{kind=link}
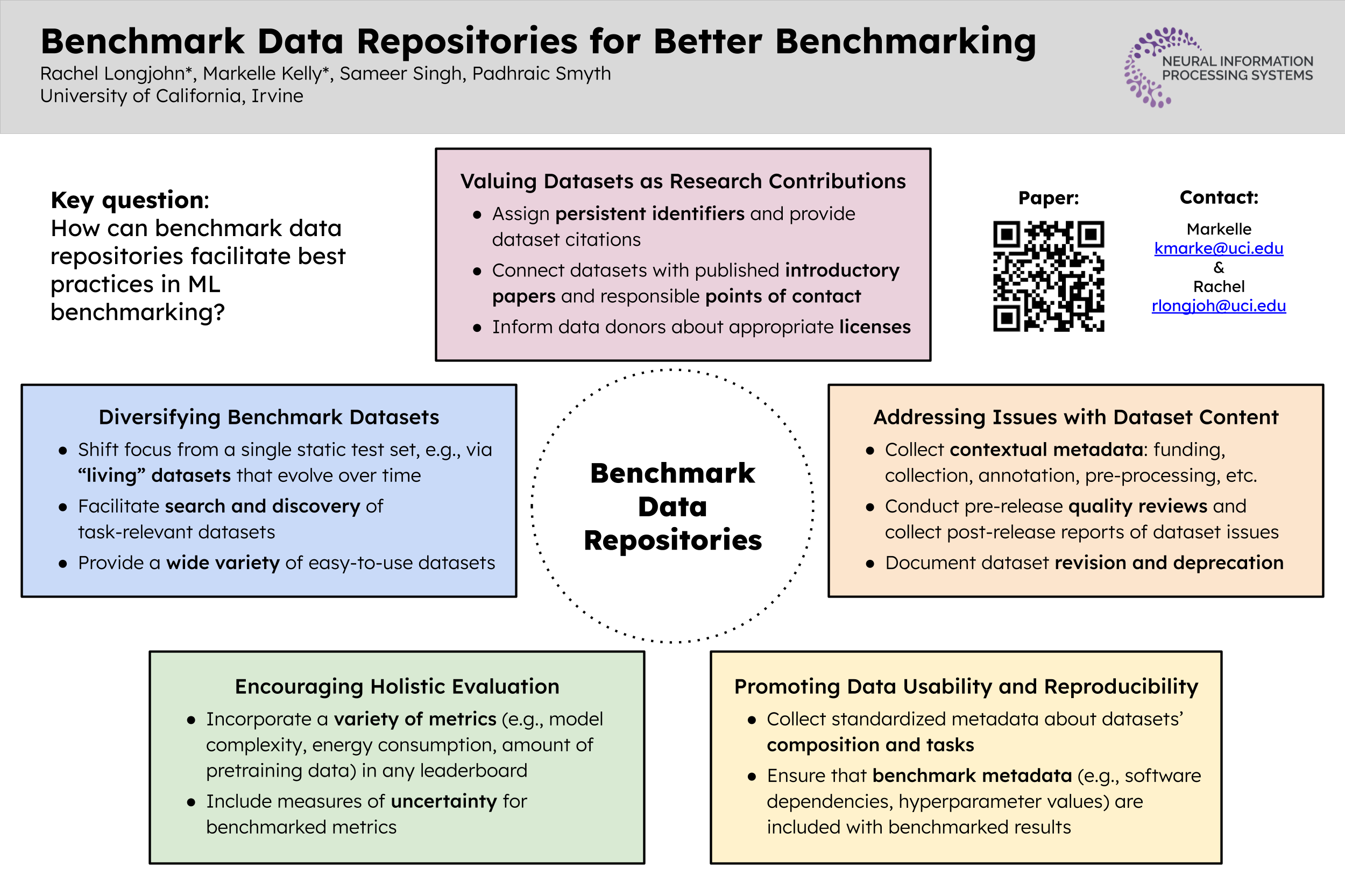
In machine learning research, it is common to evaluate algorithms via their performance on standard benchmark datasets. While a growing body of work establishes guidelines for---and levies criticisms at---data and benchmarking practices in machine learning, comparatively less attention has been paid to the data repositories where these datasets are stored, documented, and shared. In this paper, we analyze the landscape of these benchmark data repositories and the role they can play in improving benchmarking. This role includes addressing issues with both datasets themselves (e.g., representational harms, construct validity) and the manner in which evaluation is carried out using such datasets (e.g., overemphasis on a few datasets and metrics, lack of reproducibility). To this end, we identify and discuss a set of considerations surrounding the design and use of benchmark data repositories, with a focus on improving benchmarking practices in machine learning.