Spotlight Poster
A Unified Debiasing Approach for Vision-Language Models across Modalities and Tasks
Hoin Jung · Taeuk Jang · Xiaoqian Wang
East Exhibit Hall A-C #4005
{kind=link}
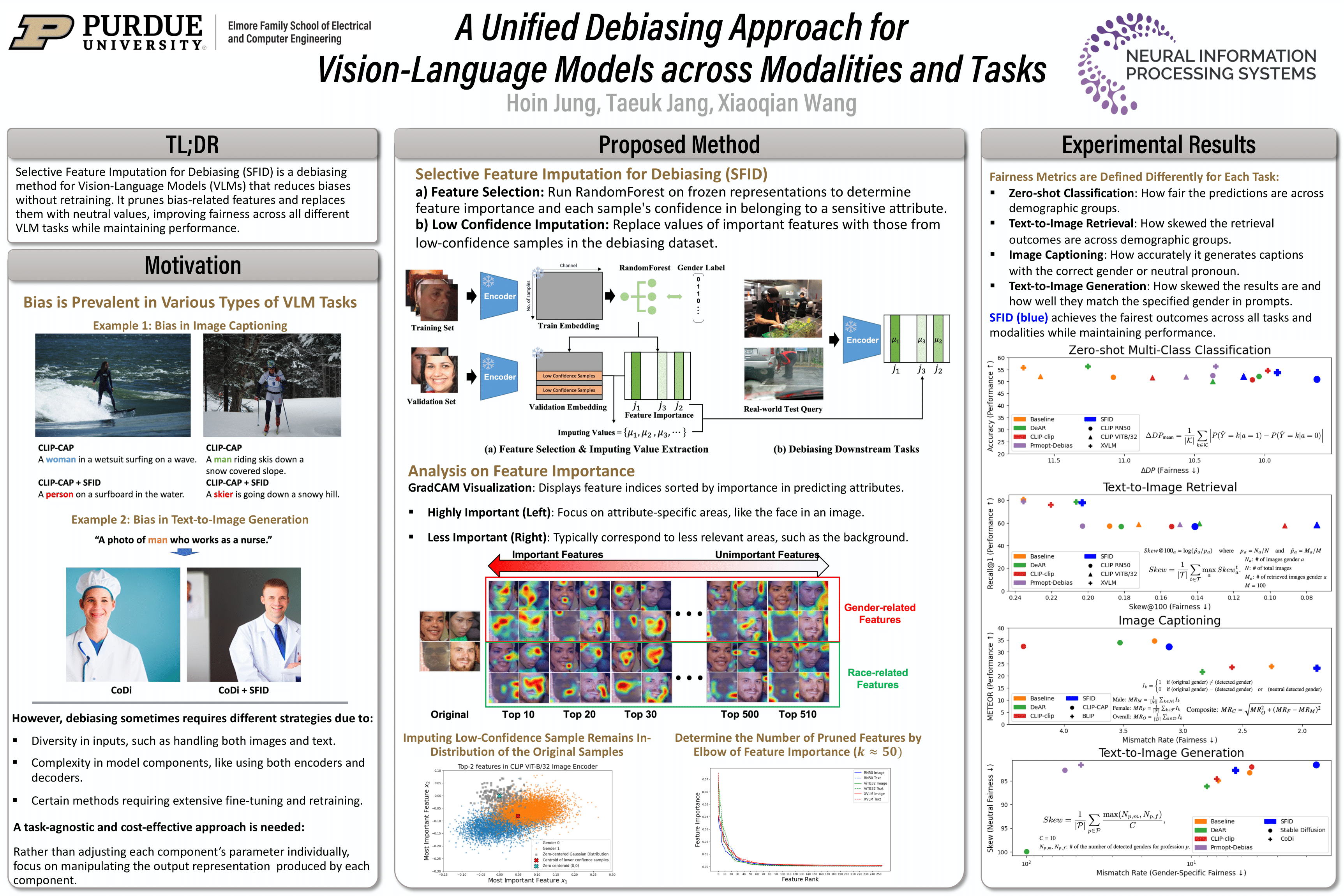
Recent advancements in Vision-Language Models (VLMs) have enabled complex multimodal tasks by processing text and image data simultaneously, significantly enhancing the field of artificial intelligence. However, these models often exhibit biases that can skew outputs towards societal stereotypes, thus necessitating debiasing strategies. Existing debiasing methods focus narrowly on specific modalities or tasks, and require extensive retraining. To address these limitations, this paper introduces Selective Feature Imputation for Debiasing (SFID), a novel methodology that integrates feature pruning and low confidence imputation (LCI) to effectively reduce biases in VLMs. SFID is versatile, maintaining the semantic integrity of outputs and costly effective by eliminating the need for retraining. Our experimental results demonstrate SFID's effectiveness across various VLMs tasks including zero-shot classification, text-to-image retrieval, image captioning, and text-to-image generation, by significantly reducing gender biases without compromising performance. This approach not only enhances the fairness of VLMs applications but also preserves their efficiency and utility across diverse scenarios.