spatial concepts, such as $\texttt{IsAmbulance}(\texttt{X})$ and $\texttt{IsClose}(\texttt{X}, \texttt{Y})$. These concepts are used to define FOL rules that govern the behavior of various agents. Since the concepts and rules are abstractions, they can be universally applied to cities with any agent compositions, facilitating the instantiation of diverse scenarios.Besides, a key feature of LogiCity is its support for user-configurable abstractions, enabling customizable simulation complexities for logical reasoning.To explore various aspects of NeSy AI, LogiCity introduces two tasks, one features long-horizon sequential decision-making, and the other focuses on one-step visual reasoning, varying in difficulty and agent behaviors.Our extensive evaluation reveals the advantage of NeSy frameworks in abstract reasoning. Moreover, we highlight the significant challenges of …
Poster
George Tsoukalas · Jasper Lee · John Jennings · Jimmy Xin · Michelle Ding · Michael Jennings · Amitayush Thakur · Swarat Chaudhuri
[ West Ballroom A-D ]
Abstract
We present PutnamBench, a new multi-language benchmark for evaluating the ability of neural theorem-provers to solve competition mathematics problems. PutnamBench consists of 1692 hand-constructed formalizations of 640 theorems sourced from the William Lowell Putnam Mathematical Competition, the premier undergraduate-level mathematics competition in North America. All the problems have formalizations in Lean 4 and Isabelle; a substantial subset also has Coq formalizations. PutnamBench requires significant problem-solving ability and proficiency in a broad range of topics taught in undergraduate mathematics courses. We use PutnamBench to evaluate several established neural and symbolic theorem-provers. These approaches can only solve a handful of the PutnamBench problems, establishing the benchmark as a difficult open challenge for research on neural theorem-proving. PutnamBench is available at https://github.com/trishullab/PutnamBench.
Poster
Nithish Kannen Senthilkumar · Arif Ahmad · Marco Andreetto · Vinodkumar Prabhakaran · Utsav Prabhu · Adji Bousso Dieng · Pushpak Bhattacharyya · Shachi Dave
[ West Ballroom A-D ]

Abstract
Text-to-Image (T2I) models are being increasingly adopted in diverse global communities where they create visual representations of their unique cultures. Current T2I benchmarks primarily focus on faithfulness, aesthetics, and realism of generated images, overlooking the critical dimension of *cultural competence*. In this work, we introduce a framework to evaluate cultural competence of T2I models along two crucial dimensions: cultural awareness and cultural diversity, and present a scalable approach using a combination of structured knowledge bases and large language models to build a large dataset of cultural artifacts to enable this evaluation. In particular, we apply this approach to build CUBE (CUltural BEnchmark for Text-to-Image models), a first-of-its-kind benchmark to evaluate cultural competence of T2I models. CUBE covers cultural artifacts associated with 8 countries across different geo-cultural regions and along 3 concepts: cuisine, landmarks, and art. CUBE consists of 1) CUBE-1K, a set of high-quality prompts that enable the evaluation of cultural awareness, and 2) CUBE-CSpace, a larger dataset of cultural artifacts that serves as grounding to evaluate cultural diversity. We also introduce cultural diversity as a novel T2I evaluation component, leveraging quality-weighted Vendi score. Our evaluations reveal significant gaps in the cultural awareness of existing models across countries and provide …
Poster
Hao Zhongkai · Jiachen Yao · Chang Su · Hang Su · Ziao Wang · Fanzhi Lu · Zeyu Xia · Yichi Zhang · Songming Liu · Lu Lu · Jun Zhu
[ West Ballroom A-D ]
Abstract
While significant progress has been made on Physics-Informed Neural Networks (PINNs), a comprehensive comparison of these methods across a wide range of Partial Differential Equations (PDEs) is still lacking. This study introduces PINNacle, a benchmarking tool designed to fill this gap. PINNacle provides a diverse dataset, comprising over 20 distinct PDEs from various domains, including heat conduction, fluid dynamics, biology, and electromagnetics. These PDEs encapsulate key challenges inherent to real-world problems, such as complex geometry, multi-scale phenomena, nonlinearity, and high dimensionality. PINNacle also offers a user-friendly toolbox, incorporating about 10 state-of-the-art PINN methods for systematic evaluation and comparison. We have conducted extensive experiments with these methods, offering insights into their strengths and weaknesses. In addition to providing a standardized means of assessing performance, PINNacle also offers an in-depth analysis to guide future research, particularly in areas such as domain decomposition methods and loss reweighting for handling multi-scale problems and complex geometry. To the best of our knowledge, it is the largest benchmark with a diverse and comprehensive evaluation that will undoubtedly foster further research in PINNs.
Spotlight Poster
Derui Zhu · Dingfan Chen · Xiongfei Wu · Jiahui Geng · Zhuo Li · Jens Grossklags · Lei Ma
[ East Exhibit Hall A-C ]
Abstract
Large Language Models (LLMs) are recognized for their potential to be an important building block toward achieving artificial general intelligence due to their unprecedented capability for solving diverse tasks. Despite these achievements, LLMs often underperform in domain-specific tasks without training on relevant domain data. This phenomenon, which is often attributed to distribution shifts, makes adapting pre-trained LLMs with domain-specific data crucial. However, this adaptation raises significant privacy concerns, especially when the data involved come from sensitive domains. In this work, we extensively investigate the privacy vulnerabilities of adapted (fine-tuned) LLMs and benchmark privacy leakage across a wide range of data modalities, state-of-the-art privacy attack methods, adaptation techniques, and model architectures. We systematically evaluate and pinpoint critical factors related to privacy leakage. With our organized codebase and actionable insights, we aim to provide a standardized auditing tool for practitioners seeking to deploy customized LLM applications with faithful privacy assessments.
Poster
Xianzhi Zeng · Wenchao Jiang · Shuhao Zhang
[ East Exhibit Hall A-C ]

Abstract
Matrix multiplication (MM) is pivotal in fields from deep learning to scientific computing, driving the quest for improved computational efficiency. Accelerating MM encompasses strategies like complexity reduction, parallel and distributed computing, hardware acceleration, and approximate computing techniques, namely AMM algorithms. Amidst growing concerns over the resource demands of large language models (LLMs), AMM has garnered renewed focus. However, understanding the nuances that govern AMM’s effectiveness remains incomplete. This study delves into AMM by examining algorithmic strategies, operational specifics, dataset characteristics, and their application in real-world tasks. Through comprehensive testing across diverse datasets and scenarios, we analyze how these factors affect AMM’s performance, uncovering that the selection of AMM approaches significantly influences the balance between efficiency and accuracy, with factors like memory access playing a pivotal role. Additionally, dataset attributes are shown to be vital for the success of AMM in applications. Our results advocate for tailored algorithmic approaches and careful strategy selection to enhance AMM’s effectiveness. To aid in the practical application and ongoing research of AMM, we introduce LibAMM —a toolkit offering a wide range of AMM algorithms, benchmarks, and tools for experiment management. LibAMM aims to facilitate research and application in AMM, guiding future developments towards more adaptive …
Poster
Patrick Chao · Edoardo Debenedetti · Alexander Robey · Maksym Andriushchenko · Francesco Croce · Vikash Sehwag · Edgar Dobriban · Nicolas Flammarion · George J. Pappas · Florian Tramer · Hamed Hassani · Eric Wong
[ East Exhibit Hall A-C ]
Abstract
Jailbreak attacks cause large language models (LLMs) to generate harmful, unethical, or otherwise objectionable content. Evaluating these attacks presents a number of challenges, which the current collection of benchmarks and evaluation techniques do not adequately address. First, there is no clear standard of practice regarding jailbreaking evaluation. Second, existing works compute costs and success rates in incomparable ways. And third, numerous works are not reproducible, as they withhold adversarial prompts, involve closed-source code, or rely on evolving proprietary APIs. To address these challenges, we introduce JailbreakBench, an open-sourced benchmark with the following components: (1) an evolving repository of state-of-the-art adversarial prompts, which we refer to as *jailbreak artifacts*; (2) a jailbreaking dataset comprising 100 behaviors---both original and sourced from prior work---which align with OpenAI's usage policies; (3) a standardized evaluation framework at https://github.com/JailbreakBench/jailbreakbench that includes a clearly defined threat model, system prompts, chat templates, and scoring functions; and (4) a leaderboard at https://jailbreakbench.github.io/ that tracks the performance of attacks and defenses for various LLMs. We have carefully considered the potential ethical implications of releasing this benchmark, and believe that it will be a net positive for the community.
Poster
Joseph Ortiz · Antoine Dedieu · Wolfgang Lehrach · J Swaroop Guntupalli · Carter Wendelken · Ahmad Humayun · Sivaramakrishnan Swaminathan · Guangyao Zhou · Miguel Lazaro-Gredilla · Kevin Murphy
[ West Ballroom A-D ]

Abstract
Learning from previously collected data via behavioral cloning or offline reinforcement learning (RL) is a powerful recipe for scaling generalist agents by avoiding the need for expensive online learning. Despite strong generalization in some respects, agents are often remarkably brittle to minor visual variations in control-irrelevant factors such as the background or camera viewpoint. In this paper, we present theDeepMind Control Visual Benchmark (DMC-VB), a dataset collected in the DeepMind Control Suite to evaluate the robustness of offline RL agents for solving continuous control tasks from visual input in the presence of visual distractors. In contrast to prior works, our dataset (a) combines locomotion and navigation tasks of varying difficulties, (b) includes static and dynamic visual variations, (c) considers data generated by policies with different skill levels, (d) systematically returns pairs of state and pixel observation, (e) is an order of magnitude larger, and (f) includes tasks with hidden goals. Accompanying our dataset, we propose three benchmarks to evaluate representation learning methods for pretraining, and carry out experiments on several recently proposed methods. First, we find that pretrained representations do not help policy learning on DMC-VB, and we highlight a large representation gap between policies learned on pixel observations and …
Poster
Lemei Zhang · Peng Liu · Marcus Henriksboe · Even Lauvrak · Jon Atle Gulla · Heri Ramampiaro
[ West Ballroom A-D ]
Abstract
With the rapid advancement of Natural Language Processing in recent years, numerous studies have shown that generic summaries generated by Large Language Models (LLMs) can sometimes surpass those annotated by experts, such as journalists, according to human evaluations. However, there is limited research on whether these generic summaries meet the individual needs of ordinary people. The biggest obstacle is the lack of human-annotated datasets from the general public. Existing work on personalized summarization often relies on pseudo datasets created from generic summarization datasets or controllable tasks that focus on specific named entities or other aspects, such as the length and specificity of generated summaries, collected from hypothetical tasks without the annotators' initiative. To bridge this gap, we propose a high-quality, personalized, manually annotated summarization dataset called PersonalSum. This dataset is the first to investigate whether the focus of public readers differs from the generic summaries generated by LLMs. It includes user profiles, personalized summaries accompanied by source sentences from given articles, and machine-generated generic summaries along with their sources. We investigate several personal signals — entities/topics, plot, and structure of articles—that may affect the generation of personalized summaries using LLMs in a few-shot in-context learning scenario. Our preliminary results and …
Poster
Jason Yang · Ariane Mora · Shengchao Liu · Bruce Wittmann · Animashree Anandkumar · Frances Arnold · Yisong Yue
[ West Ballroom A-D ]

Abstract
Enzymes are important proteins that catalyze chemical reactions. In recent years, machine learning methods have emerged to predict enzyme function from sequence; however, there are no standardized benchmarks to evaluate these methods. We introduce CARE, a benchmark and dataset suite for the Classification And Retrieval of Enzymes (CARE). CARE centers on two tasks: (1) classification of a protein sequence by its enzyme commission (EC) number and (2) retrieval of an EC number given a chemical reaction. For each task, we design train-test splits to evaluate different kinds of out-of-distribution generalization that are relevant to real use cases. For the classification task, we provide baselines for state-of-the-art methods. Because the retrieval task has not been previously formalized, we propose a method called Contrastive Reaction-EnzymE Pretraining (CREEP) as one of the first baselines for this task and compare it to the recent method, CLIPZyme. CARE is available at https://github.com/jsunn-y/CARE/.
Poster
Linyi Li · Shijie Geng · Zhenwen Li · Yibo He · Hao Yu · Ziyue Hua · Guanghan Ning · Siwei Wang · Tao Xie · Hongxia Yang
[ West Ballroom A-D ]

Abstract
Large Language Models for code (code LLMs) have witnessed tremendous progress in recent years. With the rapid development of code LLMs, many popular evaluation benchmarks, such as HumanEval, DS-1000, and MBPP, have emerged to measure the performance of code LLMs with a particular focus on code generation tasks. However, they are insufficient to cover the full range of expected capabilities of code LLMs, which span beyond code generation to answering diverse coding-related questions. To fill this gap, we propose InfiBench, the first large-scale freeform question-answering (QA) benchmark for code to our knowledge, comprising 234 carefully selected high-quality Stack Overflow questions that span across 15 programming languages. InfiBench uses four types of model-free automatic metrics to evaluate response correctness where domain experts carefully concretize the criterion for each question. We conduct a systematic evaluation for over 100 latest code LLMs on InfiBench, leading to a series of novel and insightful findings. Our detailed analyses showcase potential directions for further advancement of code LLMs. InfiBench is fully open source at https://infi-coder.github.io/infibench and continuously expanding to foster more scientific and systematic practices for code LLM evaluation.
Poster
André F. Cruz · Moritz Hardt · Celestine Mendler-Dünner
[ East Exhibit Hall A-C ]
Abstract
Current question-answering benchmarks predominantly focus on accuracy in realizable prediction tasks.Conditioned on a question and answer-key, does the most likely token match the ground truth?Such benchmarks necessarily fail to evaluate LLMs' ability to quantify ground-truth outcome uncertainty.In this work, we focus on the use of LLMs as risk scores for unrealizable prediction tasks.We introduce folktexts, a software package to systematically generate risk scores using LLMs, and evaluate them against US Census data products.A flexible API enables the use of different prompting schemes, local or web-hosted models, and diverse census columns that can be used to compose custom prediction tasks.We evaluate 17 recent LLMs across five proposed benchmark tasks.We find that zero-shot risk scores produced by multiple-choice question-answering have high predictive signal but are widely miscalibrated.Base models consistently overestimate outcome uncertainty, while instruction-tuned models underestimate uncertainty and produce over-confident risk scores.In fact, instruction-tuning polarizes answer distribution regardless of true underlying data uncertainty.This reveals a general inability of instruction-tuned models to express data uncertainty using multiple-choice answers.A separate experiment using verbalized chat-style risk queries yields substantially improved calibration across instruction-tuned models.These differences in ability to quantify data uncertainty cannot be revealed in realizable settings, and highlight a blind-spot in the current evaluation …
Poster
Ashwin Sankar · Srija Anand · Praveen Varadhan · Sherry Thomas · Mehak Singal · Shridhar Kumar · Deovrat Mehendale · Aditi Krishana · Giri Raju · Mitesh Khapra
[ West Ballroom A-D ]
Abstract
Recent advancements in text-to-speech (TTS) synthesis show that large-scale models trained with extensive web data produce highly natural-sounding output. However, such data is scarce for Indian languages due to the lack of high-quality, manually subtitled data on platforms like LibriVox or YouTube. To address this gap, we enhance existing large-scale ASR datasets containing natural conversations collected in low-quality environments to generate high-quality TTS training data. Our pipeline leverages the cross-lingual generalization of denoising and speech enhancement models trained on English and applied to Indian languages. This results in IndicVoices-R (IV-R), the largest multilingual Indian TTS dataset derived from an ASR dataset, with 1,704 hours of high-quality speech from 10,496 speakers across 22 Indian languages. IV-R matches the quality of gold-standard TTS datasets like LJSpeech, LibriTTS, and IndicTTS. We also introduce the IV-R Benchmark, the first to assess zero-shot, few-shot, and many-shot speaker generalization capabilities of TTS models on Indian voices, ensuring diversity in age, gender, and style. We demonstrate that fine-tuning an English pre-trained model on a combined dataset of high-quality IndicTTS and our IV-R dataset results in better zero-shot speaker generalization compared to fine-tuning on the IndicTTS dataset alone. Further, our evaluation reveals limited zero-shot generalization for Indian voices …
Poster
Julen Etxaniz · Gorka Azkune · Aitor Soroa · Oier Lacalle · Mikel Artetxe
[ West Ballroom A-D ]
Abstract
Large Language Models (LLMs) exhibit extensive knowledge about the world, but most evaluations have been limited to global or anglocentric subjects. This raises the question of how well these models perform on topics relevant to other cultures, whose presence on the web is not that prominent. To address this gap, we introduce BertaQA, a multiple-choice trivia dataset that is parallel in English and Basque. The dataset consists of a local subset with questions pertinent to the Basque culture, and a global subset with questions of broader interest. We find that state-of-the-art LLMs struggle with local cultural knowledge, even as they excel on global topics. However, we show that continued pre-training in Basque significantly improves the models' performance on Basque culture, even when queried in English. To our knowledge, this is the first solid evidence of knowledge transfer from a low-resource to a high-resource language. Our analysis sheds light on the complex interplay between language and knowledge, and reveals that some prior findings do not fully hold when reassessed on local topics. Our dataset and evaluation code are available under open licenses at https://github.com/juletx/BertaQA.
Poster
Paul Pu Liang · Akshay Goindani · Talha Chafekar · Leena Mathur · Haofei Yu · Ruslan Salakhutdinov · Louis-Philippe Morency
[ West Ballroom A-D ]
Abstract
Multimodal foundation models that can holistically process text alongside images, video, audio, and other sensory modalities are increasingly used in a variety of real-world applications. However, it is challenging to characterize and study progress in multimodal foundation models, given the range of possible modeling decisions, tasks, and domains. In this paper, we introduce Holistic Evaluation of Multimodal Models (HEMM) to systematically evaluate the capabilities of multimodal foundation models across a set of 3 dimensions: basic skills, information flow, and real-world use cases. Basic multimodal skills are internal abilities required to solve problems, such as learning interactions across modalities, fine-grained alignment, multi-step reasoning, and the ability to handle external knowledge. Information flow studies how multimodal content changes during a task through querying, translation, editing, and fusion. Use cases span domain-specific challenges introduced in real-world multimedia, affective computing, natural sciences, healthcare, and human-computer interaction applications. Through comprehensive experiments across the 30 tasks in HEMM, we (1) identify key dataset dimensions (e.g., basic skills, information flows, and use cases) that pose challenges to today’s models, and (2) distill performance trends regarding how different modeling dimensions (e.g., scale, pre-training data, multimodal alignment, pre-training, and instruction tuning objectives) influence performance. Our conclusions regarding challenging multimodal …
Poster
Hongbo Zhao · Lue Fan · Yuntao Chen · Haochen Wang · yuran Yang · Xiaojuan Jin · YIXIN ZHANG · GAOFENG MENG · ZHAO-XIANG ZHANG
[ West Ballroom A-D ]

Abstract
In this paper, we propose OpenSatMap, a fine-grained, high-resolution satellite dataset for large-scale map construction. Map construction is one of the foundations of the transportation industry, such as navigation and autonomous driving. Extracting road structures from satellite images is an efficient way to construct large-scale maps. However, existing satellite datasets provide only coarse semantic-level labels with a relatively low resolution (up to level 19), impeding the advancement of this field. In contrast, the proposed OpenSatMap (1) has fine-grained instance-level annotations; (2) consists of high-resolution images (level 20); (3) is currently the largest one of its kind; (4) collects data with high diversity. Moreover, OpenSatMap covers and aligns with the popular nuScenes dataset and Argoverse 2 dataset to potentially advance autonomous driving technologies. By publishing and maintaining the dataset, we provide a high-quality benchmark for satellite-based map construction and downstream tasks like autonomous driving.
Poster
Yichi Zhang · Yao Huang · Yitong Sun · Chang Liu · Zhe Zhao · Zhengwei Fang · Yifan Wang · Huanran Chen · Xiao Yang · Xingxing Wei · Hang Su · Yinpeng Dong · Jun Zhu
[ East Exhibit Hall A-C ]

Abstract
Despite the superior capabilities of Multimodal Large Language Models (MLLMs) across diverse tasks, they still face significant trustworthiness challenges. Yet, current literature on the assessment of trustworthy MLLMs remains limited, lacking a holistic evaluation to offer thorough insights into future improvements. In this work, we establish **MultiTrust**, the first comprehensive and unified benchmark on the trustworthiness of MLLMs across five primary aspects: *truthfulness*, *safety*, *robustness*, *fairness*, and *privacy*. Our benchmark employs a rigorous evaluation strategy that addresses both multimodal risks and cross-modal impacts, encompassing 32 diverse tasks with self-curated datasets. Extensive experiments with 21 modern MLLMs reveal some previously unexplored trustworthiness issues and risks, highlighting the complexities introduced by the multimodality and underscoring the necessity for advanced methodologies to enhance their reliability. For instance, typical proprietary models still struggle with the perception of visually confusing images and are vulnerable to multimodal jailbreaking and adversarial attacks; MLLMs are more inclined to disclose privacy in text and reveal ideological and cultural biases even when paired with irrelevant images in inference, indicating that the multimodality amplifies the internal risks from base LLMs. Additionally, we release a scalable toolbox for standardized trustworthiness research, aiming to facilitate future advancements in this important field. Code and …
Poster
Patrick Tser Jern Kon · Jiachen Liu · Yiming Qiu · Weijun Fan · Ting He · Lei Lin · Haoran Zhang · Owen Park · George Elengikal · Yuxin Kang · Ang Chen · Mosharaf Chowdhury · Myungjin Lee · Xinyu Wang
[ West Ballroom A-D ]
Abstract
Infrastructure-as-Code (IaC), an important component of cloud computing, allows the definition of cloud infrastructure in high-level programs. However, developing IaC programs is challenging, complicated by factors that include the burgeoning complexity of the cloud ecosystem (e.g., diversity of cloud services and workloads), and the relative scarcity of IaC-specific code examples and public repositories. While large language models (LLMs) have shown promise in general code generation and could potentially aid in IaC development, no benchmarks currently exist for evaluating their ability to generate IaC code. We present IaC-Eval, a first step in this research direction. IaC-Eval's dataset includes 458 human-curated scenarios covering a wide range of popular AWS services, at varying difficulty levels. Each scenario mainly comprises a natural language IaC problem description and an infrastructure intent specification. The former is fed as user input to the LLM, while the latter is a general notion used to verify if the generated IaC program conforms to the user's intent; by making explicit the problem's requirements that can encompass various cloud services, resources and internal infrastructure details. Our in-depth evaluation shows that contemporary LLMs perform poorly on IaC-Eval, with the top-performing model, GPT-4, obtaining a pass@1 accuracy of 19.36%. In contrast, it scores …
Poster
Arian Prabowo · Xiachong LIN · Imran Razzak · Hao Xue · Emily Yap · Matthew Amos · Flora Salim
[ West Ballroom A-D ]
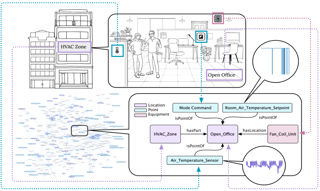
Abstract
Buildings play a crucial role in human well-being, influencing occupant comfort, health, and safety.Additionally, they contribute significantly to global energy consumption, accounting for one-third of total energy usage, and carbon emissions.Optimizing building performance presents a vital opportunity to combat climate change and promote human flourishing.However, research in building analytics has been hampered by the lack of accessible, available, and comprehensive real-world datasets on multiple building operations.In this paper, we introduce the Building TimeSeries (BTS) dataset.Our dataset covers three buildings over a three-year period, comprising more than ten thousand timeseries data points with hundreds of unique ontologies.Moreover, the metadata is standardized using the Brick schema.To demonstrate the utility of this dataset, we performed benchmarks on two tasks: timeseries ontology classification and zero-shot forecasting.These tasks represent an essential initial step in addressing challenges related to interoperability in building analytics.Access to the dataset and the code used for benchmarking are available here: https://github.com/cruiseresearchgroup/DIEF\_BTS
Poster
Zirui Wang · Mengzhou Xia · Luxi He · Howard Chen · Yitao Liu · Richard Zhu · Kaiqu Liang · Xindi Wu · Haotian Liu · Sadhika Malladi · Chevalier · Sanjeev Arora · Danqi Chen
[ West Ballroom A-D ]
Abstract
Chart understanding plays a pivotal role when applying Multimodal Large Language Models (MLLMs) to real-world tasks such as analyzing scientific papers or financial reports. However, existing datasets often focus on oversimplified and homogeneous charts with template-based questions, leading to an overly optimistic measure of progress. We demonstrate that although open-source models can appear to outperform strong proprietary models on these benchmarks, a simple stress test with slightly different charts or questions deteriorates performance by up to 34.5%. In this work, we propose CharXiv, a comprehensive evaluation suite involving 2,323 natural, challenging, and diverse charts from scientific papers. CharXiv includes two types of questions: 1) descriptive questions about examining basic chart elements and 2) reasoning questions that require synthesizing information across complex visual elements in the chart. To ensure quality, all charts and questions are handpicked, curated, and verified by human experts. Our results reveal a substantial, previously underestimated gap between the reasoning skills of the strongest proprietary model (i.e., GPT-4o), which achieves 47.1% accuracy, and the strongest open-source model (i.e., InternVL Chat V1.5), which achieves 29.2%. All models lag far behind human performance of 80.5%, underscoring weaknesses in the chart understanding capabilities of existing MLLMs. We hope that CharXiv facilitates …
Poster
Edward Vendrow · Omiros Pantazis · Alexander Shepard · Gabriel Brostow · Kate Jones · Oisin Mac Aodha · Sara Beery · Grant Van Horn
[ East Exhibit Hall A-C ]
Abstract
We introduce INQUIRE, a text-to-image retrieval benchmark designed to challenge multimodal vision-language models on expert-level queries. INQUIRE includes iNaturalist 2024 (iNat24), a new dataset of five million natural world images, along with 250 expert-level retrieval queries. These queries are paired with all relevant images comprehensively labeled within iNat24, comprising 33,000 total matches. Queries span categories such as species identification, context, behavior, and appearance, emphasizing tasks that require nuanced image understanding and domain expertise. Our benchmark evaluates two core retrieval tasks: (1) INQUIRE-Fullrank, a full dataset ranking task, and (2) INQUIRE-Rerank, a reranking task for refining top-100 retrievals. Detailed evaluation of a range of recent multimodal models demonstrates that INQUIRE poses a significant challenge, with the best models failing to achieve an mAP@50 above 50%. In addition, we show that reranking with more powerful multimodal models can enhance retrieval performance, yet there remains a significant margin for improvement. By focusing on scientifically-motivated ecological challenges, INQUIRE aims to bridge the gap between AI capabilities and the needs of real-world scientific inquiry, encouraging the development of retrieval systems that can assist with accelerating ecological and biodiversity research.
Poster
Irene Huang · Wei Lin · Muhammad Jehanzeb Mirza · Jacob Hansen · Sivan Doveh · Victor Butoi · Roei Herzig · Assaf Arbelle · Hilde Kuehne · Trevor Darrell · Chuang Gan · Aude Oliva · Rogerio Feris · Leonid Karlinsky
[ East Exhibit Hall A-C ]
Abstract
Compositional Reasoning (CR) entails grasping the significance of attributes, relations, and word order. Recent Vision-Language Models (VLMs), comprising a visual encoder and a Large Language Model (LLM) decoder, have demonstrated remarkable proficiency in such reasoning tasks. This prompts a crucial question: have VLMs effectively tackled the CR challenge? We conjecture that existing CR benchmarks may not adequately push the boundaries of modern VLMs due to the reliance on an LLM only negative text generation pipeline. Consequently, the negatives produced either appear as outliers from the natural language distribution learned by VLMs' LLM decoders or as improbable within the corresponding image context. To address these limitations, we introduce ConMe\footnote{ConMe is an abbreviation for Confuse Me.} -- a compositional reasoning benchmark and a novel data generation pipeline leveraging VLMs to produce `hard CR Q&A'. Through a new concept of VLMs conversing with each other to collaboratively expose their weaknesses, our pipeline autonomously generates, evaluates, and selects challenging compositional reasoning questions, establishing a robust CR benchmark, also subsequently validated manually. Our benchmark provokes a noteworthy, up to 33%, decrease in CR performance compared to preceding benchmarks, reinstating the CR challenge even for state-of-the-art VLMs.
Poster
Xiaoshuai Hao · Mengchuan Wei · Yifan Yang · Haimei Zhao · Hui Zhang · Yi ZHOU · Qiang Wang · Weiming Li · Lingdong Kong · Jing Zhang
[ East Exhibit Hall A-C ]
Abstract
Driving systems often rely on high-definition (HD) maps for precise environmental information, which is crucial for planning and navigation. While current HD map constructors perform well under ideal conditions, their resilience to real-world challenges, \eg, adverse weather and sensor failures, is not well understood, raising safety concerns. This work introduces MapBench, the first comprehensive benchmark designed to evaluate the robustness of HD map construction methods against various sensor corruptions. Our benchmark encompasses a total of 29 types of corruptions that occur from cameras and LiDAR sensors. Extensive evaluations across 31 HD map constructors reveal significant performance degradation of existing methods under adverse weather conditions and sensor failures, underscoring critical safety concerns. We identify effective strategies for enhancing robustness, including innovative approaches that leverage multi-modal fusion, advanced data augmentation, and architectural techniques. These insights provide a pathway for developing more reliable HD map construction methods, which are essential for the advancement of autonomous driving technology. The benchmark toolkit and affiliated code and model checkpoints have been made publicly accessible.
Poster
Mustafa Chasmai · Alexander Shepard · Subhransu Maji · Grant Van Horn
[ West Ballroom A-D ]

Abstract
We present the iNaturalist Sounds Dataset (iNatSounds), a collection of 230,000 audio files capturing sounds from over 5,500 species, contributed by more than 27,000 recordists worldwide. The dataset encompasses sounds from birds, mammals, insects, reptiles, and amphibians, with audio and species labels derived from observations submitted to iNaturalist, a global citizen science platform. Each recording in the dataset varies in length and includes a single species annotation. We benchmark multiple backbone architectures, comparing multiclass classification objectives with multilabel objectives. Despite weak labeling, we demonstrate that iNatSounds serves as a useful pretraining resource by benchmarking it on strongly labeled downstream evaluation datasets. The dataset is available as a single, freely accessible archive, promoting accessibility and research in this important domain. We envision models trained on this data powering next-generation public engagement applications, and assisting biologists, ecologists, and land use managers in processing large audio collections, thereby contributing to the understanding of species compositions in diverse soundscapes.
Poster
Pin Chen · Luoxuan Peng · Rui Jiao · Qing Mo · Zhen Wang · Wenbing Huang · Yang Liu · Yutong Lu
[ East Exhibit Hall A-C ]

Abstract
Superconductivity is a fascinating phenomenon observed in certain materials under certain conditions. However, some critical aspects of it, such as the relationship between superconductivity and materials' chemical/structural features, still need to be understood. Recent successes of data-driven approaches in material science strongly inspire researchers to study this relationship with them, but a corresponding dataset is still lacking. Hence, we present a new dataset for data-driven approaches, namely SuperCon3D, containing both 3D crystal structures and experimental superconducting transition temperature (Tc) for the first time. Based on SuperCon3D, we propose two deep learning methods for designing high Tc superconductors. The first is SODNet, a novel equivariant graph attention model for screening known structures, which differs from existing models in incorporating both ordered and disordered geometric content. The second is a diffusion generative model DiffCSP-SC for creating new structures, which enables high Tc-targeted generation. Extensive experiments demonstrate that both our proposed dataset and models are advantageous for designing new high Tc superconducting candidates.
Poster
Charles Guille-Escuret · Pierre-André Noël · Ioannis Mitliagkas · David Vazquez · Joao Monteiro
[ East Exhibit Hall A-C ]

Abstract
Deployed machine learning systems require some mechanism to detect out-of-distribution (OOD) inputs. Existing research mainly focuses on one type of distribution shift: detecting samples from novel classes, absent from the training set. However, real-world systems encounter a broad variety of anomalous inputs, and the OOD literature neglects this diversity. This work categorizes five distinct types of distribution shifts and critically evaluates the performance of recent OOD detection methods on each of them. We publicly release our benchmark under the name BROAD (Benchmarking Resilience Over Anomaly Diversity). We find that while these methods excel in detecting novel classes, their performances are inconsistent across other types of distribution shifts. In other words, they can only reliably detect unexpected inputs that they have been specifically designed to expect. As a first step toward broad OOD detection, we learn a Gaussian mixture generative model for existing detection scores, enabling an ensemble detection approach that is more consistent and comprehensive for broad OOD detection, with improved performances over existing methods. We release code to build BROAD to facilitate a more comprehensive evaluation of novel OOD detectors.
Spotlight Poster
Zeyu Wang · Xiyuxing Zhang · Ruotong Yu · Yuntao Wang · Kenneth Christofferson · Jingru Zhang · Alex Mariakakis · Yuanchun Shi
[ West Ballroom A-D ]
Abstract
Poor quality sleep can be characterized by the occurrence of events ranging from body movement to breathing impairment. Widely available earbuds equipped with sensors (also known as earables) can be combined with a sleep event detection algorithm to offer a convenient alternative to laborious clinical tests for individuals suffering from sleep disorders. Although various solutions utilizing such devices have been proposed to detect sleep events, they ignore the fact that individuals often share sleeping spaces with roommates or couples. To address this issue, we introduce DreamCatcher, the first publicly available dataset for wearer-aware sleep event algorithm development on earables. DreamCatcher encompasses eight distinct sleep events, including synchronous dual-channel audio and motion data collected from 12 pairs (24 participants) totaling 210 hours (420 hour.person) with fine-grained label. We tested multiple benchmark models on three tasks related to sleep event detection, demonstrating the usability and unique challenge of DreamCatcher. We hope that the proposed DreamCatcher can inspire other researchers to further explore efficient wearer-aware human vocal activity sensing on earables. DreamCatcher is publicly available at https://github.com/thuhci/DreamCatcher.
Poster
Yilun Jin · Zheng Li · Chenwei Zhang · Tianyu Cao · Yifan Gao · Pratik Jayarao · Mao Li · Xin Liu · Ritesh Sarkhel · Xianfeng Tang · Haodong Wang · Zhengyang Wang · Wenju Xu · Jingfeng Yang · Qingyu Yin · Xian Li · Priyanka Nigam · Yi Xu · Kai Chen · Qiang Yang · Meng Jiang · Bing Yin
[ West Ballroom A-D ]
Abstract
Online shopping is a complex multi-task, few-shot learning problem with a wide and evolving range of entities, relations, and tasks. However, existing models and benchmarks are commonly tailored to specific tasks, falling short of capturing the full complexity of online shopping. Large Language Models (LLMs), with their multi-task and few-shot learning abilities, have the potential to profoundly transform online shopping by alleviating task-specific engineering efforts and by providing users with interactive conversations. Despite the potential, LLMs face unique challenges in online shopping, such as domain-specific concepts, implicit knowledge, and heterogeneous user behaviors. Motivated by the potential and challenges, we propose Shopping MMLU, a diverse multi-task online shopping benchmark derived from real-world Amazon data. Shopping MMLU consists of 57 tasks covering 4 major shopping skills: concept understanding, knowledge reasoning, user behavior alignment, and multi-linguality, and can thus comprehensively evaluate the abilities of LLMs as general shop assistants. With Shoppping MMLU, we benchmark over 20 existing LLMs and uncover valuable insights about practices and prospects of building versatile LLM-based shop assistants. Shopping MMLU can be publicly accessed at https://github.com/KL4805/ShoppingMMLU. In addition, with Shopping MMLU, we are hosting a competition in KDD Cup 2024 with over 500 participating teams. The winning solutions and …
Poster
Mason Hargrave · Alex Spaeth · Logan Grosenick
[ West Ballroom A-D ]
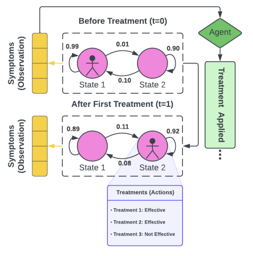
Abstract
Healthcare applications pose significant challenges to existing reinforcement learning (RL) methods due to implementation risks, low data availability, short treatment episodes, sparse rewards, partial observations, and heterogeneous treatment effects. Despite significant interest in using RL to generate dynamic treatment regimes for longitudinal patient care scenarios, no standardized benchmark has yet been developed.To fill this need we introduce *Episodes of Care* (*EpiCare*), a benchmark designed to mimic the challenges associated with applying RL to longitudinal healthcare settings. We leverage this benchmark to test five state-of-the-art offline RL models as well as five common off-policy evaluation (OPE) techniques.Our results suggest that while offline RL may be capable of improving upon existing standards of care given large data availability, its applicability does not appear to extend to the moderate to low data regimes typical of healthcare settings. Additionally, we demonstrate that several OPE techniques which have become standard in the the medical RL literature fail to perform adequately on our benchmark. These results suggest that the performance of RL models in dynamic treatment regimes may be difficult to meaningfully evaluate using current OPE methods, indicating that RL for this application may still be in its early stages. We hope that these results along …
Poster
Kien Nguyen · Fengchun Qiao · Arthur Trembanis · Xi Peng
[ West Ballroom A-D ]
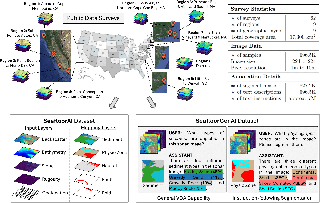
Abstract
A major obstacle to the advancements of machine learning models in marine science, particularly in sonar imagery analysis, is the scarcity of AI-ready datasets. While there have been efforts to make AI-ready sonar image dataset publicly available, they suffer from limitations in terms of environment setting and scale. To bridge this gap, we introduce $\texttt{SeafloorAI}$, the first extensive AI-ready datasets for seafloor mapping across 5 geological layers that is curated in collaboration with marine scientists. We further extend the dataset to $\texttt{SeafloorGenAI}$ by incorporating the language component in order to facilitate the development of both $\textit{vision}$- and $\textit{language}$-capable machine learning models for sonar imagery. The dataset consists of 62 geo-distributed data surveys spanning 17,300 square kilometers, with 696K sonar images, 827K annotated segmentation masks, 696K detailed language descriptions and approximately 7M question-answer pairs. By making our data processing source code publicly available, we aim to engage the marine science community to enrich the data pool and inspire the machine learning community to develop more robust models. This collaborative approach will enhance the capabilities and applications of our datasets within both fields.
Poster
Xiongkun Linghu · Jiangyong Huang · Xuesong Niu · Xiaojian (Shawn) Ma · Baoxiong Jia · Siyuan Huang
[ West Ballroom A-D ]

Abstract
Situation awareness is essential for understanding and reasoning about 3D scenes in embodied AI agents. However, existing datasets and benchmarks for situated understanding suffer from severe limitations in data modality, scope, diversity, and scale. To address these limitations, we propose Multi-modal Situated Question Answering (MSQA), a large-scale multi-modal situated reasoning dataset, scalably collected leveraging 3D scene graphs and vision-language models (VLMs) across a diverse range of real-world 3D scenes. MSQA includes 251K situated questionanswering pairs across 9 distinct question categories, covering complex scenarios and object modalities within 3D scenes. We introduce a novel interleaved multimodal input setting in our benchmark to provide both texts, images, and point clouds for situation and question description, aiming to resolve ambiguity in describing situations with single-modality inputs (e.g., texts). Additionally, we devise the Multi-modal Next-step Navigation (MSNN) benchmark to evaluate models’ grounding of actions and transitions between situations. Comprehensive evaluations on reasoning and navigation tasks highlight the limitations of existing vision-language models and underscore the importance of handling multi-modal interleaved inputs and situation modeling. Experiments on data scaling and crossdomain transfer further demonstrate the effectiveness of leveraging MSQA as a pre-training dataset for developing more powerful situated reasoning models, contributing to advancements in 3D …
Poster
Deyu Zou · Shikun Liu · Siqi Miao · Victor Fung · Shiyu Chang · Pan Li
[ East Exhibit Hall A-C ]
Abstract
Geometric deep learning (GDL) has gained significant attention in scientific fields, for its proficiency in modeling data with intricate geometric structures. Yet, very few works have delved into its capability of tackling the distribution shift problem, a prevalent challenge in many applications.To bridge this gap, we propose GeSS, a comprehensive benchmark designed for evaluating the performance of GDL models in scientific scenarios with distribution shifts.Our evaluation datasets cover diverse scientific domains from particle physics, materials science to biochemistry, and encapsulate a broad spectrum of distribution shifts including conditional, covariate, and concept shifts. Furthermore, we study three levels of information access from the out-of-distribution (OOD) test data, including no OOD information, only unlabeled OOD data, and OOD data with a few labels. Overall, our benchmark results in 30 different experiment settings, and evaluates 3 GDL backbones and 11 learning algorithms in each setting. A thorough analysis of the evaluation results is provided, poised to illuminate insights for GDL researchers and domain practitioners who are to use GDL in their applications.
Poster
Prasenjit Karmakar · Swadhin Pradhan · Sandip Chakraborty
[ West Ballroom A-D ]

Abstract
In recent years, indoor air pollution has posed a significant threat to our society, claiming over 3.2 million lives annually. Developing nations, such as India, are most affected since lack of knowledge, inadequate regulation, and outdoor air pollution lead to severe daily exposure to pollutants. However, only a limited number of studies have attempted to understand how indoor air pollution affects developing countries like India. To address this gap, we present spatiotemporal measurements of air quality from 30 indoor sites over six months during summer and winter seasons. The sites are geographically located across four regions of type: rural, suburban, and urban, covering the typical low to middle-income population in India. The dataset contains various types of indoor environments (e.g., studio apartments, classrooms, research laboratories, food canteens, and residential households), and can provide the basis for data-driven learning model research aimed at coping with unique pollution patterns in developing countries. This unique dataset demands advanced data cleaning and imputation techniques for handling missing data due to power failure or network outages during data collection. Furthermore, through a simple speech-to-text application, we provide real-time indoor activity labels annotated by occupants. Therefore, environmentalists and ML enthusiasts can utilize this dataset to understand …
Poster
Haitao Li · You Chen · Qingyao Ai · Yueyue WU · Ruizhe Zhang · Yiqun LIU
[ East Exhibit Hall A-C ]
Abstract
Large language models (LLMs) have made significant progress in natural language processing tasks and demonstrate considerable potential in the legal domain. However, legal applications demand high standards of accuracy, reliability, and fairness. Applying existing LLMs to legal systems without careful evaluation of their potential and limitations could pose significant risks in legal practice.To this end, we introduce a standardized comprehensive Chinese legal benchmark LexEval.This benchmark is notable in the following three aspects: (1) Ability Modeling: We propose a new taxonomy of legal cognitive abilities to organize different tasks. (2) Scale: To our knowledge, LexEval is currently the largest Chinese legal evaluation dataset, comprising 23 tasks and 14,150 questions. (3) Data: we utilize formatted existing datasets, exam datasets and newly annotated datasets by legal experts to comprehensively evaluate the various capabilities of LLMs. LexEval not only focuses on the ability of LLMs to apply fundamental legal knowledge but also dedicates efforts to examining the ethical issues involved in their application.We evaluated 38 open-source and commercial LLMs and obtained some interesting findings. The experiments and findings offer valuable insights into the challenges and potential solutions for developing Chinese legal systems and LLM evaluation pipelines. The LexEval dataset and leaderboard are publicly available …
Poster
Wei Chen · Xixuan Hao · Yuankai Wu · Yuxuan Liang
[ East Exhibit Hall A-C ]
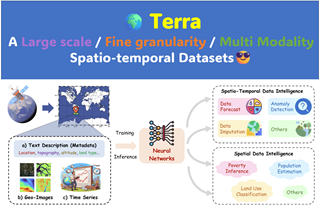
Abstract
Since the inception of our planet, the meteorological environment, as reflected through spatio-temporal data, has always been a fundamental factor influencing human life, socio-economic progress, and ecological conservation. A comprehensive exploration of this data is thus imperative to gain a deeper understanding and more accurate forecasting of these environmental shifts. Despite the success of deep learning techniques within the realm of spatio-temporal data and earth science, existing public datasets are beset with limitations in terms of spatial scale, temporal coverage, and reliance on limited time series data. These constraints hinder their optimal utilization in practical applications. To address these issues, we introduce **Terra**, a multimodal spatio-temporal dataset spanning the earth. This dataset encompasses hourly time series data from 6,480,000 grid areas worldwide over the past 45 years, while also incorporating multimodal spatial supplementary information including geo-images and explanatory text. Through a detailed data analysis and evaluation of existing deep learning models within earth sciences, utilizing our constructed dataset. we aim to provide valuable opportunities for enhancing future research in spatio-temporal data mining, thereby advancing towards more spatio-temporal general intelligence. Our source code and data can be accessed at https://github.com/CityMind-Lab/NeurIPS24-Terra.
Poster
Pranav Singh Chib · Pravendra Singh
[ West Ballroom A-D ]
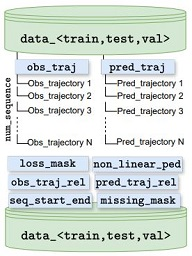
Abstract
Pedestrian trajectory prediction is crucial for several applications such as robotics and self-driving vehicles. Significant progress has been made in the past decade thanks to the availability of pedestrian trajectory datasets, which enable trajectory prediction methods to learn from pedestrians' past movements and predict future trajectories. However, these datasets and methods typically assume that the observed trajectory sequence is complete, ignoring real-world issues such as sensor failure, occlusion, and limited fields of view that can result in missing values in observed trajectories. To address this challenge, we present TrajImpute, a pedestrian trajectory prediction dataset that simulates missing coordinates in the observed trajectory, enhancing real-world applicability. TrajImpute maintains a uniform distribution of missing data within the observed trajectories. In this work, we comprehensively examine several imputation methods to reconstruct the missing coordinates and benchmark them for imputing pedestrian trajectories. Furthermore, we provide a thorough analysis of recent trajectory prediction methods and evaluate the performance of these models on the imputed trajectories. Our experimental evaluation of the imputation and trajectory prediction methods offers several valuable insights. Our dataset provides a foundational resource for future research on imputation-aware pedestrian trajectory prediction, potentially accelerating the deployment of these methods in real-world applications. Publicly accessible …
Poster
Dongfu Jiang · Max KU · Tianle Li · Yuansheng Ni · Shizhuo Sun · Rongqi Fan · Wenhu Chen
[ East Exhibit Hall A-C ]

Abstract
Generative AI has made remarkable strides to revolutionize fields such as image and video generation. These advancements are driven by innovative algorithms, architecture, and data. However, the rapid proliferation of generative models has highlighted a critical gap: the absence of trustworthy evaluation metrics. Current automatic assessments such as FID, CLIP, FVD, etc often fail to capture the nuanced quality and user satisfaction associated with generative outputs. This paper proposes an open platform GenAI-Arena to evaluate different image and video generative models, where users can actively participate in evaluating these models. By leveraging collective user feedback and votes, GenAI-Arena aims to provide a more democratic and accurate measure of model performance. It covers three tasks of text-to-image generation, text-to-video generation, and image editing respectively. Currently, we cover a total of 35 open-source generative models. GenAI-Arena has been operating for seven months, amassing over 9000 votes from the community. We describe our platform, analyze the data, and explain the statistical methods for ranking the models. To further promote the research in building model-based evaluation metrics, we release a cleaned version of our preference data for the three tasks, namely GenAI-Bench. We prompt the existing multi-modal models like Gemini, and GPT-4o to mimic …
Poster
Emanuele Vivoli · Marco Bertini · Dimosthenis Karatzas
[ West Ballroom A-D ]

Abstract
The comic domain is rapidly advancing with the development of single-page analysis and synthesis models. However, evaluation metrics and datasets lag behind, often limited to small-scale or single-style test sets. We introduce a novel benchmark, CoMix, designed to evaluate the multi-task capabilities of models in comic analysis. Unlike existing benchmarks that focus on isolated tasks such as object detection or text recognition, CoMix addresses a broader range of tasks including object detection, speaker identification, character re-identification, reading order, and multi-modal reasoning tasks like character naming and dialogue generation. Our benchmark comprises three existing datasets with expanded annotations to support multi-task evaluation. To mitigate the over-representation of manga-style data, we have incorporated a new dataset of carefully selected American comic-style books, thereby enriching the diversity of comic styles. CoMix is designed to assess pre-trained models in zero-shot and limited fine-tuning settings, probing their transfer capabilities across different comic styles and tasks. The validation split of the benchmark is publicly available for research purposes, and an evaluation server for the held-out test split is also provided. Comparative results between human performance and state-of-the-art models reveal a significant performance gap, highlighting substantial opportunities for advancements in comic understanding. The dataset, baseline models, and …
Poster
Mohamed Elrefaie · Florin Morar · Angela Dai · Faez Ahmed
[ East Exhibit Hall A-C ]
Abstract
We present DrivAerNet++, the largest and most comprehensive multimodal dataset for aerodynamic car design. DrivAerNet++ comprises 8,000 diverse car designs modeled with high-fidelity computational fluid dynamics (CFD) simulations. The dataset includes diverse car configurations such as fastback, notchback, and estateback, with different underbody and wheel designs to represent both internal combustion engines and electric vehicles. Each entry in the dataset features detailed 3D meshes, parametric models, aerodynamic coefficients, and extensive flow and surface field data, along with segmented parts for car classification and point cloud data. This dataset supports a wide array of machine learning applications including data-driven design optimization, generative modeling, surrogate model training, CFD simulation acceleration, and geometric classification. With more than 39 TB of publicly available engineering data, DrivAerNet++ fills a significant gap in available resources, providing high-quality, diverse data to enhance model training, promote generalization, and accelerate automotive design processes. Along with rigorous dataset validation, we also provide ML benchmarking results on the task of aerodynamic drag prediction, showcasing the breadth of applications supported by our dataset. This dataset is set to significantly impact automotive design and broader engineering disciplines by fostering innovation and improving the fidelity of aerodynamic evaluations. Dataset and code available at: https://github.com/Mohamedelrefaie/DrivAerNet
Poster
Jize Wang · Ma Zerun · Yining Li · Songyang Zhang · Cailian Chen · Kai Chen · Xinyi Le
[ West Ballroom A-D ]

Abstract
In developing general-purpose agents, significant focus has been placed on integrating large language models (LLMs) with various tools. This poses a challenge to the tool-use capabilities of LLMs. However, there are evident gaps between existing tool evaluations and real-world scenarios. Current evaluations often use AI-generated queries, single-step tasks, dummy tools, and text-only inputs, which fail to reveal the agents' real-world problem-solving abilities effectively. To address this, we propose GTA, a benchmark for **G**eneral **T**ool **A**gents, featuring three main aspects: (i) *Real user queries*: human-written queries with simple real-world objectives but implicit tool-use, requiring the LLM to reason the suitable tools and plan the solution steps. (ii) *Real deployed tools*: an evaluation platform equipped with tools across perception, operation, logic, and creativity categories to evaluate the agents' actual task execution performance. (iii) *Real multimodal inputs*: authentic image files, such as spatial scenes, web page screenshots, tables, code snippets, and printed/handwritten materials, used as the query contexts to align with real-world scenarios closely. We designed 229 real-world tasks and executable tool chains to evaluate mainstream LLMs. Our findings show that real-world user queries are challenging for existing LLMs, with GPT-4 completing less than 50\% of the tasks and most LLMs achieving below …
Poster
Amelia Jiménez-Sánchez · Natalia-Rozalia Avlona · Dovile Juodelyte · Théo Sourget · Caroline Vang-Larsen · Anna Rogers · Hubert Zając · Veronika Cheplygina
[ West Ballroom A-D ]

Abstract
Medical Imaging (MI) datasets are fundamental to artificial intelligence in healthcare. The accuracy, robustness, and fairness of diagnostic algorithms depend on the data (and its quality) used to train and evaluate the models. MI datasets used to be proprietary, but have become increasingly available to the public, including on community-contributed platforms (CCPs) like Kaggle or HuggingFace. While open data is important to enhance the redistribution of data's public value, we find that the current CCP governance model fails to uphold the quality needed and recommended practices for sharing, documenting, and evaluating datasets. In this paper, we conduct an analysis of publicly available machine learning datasets on CCPs, discussing datasets' context, and identifying limitations and gaps in the current CCP landscape. We highlight differences between MI and computer vision datasets, particularly in the potentially harmful downstream effects from poor adoption of recommended dataset management practices. We compare the analyzed datasets across several dimensions, including data sharing, data documentation, and maintenance. We find vague licenses, lack of persistent identifiers and storage, duplicates, and missing metadata, with differences between the platforms. Our research contributes to efforts in responsible data curation and AI algorithms for healthcare.
Poster
Rohith Peddi · Shivvrat Arya · Bharath Challa · Likhitha Pallapothula · Akshay Vyas · Bhavya Gouripeddi · Qifan Zhang · Jikai Wang · Vasundhara Komaragiri · Eric Ragan · Nicholas Ruozzi · Yu Xiang · Vibhav Gogate
[ West Ballroom A-D ]
Abstract
Following step-by-step procedures is an essential component of various activities carried out by individuals in their daily lives. These procedures serve as a guiding framework that helps to achieve goals efficiently, whether it is assembling furniture or preparing a recipe. However, the complexity and duration of procedural activities inherently increase the likelihood of making errors. Understanding such procedural activities from a sequence of frames is a challenging task that demands an accurate interpretation of visual information and the ability to reason about the structure of the activity. To this end, we collect a new egocentric 4D dataset, CaptainCook4D, comprising 384 recordings (94.5 hours) of people performing recipes in real kitchen environments. This dataset consists of two distinct types of activity: one in which participants adhere to the provided recipe instructions and another in which they deviate and induce errors. We provide 5.3K step annotations and 10K fine-grained action annotations and benchmark the dataset for the following tasks: error recognition, multistep localization and procedure learning.
Poster
Haiji Liang · Ruize Han
[ West Ballroom A-D ]

Abstract
Open-vocabulary object perception has become an important topic in artificial intelligence, which aims to identify objects with novel classes that have not been seen during training. Under this setting, open-vocabulary object detection (OVD) in a single image has been studied in many literature. However, open-vocabulary object tracking (OVT) from a video has been studied less, and one reason is the shortage of benchmarks. In this work, we have built a new large-scale benchmark for open-vocabulary multi-object tracking namely OVT-B. OVT-B contains 1,048 categories of objects and 1,973 videos with 637,608 bounding box annotations, which is much larger than the sole open-vocabulary tracking dataset, i.e., OVTAO-val dataset (200+ categories, 900+ videos). The proposed OVT-B can be used as a new benchmark to pave the way for OVT research. We also develop a simple yet effective baseline method for OVT. It integrates the motion features for object tracking, which is an important feature for MOT but is ignored in previous OVT methods. Experimental results have verified the usefulness of the proposed benchmark and the effectiveness of our method. We have released the benchmark to the public at https://github.com/Coo1Sea/OVT-B-Dataset.
Poster
Xinyu Fang · Kangrui Mao · Haodong Duan · Xiangyu Zhao · Yining Li · Dahua Lin · Kai Chen
[ East Exhibit Hall A-C ]

Abstract
The advent of large vision-language models (LVLMs) has spurred research into their applications in multi-modal contexts, particularly in video understanding. Traditional VideoQA benchmarks, despite providing quantitative metrics, often fail to encompass the full spectrum of video content and inadequately assess models' temporal comprehension. To address these limitations, we introduce MMBench-Video, a quantitative benchmark designed to rigorously evaluate LVLMs' proficiency in video understanding. MMBench-Video incorporates lengthy videos from YouTube and employs free-form questions, mirroring practical use cases. The benchmark is meticulously crafted to probe the models' temporal reasoning skills, with all questions human-annotated according to a carefully constructed ability taxonomy.We employ GPT-4 for automated assessment, demonstrating superior accuracy and robustness over earlier LLM-based evaluations. Utilizing MMBench-Video, we have conducted comprehensive evaluations that include both proprietary and open-source LVLMs for images and videos. MMBench-Video stands as a valuable resource for the research community, facilitating improved evaluation of LVLMs and catalyzing progress in the field of video understanding.
Poster
Jiawen Chen · Muqing Zhou · Wenrong Wu · Jinwei Zhang · Yun Li · Didong Li
[ West Ballroom A-D ]
Abstract
Recent advances in multi-modal algorithms have driven and been driven by the increasing availability of large image-text datasets, leading to significant strides in various fields, including computational pathology. However, in most existing medical image-text datasets, the text typically provides high-level summaries that may not sufficiently describe sub-tile regions within a large pathology image. For example, an image might cover an extensive tissue area containing cancerous and healthy regions, but the accompanying text might only specify that this image is a cancer slide, lacking the nuanced details needed for in-depth analysis. In this study, we introduce STimage-1K4M, a novel dataset designed to bridge this gap by providing genomic features for sub-tile images. STimage-1K4M contains 1,149 images derived from spatial transcriptomics data, which captures gene expression information at the level of individual spatial spots within a pathology image. Specifically, each image in the dataset is broken down into smaller sub-image tiles, with each tile paired with $15,000-30,000$ dimensional gene expressions. With $4,293,195$ pairs of sub-tile images and gene expressions, STimage-1K4M offers unprecedented granularity, paving the way for a wide range of advanced research in multi-modal data analysis an innovative applications in computational pathology, and beyond.
Poster
Rebecca Saul · Chang Liu · Noah Fleischmann · Richard Zak · Kristopher Micinski · Edward Raff · James Holt
[ West Ballroom A-D ]
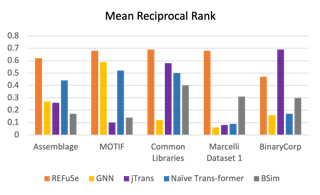
Abstract
Binary analysis is a core component of many critical security tasks, including reverse engineering, malware analysis, and vulnerability detection. Manual analysis is often time-consuming, but identifying commonly-used or previously-seen functions can reduce the time it takes to understand a new file. However, given the complexity of assembly, and the NP-hard nature of determining function equivalence, this task is extremely difficult. Common approaches often use sophisticated disassembly and decompilation tools, graph analysis, and other expensive pre-processing steps to perform function similarity searches over some corpus. In this work, we identify a number of discrepancies between the current research environment and the underlying application need. To remedy this, we build a new benchmark, REFuSe-Bench, for binary function similarity detection consisting of high-quality datasets and tests that better reflect real-world use cases. In doing so, we address issues like data duplication and accurate labeling, experiment with real malware, and perform the first serious evaluation of ML binary function similarity models on Windows data. Our benchmark reveals that a new, simple baseline — one which looks at only the raw bytes of a function, and requires no disassembly or other pre-processing --- is able to achieve state-of-the-art performance in multiple settings. Our findings challenge …
Poster
Sasha Salter · Richard Warren · Collin Schlager · Adrian Spurr · Shangchen Han · Rohin Bhasin · Yujun Cai · Peter Walkington · Anuoluwapo Bolarinwa · Robert Wang · Nathan Danielson · Josh Merel · Eftychios Pnevmatikakis · Jesse Marshall
[ West Ballroom A-D ]
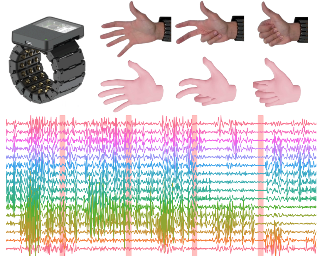
Abstract
Hands are the primary means through which humans interact with the world. Reliable and always-available hand pose inference could yield new and intuitive control schemes for human-computer interactions, particularly in virtual and augmented reality. Computer vision is effective but requires one or multiple cameras and can struggle with occlusions, limited field of view, and poor lighting. Wearable wrist-based surface electromyography (sEMG) presents a promising alternative as an always-available modality sensing muscle activities that drive hand motion. However, sEMG signals are strongly dependent on user anatomy and sensor placement; existing sEMG models have thus required hundreds of users and device placements to effectively generalize for tasks other than pose inference. To facilitate progress on sEMG pose inference, we introduce the emg2pose benchmark, which is to our knowledge the first publicly available dataset of high-quality hand pose labels and wrist sEMG recordings. emg2pose contains 2kHz, 16 channel sEMG and pose labels from a 26-camera motion capture rig for 193 users, 370 hours, and 29 stages with diverse gestures - a scale comparable to vision-based hand pose datasets. We provide competitive baselines and challenging tasks evaluating real-world generalization scenarios: held-out users, sensor placements, and stages. This benchmark provides the machine learning community a …
Poster
Zahra Gharaee · Scott C. Lowe · ZeMing Gong · Pablo Millan Arias · Nicholas Pellegrino · Austin T. Wang · Joakim Bruslund Haurum · Iuliia Eyriay · Lila Kari · Dirk Steinke · Graham Taylor · Paul Fieguth · Angel Chang
[ West Ballroom A-D ]

Abstract
As part of an ongoing worldwide effort to comprehend and monitor insect biodiversity, this paper presents the BIOSCAN-5M Insect dataset to the machine learning community and establish several benchmark tasks. BIOSCAN-5M is a comprehensive dataset containing multi-modal information for over 5 million insect specimens, and it significantly expands existing image-based biological datasets by including taxonomic labels, raw nucleotide barcode sequences, assigned barcode index numbers, geographical, and size information. We propose three benchmark experiments to demonstrate the impact of the multi-modal data types on the classification and clustering accuracy. First, we pretrain a masked language model on the DNA barcode sequences of the BIOSCAN-5M dataset, and demonstrate the impact of using this large reference library on species- and genus-level classification performance. Second, we propose a zero-shot transfer learning task applied to images and DNA barcodes to cluster feature embeddings obtained from self-supervised learning, to investigate whether meaningful clusters can be derived from these representation embeddings. Third, we benchmark multi-modality by performing contrastive learning on DNA barcodes, image data, and taxonomic information. This yields a general shared embedding space enabling taxonomic classification using multiple types of information and modalities. The code repository of the BIOSCAN-5M Insect dataset is available at https://github.com/bioscan-ml/BIOSCAN-5M.
Poster
Sri Harsha Dumpala · Aman Jaiswal · Chandramouli Shama Sastry · Evangelos Milios · Sageev Oore · Hassan Sajjad
[ East Exhibit Hall A-C ]
Abstract
Despite their remarkable successes, state-of-the-art large language models (LLMs), including vision-and-language models (VLMs) and unimodal language models (ULMs), fail to understand precise semantics. For example, semantically equivalent sentences expressed using different lexical compositions elicit diverging representations. The degree of this divergence and its impact on encoded semantics is not very well understood. In this paper, we introduce the SUGARCREPE++ dataset to analyze the sensitivity of VLMs and ULMs to lexical and semantic alterations. Each sample in SUGARCREPE++ dataset consists of an image and a corresponding triplet of captions: a pair of semantically equivalent but lexically different positive captions and one hard negative caption. This poses a 3-way semantic (in)equivalence problem to the language models. We comprehensively evaluate VLMs and ULMs that differ in architecture, pre-training objectives and datasets to benchmark the performance of SUGARCREPE++ dataset. Experimental results highlight the difficulties of VLMs in distinguishing between lexical and semantic variations, particularly to object attributes and spatial relations. Although VLMs with larger pre-training datasets, model sizes, and multiple pre-training objectives achieve better performance on SUGARCREPE++, there is a significant opportunity for improvement. We demonstrate that models excelling on compositionality datasets may not perform equally well on SUGARCREPE++. This indicates that compositionality alone …
Poster
Viswanath Sivakumar · Jeffrey Seely · Alan Du · Sean Bittner · Adam Berenzweig · Anuoluwapo Bolarinwa · Alex Gramfort · Michael Mandel
[ West Ballroom A-D ]
Abstract
Surface electromyography (sEMG) non-invasively measures signals generated by muscle activity with sufficient sensitivity to detect individual spinal neurons and richness to identify dozens of gestures and their nuances. Wearable wrist-based sEMG sensors have the potential to offer low friction, subtle, information rich, always available human-computer inputs. To this end, we introduce emg2qwerty, a large-scale dataset of non-invasive electromyographic signals recorded at the wrists while touch typing on a QWERTY keyboard, together with ground-truth annotations and reproducible baselines. With 1,135 sessions spanning 108 users and 346 hours of recording, this is the largest such public dataset to date. These data demonstrate non-trivial, but well defined hierarchical relationships both in terms of the generative process, from neurons to muscles and muscle combinations, as well as in terms of domain shift across users and user sessions. Applying standard modeling techniques from the closely related field of Automatic Speech Recognition (ASR), we show strong baseline performance on predicting key-presses using sEMG signals alone. We believe the richness of this task and dataset will facilitate progress in several problems of interest to both the machine learning and neuroscientific communities. Dataset and code can be accessed at https://github.com/facebookresearch/emg2qwerty.
Poster
Alexander Nikulin · Vladislav Kurenkov · Ilya Zisman · Artem Agarkov · Viacheslav Sinii · Sergey Kolesnikov
[ West Ballroom A-D ]
Abstract
Inspired by the diversity and depth of XLand and the simplicity and minimalism of MiniGrid, we present XLand-MiniGrid, a suite of tools and grid-world environments for meta-reinforcement learning research. Written in JAX, XLand-MiniGrid is designed to be highly scalable and can potentially run on GPU or TPU accelerators, democratizing large-scale experimentation with limited resources. Along with the environments, XLand-MiniGrid provides pre-sampled benchmarks with millions of unique tasks of varying difficulty and easy-to-use baselines that allow users to quickly start training adaptive agents. In addition, we have conducted a preliminary analysis of scaling and generalization, showing that our baselines are capable of reaching millions of steps per second during training and validating that the proposed benchmarks are challenging. XLand-MiniGrid is open-source and available at \url{https://github.com/corl-team/xland-minigrid}.
Poster
Yizhang Zhu · Shiyin Du · Boyan Li · Yuyu Luo · Nan Tang
[ East Exhibit Hall A-C ]
Abstract
Large Language Models (LLMs) have demonstrated impressive capabilities across a range of scientific tasks including mathematics, physics, and chemistry. Despite their successes, the effectiveness of LLMs in handling complex statistical tasks remains systematically under-explored. To bridge this gap, we introduce StatQA, a new benchmark designed for statistical analysis tasks. StatQA comprises 11,623 examples tailored to evaluate LLMs' proficiency in specialized statistical tasks and their applicability assessment capabilities, particularly for hypothesis testing methods. We systematically experiment with representative LLMs using various prompting strategies and show that even state-of-the-art models such as GPT-4o achieve a best performance of only 64.83%, indicating significant room for improvement. Notably, while open-source LLMs (e.g. LLaMA-3) show limited capability, those fine-tuned ones exhibit marked improvements, outperforming all in-context learning-based methods (e.g. GPT-4o). Moreover, our comparative human experiments highlight a striking contrast in error types between LLMs and humans: LLMs primarily make applicability errors, whereas humans mostly make statistical task confusion errors. This divergence highlights distinct areas of proficiency and deficiency, suggesting that combining LLM and human expertise could lead to complementary strengths, inviting further investigation into their collaborative potential. Our source code and data are available at https://statqa.github.io/.
Poster
Marek Herde · Denis Huseljic · Lukas Rauch · Bernhard Sick
[ West Ballroom A-D ]
Abstract
Human annotators typically provide annotated data for training machine learning models, such as neural networks. Yet, human annotations are subject to noise, impairing generalization performances. Methodological research on approaches counteracting noisy annotations requires corresponding datasets for a meaningful empirical evaluation. Consequently, we introduce a novel benchmark dataset, dopanim, consisting of about 15,750 animal images of 15 classes with ground truth labels. For approximately 10,500 of these images, 20 humans provided over 52,000 annotations with an accuracy of circa 67%. Its key attributes include (1) the challenging task of classifying doppelganger animals, (2) human-estimated likelihoods as annotations, and (3) annotator metadata. We benchmark well-known multi-annotator learning approaches using seven variants of this dataset and outline further evaluation use cases such as learning beyond hard class labels and active learning. Our dataset and a comprehensive codebase are publicly available to emulate the data collection process and to reproduce all empirical results.
Poster
Imanol Miranda · Ander Salaberria · Eneko Agirre · Gorka Azkune
[ West Ballroom A-D ]

Abstract
Existing Vision-Language Compositionality (VLC) benchmarks like SugarCrepe are formulated as image-to-text retrieval problems, where, given an image, the models need to select between the correct textual description and a synthetic hard negative text. In this work, we present the Bidirectional Vision-Language Compositionality (BiVLC) dataset. The novelty of BiVLC is to add a synthetic hard negative image generated from the synthetic text, resulting in two image-to-text retrieval examples (one for each image) and, more importantly, two text-to-image retrieval examples (one for each text). Human annotators filter out ill-formed examples ensuring the validity of the benchmark. The experiments on BiVLC uncover a weakness of current multimodal models, as they perform poorly in the text-to-image direction. In fact, when considering both retrieval directions, the conclusions obtained in previous works change significantly. In addition to the benchmark, weshow that a contrastive model trained using synthetic images and texts significantly improves over the base model in SugarCrepe and in BiVLC for both retrieval directions. The gap to human performance in BiVLC confirms that Vision-Language Compositionality is still a challenging problem.
Poster
Suzanne Duncan · Gianna Leoni · Lee Steven · Keoni K Mahelona · Peter Lucas K Jones
[ West Ballroom A-D ]

Abstract
Influential and popular benchmarks in AI are largely irrelevant to developing NLP tools for low-resource, Indigenous languages. With the primary goal of measuring the performance of general-purpose AI systems, these benchmarks fail to give due consideration and care to individual language communities, especially low-resource languages. The datasets contain numerous grammatical and orthographic errors, poor pronunciation, limited vocabulary, and the content lacks cultural relevance to the language community. To overcome the issues with these benchmarks, we have created a dataset for te reo Māori (the Indigenous language of Aotearoa/New Zealand) to pursue NLP tools that are ‘fit-for-our-purpose’. This paper demonstrates how low-resourced, Indigenous languages can develop tailored, high-quality benchmarks that; i. Consider the impact of colonisation on their language; ii. Reflect the diversity of speakers in the language community; iii. Support the aspirations for the tools they are developing and their language revitalisation efforts.
Spotlight Poster
Jio Oh · Soyeon Kim · Junseok Seo · Jindong Wang · Ruochen Xu · Xing Xie · Steven Whang
[ West Ballroom A-D ]
Abstract
Large language models (LLMs) have achieved unprecedented performances in various applications, yet evaluating them is still challenging. Existing benchmarks are either manually constructed or are automatic, but lack the ability to evaluate the thought process of LLMs with arbitrary complexity. We contend that utilizing existing relational databases based on the entity-relationship (ER) model is a promising approach for constructing benchmarks as they contain structured knowledge that can be used to question LLMs. Unlike knowledge graphs, which are also used to evaluate LLMs, relational databases have integrity constraints that can be used to better construct complex in-depth questions and verify answers: (1) functional dependencies can be used to pinpoint critical keywords that an LLM must know to properly answer a given question containing certain attribute values; and (2) foreign key constraints can be used to join relations and construct multi-hop questions, which can be arbitrarily long and used to debug intermediate answers. We thus propose ERBench, which uses these integrity constraints to convert any database into an LLM benchmark. ERBench supports continuous evaluation as databases change, multimodal questions, and various prompt engineering techniques. In our experiments, we construct LLM benchmarks using databases of multiple domains and make an extensive comparison of …
Spotlight Poster
Jacob Silberg · Kyle Swanson · Elana Simon · Angela Zhang · Zaniar Ghazizadeh · Scott Ogden · Hisham Hamadeh · James Zou
[ East Exhibit Hall A-C ]
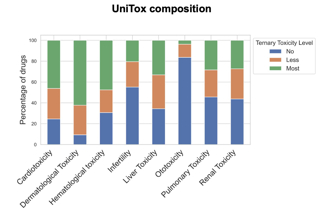
Abstract
Drug-induced toxicity is one of the leading reasons new drugs fail clinical trials. Machine learning models that predict drug toxicity from molecular structure could help researchers prioritize less toxic drug candidates. However, current toxicity datasets are typically small and limited to a single organ system (e.g., cardio, renal, or liver). Creating these datasets often involved time-intensive expert curation by parsing drug labelling documents that can exceed 100 pages per drug. Here, we introduce UniTox, a unified dataset of 2,418 FDA-approved drugs with drug-induced toxicity summaries and ratings created by using GPT-4o to process FDA drug labels. UniTox spans eight types of toxicity: cardiotoxicity, liver toxicity, renal toxicity, pulmonary toxicity, hematological toxicity, dermatological toxicity, ototoxicity, and infertility. This is, to the best of our knowledge, the largest such systematic human in vivo database by number of drugs and toxicities, and the first covering nearly all non-combination FDA-approved medications for several of these toxicities. We recruited clinicians to validate a random sample of our GPT-4o annotated toxicities, and UniTox's toxicity ratings concord with clinician labelers 85-96\% of the time. Finally, we benchmark several machine learning models trained on UniTox to demonstrate the utility of this dataset for building molecular toxicity prediction models.
Poster
Austin Coursey · Junyi Ji · Marcos Quinones Grueiro · William Barbour · Yuhang Zhang · Tyler Derr · Gautam Biswas · Daniel Work
[ West Ballroom A-D ]
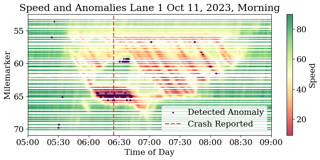
Abstract
Early and accurate detection of anomalous events on the freeway, such as accidents, can improve emergency response and clearance. However, existing delays and mistakes from manual crash reporting records make it a difficult problem to solve. Current large-scale freeway traffic datasets are not designed for anomaly detection and ignore these challenges. In this paper, we introduce the first large-scale lane-level freeway traffic dataset for anomaly detection. Our dataset consists of a month of weekday radar detection sensor data collected in 4 lanes along an 18-mile stretch of Interstate 24 heading toward Nashville, TN, comprising over 3.7 million sensor measurements. We also collect official crash reports from the Tennessee Department of Transportation Traffic Management Center and manually label all other potential anomalies in the dataset. To show the potential for our dataset to be used in future machine learning and traffic research, we benchmark numerous deep learning anomaly detection models on our dataset. We find that unsupervised graph neural network autoencoders are a promising solution for this problem and that ignoring spatial relationships leads to decreased performance. We demonstrate that our methods can reduce reporting delays by over 10 minutes on average while detecting 75% of crashes. Our dataset and all …
Poster
Anton Antonov · Andrei Moskalenko · Denis Shepelev · Alexander Krapukhin · Konstantin Soshin · Anton Konushin · Vlad Shakhuro
[ West Ballroom A-D ]

Abstract
The emergence of Segment Anything (SAM) sparked research interest in the field of interactive segmentation, especially in the context of image editing tasks and speeding up data annotation. Unlike common semantic segmentation, interactive segmentation methods allow users to directly influence their output through prompts (e.g. clicks). However, click patterns in real-world interactive segmentation scenarios remain largely unexplored. Most methods rely on the assumption that users would click in the center of the largest erroneous area. Nevertheless, recent studies show that this is not always the case. Thus, methods may have poor performance in real-world deployment despite high metrics in a baseline benchmark. To accurately simulate real-user clicks, we conducted a large crowdsourcing study of click patterns in an interactive segmentation scenario and collected 475K real-user clicks. Drawing on ideas from saliency tasks, we develop a clickability model that enables sampling clicks, which closely resemble actual user inputs. Using our model and dataset, we propose RClicks benchmark for a comprehensive comparison of existing interactive segmentation methods on realistic clicks. Specifically, we evaluate not only the average quality of methods, but also the robustness w.r.t. click patterns. According to our benchmark, in real-world usage interactive segmentation models may perform worse than it …
Poster
Nidhish Shah · Zulkuf Genc · Dogu Araci
[ West Ballroom A-D ]
Abstract
We present two comprehensive benchmarks to evaluate the performance of language models in coding assistance tasks, covering code writing, debugging, code review, and conceptual understanding. Our main contribution includes two curated datasets: StackEval, a large-scale benchmark derived from Stack Overflow questions, and StackUnseen, a dynamic benchmark featuring the most recent Stack Overflow content. These benchmarks offer novel insights into the capabilities and limitations of LLMs, particularly in handling new and emerging content. Additionally, we assess LLMs' proficiency as judges for coding tasks using a curated, human-annotated dataset, exploring their evaluation capabilities and potential biases, including whether they favor their own generated solutions. Our findings underscore the potential of these benchmarks to advance LLM development and application in coding assistance. To ensure reproducibility, we publicly share our datasets and evaluation code at https://github.com/ProsusAI/stack-eval.
Poster
Yuli Wang · Peng jian · Yuwei Dai · Craig Jones · Haris Sair · Jinglai Shen · Nicolas Loizou · jing wu · Wen-Chi Hsu · Maliha Imami · Zhicheng Jiao · Paul Zhang · Harrison Bai
[ East Exhibit Hall A-C ]
Abstract
Recent approaches to vision-language tasks are built on the remarkable capabilities of large vision-language models (VLMs). These models excel in zero-shot and few-shot learning, enabling them to learn new tasks without parameter updates. However, their primary challenge lies in their design, which primarily accommodates 2D input, thus limiting their effectiveness for medical images, particularly radiological images like MRI and CT, which are typically 3D. To bridge the gap between state-of-the-art 2D VLMs and 3D medical image data, we developed an innovative, one-pass, unsupervised representative slice selection method called Vote-MI, which selects representative 2D slices from 3D medical imaging. To evaluate the effectiveness of vote-MI when implemented with VLMs, we introduce BrainMD, a robust, multimodal dataset comprising 2,453 annotated 3D MRI brain scans with corresponding textual radiology reports and electronic health records. Based on BrainMD, we further develop two benchmarks, BrainMD-select (including the most representative 2D slice of 3D image) and BrainBench (including various vision-language downstream tasks). Extensive experiments on the BrainMD dataset and its two corresponding benchmarks demonstrate that our representative selection method significantly improves performance in zero-shot and few-shot learning tasks. On average, Vote-MI achieves a 14.6\% and 16.6\% absolute gain for zero-shot and few-shot learning, respectively, compared to …
Poster
Nicholas Dronen · Bardiya Akhbari · Manish Digambar Gawali
[ West Ballroom A-D ]
Abstract
Set theory is foundational to mathematics and, when sets are finite, to reasoning about the world. An intelligent system should perform set operations consistently, regardless of superficial variations in the operands. Initially designed for semantically-oriented NLP tasks, large language models (LLMs) are now being evaluated on algorithmic tasks. Because sets are comprised of arbitrary symbols (e.g. numbers, words), they provide an opportunity to test, systematically, the invariance of LLMs’ algorithmic abilities under simple lexical or semantic variations. To this end, we present the SETLEXSEM CHALLENGE, a synthetic benchmark that evaluates the performance of LLMs on set operations. SETLEXSEM assesses the robustness of LLMs’ instruction-following abilities under various conditions, focusing on the set operations and the nature and construction of the set members. Evaluating seven LLMs with SETLEXSEM, we find that they exhibit poor robust- ness to variation in both operation and operands. We show – via the framework’s systematic sampling of set members along lexical and semantic dimensions – that LLMs are not only not robust to variation along these dimensions but demonstrate unique failure modes in particular, easy-to-create semantic groupings of "deceptive" sets. We find that rigorously measuring language model robustness to variation in frequency and length is challenging …
Poster
Polina Turishcheva · Paul Fahey · Michaela Vystrčilová · Laura Hansel · Rachel Froebe · Kayla Ponder · Yongrong Qiu · Konstantin Willeke · Mohammad Bashiri · Ruslan Baikulov · Yu Zhu · Lei Ma · Shan Yu · Tiejun Huang · Bryan Li · Wolf De Wulf · Nina Kudryashova · Matthias Hennig · Nathalie Rochefort · Arno Onken · Eric Y. Wang · Zhiwei Ding · Andreas Tolias · Fabian Sinz · Alexander Ecker
[ West Ballroom A-D ]
Abstract
Understanding how biological visual systems process information is challenging because of the nonlinear relationship between visual input and neuronal responses. Artificial neural networks allow computational neuroscientists to create predictive models that connect biological and machine vision.Machine learning has benefited tremendously from benchmarks that compare different models on the same task under standardized conditions. However, there was no standardized benchmark to identify state-of-the-art dynamic models of the mouse visual system.To address this gap, we established the SENSORIUM 2023 Benchmark Competition with dynamic input, featuring a new large-scale dataset from the primary visual cortex of ten mice. This dataset includes responses from 78,853 neurons to 2 hours of dynamic stimuli per neuron, together with behavioral measurements such as running speed, pupil dilation, and eye movements.The competition ranked models in two tracks based on predictive performance for neuronal responses on a held-out test set: one focusing on predicting in-domain natural stimuli and another on out-of-distribution (OOD) stimuli to assess model generalization.As part of the NeurIPS 2023 Competition Track, we received more than 160 model submissions from 22 teams. Several new architectures for predictive models were proposed, and the winning teams improved the previous state-of-the-art model by 50\%. Access to the dataset as well …
Poster
Mehran Kazemi · Nishanth Dikkala · Ankit Anand · Petar Devic · Ishita Dasgupta · Fangyu Liu · Bahare Fatemi · Pranjal Awasthi · Sreenivas Gollapudi · Dee Guo · Ahmed Qureshi
[ West Ballroom A-D ]

Abstract
With the continuous advancement of large language models (LLMs), it is essential to create new benchmarks to evaluate their expanding capabilities and identify areas for improvement. This work focuses on multi-image reasoning, an emerging capability in state-of-the-art LLMs. We introduce ReMI, a dataset designed to assess LLMs' ability to reason with multiple images. This dataset encompasses a diverse range of tasks, spanning various reasoning domains such as math, physics, logic, code, table/chart understanding, and spatial and temporal reasoning. It also covers a broad spectrum of characteristics found in multi-image reasoning scenarios. We have benchmarked several cutting-edge LLMs using ReMI and found a substantial gap between their performance and human-level proficiency. This highlights the challenges in multi-image reasoning and the need for further research. Our analysis also reveals the strengths and weaknesses of different models, shedding light on the types of reasoning that are currently attainable and areas where future models require improvement. We anticipate that ReMI will be a valuable resource for developing and evaluating more sophisticated LLMs capable of handling real-world multi-image understanding tasks.
Poster
Ralph Peterson · Aramis Tanelus · Christopher Ick · Bartul Mimica · Niegil Francis Muttath Joseph · Violet Ivan · Aman Choudhri · Annegret Falkner · Mala Murthy · David Schneider · Dan Sanes · Alex Williams
[ West Ballroom A-D ]

Abstract
Understanding the behavioral and neural dynamics of social interactions is a goalof contemporary neuroscience. Many machine learning methods have emergedin recent years to make sense of complex video and neurophysiological data thatresult from these experiments. Less focus has been placed on understanding howanimals process acoustic information, including social vocalizations. A criticalstep to bridge this gap is determining the senders and receivers of acoustic infor-mation in social interactions. While sound source localization (SSL) is a classicproblem in signal processing, existing approaches are limited in their ability tolocalize animal-generated sounds in standard laboratory environments. Advancesin deep learning methods for SSL are likely to help address these limitations,however there are currently no publicly available models, datasets, or benchmarksto systematically evaluate SSL algorithms in the domain of bioacoustics. Here,we present the VCL Benchmark: the first large-scale dataset for benchmarkingSSL algorithms in rodents. We acquired synchronized video and multi-channelaudio recordings of 767,295 sounds with annotated ground truth sources across 9conditions. The dataset provides benchmarks which evaluate SSL performance onreal data, simulated acoustic data, and a mixture of real and simulated data. Weintend for this benchmark to facilitate knowledge transfer between the neuroscienceand acoustic machine learning communities, which have had limited overlap.
Poster
Sanjay Haresh · Daniel Dijkman · Apratim Bhattacharyya · Roland Memisevic
[ East Exhibit Hall A-C ]
Abstract
Robotics tasks are highly compositional by nature. For example, to perform a high-level task like cleaning the table a robot must employ low-level capabilities of moving the effectors to the objects on the table, pick them up and then move them off the table one-by-one, while re-evaluating the consequently dynamic scenario in the process. Given that large vision language models (VLMs) have shown progress on many tasks that require high level, human-like reasoning, we ask the question: if the models are taught the requisite low-level capabilities, can they compose them in novel ways to achieve interesting high-level tasks like cleaning the table without having to be explicitly taught so? To this end, we present ClevrSkills - a benchmark suite for compositional reasoning in robotics. ClevrSkills is an environment suite developed on top of the ManiSkill2 simulator and an accompanying dataset. The dataset contains trajectories generated on a range of robotics tasks with language and visual annotations as well as multi-modal prompts as task specification. The suite includes a curriculum of tasks with three levels of compositional understanding, starting with simple tasks requiring basic motor skills. We benchmark multiple different VLM baselines on ClevrSkills and show that even after being pre-trained …
Spotlight Poster
Peter Jansen · Marc-Alexandre Côté · Tushar Khot · Erin Bransom · Bhavana Dalvi Mishra · Bodhisattwa Prasad Majumder · Oyvind Tafjord · Peter Clark
[ West Ballroom A-D ]

Abstract
Automated scientific discovery promises to accelerate progress across scientific domains, but evaluating an agent's capacity for end-to-end scientific reasoning is challenging as running real-world experiments is often prohibitively expensive or infeasible. In this work we introduce DiscoveryWorld, a virtual environment that enables benchmarking an agent's ability to perform complete cycles of novel scientific discovery in an inexpensive, simulated, multi-modal, long-horizon, and fictional setting.DiscoveryWorld consists of 24 scientific tasks across three levels of difficulty, each with parametric variations that provide new discoveries for agents to make across runs. Tasks require an agent to form hypotheses, design and run experiments, analyze results, and act on conclusions. Task difficulties are normed to range from straightforward to challenging for human scientists with advanced degrees. DiscoveryWorld further provides three automatic metrics for evaluating performance, including: (1) binary task completion, (2) fine-grained report cards detailing procedural scoring of task-relevant actions, and (3) the accuracy of discovered explanatory knowledge.While simulated environments such as DiscoveryWorld are low-fidelity compared to the real world, we find that strong baseline agents struggle on most DiscoveryWorld tasks, highlighting the utility of using simulated environments as proxy tasks for near-term development of scientific discovery competency in agents.
Poster
Ori Press · Andreas Hochlehnert · Ameya Prabhu · Vishaal Udandarao · Ofir Press · Matthias Bethge
[ East Exhibit Hall A-C ]

Abstract
Thousands of new scientific papers are published each month. Such information overload complicates researcher efforts to stay current with the state-of-the-art as well as to verify and correctly attribute claims. We pose the following research question: Given a text excerpt referencing a paper, could an LM act as a research assistant to correctly identify the referenced paper? We advance efforts to answer this question by building a benchmark that evaluates the abilities of LMs in citation attribution. Our benchmark, CiteME, consists of text excerpts from recent machine learning papers, each referencing a single other paper. CiteME use reveals a large gap between frontier LMs and human performance, with LMs achieving only 4.2-18.5% accuracy and humans 69.7%. We close this gap by introducing CiteAgent, an autonomous system built on the GPT-4o LM that can also search and read papers, which achieves an accuracy of 35.3% on CiteME. Overall, CiteME serves as a challenging testbed for open-ended claim attribution, driving the research community towards a future where any claim made by an LM can be automatically verified and discarded if found to be incorrect.
Poster
Spandan Madan · Will Xiao · Mingran Cao · Hanspeter Pfister · Margaret Livingstone · Gabriel Kreiman
[ East Exhibit Hall A-C ]
Abstract
We characterized the generalization capabilities of deep neural network encoding models when predicting neuronal responses from the visual cortex to flashed images. We collected MacaqueITBench, a large-scale dataset of neuronal population responses from the macaque inferior temporal (IT) cortex to over $300,000$ images, comprising $8,233$ unique natural images presented to seven monkeys over $109$ sessions. Using MacaqueITBench, we investigated the impact of distribution shifts on models predicting neuronal activity by dividing the images into Out-Of-Distribution (OOD) train and test splits. The OOD splits included variations in image contrast, hue, intensity, temperature, and saturation. Compared to the performance on in-distribution test images---the conventional way in which these models have been evaluated---models performed worse at predicting neuronal responses to out-of-distribution images, retaining as little as $20\\%$ of the performance on in-distribution test images. Additionally, the relative ranking of different models in terms of their ability to predict neuronal responses changed drastically across OOD shifts. The generalization performance under OOD shifts can be well accounted by a simple image similarity metric---the cosine distance between image representations extracted from a pre-trained object recognition model is a strong predictor of neuronal predictivity under different distribution shifts. The dataset of images, neuronal firing rate recordings, and …
Poster
Josselin Roberts · Tony Lee · Chi Heem Wong · Michihiro Yasunaga · Yifan Mai · Percy Liang
[ East Exhibit Hall A-C ]
Abstract
We introduce Image2Struct, a benchmark to evaluate vision-language models (VLMs) on extracting structure from images.Our benchmark 1) captures real-world use cases, 2) is fully automatic and does not require human judgment, and 3) is based on a renewable stream of fresh data.In Image2Struct, VLMs are prompted to generate the underlying structure (e.g., LaTeX code or HTML) from an input image (e.g., webpage screenshot).The structure is then rendered to produce an output image (e.g., rendered webpage), which is compared against the input image to produce a similarity score.This round-trip evaluation allows us to quantitatively evaluate VLMs on tasks with multiple valid structures.We create a pipeline that downloads fresh data from active online communities upon execution and evaluates the VLMs without human intervention.We introduce three domains (Webpages, LaTeX, and Musical Scores) and use five image metrics (pixel similarity, cosine similarity between the Inception vectors, learned perceptual image patch similarity, structural similarity index measure, and earth mover similarity) that allow efficient and automatic comparison between pairs of images. We evaluate Image2Struct on 14 prominent VLMs and find that scores vary widely, indicating that Image2Struct can differentiate between the performances of different VLMs.Additionally, the best score varies considerably across domains (e.g., 0.402 on sheet …
Poster
Rohan Gupta · Iván Arcuschin Moreno · Thomas Kwa · Adrià Garriga-Alonso
[ East Exhibit Hall A-C ]
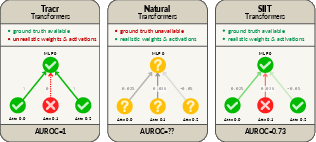
Abstract
Mechanistic interpretability methods aim to identify the algorithm a neural network implements, but it is difficult to validate such methods when the true algorithm is unknown. This work presents InterpBench, a collection of semi-synthetic yet realistic transformers with known circuits for evaluating these techniques. We train simple neural networks using a stricter version of Interchange Intervention Training (IIT) which we call Strict IIT (SIIT). Like the original, SIIT trains neural networks by aligning their internal computation with a desired high-level causal model, but it also prevents non-circuit nodes from affecting the model's output. We evaluate SIIT on sparse transformers produced by the Tracr tool and find that SIIT models maintain Tracr's original circuit while being more realistic. SIIT can also train transformers with larger circuits, like Indirect Object Identification (IOI). Finally, we use our benchmark to evaluate existing circuit discovery techniques.
Poster
Zhonghao Wang · Danyu Sun · Sheng Zhou · Haobo Wang · Jiapei Fan · Longtao Huang · Jiajun Bu
[ East Exhibit Hall A-C ]

Abstract
Graph Neural Networks (GNNs) exhibit strong potential in node classification task through a message-passing mechanism. However, their performance often hinges on high-quality node labels, which are challenging to obtain in real-world scenarios due to unreliable sources or adversarial attacks. Consequently, label noise is common in real-world graph data, negatively impacting GNNs by propagating incorrect information during training. To address this issue, the study of Graph Neural Networks under Label Noise (GLN) has recently gained traction. However, due to variations in dataset selection, data splitting, and preprocessing techniques, the community currently lacks a comprehensive benchmark, which impedes deeper understanding and further development of GLN. To fill this gap, we introduce NoisyGL in this paper, the first comprehensive benchmark for graph neural networks under label noise. NoisyGL enables fair comparisons and detailed analyses of GLN methods on noisy labeled graph data across various datasets, with unified experimental settings and interface. Our benchmark has uncovered several important insights that were missed in previous research, and we believe these findings will be highly beneficial for future studies. We hope our open-source benchmark library will foster further advancements in this field. The code of the benchmark can be found in https://github.com/eaglelab-zju/NoisyGL.
Poster
Rakshit Trivedi · Akbir Khan · Jesse Clifton · Lewis Hammond · Edgar Duenez-Guzman · Dipam Chakraborty · John Agapiou · Jayd Matyas · Sasha Vezhnevets · Barna Pásztor · Yunke Ao · Omar G. Younis · Jiawei Huang · Benjamin Swain · Haoyuan Qin · Deng · Ziwei Deng · Utku Erdoğanaras · Yue Zhao · Marko Tesic · Natasha Jaques · Jakob Foerster · Vincent Conitzer · José Hernández-Orallo · Dylan Hadfield-Menell · Joel Leibo
[ West Ballroom A-D ]
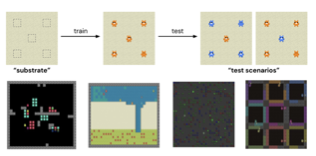
Abstract
Multi-agent AI research promises a path to develop human-like and human-compatible intelligent technologies that complement the solipsistic view of other approaches, which mostly do not consider interactions between agents. Aiming to make progress in this direction, the Melting Pot contest 2023 focused on the problem of cooperation among interacting agents and challenged researchers to push the boundaries of multi-agent reinforcement learning (MARL) for mixed-motive games. The contest leveraged the Melting Pot environment suite to rigorously evaluate how well agents can adapt their cooperative skills to interact with novel partners in unforeseen situations. Unlike other reinforcement learning challenges, this challenge focused on social rather than environmental generalization. In particular, a population of agents performs well in Melting Pot when its component individuals are adept at finding ways to cooperate both with others in their population and with strangers. Thus Melting Pot measures cooperative intelligence.The contest attracted over 600 participants across 100+ teams globally and was a success on multiple fronts: (i) it contributed to our goal of pushing the frontiers of MARL towards building more cooperatively intelligent agents, evidenced by several submissions that outperformed established baselines; (ii) it attracted a diverse range of participants, from independent researchers to industry affiliates and …
Poster
Dapeng Hu · Romy Luo · Jian Liang · Chuan Sheng Foo
[ West Ballroom A-D ]
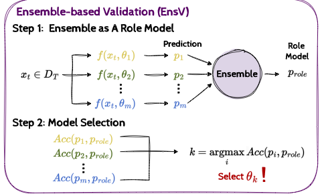
Abstract
Selecting appropriate hyperparameters is crucial for unlocking the full potential of advanced unsupervised domain adaptation (UDA) methods in unlabeled target domains. Although this challenge remains under-explored, it has recently garnered increasing attention with the proposals of various model selection methods. Reliable model selection should maintain performance across diverse UDA methods and scenarios, especially avoiding highly risky worst-case selections—selecting the model or hyperparameter with the worst performance in the pool.\textit{Are existing model selection methods reliable and versatile enough for different UDA tasks?} In this paper, we provide a comprehensive empirical study involving 8 existing model selection approaches to answer this question. Our evaluation spans 12 UDA methods across 5 diverse UDA benchmarks and 5 popular UDA scenarios.Surprisingly, we find that none of these approaches can effectively avoid the worst-case selection. In contrast, a simple but overlooked ensemble-based selection approach, which we call EnsV, is both theoretically and empirically certified to avoid the worst-case selection, ensuring high reliability. Additionally, EnsV is versatile for various practical but challenging UDA scenarios, including validation of open-partial-set UDA and source-free UDA.Finally, we call for more attention to the reliability of model selection in UDA: avoiding the worst-case is as significant as achieving peak selection performance and …
Poster
David Castillo-Bolado · Joseph Davidson · Finlay Gray · Marek Rosa
[ West Ballroom A-D ]
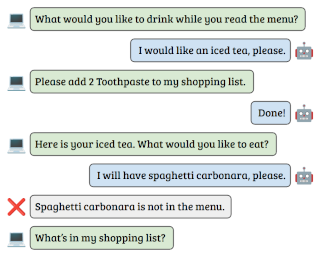
Abstract
We introduce a dynamic benchmarking system for conversational agents that evaluates their performance through a single, simulated, and lengthy user$\leftrightarrow$agent interaction. The interaction is a conversation between the user and agent, where multiple tasks are introduced and then undertaken concurrently. We context switch regularly to interleave the tasks, which constructs a realistic testing scenario in which we assess the Long-Term Memory, Continual Learning, and Information Integration capabilities of the agents. Results from both proprietary and open-source Large-Language Models show that LLMs in general perform well on single-task interactions, but they struggle on the same tasks when they are interleaved. Notably, short-context LLMs supplemented with an LTM system perform as well as or better than those with larger contexts. Our benchmark suggests that there are other challenges for LLMs responding to more natural interactions that contemporary benchmarks have heretofore not been able to capture.
Spotlight Poster
Tianyi (Alex) Qiu · Yang Zhang · Xuchuan Huang · Jasmine Li · Jiaming Ji · Yaodong Yang
[ East Exhibit Hall A-C ]
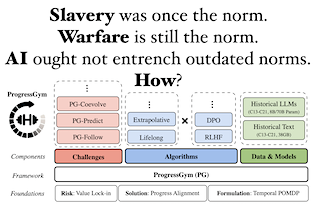
Abstract
Frontier AI systems, including large language models (LLMs), hold increasing influence over the epistemology of human users. Such influence can reinforce prevailing societal values, potentially contributing to the lock-in of misguided moral beliefs and, consequently, the perpetuation of problematic moral practices on a broad scale. We introduce **progress alignment** as a technical solution to mitigate this imminent risk. Progress alignment algorithms learn to emulate the mechanics of human moral progress, thereby addressing the susceptibility of existing alignment methods to contemporary moral blindspots. To empower research in progress alignment, we introduce [**ProgressGym**](https://github.com/PKU-Alignment/ProgressGym), an experimental framework allowing the learning of moral progress mechanics from history, in order to facilitate future progress in real-world moral decisions. Leveraging 9 centuries of historical text and 18 [historical LLMs](https://huggingface.co/collections/PKU-Alignment/progressgym-666735fcf3e4efa276226eaa), ProgressGym enables codification of real-world progress alignment challenges into concrete benchmarks. Specifically, we introduce three core challenges: tracking evolving values (PG-Follow), preemptively anticipating moral progress (PG-Predict), and regulating the feedback loop between human and AI value shifts (PG-Coevolve). Alignment methods without a temporal dimension are inapplicable to these tasks. In response, we present *lifelong* and *extrapolative* algorithms as baseline methods of progress alignment, and build an [open leaderboard](https://huggingface.co/spaces/PKU-Alignment/ProgressGym-LeaderBoard) soliciting novel algorithms and challenges.
Poster
Alexander Nikitin · Letizia Iannucci · Samuel Kaski
[ East Exhibit Hall A-C ]

Abstract
Time series data are essential in a wide range of machine learning (ML) applications. However, temporal data are often scarce or highly sensitive, limiting data sharing and the use of data-intensive ML methods. A possible solution to this problem is the generation of synthetic datasets that resemble real data. In this work, we introduce Time Series Generative Modeling (TSGM), an open-source framework for the generative modeling and evaluation of synthetic time series datasets. TSGM includes a broad repertoire of machine learning methods: generative models, probabilistic, simulation-based approaches, and augmentation techniques. The framework enables users to evaluate the quality of the produced data from different angles: similarity, downstream effectiveness, predictive consistency, diversity, fairness, and privacy. TSGM is extensible and user-friendly, which allows researchers to rapidly implement their own methods and compare them in a shareable environment. The framework has been tested on open datasets and in production and proved to be beneficial in both cases. https://github.com/AlexanderVNikitin/tsgm
Poster
Yunchao Liu · Ha Dong · Xin Wang · Rocco Moretti · Yu Wang · Zhaoqian Su · Jiawei Gu · Bobby Bodenheimer · Charles Weaver · Jens Meiler · Tyler Derr
[ West Ballroom A-D ]

Abstract
While deep learning has revolutionized computer-aided drug discovery, the AI community has predominantly focused on model innovation and placed less emphasis on establishing best benchmarking practices. We posit that without a sound model evaluation framework, the AI community's efforts cannot reach their full potential, thereby slowing the progress and transfer of innovation into real-world drug discovery.Thus, in this paper, we seek to establish a new gold standard for small molecule drug discovery benchmarking, *WelQrate*. Specifically, our contributions are threefold: ***WelQrate*** **dataset collection** - we introduce a meticulously curated collection of 9 datasets spanning 5 therapeutic target classes. Our hierarchical curation pipelines, designed by drug discovery experts, go beyond the primary high-throughput screen by leveraging additional confirmatory and counter screens along with rigorous domain-driven preprocessing, such as Pan-Assay Interference Compounds (PAINS) filtering, to ensure the high-quality data in the datasets; ***WelQrate*** **Evaluation Framework** - we propose a standardized model evaluation framework considering high-quality datasets, featurization, 3D conformation generation, evaluation metrics, and data splits, which provides a reliable benchmarking for drug discovery experts conducting real-world virtual screening; **Benchmarking** - we evaluate model performance through various research questions using the *WelQrate* dataset collection, exploring the effects of different models, dataset quality, featurization methods, …
Spotlight Poster
Zhenbang Wu · Anant Dadu · Michael Nalls · Faraz Faghri · Jimeng Sun
[ West Ballroom A-D ]

Abstract
Large language models (LLMs) have shown impressive capabilities in solving a wide range of tasks based on human instructions. However, developing a conversational AI assistant for electronic health record (EHR) data remains challenging due to (1) the lack of large-scale instruction-following datasets and (2) the limitations of existing model architectures in handling complex and heterogeneous EHR data.In this paper, we introduce MIMIC-Instr, a dataset comprising over 400K open-ended instruction-following examples derived from the MIMIC-IV EHR database. This dataset covers various topics and is suitable for instruction-tuning general-purpose LLMs for diverse clinical use cases. Additionally, we propose Llemr, a general framework that enables LLMs to process and interpret EHRs with complex data structures. Llemr demonstrates competitive performance in answering a wide range of patient-related questions based on EHR data.Furthermore, our evaluations on clinical predictive modeling benchmarks reveal that the fine-tuned Llemr achieves performance comparable to state-of-the-art (SOTA) baselines using curated features. The dataset and code are available at \url{https://github.com/zzachw/llemr}.
Poster
Huaiyuan Ying · Zijian Wu · Yihan Geng · JIayu Wang · Dahua Lin · Kai Chen
[ West Ballroom A-D ]

Abstract
Large language models have demonstrated impressive capabilities across various natural language processing tasks, especially in solving mathematical problems. However, large language models are not good at math theorem proving using formal languages like Lean. A significant challenge in this area is the scarcity of training data available in these formal languages. To address this issue, we propose a novel pipeline that iteratively generates and filters synthetic data to translate natural language mathematical problems into Lean 4 statements, and vice versa. Our results indicate that the synthetic data pipeline can provide useful training data and improve the performance of LLMs in translating and understanding complex mathematical problems and proofs. Our final dataset contains about 57K formal-informal question pairs along with searched proof from the math contest forum and 21 new IMO questions. We open-source our code at \url{https://github.com/InternLM/InternLM-Math} and our data at \url{https://huggingface.co/datasets/InternLM/Lean-Workbook}.
Spotlight Poster
Roman Bushuiev · Anton Bushuiev · Niek de Jonge · Adamo Young · Fleming Kretschmer · Raman Samusevich · Janne Heirman · Fei Wang · Luke Zhang · Kai Dührkop · Marcus Ludwig · Nils Haupt · Apurva Kalia · Corinna Brungs · Robin Schmid · Russell Greiner · Bo Wang · David Wishart · Liping Liu · Juho Rousu · Wout Bittremieux · Hannes Rost · Tytus Mak · Soha Hassoun · Florian Huber · Justin J.J. van der Hooft · Michael Stravs · Sebastian Böcker · Josef Sivic · Tomáš Pluskal
[ West Ballroom A-D ]
Abstract
The discovery and identification of molecules in biological and environmental samples is crucial for advancing biomedical and chemical sciences. Tandem mass spectrometry (MS/MS) is the leading technique for high-throughput elucidation of molecular structures. However, decoding a molecular structure from its mass spectrum is exceptionally challenging, even when performed by human experts. As a result, the vast majority of acquired MS/MS spectra remain uninterpreted, thereby limiting our understanding of the underlying (bio)chemical processes. Despite decades of progress in machine learning applications for predicting molecular structures from MS/MS spectra, the development of new methods is severely hindered by the lack of standard datasets and evaluation protocols. To address this problem, we propose MassSpecGym -- the first comprehensive benchmark for the discovery and identification of molecules from MS/MS data. Our benchmark comprises the largest publicly available collection of high-quality MS/MS spectra and defines three MS/MS annotation challenges: \textit{de novo} molecular structure generation, molecule retrieval, and spectrum simulation. It includes new evaluation metrics and a generalization-demanding data split, therefore standardizing the MS/MS annotation tasks and rendering the problem accessible to the broad machine learning community. MassSpecGym is publicly available at \url{https://github.com/pluskal-lab/MassSpecGym}.
Poster
Chenrui Wei · Mengzhou Sun · Wei Wang
[ East Exhibit Hall A-C ]

Abstract
Solving Olympiad-level mathematical problems represents a significant advancement in machine intelligence and automated reasoning. Current machine learning methods, however, struggle to solve Olympiad-level problems beyond Euclidean plane geometry due to a lack of large-scale, high-quality datasets. The challenge is even greater in algebraic systems, which involve infinite reasoning spaces within finite conditions. To address these issues, we propose *AIPS*, an *Algebraic Inequality Proving System* capable of autonomously generating complex inequality theorems and effectively solving Olympiad-level inequality problems without requiring human demonstrations. During proof search in a mixed reasoning manner, a value curriculum learning strategy on generated datasets is implemented to improve proving performance, demonstrating strong mathematical intuitions. On a test set of 20 International Mathematical Olympiad-level inequality problems, AIPS successfully solved 10, outperforming state-of-the-art methods. Furthermore, AIPS automatically generated a vast array of non-trivial theorems without human intervention, some of which have been evaluated by professional contestants and deemed to reach the level of the International Mathematical Olympiad. Notably, one theorem was selected as a competition problem in a major city's 2024 Mathematical Olympiad.All the materials are available at [sites.google.com/view/aips2](https://sites.google.com/view/aips2)
Poster
Boris Repasky · Ehsan Abbasnejad · Anthony Dick
[ West Ballroom A-D ]

Abstract
Recent advancements in pre-trained vision models have made them pivotal in computer vision, emphasizing the need for their thorough evaluation and benchmarking. This evaluation needs to consider various factors of variation, their potential biases, shortcuts, and inaccuracies that ultimately lead to disparate performance in models. Such evaluations are conventionally done using either synthetic data from 2D or 3D rendering software or real-world images in controlled settings. Synthetic methods offer full control and flexibility, while real-world methods are limited by high costs and less adaptability. Moreover, 3D rendering can't yet fully replicate real photography, creating a realism gap.In this paper, we introduce BLURD--Benchmarking and Learning using a Unified Rendering and Diffusion Model--a novel method combining 3D rendering and Stable Diffusion to bridge this gap in representation learning. With BLURD we create a new family of datasets that allow for the creation of both 3D rendered and photo-realistic images with identical factors. BLURD, therefore, provides deeper insights into the representations learned by various CLIP backbones. The source code for creating the BLURD datasets is available at https://github.com/squaringTheCircle/BLURD
Poster
Yizhe Huang · Xingbo Wang · Hao Liu · Fanqi Kong · Aoyang Qin · Min Tang · Xiaoxi Wang · Song-Chun Zhu · Mingjie Bi · Siyuan Qi · Xue Feng
[ West Ballroom A-D ]
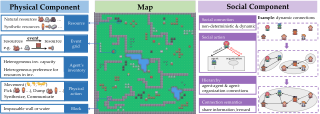
Abstract
Traditional interactive environments limit agents' intelligence growth with fixed tasks. Recently, single-agent environments address this by generating new tasks based on agent actions, enhancing task diversity. We consider the decision-making problem in multi-agent settings, where tasks are further influenced by social connections, affecting rewards and information access. However, existing multi-agent environments lack a combination of adaptive physical surroundings and social connections, hindering the learning of intelligent behaviors.To address this, we introduce AdaSociety, a customizable multi-agent environment featuring expanding state and action spaces, alongside explicit and alterable social structures. As agents progress, the environment adaptively generates new tasks with social structures for agents to undertake. In AdaSociety, we develop three mini-games showcasing distinct social structures and tasks. Initial results demonstrate that specific social structures can promote both individual and collective benefits, though current reinforcement learning and LLM-based algorithms show limited effectiveness in leveraging social structures to enhance performance. Overall, AdaSociety serves as a valuable research platform for exploring intelligence in diverse physical and social settings. The code is available at https://github.com/bigai-ai/AdaSociety.
Poster
Xuan Ju · Yiming Gao · Zhaoyang Zhang · Ziyang Yuan · Xintao Wang · AILING ZENG · Yu Xiong · Qiang Xu · Ying Shan
[ West Ballroom A-D ]
Abstract
Sora's high-motion intensity and long consistent videos have significantly impacted the field of video generation, attracting unprecedented attention. However, existing publicly available datasets are inadequate for generating Sora-like videos, as they mainly contain short videos with low motion intensity and brief captions. To address these issues, we propose MiraData, a high-quality video dataset that surpasses previous ones in video duration, caption detail, motion strength, and visual quality. We curate MiraData from diverse, manually selected sources and meticulously process the data to obtain semantically consistent clips. GPT-4V is employed to annotate structured captions, providing detailed descriptions from four different perspectives along with a summarized dense caption. To better assess temporal consistency and motion intensity in video generation, we introduce MiraBench, which enhances existing benchmarks by adding 3D consistency and tracking-based motion strength metrics. MiraBench includes 150 evaluation prompts and 17 metrics covering temporal consistency, motion strength, 3D consistency, visual quality, text-video alignment, and distribution similarity. To demonstrate the utility and effectiveness of MiraData, we conduct experiments using our DiT-based video generation model, MiraDiT. The experimental results on MiraBench demonstrate the superiority of MiraData, especially in motion strength.
Poster
Qinghua Liu · John Paparrizos
[ East Exhibit Hall A-C ]

Abstract
Time-series anomaly detection is a fundamental task across scientific fields and industries. However, the field has long faced the ``elephant in the room:'' critical issues including flawed datasets, biased evaluation measures, and inconsistent benchmarking practices that have remained largely ignored and unaddressed. We introduce the TSB-AD to systematically tackle these issues in the following three aspects: (i) Dataset Integrity: with 1070 high-quality time series from a diverse collection of 40 datasets (doubling the size of the largest collection and four times the number of existing curated datasets), we provide the first large-scale, heterogeneous, meticulously curated dataset that combines the effort of human perception and model interpretation; (ii) Measure Reliability: by revealing issues and biases in evaluation measures, we identify the most reliable and accurate measure, namely, VUS-PR for anomaly detection in time series to address concerns from the community; and (iii) Comprehensive Benchmarking: with a broad spectrum of 40 detection algorithms, from statistical methods to the latest foundation models, we perform a comprehensive evaluation that includes a thorough hyperparameter tuning and a unified setup for a fair and reproducible comparison. Our findings challenge the conventional wisdom regarding the superiority of advanced neural network architectures, revealing that simpler architectures and statistical …
Poster
Jia Li · Ge Li · Xuanming Zhang · YunFei Zhao · Yihong Dong · Zhi Jin · Binhua Li · Fei Huang · Yongbin Li
[ West Ballroom A-D ]

Abstract
How to evaluate Large Language Models (LLMs) in code generation remains an open question. Many benchmarks have been proposed, but they have two limitations, i.e., data leakage and lack of domain-specific evaluation.The former hurts the fairness of benchmarks, and the latter hinders practitioners from selecting superior LLMs for specific programming domains.To address these two limitations, we propose a new benchmark - EvoCodeBench, which has the following advances: (1) Evolving data. EvoCodeBench will be dynamically updated every period (e.g., 6 months) to avoid data leakage. This paper releases the first version - EvoCodeBench-2403, containing 275 samples from 25 repositories.(2) A domain taxonomy and domain labels. Based on the statistics of open-source communities, we design a programming domain taxonomy consisting of 10 popular domains. Based on the taxonomy, we annotate each sample in EvoCodeBench with a domain label. EvoCodeBench provides a broad platform for domain-specific evaluations.(3) Domain-specific evaluations. Besides the Pass@k, we compute the Domain-Specific Improvement (DSI) and define LLMs' comfort and strange domains. These evaluations help practitioners select superior LLMs in specific domains and discover the shortcomings of existing LLMs.Besides, EvoCodeBench is collected by a rigorous pipeline and aligns with real-world repositories in multiple aspects (e.g., code distributions).We evaluate 8 popular …
Poster
wang lin · Yueying Feng · WenKang Han · Tao Jin · Zhou Zhao · Fei Wu · Chang Yao · Jingyuan Chen
[ West Ballroom A-D ]
Abstract
Understanding human emotions is fundamental to enhancing human-computer interaction, especially for embodied agents that mimic human behavior. Traditional emotion analysis often takes a third-person perspective, limiting the ability of agents to interact naturally and empathetically. To address this gap, this paper presents $E^3$ for Exploring Embodied Emotion, the first massive first-person view video dataset. $E^3$ contains more than $50$ hours of video, capturing $8$ different emotion types in diverse scenarios and languages. The dataset features videos recorded by individuals in their daily lives, capturing a wide range of real-world emotions conveyed through visual, acoustic, and textual modalities. By leveraging this dataset, we define $4$ core benchmark tasks - emotion recognition, emotion classification, emotion localization, and emotion reasoning - supported by more than $80$k manually crafted annotations, providing a comprehensive resource for training and evaluating emotion analysis models. We further present Emotion-LlaMa, which complements visual modality with acoustic modality to enhance the understanding of emotion in first-person videos. The results of comparison experiments with a large number of baselines demonstrate the superiority of Emotion-LlaMa and set a new benchmark for embodied emotion analysis. We expect that $E^3$ can promote advances in multimodal understanding, robotics, and augmented reality, and provide a solid …
Poster
Samuele Bortolotti · Emanuele Marconato · Tommaso Carraro · Paolo Morettin · Emile van Krieken · Antonio Vergari · Stefano Teso · Andrea Passerini
[ West Ballroom A-D ]
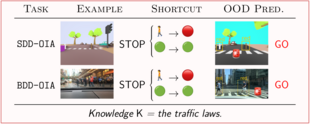
Abstract
The advent of powerful neural classifiers has increased interest in problems that require both learning and reasoning.These problems are critical for understanding important properties of models, such as trustworthiness, generalization, interpretability, and compliance to safety and structural constraints. However, recent research observed that tasks requiring both learning and reasoning on background knowledge often suffer from reasoning shortcuts (RSs): predictors can solve the downstream reasoning task without associating the correct concepts to the high-dimensional data. To address this issue, we introduce rsbench, a comprehensive benchmark suite designed to systematically evaluate the impact of RSs on models by providing easy access to highly customizable tasks affected by RSs. Furthermore, rsbench implements common metrics for evaluating concept quality and introduces novel formal verification procedures for assessing the presence of RSs in learning tasks. Using rsbench, we highlight that obtaining high quality concepts in both purely neural and neuro-symbolic models is a far-from-solved problem. rsbench is available at: https://unitn-sml.github.io/rsbench.
Poster
Xian Wu · Yutian Zhao · Yunyan Zhang · Jiageng Wu · Zhihong Zhu · Yingying Zhang · Yi Ouyang · Ziheng Zhang · Huimin WANG · zhenxi Lin · Jie Yang · Shuang Zhao · Yefeng Zheng
[ East Exhibit Hall A-C ]
Abstract
Large language models (LLMs) have demonstrated remarkable capabilities in language understanding and generation, leading to their widespread adoption across various fields. Among these, the medical field is particularly well-suited for LLM applications, as many medical tasks can be enhanced by LLMs. Despite the existence of benchmarks for evaluating LLMs in medical question-answering and exams, there remains a notable gap in assessing LLMs' performance in supporting patients throughout their entire hospital visit journey in real-world clinical practice. In this paper, we address this gap by dividing a typical patient's clinical journey into four stages: planning, access, delivery and ongoing care. For each stage, we introduce multiple tasks and corresponding datasets, resulting in a comprehensive benchmark comprising 12 datasets, of which five are newly introduced, and seven are constructed from existing datasets. This proposed benchmark facilitates a thorough evaluation of LLMs' effectiveness across the entire patient journey, providing insights into their practical application in clinical settings. Additionally, we evaluate three categories of LLMs against this benchmark: 1) proprietary LLM services such as GPT-4; 2) public LLMs like QWen; and 3) specialized medical LLMs, like HuatuoGPT2. Through this extensive evaluation, we aim to provide a better understanding of LLMs' performance in the medical …
Poster
Yiheng Wang · Tianyu Wang · YuYing Zhang · Hongji Zhang · Haoyu Zheng · Guanjie Zheng · Linghe Kong
[ West Ballroom A-D ]
Abstract
The rapid progression of urbanization has generated a diverse array of urban data, facilitating significant advancements in urban science and urban computing. Current studies often work on separate problems case by case using diverse data, e.g., air quality prediction, and built-up areas classification. This fragmented approach hinders the urban research field from advancing at the pace observed in Computer Vision and Natural Language Processing, due to two primary reasons. On the one hand, the diverse data processing steps lead to the lack of large-scale benchmarks and therefore decelerate iterative methodology improvement on a single problem. On the other hand, the disparity in multi-modal data formats hinders the combination of the related modal data to stimulate more research findings. To address these challenges, we propose UrbanDataLayer (UDL), a suite of standardized data structures and pipelines for city data engineering, providing a unified data format for researchers. This allows researchers to easily build up large-scale benchmarks and combine multi-modal data, thus expediting the development of multi-modal urban foundation models. To verify the effectiveness of our work, we present four distinct urban problem tasks utilizing the proposed data layer. UrbanDataLayer aims to enhance standardization and operational efficiency within the urban science research community. …
Poster
Sukmin Yun · haokun lin · Rusiru Thushara · Mohammad Bhat · Yongxin Wang · zutao jiang · Mingkai Deng · Jinhong Wang · Tianhua Tao · Junbo Li · Haonan Li · Preslav Nakov · Timothy Baldwin · Zhengzhong Liu · Eric Xing · Xiaodan Liang · Zhiqiang Shen
[ West Ballroom A-D ]
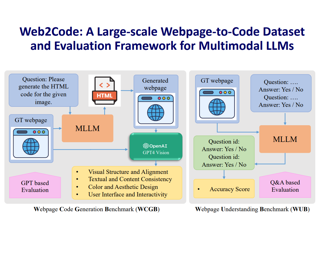
Abstract
Multimodal large language models (MLLMs) have shown impressive success across modalities such as image, video, and audio in a variety of understanding and generation tasks. However, current MLLMs are surprisingly poor at understanding webpage screenshots and generating their corresponding HTML code. To address this problem, we propose Web2Code, a benchmark consisting of a new large-scale webpage-to-code dataset for instruction tuning and an evaluation framework for the webpage understanding and HTML code translation abilities of MLLMs. For dataset construction, we leverage pretrained LLMs to enhance existing webpage-to-code datasets as well as generate a diverse pool of new webpages rendered into images. Specifically, the inputs are webpage images and instructions, while the responses are the webpage's HTML code. We further include diverse natural language QA pairs about the webpage content in the responses to enable a more comprehensive understanding of the web content. To evaluate model performance in these tasks, we develop an evaluation framework for testing MLLMs' abilities in webpage understanding and web-to-code generation. Extensive experiments show that our proposed dataset is beneficial not only to our proposed tasks but also in the general visual domain. We hope our work will contribute to the development of general MLLMs suitable for web-based …
Poster
Kuzma Khrabrov · Anton Ber · Artem Tsypin · Konstantin Ushenin · Egor Rumiantsev · Alexander Telepov · Dmitry Protasov · Ilya Shenbin · Anton Alekseev · Mikhail Shirokikh · Sergey Nikolenko · Elena Tutubalina · Artur Kadurin
[ East Exhibit Hall A-C ]

Abstract
Methods of computational quantum chemistry provide accurate approximations of molecular properties crucial for computer-aided drug discovery and other areas of chemical science. However, high computational complexity limits the scalability of their applications.Neural network potentials (NNPs) are a promising alternative to quantum chemistry methods, but they require large and diverse datasets for training.This work presents a new dataset and benchmark called $\nabla^2$DFT that is based on the nablaDFT.It contains twice as much molecular structures, three times more conformations, new data types and tasks, and state-of-the-art models.The dataset includes energies, forces, 17 molecular properties, Hamiltonian and overlap matrices, and a wavefunction object.All calculations were performed at the DFT level ($\omega$B97X-D/def2-SVP) for each conformation. Moreover, $\nabla^2$DFT is the first dataset that contains relaxation trajectories for a substantial number of drug-like molecules. We also introduce a novel benchmark for evaluating NNPs in molecular property prediction, Hamiltonian prediction, and conformational optimization tasks. Finally, we propose an extendable framework for training NNPs and implement 10 models within it.
Poster
Theodore Tsesmelis · Luca Palmieri · Marina Khoroshiltseva · Adeela Islam · Gur Elkin · Ofir I Shahar · Gianluca Scarpellini · Stefano Fiorini · Yaniv Ohayon · Nadav Alali · Sinem Aslan · Pietro Morerio · Sebastiano Vascon · Elena gravina · Maria Napolitano · Giuseppe Scarpati · Gabriel zuchtriegel · Alexandra Spühler · Michel Fuchs · Stuart James · Ohad Ben-Shahar · Marcello Pelillo · Alessio Del Bue
[ West Ballroom A-D ]

Abstract
This paper proposes the RePAIR dataset that represents a challenging benchmark to test modern computational and data driven methods for puzzle-solving and reassembly tasks. Our dataset has unique properties that are uncommon to current benchmarks for 2D and 3D puzzle solving. The fragments and fractures are realistic, caused by a collapse of a fresco during a World War II bombing at the Pompeii archaeological park. The fragments are also eroded and have missing pieces with irregular shapes and different dimensions, challenging further the reassembly algorithms. The dataset is multi-modal providing high resolution images with characteristic pictorial elements, detailed 3D scans of the fragments and meta-data annotated by the archaeologists. Ground truth has been generated through several years of unceasing fieldwork, including the excavation and cleaning of each fragment, followed by manual puzzle solving by archaeologists of a subset of approx. 1000 pieces among the 16000 available. After digitizing all the fragments in 3D, a benchmark was prepared to challenge current reassembly and puzzle-solving methods that often solve more simplistic synthetic scenarios. The tested baselines show that there clearly exists a gap to fill in solving this computationally complex problem.
Poster
Luca Barsellotti · Roberto Bigazzi · Marcella Cornia · Lorenzo Baraldi · Rita Cucchiara
[ West Ballroom A-D ]
Abstract
In the last years, the research interest in visual navigation towards objects in indoor environments has grown significantly. This growth can be attributed to the recent availability of large navigation datasets in photo-realistic simulated environments, like Gibson and Matterport3D. However, the navigation tasks supported by these datasets are often restricted to the objects present in the environment at acquisition time. Also, they fail to account for the realistic scenario in which the target object is a user-specific instance that can be easily confused with similar objects and may be found in multiple locations within the environment. To address these limitations, we propose a new task denominated Personalized Instance-based Navigation (PIN), in which an embodied agent is tasked with locating and reaching a specific personal object by distinguishing it among multiple instances of the same category. The task is accompanied by PInNED, a dedicated new dataset composed of photo-realistic scenes augmented with additional 3D objects. In each episode, the target object is presented to the agent using two modalities: a set of visual reference images on a neutral background and manually annotated textual descriptions. Through comprehensive evaluations and analyses, we showcase the challenges of the PIN task as well as the …
Poster
Tyler Bonnen · Stephanie Fu · Yutong Bai · Thomas O'Connell · Yoni Friedman · Nancy Kanwisher · Josh Tenenbaum · Alexei Efros
[ East Exhibit Hall A-C ]
Abstract
We introduce a benchmark to directly evaluate the alignment between human observers and vision models on a 3D shape inference task. We leverage an experimental design from the cognitive sciences: given a set of images, participants identify which contain the same/different objects, despite considerable viewpoint variation. We draw from a diverse range of images that include common objects (e.g., chairs) as well as abstract shapes (i.e., procedurally generated 'nonsense' objects). After constructing over 2000 unique image sets, we administer these tasks to human participants, collecting 35K trials of behavioral data from over 500 participants. This includes explicit choice behaviors as well as intermediate measures, such as reaction time and gaze data. We then evaluate the performance of common vision models (e.g., DINOv2, MAE, CLIP). We find that humans outperform all models by a wide margin. Using a multi-scale evaluation approach, we identify underlying similarities and differences between models and humans: while human-model performance is correlated, humans allocate more time/processing on challenging trials. All images, data, and code can be accessed via our project page.
Poster
Rachel Longjohn · Markelle Kelly · Sameer Singh · Padhraic Smyth
[ West Ballroom A-D ]

Abstract
In machine learning research, it is common to evaluate algorithms via their performance on standard benchmark datasets. While a growing body of work establishes guidelines for---and levies criticisms at---data and benchmarking practices in machine learning, comparatively less attention has been paid to the data repositories where these datasets are stored, documented, and shared. In this paper, we analyze the landscape of these _benchmark data repositories_ and the role they can play in improving benchmarking. This role includes addressing issues with both datasets themselves (e.g., representational harms, construct validity) and the manner in which evaluation is carried out using such datasets (e.g., overemphasis on a few datasets and metrics, lack of reproducibility). To this end, we identify and discuss a set of considerations surrounding the design and use of benchmark data repositories, with a focus on improving benchmarking practices in machine learning.
Poster
Andrej Tschalzev · Sascha Marton · Stefan Lüdtke · Christian Bartelt · Heiner Stuckenschmidt
[ West Ballroom A-D ]
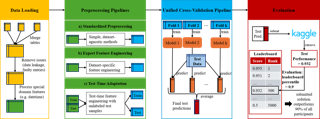
Abstract
Tabular data is prevalent in real-world machine learning applications, and new models for supervised learning of tabular data are frequently proposed. Comparative studies assessing performance differences typically have model-centered evaluation setups with overly standardized data preprocessing. This limits the external validity of these studies, as in real-world modeling pipelines, models are typically applied after dataset-specific preprocessing and feature engineering. We address this gap by proposing a data-centric evaluation framework. We select 10 relevant datasets from Kaggle competitions and implement expert-level preprocessing pipelines for each dataset. We conduct experiments with different preprocessing pipelines and hyperparameter optimization (HPO) regimes to quantify the impact of model selection, HPO, feature engineering, and test-time adaptation. Our main findings reveal: 1) After dataset-specific feature engineering, model rankings change considerably, performance differences decrease, and the importance of model selection reduces. 2) Recent models, despite their measurable progress, still significantly benefit from manual feature engineering. This holds true for both tree-based models and neural networks. 3) While tabular data is typically considered static, samples are often collected over time, and adapting to distribution shifts can be important even in supposedly static data. These insights suggest that research efforts should be directed toward a data-centric perspective, acknowledging that tabular …
Poster
Chaochao Chen · Jiaming Zhang · Yizhao Zhang · Li Zhang · Lingjuan Lyu · Yuyuan Li · Biao Gong · Chenggang Yan
[ East Exhibit Hall A-C ]
Abstract
With increasing privacy concerns in artificial intelligence, regulations have mandated the right to be forgotten, granting individuals the right to withdraw their data from models. Machine unlearning has emerged as a potential solution to enable selective forgetting in models, particularly in recommender systems where historical data contains sensitive user information. Despite recent advances in recommendation unlearning, evaluating unlearning methods comprehensively remains challenging due to the absence of a unified evaluation framework and overlooked aspects of deeper influence, e.g., fairness. To address these gaps, we propose CURE4Rec, the first comprehensive benchmark for recommendation unlearning evaluation. CURE4Rec covers four aspects, i.e., unlearning Completeness, recommendation Utility, unleaRning efficiency, and recommendation fairnEss, under three data selection strategies, i.e., core data, edge data, and random data. Specifically, we consider the deeper influence of unlearning on recommendation fairness and robustness towards data with varying impact levels. We construct multiple datasets with CURE4Rec evaluation and conduct extensive experiments on existing recommendation unlearning methods. Our code is released at https://github.com/xiye7lai/CURE4Rec.
Poster
Hexuan Deng · Wenxiang Jiao · Xuebo Liu · Min Zhang · Zhaopeng Tu
[ West Ballroom A-D ]
Abstract
Despite their remarkable abilities in various tasks, large language models (LLMs) still struggle with real-time information (e.g., new facts and terms) due to the knowledge cutoff in their development process. However, existing benchmarks focus on outdated content and limited fields, facing difficulties in real-time updating and leaving new terms unexplored. To address this problem, we propose an adaptive benchmark, NewTerm, for real-time evaluation of new terms. We design a highly automated construction method to ensure high-quality benchmark construction with minimal human effort, allowing flexible updates for real-time information. Empirical results on various LLMs demonstrate over 20% performance reduction caused by new terms. Additionally, while updates to the knowledge cutoff of LLMs can cover some of the new terms, they are unable to generalize to more distant new terms. We also analyze which types of terms are more challenging and why LLMs struggle with new terms, paving the way for future research. Finally, we construct NewTerm 2022 and 2023 to evaluate the new terms updated each year and will continue updating annually. The benchmark and codes can be found at https://anonymous.4open.science/r/NewTerms.
Spotlight Poster
John Arevalo · Ellen Su · Anne Carpenter · Shantanu Singh
[ East Exhibit Hall A-C ]
Abstract
Drug-target interaction (DTI) prediction is crucial for identifying new therapeutics and detecting mechanisms of action. While structure-based methods accurately model physical interactions between a drug and its protein target, cell-based assays such as Cell Painting can better capture complex DTI interactions. This paper introduces MOTIVE, a Morphological cOmpound Target Interaction Graph dataset comprising Cell Painting features for 11,000 genes and 3,600 compounds, along with their relationships extracted from seven publicly available databases. We provide random, cold-source (new drugs), and cold-target (new genes) data splits to enable rigorous evaluation under realistic use cases. Our benchmark results show that graph neural networks that use Cell Painting features consistently outperform those that learn from graph structure alone, feature-based models, and topological heuristics. MOTIVE accelerates both graph ML research and drug discovery by promoting the development of more reliable DTI prediction models. MOTIVE resources are available at https://github.com/carpenter-singh-lab/motive.
Poster
Zengzhi Wang · Xuefeng Li · Rui Xia · Pengfei Liu
[ West Ballroom A-D ]

Abstract
High-quality, large-scale corpora are the cornerstone of building foundation models. In this work, we introduce MathPile, a diverse and high-quality math-centric corpus comprising about 9.5 billion tokens. Throughout its creation, we adhered to the principle of “less is more”, firmly believing in the supremacy of data quality over quantity, even in the pre-training phase. Our meticulous data collection and processing efforts included a complex suite of preprocessing, prefiltering, language identification, cleaning, filtering, and deduplication, ensuring the high quality of our corpus. Furthermore, we performed data contamination detection on downstream benchmark test sets to eliminate duplicates and conducted continual pre-training experiments, booting the performance on common mathematical reasoning benchmarks. We aim for our MathPile to boost language models’ mathematical reasoning abilities and open-source its different versions and processing scripts to advance the field.
Poster
Joshua Robinson · Rishabh Ranjan · Weihua Hu · Kexin Huang · Jiaqi Han · Alejandro Dobles · Matthias Fey · Jan Eric Lenssen · Yiwen Yuan · Zecheng Zhang · Xinwei He · Jure Leskovec
[ West Ballroom A-D ]
Abstract
We present RelBench, a public benchmark for solving predictive tasks in relational databases with deep learning. RelBench provides databases and tasks spanning diverse domains, scales, and database dimensions, and is intended to be a foundational infrastructure for future research in this direction. We use RelBench to conduct the first comprehensive empirical study of graph neural network (GNN) based predictive models on relational data, as recently proposed by Fey et al. 2024. End-to-end learned GNNs are capable fully exploiting the predictive signal encoded in links between entities, marking a significant shift away from the dominant paradigm of manual feature engineering combined with tabular machine learning. To thoroughly evaluate GNNs against the prior gold-standard we conduct a user study, where an experienced data scientist manually engineers features for each task. In this study, GNNs learn better models whilst reducing human work needed by more than an order of magnitude. This result demonstrates the power of GNNs for solving predictive tasks in relational databases, opening up new research opportunities.
Poster
Kiran Lekkala · Henghui Bao · Peixu Cai · Wei Lim · Chen Liu · Laurent Itti
[ East Exhibit Hall A-C ]
Abstract
In this paper, we introduce the \textbf{USCILab3D dataset}, a large-scale, annotated outdoor dataset designed for versatile applications across multiple domains, including computer vision, robotics, and machine learning. The dataset was acquired using a mobile robot equipped with 5 cameras and a 32-beam, $360^{\circ}$ scanning LIDAR. The robot was teleoperated, over the course of a year and under a variety of weather and lighting conditions, through a rich variety of paths within the USC campus (229 acres = $\sim 92.7$ hectares). The raw data was annotated using state-of-the-art large foundation models, and processed to provide multi-view imagery, 3D reconstructions, semantically-annotated images and point clouds (267 semantic categories), and text descriptions of images and objects within. The dataset also offers a diverse array of complex analyses using pose-stamping and trajectory data. In sum, the dataset offers 1.4M point clouds and 10M images ($\sim 6$TB of data). Despite covering a narrower geographical scope compared to a whole-city dataset, our dataset prioritizes intricate intersections along with denser multi-view scene images and semantic point clouds, enabling more precise 3D labelling and facilitating a broader spectrum of 3D vision tasks. For data, code and more details, please visit our website.
Poster
Zibin Dong · Yifu Yuan · Jianye Hao · Fei Ni · Yi Ma · Pengyi Li · YAN ZHENG
[ West Ballroom A-D ]
Abstract
Leveraging the powerful generative capability of diffusion models (DMs) to build decision-making agents has achieved extensive success. However, there is still a demand for an easy-to-use and modularized open-source library that offers customized and efficient development for DM-based decision-making algorithms. In this work, we introduce **CleanDiffuser**, the first DM library specifically designed for decision-making algorithms. By revisiting the roles of DMs in the decision-making domain, we identify a set of essential sub-modules that constitute the core of CleanDiffuser, allowing for the implementation of various DM algorithms with simple and flexible building blocks. To demonstrate the reliability and flexibility of CleanDiffuser, we conduct comprehensive evaluations of various DM algorithms implemented with CleanDiffuser across an extensive range of tasks. The analytical experiments provide a wealth of valuable design choices and insights, reveal opportunities and challenges, and lay a solid groundwork for future research. CleanDiffuser will provide long-term support to the decision-making community, enhancing reproducibility and fostering the development of more robust solutions.
Poster
Neil Ashton · Jordan Angel · Aditya Ghate · Gaetan Kenway · Man Long Wong · Cetin Kiris · Astrid Walle · Danielle Maddix · Gary Page
[ West Ballroom A-D ]
Abstract
This paper presents a new open-source high-fidelity dataset for Machine Learning (ML) containing 355 geometric variants of the Windsor body, to help the development and testing of ML surrogate models for external automotive aerodynamics. Each Computational Fluid Dynamics (CFD) simulation was run with a GPU-native high-fidelity Wall-Modeled Large-Eddy Simulations (WMLES) using a Cartesian immersed-boundary method using more than 280M cells to ensure the greatest possible accuracy. The dataset contains geometry variants that exhibits a wide range of flow characteristics that are representative of those observed on road-cars. The dataset itself contains the 3D time-averaged volume \& boundary data as well as the geometry and force \& moment coefficients. This paper discusses the validation of the underlying CFD methods as well as contents and structure of the dataset. To the authors knowledge, this represents the first, large-scale high-fidelity CFD dataset for the Windsor body with a permissive open-source license (CC-BY-SA).
Poster
Juntao Dai · Tianle Chen · Xuyao Wang · Ziran Yang · Taiye Chen · Jiaming Ji · Yaodong Yang
[ West Ballroom A-D ]

Abstract
To mitigate the risk of harmful outputs from large vision models (LVMs), we introduce the *SafeSora* dataset to promote research on aligning text-to-video generation with human values. This dataset encompasses human preferences in text-to-video generation tasks along two primary dimensions: helpfulness and harmlessness. To capture in-depth human preferences and facilitate structured reasoning by crowdworkers, we subdivide helpfulness into 4 sub-dimensions and harmlessness into 12 sub-categories, serving as the basis for pilot annotations. The *SafeSora* dataset includes 14,711 unique prompts, 57,333 unique videos generated by 4 distinct LVMs, and 51,691 pairs of preference annotations labeled by humans. We further demonstrate the utility of the *SafeSora* dataset through several applications, including training the text-video moderation model and aligning LVMs with human preference by fine-tuning a prompt augmentation module or the diffusion model. These applications highlight its potential as the foundation for text-to-video alignment research, such as human preference modeling and the development and validation of alignment algorithms. Our project is available at https://sites.google.com/view/safe-sora.Warning: this paper contains example data that may be offensive or harmful.
Oral Poster
Christopher Wang · Adam Yaari · Aaditya Singh · Vighnesh Subramaniam · Dana Rosenfarb · Jan DeWitt · Pranav Misra · Joseph Madsen · Scellig Stone · Gabriel Kreiman · Boris Katz · Ignacio Cases · Andrei Barbu
[ East Exhibit Hall A-C ]
Abstract
We present the Brain Treebank, a large-scale dataset of electrophysiological neural responses, recorded from intracranial probes while 10 subjects watched one or more Hollywood movies. Subjects watched on average 2.6 Hollywood movies, for an average viewing time of 4.3 hours, and a total of 43 hours. The audio track for each movie was transcribed with manual corrections. Word onsets were manually annotated on spectrograms of the audio track for each movie. Each transcript was automatically parsed and manually corrected into the universal dependencies (UD) formalism, assigning a part of speech to every word and a dependency parse to every sentence. In total, subjects heard over 38,000 sentences (223,000 words), while they had on average 168 electrodes implanted. This is the largest dataset of intracranial recordings featuring grounded naturalistic language, one of the largest English UD treebanks in general, and one of only a few UD treebanks aligned to multimodal features. We hope that this dataset serves as a bridge between linguistic concepts, perception, and their neural representations. To that end, we present an analysis of which electrodes are sensitive to language features while also mapping out a rough time course of language processing across these electrodes. The Brain Treebank is …
Poster
Junyi AO · Yuancheng Wang · Xiaohai Tian · Dekun Chen · Jun Zhang · Lu Lu · Yuxuan Wang · Haizhou Li · Zhizheng Wu
[ East Exhibit Hall A-C ]
Abstract
Speech encompasses a wealth of information, including but not limited to content, paralinguistic, and environmental information.This comprehensive nature of speech significantly impacts communication and is crucial for human-computer interaction.Chat-Oriented Large Language Models (LLMs), known for their general-purpose assistance capabilities, have evolved to handle multi-modal inputs, including speech.Although these models can be adept at recognizing and analyzing speech, they often fall short of generating appropriate responses.We argue that this is due to the lack of principles on task definition and model development, which requires open-source datasets and metrics suitable for model evaluation.To bridge the gap, we present SD-Eval, a benchmark dataset aimed at multidimensional evaluation of spoken dialogue understanding and generation.SD-Eval focuses on paralinguistic and environmental information and includes 7,303 utterances, amounting to 8.76 hours of speech data. The data is aggregated from eight public datasets, representing four perspectives: emotion, accent, age, and background sound.To assess the SD-Eval benchmark dataset, we implement three different models and construct a training set following a process similar to that of SD-Eval. The training set contains 1,052.72 hours of speech data and 724.4k utterances. We also conduct a comprehensive evaluation using objective evaluation methods (e.g. BLEU and ROUGE), subjective evaluations and LLM-based metrics for the …
Poster
Dominik Hollidt · Paul Streli · Jiaxi Jiang · Yasaman Haghighi · Changlin Qian · Xintong Liu · Christian Holz
[ West Ballroom A-D ]

Abstract
Research on egocentric tasks in computer vision has mostly focused on head-mounted cameras, such as fisheye cameras or embedded cameras inside immersive headsets.We argue that the increasing miniaturization of optical sensors will lead to the prolific integration of cameras into many more body-worn devices at various locations.This will bring fresh perspectives to established tasks in computer vision and benefit key areas such as human motion tracking, body pose estimation, or action recognition---particularly for the lower body, which is typically occluded.In this paper, we introduce EgoSim, a novel simulator of body-worn cameras that generates realistic egocentric renderings from multiple perspectives across a wearer's body.A key feature of EgoSim is its use of real motion capture data to render motion artifacts, which are especially noticeable with arm- or leg-worn cameras.In addition, we introduce MultiEgoView, a dataset of egocentric footage from six body-worn cameras and ground-truth full-body 3D poses during several activities:119 hours of data are derived from AMASS motion sequences in four high-fidelity virtual environments, which we augment with 5 hours of real-world motion data from 13 participants using six GoPro cameras and 3D body pose references from an Xsens motion capture suit.We demonstrate EgoSim's effectiveness by training an end-to-end video-only 3D …
Poster
Xiao Yang · Kai Sun · Hao Xin · Yushi Sun · Nikita Bhalla · Xiangsen Chen · Sajal Choudhary · Rongze Gui · Ziran Jiang · Ziyu Jiang · Lingkun Kong · Brian Moran · Jiaqi Wang · Yifan Xu · An Yan · Chenyu Yang · Eting Yuan · Hanwen Zha · Nan Tang · Lei Chen · Nicolas Scheffer · Yue Liu · Nirav Shah · Rakesh Wanga · Anuj Kumar · Scott Yih · Xin Dong
[ West Ballroom A-D ]
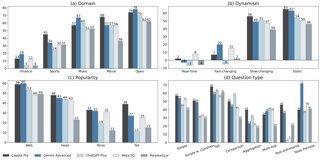
Abstract
Retrieval-Augmented Generation (RAG) has recently emerged as a promising solution to alleviate Large Language Model (LLM)’s deficiency in lack of knowledge. Existing RAG datasets, however, do not adequately represent the diverse and dynamic nature of real-world Question Answering (QA) tasks. To bridge this gap, we introduce the Comprehensive RAG Benchmark (CRAG), a factual question answering benchmark of 4,409 question-answer pairs and mock APIs to simulate web and Knowledge Graph (KG) search. CRAG is designed to encapsulate a diverse array of questions across five domains and eight question categories, reflecting varied entity popularity from popular to long-tail, and temporal dynamisms ranging from years to seconds. Our evaluation on this benchmark highlights the gap to fully trustworthy QA. Whereas most advanced LLMs achieve $\le 34\%$ accuracy on CRAG, adding RAG in a straightforward manner improves the accuracy only to 44%. State-of-the-art industry RAG solutions only answer 63% questions without any hallucination. CRAG also reveals much lower accuracy in answering questions regarding facts with higher dynamism, lower popularity, or higher complexity, suggesting future research directions. The CRAG benchmark laid the groundwork for a KDD Cup 2024 challenge, attracted thousands of participants and submissions. We commit to maintaining CRAG to serve research communities in …
Poster
Hirofumi Tsuruta · Hiroyuki Yamazaki · Ryota Maeda · Ryotaro Tamura · Akihiro Imura
[ East Exhibit Hall A-C ]
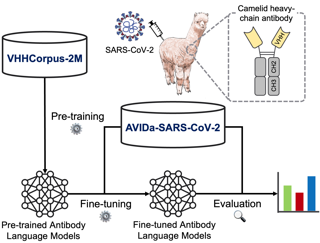
Abstract
Antibodies are crucial proteins produced by the immune system to eliminate harmful foreign substances and have become pivotal therapeutic agents for treating human diseases.To accelerate the discovery of antibody therapeutics, there is growing interest in constructing language models using antibody sequences.However, the applicability of pre-trained language models for antibody discovery has not been thoroughly evaluated due to the scarcity of labeled datasets.To overcome these limitations, we introduce AVIDa-SARS-CoV-2, a dataset featuring the antigen-variable domain of heavy chain of heavy chain antibody (VHH) interactions obtained from two alpacas immunized with severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) spike proteins.AVIDa-SARS-CoV-2 includes binary labels indicating the binding or non-binding of diverse VHH sequences to 12 SARS-CoV-2 mutants, such as the Delta and Omicron variants.Furthermore, we release VHHCorpus-2M, a pre-training dataset for antibody language models, containing over two million VHH sequences.We report benchmark results for predicting SARS-CoV-2-VHH binding using VHHBERT pre-trained on VHHCorpus-2M and existing general protein and antibody-specific pre-trained language models.These results confirm that AVIDa-SARS-CoV-2 provides valuable benchmarks for evaluating the representation capabilities of antibody language models for binding prediction, thereby facilitating the development of AI-driven antibody discovery.The datasets are available at https://datasets.cognanous.com.
Poster
Anish Madan · Neehar Peri · Shu Kong · Deva Ramanan
[ East Exhibit Hall A-C ]

Abstract
The era of vision-language models (VLMs) trained on web-scale datasets challenges conventional formulations of “open-world" perception. In this work, we revisit the task of few-shot object detection (FSOD) in the context of recent foundational VLMs. First, we point out that zero-shot predictions from VLMs such as GroundingDINO significantly outperform state-of-the-art few-shot detectors (48 vs. 33 AP) on COCO. Despite their strong zero-shot performance, such foundation models may still be sub-optimal. For example, trucks on the web may be defined differently from trucks for a target applications such as autonomous vehicle perception. We argue that the task of few-shot recognition can be reformulated as aligning foundation models to target concepts using a few examples. Interestingly, such examples can be multi-modal, using both text and visual cues, mimicking instructions that are often given to human annotators when defining a target concept of interest. Concretely, we propose Foundational FSOD, a new benchmark protocol that evaluates detectors pre-trained on any external data and fine-tuned on multi-modal (text and visual) K-shot examples per target class. We repurpose nuImages for Foundational FSOD, benchmark several popular open-source VLMs, and provide an empirical analysis of state-of-the-art methods. Lastly, we discuss our recent CVPR 2024 Foundational FSOD competition and …
Oral Poster
Dora Zhao · Morgan Scheuerman · Pooja Chitre · Jerone Andrews · Georgia Panagiotidou · Shawn Walker · Kathleen Pine · Alice Xiang
[ East Exhibit Hall A-C ]
Abstract
Despite extensive efforts to create fairer machine learning (ML) datasets, there remains a limited understanding of the practical aspects of dataset curation. Drawing from interviews with 30 ML dataset curators, we present a comprehensive taxonomy of the challenges and trade-offs encountered throughout the dataset curation lifecycle. Our findings underscore overarching issues within the broader fairness landscape that impact data curation. We conclude with recommendations aimed at fostering systemic changes to better facilitate fair dataset curation practices.
Poster
Mahmoud Ahmed · Xiang Li · Arpit Prajapati · Mohamed Elhoseiny
[ West Ballroom A-D ]
Abstract
Understanding objects in 3D at the part level is essential for humans and robots to navigate and interact with the environment. Current datasets for part-level 3D object understanding encompass a limited range of categories. For instance, the ShapeNet-Part and PartNet datasets only include 16, and 24 object categories respectively. The 3DCoMPaT dataset, specifically designed for compositional understanding of parts and materials, contains only 42 object categories. To foster richer and fine-grained part-level 3D understanding, we introduce 3DCoMPaT200, a large-scale dataset tailored for compositional understanding of object parts and materials, with 200 object categories with approximately 5 times larger object vocabulary compared to 3DCoMPaT and almost 4 times larger part categories. Concretely, 3DCoMPaT200 significantly expands upon 3DCoMPaT, featuring 1,031 fine-grained part categories and 293 distinct material classes for compositional application to 3D object parts. Additionally, to address the complexities of compositional 3D modeling, we propose a novel task of Compositional Part Shape Retrieval using ULIP to provide a strong 3D foundational model for 3D Compositional Understanding. This method evaluates the model shape retrieval performance given one, three, or six parts described in text format. These results show that the model's performance improves with an increasing number of style compositions, highlighting the …
Poster
Yibo Miao · Yifan Zhu · Lijia Yu · Jun Zhu · Xiao-Shan Gao · Yinpeng Dong
[ East Exhibit Hall A-C ]
Abstract
The recent development of Sora leads to a new era in text-to-video (T2V) generation. Along with this comes the rising concern about its safety risks. The generated videos may contain illegal or unethical content, and there is a lack of comprehensive quantitative understanding of their safety, posing a challenge to their reliability and practical deployment. Previous evaluations primarily focus on the quality of video generation. While some evaluations of text-to-image models have considered safety, they cover limited aspects and do not address the unique temporal risk inherent in video generation. To bridge this research gap, we introduce T2VSafetyBench, the first comprehensive benchmark for conducting safety-critical assessments of text-to-video models. We define 4 primary categories with 14 critical aspects of video generation safety and construct a malicious prompt dataset including real-world prompts, LLM-generated prompts, and jailbreak attack-based prompts. We then conduct a thorough safety evaluation on 9 recently released T2V models. Based on our evaluation results, we draw several important findings, including: 1) no single model excels in all aspects, with different models showing various strengths; 2) the correlation between GPT-4 assessments and manual reviews is generally high; 3) there is a trade-off between the usability and safety of text-to-video generative …
Oral Poster
Juan Nathaniel · Yongquan Qu · Tung Nguyen · Sungduk Yu · Julius Busecke · Aditya Grover · Pierre Gentine
[ West Ballroom A-D ]

Abstract
Accurate prediction of climate in the subseasonal-to-seasonal scale is crucial for disaster preparedness and robust decision making amidst climate change. Yet, forecasting beyond the weather timescale is challenging because it deals with problems other than initial condition, including boundary interaction, butterfly effect, and our inherent lack of physical understanding. At present, existing benchmarks tend to have shorter forecasting range of up-to 15 days, do not include a wide range of operational baselines, and lack physics-based constraints for explainability. Thus, we propose ChaosBench, a challenging benchmark to extend the predictability range of data-driven weather emulators to S2S timescale. First, ChaosBench is comprised of variables beyond the typical surface-atmospheric ERA5 to also include ocean, ice, and land reanalysis products that span over 45 years to allow for full Earth system emulation that respects boundary conditions. We also propose physics-based, in addition to deterministic and probabilistic metrics, to ensure a physically-consistent ensemble that accounts for butterfly effect. Furthermore, we evaluate on a diverse set of physics-based forecasts from four national weather agencies as baselines to our data-driven counterpart such as ViT/ClimaX, PanguWeather, GraphCast, and FourCastNetV2. Overall, we find methods originally developed for weather-scale applications fail on S2S task: their performance simply collapse to …
Poster
Tianwei Xiong · Yuqing Wang · Daquan Zhou · Zhijie Lin · Jiashi Feng · Xihui Liu
[ East Exhibit Hall A-C ]

Abstract
The efficacy of video generation models heavily depends on the quality of their training datasets. Most previous video generation models are trained on short video clips, while recently there has been increasing interest in training long video generation models directly on longer videos. However, the lack of such high-quality long videos impedes the advancement long video generation. To promote research in long video generation, we desire a new dataset with four key features essential for training long video generation models: (1) long videos covering at least 10 seconds, (2) long-take videos without cuts, (3) large motion and diverse contents, and (4) temporally dense captions. To achieve this, we introduce a new pipeline for filtering high-quality long-take videos and generating temporally dense captions. Specifically, we define a set of metrics to quantitatively assess video quality including scene cuts, dynamic degrees, and semantic-level scores, enabling us to filter high-quality long-take videos from a large amount of source videos. Subsequently, we develop a hierarchical video captioning pipeline to annotate long videos with temporally-dense captions. With this pipeline, we curate the first long-take video dataset, LVD-2M, comprising 2 million long-take videos, each covering more than 10 seconds and annotated with temporally dense captions. We …
Poster
Weiyun Wang · Shuibo Zhang · Yiming Ren · Yuchen Duan · Tiantong Li · Shuo Liu · Mengkang Hu · Zhe Chen · Kaipeng Zhang · Lewei Lu · Xizhou Zhu · Ping Luo · Yu Qiao · Jifeng Dai · Wenqi Shao · Wenhai Wang
[ East Exhibit Hall A-C ]

Abstract
With the rapid advancement of multimodal large language models (MLLMs), their evaluation has become increasingly comprehensive. However, understanding long multimodal content, as a foundational ability for real-world applications, remains underexplored. In this work, we present Needle In A Multimodal Haystack (MM-NIAH), the first benchmark specifically designed to systematically evaluate the capability of existing MLLMs to comprehend long multimodal documents. Our benchmark includes three types of evaluation tasks: multimodal retrieval, counting, and reasoning. In each task, the model is required to answer the questions according to different key information scattered throughout the given multimodal document. Evaluating the leading MLLMs on MM-NIAH, we observe that existing models still have significant room for improvement on these tasks, especially on vision-centric evaluation. We hope this work can provide a platform for further research on long multimodal document comprehension and contribute to the advancement of MLLMs. Code and benchmark are released at https://github.com/OpenGVLab/MM-NIAH.
Poster
Sunny Panchal · Apratim Bhattacharyya · Guillaume Berger · Antoine Mercier · Cornelius Böhm · Florian Dietrichkeit · Reza Pourreza · Xuanlin Li · Pulkit Madan · Mingu Lee · Mark Todorovich · Ingo Bax · Roland Memisevic
[ East Exhibit Hall A-C ]
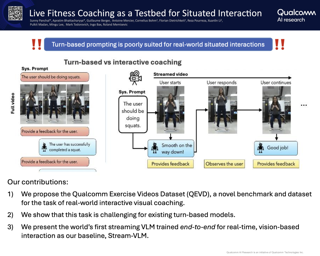
Abstract
Vision-language models have shown impressive progress in recent years. However, existing models are largely limited to turn-based interactions, where each turn must be stepped (i.e., prompted) by the user. Open-ended, asynchronous interactions, where an AI model may proactively deliver timely responses or feedback based on the unfolding situation in real-time, are an open challenge. In this work, we present the QEVD benchmark and dataset, which explores human-AI interaction in the challenging, yet controlled, real-world domain of fitness coaching – a task which intrinsically requires monitoring live user activity and providing immediate feedback. The benchmark requires vision-language models to recognize complex human actions, identify possible mistakes, and provide appropriate feedback in real-time. Our experiments reveal the limitations of existing state-of-the-art vision-language models for such asynchronous situated interactions. Motivated by this, we propose a simple end-to-end streaming baseline that can respond asynchronously to human actions with appropriate feedback at the appropriate time.
Spotlight Poster
Kefan Su · Yusen Huo · ZHILIN ZHANG · Shuai Dou · Chuan Yu · Jian Xu · Zongqing Lu · Bo Zheng
[ West Ballroom A-D ]

Abstract
Decision-making in large-scale games is an essential research area in artificial intelligence (AI) with significant real-world impact. However, the limited access to realistic large-scale game environments has hindered research progress in this area. In this paper, we present AuctionNet, a benchmark for bid decision-making in large-scale ad auctions derived from a real-world online advertising platform. AuctionNet is composed of three parts: an ad auction environment, a pre-generated dataset based on the environment, and performance evaluations of several baseline bid decision-making algorithms. More specifically, the environment effectively replicates the integrity and complexity of real-world ad auctions through the interaction of several modules: the ad opportunity generation module employs deep generative networks to bridge the gap between simulated and real-world data while mitigating the risk of sensitive data exposure; the bidding module implements diverse auto-bidding agents trained with different decision-making algorithms; and the auction module is anchored in the classic Generalized Second Price (GSP) auction but also allows for customization of auction mechanisms as needed. To facilitate research and provide insights into the environment, we have also pre-generated a substantial dataset based on the environment. The dataset contains 10 million ad opportunities, 48 diverse auto-bidding agents, and over 500 million auction records. …
Poster
Ian Magnusson · Akshita Bhagia · Valentin Hofmann · Luca Soldaini · Ananya Harsh Jha · Oyvind Tafjord · Dustin Schwenk · Evan Walsh · Yanai Elazar · Kyle Lo · Dirk Groeneveld · Iz Beltagy · Hanna Hajishirzi · Noah Smith · Kyle Richardson · Jesse Dodge
[ West Ballroom A-D ]

Abstract
Evaluations of language models (LMs) commonly report perplexity on monolithic data held out from training. Implicitly or explicitly, this data is composed of domains—varying distributions of language. We introduce Perplexity Analysis for Language Model Assessment (Paloma), a benchmark to measure LM fit to 546 English and code domains, instead of assuming perplexity on one distribution extrapolates to others. We include two new datasets of the top 100 subreddits (e.g., r/depression on Reddit) and programming languages (e.g., Java on GitHub), both sources common in contemporary LMs. With our benchmark, we release 6 baseline 1B LMs carefully controlled to provide fair comparisons about which pretraining corpus is best and code for others to apply those controls to their own experiments. Our case studies demonstrate how the fine-grained results from Paloma surface findings such as that models pretrained without data beyond Common Crawl exhibit anomalous gaps in LM fit to many domains or that loss is dominated by the most frequently occurring strings in the vocabulary.
Poster
Xiaojuan Tang · Jiaqi Li · Yitao Liang · Song-Chun Zhu · Muhan Zhang · Zilong Zheng
[ East Exhibit Hall A-C ]
Abstract
Large Language Models (LLMs) trained on massive corpora have shown remarkable success in knowledge-intensive tasks. Yet, most of them rely on pre-stored knowledge. Inducing new general knowledge from a specific environment andperforming reasoning with the acquired knowledge—situated inductive reasoning, is crucial and challenging for machine intelligence. In this paper, we design Mars, an interactive environment devised for situated inductive reasoning. It introduces counter-commonsense game mechanisms by modifying terrain, survival setting and task dependency while adhering to certain principles. In Mars, agents need to actively interact with their surroundings, derive useful rules and perform decision-making tasks in specific contexts. We conduct experiments on various RL-based and LLM-based methods, finding that they all struggle on this challenging situated inductive reasoning benchmark. Furthermore, we explore Induction from Reflection, where we instruct agents to perform inductive reasoning from history trajectory. The superior performance underscores the importance of inductive reasoning in Mars. Through Mars, we aim to galvanize advancements in situated inductive reasoning and set the stage for developing the next generation of AI systems that can reason in an adaptive and context-sensitive way.
Poster
Nemin Wu · Qian Cao · Zhangyu Wang · Zeping Liu · Yanlin Qi · Jielu Zhang · Joshua Ni · X. Yao · Hongxu Ma · Lan Mu · Stefano Ermon · Tanuja Ganu · Akshay Nambi · Ni Lao · Gengchen Mai
[ West Ballroom A-D ]

Abstract
Spatial representation learning (SRL) aims at learning general-purpose neural network representations from various types of spatial data (e.g., points, polylines, polygons, networks, images, etc.) in their native formats. Learning good spatial representations is a fundamental problem for various downstream applications such as species distribution modeling, weather forecasting, trajectory generation, geographic question answering, etc. Even though SRL has become the foundation of almost all geospatial artificial intelligence (GeoAI) research, we have not yet seen significant efforts to develop an extensive deep learning framework and benchmark to support SRL model development and evaluation. To fill this gap, we propose TorchSpatial, a learning framework and benchmark for location (point) encoding,which is one of the most fundamental data types of spatial representation learning. TorchSpatial contains three key components: 1) a unified location encoding framework that consolidates 15 commonly recognized location encoders, ensuring scalability and reproducibility of the implementations; 2) the LocBench benchmark tasks encompassing 7 geo-aware image classification and 10 geo-aware imageregression datasets; 3) a comprehensive suite of evaluation metrics to quantify geo-aware models’ overall performance as well as their geographic bias, with a novel Geo-Bias Score metric. Finally, we provide a detailed analysis and insights into the model performance and geographic bias of …
Poster
Yuxin Wang · Duanyu Feng · Yongfu Dai · Zhengyu Chen · Jimin Huang · Sophia Ananiadou · Qianqian Xie · Hao Wang
[ West Ballroom A-D ]

Abstract
Data serves as the fundamental basis for advancing deep learning. The tabular data presented in a structured format is highly valuable for modeling and training.However, even in the era of LLM, obtaining tabular data from sensitive domains remains a challenge due to privacy or copyright concerns. Therefore, exploring the methods for effectively using models like LLMs to generate synthetic tabular data, which is privacy-preserving but similar to original one, is urgent.In this paper, we introduce a new framework HARMONIC for tabular data generation and evaluation by LLMs. In the data generation part of our framework, we employ fine-tuning to generate tabular data and enhance privacy rather than continued pre-training which is often used by previous small-scale LLM-based methods. In particular, we construct an instruction fine-tuning dataset based on the idea of the k-nearest neighbors algorithm to inspire LLMs to discover inter-row relationships. By such fine-tuning, LLMs are trained to remember the format and connections of the data rather than the data itself, which reduces the risk of privacy leakage. The experiments find that our tabular data generation achieves equivalent performance as existing methods but with better privacy by the metric of MLE, DCR, etc.In the evaluation part of our framework, …
Spotlight Poster
Wei Li · William Bishop · Alice Li · Christopher Rawles · Folawiyo Campbell-Ajala · Divya Tyamagundlu · Oriana Riva
[ West Ballroom A-D ]

Abstract
Autonomous agents that control user interfaces to accomplish human tasks are emerging. Leveraging LLMs to power such agents has been of special interest, but unless fine-tuned on human-collected task demonstrations, performance is still relatively low. In this work we study whether fine-tuning alone is a viable approach for building real-world UI control agents. To this end we collect and release a new dataset, AndroidControl, consisting of 15,283 demonstrations of everyday tasks with Android apps. Compared to existing datasets, each AndroidControl task instance includes both high and low-level human-generated instructions, allowing us to explore the level of task complexity an agent can handle. Moreover, AndroidControl is the most diverse computer control dataset to date, including 14,548 unique tasks over 833 Android apps, thus allowing us to conduct in-depth analysis of the model performance in and out of the domain of the training data. Using the dataset, we find that when tested in domain fine-tuned models outperform zero and few-shot baselines and scale in such a way that robust performance might feasibly be obtained simply by collecting more data. Out of domain, performance scales significantly more slowly and suggests that in particular for high-level tasks, fine-tuning on more data alone may be …
Poster
Jiawen Zhang · Xumeng Wen · Zhenwei Zhang · Shun Zheng · Jia Li · Jiang Bian
[ West Ballroom A-D ]
Abstract
Delivering precise point and distributional forecasts across a spectrum of prediction horizons represents a significant and enduring challenge in the application of time-series forecasting within various industries.Prior research on developing deep learning models for time-series forecasting has often concentrated on isolated aspects, such as long-term point forecasting or short-term probabilistic estimations. This narrow focus may result in skewed methodological choices and hinder the adaptability of these models to uncharted scenarios.While there is a rising trend in developing universal forecasting models, a thorough understanding of their advantages and drawbacks, especially regarding essential forecasting needs like point and distributional forecasts across short and long horizons, is still lacking.In this paper, we present ProbTS, a benchmark tool designed as a unified platform to evaluate these fundamental forecasting needs and to conduct a rigorous comparative analysis of numerous cutting-edge studies from recent years.We dissect the distinctive data characteristics arising from disparate forecasting requirements and elucidate how these characteristics can skew methodological preferences in typical research trajectories, which often fail to fully accommodate essential forecasting needs.Building on this, we examine the latest models for universal time-series forecasting and discover that our analyses of methodological strengths and weaknesses are also applicable to these universal models.Finally, we …
Poster
Guangzhao Cheng · Chengbo Fu · Lu Cheng
[ East Exhibit Hall A-C ]

Abstract
Nanopore sequencing is the third-generation sequencing technology with capabilities of generating long-read sequences and directly measuring modifications on DNA/RNA molecules, which makes it ideal for biological applications such as human Telomere-to-Telomere (T2T) genome assembly, Ebola virus surveillance and COVID-19 mRNA vaccine development. However, accuracies of computational methods in various tasks of Nanopore sequencing data analysis are far from satisfactory. For instance, the base calling accuracy of Nanopore RNA sequencing is $\sim$90\%, while the aim is $\sim$99.9\%. This highlights an urgent need of contributions from the machine learning community. A bottleneck that prevents machine learning researchers from entering this field is the lack of a large integrated benchmark dataset. To this end, we present NanoBaseLib, a comprehensive multi-task benchmark dataset. It integrates 16 public datasets with over 30 million reads for four critical tasks in Nanopore data analysis. To facilitate method development, we have preprocessed all the raw data using a uniform workflow, stored all the intermediate results in uniform formats, analysed test datasets with various baseline methods for four benchmark tasks, and developed a software package to easily access these results. NanoBaseLib is available at https://nanobaselib.github.io.
Poster
Chunhui Zhang · Li Liu · Guanjie Huang · Hao Wen · XI ZHOU · Yanfeng Wang
[ West Ballroom A-D ]

Abstract
Underwater Object Tracking (UOT) is essential for identifying and tracking submerged objects in underwater videos, but existing datasets are limited in scale, diversity of target categories and scenarios covered, impeding the development of advanced tracking algorithms. To bridge this gap, we take the first step and introduce WebUOT-1M, \ie, the largest public UOT benchmark to date, sourced from complex and realistic underwater environments. It comprises 1.1 million frames across 1,500 video clips filtered from 408 target categories, largely surpassing previous UOT datasets, \eg, UVOT400. Through meticulous manual annotation and verification, we provide high-quality bounding boxes for underwater targets. Additionally, WebUOT-1M includes language prompts for video sequences, expanding its application areas, \eg, underwater vision-language tracking. Given that most existing trackers are designed for open-air conditions and perform poorly in underwater environments due to domain gaps, we propose a novel framework that uses omni-knowledge distillation to train a student Transformer model effectively. To the best of our knowledge, this framework is the first to effectively transfer open-air domain knowledge to the UOT model through knowledge distillation, as demonstrated by results on both existing UOT datasets and the newly proposed WebUOT-1M. We have thoroughly tested WebUOT-1M with 30 deep trackers, showcasing its potential …
Poster
Xingming Long · Jie Zhang · Shiguang Shan · Xilin Chen
[ West Ballroom A-D ]
Abstract
Most existing out-of-distribution (OOD) detection benchmarks classify samples with novel labels as the OOD data. However, some marginal OOD samples actually have close semantic contents to the in-distribution (ID) sample, which makes determining the OOD sample a Sorites Paradox. In this paper, we construct a benchmark named Incremental Shift OOD (IS-OOD) to address the issue, in which we divide the test samples into subsets with different semantic and covariate shift degrees relative to the ID dataset. The data division is achieved through a shift measuring method based on our proposed Language Aligned Image feature Decomposition (LAID). Moreover, we construct a Synthetic Incremental Shift (Syn-IS) dataset that contains high-quality generated images with more diverse covariate contents to complement the IS-OOD benchmark. We evaluate current OOD detection methods on our benchmark and find several important insights: (1) The performance of most OOD detection methods significantly improves as the semantic shift increases; (2) Some methods like GradNorm may have different OOD detection mechanisms as they rely less on semantic shifts to make decisions; (3) Excessive covariate shifts in the image are also likely to be considered as OOD for some methods. Our code and data are released in https://github.com/qqwsad5/IS-OOD.
Poster
Yutao Dou · Huimin Yu · Wei Li · Jingyang Li · Fei Xia · Jian Xiao
[ West Ballroom A-D ]

Abstract
Over half of cancer patients experience long-term pain management challenges. Recently, interest has grown in systems for cancer pain treatment effectiveness assessment (TEA) and medication recommendation (MR) to optimize pharmacological care. These systems aim to improve treatment effectiveness by recommending personalized medication plans based on comprehensive patient information. Despite progress, current systems lack multidisciplinary treatment (MDT) team assessments of treatment and the patient's perception of medication, crucial for effective cancer pain management. Moreover, managing cancer pain medication requires multiple adjustments to the treatment plan based on the patient's evolving condition, a detail often missing in existing datasets. To tackle these issues, we designed the PEACE dataset specifically for cancer pain medication research. It includes detailed pharmacological care records for over 38,000 patients, covering demographics, clinical examination, treatment outcomes, medication plans, and patient self-perceptions. Unlike existing datasets, PEACE records not only long-term and multiple follow-ups both inside and outside hospitals but also includes patients' self-assessments of medication effects and the impact on their lives. We conducted a proof-of-concept study with 13 machine learning algorithms on the PEACE dataset for the TEA (classification task) and MR (regression task). These experiments provide valuable insights into the potential of the PEACE dataset for advancing …
Poster
Robin Hesse · Simone Schaub-Meyer · Stefan Roth
[ East Exhibit Hall A-C ]
Abstract
Attribution maps are one of the most established tools to explain the functioning of computer vision models. They assign importance scores to input features, indicating how relevant each feature is for the prediction of a deep neural network. While much research has gone into proposing new attribution methods, their proper evaluation remains a difficult challenge. In this work, we propose a novel evaluation protocol that overcomes two fundamental limitations of the widely used incremental-deletion protocol, i.e., the out-of-domain issue and lacking inter-model comparisons. This allows us to evaluate 23 attribution methods and how different design choices of popular vision backbones affect their attribution quality. We find that intrinsically explainable models outperform standard models and that raw attribution values exhibit a higher attribution quality than what is known from previous work. Further, we show consistent changes in the attribution quality when varying the network design, indicating that some standard design choices promote attribution quality.
Poster
Rudolf Laine · Bilal Chughtai · Jan Betley · Kaivalya Hariharan · Mikita Balesni · Jérémy Scheurer · Marius Hobbhahn · Alexander Meinke · Owain Evans
[ West Ballroom A-D ]
Abstract
AI assistants such as ChatGPT are trained to respond to users by saying, "I am a large language model”.This raises questions. Do such models "know'' that they are LLMs and reliably act on this knowledge? Are they "aware" of their current circumstances, such as being deployed to the public?We refer to a model's knowledge of itself and its circumstances as **situational awareness**.To quantify situational awareness in LLMs, we introduce a range of behavioral tests, based on question answering and instruction following. These tests form the **Situational Awareness Dataset (SAD)**, a benchmark comprising 7 task categories and over 13,000 questions.The benchmark tests numerous abilities, including the capacity of LLMs to (i) recognize their own generated text, (ii) predict their own behavior, (iii) determine whether a prompt is from internal evaluation or real-world deployment, and (iv) follow instructions that depend on self-knowledge.We evaluate 16 LLMs on SAD, including both base (pretrained) and chat models.While all models perform better than chance, even the highest-scoring model (Claude 3 Opus) is far from a human baseline on certain tasks. We also observe that performance on SAD is only partially predicted by metrics of general knowledge. Chat models, which are finetuned to serve as AI assistants, …
Poster
Jihyung Kil · Zheda Mai · Justin Lee · Arpita Chowdhury · Zihe Wang · Kerrie Cheng · Lemeng Wang · Ye Liu · Wei-Lun (Harry) Chao
[ West Ballroom A-D ]
Abstract
The ability to compare objects, scenes, or situations is crucial for effective decision-making and problem-solving in everyday life. For instance, comparing the freshness of apples enables better choices during grocery shopping, while comparing sofa designs helps optimize the aesthetics of our living space. Despite its significance, the comparative capability is largely unexplored in artificial general intelligence (AGI). In this paper, we introduce MLLM-CompBench, a benchmark designed to evaluate the comparative reasoning capability of multimodal large language models (MLLMs). MLLM-CompBench mines and pairs images through visually oriented questions covering eight dimensions of relative comparison: visual attribute, existence, state, emotion, temporality, spatiality, quantity, and quality. We curate a collection of around 40K image pairs using metadata from diverse vision datasets and CLIP similarity scores. These image pairs span a broad array of visual domains, including animals, fashion, sports, and both outdoor and indoor scenes. The questions are carefully crafted to discern relative characteristics between two images and are labeled by human annotators for accuracy and relevance. We use MLLM-CompBench to evaluate recent MLLMs, including GPT-4V(ision), Gemini-Pro, and LLaVA-1.6. Our results reveal notable shortcomings in their comparative abilities. We believe MLLM-CompBench not only sheds light on these limitations but also establishes a solid …
Spotlight Poster
Edoardo Debenedetti · Javier Rando · Daniel Paleka · Silaghi Florin · Dragos Albastroiu · Niv Cohen · Yuval Lemberg · Reshmi Ghosh · Rui Wen · Ahmed Salem · Giovanni Cherubin · Santiago Zanella-Beguelin · Robin Schmid · Victor Klemm · Takahiro Miki · Chenhao Li · Stefan Kraft · Mario Fritz · Florian Tramer · Sahar Abdelnabi · Lea Schönherr
[ West Ballroom A-D ]
Abstract
Large language model systems face significant security risks from maliciously crafted messages that aim to overwrite the system's original instructions or leak private data. To study this problem, we organized a capture-the-flag competition at IEEE SaTML 2024, where the flag is a secret string in the LLM system prompt. The competition was organized in two phases. In the first phase, teams developed defenses to prevent the model from leaking the secret. During the second phase, teams were challenged to extract the secrets hidden for defenses proposed by the other teams. This report summarizes the main insights from the competition. Notably, we found that all defenses were bypassed at least once, highlighting the difficulty of designing a successful defense and the necessity for additional research to protect LLM systems. To foster future research in this direction, we compiled a dataset with over 137k multi-turn attack chats and open-sourced the platform.
Poster
Haoxin Liu · Shangqing Xu · Zhiyuan Zhao · Lingkai Kong · Harshavardhan Prabhakar Kamarthi · Aditya Sasanur · Megha Sharma · Jiaming Cui · Qingsong Wen · Chao Zhang · B. Aditya Prakash
[ East Exhibit Hall A-C ]
Abstract
Time series data are ubiquitous across a wide range of real-world domains. Whilereal-world time series analysis (TSA) requires human experts to integrate numerical series data with multimodal domain-specific knowledge, most existing TSAmodels rely solely on numerical data, overlooking the significance of information beyond numerical series. This oversight is due to the untapped potentialof textual series data and the absence of a comprehensive, high-quality multimodal dataset. To overcome this obstacle, we introduce Time-MMD, the firstmulti-domain, multimodal time series dataset covering 9 primary data domains.Time-MMD ensures fine-grained modality alignment, eliminates data contamination, and provides high usability. Additionally, we develop MM-TSFlib, thefirst-cut multimodal time-series forecasting (TSF) library, seamlessly pipeliningmultimodal TSF evaluations based on Time-MMD for in-depth analyses. Extensiveexperiments conducted on Time-MMD through MM-TSFlib demonstrate significant performance enhancements by extending unimodal TSF to multimodality,evidenced by over 15% mean squared error reduction in general, and up to 40%in domains with rich textual data. More importantly, our datasets and libraryrevolutionize broader applications, impacts, research topics to advance TSA. Thedataset is available at https://github.com/AdityaLab/Time-MMD.
Poster
Ke Wang · Junting Pan · Weikang Shi · Zimu Lu · Houxing Ren · Aojun Zhou · Mingjie Zhan · Hongsheng Li
[ East Exhibit Hall A-C ]
Abstract
Recent advancements in Large Multimodal Models (LMMs) have shown promising results in mathematical reasoning within visual contexts, with models exceeding human-level performance on existing benchmarks such as MathVista. However, we observe significant limitations in the diversity of questions and breadth of subjects covered by these benchmarks. To address this issue, we present the MATH-Vision (MATH-V) dataset, a meticulously curated collection of 3,040 high-quality mathematical problems with visual contexts sourced from real math competitions. Spanning 16 distinct mathematical disciplines and graded across 5 levels of difficulty, our dataset provides a comprehensive and diverse set of challenges for evaluating the mathematical reasoning abilities of LMMs. Through extensive experimentation, we unveil a notable performance gap between current LMMs and human performance on \datasetname, underscoring the imperative for further advancements in LMMs. Moreover, our detailed categorization allows for a thorough error analysis of LMMs, offering valuable insights to guide future research and development. The dataset is released at [MathLLMs/MathVision](https://huggingface.co/datasets/MathLLMs/MathVision)
Poster
Haoyu Geng · Hang Ruan · Runzhong Wang · Yang Li · YANG WANG · Lei Chen · Junchi Yan
[ West Ballroom A-D ]
Abstract
Predictive combinatorial optimization, where the parameters of combinatorial optimization (CO) are unknown at the decision-making time, is the precise modeling of many real-world applications, including energy cost-aware scheduling and budget allocation on advertising. Tackling such a problem usually involves a prediction model and a CO solver. These two modules are integrated into the predictive CO pipeline following two design principles: ''Predict-then-Optimize (PtO)'', which learns predictions by supervised training and subsequently solves CO using predicted coefficients, while the other, named ''Predict-and-Optimize (PnO)'', directly optimizes towards the ultimate decision quality and claims to yield better decisions than traditional PtO approaches. However, there lacks a systematic benchmark of both approaches, including the specific design choices at the module level, as well as an evaluation dataset that covers representative real-world scenarios. To this end, we develop a modular framework to benchmark 11 existing PtO/PnO methods on 8 problems, including a new industrial dataset for combinatorial advertising that will be released. Our study shows that PnO approaches are better than PtO on 7 out of 8 benchmarks, but there is no silver bullet found for the specific design choices of PnO. A comprehensive categorization of current approaches and integration of typical scenarios are provided under …
Poster
Chuanyi Xue · Qihan Liu · Xiaoteng Ma · Xinyao Qin · Gui Ning · Yang Qi · Jinsheng Ren · Bin Liang · Jun Yang
[ West Ballroom A-D ]
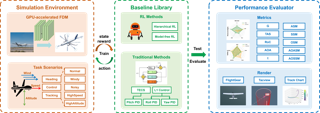
Abstract
Reinforcement learning (RL) demonstrates superior potential over traditional flight control methods for fixed-wing aircraft, particularly under extreme operational conditions. However, the high demand for training samples and the lack of efficient computation in existing simulators hinder its further application. In this paper, we introduce NeuralPlane, the first benchmark platform for large-scale parallel simulations of fixed-wing aircraft. NeuralPlane significantly boosts high-fidelity simulation via GPU-accelerated Flight Dynamics Model (FDM) computation, achieving a single-step simulation time of just 0.2 seconds at a parallel scale of $10^{6}$, far exceeding current platforms. We also provide clear code templates, comprehensive evaluation/visualization tools and hierarchical frameworks for integrating RL and traditional control methods. We believe that NeuralPlane can accelerate the development of RL-based fixed-wing flight control and serve as a new challenging benchmark for the RL community. Our NeuralPlane is open-source and accessible at https://github.com/xuecy22/NeuralPlane.
Poster
Ziyu Liu · Tao Chu · Yuhang Zang · Xilin Wei · Xiaoyi Dong · Pan Zhang · Zijian Liang · Yuanjun Xiong · Yu Qiao · Dahua Lin · Jiaqi Wang
[ West Ballroom A-D ]

Abstract
Generating natural and meaningful responses to communicate with multi-modal human inputs is a fundamental capability of Large Vision-Language Models (LVLMs). While current open-source LVLMs demonstrate promising performance in simplified scenarios such as single-turn single-image input, they fall short in real-world conversation scenarios such as following instructions in a long context history with multi-turn and multi-images. Existing LVLM benchmarks primarily focus on single-choice questions or short-form responses, which do not adequately assess the capabilities of LVLMs in real-world human-AI interaction applications. Therefore, we introduce MMDU, a comprehensive benchmark, and MMDU-45k, a large-scale instruction tuning dataset, designed to evaluate and improve LVLMs' abilities in multi-turn and multi-image conversations. We employ the clustering algorithm to find the relevant images and textual descriptions from the open-source Wikipedia and construct the question-answer pairs by human annotators with the assistance of the GPT-4o model.MMDU has a maximum of 18k image+text tokens, 20 images, and 27 turns, which is at least 5x longer than previous benchmarks and poses challenges to current LVLMs. Our in-depth analysis of 15 representative LVLMs using MMDU reveals that open-source LVLMs lag behind closed-source counterparts due to limited conversational instruction tuning data.We demonstrate that fine-tuning open-source LVLMs on MMDU-45k significantly address this gap, …
Poster
Zhongkai Shangguan · Zanming Huang · Eshed Ohn-Bar · Ola Ozernov-Palchik · Derek Kosty · Michael Stoolmiller · Hank Fien
[ East Exhibit Hall A-C ]
Abstract
Models for student reading performance can empower educators and institutions to proactively identify at-risk students, thereby enabling early and tailored instructional interventions. However, there are no suitable publicly available educational datasets for modeling and predicting future reading performance. In this work, we introduce the Enhanced Core Reading Instruction (ECRI) dataset, a novel large-scale longitudinal tabular dataset collected across 44 schools with 6,916 students and 172 teachers. We leverage the dataset to empirically evaluate the ability of state-of-the-art machine learning models to recognize early childhood educational patterns in multivariate and partial measurements. Specifically, we demonstrate a simple self-supervised strategy in which a Multi-Layer Perception (MLP) network is pre-trained over masked inputs to outperform several strong baselines while generalizing over diverse educational settings. To facilitate future developments in precise modeling and responsible use of models for individualized and early intervention strategies, our data and code are available at https://ecri-data.github.io/.
Poster
Jeffrey Li · Alex Fang · Georgios Smyrnis · Maor Ivgi · Matt Jordan · Samir Yitzhak Gadre · Hritik Bansal · Etash Guha · Sedrick Scott Keh · Kushal Arora · Saurabh Garg · Rui Xin · Niklas Muennighoff · Reinhard Heckel · Jean Mercat · Mayee Chen · Suchin Gururangan · Mitchell Wortsman · Alon Albalak · Yonatan Bitton · Marianna Nezhurina · Amro Abbas · Cheng-Yu Hsieh · Dhruba Ghosh · Josh Gardner · Maciej Kilian · Hanlin Zhang · Rulin Shao · Sarah Pratt · Sunny Sanyal · Gabriel Ilharco · Giannis Daras · Kalyani Marathe · Aaron Gokaslan · Jieyu Zhang · Khyathi Chandu · Thao Nguyen · Igor Vasiljevic · Sham Kakade · Shuran Song · Sujay Sanghavi · Fartash Faghri · Sewoong Oh · Luke Zettlemoyer · Kyle Lo · Alaaeldin El-Nouby · Hadi Pouransari · Alexander Toshev · Stephanie Wang · Dirk Groeneveld · Luca Soldaini · Pang Wei Koh · Jenia Jitsev · Thomas Kollar · Alex Dimakis · Yair Carmon · Achal Dave · Ludwig Schmidt · Vaishaal Shankar
[ West Ballroom A-D ]
Abstract
We introduce DataComp for Language Models, a testbed for controlled dataset experiments with the goal of improving language models.As part of DCLM, we provide a standardized corpus of 240T tokens extracted from Common Crawl, effective pretraining recipes based on the OpenLM framework, and a broad suite of 53 downstream evaluations.Participants in the DCLM benchmark can experiment with data curation strategies such as deduplication, filtering, and data mixing atmodel scales ranging from 412M to 7B parameters.As a baseline for DCLM, we conduct extensive experiments and find that model-based filtering is key to assembling a high-quality training set.The resulting dataset, DCLM-Baseline, enables training a 7B parameter language model from scratch to 63% 5-shot accuracy on MMLU with 2T training tokens.Compared to MAP-Neo, the previous state-of-the-art in open-data language models, DCLM-Baseline represents a 6 percentage point improvement on MMLU while being trained with half the compute.Our results highlight the importance of dataset design for training language models and offer a starting point for further research on data curation. We release the \dclm benchmark, framework, models, and datasets at https://www.datacomp.ai/dclm/
Poster
Shirley Wu · Shiyu Zhao · Michihiro Yasunaga · Kexin Huang · Kaidi Cao · Qian Huang · Vassilis Ioannidis · Karthik Subbian · James Zou · Jure Leskovec
[ West Ballroom A-D ]
Abstract
Answering real-world complex queries, such as complex product search, often requires accurate retrieval from semi-structured knowledge bases that involve blend of unstructured (e.g., textual descriptions of products) and structured (e.g., entity relations of products) information. However, many previous works studied textual and relational retrieval tasks as separate topics. To address the gap, we develop STARK, a large-scale Semi-structure retrieval benchmark on Textual and Relational Knowledge Bases. Our benchmark covers three domains: product search, academic paper search, and queries in precision medicine. We design a novel pipeline to synthesize realistic user queries that integrate diverse relational information and complex textual properties, together with their ground-truth answers (items). We conduct rigorous human evaluation to validate the quality of our synthesized queries. We further enhance the benchmark with high-quality human-generated queries to provide an authentic reference. STARK serves as a comprehensive testbed for evaluating the performance of retrieval systems driven by large language models (LLMs). Our experiments suggest that STARK presents significant challenges to the current retrieval and LLM systems, highlighting the need for more capable semi-structured retrieval systems.
Spotlight Poster
Mubashara Akhtar · Omar Benjelloun · Costanza Conforti · Luca Foschini · Joan Giner-Miguelez · Pieter Gijsbers · Sujata Goswami · Nitisha Jain · Michalis Karamousadakis · Michael Kuchnik · Satyapriya Krishna · Sylvain Lesage · Quentin Lhoest · Pierre Marcenac · Manil Maskey · Peter Mattson · Luis Oala · Hamidah Oderinwale · Pierre Ruyssen · Tim Santos · Rajat Shinde · Elena Simperl · Arjun Suresh · Goeffry Thomas · Slava Tykhonov · Joaquin Vanschoren · Susheel Varma · Jos van der Velde · Steffen Vogler · Carole-Jean Wu · Luyao Zhang
[ West Ballroom A-D ]
Abstract
Data is a critical resource for machine learning (ML), yet working with data remains a key friction point. This paper introduces Croissant, a metadata format for datasets that creates a shared representation across ML tools, frameworks, and platforms. Croissant makes datasets more discoverable, portable, and interoperable, thereby addressing significant challenges in ML data management. Croissant is already supported by several popular dataset repositories, spanning hundreds of thousands of datasets, enabling easy loading into the most commonly-used ML frameworks, regardless of where the data is stored. Our initial evaluation by human raters shows that Croissant metadata is readable, understandable, complete, yet concise.
Poster
Jae-Yong Baek · Yong-Sang Yoo · Seung-Hwan Bae
[ West Ballroom A-D ]

Abstract
This paper addresses a multi-source light detection (LD) problem from vehicles, traffic signals, and streetlights under driving scenarios. Albeit it is crucial for autonomous driving and night vision, this problem has not been yet focused on as much as other object detection (OD). One of the main reasons is the absence of a public available LD benchmark dataset. Therefore, we construct a new large LD dataset consisting of different light sources via heavy annotation: YouTube Driving Light Detection dataset (YDLD). Compared to the existing LD datasets, our dataset has much more images and box annotations for multi-source lights. We also provide rigorous statistical analysis and transfer learning comparison of other well-known detection benchmark datasets to prove the generality of our YDLD.For the recent object detectors, we achieve the extensive comparison results on YDLD. However, they tend to yield the low mAP scores due to the intrinsic challenges of LD caused by very tiny size and similar appearance. To resolve those, we design a novel lightness focal loss which penalizes miss-classified samples more and a lightness spatial attention prior by reflecting a global scene context. In addition, we develop a semi-supervised focal light detection (SS-FLD) by embedding our lightness focal loss …
Poster
Cristobal Eyzaguirre · Eric Tang · Shyamal Buch · Adrien Gaidon · Jiajun Wu · Juan Carlos Niebles
[ West Ballroom A-D ]
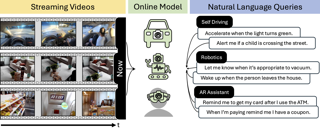
Abstract
Robotics, autonomous driving, augmented reality, and many embodied computer vision applications must quickly react to user-defined events unfolding in real time. We address this setting by proposing a novel task for multimodal video understanding---Streaming Detection of Queried Event Start (SDQES).The goal of SDQES is to identify the beginning of a complex event as described by a natural language query, with high accuracy and low latency. We introduce a new benchmark based on the Ego4D dataset, as well as new task-specific metrics to study streaming multimodal detection of diverse events in an egocentric video setting.Inspired by parameter-efficient fine-tuning methods in NLP and for video tasks, we propose adapter-based baselines that enable image-to-video transfer learning, allowing for efficient online video modeling.We evaluate three vision-language backbones and three adapter architectures on both short-clip and untrimmed video settings.
Spotlight Poster
Ge Yang · Changyi He · Jinyang Guo · Jianyu Wu · Yifu Ding · Aishan Liu · Haotong Qin · Pengliang Ji · Xianglong Liu
[ West Ballroom A-D ]

Abstract
Although large language models (LLMs) have demonstrated their strong intelligence ability, the high demand for computation and storage hinders their practical application. To this end, many model compression techniques are proposed to increase the efficiency of LLMs. However, current researches only validate their methods on limited models, datasets, metrics, etc, and still lack a comprehensive evaluation under more general scenarios. So it is still a question of which model compression approach we should use under a specific case. To mitigate this gap, we present the Large Language Model Compression Benchmark (LLMCBench), a rigorously designed benchmark with an in-depth analysis for LLM compression algorithms. We first analyze the actual model production requirements and carefully design evaluation tracks and metrics. Then, we conduct extensive experiments and comparison using multiple mainstream LLM compression approaches. Finally, we perform an in-depth analysis based on the evaluation and provide useful insight for LLM compression design. We hope our LLMCBench can contribute insightful suggestions for LLM compression algorithm design and serve as a foundation for future research.
Poster
Peng Xia · Ze Chen · Juanxi Tian · Yangrui Gong · Ruibo Hou · Yue Xu · Zhenbang Wu · Zhiyuan Fan · Yiyang Zhou · Kangyu Zhu · Wenhao Zheng · Zhaoyang Wang · Xiao Wang · Xuchao Zhang · Chetan Bansal · Marc Niethammer · Junzhou Huang · Hongtu Zhu · Yun Li · Jimeng Sun · Zongyuan Ge · Gang Li · James Zou · Huaxiu Yao
[ West Ballroom A-D ]
Abstract
Artificial intelligence has significantly impacted medical applications, particularly with the advent of Medical Large Vision Language Models (Med-LVLMs), sparking optimism for the future of automated and personalized healthcare. However, the trustworthiness of Med-LVLMs remains unverified, posing significant risks for future model deployment. In this paper, we introduce CARES and aim to comprehensively evaluate the Trustworthiness of Med-LVLMs across the medical domain. We assess the trustworthiness of Med-LVLMs across five dimensions, including trustfulness, fairness, safety, privacy, and robustness. CARES comprises about 41K question-answer pairs in both closed and open-ended formats, covering 16 medical image modalities and 27 anatomical regions. Our analysis reveals that the models consistently exhibit concerns regarding trustworthiness, often displaying factual inaccuracies and failing to maintain fairness across different demographic groups. Furthermore, they are vulnerable to attacks and demonstrate a lack of privacy awareness. We publicly release our benchmark and code in https://github.com/richard-peng-xia/CARES.
Poster
Xiaotong Li · Fan Zhang · Haiwen Diao · Yueze Wang · Xinlong Wang · LINGYU DUAN
[ West Ballroom A-D ]

Abstract
Existing Multimodal Large Language Models (MLLMs) increasingly emphasize complex understanding of various visual elements, including multiple objects, text information, spatial relations. Their development for comprehensive visual perception hinges on the availability of high-quality image-text datasets that offer diverse visual elements and throughout image descriptions. However, the scarcity of such hyper-detailed datasets currently hinders progress within the MLLM community. The bottleneck stems from the limited perceptual capabilities of current caption engines, which fall short in providing complete and accurate annotations. To facilitate the cutting-edge research of MLLMs on comprehensive vision perception, we thereby propose Perceptual Fusion, using a low-budget but highly effective caption engine for complete and accurate image descriptions. Specifically, Perceptual Fusion integrates diverse perception experts as image priors to provide explicit information on visual elements and adopts an efficient MLLM as a centric pivot to mimic advanced MLLMs' perception abilities. We carefully select 1M highly representative images from uncurated LAION dataset and generate dense descriptions using our engine, dubbed DenseFusion-1M. Extensive experiments validate that our engine outperforms its counterparts, where the resulting dataset significantly improves the perception and cognition abilities of existing MLLMs across diverse vision-language benchmarks, especially with high-resolution images as inputs. The code and dataset are available …
Poster
Haider Al-Tahan · Quentin Garrido · Randall Balestriero · Diane Bouchacourt · Caner Hazirbas · Mark Ibrahim
[ West Ballroom A-D ]

Abstract
Significant research efforts have been made to scale and improve vision-language model (VLM) training approaches. Yet, with an ever-growing number of benchmarks,researchers are tasked with the heavy burden of implementing each protocol, bearing a non-trivial computational cost, and making sense of how all these benchmarks translate into meaningful axes of progress.To facilitate a systematic evaluation of VLM progress, we introduce UniBench: a unified implementation of 50+ VLM benchmarks spanning a range of carefully categorized vision-centric capabilities from object recognition to spatial awareness, counting, and much more. We showcase the utility of UniBench for measuring progress by evaluating nearly 60 publicly available vision-language models, trained on scales of up to 12.8B samples. We find that while scaling training data or model size can boost many vision-language model capabilities, scaling offers little benefit for reasoning or relations. Surprisingly, we also discover today's best VLMs struggle on simple digit recognition and counting tasks, e.g. MNIST, which much simpler networks can solve. Where scale falls short, we find that more precise interventions, such as data quality or tailored-learning objectives offer more promise. For practitioners, we also offer guidance on selecting a suitable VLM for a given application. Finally, we release an easy-to-run UniBench code-base …
Poster
Emily Silcock · Abhishek Arora · Luca D'Amico-Wong · Melissa Dell
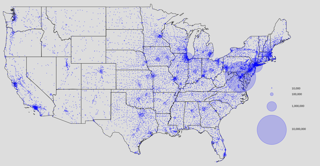
Abstract
In the U.S. historically, local newspapers drew their content largely from newswires like the Associated Press. Historians argue that newswires played a pivotal role in creating a national identity and shared understanding of the world, but there is no comprehensive archive of the content sent over newswires. We reconstruct such an archive by applying a customized deep learning pipeline to hundreds of terabytes of raw image scans from thousands of local newspapers. The resulting dataset contains 2.7 million unique public domain U.S. news wire articles, written between 1878 and 1977. Locations in these articles are georeferenced, topics are tagged using customized neural topic classification, named entities are recognized, and individuals are disambiguated to Wikipedia using a novel entity disambiguation model. To construct the Newswire dataset, we first recognize newspaper layouts and transcribe around 138 millions structured article texts from raw image scans. We then use a customized neural bi-encoder model to de-duplicate reproduced articles, in the presence of considerable abridgement and noise, quantifying how widely each article was reproduced. A text classifier is used to ensure that we only include newswire articles, which historically are in the public domain. The structured data that accompany the texts provide rich information about …
Poster
Jiefeng Ma · Yan Wang · Chenyu Liu · Jun Du · Yu Hu · Zhenrong Zhang · Pengfei Hu · Qing Wang · Jianshu Zhang
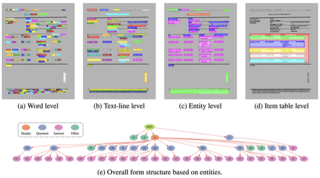
Abstract
Accurately identifying and organizing textual content is crucial for the automation of document processing in the field of form understanding. Existing datasets, such as FUNSD and XFUND, support entity classification and relationship prediction tasks but are typically limited to local and entity-level annotations. This limitation overlooks the hierarchically structured representation of documents, constraining comprehensive understanding of complex forms. To address this issue, we present the SRFUND, a hierarchically structured multi-task form understanding benchmark. SRFUND provides refined annotations on top of the original FUNSD and XFUND datasets, encompassing five tasks: (1) word to text-line merging, (2) text-line to entity merging, (3) entity category classification, (4) item table localization, and (5) entity-based full-document hierarchical structure recovery. We meticulously supplemented the original dataset with missing annotations at various levels of granularity and added detailed annotations for multi-item table regions within the forms. Additionally, we introduce global hierarchical structure dependencies for entity relation prediction tasks, surpassing traditional local key-value associations. The SRFUND dataset includes eight languages including English, Chinese, Japanese, German, French, Spanish, Italian, and Portuguese, making it a powerful tool for cross-lingual form understanding. Extensive experimental results demonstrate that the SRFUND dataset presents new challenges and significant opportunities in handling diverse layouts and …
Poster
Ming Zhong · FANG LYU · Lulin Wang · Hongna Geng · Lei Qiu · Huimin Cui · Xiaobing Feng

Abstract
Compiler backends are tasked with generating executable machine code for processors. With the proliferation of diverse processors, it is imperative for programmers to tailor specific compiler backends to accommodate each one. Meanwhile, compiler backend development is a laborious and time-consuming task, lacking effective automation methods. Although language models have demonstrated strong abilities in code related tasks, the lack of appropriate datasets for compiler backend development limits the application of language models in this field.In this paper, we introduce ComBack, the first public dataset designed for improving compiler backend development capabilities of language models. ComBack includes 178 backends for mainstream compilers and three tasks including statement-level completion, next-statement suggestion and code generation, representing common development scenarios. We conducted experiments by fine-tuning six pre-trained language models with ComBack, demonstrating its effectiveness in enhancing model accuracy across the three tasks. We further evaluated the top-performing model(CodeT5+) across the three tasks for new targets, comparing its accuracy with conventional methods (Fork-Flow), ChatGPT-3.5-Turbo, and Code-LLaMA-34B-Instruct. Remarkably, fine-tuned CodeT5+ with only 220M parameters on ComBack outperformed Fork-Flow methods significantly and surpassed ChatGPT and Code-LLaMA. This suggests potential efficiency improvements in compiler development. ComBack is avaliable at https://huggingface.co/datasets/docz1105/ComBack.
Oral Poster
Nikhil Khandekar · Qiao Jin · Guangzhi Xiong · Soren Dunn · Serina Applebaum · Zain Anwar · Maame Sarfo-Gyamfi · Conrad Safranek · Abid Anwar · Andrew Zhang · Aidan Gilson · Maxwell Singer · Amisha Dave · Anrew Taylor · Aidong Zhang · Qingyu Chen · Zhiyong Lu
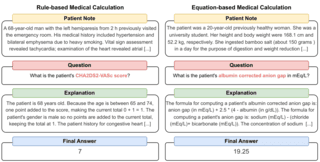
Abstract
Current benchmarks for evaluating large language models (LLMs) in medicine are primarily focused on question-answering involving domain knowledge and descriptive reasoning. While such qualitative capabilities are vital to medical diagnosis, in real-world scenarios, doctors frequently use clinical calculators that follow quantitative equations and rule-based reasoning paradigms for evidence-based decision support. To this end, we propose MedCalc-Bench, a first-of-its-kind dataset focused on evaluating the medical calculation capability of LLMs. MedCalc-Bench contains an evaluation set of over 1000 manually reviewed instances from 55 different medical calculation tasks. Each instance in MedCalc-Bench consists of a patient note, a question requesting to compute a specific medical value, a ground truth answer, and a step-by-step explanation showing how the answer is obtained. While our evaluation results show the potential of LLMs in this area, none of them are effective enough for clinical settings. Common issues include extracting the incorrect entities, not using the correct equation or rules for a calculation task, or incorrectly performing the arithmetic for the computation. We hope our study highlights the quantitative knowledge and reasoning gaps in LLMs within medical settings, encouraging future improvements of LLMs for various clinical calculation tasks. MedCalc-Bench is publicly available at: https://github.com/ncbi-nlp/MedCalc-Bench.
Poster
Xin Jin · Qianqian Qiao · Yi Lu · HuayeWang · Heng Huang · Shan Gao · Jianfei Liu · Rui Li

Abstract
Datasets play a pivotal role in training visual models, facilitating the development of abstract understandings of visual features through diverse image samples and multidimensional attributes. However, in the realm of aesthetic evaluation of artistic images, datasets remain relatively scarce. Existing painting datasets are often characterized by limited scoring dimensions and insufficient annotations, thereby constraining the advancement and application of automatic aesthetic evaluation methods in the domain of painting.To bridge this gap, we introduce the Aesthetics Paintings and Drawings Dataset (APDD), the first comprehensive collection of paintings encompassing 24 distinct artistic categories and 10 aesthetic attributes. Building upon the initial release of APDDv1, our ongoing research has identified opportunities for enhancement in data scale and annotation precision. Consequently, APDDv2 boasts an expanded image corpus and improved annotation quality, featuring detailed language comments to better cater to the needs of both researchers and practitioners seeking high-quality painting datasets.Furthermore, we present an updated version of the Art Assessment Network for Specific Painting Styles, denoted as ArtCLIP. Experimental validation demonstrates the superior performance of this revised model in the realm of aesthetic evaluation, surpassing its predecessor in accuracy and efficacy.The dataset and model are available at https://github.com/BestiVictory/APDDv2.git.
Poster
Xi Chen · Chuan Qin · Chuyu Fang · Chao Wang · chen zhu · Fuzhen Zhuang · Hengshu Zhu · Hui Xiong
Abstract
In a rapidly evolving job market, skill demand forecasting is crucial as it enables policymakers and businesses to anticipate and adapt to changes, ensuring that workforce skills align with market needs, thereby enhancing productivity and competitiveness. Additionally, by identifying emerging skill requirements, it directs individuals towards relevant training and education opportunities, promoting continuous self-learning and development. However, the absence of comprehensive datasets presents a significant challenge, impeding research and the advancement of this field. To bridge this gap, we present Job-SDF, a dataset designed to train and benchmark job-skill demand forecasting models. Based on millions of public job advertisements collected from online recruitment platforms, this dataset encompasses monthly recruitment demand.Our dataset uniquely enables evaluating skill demand forecasting models at various granularities, including occupation, company, and regional levels. We benchmark a range of models on this dataset, evaluating their performance in standard scenarios, in predictions focused on lower value ranges, and in the presence of structural breaks, providing new insights for further research. Our code and dataset are publicly accessible via the https://github.com/Job-SDF/benchmark.
Poster
Jing Yao · Xiaoyuan Yi · Xing Xie
Abstract
The rapid progress in Large Language Models (LLMs) poses potential risks such as generating unethical content. Assessing the values embedded in LLMs' generated responses can help expose their misalignment, but this relies on reference-free value evaluators, e.g. fine-tuned LLMs or closed-source models like GPT-4. Nevertheless, two key challenges emerge in open-ended value evaluation: the evaluator should adapt to changing human value definitions with minimal annotation, against their own bias (adaptability); and remain robust across varying value expressions and scenarios (generalizability). To handle these challenges, we introduce CLAVE, a novel framework that integrates two complementary LLMs: a large model to extract high-level value concepts from diverse responses, leveraging its extensive knowledge and generalizability, and a small model fine-tuned on these concepts to adapt to human value annotations. This dual-model framework enables adaptation to any value system using <100 human-labeled samples per value type. We also present ValEval, a comprehensive dataset comprising 13k+ (text,value,label) tuples across diverse domains, covering three major value systems. We benchmark the performance of 15+ popular LLM evaluators and fully analyze their strengths and weaknesses. Our findings reveal that CLAVE combining a large prompt-based model and a small fine-tuned one serves as an optimal balance in value evaluation.
Poster
Hongbin Liu · Moyang Guo · Zhengyuan Jiang · Lun Wang · Neil Gong
Abstract
The increasing realism of synthetic speech, driven by advancements in text-to-speech models, raises ethical concerns regarding impersonation and disinformation. Audio watermarking offers a promising solution via embedding human-imperceptible watermarks into AI-generated audios. However, the robustness of audio watermarking against common/adversarial perturbations remains understudied. We present AudioMarkBench, the first systematic benchmark for evaluating the robustness of audio watermarking against *watermark removal* and *watermark forgery*. AudioMarkBench includes a new dataset created from Common-Voice across languages, biological sexes, and ages, 3 state-of-the-art watermarking methods, and 15 types of perturbations. We benchmark the robustness of these methods against the perturbations in no-box, black-box, and white-box settings. Our findings highlight the vulnerabilities of current watermarking techniques and emphasize the need for more robust and fair audio watermarking solutions. Our dataset and code are publicly available at https://github.com/moyangkuo/AudioMarkBench.
Poster
Yiwei Li · Jiayi Shi · Shaoxiong Feng · Peiwen Yuan · Xinglin Wang · Boyuan Pan · Heda Wang · Yao Hu · Prof. Kan

Abstract
Instruction data is crucial for improving the capability of Large Language Models (LLMs) to align with human-level performance. Recent research LIMA demonstrates that alignment is essentially a process where the model adapts instructions' interaction style or format to solve various tasks, leveraging pre-trained knowledge and skills. Therefore, for instructional data, the most important aspect is the task it represents, rather than the specific semantics and knowledge information. The latent representations of instructions play roles for some instruction-related tasks like data selection and demonstrations retrieval. However, they are always derived from text embeddings, encompass overall semantic information that influences the representation of task categories. In this work, we introduce a new concept, instruction embedding, and construct Instruction Embedding Benchmark (IEB) for its training and evaluation. Then, we propose a baseline Prompt-based Instruction Embedding (PIE) method to make the representations more attention on tasks. The evaluation of PIE, alongside other embedding methods on IEB with two designed tasks, demonstrates its superior performance in accurately identifying task categories. Moreover, the application of instruction embeddings in four downstream tasks showcases its effectiveness and suitability for instruction-related tasks.
Poster
Xiaohan Lin · Qingxing Cao · Yinya Huang · Haiming Wang · Jianqiao Lu · Zhengying Liu · Linqi Song · Xiaodan Liang
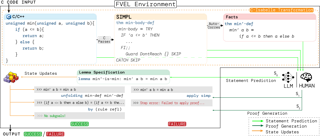
Abstract
Formal verification (FV) has witnessed growing significance with current emerging program synthesis by the evolving large language models (LLMs). However, current formal verification mainly resorts to symbolic verifiers or hand-craft rules, resulting in limitations for extensive and flexible verification. On the other hand, formal languages for automated theorem proving, such as Isabelle, as another line of rigorous verification, are maintained with comprehensive rules and theorems. In this paper, we propose FVEL, an interactive Formal Verification Environment with LLMs. Specifically, FVEL transforms a given code to be verified into Isabelle, and then conducts verification via neural automated theorem proving with an LLM. The joined paradigm leverages the rigorous yet abundant formulated and organized rules in Isabelle and is also convenient for introducing and adjusting cutting-edge LLMs. To achieve this goal, we extract a large-scale FVELER. The FVELER dataset includes code dependencies and verification processes that are formulated in Isabelle, containing 758 theories, 29,304 lemmas, and 201,498 proof steps in total with in-depth dependencies. We benchmark FVELER in the FVEL environment by first fine-tuning LLMs with FVELER and then evaluating them on Code2Inv and SV-COMP. The results show that FVEL with FVELER fine-tuned Llama3-8B solves 17.39% (69→81) more problems, and Mistral-7B 12% …
Poster
Junyu Lu · Bo Xu · Xiaokun Zhang · Hongbo Wang · Haohao Zhu · Dongyu Zhang · Liang Yang · Hongfei Lin
Abstract
Harmful memes have proliferated on the Chinese Internet, while research on detecting Chinese harmful memes significantly lags behind due to the absence of reliable datasets and effective detectors.To this end, we present the comprehensive detection of Chinese harmful memes.We introduce ToxiCN MM, the first Chinese harmful meme dataset, which consists of 12,000 samples with fine-grained annotations for meme types. Additionally, we propose a baseline detector, Multimodal Knowledge Enhancement (MKE), designed to incorporate contextual information from meme content, thereby enhancing the model's understanding of Chinese memes.In the evaluation phase, we conduct extensive quantitative experiments and qualitative analyses on multiple baselines, including LLMs and our MKE. Experimental results indicate that detecting Chinese harmful memes is challenging for existing models, while demonstrating the effectiveness of MKE.
Poster
Bing Yang · Changsheng Quan · Yabo Wang · Pengyu Wang · Yujie Yang · Ying Fang · Nian Shao · Hui Bu · Xin Xu · Xiaofei Li

Abstract
The training of deep learning-based multichannel speech enhancement and source localization systems relies heavily on the simulation of room impulse response and multichannel diffuse noise, due to the lack of large-scale real-recorded datasets. However, the acoustic mismatch between simulated and real-world data could degrade the model performance when applying in real-world scenarios. To bridge this simulation-to-real gap, this paper presents a new relatively large-scale Real-recorded and annotated Microphone Array speech&Noise (RealMAN) dataset. The proposed dataset is valuable in two aspects: 1) benchmarking speech enhancement and localization algorithms in real scenarios; 2) offering a substantial amount of real-world training data for potentially improving the performance of real-world applications. Specifically, a 32-channel array with high-fidelity microphones is used for recording. A loudspeaker is used for playing source speech signals (about 35 hours of Mandarin speech). A total of 83.7 hours of speech signals (about 48.3 hours for static speaker and 35.4 hours for moving speaker) are recorded in 32 different scenes, and 144.5 hours of background noise are recorded in 31 different scenes. Both speech and noise recording scenes cover various common indoor, outdoor, semi-outdoor and transportation environments, which enables the training of general-purpose speech enhancement and source localization networks. To obtain …
Spotlight Poster
Zijian Chen · Wei Sun · Yuan Tian · Jun Jia · Zicheng Zhang · Wang Jiarui · Ru Huang · Xiongkuo Min · Guangtao Zhai · Wenjun Zhang
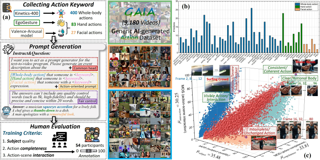
Abstract
Assessing action quality is both imperative and challenging due to its significant impact on the quality of AI-generated videos, further complicated by the inherently ambiguous nature of actions within AI-generated video (AIGV). Current action quality assessment (AQA) algorithms predominantly focus on actions from real specific scenarios and are pre-trained with normative action features, thus rendering them inapplicable in AIGVs. To address these problems, we construct GAIA, a Generic AI-generated Action dataset, by conducting a large-scale subjective evaluation from a novel causal reasoning-based perspective, resulting in 971,244 ratings among 9,180 video-action pairs. Based on GAIA, we evaluate a suite of popular text-to-video (T2V) models on their ability to generate visually rational actions, revealing their pros and cons on different categories of actions. We also extend GAIA as a testbed to benchmark the AQA capacity of existing automatic evaluation methods. Results show that traditional AQA methods, action-related metrics in recent T2V benchmarks, and mainstream video quality methods perform poorly with an average SRCC of 0.454, 0.191, and 0.519, respectively, indicating a sizable gap between current models and human action perception patterns in AIGVs. Our findings underscore the significance of action quality as a unique perspective for studying AIGVs and can catalyze progress …
Poster
Ruohan Li · Yiqun Xie · Xiaowei Jia · Dongdong Wang · Yanhua Li · Yingxue Zhang · Zhihao Wang · Zhili Li
Abstract
Solar power is a critical source of renewable energy, offering significant potential to lower greenhouse gas emissions and mitigate climate change. However, the cloud induced-variability of solar radiation reaching the earth’s surface presents a challenge for integrating solar power into the grid (e.g., storage and backup management). The new generation of geostationary satellites such as GOES-16 has become an important data source for large-scale and high temporal frequency solar radiation forecasting. However, no machine-learning-ready dataset has integrated geostationary satellite data with fine-grained solar radiation information to support forecasting model development and benchmarking with consistent metrics. We present SolarCube, a new ML-ready benchmark dataset for solar radiation forecasting. SolarCube covers 19 study areas distributed over multiple continents: North America, South America, Asia, and Oceania. The dataset supports short (i.e., 30 minutes to 6 hours) and long-term (i.e., day-ahead or longer) solar radiation forecasting at both point-level (i.e., specific locations of monitoring stations) and area-level, by processing and integrating data from multiple sources, including geostationary satellite images, physics-derived solar radiation, and ground station observations from different monitoring networks over the globe. We also evaluated a set of forecasting models for point- and image-based time-series data to develop performance benchmarks under different testing …
Poster
Zhuoran Jin · Pengfei Cao · Chenhao Wang · Zhitao He · Hongbang Yuan · Jiachun Li · Yubo Chen · Kang Liu · Jun Zhao
Abstract
Large language models (LLMs) inevitably memorize sensitive, copyrighted, and harmful knowledge from the training corpus; therefore, it is crucial to erase this knowledge from the models. Machine unlearning is a promising solution for efficiently removing specific knowledge by post hoc modifying models. In this paper, we propose a Real-World Knowledge Unlearning benchmark (RWKU) for LLM unlearning. RWKU is designed based on the following three key factors: (1) For the task setting, we consider a more practical and challenging unlearning setting, where neither the forget corpus nor the retain corpus is accessible. (2) For the knowledge source, we choose 200 real-world famous people as the unlearning targets and show that such popular knowledge is widely present in various LLMs. (3) For the evaluation framework, we design the forget set and the retain set to evaluate the model’s capabilities across various real-world applications. Regarding the forget set, we provide four four membership inference attack (MIA) methods and nine kinds of adversarial attack probes to rigorously test unlearning efficacy. Regarding the retain set, we assess locality and utility in terms of neighbor perturbation, general ability, reasoning ability, truthfulness, factuality, and fluency. We conduct extensive experiments across two unlearning scenarios, two models and six …
Poster
Shuyi Lin · Haoyu He · Tianhao WEI · Kaidi Xu · Huan Zhang · Gagandeep Singh · Changliu Liu · Cheng Tan

Abstract
We present NN4SysBench, a benchmark suite for neural network verification that is composed of applications from the domain of computer systems. We call these neural networks for computer systems or NN4Sys. NN4Sys is booming: there are many proposals for using neural networks in computer systems—for example, databases, OSes, and networked systems—many of which are safety critical. Neural network verification is a technique to formally verify whether neural networks satisfy safety properties. We however observe that NN4Sys has some unique characteristics that today’s verification tools overlook and have limited support. Therefore, this benchmark suite aims at bridging the gap between NN4Sys and the verification by using impactful NN4Sys applications as benchmarks to illustrate computer systems’ unique challenges. We also build a compatible version of NN4SysBench, so that today’s verifiers can also work on these benchmarks with approximately the same verification difficulties. The code is available at https://github.com/lydialin1212/NN4Sys_Benchmark.
Poster
Biao Gong · Shuai Tan · Yutong Feng · Xiaoying Xie · Yuyuan Li · Chaochao Chen · Kecheng Zheng · Yujun Shen · Deli Zhao

Abstract
This work presents a unified knowledge protocol, called UKnow, which facilitates knowledge-based studies from the perspective of data. Particularly focusing on visual and linguistic modalities, we categorize data knowledge into five unit types, namely, in-image, in-text, cross-image, cross-text, and image-text, and set up an efficient pipeline to help construct the multimodal knowledge graph from any data collection. Thanks to the logical information naturally contained in knowledge graph, organizing datasets under UKnow format opens up more possibilities of data usage compared to the commonly used image-text pairs. Following UKnow protocol, we collect, from public international news, a large-scale multimodal knowledge graph dataset that consists of 1,388,568 nodes (with 571,791 vision-related ones) and 3,673,817 triplets. The dataset is also annotated with rich event tags, including 11 coarse labels and 9,185 fine labels. Experiments on four benchmarks demonstrate the potential of UKnow in supporting common-sense reasoning and boosting vision-language pre-training with a single dataset, benefiting from its unified form of knowledge organization. Code, dataset, and models will be made publicly available. See Appendix to download the dataset.
Poster
Jiahuan Cao · Yang Liu · Yongxin Shi · Kai Ding · Lianwen Jin
Abstract
Large Language Models (LLMs) have made significant advancements across numerous domains, but their capabilities in Chinese Classical Literature and Language Arts (CCLLA) remain largely unexplored due to the limited scope and tasks of existing benchmarks. To fill this gap, we propose WenMind, a comprehensive benchmark dedicated for evaluating LLMs in CCLLA. WenMind covers the sub-domains of Ancient Prose, Ancient Poetry, and Ancient Literary Culture, comprising 4,875 question-answer pairs, spanning 42 fine-grained tasks, 3 question formats, and 2 evaluation scenarios: domain-oriented and capability-oriented. Based on WenMind, we conduct a thorough evaluation of 31 representative LLMs, including general-purpose models and ancient Chinese LLMs. The results reveal that even the best-performing model, ERNIE-4.0, only achieves a total score of 64.3, indicating significant room for improvement of LLMs in the CCLLA domain. We also provide insights into the strengths and weaknesses of different LLMs and highlight the importance of pre-training data in achieving better results.Overall, WenMind serves as a standardized and comprehensive baseline, providing valuable insights for future CCLLA research. Our benchmark and related code are available at \url{https://github.com/SCUT-DLVCLab/WenMind}.
Poster
Yulong Hui · YAO LU · Huanchen Zhang

Abstract
The use of Retrieval-Augmented Generation (RAG) has improved Large Language Models (LLMs) in collaborating with external data, yet significant challenges exist in real-world scenarios. In areas such as academic literature and finance question answering, data are often found in raw text and tables in HTML or PDF formats, which can be lengthy and highly unstructured. In this paper, we introduce a benchmark suite, namely Unstructured Document Analysis (UDA), that involves 2,965 real-world documents and 29,590 expert-annotated Q&A pairs. We revisit popular LLM- and RAG-based solutions for document analysis and evaluate the design choices and answer qualities across multiple document domains and diverse query types. Our evaluation yields interesting findings and highlights the importance of data parsing and retrieval. We hope our benchmark can shed light and better serve real-world document analysis applications. The benchmark suite and code can be found at https://github.com/qinchuanhui/UDA-Benchmark
Poster
Zhiyuan Yan · Taiping Yao · Shen Chen · Yandan Zhao · Xinghe Fu · Junwei Zhu · Donghao Luo · Chengjie Wang · Shouhong Ding · Yunsheng Wu · Li Yuan
Abstract
We propose a new comprehensive benchmark to revolutionize the current deepfake detection field to the next generation. Predominantly, existing works identify top-notch detection algorithms and models by adhering to the common practice: training detectors on one specific dataset (*e.g.,* FF++) and testing them on other prevalent deepfake datasets. This protocol is often regarded as a "golden compass" for navigating SoTA detectors. But can these stand-out "winners" be truly applied to tackle the myriad of realistic and diverse deepfakes lurking in the real world? If not, what underlying factors contribute to this gap? In this work, we found the **dataset** (both train and test) can be the "primary culprit" due to the following: (1) *forgery diversity*: Deepfake techniques are commonly referred to as both face forgery (face-swapping and face-reenactment) and entire image synthesis (AIGC, especially face). Most existing datasets only contain partial types of them, with limited forgery methods implemented (*e.g.,* 2 swapping and 2 reenactment methods in FF++); (2) *forgery realism*: The dominated training dataset, FF++, contains out-of-date forgery techniques from the past four years. "Honing skills" on these forgeries makes it difficult to guarantee effective detection generalization toward nowadays' SoTA deepfakes; (3) *evaluation protocol*: Most detection works perform evaluations …
Poster
Yutao Mou · Shikun Zhang · Wei Ye

Abstract
Ensuring the safety of large language model (LLM) applications is essential for developing trustworthy artificial intelligence. Current LLM safety benchmarks have two limitations. First, they focus solely on either discriminative or generative evaluation paradigms while ignoring their interconnection. Second, they rely on standardized inputs, overlooking the effects of widespread prompting techniques, such as system prompts, few-shot demonstrations, and chain-of-thought prompting. To overcome these issues, we developed SG-Bench, a novel benchmark to assess the generalization of LLM safety across various tasks and prompt types. This benchmark integrates both generative and discriminative evaluation tasks and includes extended data to examine the impact of prompt engineering and jailbreak on LLM safety. Our assessment of 3 advanced proprietary LLMs and 10 open-source LLMs with the benchmark reveals that most LLMs perform worse on discriminative tasks than generative ones, and are highly susceptible to prompts, indicating poor generalization in safety alignment. We also explain these findings quantitatively and qualitatively to provide insights for future research.
Poster
Cheng Chen · Junchen Zhu · Xu Luo · Hengtao Shen · Jingkuan Song · Lianli Gao

Abstract
Instruction tuning demonstrates impressive performance in adapting Multimodal Large Language Models (MLLMs) to follow task instructions and improve generalization ability. By extending tuning across diverse tasks, MLLMs can further enhance their understanding of world knowledge and instruction intent. However, continual instruction tuning has been largely overlooked and there are no public benchmarks available. In this paper, we present CoIN, a comprehensive benchmark tailored for assessing the behavior of existing MLLMs under continual instruction tuning. CoIN comprises 10 meticulously crafted datasets spanning 8 tasks, ensuring diversity and serving as a robust evaluation framework to assess crucial aspects of continual instruction tuning, such as task order, instruction diversity and volume. Additionally, apart from traditional evaluation, we design another LLM-based metric to assess the knowledge preserved within MLLMs for reasoning. Following an in-depth evaluation of several MLLMs, we demonstrate that they still suffer catastrophic forgetting, and the failure in instruction alignment assumes the main responsibility, instead of reasoning knowledge forgetting. To this end, we introduce MoELoRA which is effective in retaining the previous instruction alignment.
Poster
jialin luo · Yuanzhi Wang · Ziqi Gu · Yide Qiu · Shuaizhen Yao · Fuyun Wang · Chunyan Xu · Wenhua Zhang · Dan Wang · Zhen Cui

Abstract
Recently, the diffusion-based generative paradigm has achieved impressive general image generation capabilities with text prompts due to its accurate distribution modeling and stable training process. However, generating diverse remote sensing (RS) images that are tremendously different from general images in terms of scale and perspective remains a formidable challenge due to the lack of a comprehensive remote sensing image generation dataset with various modalities, ground sample distances (GSD), and scenes. In this paper, we propose a Multi-modal, Multi-GSD, Multi-scene Remote Sensing (MMM-RS) dataset and benchmark for text-to-image generation in diverse remote sensing scenarios. Specifically, we first collect nine publicly available RS datasets and conduct standardization for all samples. To bridge RS images to textual semantic information, we utilize a large-scale pretrained vision-language model to automatically output text prompts and perform hand-crafted rectification, resulting in information-rich text-image pairs (including multi-modal images). In particular, we design some methods to obtain the images with different GSD and various environments (e.g., low-light, foggy) in a single sample. With extensive manual screening and refining annotations, we ultimately obtain a MMM-RS dataset that comprises approximately 2.1 million text-image pairs. Extensive experimental results verify that our proposed MMM-RS dataset allows off-the-shelf diffusion models to generate diverse RS …
Poster
Hang Zhang · Jiawei SUN · Renqi Chen · Wei Liu · Zhonghang Yuan · Xinzhe Zheng · Zhefan Wang · Zhiyuan Yang · Hang Yan · Han-Sen Zhong · Xiqing Wang · Wanli Ouyang · Fan Yang · Nanqing Dong

Abstract
Large language models (LLMs) have demonstrated remarkable efficacy across knowledge-intensive tasks. Nevertheless, their untapped potential in crop science presents an opportunity for advancement. To narrow this gap, we introduce CROP, which includes a novel instruction tuning dataset specifically designed to enhance LLMs’ professional capabilities in the crop science sector, along with a benchmark that serves as a comprehensive evaluation of LLMs’ understanding of the domain knowledge. The CROP dataset is curated through a task-oriented and LLM-human integrated pipeline, comprising 210,038 single-turn and 1,871 multi-turn dialogues related to crop science scenarios. The CROP benchmark includes 5,045 multiple-choice questions covering three difficulty levels. Our experiments based on the CROP benchmark demonstrate notable enhancements in crop science-related tasks when LLMs are fine-tuned with the CROP dataset. To the best of our knowledge, CROP dataset is the first-ever instruction tuning dataset in the crop science domain. We anticipate that CROP will accelerate the adoption of LLMs in the domain of crop science, ultimately contributing to global food production.
Poster
Linfeng Dong · Wei Wang · Yu Qiao · Xiao Sun

Abstract
Action Quality Assessment (AQA) research confronts formidable obstacles due to limited, mono-modal datasets sourced from one-shot competitions, which hinder the generalizability and comprehensiveness of AQA models. To address these limitations, we present LucidAction, the first systematically collected multi-view AQA dataset structured on curriculum learning principles. LucidAction features a three-tier hierarchical structure, encompassing eight diverse sports events with four curriculum levels, facilitating sequential skill mastery and supporting a wide range of athletic abilities. The dataset encompasses multi-modal data, including multi-view RGB video, 2D and 3D pose sequences, enhancing the richness of information available for analysis. Leveraging a high-precision multi-view Motion Capture (MoCap) system ensures precise capture of complex movements. Meticulously annotated data, incorporating detailed penalties from professional gymnasts, ensures the establishment of robust and comprehensive ground truth annotations. Experimental evaluations employing diverse contrastive regression baselines on LucidAction elucidate the dataset's complexities. Through ablation studies, we investigate the advantages conferred by multi-modal data and fine-grained annotations, offering insights into improving AQA performance. The data and code will be openly released to support advancements in the AI sports field.
Poster
Jakob Hauser · Dániel Kondor · Jenny Reddish · Majid Benam · Enrico Cioni · Federica Villa · James Bennett · Daniel Hoyer · Pieter Francois · Peter Turchin · R. Maria del Rio-Chanona
Abstract
Large Language Models (LLMs) have the potential to transform humanities and social science research, yet their history knowledge and comprehension at a graduate level remains untested. Benchmarking LLMs in history is particularly challenging, given that human knowledge of history is inherently unbalanced, with more information available on Western history and recent periods. We introduce the History Seshat Test for LLMs (HiST-LLM), based on a subset of the Seshat Global History Databank, which provides a structured representation of human historical knowledge, containing 36,000 data points across 600 historical societies and over 2,700 scholarly references. This dataset covers every major world region from the Neolithic period to the Industrial Revolution and includes information reviewed and assembled by history experts and graduate research assistants. Using this dataset, we benchmark a total of seven models from the Gemini, OpenAI, and Llama families. We find that, in a four-choice format, LLMs have a balanced accuracy ranging from 33.6% (Llama-3.1-8B) to 46% (GPT-4-Turbo), outperforming random guessing (25%) but falling short of expert comprehension. LLMs perform better on earlier historical periods. Regionally, performance is more even but still better for the Americas and lowest in Oceania and Sub-Saharan Africa for the more advanced models. Our benchmark shows …