Spotlight Poster
Rethinking Exploration in Reinforcement Learning with Effective Metric-Based Exploration Bonus
Yiming Wang · Kaiyan Zhao · Furui Liu · Leong Hou U
West Ballroom A-D #7006
{kind=link}
Abstract:
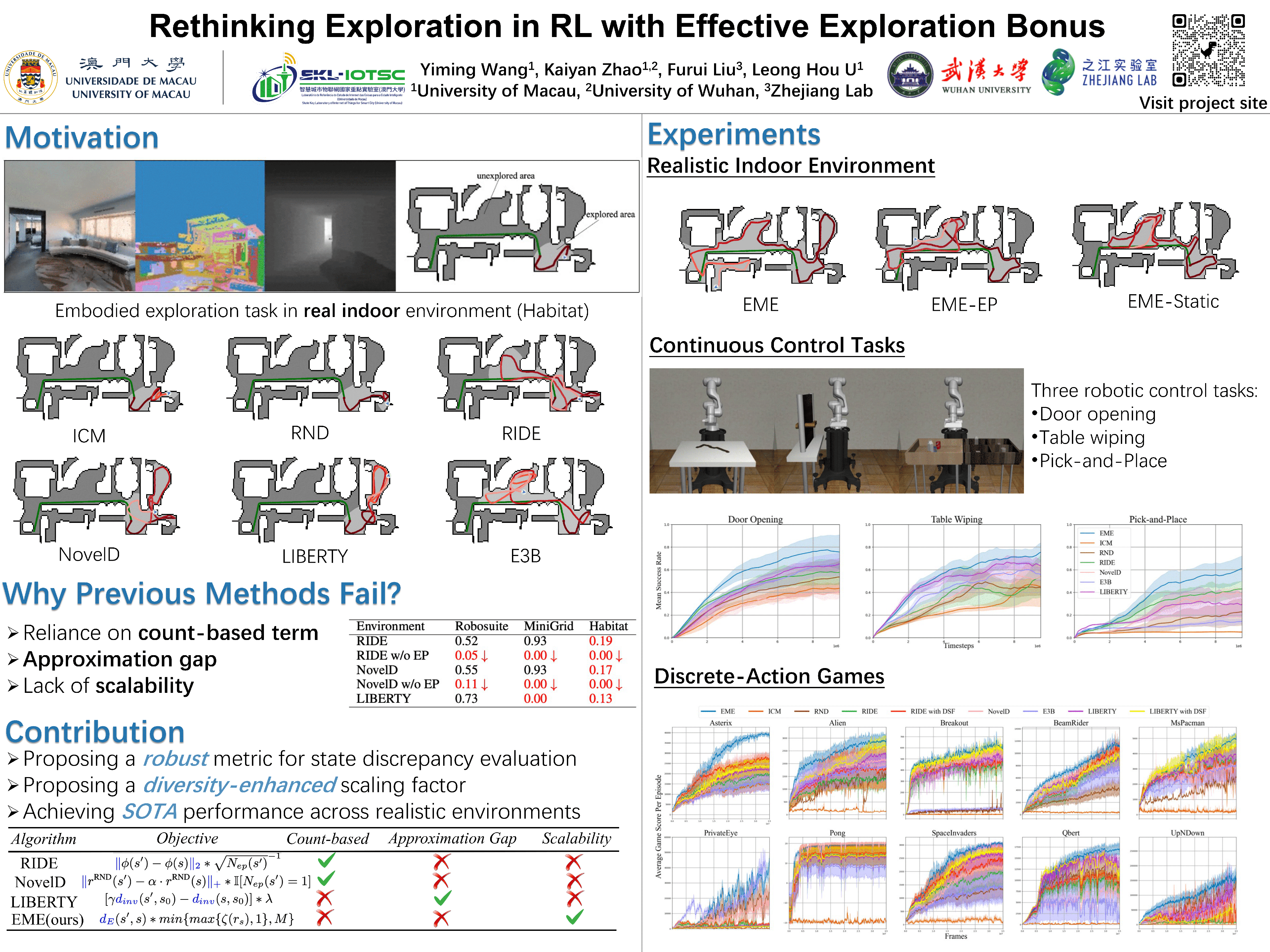
Enhancing exploration in reinforcement learning (RL) through the incorporation of intrinsic rewards, specifically by leveraging *state discrepancy* measures within various metric spaces as exploration bonuses, has emerged as a prevalent strategy to encourage agents to visit novel states. The critical factor lies in how to quantify the difference between adjacent states as *novelty* for promoting effective exploration.Nonetheless, existing methods that evaluate state discrepancy in the latent space under $L_1$ or $L_2$ norm often depend on count-based episodic terms as scaling factors for exploration bonuses, significantly limiting their scalability. Additionally, methods that utilize the bisimulation metric for evaluating state discrepancies face a theory-practice gap due to improper approximations in metric learning, particularly struggling with *hard exploration* tasks. To overcome these challenges, we introduce the **E**ffective **M**etric-based **E**xploration-bonus (EME). EME critically examines and addresses the inherent limitations and approximation inaccuracies of current metric-based state discrepancy methods for exploration, proposing a robust metric for state discrepancy evaluation backed by comprehensive theoretical analysis. Furthermore, we propose the diversity-enhanced scaling factor integrated into the exploration bonus to be dynamically adjusted by the variance of prediction from an ensemble of reward models, thereby enhancing exploration effectiveness in particularly challenging scenarios. Extensive experiments are conducted on hard exploration tasks within Atari games, Minigrid, Robosuite, and Habitat, which illustrate our method's scalability to various scenarios. The project website can be found at https://sites.google.com/view/effective-metric-exploration.
Chat is not available.