[ East Exhibit Hall A-C ]
Abstract
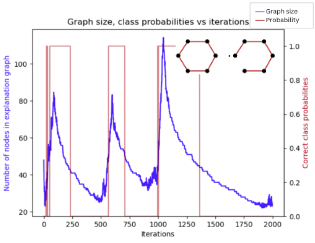
Graph Neural Networks have recently gained recognition for their performance on graph machine learning tasks. The increasing attention on these models’ trustworthiness and decision-making mechanisms has instilled interest in the exploration of explainability tech- niques, including the model proposed in "GNNInterpreter: A probabilistic generative model- level explanation for Graph Neural Networks." (Wang & Shen (2022)). This work aims to reproduce the findings of the original paper, by investigation the main claims made by its authors, namely that GNNInterpreter (i) generates faithful and realistic explanations with- out requiring domain-specific knowledge, (ii) has the ability to work with various node and edge features, (iii) produces explanations that are representative for the target class and (iv) has a much lower training time compared to XGNN, the current state-of-the-art model- level GNN explanation technique. To reproduce the results, we make use of the open-source implementation and we test the interpreter on the same datasets and GNN models as in the original paper. We conduct an enhanced quantitative and qualitative evaluation, and additionally we extend the original experiments to include another real-world dataset. Our results show that we are not able to validate the first claim, due to significant hyperpa- rameter and seed variation, as …
[ West Ballroom A-D ]
Abstract
The field of Multi-Agent Reinforcement Learning (MARL) is currently facing a reproducibility crisis. While solutions for standardized reporting have been proposed to address the issue, we still lack a benchmarking tool that enables standardization and reproducibility, while leveraging cutting-edge Reinforcement Learning (RL) implementations. In this paper, we introduce BenchMARL, the first MARL training library created to enable standardized benchmarking across different algorithms, models, and environments. BenchMARL uses TorchRL as its backend, granting it high-performance and maintained state-of-the-art implementations while addressing the broad community of MARL PyTorch users. Its design enables systematic configuration and reporting, thus allowing users to create and run complex benchmarks from simple one-line inputs. BenchMARL is open-sourced on GitHub at https://github.com/facebookresearch/BenchMARL
[ East Exhibit Hall A-C ]
Abstract
Despite significant advances, deep networks remain highly susceptible to adversarial attack. One fundamental challenge is that small input perturbations can often produce large movements in the network’s final-layer feature space. In this paper, we define an attack model that abstracts this challenge, to help understand its intrinsic properties. In our model, the adversary may move data an arbitrary distance in feature space but only in random low-dimensional subspaces. We prove such adversaries can be quite powerful: defeating any algorithm that must classify any input it is given. However, by allowing the algorithm to abstain on unusual inputs, we show such adversaries can be overcome when classes are reasonably well-separated in feature space. We further provide strong theoretical guarantees for setting algorithm parameters to optimize over accuracy-abstention trade-offs using data-driven methods. Our results provide new robustness guarantees for nearest-neighbor style algorithms, and also have application to contrastive learning, where we empirically demonstrate the ability of such algorithms to obtain high robust accuracy with low abstention rates. Our model is also motivated by strategic classification, where entities being classified aim to manipulate their observable features to produce a preferred classification, and we provide new insights into that area as well.
[ East Exhibit Hall A-C ]
Abstract
Bayesian optimization (BO) has become a popular strategy for global optimization of expensive real-world functions. Contrary to a common expectation that BO is suited to optimizing black-box functions, it actually requires domain knowledge about those functions to deploy BO successfully. Such domain knowledge often manifests in Gaussian process (GP) priors that specify initial beliefs on functions. However, even with expert knowledge, it is non-trivial to quantitatively define a prior. This is especially true for hyperparameter tuning problems on complex machine learning models, where landscapes of tuning objectives are often difficult to comprehend. We seek an alternative practice for setting these functional priors. In particular, we consider the scenario where we have data from similar functions that allow us to pre-train a tighter distribution a priori. We detail what pre-training entails for GPs using a KL divergence based loss function, and propose a new pre-training based BO framework named HyperBO. Theoretically, we show bounded posterior predictions and near-zero regrets for HyperBO without assuming the "ground truth" GP prior is known. To verify our approach in realistic setups, we collect a large multi-task hyperparameter tuning dataset by training tens of thousands of configurations of near-state-of-the-art deep learning models on popular image and …
[ East Exhibit Hall A-C ]
Abstract
This paper seeks to reproduce and extend the results of the paper “Explaining Temporal Graph Models Through an Explorer-Navigator Framework” by (Xia et al., 2023). The main contribution of the original authors is a novel explainer for temporal graph networks, the Temporal GNN Explainer (T-GNNExplainer), which finds a subset of preceding events that “explain” a prediction made by a temporal graph model. The explorer is tested on two temporal graph models that are trained on two real-world and two synthetic datasets. The explorer is evaluated using a newly proposed metric for explanatory graph models. The authors compare the performance of their explorer to three baseline explainer methods, either adapted from a GNN explainer or developed by the authors. The authors claim that T-GNNExplainer achieves superior performance compared to the baselines when evaluated with their proposed metric. This work reproduces the original experiments by using the code (with minor adjustments), model specifications, and hyperparameters provided by the original authors. To evaluate the robustness of these claims, the method was extended to one new dataset (MOOC). Results show that the T-GNNexplainer performs best on some, but not all metrics as reported in the original findings. We conclude that the main lines of …
[ East Exhibit Hall A-C ]

Abstract
Model guidance describes the approach of regularizing the explanations of a deep neu- ral network model towards highlighting the correct features to ensure that the model is “right for the right reasons”. Rao et al. (2023) conducted an in-depth evaluation of ef- fective and efficient model guidance for object classification across various loss functions, attributions methods, models, and ’guidance depths’ to study the effectiveness of differ- ent methods. Our work aims to (1) reproduce the main results obtained by Rao et al. (2023), and (2) propose several extensions to their research. We conclude that the major part of the original work is reproducible, with certain minor exceptions, which we discuss in this paper. In our extended work, we point to an issue with the Energy Pointing Game (EPG) metric used for evaluation and propose an extension for increasing its robustness. In addition, we observe the EPG metric’s predisposition towards favoring larger bounding boxes, a bias we address by incorporating a corrective penalty term into the original En- ergy loss function. Furthermore, we revisit the feasibility of using segmentation masks in light of the original study’s finding that minimal annotated data can significantly boost model performance. Our findings suggests that Energy …
[ East Exhibit Hall A-C ]
Abstract
The growing reproducibility crisis in machine learning has brought forward a need for careful examination of research findings. This paper investigates the claims made by Lei et al. (2023) regarding their proposed method, LICO, for enhancing post-hoc interpretability techniques and improving image classification performance. LICO leverages natural language supervision from a vision-language model to enrich feature representations and guide the learning process. We conduct a comprehensive reproducibility study, employing (Wide) ResNets and established interpretability methods like Grad-CAM and RISE. We were mostly unable to reproduce the authors' results. In particular, we did not find that LICO consistently led to improved classification performance or improvements in quantitative and qualitative measures of interpretability. Thus, our findings highlight the importance of rigorous evaluation and transparent reporting in interpretability research.
[ West Ballroom A-D ]
Abstract
Clustering algorithms play a pivotal role in various societal applications, where fairness is paramount to prevent adverse impacts on individuals. In this study, we revisit the robustness of fair clustering algorithms against adversarial attacks, affirming previous research findings that highlighted their susceptibility and the resilience of the Consensus Fair Clustering (CFC) model. Beyond reproducing these critical results, our work extends the original analysis by refining the codebase for enhanced experimentation, introducing additional metrics and datasets to deepen the evaluation of fairness and clustering quality, and exploring novel attack strategies, including targeted attacks on new metrics and a combined approach for balance and entropy as well as an ablation study. These contributions validate the original claims about the vulnerability and resilience of fair clustering algorithms and broaden the research landscape by offering a more comprehensive toolkit for assessing adversarial robustness in fair clustering.
[ East Exhibit Hall A-C ]
Abstract
This paper introduces a novel theoretical framework for the analysis of vector-valued neural networks through the development of vector-valued variation spaces, a new class of reproducing kernel Banach spaces. These spaces emerge from studying the regularization effect of weight decay in training networks with activation functions like the rectified linear unit (ReLU). This framework offers a deeper understanding of multi-output networks and their function-space characteristics. A key contribution of this work is the development of a representer theorem for the vector-valued variation spaces. This representer theorem establishes that shallow vector-valued neural networks are the solutions to data-fitting problems over these infinite-dimensional spaces, where the network widths are bounded by the square of the number of training data. This observation reveals that the norm associated with these vector-valued variation spaces encourages the learning of features that are useful for multiple tasks, shedding new light on multi-task learning with neural networks. Finally, this paper develops a connection between weight-decay regularization and the multi-task lasso problem. This connection leads to novel bounds for layer widths in deep networks that depend on the intrinsic dimensions of the training data representations. This insight not only deepens the understanding of the deep network architectural requirements, but …
[ West Ballroom A-D ]
Abstract
[ West Ballroom A-D ]
Abstract
Causal discovery aims at revealing causal relations from observational data, which is a fundamental task in science and engineering. We describe causal-learn, an open-source Python library for causal discovery. This library focuses on bringing a comprehensive collection of causal discovery methods to both practitioners and researchers. It provides easy-to-use APIs for non-specialists, modular building blocks for developers, detailed documentation for learners, and comprehensive methods for all. Different from previous packages in R or Java, causal-learn is fully developed in Python, which could be more in tune with the recent preference shift in programming languages within related communities. The library is available at https://github.com/py-why/causal-learn.
[ West Ballroom A-D ]
Abstract
This reproducibility study examines "Robust Fair Clustering: A Novel Fairness Attack and Defense Framework" by Chhabra et al. (2023), an innovative work in fair clustering algorithms. Our study focuses on validating the original paper's claims concerning the susceptibility of state-of-the-art fair clustering models to adversarial attacks and the efficacy of the proposed Consensus Fair Clustering (CFC) defence mechanism. We employ a similar experimental framework but extend our investigations by using additional datasets. Our findings confirm the original paper's claims, reinforcing the vulnerability of fair clustering models to adversarial attacks and the robustness of the CFC mechanism.
[ East Exhibit Hall A-C ]
Abstract
To obtain state-of-the-art performance, many deeper artificial intelligence models sacrifice human explainability in their decision-making. One solution proposed for achieving top performance and retaining explainability is the Post-Hoc Concept Bottleneck Model (PCBM) (Yuksekgonul et al., 2023), which can convert the embeddings of any deep neural network into a set of human-interpretable concept weights. In this work, we reproduce and expand upon the findings of Yuksekgonul et al. (2023). Our results show that while most of the authors’ claims and results hold, some of the results they obtained could not be sufficiently replicated. Specifically, the claims relating to PCBM performance preservation and its non-requirement of labeled concept datasets were generally reproduced, whereas the one claiming its model editing capabilities was not. Beyond these results, our contributions to their work include evidence that PCBMs may work for audio classification problems, verification of the interpretability of their methods, and updates to their code for missing implementations. The code for our implementations can be found at https://github.com/dgcnz/FACT.
[ West Ballroom A-D ]
Abstract
This work investigates the reproducibility of the paper "Explaining RL decisions with trajectories“ by Deshmukh et al. (2023). The original paper introduces a novel approach in explainable reinforcement learning based on the attribution decisions of an agent to specific clusters of trajectories encountered during training. We verify the main claims from the paper, which state that (i) training on less trajectories induces a lower initial state value, (ii) trajectories in a cluster present similar high-level patterns, (iii) distant trajectories influence the decision of an agent, and (iv) humans correctly identify the attributed trajectories to the decision of the agent. We recover the environments used by the authors based on the partial original code they provided for one of the environments (Grid-World), and implemented the remaining from scratch (Seaquest and HalfCheetah, Breakout, Q*Bert). While we confirm that (i), (ii), and (iii) partially hold, we extend on the largely qualitative experiments from the authors by introducing a quantitative metric to further support (iii), and new experiments and visual results for (i). Moreover, we investigate the use of different clustering algorithms and encoder architectures to further support (ii). We could not support (iv), given the limited extent of the original experiments. We conclude …
[ West Ballroom A-D ]
Abstract
This reproducibility study aims to evaluate the robustness of Equal Improvability (EI) - an effort-based framework for ensuring long-term fairness. To this end, we seek to analyze the three proposed EI-ensuring regularization techniques, i.e. Covariance-based, KDE-based, and Loss-based EI. Our findings largely substantiate the initial assertions, demonstrating EI’s enhanced performance over Empirical Risk Minimization (ERM) techniques on various test datasets. Furthermore, while affirming the long-term effectiveness in fairness, the study also uncovers challenges in resilience to overfitting, particularly in highly complex models. Building upon the original study, the experiments were extended to include a new dataset and multiple sensitive attributes. These additional tests further demonstrated the effec- tiveness of the EI approach, reinforcing its continued success. Our study highlights the importance of adaptable strategies in AI fairness, contributing to the ongoing discourse in this field of research.
[ East Exhibit Hall A-C ]
Abstract
[ East Exhibit Hall A-C ]
Abstract
New transformer networks have been integrated into object tracking pipelines and have demonstrated strong performance on the latest benchmarks. This paper focuses on understanding how transformer trackers behave under adversarial attacks and how different attacks perform on tracking datasets as their parameters change. We conducted a series of experiments to evaluate the effectiveness of existing adversarial attacks on object trackers with transformer and non-transformer backbones. We experimented on 7 different trackers, including 3 that are transformer-based, and 4 which leverage other architectures. These trackers are tested against 4 recent attack methods to assess their performance and robustness on VOT2022ST, UAV123 and GOT10k datasets. Our empirical study focuses on evaluating adversarial robustness of object trackers based on bounding box versus binary mask predictions, and attack methods at different levels of perturbations. Interestingly, our study found that altering the perturbation level may not significantly affect the overall object tracking results after the attack. Similarly, the sparsity and imperceptibility of the attack perturbations may remain stable against perturbation level shifts. By applying a specific attack on all transformer trackers, we show that new transformer trackers having a stronger cross-attention modeling achieve a greater adversarial robustness on tracking datasets, such as VOT2022ST and GOT10k. …
[ East Exhibit Hall A-C ]
Abstract
[ West Ballroom A-D ]

Abstract
Text-to-image generative models often present issues regarding fairness with respect to certain sensitive attributes, such as gender or skin tone. This study aims to reproduce the results presented in "ITI-GEN: Inclusive Text-to-Image Generation" by Zhang et al. (2023), which introduces a model to improve inclusiveness in these kinds of models. We show that most of the claims made by the authors about ITI-GEN hold: it improves the diversity and quality of generated images, it is scalable to different domains, it has plug-and-play capabilities, and it is efficient from a computational point of view. However, ITI-GEN sometimes uses undesired attributes as proxy features and it is unable to disentangle some pairs of (correlated) attributes such as gender and baldness. In addition, when the number of considered attributes increases, the training time grows exponentially and ITI-GEN struggles to generate inclusive images for all elements in the joint distribution. To solve these issues, we propose using Hard Prompt Search with negative prompting, a method that does not require training and that handles negation better than vanilla Hard Prompt Search. Nonetheless, Hard Prompt Search (with or without negative prompting) cannot be used for continuous attributes that are hard to express in natural language, an …
[ West Ballroom A-D ]
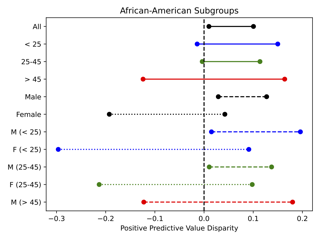
Abstract
Before deploying a black-box model in high-stakes problems, it is important to evaluate the model’s performance on sensitive subpopulations. For example, in a recidivism prediction task, we may wish to identify demographic groups for which our prediction model has unacceptably high false positive rates or certify that no such groups exist. In this paper, we frame this task, often referred to as ``fairness auditing,'' in terms of multiple hypothesis testing. We show how the bootstrap can be used to simultaneously bound performance disparities over a collection of groups with statistical guarantees. Our methods can be used to flag subpopulations affected by model underperformance, and certify subpopulations for which the model performs adequately. Crucially, our audit is model-agnostic and applicable to nearly any performance metric or group fairness criterion. Our methods also accommodate extremely rich---even infinite---collections of subpopulations. Further, we generalize beyond subpopulations by showing how to assess performance over certain distribution shifts. We test the proposed methods on benchmark datasets in predictive inference and algorithmic fairness and find that our audits can provide interpretable and trustworthy guarantees.
[ West Ballroom A-D ]
Abstract
[ West Ballroom A-D ]
Abstract
Recent work has highlighted the label alignment property (LAP) in supervised learning, where the vector of all labels in the dataset is mostly in the span of the top few singular vectors of the data matrix. Drawing inspiration from this observation, we propose a regularization method for unsupervised domain adaptation that encourages alignment between the predictions in the target domain and its top singular vectors. Unlike conventional domain adaptation approaches that focus on regularizing representations, we instead regularize the classifier to align with the unsupervised target data, guided by the LAP in both the source and target domains. Theoretical analysis demonstrates that, under certain assumptions, our solution resides within the span of the top right singular vectors of the target domain data and aligns with the optimal solution. By removing the reliance on the commonly used optimal joint risk assumption found in classic domain adaptation theory, we showcase the effectiveness of our method on addressing problems where traditional domain adaptation methods often fall short due to high joint error. Additionally, we report improved performance over domain adaptation baselines in well-known tasks such as MNIST-USPS domain adaptation and cross-lingual sentiment analysis. An implementation is available at https://github.com/EhsanEI/lar/.
[ East Exhibit Hall A-C ]
Abstract
[ East Exhibit Hall A-C ]
Abstract
[ East Exhibit Hall A-C ]
Abstract
Latent variable models (LVMs) represent observed variables by parameterized functions of latent variables. Prominent examples of LVMs for unsupervised learning are probabilistic PCA or probabilistic sparse coding which both assume a weighted linear summation of the latents to determine the mean of a Gaussian distribution for the observables. In many cases, however, observables do not follow a Gaussian distribution. For unsupervised learning, LVMs which assume specific non-Gaussian observables (e.g., Bernoulli or Poisson) have therefore been considered. Already for specific choices of distributions, parameter optimization is challenging and only a few previous contributions considered LVMs with more generally defined observable distributions. In this contribution, we do consider LVMs that are defined for a range of different distributions, i.e., observables can follow any (regular) distribution of the exponential family. Furthermore, the novel class of LVMs presented here is defined for binary latents, and it uses maximization in place of summation to link the latents to observables. In order to derive an optimization procedure, we follow an expectation maximization approach for maximum likelihood parameter estimation. We then show, as our main result, that a set of very concise parameter update equations can be derived which feature the same functional form for all exponential …
[ West Ballroom A-D ]
Abstract
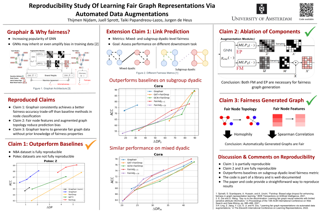
In this study, we undertake a reproducibility analysis of "Learning Fair Graph Representations Via Automated Data Augmentations" by Ling et al. (2022). We assess the validity of the original claims focused on node classification tasks and explore the performance of the Graphair framework in link prediction tasks. Our investigation reveals that we can partially reproduce one of the original three claims and fully substantiate the other two. Additionally, we broaden the application of Graphair from node classification to link prediction across various datasets. Our findings indicate that, while Graphair demonstrates a comparable fairness-accuracy trade-off to baseline models for mixed dyadic-level fairness, it has a superior trade-off for subgroup dyadic-level fairness. These findings underscore Graphair’s potential for wider adoption in graph-based learning. Our code base can be found on GitHub at https://github.com/juellsprott/graphair-reproducibility.
[ West Ballroom A-D ]
Abstract
This paper presents a new optimization approach to causal estimation. Given data that contains covariates and an outcome, which covariates are causes of the outcome, and what is the strength of the causality? In classical machine learning (ML), the goal of optimization is to maximize predictive accuracy. However, some covariates might exhibit a non-causal association with the outcome. Such spurious associations provide predictive power for classical ML, but they prevent us from causally interpreting the result. This paper proposes CoCo, an optimization algorithm that bridges the gap between pure prediction and causal inference. CoCo leverages the recently-proposed idea of environments, datasets of covariates/response where the causal relationships remain invariant but where the distribution of the covariates changes from environment to environment. Given datasets from multiple environments—and ones that exhibit sufficient heterogeneity—CoCo maximizes an objective for which the only solution is the causal solution. We describe the theoretical foundations of this approach and demonstrate its effectiveness on simulated and real datasets. Compared to classical ML and existing methods, CoCo provides more accurate estimates of the causal model and more accurate predictions under interventions.
[ East Exhibit Hall A-C ]
Abstract
[ West Ballroom A-D ]
Abstract
We use fixed point theory to analyze nonnegative neural networks, which we define as neural networks that map nonnegative vectors to nonnegative vectors. We first show that nonnegative neural networks with nonnegative weights and biases can be recognized as monotonic and (weakly) scalable mappings within the framework of nonlinear Perron-Frobenius theory. This fact enables us to provide conditions for the existence of fixed points of nonnegative neural networks having inputs and outputs of the same dimension, and these conditions are weaker than those recently obtained using arguments in convex analysis. Furthermore, we prove that the shape of the fixed point set of nonnegative neural networks with nonnegative weights and biases is an interval, which under mild conditions degenerates to a point. These results are then used to obtain the existence of fixed points of more general nonnegative neural networks. From a practical perspective, our results contribute to the understanding of the behavior of autoencoders, and we also offer valuable mathematical machinery for future developments in deep equilibrium models.
[ East Exhibit Hall A-C ]
Abstract
The accuracy and complexity of machine learning algorithms based on kernel optimization are determined by the set of kernels over which they are able to optimize. An ideal set of kernels should: admit a linear parameterization (for tractability); be dense in the set of all kernels (for robustness); be universal (for accuracy). Recently, a framework was proposed for using positive matrices to parameterize a class of positive semi-separable kernels. Although this class can be shown to meet all three criteria, previous algorithms for optimization of such kernels were limited to classification and furthermore relied on computationally complex Semidefinite Programming (SDP) algorithms. In this paper, we pose the problem of learning semiseparable kernels as a minimax optimization problem and propose a SVD-QCQP primal-dual algorithm which dramatically reduces the computational complexity as compared with previous SDP-based approaches. Furthermore, we provide an efficient implementation of this algorithm for both classification and regression -- an implementation which enables us to solve problems with 100 features and up to 30,000 datums. Finally, when applied to benchmark data, the algorithm demonstrates the potential for significant improvement in accuracy over typical (but non-convex) approaches such as Neural Nets and Random Forest with similar or better computation time.
[ East Exhibit Hall A-C ]
Abstract
[ West Ballroom A-D ]
Abstract
This work aims to reproduce the findings of the paper "Fair Attribute Completion on Graph with Missing Attributes" written by Guo et al. (2023) by investigating the claims made in the paper. This paper suggests that the results of the original paper are reproducible and thus, the claims hold. However, the claim that FairAC is a generic framework for many downstream tasks is very broad and could therefore only be partially tested. Moreover, we show that FairAC is generalizable to various datasets and sensitive attributes and show evidence that the improvement in group fairness of the FairAC framework does not come at the expense of individual fairness. Lastly, the codebase of FairAC has been refactored and is now easily applicable for various datasets and models.
[ East Exhibit Hall A-C ]
Abstract
Deep Learning models have taken the front stage in the AI community, yet explainability challenges hinder their widespread adoption. Time series models, in particular, lack attention in this regard. This study tries to reproduce and extend the work of Enguehard (2023b), focusing on time series explainability by incorporating learnable masks and perturbations. Enguehard (2023b) employed two methods to learn these masks and perturbations, the preservation game (yielding SOTA results) and the deletion game (with poor performance). We extend the work by revising the deletion game’s loss function, testing the robustness of the proposed method on a novel weather dataset, and visualizing the learned masks and perturbations. Despite notable discrepancies in results across many experiments, our findings demonstrate that the proposed method consistently outperforms all baselines and exhibits robust performance across datasets. However, visualizations for the preservation game reveal that the learned perturbations primarily resemble a constant zero signal, questioning the importance of learning perturbations. Nevertheless, our revised deletion game shows promise, recovering meaningful perturbations and, in certain instances, surpassing the performance of the preservation game.
[ West Ballroom A-D ]
Abstract
We present a unified framework for deriving PAC-Bayesian generalization bounds. Unlike most previous literature on this topic, our bounds are anytime-valid (i.e., time-uniform), meaning that they hold at all stopping times, not only for a fixed sample size. Our approach combines four tools in the following order: (a) nonnegative supermartingales or reverse submartingales, (b) the method of mixtures, (c) the Donsker-Varadhan formula (or other convex duality principles), and (d) Ville's inequality. Our main result is a PAC-Bayes theorem which holds for a wide class of discrete stochastic processes. We show how this result implies time-uniform versions of well-known classical PAC-Bayes bounds, such as those of Seeger, McAllester, Maurer, and Catoni, in addition to many recent bounds. We also present several novel bounds. Our framework also enables us to relax traditional assumptions; in particular, we consider nonstationary loss functions and non-iid data. In sum, we unify the derivation of past bounds and ease the search for future bounds: one may simply check if our supermartingale or submartingale conditions are met and, if so, be guaranteed a (time-uniform) PAC-Bayes bound.
[ West Ballroom A-D ]
Abstract
[ East Exhibit Hall A-C ]
Abstract
We pursue transfer learning to improve classifier accuracy on a target task with few labeled examples available for training. Recent work suggests that using a source task to learn a prior distribution over neural net weights, not just an initialization, can boost target task performance. In this study, we carefully compare transfer learning with and without source task informed priors across 5 datasets. We find that standard transfer learning informed by an initialization only performs far better than reported in previous comparisons. The relative gains of methods using informative priors over standard transfer learning vary in magnitude across datasets. For the scenario of 5-300 examples per class, we find negative or negligible gains on 2 datasets, modest gains (between 1.5-3 points of accuracy) on 2 other datasets, and substantial gains (>8 points) on one dataset. Among methods using informative priors, we find that an isotropic covariance appears competitive with learned low-rank covariance matrix while being substantially simpler to understand and tune. Further analysis suggests that the mechanistic justification for informed priors -- hypothesized improved alignment between train and test loss landscapes -- is not consistently supported due to high variability in empirical landscapes. We release code to allow independent reproduction …
[ East Exhibit Hall A-C ]
Abstract
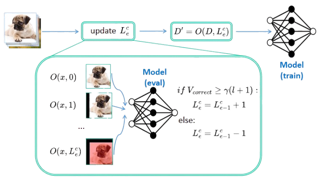
In this reproducibility study, we present our results and experience during replicating the paper, titled CUDA: Curriculum of Data Augmentation for Long-Tailed Recognition(Ahn et al., 2023).Traditional datasets used in image recognition, such as ImageNet, are often synthetically balanced, meaning each class has an equal number of samples. In practical scenarios, datasets frequently exhibit significant class imbalances, with certain classes having a disproportionately larger number of samples compared to others. This discrepancy poses a challenge for traditional image recognition models, as they tend to favor classes with larger sample sizes, leading to poor performance on minority classes. CUDA proposes a class-wise data augmentation technique which can be used over any existing model to improve the accuracy for LTR: Long Tailed Recognition. We successfully replicated all of the results pertaining to the long-tailed CIFAR-100-LT dataset and extended our analysis to provide deeper insights into how CUDA efficiently tackles class imbalance. The code and the readings are available in https://anonymous.4open.science/r/CUDA-org--C2FD/README.md
[ West Ballroom A-D ]
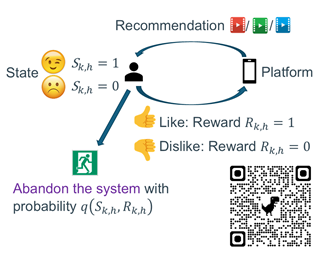
Abstract
[ East Exhibit Hall A-C ]
Abstract
Recent research has proposed various methods to formally verify neural networks against minimal input perturbations; this verification task is also known as local robustness verification. The research area of local robustness verification is highly diverse, as verifiers rely on a multitude of techniques, including mixed integer programming and satisfiability modulo theories. At the same time, the problem instances encountered when performing local robustness verification differ based on the network to be verified, the property to be verified and the specific network input. This raises the question of which verification algorithm is most suitable for solving specific types of instances of the local robustness verification problem. To answer this question, we performed a systematic performance analysis of several CPU- and GPU-based local robustness verification systems on a newly and carefully assembled set of 79 neural networks, of which we verified a broad range of robustness properties, while taking a practitioner's point of view -- a perspective that complements the insights from initiatives such as the VNN competition, where the participating tools are carefully adapted to the given benchmarks by their developers. Notably, we show that no single best algorithm dominates performance across all verification problem instances. Instead, our results reveal complementarities …
[ West Ballroom A-D ]
Abstract
In recent years, there has been an exponentially increased amount of point clouds collected with irregular shapes in various areas. Motivated by the importance of solid modeling for point clouds, we develop a novel and efficient smoothing tool based on multivariate splines over the triangulation to extract the underlying signal and build up a 3D solid model from the point cloud. The proposed method can denoise or deblur the point cloud effectively, provide a multi-resolution reconstruction of the actual signal, and handle sparse and irregularly distributed point clouds to recover the underlying trajectory. In addition, our method provides a natural way of numerosity data reduction. We establish the theoretical guarantees of the proposed method, including the convergence rate and asymptotic normality of the estimator, and show that the convergence rate achieves optimal nonparametric convergence. We also introduce a bootstrap method to quantify the uncertainty of the estimators. Through extensive simulation studies and a real data example, we demonstrate the superiority of the proposed method over traditional smoothing methods in terms of estimation accuracy and efficiency of data reduction.
[ East Exhibit Hall A-C ]

Abstract
Unlike classical lexical overlap metrics such as BLEU, most current evaluation metrics for machine translation (for example, COMET or BERTScore) are based on black-box large language models. They often achieve strong correlations with human judgments, but recent research indicates that the lower-quality classical metrics remain dominant, one of the potential reasons being that their decision processes are more transparent. To foster more widespread acceptance of novel high-quality metrics, explainability thus becomes crucial. In this concept paper, we identify key properties as well as key goals of explainable machine translation metrics and provide a comprehensive synthesis of recent techniques, relating them to our established goals and properties. In this context, we also discuss the latest state-of-the-art approaches to explainable metrics based on generative models such as ChatGPT and GPT4. Finally, we contribute a vision of next-generation approaches, including natural language explanations. We hope that our work can help catalyze and guide future research on explainable evaluation metrics and, mediately, also contribute to better and more transparent machine translation systems.
[ West Ballroom A-D ]
Abstract
Optimization problems with continuous data appear in, e.g., robust machine learning, functional data analysis, and variational inference. Here, the target function is given as an integral over a family of (continuously) indexed target functions---integrated with respect to a probability measure. Such problems can often be solved by stochastic optimization methods: performing optimization steps with respect to the indexed target function with randomly switched indices. In this work, we study a continuous-time variant of the stochastic gradient descent algorithm for optimization problems with continuous data. This so-called stochastic gradient process consists in a gradient flow minimizing an indexed target function that is coupled with a continuous-time index process determining the index. Index processes are, e.g., reflected diffusions, pure jump processes, or other Lévy processes on compact spaces. Thus, we study multiple sampling patterns for the continuous data space and allow for data simulated or streamed at runtime of the algorithm. We analyze the approximation properties of the stochastic gradient process and study its longtime behavior and ergodicity under constant and decreasing learning rates. We end with illustrating the applicability of the stochastic gradient process in a polynomial regression problem with noisy functional data, as well as in a physics-informed neural network.
[ West Ballroom A-D ]

Abstract
Differentiable optimization algorithms often involve expensive computations of various meta-gradients. To address this, we design and implement TorchOpt, a new PyTorch-based differentiable optimization library. TorchOpt provides an expressive and unified programming interface that simplifies the implementation of explicit, implicit, and zero-order gradients. Moreover, TorchOpt has a distributed execution runtime capable of parallelizing diverse operations linked to differentiable optimization tasks across CPU and GPU devices. Experimental results demonstrate that TorchOpt achieves a 5.2× training time speedup in a cluster. TorchOpt is open-sourced at https://github.com/metaopt/torchopt and has become a PyTorch Ecosystem project.
[ East Exhibit Hall A-C ]
Abstract
Gaussian processes are frequently deployed as part of larger machine learning and decision-making systems, for instance in geospatial modeling, Bayesian optimization, or in latent Gaussian models. Within a system, the Gaussian process model needs to perform in a stable and reliable manner to ensure it interacts correctly with other parts of the system. In this work, we study the numerical stability of scalable sparse approximations based on inducing points. To do so, we first review numerical stability, and illustrate typical situations in which Gaussian process models can be unstable. Building on stability theory originally developed in the interpolation literature, we derive sufficient and in certain cases necessary conditions on the inducing points for the computations performed to be numerically stable. For low-dimensional tasks such as geospatial modeling, we propose an automated method for computing inducing points satisfying these conditions. This is done via a modification of the cover tree data structure, which is of independent interest. We additionally propose an alternative sparse approximation for regression with a Gaussian likelihood which trades off a small amount of performance to further improve stability. We provide illustrative examples showing the relationship between stability of calculations and predictive performance of inducing point methods on …