Poster
GenAI Arena: An Open Evaluation Platform for Generative Models
Dongfu Jiang · Max KU · Tianle Li · Yuansheng Ni · Shizhuo Sun · Rongqi Fan · Wenhu Chen
East Exhibit Hall A-C #1103
{kind=link}
Abstract:
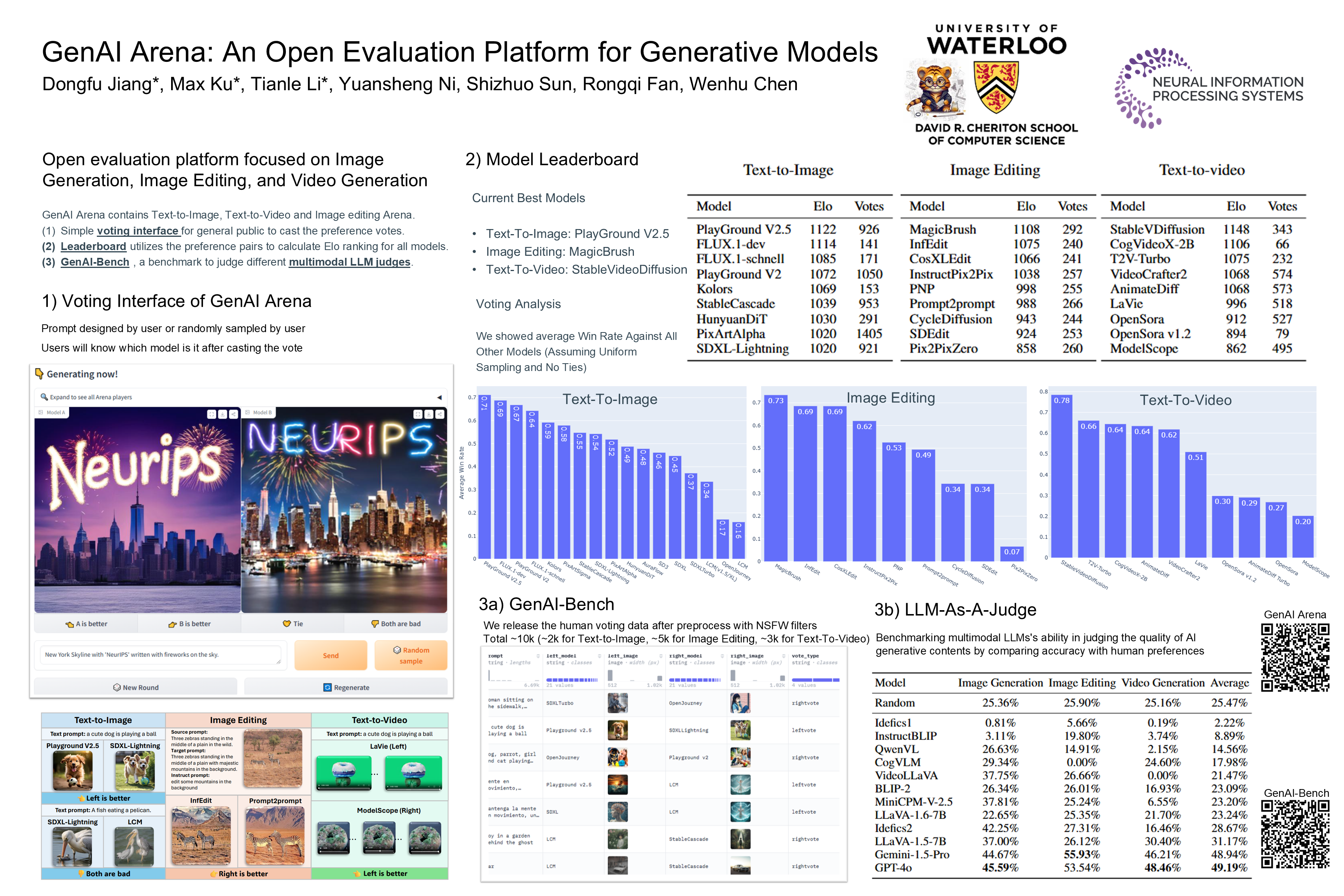
Generative AI has made remarkable strides to revolutionize fields such as image and video generation. These advancements are driven by innovative algorithms, architecture, and data. However, the rapid proliferation of generative models has highlighted a critical gap: the absence of trustworthy evaluation metrics. Current automatic assessments such as FID, CLIP, FVD, etc often fail to capture the nuanced quality and user satisfaction associated with generative outputs. This paper proposes an open platform GenAI-Arena to evaluate different image and video generative models, where users can actively participate in evaluating these models. By leveraging collective user feedback and votes, GenAI-Arena aims to provide a more democratic and accurate measure of model performance. It covers three tasks of text-to-image generation, text-to-video generation, and image editing respectively. Currently, we cover a total of 35 open-source generative models. GenAI-Arena has been operating for seven months, amassing over 9000 votes from the community. We describe our platform, analyze the data, and explain the statistical methods for ranking the models. To further promote the research in building model-based evaluation metrics, we release a cleaned version of our preference data for the three tasks, namely GenAI-Bench. We prompt the existing multi-modal models like Gemini, and GPT-4o to mimic human voting. We compute the accuracy by comparing the model voting with the human voting to understand their judging abilities. Our results show existing multimodal models are still lagging in assessing the generated visual content, even the best model GPT-4o only achieves an average accuracy of $49.19\%$ across the three generative tasks. Open-source MLLMs perform even worse due to the lack of instruction-following and reasoning ability in complex vision scenarios.
Chat is not available.