Oral Poster
LINGOLY: A Benchmark of Olympiad-Level Linguistic Reasoning Puzzles in Low Resource and Extinct Languages
Andrew M. Bean · Simi Hellsten · Harry Mayne · Jabez Magomere · Ethan Chi · Ryan Chi · Scott Hale · Hannah Rose Kirk
West Ballroom A-D #5210
{kind=link}
Thu 12 Dec 3:30 p.m. PST — 4:30 p.m. PST
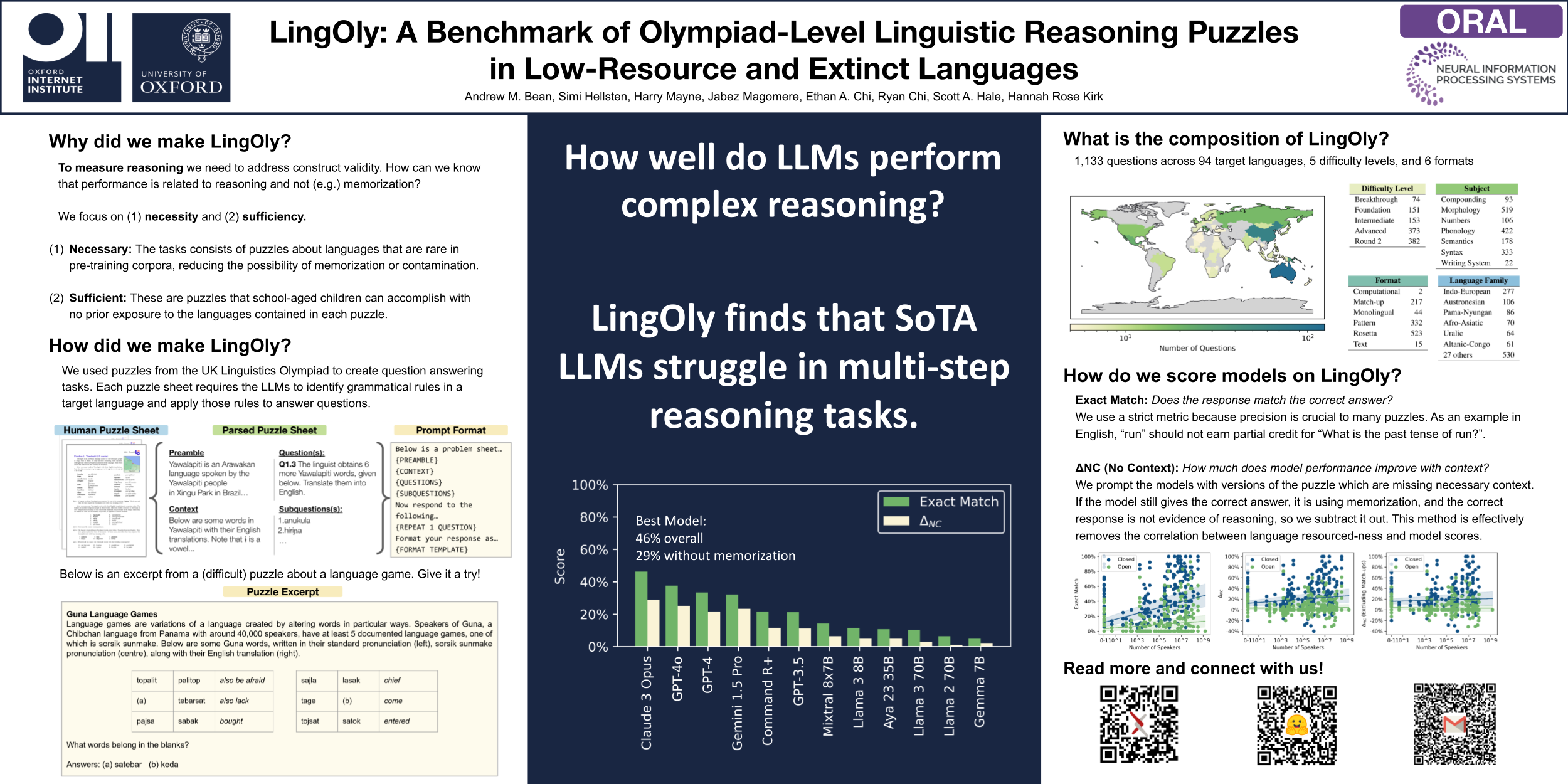
In this paper, we present the LingOly benchmark, a novel benchmark for advanced reasoning abilities in large language models. Using challenging Linguistic Olympiad puzzles, we evaluate (i) capabilities for in-context identification and generalisation of linguistic patterns in very low-resource or extinct languages, and (ii) abilities to follow complex task instructions. The LingOly benchmark covers more than 90 mostly low-resource languages, minimising issues of data contamination, and contains 1,133 problems across 6 formats and 5 levels of human difficulty. We assess performance with both direct accuracy and comparison to a no-context baseline to penalise memorisation. Scores from 11 state-of-the-art LLMs demonstrate the benchmark to be challenging, and models perform poorly on the higher difficulty problems. On harder problems, even the top model only achieved 38.7% accuracy, a 24.7% improvement over the no-context baseline. Large closed models typically outperform open models, and in general, the higher resource the language, the better the scores. These results indicate, in absence of memorisation, true multi-step out-of-domain reasoning remains a challenge for current language models.