Oral
Jin Zhang · Ze Liu · Defu Lian · Enhong Chen
[ East Meeting Room 1-3 ]

Abstract
Two-stage recommender systems play a crucial role in efficiently identifying relevant items and personalizing recommendations from a vast array of options. This paper, based on an error decomposition framework, analyzes the generalization error for two-stage recommender systems with a tree structure, which consist of an efficient tree-based retriever and a more precise yet time-consuming ranker. We use the Rademacher complexity to establish the generalization upper bound for various tree-based retrievers using beam search, as well as for different ranker models under a shifted training distribution. Both theoretical insights and practical experiments on real-world datasets indicate that increasing the branches in tree-based retrievers and harmonizing distributions across stages can enhance the generalization performance of two-stage recommender systems.
Oral
Tianyu He · Darshil Doshi · Aritra Das · Andrey Gromov
[ East Ballroom A, B ]

Abstract
Large language models can solve tasks that were not present in the training set. This capability is believed to be due to in-context learning and skill composition. In this work, we study the emergence of in-context learning and skill composition in a collection of modular arithmetic tasks. Specifically, we consider a finite collection of linear modular functions $z = a x + b y \text{ mod } p$ labeled by the vector $(a, b) \in \mathbb{Z}_p^2$. We use some of these tasks for pre-training and the rest for out-of-distribution testing. We empirically show that a GPT-style transformer exhibits a transition from in-distribution to out-of-distribution generalization as the number of pre-training tasks increases. We find that the smallest model capable of out-of-distribution generalization requires two transformer blocks, while for deeper models, the out-of-distribution generalization phase is *transient*, necessitating early stopping. Finally, we perform an interpretability study of the pre-trained models, revealing highly structured representations in both attention heads and MLPs; and discuss the learned algorithms. Notably, we find an algorithmic shift in deeper models, as we go from few to many in-context examples.
Oral
Aaron Defazio · Xingyu Yang · Ahmed Khaled · Konstantin Mishchenko · Harsh Mehta · Ashok Cutkosky
[ West Meeting Room 211-214 ]
Abstract
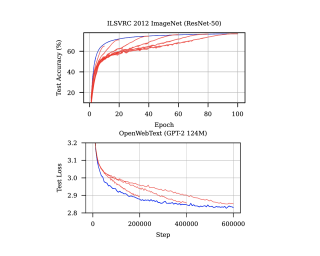
Existing learning rate schedules that do not require specification of the optimization stopping step $T$ are greatly out-performed by learning rate schedules that depend on $T$. We propose an approach that avoids the need for this stopping time by eschewing the use of schedules entirely, while exhibiting state-of-the-art performance compared to schedules across a wide family of problems ranging from convex problems to large-scale deep learning problems. Our Schedule-Free approach introduces no additional hyper-parameters over standard optimizers with momentum. Our method is a direct consequence of a new theory we develop that unifies scheduling and iterate averaging. An open source implementation of our method is available at https://github.com/facebookresearch/schedule_free. Schedule-Free AdamW is the core algorithm behind our winning entry to the MLCommons 2024 AlgoPerf Algorithmic Efficiency Challenge Self-Tuning track.
Oral
Rohan Alur · Manish Raghavan · Devavrat Shah
[ West Exhibition Hall C, B3 ]

Abstract
We introduce a novel framework for incorporating human expertise into algorithmic predictions. Our approach leverages human judgment to distinguish inputs which are *algorithmically indistinguishable*, or "look the same" to predictive algorithms. We argue that this framing clarifies the problem of human-AI collaboration in prediction tasks, as experts often form judgments by drawing on information which is not encoded in an algorithm's training data. Algorithmic indistinguishability yields a natural test for assessing whether experts incorporate this kind of "side information", and further provides a simple but principled method for selectively incorporating human feedback into algorithmic predictions. We show that this method provably improves the performance of any feasible algorithmic predictor and precisely quantify this improvement. We find empirically that although algorithms often outperform their human counterparts *on average*, human judgment can improve algorithmic predictions on *specific* instances (which can be identified ex-ante). In an X-ray classification task, we find that this subset constitutes nearly 30% of the patient population. Our approach provides a natural way of uncovering this heterogeneity and thus enabling effective human-AI collaboration.
Oral
Spencer Rooke · Zhaoze Wang · Ronald Di Tullio · Vijay Balasubramanian
[ East Ballroom A, B ]
Abstract
Many animals learn cognitive maps of their environment - a simultaneous representation of context, experience, and position. Place cells in the hippocampus, named for their explicit encoding of position, are believed to be a neural substrate of these maps, with place cell "remapping" explaining how this system can represent different contexts. Briefly, place cells alter their firing properties, or "remap", in response to changes in experiential or sensory cues. Substantial sensory changes, produced, e.g., by moving between environments, cause large subpopulations of place cells to change their tuning entirely. While many studies have looked at the physiological basis of remapping, we lack explicit calculations of how the contextual capacity of the place cell system changes as a function of place field firing properties. Here, we propose a geometric approach to understanding population level activity of place cells. Using known firing field statistics, we investigate how changes to place cell firing properties affect the distances between representations of different environments within firing rate space. Using this approach, we find that the number of contexts storable by the hippocampus grows exponentially with the number of place cells, and calculate this exponent for environments of different sizes. We identify a fundamental trade-off between …
Oral
Changli Wu · qi chen · Jiayi Ji · Haowei Wang · Yiwei Ma · You Huang · Gen Luo · Hao Fei · Xiaoshuai Sun · Rongrong Ji
[ West Exhibition Hall C, B3 ]
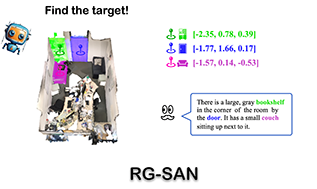
Abstract
3D Referring Expression Segmentation (3D-RES) aims to segment 3D objects by correlating referring expressions with point clouds. However, traditional approaches frequently encounter issues like over-segmentation or mis-segmentation, due to insufficient emphasis on spatial information of instances. In this paper, we introduce a Rule-Guided Spatial Awareness Network (RG-SAN) by utilizing solely the spatial information of the target instance for supervision. This approach enables the network to accurately depict the spatial relationships among all entities described in the text, thus enhancing the reasoning capabilities. The RG-SAN consists of the Text-driven Localization Module (TLM) and the Rule-guided Weak Supervision (RWS) strategy. The TLM initially locates all mentioned instances and iteratively refines their positional information. The RWS strategy, acknowledging that only target objects have supervised positional information, employs dependency tree rules to precisely guide the core instance’s positioning. Extensive testing on the ScanRefer benchmark has shown that RG-SAN not only establishes new performance benchmarks, with an mIoU increase of 5.1 points, but also exhibits significant improvements in robustness when processing descriptions with spatial ambiguity. All codes are available at https://github.com/sosppxo/RG-SAN.
Oral
Antonio Terpin · Nicolas Lanzetti · Martín Gadea · Florian Dorfler
[ West Meeting Room 211-214 ]

Abstract
Diffusion regulates numerous natural processes and the dynamics of many successful generative models. Existing models to learn the diffusion terms from observational data rely on complex bilevel optimization problems and model only the drift of the system.We propose a new simple model, JKOnet*, which bypasses the complexity of existing architectures while presenting significantly enhanced representational capabilities: JKOnet* recovers the potential, interaction, and internal energy components of the underlying diffusion process. JKOnet* minimizes a simple quadratic loss and outperforms other baselines in terms of sample efficiency, computational complexity, and accuracy. Additionally, JKOnet* provides a closed-form optimal solution for linearly parametrized functionals, and, when applied to predict the evolution of cellular processes from real-world data, it achieves state-of-the-art accuracy at a fraction of the computational cost of all existing methods.Our methodology is based on the interpretation of diffusion processes as energy-minimizing trajectories in the probability space via the so-called JKO scheme, which we study via its first-order optimality conditions.
Oral
Arthur da Cunha · Mikael Møller Høgsgaard · Kasper Green Larsen
[ East Meeting Room 1-3 ]
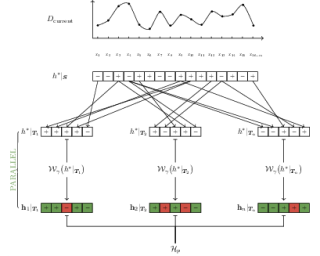
Abstract
Recent works on the parallel complexity of Boosting have established strong lower bounds on the tradeoff between the number of training rounds $p$ and the total parallel work per round $t$.These works have also presented highly non-trivial parallel algorithms that shed light on different regions of this tradeoff.Despite these advancements, a significant gap persists between the theoretical lower bounds and the performance of these algorithms across much of the tradeoff space.In this work, we essentially close this gap by providing both improved lower bounds on the parallel complexity of weak-to-strong learners, and a parallel Boosting algorithm whose performance matches these bounds across the entire $p$ vs. $t$ compromise spectrum, up to logarithmic factors.Ultimately, this work settles the parallel complexity of Boosting algorithms that are nearly sample-optimal.
Oral
Hannah Rose Kirk · Alexander Whitefield · Paul Rottger · Andrew M. Bean · Katerina Margatina · Rafael Mosquera-Gomez · Juan Ciro · Max Bartolo · Adina Williams · He He · Bertie Vidgen · Scott Hale
[ West Exhibition Hall C, B3 ]
Abstract
Human feedback is central to the alignment of Large Language Models (LLMs). However, open questions remain about the methods (how), domains (where), people (who) and objectives (to what end) of feedback processes. To navigate these questions, we introduce PRISM, a new dataset which maps the sociodemographics and stated preferences of 1,500 diverse participants from 75 countries, to their contextual preferences and fine-grained feedback in 8,011 live conversations with 21 LLMs. With PRISM, we contribute (i) wider geographic and demographic participation in feedback; (ii) census-representative samples for two countries (UK, US); and (iii) individualised ratings that link to detailed participant profiles, permitting personalisation and attribution of sample artefacts. We target subjective and multicultural perspectives on value-laden and controversial issues, where we expect interpersonal and cross-cultural disagreement. We use PRISM in three case studies to demonstrate the need for careful consideration of which humans provide alignment data.
Oral
Xin Chen · Anderson Ye Zhang
[ East Meeting Room 1-3 ]
Abstract
We study clustering under anisotropic Gaussian Mixture Models (GMMs), where covariance matrices from different clusters are unknown and are not necessarily the identity matrix. We analyze two anisotropic scenarios: homogeneous, with identical covariance matrices, and heterogeneous, with distinct matrices per cluster. For these models, we derive minimax lower bounds that illustrate the critical influence of covariance structures on clustering accuracy. To solve the clustering problem, we consider a variant of Lloyd's algorithm, adapted to estimate and utilize covariance information iteratively. We prove that the adjusted algorithm not only achieves the minimax optimality but also converges within a logarithmic number of iterations, thus bridging the gap between theoretical guarantees and practical efficiency.
Oral
Zixuan Gong · Guangyin Bao · Qi Zhang · Zhongwei Wan · Duoqian Miao · Shoujin Wang · Lei Zhu · Changwei Wang · Rongtao Xu · Liang Hu · Ke Liu · Yu Zhang
[ East Ballroom A, B ]
Abstract
Reconstruction of static visual stimuli from non-invasion brain activity fMRI achieves great success, owning to advanced deep learning models such as CLIP and Stable Diffusion. However, the research on fMRI-to-video reconstruction remains limited since decoding the spatiotemporal perception of continuous visual experiences is formidably challenging. We contend that the key to addressing these challenges lies in accurately decoding both high-level semantics and low-level perception flows, as perceived by the brain in response to video stimuli. To the end, we propose NeuroClips, an innovative framework to decode high-fidelity and smooth video from fMRI. NeuroClips utilizes a semantics reconstructor to reconstruct video keyframes, guiding semantic accuracy and consistency, and employs a perception reconstructor to capture low-level perceptual details, ensuring video smoothness. During inference, it adopts a pre-trained T2V diffusion model injected with both keyframes and low-level perception flows for video reconstruction. Evaluated on a publicly available fMRI-video dataset, NeuroClips achieves smooth high-fidelity video reconstruction of up to 6s at 8FPS, gaining significant improvements over state-of-the-art models in various metrics, e.g., a 128% improvement in SSIM and an 81% improvement in spatiotemporal metrics. Our project is available at https://github.com/gongzix/NeuroClips.
Oral
Philip Amortila · Dylan J Foster · Nan Jiang · Akshay Krishnamurthy · Zak Mhammedi
[ West Meeting Room 211-214 ]
Abstract
Real-world applications of reinforcement learning often involve environments where agents operate on complex, high-dimensional observations, but the underlying (``latent'') dynamics are comparatively simple. However, beyond restrictive settings such as tabular latent dynamics, the fundamental statistical requirements and algorithmic principles for *reinforcement learning under latent dynamics* are poorly understood. This paper addresses the question of reinforcement learning under *general latent dynamics* from a statistical and algorithmic perspective. On the statistical side, our main negativeresult shows that *most* well-studied settings for reinforcement learning with function approximation become intractable when composed with rich observations; we complement this with a positive result, identifying *latent pushforward coverability* as ageneral condition that enables statistical tractability. Algorithmically, we develop provably efficient *observable-to-latent* reductions ---that is, reductions that transform an arbitrary algorithm for the latent MDP into an algorithm that can operate on rich observations--- in two settings: one where the agent has access to hindsightobservations of the latent dynamics (Lee et al., 2023) and onewhere the agent can estimate *self-predictive* latent models (Schwarzer et al., 2020). Together, our results serve as a first step toward a unified statistical and algorithmic theory forreinforcement learning under latent dynamics.
Oral
Shen Li · Yuyang Zhang · Zhaolin Ren · Claire Liang · Na Li · Julie A Shah
[ East Ballroom A, B ]

Abstract
Interactive preference learning systems infer human preferences by presenting queries as pairs of options and collecting binary choices. Although binary choices are simple and widely used, they provide limited information about preference strength. To address this, we leverage human response times, which are inversely related to preference strength, as an additional signal. We propose a computationally efficient method that combines choices and response times to estimate human utility functions, grounded in the EZ diffusion model from psychology. Theoretical and empirical analyses show that for queries with strong preferences, response times complement choices by providing extra information about preference strength, leading to significantly improved utility estimation. We incorporate this estimator into preference-based linear bandits for fixed-budget best-arm identification. Simulations on three real-world datasets demonstrate that using response times significantly accelerates preference learning compared to choice-only approaches. Additional materials, such as code, slides, and talk video, are available at https://shenlirobot.github.io/pages/NeurIPS24.html.
Oral
Shaoteng Liu · Haoqi Yuan · Minda Hu · Yanwei Li · Yukang Chen · Shu Liu · Zongqing Lu · Jiaya Jia
[ East Meeting Room 1-3 ]
Abstract
Large Language Models (LLMs) have demonstrated proficiency in utilizing various tools by coding, yet they face limitations in handling intricate logic and precise control. In embodied tasks, high-level planning is amenable to direct coding, while low-level actions often necessitate task-specific refinement, such as Reinforcement Learning (RL). To seamlessly integrate both modalities, we introduce a two-level hierarchical framework, RL-GPT, comprising a slow agent and a fast agent. The slow agent analyzes actions suitable for coding, while the fast agent executes coding tasks. This decomposition effectively focuses each agent on specific tasks, proving highly efficient within our pipeline. Our approach outperforms traditional RL methods and existing GPT agents, demonstrating superior efficiency. In the Minecraft game, it rapidly obtains diamonds within a single day on an RTX3090. Additionally, it achieves SOTA performance across all designated MineDojo tasks.
Oral
Matthew Zurek · Yudong Chen
[ West Exhibition Hall C, B3 ]
Abstract
We study the sample complexity of learning an $\varepsilon$-optimal policy in an average-reward Markov decision process (MDP) under a generative model. For weakly communicating MDPs, we establish the complexity bound $\widetilde{O}\left(SA\frac{\mathsf{H}}{\varepsilon^2} \right)$, where $\mathsf{H}$ is the span of the bias function of the optimal policy and $SA$ is the cardinality of the state-action space. Our result is the first that is minimax optimal (up to log factors) in all parameters $S,A,\mathsf{H}$, and $\varepsilon$, improving on existing work that either assumes uniformly bounded mixing times for all policies or has suboptimal dependence on the parameters. We also initiate the study of sample complexity in general (multichain) average-reward MDPs. We argue a new transient time parameter $\mathsf{B}$ is necessary, establish an $\widetilde{O}\left(SA\frac{\mathsf{B} + \mathsf{H}}{\varepsilon^2} \right)$ complexity bound, and prove a matching (up to log factors) minimax lower bound. Both results are based on reducing the average-reward MDP to a discounted MDP, which requires new ideas in the general setting. To optimally analyze this reduction, we develop improved bounds for $\gamma$-discounted MDPs, showing that $\widetilde{O}\left(SA\frac{\mathsf{H}}{(1-\gamma)^2\varepsilon^2} \right)$ and $\widetilde{O}\left(SA\frac{\mathsf{B} + \mathsf{H}}{(1-\gamma)^2\varepsilon^2} \right)$ samples suffice to learn $\varepsilon$-optimal policies in weakly communicating and in general MDPs, respectively. Both these results circumvent the well-known minimax lower …
Oral
Jayden Teoh · Wenjun Li · Pradeep Varakantham
[ West Meeting Room 211-214 ]
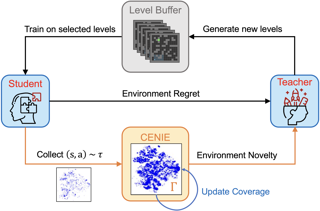
Abstract
Unsupervised Environment Design (UED) formalizes the problem of autocurricula through interactive training between a teacher agent and a student agent. The teacher generates new training environments with high learning potential, curating an adaptive curriculum that strengthens the student's ability to handle unseen scenarios. Existing UED methods mainly rely on *regret*, a metric that measures the difference between the agent's optimal and actual performance, to guide curriculum design. Regret-driven methods generate curricula that progressively increase environment complexity for the student but overlook environment *novelty* — a critical element for enhancing an agent's generalizability. Measuring environment novelty is especially challenging due to the underspecified nature of environment parameters in UED, and existing approaches face significant limitations. To address this, this paper introduces the *Coverage-based Evaluation of Novelty In Environment* (CENIE) framework. CENIE proposes a scalable, domain-agnostic, and curriculum-aware approach to quantifying environment novelty by leveraging the student's state-action space coverage from previous curriculum experiences. We then propose an implementation of CENIE that models this coverage and measures environment novelty using Gaussian Mixture Models. By integrating both regret and novelty as complementary objectives for curriculum design, CENIE facilitates effective exploration across the state-action space while progressively increasing curriculum complexity. Empirical evaluations demonstrate that …
Oral
Yang Peng · Liangyu Zhang · Zhihua Zhang
[ East Meeting Room 1-3 ]

Abstract
Distributional reinforcement learning (DRL) has achieved empirical success in various domains.One of the core tasks in the field of DRL is distributional policy evaluation, which involves estimating the return distribution $\eta^\pi$ for a given policy $\pi$.The distributional temporal difference learning has been accordingly proposed, whichis an extension of the temporal difference learning (TD) in the classic RL area.In the tabular case, Rowland et al. [2018] and Rowland et al. [2023] proved the asymptotic convergence of two instances of distributional TD, namely categorical temporal difference learning (CTD) and quantile temporal difference learning (QTD), respectively.In this paper, we go a step further and analyze the finite-sample performance of distributional TD.To facilitate theoretical analysis, we propose a non-parametric distributional TD learning (NTD).For a $\gamma$-discounted infinite-horizon tabular Markov decision process,we show that for NTD we need $\widetilde O\left(\frac{1}{\varepsilon^{2p}(1-\gamma)^{2p+1}}\right)$ iterations to achieve an $\varepsilon$-optimal estimator with high probability, when the estimation error is measured by the $p$-Wasserstein distance.This sample complexity bound is minimax optimal (up to logarithmic factors) in the case of the $1$-Wasserstein distance.To achieve this, we establish a novel Freedman's inequality in Hilbert spaces, which would be of independent interest.In addition, we revisit CTD, showing that the same non-asymptotic convergence bounds hold for …
Oral
Manling Li · Shiyu Zhao · Qineng Wang · Kangrui Wang · Yu Zhou · Sanjana Srivastava · Cem Gokmen · Tony Lee · Erran Li Li · Ruohan Zhang · Weiyu Liu · Percy Liang · Fei-Fei Li · Jiayuan Mao · Jiajun Wu
[ East Ballroom A, B ]
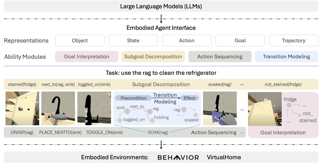
Abstract
We aim to evaluate Large Language Models (LLMs) for embodied decision making. While a significant body of work has been leveraging LLMs for decision making in embodied environments, we still lack a systematic understanding of their performance because they are usually applied in different domains, for different purposes, and built based on different inputs and outputs. Furthermore, existing evaluations tend to rely solely on a final success rate, making it difficult to pinpoint what ability is missing in LLMs and where the problem lies, which in turn blocks embodied agents from leveraging LLMs effectively and selectively. To address these limitations, we propose a generalized interface (Embodied Agent Interface) that supports the formalization of various types of tasks and input-output specifications of LLM-based modules. Specifically, it allows us to unify 1) a broad set of embodied decision-making tasks involving both state and temporally extended goals, 2) four commonly-used LLM-based modules for decision making: goal interpretation, subgoal decomposition, action sequencing, and transition modeling, and 3) a collection of fine-grained metrics that break down evaluation into error types, such as hallucination errors, affordance errors, and various types of planning errors. Overall, our benchmark offers a comprehensive assessment of LLMs’ performance for different subtasks, …
Oral
Sicheng Xu · Guojun Chen · Yu-Xiao Guo · Jiaolong Yang · Chong Li · Zhenyu Zang · Yizhong Zhang · Xin Tong · Baining Guo
[ West Exhibition Hall C, B3 ]
Abstract
We introduce VASA, a framework for generating lifelike talking faces with appealing visual affective skills (VAS) given a single static image and a speech audio clip. Our premiere model, VASA-1, is capable of not only generating lip movements that are exquisitely synchronized with the audio, but also producing a large spectrum of facial nuances and natural head motions that contribute to the perception of authenticity and liveliness. The core innovations include a diffusion-based holistic facial dynamics and head movement generation model that works in a face latent space, and the development of such an expressive and disentangled face latent space using videos.Through extensive experiments including evaluation on a set of new metrics, we show that our method significantly outperforms previous methods along various dimensions comprehensively. Our method delivers high video quality with realistic facial and head dynamics and also supports the online generation of 512$\times$512 videos at up to 40 FPS with negligible starting latency.It paves the way for real-time engagements with lifelike avatars that emulate human conversational behaviors.
Oral
Sudeep Salgia · Yuejie Chi
[ West Meeting Room 211-214 ]
Abstract
We consider the problem of Federated Q-learning, where $M$ agents aim to collaboratively learn the optimal Q-function of an unknown infinite horizon Markov Decision Process with finite state and action spaces. We investigate the trade-off between sample and communication complexity for the widely used class of intermittent communication algorithms. We first establish the converse result, where we show that any Federated Q-learning that offers a linear speedup with respect to number of agents in sample complexity needs to incur a communication cost of at least $\Omega(\frac{1}{1-\gamma})$, where $\gamma$ is the discount factor. We also propose a new Federated Q-learning algorithm, called Fed-DVR-Q, which is the first Federated Q-learning algorithm to simultaneously achieve order-optimal sample and communication complexities. Thus, together these results provide a complete characterization of the sample-communication complexity trade-off in Federated Q-learning.
Oral
Ma Chang · Junlei Zhang · Zhihao Zhu · Cheng Yang · Yujiu Yang · Yaohui Jin · Zhenzhong Lan · Lingpeng Kong · Junxian He
[ East Ballroom A, B ]

Abstract
Evaluating large language models (LLMs) as general-purpose agents is essential for understanding their capabilities and facilitating their integration into practical applications. However, the evaluation process presents substantial challenges. A primary obstacle is the benchmarking of agent performance across diverse scenarios within a unified framework, especially in maintaining partially-observable environments and ensuring multi-round interactions. Moreover, current evaluation frameworks mostly focus on the final success rate, revealing few insights during the process and failing to provide a deep understanding of the model abilities. To address these challenges, we introduce AgentBoard, a pioneering comprehensive benchmark and accompanied open-source evaluation framework tailored to analytical evaluation of LLM agents. AgentBoard offers a fine-grained progress rate metric that captures incremental advancements as well as a comprehensive evaluation toolkit that features easy assessment of agents for multi-faceted analysis through interactive visualization. This not only sheds light on the capabilities and limitations of LLM agents but also propels the interpretability of their performance to the forefront. Ultimately, AgentBoard serves as a significant step towards demystifying agent behaviors and accelerating the development of stronger LLM agents.
Oral
Dengwei Zhao · Shikui Tu · Lei Xu
[ East Meeting Room 1-3 ]

Abstract
Monte-Carlo tree search (MCTS) and reinforcement learning contributed crucially to the success of AlphaGo and AlphaZero, and A$^*$ is a tree search algorithm among the most well-known ones in the classical AI literature. MCTS and A$^*$ both perform heuristic search and are mutually beneficial. Efforts have been made to the renaissance of A$^*$ from three possible aspects, two of which have been confirmed by studies in recent years, while the third is about the OPEN list that consists of open nodes of A$^*$ search, but still lacks deep investigation. This paper aims at the third, i.e., developing the Sampling-exploration enhanced A$^*$ (SeeA$^*$) search by constructing a dynamic subset of OPEN through a selective sampling process, such that the node with the best heuristic value in this subset instead of in the OPEN is expanded. Nodes with the best heuristic values in OPEN are most probably picked into this subset, but sometimes may not be included, which enables SeeA$^*$ to explore other promising branches. Three sampling techniques are presented for comparative investigations. Moreover, under the assumption about the distribution of prediction errors, we have theoretically shown the superior efficiency of SeeA$^*$ over A$^*$ search, particularly when the accuracy of the guiding …
Oral
Keyu Tian · Yi Jiang · Zehuan Yuan · BINGYUE PENG · Liwei Wang
[ West Exhibition Hall C, B3 ]
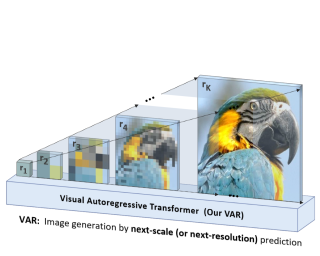
Abstract
We present Visual AutoRegressive modeling (VAR), a new generation paradigm that redefines the autoregressive learning on images as coarse-to-fine "next-scale prediction" or "next-resolution prediction", diverging from the standard raster-scan "next-token prediction". This simple, intuitive methodology allows autoregressive (AR) transformers to learn visual distributions fast and generalize well: VAR, for the first time, makes GPT-style AR models surpass diffusion transformers in image generation. On ImageNet 256x256 benchmark, VAR significantly improve AR baseline by improving Frechet inception distance (FID) from 18.65 to 1.73, inception score (IS) from 80.4 to 350.2, with around 20x faster inference speed. It is also empirically verified that VAR outperforms the Diffusion Transformer (DiT) in multiple dimensions including image quality, inference speed, data efficiency, and scalability. Scaling up VAR models exhibits clear power-law scaling laws similar to those observed in LLMs, with linear correlation coefficients near -0.998 as solid evidence. VAR further showcases zero-shot generalization ability in downstream tasks including image in-painting, out-painting, and editing. These results suggest VAR has initially emulated the two important properties of LLMs: Scaling Laws and zero-shot task generalization. We have released all models and codes to promote the exploration of AR/VAR models for visual generation and unified learning.
Oral
Xiong-Hui Chen · Ziyan Wang · Yali Du · Shengyi Jiang · Meng Fang · Yang Yu · Jun Wang
[ West Meeting Room 211-214 ]
Abstract
When humans need to learn a new skill, we can acquire knowledge through written books, including textbooks, tutorials, etc. However, current research for decision-making, like reinforcement learning (RL), has primarily required numerous real interactions with the target environment to learn a skill, while failing to utilize the existing knowledge already summarized in the text. The success of Large Language Models (LLMs) sheds light on utilizing such knowledge behind the books. In this paper, we discuss a new policy learning problem called Policy Learning from tutorial Books (PLfB) upon the shoulders of LLMs’ systems, which aims to leverage rich resources such as tutorial books to derive a policy network. Inspired by how humans learn from books, we solve the problem via a three-stage framework: Understanding, Rehearsing, and Introspecting (URI). In particular, it first rehearses decision-making trajectories based on the derived knowledge after understanding the books, then introspects in the imaginary dataset to distill a policy network. We build two benchmarks for PLfB~based on Tic-Tac-Toe and Football games. In experiment, URI's policy achieves at least 44% net win rate against GPT-based agents without any real data; In Football game, which is a complex scenario, URI's policy beat the built-in AIs with a …
Oral
Zhenghao Lin · Zhibin Gou · Yeyun Gong · Xiao Liu · yelong shen · Ruochen Xu · Chen Lin · Yujiu Yang · Jian Jiao · Nan Duan · Weizhu Chen
[ West Exhibition Hall C, B3 ]
Abstract
Previous language model pre-training methods have uniformly applied a next-token prediction loss to all training tokens. Challenging this norm, we posit that ''Not all tokens in a corpus are equally important for language model training''. Our initial analysis examines token-level training dynamics of language model, revealing distinct loss patterns for different tokens. Leveraging these insights, we introduce a new language model called Rho-1. Unlike traditional LMs that learn to predict every next token in a corpus, Rho-1 employs Selective Language Modeling (SLM), which selectively trains on useful tokens that aligned with the desired distribution. This approach involves scoring training tokens using a reference model, and then training the language model with a focused loss on tokens with higher scores. When continual continual pretraining on 15B OpenWebMath corpus, Rho-1 yields an absolute improvement in few-shot accuracy of up to 30% in 9 math tasks. After fine-tuning, Rho-1-1B and 7B achieved state-of-the-art results of 40.6% and 51.8% on MATH dataset, respectively - matching DeepSeekMath with only 3% of the pretraining tokens. Furthermore, when continual pretraining on 80B general tokens, Rho-1 achieves 6.8% average enhancement across 15 diverse tasks, increasing both data efficiency and performance of the language model pre-training.
Oral
Vladimir Malinovskii · Denis Mazur · Ivan Ilin · Denis Kuznedelev · Konstantin Burlachenko · Kai Yi · Dan Alistarh · Peter Richtarik
[ West Meeting Room 211-214 ]
Abstract
There has been significant interest in "extreme" compression of large language models (LLMs), i.e. to 1-2 bits per parameter, which allows such models to be executed efficiently on resource-constrained devices. Existing work focused on improved one-shot quantization techniques and weight representations; yet, purely post-training approaches are reaching diminishing returns in terms of the accuracy-vs-bit-width trade-off. State-of-the-art quantization methods such as QuIP# and AQLM include fine-tuning (part of) the compressed parameters over a limited amount of calibration data; however, such fine-tuning techniques over compressed weights often make exclusive use of straight-through estimators (STE), whose performance is not well-understood in this setting. In this work, we question the use of STE for extreme LLM compression, showing that it can be sub-optimal, and perform a systematic study of quantization-aware fine-tuning strategies for LLMs.We propose PV-Tuning - a representation-agnostic framework that generalizes and improves upon existing fine-tuning strategies, and provides convergence guarantees in restricted cases.On the practical side, when used for 1-2 bit vector quantization, PV-Tuning outperforms prior techniques for highly-performant models such as Llama and Mistral. Using PV-Tuning, we achieve the first Pareto-optimal quantization for Llama-2 family models at 2 bits per parameter.
Oral
Jingchang Chen · Hongxuan Tang · Zheng Chu · Qianglong Chen · Zekun Wang · Ming Liu · Bing Qin
[ East Ballroom A, B ]
Abstract
Despite recent progress made by large language models in code generation, they still struggle with programs that meet complex requirements. Recent work utilizes plan-and-solve decomposition to decrease the complexity and leverage self-tests to refine the generated program. Yet, planning deep-inside requirements in advance can be challenging, and the tests need to be accurate to accomplish self-improvement. To this end, we propose FunCoder, a code generation framework incorporating the divide-and-conquer strategy with functional consensus. Specifically, FunCoder recursively branches off sub-functions as smaller goals during code generation, represented by a tree hierarchy. These sub-functions are then composited to attain more complex objectives. Additionally, we designate functions via a consensus formed by identifying similarities in program behavior, mitigating error propagation. FunCoder outperforms state-of-the-art methods by +9.8% on average in HumanEval, MBPP, xCodeEval and MATH with GPT-3.5 and GPT-4. Moreover, our method demonstrates superiority on smaller models: With FunCoder, StableCode-3b surpasses GPT-3.5 by +18.6% and achieves 97.7% of GPT-4's performance on HumanEval. Further analysis reveals that our proposed dynamic function decomposition is capable of handling complex requirements, and the functional consensus prevails over self-testing in correctness evaluation.
Oral
Zhe Hu · Tuo Liang · Jing Li · Yiren Lu · Yunlai Zhou · Yiran Qiao · Jing Ma · Yu Yin
[ East Meeting Room 1-3 ]
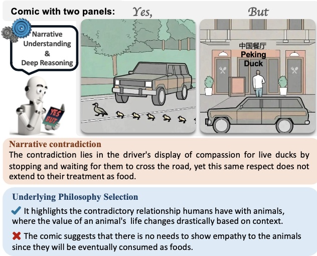
Abstract
Recent advancements in large vision language models have demonstrated remarkable proficiency across a wide range of tasks. Yet, these models still struggle with understanding the nuances of human humor through juxtaposition, particularly when it involves nonlinear narratives that underpin many jokes and humor cues. This paper investigates this challenge by focusing on comics with contradictory narratives, where each comic consists of two panels that create a humorous contradiction. We introduce the YesBut benchmark, which comprises tasks of varying difficulty aimed at assessing AI's capabilities in recognizing and interpreting these comics, ranging from literal content comprehension to deep narrative reasoning. Through extensive experimentation and analysis of recent commercial or open-sourced large vision language models, we assess their capability to comprehend the complex interplay of the narrative humor inherent in these comics. Our results show that even the state-of-the-art models still struggle with this task. Our findings offer insights into the current limitations and potential improvements for AI in understanding human creative expressions.
Oral
Tianhong Li · Dina Katabi · Kaiming He
[ West Exhibition Hall C, B3 ]
Abstract
Unconditional generation -- the problem of modeling data distribution without relying on human-annotated labels -- is a long-standing and fundamental challenge in generative models, creating a potential of learning from large-scale unlabeled data. In the literature, the generation quality of an unconditional method has been much worse than that of its conditional counterpart. This gap can be attributed to the lack of semantic information provided by labels. In this work, we show that one can close this gap by generating semantic representations in the representation space produced by a self-supervised encoder. These representations can be used to condition the image generator. This framework, called Representation-Conditioned Generation (RCG), provides an effective solution to the unconditional generation problem without using labels. Through comprehensive experiments, we observe that RCG significantly improves unconditional generation quality: e.g., it achieves a new state-of-the-art FID of 2.15 on ImageNet 256x256, largely reducing the previous best of 5.91 by a relative 64%. Our unconditional results are situated in the same tier as the leading class-conditional ones. We hope these encouraging observations will attract the community's attention to the fundamental problem of unconditional generation. Code is available at [https://github.com/LTH14/rcg](https://github.com/LTH14/rcg).
Oral
Shangzi Xue · Zhenya Huang · Jiayu Liu · Xin Lin · Yuting Ning · Binbin Jin · Xin Li · Qi Liu
[ East Meeting Room 1-3 ]
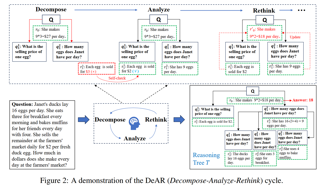
Abstract
In this paper, we introduce DeAR (_Decompose-Analyze-Rethink_), a framework that iteratively builds a reasoning tree to tackle intricate problems within a single large language model (LLM). Unlike approaches that extend or search for rationales, DeAR is featured by 1) adopting a tree-based question decomposition manner to plan the organization of rationales, which mimics the logical planning inherentin human cognition; 2) globally updating the rationales at each reasoning step through natural language feedback. Specifically, the _Decompose_ stage decomposes the question into simpler sub-questions, storing them as new nodes; the _Analyze_ stage generates and self-checks rationales for sub-questions at each node evel; and the _Rethink_ stage updates parent-node rationales based on feedback from their child nodes. By generating and updating the reasoning process from a more global perspective, DeAR constructs more adaptive and accurate logical structures for complex problems, facilitating timely error correction compared to rationale-extension and search-based approaches such as Tree-of-Thoughts (ToT) and Graph-of-Thoughts (GoT). We conduct extensive experiments on three reasoning benchmarks, including ScienceQA, StrategyQA, and GSM8K, which cover a variety of reasoning tasks, demonstrating that our approach significantly reduces logical errors and enhances performance across various LLMs. Furthermore, we validate that DeAR is an efficient method that achieves a …
Oral
Arjun Panickssery · Samuel Bowman · Shi Feng
[ West Meeting Room 211-214 ]
Abstract
Self-evaluation using large language models (LLMs) has proven valuable not only in benchmarking but also methods like reward modeling, constitutional AI, and self-refinement. But new biases are introduced due to the same LLM acting as both the evaluator and the evaluatee. One such bias is self-preference, where an LLM evaluator scores its own outputs higher than others’ while human annotators consider them of equal quality. But do LLMs actually recognize their own outputs when they give those texts higher scores, or is it just a coincidence? In this paper, we investigate if self-recognition capability contributes to self-preference. We discover that, out of the box, LLMs such as GPT-4 and Llama 2 have non-trivial accuracy at distinguishing themselves from other LLMs and humans. By finetuning LLMs, we discover a linear correlation between self-recognition capability and the strength of self-preference bias; using controlled experiments, we show that the causal explanation resists straightforward confounders. We discuss how self-recognition can interfere with unbiased evaluations and AI safety more generally.
Oral
Haokun Lin · Haobo Xu · Yichen WU · Jingzhi Cui · Yingtao Zhang · Linzhan Mou · Linqi Song · Zhenan Sun · Ying Wei
[ East Ballroom A, B ]
Abstract
Quantization of large language models (LLMs) faces significant challenges, particularly due to the presence of outlier activations that impede efficient low-bit representation. Traditional approaches predominantly address Normal Outliers, which are activations across all tokens with relatively large magnitudes. However, these methods struggle with smoothing Massive Outliers that display significantly larger values, which leads to significant performance degradation in low-bit quantization. In this paper, we introduce DuQuant, a novel approach that utilizes rotation and permutation transformations to more effectively mitigate both massive and normal outliers. First, DuQuant starts by constructing the rotation matrix, using specific outlier dimensions as prior knowledge, to redistribute outliers to adjacent channels by block-wise rotation. Second, We further employ a zigzag permutation to balance the distribution of outliers across blocks, thereby reducing block-wise variance. A subsequent rotation further smooths the activation landscape, enhancing model performance. DuQuant simplifies the quantization process and excels in managing outliers, outperforming the state-of-the-art baselines across various sizes and types of LLMs on multiple tasks, even with 4-bit weight-activation quantization. Our code is available at https://github.com/Hsu1023/DuQuant.
Oral
Qiguang Chen · Libo Qin · Jiaqi Wang · Jingxuan Zhou · Wanxiang Che
[ West Meeting Room 211-214 ]

Abstract
Chain-of-Thought (CoT) reasoning has emerged as a promising approach for enhancing the performance of large language models (LLMs) on complex reasoning tasks. Recently, a series of studies attempt to explain the mechanisms underlying CoT, aiming to deepen the understanding of its efficacy. Nevertheless, the existing research faces two major challenges: (1) a lack of quantitative metrics to assess CoT capabilities and (2) a dearth of guidance on optimizing CoT performance. Motivated by this, in this work, we introduce a novel reasoning boundary framework (RBF) to address these challenges. To solve the lack of quantification, we first define a reasoning boundary (RB) to quantify the upper-bound of CoT and establish a combination law for RB, enabling a practical quantitative approach applicable to various real-world CoT tasks. To address the lack of optimization, we propose three categories of RBs. We further optimize these categories with combination laws focused on RB promotion and reasoning path optimization for CoT improvement. Through extensive experiments on 27 models and 5 tasks, the study validates the existence and rationality of the proposed framework. Furthermore, it explains the effectiveness of 10 CoT strategies and guides optimization from two perspectives. We hope this work can provide a comprehensive understanding …
Oral
Sangwoong Yoon · Himchan Hwang · Dohyun Kwon · Yung-Kyun Noh · Frank Park
[ East Ballroom A, B ]
Abstract
We present a maximum entropy inverse reinforcement learning (IRL) approach for improving the sample quality of diffusion generative models, especially when the number of generation time steps is small. Similar to how IRL trains a policy based on the reward function learned from expert demonstrations, we train (or fine-tune) a diffusion model using the log probability density estimated from training data. Since we employ an energy-based model (EBM) to represent the log density, our approach boils down to the joint training of a diffusion model and an EBM. Our IRL formulation, named Diffusion by Maximum Entropy IRL (DxMI), is a minimax problem that reaches equilibrium when both models converge to the data distribution. The entropy maximization plays a key role in DxMI, facilitating the exploration of the diffusion model and ensuring the convergence of the EBM. We also propose Diffusion by Dynamic Programming (DxDP), a novel reinforcement learning algorithm for diffusion models, as a subroutine in DxMI. DxDP makes the diffusion model update in DxMI efficient by transforming the original problem into an optimal control formulation where value functions replace back-propagation in time. Our empirical studies show that diffusion models fine-tuned using DxMI can generate high-quality samples in as few …
Oral
Chunlin Tian · Zhan Shi · Zhijiang Guo · Li Li · Cheng-Zhong Xu
[ West Exhibition Hall C, B3 ]

Abstract
Adapting Large Language Models (LLMs) to new tasks through fine-tuning has been made more efficient by the introduction of Parameter-Efficient Fine-Tuning (PEFT) techniques, such as LoRA. However, these methods often underperform compared to full fine-tuning, particularly in scenarios involving complex datasets. This issue becomes even more pronounced in complex domains, highlighting the need for improved PEFT approaches that can achieve better performance. Through a series of experiments, we have uncovered two critical insights that shed light on the training and parameter inefficiency of LoRA. Building on these insights, we have developed HydraLoRA, a LoRA framework with an asymmetric structure that eliminates the need for domain expertise. Our experiments demonstrate that HydraLoRA outperforms other PEFT approaches, even those that rely on domain knowledge during the training and inference phases. Our anonymous codes are submitted with the paper and will be publicly available. Code is available: https://github.com/Clin0212/HydraLoRA.
Oral
Ricardo Dominguez-Olmedo · Moritz Hardt · Celestine Mendler-Dünner
[ East Meeting Room 1-3 ]
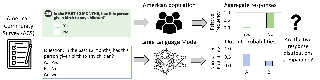
Abstract
Surveys have recently gained popularity as a tool to study large language models. By comparing models’ survey responses to those of different human reference populations, researchers aim to infer the demographics, political opinions, or values best represented by current language models. In this work, we critically examine language models' survey responses on the basis of the well-established American Community Survey by the U.S. Census Bureau. Evaluating 43 different language models using de-facto standard prompting methodologies, we establish two dominant patterns. First, models' responses are governed by ordering and labeling biases, for example, towards survey responses labeled with the letter “A”. Second, when adjusting for these systematic biases through randomized answer ordering, models across the board trend towards uniformly random survey responses, irrespective of model size or training data. As a result, models consistently appear to better represent subgroups whose aggregate statistics are closest to uniform for the survey under consideration, leading to potentially misguided conclusions about model alignment.
Oral
Junhao Cai · Yuji Yang · Weihao Yuan · Yisheng HE · Zilong Dong · Liefeng Bo · Hui Cheng · Qifeng Chen
[ West Meeting Room 211-214 ]

Abstract
This paper studies the problem of estimating physical properties (system identification) through visual observations. To facilitate geometry-aware guidance in physical property estimation, we introduce a novel hybrid framework that leverages 3D Gaussian representation to not only capture explicit shapes but also enable the simulated continuum to render object masks as 2D shape surrogates during training. We propose a new dynamic 3D Gaussian framework based on motion factorization to recover the object as 3D Gaussian point sets across different time states. Furthermore, we develop a coarse-to-fine filling strategy to generate the density fields of the object from the Gaussian reconstruction, allowing for the extraction of object continuums along with their surfaces and the integration of Gaussian attributes into these continuum. In addition to the extracted object surfaces, the Gaussian-informed continuum also enables the rendering of object masks during simulations, serving as 2D-shape guidance for physical property estimation. Extensive experimental evaluations demonstrate that our pipeline achieves state-of-the-art performance across multiple benchmarks and metrics. Additionally, we illustrate the effectiveness of the proposed method through real-world demonstrations, showcasing its practical utility. Our project page is at https://jukgei.github.io/project/gic.
Oral
zhengrui Xu · Guan'an Wang · Xiaowen Huang · Jitao Sang
[ East Ballroom A, B ]

Abstract
The denoising model has been proven a powerful generative model but has little exploration of discriminative tasks. Representation learning is important in discriminative tasks, which is defined as *"learning representations (or features) of the data that make it easier to extract useful information when building classifiers or other predictors"*. In this paper, we propose a novel Denoising Model for Representation Learning (*DenoiseRep*) to improve feature discrimination with joint feature extraction and denoising. *DenoiseRep* views each embedding layer in a backbone as a denoising layer, processing the cascaded embedding layers as if we are recursively denoise features step-by-step. This unifies the frameworks of feature extraction and denoising, where the former progressively embeds features from low-level to high-level, and the latter recursively denoises features step-by-step. After that, *DenoiseRep* fuses the parameters of feature extraction and denoising layers, and *theoretically demonstrates* its equivalence before and after the fusion, thus making feature denoising computation-free. *DenoiseRep* is a label-free algorithm that incrementally improves features but also complementary to the label if available. Experimental results on various discriminative vision tasks, including re-identification (Market-1501, DukeMTMC-reID, MSMT17, CUHK-03, vehicleID), image classification (ImageNet, UB200, Oxford-Pet, Flowers), object detection (COCO), image segmentation (ADE20K) show stability and impressive improvements. We also …
Oral
Alvin Tan · Chunhua Yu · Bria Long · Wanjing Ma · Tonya Murray · Rebecca Silverman · Jason Yeatman · Michael C Frank
[ East Meeting Room 1-3 ]
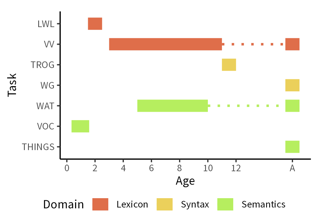
Abstract
How (dis)similar are the learning trajectories of vision–language models and children? Recent modeling work has attempted to understand the gap between models’ and humans’ data efficiency by constructing models trained on less data, especially multimodal naturalistic data. However, such models are often evaluated on adult-level benchmarks, with limited breadth in language abilities tested, and without direct comparison to behavioral data. We introduce DevBench, a multimodal benchmark comprising seven language evaluation tasks spanning the domains of lexical, syntactic, and semantic ability, with behavioral data from both children and adults. We evaluate a set of vision–language models on these tasks, comparing models and humans on their response patterns, not their absolute performance. Across tasks, models exhibit variation in their closeness to human response patterns, and models that perform better on a task also more closely resemble human behavioral responses. We also examine the developmental trajectory of OpenCLIP over training, finding that greater training results in closer approximations to adult response patterns. DevBench thus provides a benchmark for comparing models to human language development. These comparisons highlight ways in which model and human language learning processes diverge, providing insight into entry points for improving language models.
Oral
Ruiqi Gao · Aleksander Holynski · Philipp Henzler · Arthur Brussee · Ricardo Martin Brualla · Pratul Srinivasan · Jonathan Barron · Ben Poole
[ West Exhibition Hall C, B3 ]
Abstract
Advances in 3D reconstruction have enabled high-quality 3D capture, but require a user to collect hundreds to thousands of images to create a 3D scene. We present CAT3D, a method for creating anything in 3D by simulating this real-world capture process with a multi-view diffusion model. Given any number of input images and a set of target novel viewpoints, our model generates highly consistent novel views of a scene. These generated views can be used as input to robust 3D reconstruction techniques to produce 3D representations that can be rendered from any viewpoint in real-time. CAT3D can create entire 3D scenes in as little as one minute, and outperforms existing methods for single image and few-view 3D scene creation.
Oral
David Romero · Chenyang Lyu · Haryo Wibowo · Santiago Góngora · Aishik Mandal · Sukannya Purkayastha · Jesus-German Ortiz-Barajas · Emilio Cueva · Jinheon Baek · Soyeong Jeong · Injy Hamed · Yong Zheng-Xin · Zheng Wei Lim · Paula Silva · Jocelyn Dunstan · Mélanie Jouitteau · David LE MEUR · Joan Nwatu · Ganzorig Batnasan · Munkh-Erdene Otgonbold · Munkhjargal Gochoo · Guido Ivetta · Luciana Benotti · Laura Alonso Alemany · Hernán Maina · Jiahui Geng · Tiago Timponi Torrent · Frederico Belcavello · Marcelo Viridiano · Jan Christian Blaise Cruz · Dan John Velasco · Oana Ignat · Zara Burzo · Chenxi Whitehouse · Artem Abzaliev · Teresa Clifford · Gráinne Caulfield · Teresa Lynn · Christian Salamea-Palacios · Vladimir Araujo · Yova Kementchedjhieva · Mihail Mihaylov · Israel Azime · Henok Ademtew · Bontu Balcha · Naome A. Etori · David Adelani · Rada Mihalcea · Atnafu Lambebo Tonja · Maria Cabrera · Gisela Vallejo · Holy Lovenia · Ruochen Zhang · Marcos Estecha-Garitagoitia · Mario Rodríguez-Cantelar · Toqeer Ehsan · Rendi Chevi · Muhammad Adilazuarda · Ryandito Diandaru · Samuel Cahyawijaya · Fajri Koto · Tatsuki Kuribayashi · Haiyue Song · Aditya Khandavally · Thanmay Jayakumar · Raj Dabre · Mohamed Imam · Kumaranage Nagasinghe · Alina Dragonetti · Luis Fernando D'Haro · Niyomugisha Olivier · Jay Gala · Pranjal Chitale · Fauzan Farooqui · Thamar Solorio · Alham Aji
[ East Meeting Room 1-3 ]

Abstract
Visual Question Answering~(VQA) is an important task in multimodal AI, which requires models to understand and reason on knowledge present in visual and textual data. However, most of the current VQA datasets and models are primarily focused on English and a few major world languages, with images that are Western-centric. While recent efforts have tried to increase the number of languages covered on VQA datasets, they still lack diversity in low-resource languages. More importantly, some datasets extend the text to other languages, either via translation or some other approaches, but usually keep the same images, resulting in narrow cultural representation. To address these limitations, we create CVQA, a new Culturally-diverse Multilingual Visual Question Answering benchmark dataset, designed to cover a rich set of languages and regions, where we engage native speakers and cultural experts in the data collection process. CVQA includes culturally-driven images and questions from across 28 countries in four continents, covering 26 languages with 11 scripts, providing a total of 9k questions. We benchmark several Multimodal Large Language Models (MLLMs) on CVQA, and we show that the dataset is challenging for the current state-of-the-art models. This benchmark will serve as a probing evaluation suite for assessing the cultural …
Oral
Michael Luo · Justin Wong · Brandon Trabucco · Yanping Huang · Joseph Gonzalez · zhifeng Chen · Ruslan Salakhutdinov · Ion Stoica
[ West Exhibition Hall C, B3 ]

Abstract
Beyond scaling base models with more data or parameters, fine-tuned adapters provide an alternative way to generate high fidelity, custom images at reduced costs. As such, adapters have been widely adopted by open-source communities, accumulating a database of over 100K adapters—most of which are highly customized with insufficient descriptions. To generate high quality images, this paper explores the problem of matching the prompt to a Stylus of relevant adapters, built on recent work that highlight the performance gains of composing adapters. We introduce Stylus, which efficiently selects and automatically composes task-specific adapters based on a prompt's keywords. Stylus outlines a three-stage approach that first summarizes adapters with improved descriptions and embeddings, retrieves relevant adapters, and then further assembles adapters based on prompts' keywords by checking how well they fit the prompt. To evaluate Stylus, we developed StylusDocs, a curated dataset featuring 75K adapters with pre-computed adapter embeddings. In our evaluation on popular Stable Diffusion checkpoints, Stylus achieves greater CLIP/FID Pareto efficiency and is twice as preferred, with humans and multimodal models as evaluators, over the base model.
Oral
Tianwei Yin · Michaël Gharbi · Taesung Park · Richard Zhang · Eli Shechtman · Fredo Durand · Bill Freeman
[ East Ballroom A, B ]
Abstract
Recent approaches have shown promises distilling expensive diffusion models into efficient one-step generators.Amongst them, Distribution Matching Distillation (DMD) produces one-step generators that match their teacher in distribution, i.e., the distillation process does not enforce a one-to-one correspondence with the sampling trajectories of their teachers.However, to ensure stable training in practice, DMD requires an additional regression loss computed using a large set of noise--image pairs, generated by the teacher with many steps of a deterministic sampler.This is not only computationally expensive for large-scale text-to-image synthesis, but it also limits the student's quality, tying it too closely to the teacher's original sampling paths.We introduce DMD2, a set of techniques that lift this limitation and improve DMD training.First, we eliminate the regression loss and the need for expensive dataset construction.We show that the resulting instability is due to the "fake" critic not estimating the distribution of generated samples with sufficient accuracy and propose a two time-scale update rule as a remedy.Second, we integrate a GAN loss into the distillation procedure, discriminating between generated samples and real images.This lets us train the student model on real data, thus mitigating the imperfect "real" score estimation from the teacher model, and thereby enhancing quality.Third, we introduce …
Oral
Minghua Liu · Chong Zeng · Xinyue Wei · Ruoxi Shi · Linghao Chen · Chao Xu · Mengqi Zhang · Zhaoning Wang · Xiaoshuai Zhang · Isabella Liu · Hongzhi Wu · Hao Su
[ West Meeting Room 211-214 ]
Abstract
Open-world 3D reconstruction models have recently garnered significant attention. However, without sufficient 3D inductive bias, existing methods typically entail expensive training costs and struggle to extract high-quality 3D meshes. In this work, we introduce MeshFormer, a sparse-view reconstruction model that explicitly leverages 3D native structure, input guidance, and training supervision. Specifically, instead of using a triplane representation, we store features in 3D sparse voxels and combine transformers with 3D convolutions to leverage an explicit 3D structure and projective bias. In addition to sparse-view RGB input, we require the network to take input and generate corresponding normal maps. The input normal maps can be predicted by 2D diffusion models, significantly aiding in the guidance and refinement of the geometry's learning. Moreover, by combining Signed Distance Function (SDF) supervision with surface rendering, we directly learn to generate high-quality meshes without the need for complex multi-stage training processes. By incorporating these explicit 3D biases, MeshFormer can be trained efficiently and deliver high-quality textured meshes with fine-grained geometric details. It can also be integrated with 2D diffusion models to enable fast single-image-to-3D and text-to-3D tasks. **Videos are available at https://meshformer3d.github.io/**
Oral
Andrew M. Bean · Simeon Hellsten · Harry Mayne · Jabez Magomere · Ethan Chi · Ryan Chi · Scott Hale · Hannah Rose Kirk
[ East Meeting Room 1-3 ]
Abstract
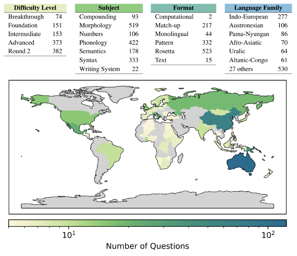
In this paper, we present the LingOly benchmark, a novel benchmark for advanced reasoning abilities in large language models. Using challenging Linguistic Olympiad puzzles, we evaluate (i) capabilities for in-context identification and generalisation of linguistic patterns in very low-resource or extinct languages, and (ii) abilities to follow complex task instructions. The LingOly benchmark covers more than 90 mostly low-resource languages, minimising issues of data contamination, and contains 1,133 problems across 6 formats and 5 levels of human difficulty. We assess performance with both direct accuracy and comparison to a no-context baseline to penalise memorisation. Scores from 11 state-of-the-art LLMs demonstrate the benchmark to be challenging, and models perform poorly on the higher difficulty problems. On harder problems, even the top model only achieved 38.7% accuracy, a 24.7% improvement over the no-context baseline. Large closed models typically outperform open models, and in general, the higher resource the language, the better the scores. These results indicate, in absence of memorisation, true multi-step out-of-domain reasoning remains a challenge for current language models.
Oral
Shubham Toshniwal · Ivan Moshkov · Sean Narenthiran · Daria Gitman · Fei Jia · Igor Gitman
[ East Ballroom A, B ]

Abstract
Recent work has shown the immense potential of synthetically generated datasets for training large language models (LLMs), especially for acquiring targeted skills. Current large-scale math instruction tuning datasets such as MetaMathQA (Yu et al., 2024) and MAmmoTH (Yue et al., 2024) are constructed using outputs from closed-source LLMs with commercially restrictive licenses. A key reason limiting the use of open-source LLMs in these data generation pipelines has been the wide gap between the mathematical skills of the best closed-source LLMs, such as GPT-4, and the best open-source LLMs. Building on the recent progress in open-source LLMs, our proposed prompting novelty, and some brute-force scaling, we construct OpenMathInstruct-1, a math instruction tuning dataset with 1.8M problem-solution pairs. The dataset is constructed by synthesizing code-interpreter solutions for GSM8K and MATH, two popular math reasoning benchmarks, using the recently released and permissively licensed Mixtral model. Our best model, OpenMath-CodeLlama-70B, trained on a subset of OpenMathInstruct-1, achieves a score of 84.6% on GSM8K and 50.7% on MATH, which is competitive with the best gpt-distilled models. We will release our code, models, and the OpenMathInstruct-1 dataset under a commercially permissive license.
Oral
Tero Karras · Miika Aittala · Tuomas Kynkäänniemi · Jaakko Lehtinen · Timo Aila · Samuli Laine
[ West Exhibition Hall C, B3 ]
Abstract
The primary axes of interest in image-generating diffusion models are image quality, the amount of variation in the results, and how well the results align with a given condition, e.g., a class label or a text prompt. The popular classifier-free guidance approach uses an unconditional model to guide a conditional model, leading to simultaneously better prompt alignment and higher-quality images at the cost of reduced variation. These effects seem inherently entangled, and thus hard to control. We make the surprising observation that it is possible to obtain disentangled control over image quality without compromising the amount of variation by guiding generation using a smaller, less-trained version of the model itself rather than an unconditional model. This leads to significant improvements in ImageNet generation, setting record FIDs of 1.01 for 64x64 and 1.25 for 512x512, using publicly available networks. Furthermore, the method is also applicable to unconditional diffusion models, drastically improving their quality.
Oral
Jiaqing Zhang · Mingxiang Cao · Weiying Xie · Jie Lei · Daixun Li · Wenbo Huang · Yunsong Li · Xue Yang
[ West Meeting Room 211-214 ]

Abstract
Multimodal image fusion and object detection are crucial for autonomous driving. While current methods have advanced the fusion of texture details and semantic information, their complex training processes hinder broader applications. Addressing this challenge, we introduce E2E-MFD, a novel end-to-end algorithm for multimodal fusion detection. E2E-MFD streamlines the process, achieving high performance with a single training phase. It employs synchronous joint optimization across components to avoid suboptimal solutions associated to individual tasks. Furthermore, it implements a comprehensive optimization strategy in the gradient matrix for shared parameters, ensuring convergence to an optimal fusion detection configuration. Our extensive testing on multiple public datasets reveals E2E-MFD's superior capabilities, showcasing not only visually appealing image fusion but also impressive detection outcomes, such as a 3.9\% and 2.0\% $\text{mAP}_{50}$ increase on horizontal object detection dataset M3FD and oriented object detection dataset DroneVehicle, respectively, compared to state-of-the-art approaches.
Oral
Haonan Lin · Wenbin An · Jiahao Wang · Yan Chen · Feng Tian · Mengmeng Wang · QianYing Wang · Guang Dai · Jingdong Wang
[ East Ballroom A, B ]

Abstract
Recent advancements have shown promise in applying traditional Semi-Supervised Learning strategies to the task of Generalized Category Discovery (GCD). Typically, this involves a teacher-student framework in which the teacher imparts knowledge to the student to classify categories, even in the absence of explicit labels. Nevertheless, GCD presents unique challenges, particularly the absence of priors for new classes, which can lead to the teacher's misguidance and unsynchronized learning with the student, culminating in suboptimal outcomes. In our work, we delve into why traditional teacher-student designs falter in generalized category discovery as compared to their success in closed-world semi-supervised learning. We identify inconsistent pattern learning as the crux of this issue and introduce FlipClass—a method that dynamically updates the teacher to align with the student's attention, instead of maintaining a static teacher reference. Our teacher-attention-update strategy refines the teacher's focus based on student feedback, promoting consistent pattern recognition and synchronized learning across old and new classes. Extensive experiments on a spectrum of benchmarks affirm that FlipClass significantly surpasses contemporary GCD methods, establishing new standards for the field.
Oral
Yulia Rubanova · Tatiana Lopez-Guevara · Kelsey Allen · Will Whitney · Kimberly Stachenfeld · Tobias Pfaff
[ West Exhibition Hall C, B3 ]
Abstract
Simulating large scenes with many rigid objects is crucial for a variety of applications, such as robotics, engineering, film and video games. Rigid interactions are notoriously hard to model: small changes to the initial state or the simulation parameters can lead to large changes in the final state. Recently, learned simulators based on graph networks (GNNs) were developed as an alternative to hand-designed simulators like MuJoCo and Bullet. They are able to accurately capture dynamics of real objects directly from real-world observations. However, current state-of-the-art learned simulators operate on meshes and scale poorly to scenes with many objects or detailed shapes. Here we present SDF-Sim, the first learned rigid-body simulator designed for scale. We use learned signed-distance functions (SDFs) to represent the object shapes and to speed up distance computation. We design the simulator to leverage SDFs and avoid the fundamental bottleneck of the previous simulators associated with collision detection.For the first time in literature, we demonstrate that we can scale the GNN-based simulators to scenes with hundreds of objects and up to 1.1 million nodes, where mesh-based approaches run out of memory. Finally, we show that SDF-Sim can be applied to real world scenes by extracting SDFs from multi-view …
Oral
Dongxiao He · Lianze Shan · Jitao Zhao · Hengrui Zhang · Zhen Wang · Weixiong Zhang
[ West Meeting Room 211-214 ]

Abstract
Graph Contrastive Learning (GCL) has emerged as a powerful approach for generating graph representations without the need for manual annotation. Most advanced GCL methods fall into three main frameworks: node discrimination, group discrimination, and bootstrapping schemes, all of which achieve comparable performance. However, the underlying mechanisms and factors that contribute to their effectiveness are not yet fully understood. In this paper, we revisit these frameworks and reveal a common mechanism—representation scattering—that significantly enhances their performance. Our discovery highlights an essential feature of GCL and unifies these seemingly disparate methods under the concept of representation scattering. To leverage this insight, we introduce Scattering Graph Representation Learning (SGRL), a novel framework that incorporates a new representation scattering mechanism designed to enhance representation diversity through a center-away strategy. Additionally, consider the interconnected nature of graphs, we develop a topology-based constraint mechanism that integrates graph structural properties with representation scattering to prevent excessive scattering. We extensively evaluate SGRL across various downstream tasks on benchmark datasets, demonstrating its efficacy and superiority over existing GCL methods. Our findings underscore the significance of representation scattering in GCL and provide a structured framework for harnessing this mechanism to advance graph representation learning. The code of SGRL is at …
Oral
Zhongchao Yi · Zhengyang Zhou · Qihe Huang · Yanjiang Chen · Liheng Yu · Xu Wang · Yang Wang
[ East Meeting Room 1-3 ]
Abstract
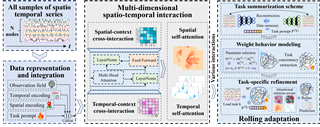
Spatiotemporal learning has become a pivotal technique to enable urban intelligence. Traditional spatiotemporal models mostly focus on a specific task by assuming a same distribution between training and testing sets. However, given that urban systems are usually dynamic, multi-sourced with imbalanced data distributions, current specific task-specific models fail to generalize to new urban conditions and adapt to new domains without explicitly modeling interdependencies across various dimensions and types of urban data. To this end, we argue that there is an essential to propose a Continuous Multi-task Spatio-Temporal learning framework (CMuST) to empower collective urban intelligence, which reforms the urban spatiotemporal learning from single-domain to cooperatively multi-dimensional and multi-task learning. Specifically, CMuST proposes a new multi-dimensional spatiotemporal interaction network (MSTI) to allow cross-interactions between context and main observations as well as self-interactions within spatial and temporal aspects to be exposed, which is also the core for capturing task-level commonality and personalization. To ensure continuous task learning, a novel Rolling Adaptation training scheme (RoAda) is devised, which not only preserves task uniqueness by constructing data summarization-driven task prompts, but also harnesses correlated patterns among tasks by iterative model behavior modeling. We further establish a benchmark of three cities for multi-task spatiotemporal learning, …
Oral
Siyuan Guo · Chi Zhang · Karthika Mohan · Ferenc Huszar · Bernhard Schölkopf
[ West Meeting Room 211-214 ]
Abstract
We study causal effect estimation in a setting where the data are not i.i.d.$\ $(independent and identically distributed). We focus on exchangeable data satisfying an assumption of independent causal mechanisms. Traditional causal effect estimation frameworks, e.g., relying on structural causal models and do-calculus, are typically limited to i.i.d. data and do not extend to more general exchangeable generative processes, which naturally arise in multi-environment data. To address this gap, we develop a generalized framework for exchangeable data and introduce a truncated factorization formula that facilitates both the identification and estimation of causal effects in our setting. To illustrate potential applications, we introduce a causal Pólya urn model and demonstrate how intervention propagates effects in exchangeable data settings. Finally, we develop an algorithm that performs simultaneous causal discovery and effect estimation given multi-environment data.
Oral
Zekun Shi · Zheyuan Hu · Min Lin · Kenji Kawaguchi
[ East Meeting Room 1-3 ]
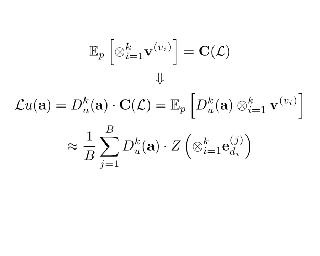
Abstract
Optimizing neural networks with loss that contain high-dimensional and high-order differential operators is expensive to evaluate with back-propagation due to $\mathcal{O}(d^{k})$ scaling of the derivative tensor size and the $\mathcal{O}(2^{k-1}L)$ scaling in the computation graph, where $d$ is the dimension of the domain, $L$ is the number of ops in the forward computation graph, and $k$ is the derivative order. In previous works, the polynomial scaling in $d$ was addressed by amortizing the computation over the optimization process via randomization. Separately, the exponential scaling in $k$ for univariate functions ($d=1$) was addressed with high-order auto-differentiation (AD). In this work, we show how to efficiently perform arbitrary contraction of the derivative tensor of arbitrary order for multivariate functions, by properly constructing the input tangents to univariate high-order AD, which can be used to efficiently randomize any differential operator. When applied to Physics-Informed Neural Networks (PINNs), our method provides >1000$\times$ speed-up and >30$\times$ memory reduction over randomization with first-order AD, and we can now solve 1-million-dimensional PDEs in 8 minutes on a single NVIDIA A100 GPU. This work opens the possibility of using high-order differential operators in large-scale problems.
Oral
Felix Petersen · Hilde Kuehne · Christian Borgelt · Julian Welzel · Stefano Ermon
[ East Ballroom A, B ]
Abstract
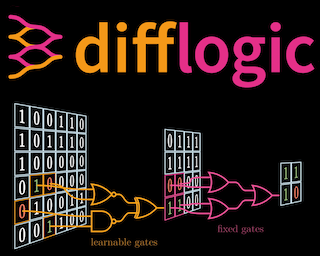
With the increasing inference cost of machine learning models, there is a growing interest in models with fast and efficient inference. Recently, an approach for learning logic gate networks directly via a differentiable relaxation was proposed. Logic gate networks are faster than conventional neural network approaches because their inference only requires logic gate operators such as NAND, OR, and XOR, which are the underlying building blocks of current hardware and can be efficiently executed. We build on this idea, extending it by deep logic gate tree convolutions, logical OR pooling, and residual initializations. This allows scaling logic gate networks up by over one order of magnitude and utilizing the paradigm of convolution. On CIFAR-10, we achieve an accuracy of 86.29% using only 61 million logic gates, which improves over the SOTA while being 29x smaller.
Oral
Raffaele Paolino · Sohir Maskey · Pascal Welke · Gitta Kutyniok
[ West Exhibition Hall C, B3 ]
Abstract
We introduce $r$-loopy Weisfeiler-Leman ($r$-$\ell$WL), a novel hierarchy of graph isomorphism tests and a corresponding GNN framework, $r$-$\ell$MPNN, that can count cycles up to length $r{+}2$. Most notably, we show that $r$-$\ell$WL can count homomorphisms of cactus graphs. This extends 1-WL, which can only count homomorphisms of trees and, in fact, is incomparable to $k$-WL for any fixed $k$. We empirically validate the expressive and counting power of $r$-$\ell$MPNN on several synthetic datasets and demonstrate the scalability and strong performance on various real-world datasets, particularly on sparse graphs.
Oral
Peter Tong · Ellis Brown · Penghao Wu · Sanghyun Woo · Adithya Jairam Vedagiri IYER · Sai Charitha Akula · Shusheng Yang · Jihan Yang · Manoj Middepogu · Ziteng Wang · Xichen Pan · Rob Fergus · Yann LeCun · Saining Xie
[ East Ballroom A, B ]
Abstract
We introduce Cambrian-1, a family of multimodal LLMs (MLLMs) designed with a vision-centric approach. While stronger language models can enhance multimodal capabilities, the design choices for vision components are often insufficiently explored and disconnected from visual representation learning research. This gap hinders accurate sensory grounding in real-world scenarios. Our study uses LLMs and visual instruction tuning as an interface to evaluate various visual representations, offering new insights into different models and architectures—self-supervised, strongly supervised, or combinations thereof—based on experiments with over 15 vision models. We critically examine existing MLLM benchmarks, addressing the difficulties involved in consolidating and interpreting results from various tasks. To further improve visual grounding, we propose spatial vision aggregator (SVA), a dynamic and spatially-aware connector that integrates vision features with LLMs while reducing the number of tokens. Additionally, we discuss the curation of high-quality visual instruction-tuning data from publicly available sources, emphasizing the importance of distribution balancing. Collectively, Cambrian-1 not only achieves state-of-the-art performances but also serves as a comprehensive, open cookbook for instruction-tuned MLLMs. We provide model weights, code, supporting tools, datasets, and detailed instruction-tuning and evaluation recipes. We hope our release will inspire and accelerate advancements in multimodal systems and visual representation learning.
Oral
Feng Xie · Zhen Yao · Lin Xie · Yan Zeng · Zhi Geng
[ West Meeting Room 211-214 ]
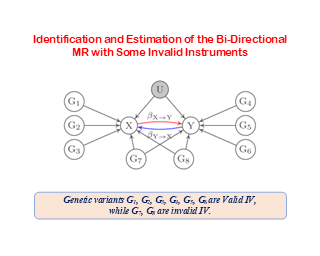
Abstract
We consider the challenging problem of estimating causal effects from purely observational data in the bi-directional Mendelian randomization (MR), where some invalid instruments, as well as unmeasured confounding, usually exist. To address this problem, most existing methods attempt to find proper valid instrumental variables (IVs) for the target causal effect by expert knowledge or by assuming that the causal model is a one-directional MR model. As such, in this paper, we first theoretically investigate the identification of the bi-directional MR from observational data. In particular, we provide necessary and sufficient conditions under which valid IV sets are correctly identified such that the bi-directional MR model is identifiable, including the causal directions of a pair of phenotypes (i.e., the treatment and outcome).Moreover, based on the identification theory, we develop a cluster fusion-like method to discover valid IV sets and estimate the causal effects of interest.We theoretically demonstrate the correctness of the proposed algorithm.Experimental results show the effectiveness of our method for estimating causal effects in both one-directional and bi-directional MR models.
Oral
Ioannis Kalogeropoulos · Giorgos Bouritsas · Yannis Panagakis
[ West Exhibition Hall C, B3 ]
Abstract
This paper pertains to an emerging machine learning paradigm: learning higher- order functions, i.e. functions whose inputs are functions themselves, particularly when these inputs are Neural Networks (NNs). With the growing interest in architectures that process NNs, a recurring design principle has permeated the field: adhering to the permutation symmetries arising from the connectionist structure ofNNs. However, are these the sole symmetries present in NN parameterizations? Zooming into most practical activation functions (e.g. sine, ReLU, tanh) answers this question negatively and gives rise to intriguing new symmetries, which we collectively refer to as scaling symmetries, that is, non-zero scalar multiplications and divisions of weights and biases. In this work, we propose Scale Equivariant Graph MetaNetworks - ScaleGMNs, a framework that adapts the Graph Metanetwork (message-passing) paradigm by incorporating scaling symmetries and thus rendering neuron and edge representations equivariant to valid scalings. We introduce novel building blocks, of independent technical interest, that allow for equivariance or invariance with respect to individual scalar multipliers or their product and use them in all components of ScaleGMN. Furthermore, we prove that, under certain expressivity conditions, ScaleGMN can simulate the forward and backward pass of any input feedforward neural network. Experimental results demonstrate that our …
Oral
Gabriel Poesia · David Broman · Nick Haber · Noah Goodman
[ East Meeting Room 1-3 ]
Abstract
How did humanity coax mathematics from the aether? We explore the Platonic view that mathematics can be discovered from its axioms---a game of conjecture and proof. We describe an agent that jointly learns to pose challenging problems for itself (conjecturing) and solve them (theorem proving). Given a mathematical domain axiomatized in dependent type theory, we first combine methods for constrained decoding and type-directed synthesis to sample valid conjectures from a language model. Our method guarantees well-formed conjectures by construction, even as we start with a randomly initialized model. We use the same model to represent a policy and value function for guiding proof search. Our agent targets generating hard but provable conjectures --- a moving target, since its own theorem proving ability also improves as it trains. We propose novel methods for hindsight relabeling on proof search trees to significantly improve the agent's sample efficiency in both tasks. Experiments on 3 axiomatic domains (propositional logic, arithmetic and group theory) demonstrate that our agent can bootstrap from only the axioms, self-improving in generating true and challenging conjectures and in finding proofs.
Oral
Nicholas Gao · Stephan Günnemann
[ East Ballroom A, B ]
Abstract
Neural wave functions accomplished unprecedented accuracies in approximating the ground state of many-electron systems, though at a high computational cost. Recent works proposed amortizing the cost by learning generalized wave functions across different structures and compounds instead of solving each problem independently. Enforcing the permutation antisymmetry of electrons in such generalized neural wave functions remained challenging as existing methods require discrete orbital selection via non-learnable hand-crafted algorithms. This work tackles the problem by defining overparametrized, fully learnable neural wave functions suitable for generalization across molecules. We achieve this by relying on Pfaffians rather than Slater determinants. The Pfaffian allows us to enforce the antisymmetry on arbitrary electronic systems without any constraint on electronic spin configurations or molecular structure. Our empirical evaluation finds that a single neural Pfaffian calculates the ground state and ionization energies with chemical accuracy across various systems. On the TinyMol dataset, we outperform the `gold-standard' CCSD(T) CBS reference energies by 1.9m$E_h$ and reduce energy errors compared to previous generalized neural wave functions by up to an order of magnitude.
Oral
Yongzhe Jia · Xuyun Zhang · Hongsheng Hu · Kim-Kwang Raymond Choo · Lianyong Qi · Xiaolong Xu · Amin Beheshti · Wanchun Dou
[ West Exhibition Hall C, B3 ]

Abstract
Federated learning (FL) has emerged as a prominent machine learning paradigm in edge computing environments, enabling edge devices to collaboratively optimize a global model without sharing their private data. However, existing FL frameworks suffer from efficacy deterioration due to the system heterogeneity inherent in edge computing, especially in the presence of domain shifts across local data. In this paper, we propose a heterogeneous FL framework DapperFL, to enhance model performance across multiple domains. In DapperFL, we introduce a dedicated Model Fusion Pruning (MFP) module to produce personalized compact local models for clients to address the system heterogeneity challenges. The MFP module prunes local models with fused knowledge obtained from both local and remaining domains, ensuring robustness to domain shifts. Additionally, we design a Domain Adaptive Regularization (DAR) module to further improve the overall performance of DapperFL. The DAR module employs regularization generated by the pruned model, aiming to learn robust representations across domains. Furthermore, we introduce a specific aggregation algorithm for aggregating heterogeneous local models with tailored architectures and weights. We implement DapperFL on a real-world FL platform with heterogeneous clients. Experimental results on benchmark datasets with multiple domains demonstrate that DapperFL outperforms several state-of-the-art FL frameworks by up to …
Oral
Jiaming Ji · Boyuan Chen · Hantao Lou · Donghai Hong · Borong Zhang · Xuehai Pan · Tianyi (Alex) Qiu · Juntao Dai · Yaodong Yang
[ West Meeting Room 211-214 ]
Abstract
With the rapid development of large language models (LLMs) and ever-evolving practical requirements, finding an efficient and effective alignment method has never been more critical. However, the tension between the complexity of current alignment methods and the need for rapid iteration in deployment scenarios necessitates the development of a model-agnostic alignment approach that can operate under these constraints. In this paper, we introduce Aligner, a novel and simple alignment paradigm that learns the correctional residuals between preferred and dispreferred answers using a small model. Designed as a model-agnostic, plug-and-play module, Aligner can be directly applied to various open-source and API-based models with only one-off training, making it suitable for rapid iteration. Notably, Aligner can be applied to any powerful, large-scale upstream models. Moreover, it can even iteratively bootstrap the upstream models using corrected responses as synthetic human preference data, breaking through the model's performance ceiling. Our experiments demonstrate performance improvements by deploying the same Aligner model across 11 different LLMs, evaluated on the 3H dimensions (helpfulness, harmlessness, and honesty). Specifically, Aligner-7B has achieved an average improvement of 68.9% in helpfulness and 22.8% in harmlessness across the tested LLMs while also effectively reducing hallucination. In the Alpaca-Eval leaderboard, stacking Aligner-2B on …
Oral
Nikhil Khandekar · Qiao Jin · Guangzhi Xiong · Soren Dunn · Serina Applebaum · Zain Anwar · Maame Sarfo-Gyamfi · Conrad Safranek · Abid Anwar · Andrew Zhang · Aidan Gilson · Maxwell Singer · Amisha Dave · Anrew Taylor · Aidong Zhang · Qingyu Chen · Zhiyong Lu
[ East Meeting Room 1-3 ]
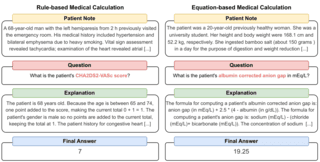
Abstract
Current benchmarks for evaluating large language models (LLMs) in medicine are primarily focused on question-answering involving domain knowledge and descriptive reasoning. While such qualitative capabilities are vital to medical diagnosis, in real-world scenarios, doctors frequently use clinical calculators that follow quantitative equations and rule-based reasoning paradigms for evidence-based decision support. To this end, we propose MedCalc-Bench, a first-of-its-kind dataset focused on evaluating the medical calculation capability of LLMs. MedCalc-Bench contains an evaluation set of over 1000 manually reviewed instances from 55 different medical calculation tasks. Each instance in MedCalc-Bench consists of a patient note, a question requesting to compute a specific medical value, a ground truth answer, and a step-by-step explanation showing how the answer is obtained. While our evaluation results show the potential of LLMs in this area, none of them are effective enough for clinical settings. Common issues include extracting the incorrect entities, not using the correct equation or rules for a calculation task, or incorrectly performing the arithmetic for the computation. We hope our study highlights the quantitative knowledge and reasoning gaps in LLMs within medical settings, encouraging future improvements of LLMs for various clinical calculation tasks. MedCalc-Bench is publicly available at: https://github.com/ncbi-nlp/MedCalc-Bench.
Oral
Christopher Wang · Adam Yaari · Aaditya Singh · Vighnesh Subramaniam · Dana Rosenfarb · Jan DeWitt · Pranav Misra · Joseph Madsen · Scellig Stone · Gabriel Kreiman · Boris Katz · Ignacio Cases · Andrei Barbu
[ East Meeting Room 1-3 ]
Abstract
We present the Brain Treebank, a large-scale dataset of electrophysiological neural responses, recorded from intracranial probes while 10 subjects watched one or more Hollywood movies. Subjects watched on average 2.6 Hollywood movies, for an average viewing time of 4.3 hours, and a total of 43 hours. The audio track for each movie was transcribed with manual corrections. Word onsets were manually annotated on spectrograms of the audio track for each movie. Each transcript was automatically parsed and manually corrected into the universal dependencies (UD) formalism, assigning a part of speech to every word and a dependency parse to every sentence. In total, subjects heard over 38,000 sentences (223,000 words), while they had on average 168 electrodes implanted. This is the largest dataset of intracranial recordings featuring grounded naturalistic language, one of the largest English UD treebanks in general, and one of only a few UD treebanks aligned to multimodal features. We hope that this dataset serves as a bridge between linguistic concepts, perception, and their neural representations. To that end, we present an analysis of which electrodes are sensitive to language features while also mapping out a rough time course of language processing across these electrodes. The Brain Treebank is …
Oral
Yutao Sun · Li Dong · Yi Zhu · Shaohan Huang · Wenhui Wang · Shuming Ma · Quanlu Zhang · Jianyong Wang · Furu Wei
[ West Exhibition Hall C, B3 ]
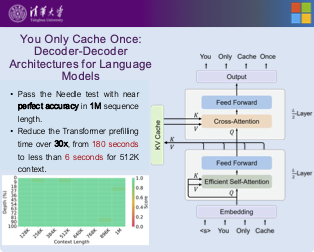
Abstract
We introduce a decoder-decoder architecture, YOCO, for large language models, which only caches key-value pairs once. It consists of two components, i.e., a cross-decoder stacked upon a self-decoder. The self-decoder efficiently encodes global key-value (KV) caches that are reused by the cross-decoder via cross-attention. The overall model behaves like a decoder-only Transformer, although YOCO only caches once. The design substantially reduces GPU memory demands, yet retains global attention capability. Additionally, the computation flow enables prefilling to early exit without changing the final output, thereby significantly speeding up the prefill stage. Experimental results demonstrate that YOCO achieves favorable performance compared to Transformer in various settings of scaling up model size and number of training tokens. We also extend YOCO to 1M context length with near-perfect needle retrieval accuracy. The profiling results show that YOCO improves inference memory, prefill latency, and throughput by orders of magnitude across context lengths and model sizes.
Oral
Yubin Kim · Chanwoo Park · Hyewon Jeong · Yik Siu Chan · Xuhai "Orson" Xu · Daniel McDuff · Hyeonhoon Lee · Marzyeh Ghassemi · Cynthia Breazeal · Hae Park
[ East Ballroom A, B ]
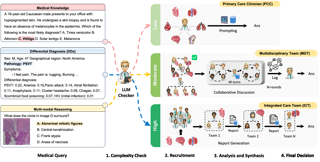
Abstract
Foundation models are becoming valuable tools in medicine. Yet despite their promise, the best way to leverage Large Language Models (LLMs) in complex medical tasks remains an open question. We introduce a novel multi-agent framework, named **M**edical **D**ecision-making **Agents** (**MDAgents**) that helps to address this gap by automatically assigning a collaboration structure to a team of LLMs. The assigned solo or group collaboration structure is tailored to the medical task at hand, a simple emulation inspired by the way real-world medical decision-making processes are adapted to tasks of different complexities. We evaluate our framework and baseline methods using state-of-the-art LLMs across a suite of real-world medical knowledge and clinical diagnosis benchmarks, including a comparison ofLLMs’ medical complexity classification against human physicians. MDAgents achieved the **best performance in seven out of ten** benchmarks on tasks requiring an understanding of medical knowledge and multi-modal reasoning, showing a significant **improvement of up to 4.2\%** ($p$ < 0.05) compared to previous methods' best performances. Ablation studies reveal that MDAgents effectively determines medical complexity to optimize for efficiency and accuracy across diverse medical tasks. Notably, the combination of moderator review and external medical knowledge in group collaboration resulted in an average accuracy **improvement of 11.8\%**. Our …
Oral
Chengyi Cai · Zesheng Ye · Lei Feng · Jianzhong Qi · Feng Liu
[ West Meeting Room 211-214 ]
Abstract
*Visual reprogramming* (VR) leverages the intrinsic capabilities of pretrained vision models by adapting their input or output interfaces to solve downstream tasks whose labels (i.e., downstream labels) might be totally different from the labels associated with the pretrained models (i.e., pretrained labels). When adapting the output interface, label mapping methods transform the pretrained labels to downstream labels by establishing a gradient-free one-to-one correspondence between the two sets of labels.However, in this paper, we reveal that one-to-one mappings may overlook the complex relationship between pretrained and downstream labels. Motivated by this observation, we propose a ***B**ayesian-guided **L**abel **M**apping* (BLM) method. BLM constructs an iteratively-updated probabilistic label mapping matrix, with each element quantifying a pairwise relationship between pretrained and downstream labels.The assignment of values to the constructed matrix is guided by Bayesian conditional probability, considering the joint distribution of the downstream labels and the labels predicted by the pretrained model on downstream samples. Experiments conducted on both pretrained vision models (e.g., ResNeXt) and vision-language models (e.g., CLIP) demonstrate the superior performance of BLM over existing label mapping methods. The success of BLM also offers a probabilistic lens through which to understand and analyze the effectiveness of VR.Our code is available at https://github.com/tmlr-group/BayesianLM.
Oral
Gang Liu · Jiaxin Xu · Tengfei Luo · Meng Jiang
[ East Ballroom A, B ]
Abstract
Inverse molecular design with diffusion models holds great potential for advancements in material and drug discovery. Despite success in unconditional molecule generation, integrating multiple properties such as synthetic score and gas permeability as condition constraints into diffusion models remains unexplored. We present the Graph Diffusion Transformer (Graph DiT) for multi-conditional molecular generation. Graph DiT has a condition encoder to learn the representation of numerical and categorical properties and utilizes a Transformer-based graph denoiser to achieve molecular graph denoising under conditions. Unlike previous graph diffusion models that add noise separately on the atoms and bonds in the forward diffusion process, we propose a graph-dependent noise model for training Graph DiT, designed to accurately estimate graph-related noise in molecules. We extensively validate the Graph DiT for multi-conditional polymer and small molecule generation. Results demonstrate our superiority across metrics from distribution learning to condition control for molecular properties. A polymer inverse design task for gas separation with feedback from domain experts further demonstrates its practical utility. The code is available at https://github.com/liugangcode/Graph-DiT.
Oral
Juan Nathaniel · Yongquan Qu · Tung Nguyen · Sungduk Yu · Julius Busecke · Aditya Grover · Pierre Gentine
[ East Meeting Room 1-3 ]

Abstract
Accurate prediction of climate in the subseasonal-to-seasonal scale is crucial for disaster preparedness and robust decision making amidst climate change. Yet, forecasting beyond the weather timescale is challenging because it deals with problems other than initial condition, including boundary interaction, butterfly effect, and our inherent lack of physical understanding. At present, existing benchmarks tend to have shorter forecasting range of up-to 15 days, do not include a wide range of operational baselines, and lack physics-based constraints for explainability. Thus, we propose ChaosBench, a challenging benchmark to extend the predictability range of data-driven weather emulators to S2S timescale. First, ChaosBench is comprised of variables beyond the typical surface-atmospheric ERA5 to also include ocean, ice, and land reanalysis products that span over 45 years to allow for full Earth system emulation that respects boundary conditions. We also propose physics-based, in addition to deterministic and probabilistic metrics, to ensure a physically-consistent ensemble that accounts for butterfly effect. Furthermore, we evaluate on a diverse set of physics-based forecasts from four national weather agencies as baselines to our data-driven counterpart such as ViT/ClimaX, PanguWeather, GraphCast, and FourCastNetV2. Overall, we find methods originally developed for weather-scale applications fail on S2S task: their performance simply collapse to …
Oral
Dora Zhao · Morgan Scheuerman · Pooja Chitre · Jerone Andrews · Georgia Panagiotidou · Shawn Walker · Kathleen Pine · Alice Xiang
[ West Meeting Room 211-214 ]
Abstract
Despite extensive efforts to create fairer machine learning (ML) datasets, there remains a limited understanding of the practical aspects of dataset curation. Drawing from interviews with 30 ML dataset curators, we present a comprehensive taxonomy of the challenges and trade-offs encountered throughout the dataset curation lifecycle. Our findings underscore overarching issues within the broader fairness landscape that impact data curation. We conclude with recommendations aimed at fostering systemic changes to better facilitate fair dataset curation practices.
Oral
YUHONG CHOU · Man Yao · Kexin Wang · Yuqi Pan · Rui-Jie Zhu · Jibin Wu · Yiran Zhong · Yu Qiao · Bo Xu · Guoqi Li
[ West Exhibition Hall C, B3 ]
Abstract
Various linear complexity models, such as Linear Transformer (LinFormer), State Space Model (SSM), and Linear RNN (LinRNN), have been proposed to replace the conventional softmax attention in Transformer structures. However, the optimal design of these linear models is still an open question. In this work, we attempt to answer this question by finding the best linear approximation to softmax attention from a theoretical perspective. We start by unifying existing linear complexity models as the linear attention form and then identify three conditions for the optimal linear attention design: (1) Dynamic memory ability; (2) Static approximation ability; (3) Least parameter approximation. We find that none of the current linear models meet all three conditions, resulting in suboptimal performance. Instead, we propose Meta Linear Attention (MetaLA) as a solution that satisfies these conditions. Our experiments on Multi-Query Associative Recall (MQAR) task, language modeling, image classification, and Long-Range Arena (LRA) benchmark demonstrate that MetaLA is more effective than the existing linear models.