Poster
IaC-Eval: A Code Generation Benchmark for Cloud Infrastructure-as-Code Programs
Patrick Tser Jern Kon · Jiachen Liu · Yiming Qiu · Weijun Fan · Ting He · Lei Lin · Haoran Zhang · Owen Park · George Elengikal · Yuxin Kang · Ang Chen · Mosharaf Chowdhury · Myungjin Lee · Xinyu Wang
West Ballroom A-D #5105
{kind=link}
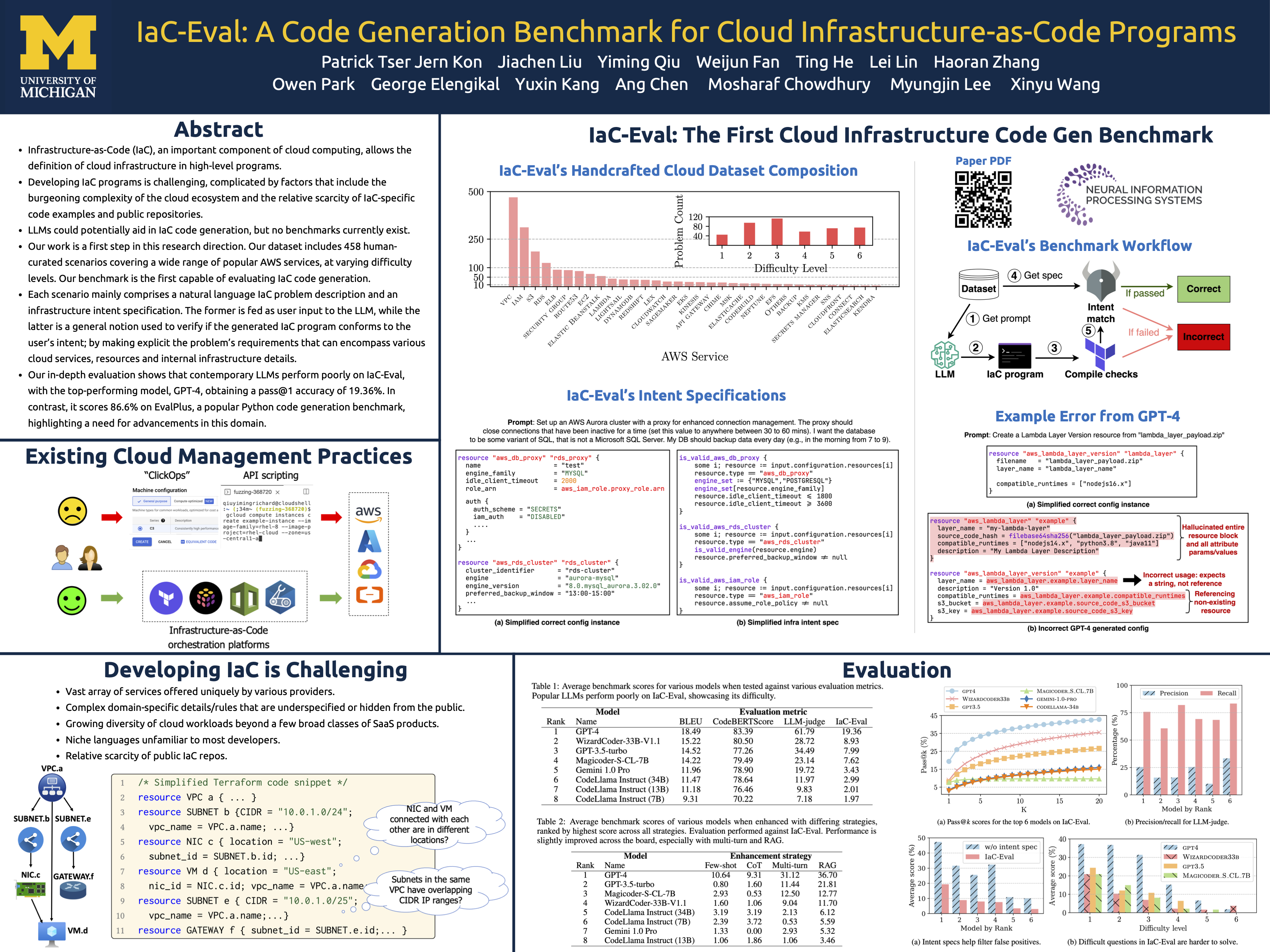
Infrastructure-as-Code (IaC), an important component of cloud computing, allows the definition of cloud infrastructure in high-level programs. However, developing IaC programs is challenging, complicated by factors that include the burgeoning complexity of the cloud ecosystem (e.g., diversity of cloud services and workloads), and the relative scarcity of IaC-specific code examples and public repositories. While large language models (LLMs) have shown promise in general code generation and could potentially aid in IaC development, no benchmarks currently exist for evaluating their ability to generate IaC code. We present IaC-Eval, a first step in this research direction. IaC-Eval's dataset includes 458 human-curated scenarios covering a wide range of popular AWS services, at varying difficulty levels. Each scenario mainly comprises a natural language IaC problem description and an infrastructure intent specification. The former is fed as user input to the LLM, while the latter is a general notion used to verify if the generated IaC program conforms to the user's intent; by making explicit the problem's requirements that can encompass various cloud services, resources and internal infrastructure details. Our in-depth evaluation shows that contemporary LLMs perform poorly on IaC-Eval, with the top-performing model, GPT-4, obtaining a pass@1 accuracy of 19.36%. In contrast, it scores 86.6% on EvalPlus, a popular Python code generation benchmark, highlighting a need for advancements in this domain. We open-source the IaC-Eval dataset and evaluation framework at https://github.com/autoiac-project/iac-eval to enable future research on LLM-based IaC code generation.