Spotlight Poster
EMR-Merging: Tuning-Free High-Performance Model Merging
Chenyu Huang · Peng Ye · Tao Chen · Tong He · Xiangyu Yue · Wanli Ouyang
East Exhibit Hall A-C #3600
{kind=link}
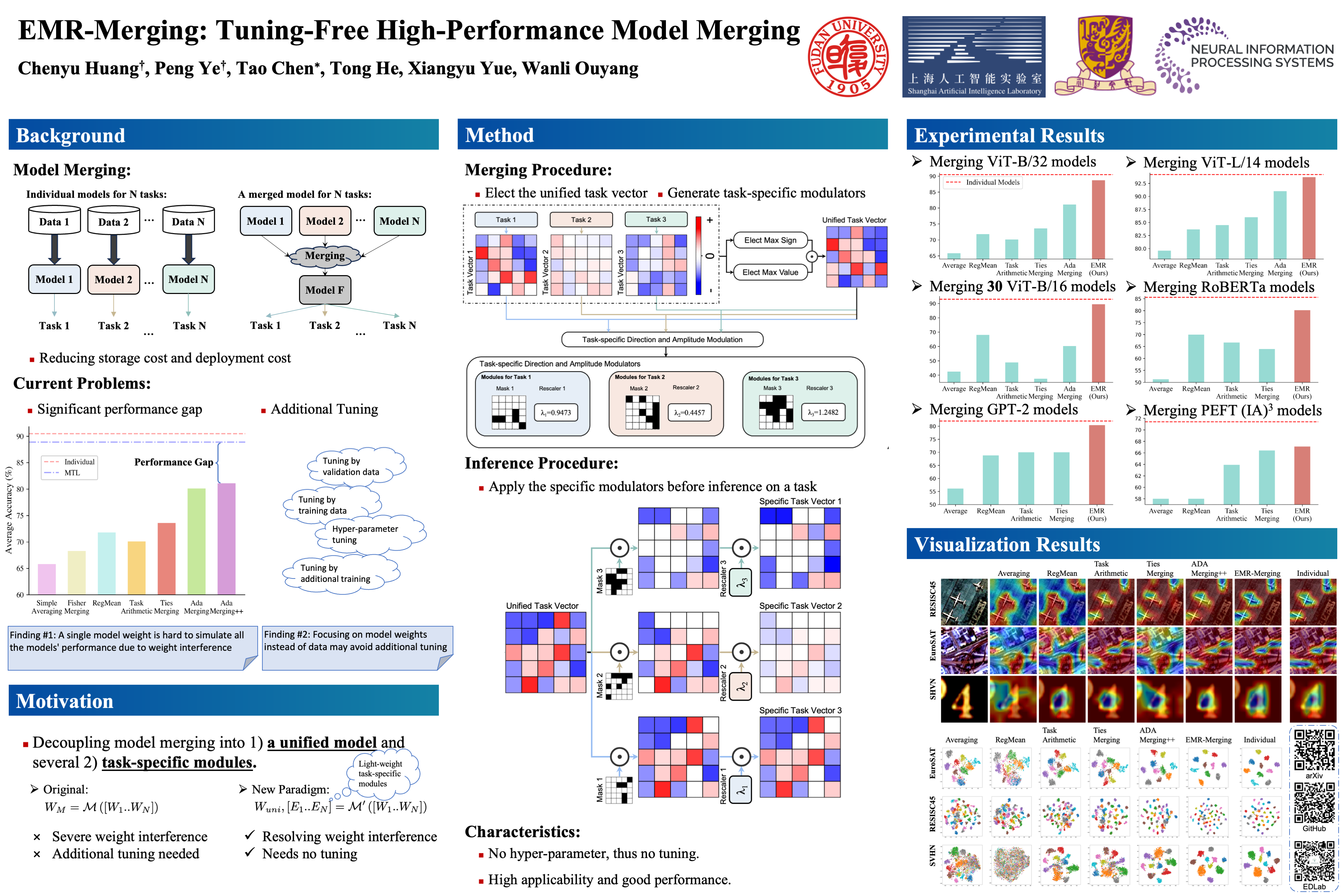
The success of pretrain-finetune paradigm brings about the release of numerous model weights. In this case, merging models finetuned on different tasks to enable a single model with multi-task capabilities is gaining increasing attention for its practicability. Existing model merging methods usually suffer from (1) significant performance degradation or (2) requiring tuning by additional data or training. In this paper, we rethink and analyze the existing model merging paradigm. We discover that using a single model's weights can hardly simulate all the models' performance. To tackle this issue, we propose Elect, Mask & Rescale-Merging (EMR-Merging). We first (a) elect a unified model from all the model weights and then (b) generate extremely lightweight task-specific modulators, including masks and rescalers, to align the direction and magnitude between the unified model and each specific model, respectively. EMR-Merging is tuning-free, thus requiring no data availability or any additional training while showing impressive performance. We find that EMR-Merging shows outstanding performance compared to existing merging methods under different classical and newly-established settings, including merging different numbers of vision models (up to 30), NLP models, PEFT models, and multi-modal models.