[ La Nouvelle Orleans Ballroom A-C (level 2) ]
Abstract
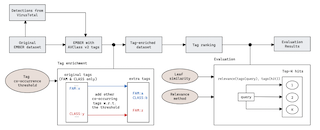
Large language models (LLMs) have shown promise in proving formal theorems using proof assistants such as Lean. However, existing methods are difficult to reproduce or build on, due to private code, data, and large compute requirements. This has created substantial barriers to research on machine learning methods for theorem proving. This paper removes these barriers by introducing LeanDojo: an open-source Lean playground consisting of toolkits, data, models, and benchmarks. LeanDojo extracts data from Lean and enables interaction with the proof environment programmatically. It contains fine-grained annotations of premises in proofs, providing valuable data for premise selection—a key bottleneck in theorem proving. Using this data, we develop ReProver (Retrieval-Augmented Prover): an LLM-based prover augmented with retrieval for selecting premises from a vast math library. It is inexpensive and needs only one GPU week of training. Our retriever leverages LeanDojo's program analysis capability to identify accessible premises and hard negative examples, which makes retrieval much more effective. Furthermore, we construct a new benchmark consisting of 98,734 theorems and proofs extracted from Lean's math library. It features challenging data split requiring the prover to generalize to theorems relying on novel premises that are never used in training. We use this benchmark for training …
[ La Nouvelle Orleans Ballroom A-C (level 2) ]
Abstract
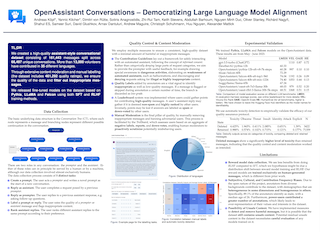
Aligning large language models (LLMs) with human preferences has proven to drastically improve usability and has driven rapid adoption as demonstrated by ChatGPT.Alignment techniques such as supervised fine-tuning (\textit{SFT}) and reinforcement learning from human feedback (\textit{RLHF}) greatly reduce the required skill and domain knowledge to effectively harness the capabilities of LLMs, increasing their accessibility and utility across various domains.However, state-of-the-art alignment techniques like \textit{RLHF} rely on high-quality human feedback data, which is expensive to create and often remains proprietary.In an effort to democratize research on large-scale alignment, we release OpenAssistant Conversations, a human-generated, human-annotated assistant-style conversation corpus consisting of 161,443 messages in 35 different languages, annotated with 461,292 quality ratings, resulting in over 10,000 complete and fully annotated conversation trees.The corpus is a product of a worldwide crowd-sourcing effort involving over 13,500 volunteers.Models trained on OpenAssistant Conversations show consistent improvements on standard benchmarks over respective base models.We release our code\footnote{\git} and data\footnote{\data} under a fully permissive licence.
[ La Nouvelle Orleans Ballroom A-C (level 2) ]
Abstract
Generative Pre-trained Transformer (GPT) models have exhibited exciting progress in capabilities, capturing the interest of practitioners and the public alike. Yet, while the literature on the trustworthiness of GPT models remains limited, practitioners have proposed employing capable GPT models for sensitive applications to healthcare and finance – where mistakes can be costly. To this end, this work proposes a comprehensive trustworthiness evaluation for large language models with a focus on GPT-4 and GPT-3.5, considering diverse perspectives – including toxicity, stereotype bias, adversarial robustness, out-of-distribution robustness, robustness on adversarial demonstrations, privacy, machine ethics, and fairness. Based on our evaluations, we discover previously unpublished vulnerabilities to trustworthiness threats. For instance, we find that GPT models can be easily misled to generate toxic and biased outputs and leak private information in both training data and conversation history. We also find that although GPT-4 is usually more trustworthy than GPT-3.5 on standard benchmarks, GPT-4 is more vulnerable given jailbreaking system or user prompts, potentially due to the reason that GPT-4 follows the (misleading) instructions more precisely. Our work illustrates a comprehensive trustworthiness evaluation of GPT models and sheds light on the trustworthiness gaps. Our benchmark is publicly available at https://decodingtrust.github.io/.
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
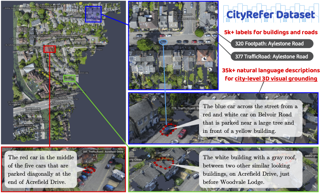
City-scale 3D point cloud is a promising way to express detailed and complicated outdoor structures. It encompasses both the appearance and geometry features of segmented city components, including cars, streets, and buildings that can be utilized for attractive applications such as user-interactive navigation of autonomous vehicles and drones. However, compared to the extensive text annotations available for images and indoor scenes, the scarcity of text annotations for outdoor scenes poses a significant challenge for achieving these applications. To tackle this problem, we introduce the CityRefer dataset for city-level visual grounding. The dataset consists of 35k natural language descriptions of 3D objects appearing in SensatUrban city scenes and 5k landmarks labels synchronizing with OpenStreetMap. To ensure the quality and accuracy of the dataset, all descriptions and labels in the CityRefer dataset are manually verified. We also have developed a baseline system that can learn encoded language descriptions, 3D object instances, and geographical information about the city's landmarks to perform visual grounding on the CityRefer dataset. To the best of our knowledge, the CityRefer dataset is the largest city-level visual grounding dataset for localizing specific 3D objects.
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
Aligning large language models (LLMs) with human preferences has proven to drastically improve usability and has driven rapid adoption as demonstrated by ChatGPT.Alignment techniques such as supervised fine-tuning (\textit{SFT}) and reinforcement learning from human feedback (\textit{RLHF}) greatly reduce the required skill and domain knowledge to effectively harness the capabilities of LLMs, increasing their accessibility and utility across various domains.However, state-of-the-art alignment techniques like \textit{RLHF} rely on high-quality human feedback data, which is expensive to create and often remains proprietary.In an effort to democratize research on large-scale alignment, we release OpenAssistant Conversations, a human-generated, human-annotated assistant-style conversation corpus consisting of 161,443 messages in 35 different languages, annotated with 461,292 quality ratings, resulting in over 10,000 complete and fully annotated conversation trees.The corpus is a product of a worldwide crowd-sourcing effort involving over 13,500 volunteers.Models trained on OpenAssistant Conversations show consistent improvements on standard benchmarks over respective base models.We release our code\footnote{\git} and data\footnote{\data} under a fully permissive licence.
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
Lifelong learning offers a promising paradigm of building a generalist agent that learns and adapts over its lifespan. Unlike traditional lifelong learning problems in image and text domains, which primarily involve the transfer of declarative knowledge of entities and concepts, lifelong learning in decision-making (LLDM) also necessitates the transfer of procedural knowledge, such as actions and behaviors. To advance research in LLDM, we introduce LIBERO, a novel benchmark of lifelong learning for robot manipulation. Specifically, LIBERO highlights five key research topics in LLDM: 1) how to efficiently transfer declarative knowledge, procedural knowledge, or the mixture of both; 2) how to design effective policy architectures and 3) effective algorithms for LLDM; 4) the robustness of a lifelong learner with respect to task ordering; and 5) the effect of model pretraining for LLDM. We develop an extendible procedural generation pipeline that can in principle generate infinitely many tasks. For benchmarking purpose, we create four task suites (130 tasks in total) that we use to investigate the above-mentioned research topics. To support sample-efficient learning, we provide high-quality human-teleoperated demonstration data for all tasks. Our extensive experiments present several insightful or even unexpected discoveries: sequential finetuning outperforms existing lifelong learning methods in forward transfer, …
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
Sampling in discrete spaces, with critical applications in simulation and optimization, has recently been boosted by significant advances in gradient-based approaches that exploit modern accelerators like GPUs. However, two key challenges are hindering further advancement in research on discrete sampling. First, since there is no consensus on experimental settings and evaluation setups, the empirical results in different research papers are often not comparable. Second, implementing samplers and target distributions often requires a nontrivial amount of effort in terms of calibration and parallelism. To tackle these challenges, we propose DISCS (DISCrete Sampling), a tailored package and benchmark that supports unified and efficient experiment implementation and evaluations for discrete sampling in three types of tasks: sampling from classical graphical models and energy based generative models, and sampling for solving combinatorial optimization. Throughout the comprehensive evaluations in DISCS, we gained new insights into scalability, design principles for proposal distributions, and lessons for adaptive sampling design. DISCS efficiently implements representative discrete samplers in existing research works as baselines and offers a simple interface that researchers can conveniently add new discrete samplers and directly compare their performance with the benchmark result in a calibrated setup.
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
Modeling customer shopping intentions is a crucial task for e-commerce, as it directly impacts user experience and engagement. Thus, accurately understanding customer preferences is essential for providing personalized recommendations. Session-based recommendation, which utilizes customer session data to predict their next interaction, has become increasingly popular. However, existing session datasets have limitations in terms of item attributes, user diversity, and dataset scale. As a result, they cannot comprehensively capture the spectrum of user behaviors and preferences.To bridge this gap, we present the Amazon Multilingual Multi-locale Shopping Session Dataset, namely Amazon-M2. It is the first multilingual dataset consisting of millions of user sessions from six different locales, where the major languages of products are English, German, Japanese, French, Italian, and Spanish.Remarkably, the dataset can help us enhance personalization and understanding of user preferences, which can benefit various existing tasks as well as enable new tasks. To test the potential of the dataset, we introduce three tasks in this work:(1) next-product recommendation, (2) next-product recommendation with domain shifts, and (3) next-product title generation.With the above tasks, we benchmark a range of algorithms on our proposed dataset, drawing new insights for further research and practice. In addition, based on the proposed dataset and tasks, …
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
Task-oriented dialogue (TOD) models have made significant progress in recent years. However, previous studies primarily focus on datasets written by annotators, which has resulted in a gap between academic research and real-world spoken con- versation scenarios. While several small-scale spoken TOD datasets are proposed to address robustness issues such as ASR errors, they ignore the unique challenges in spoken conversation. To tackle the limitations, we introduce SpokenWOZ, a large-scale speech-text dataset for spoken TOD, containing 8 domains, 203k turns, 5.7k dialogues and 249 hours of audios from human-to-human spoken conversations. SpokenWOZ further incorporates common spoken characteristics such as word-by-word processing and reasoning in spoken language. Based on these characteristics, we present cross-turn slot and reasoning slot detection as new challenges. We conduct experiments on various baselines, including text-modal models, newly proposed dual-modal models, and LLMs, e.g., ChatGPT. The results show that the current models still have substantial room for improvement in spoken conversation, where the most advanced dialogue state tracker only achieves 25.65% in joint goal accuracy and the SOTA end-to-end model only correctly completes the user request in 52.1% of dialogues. Our dataset, code, and leaderboard are available at https://spokenwoz.github.io/SpokenWOZ-github.io/.
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
It is well-known that modern computer vision systems often exhibit behaviors misaligned with those of humans: from adversarial attacks to image corruptions, deeplearning vision models suffer in a variety of settings that humans capably handle. Inlight of these phenomena, here we introduce another, orthogonal perspective studying the human-machine vision gap. We revisit the task of recovering images underdegradation, first introduced over 30 years ago in the Recognition-by-Componentstheory of human vision. Specifically, we study the performance and behavior ofneural networks on the seemingly simple task of classifying regular polygons atvarying orders of degradation along their perimeters. To this end, we implement theAutomated Shape Recoverability Testfor rapidly generating large-scale datasetsof perimeter-degraded regular polygons, modernizing the historically manual creation of image recoverability experiments. We then investigate the capacity ofneural networks to recognize and recover such degraded shapes when initializedwith different priors. Ultimately, we find that neural networks’ behavior on thissimple task conflicts with human behavior, raising a fundamental question of therobustness and learning capabilities of modern computer vision models
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
Code completion models have made significant progress in recent years, yet current popular evaluation datasets, such as HumanEval and MBPP, predominantly focus on code completion tasks within a single file. This over-simplified setting falls short of representing the real-world software development scenario where repositories span multiple files with numerous cross-file dependencies, and accessing and understanding cross-file context is often required to complete the code correctly. To fill in this gap, we propose CrossCodeEval, a diverse and multilingual code completion benchmark that necessitates an in-depth cross-file contextual understanding to complete the code accurately. CrossCodeEval is built on a diverse set of real-world, open-sourced, permissively-licensed repositories in four popular programming languages: Python, Java, TypeScript, and C#. To create examples that strictly require cross-file context for accurate completion, we propose a straightforward yet efficient static-analysis-based approach to pinpoint the use of cross-file context within the current file. Extensive experiments on state-of-the-art code language models like CodeGen and StarCoder demonstrate that CrossCodeEval is extremely challenging when the relevant cross-file context is absent, and we see clear improvements when adding these context into the prompt. However, despite such improvements, the pinnacle of performance remains notably unattained even with the highest-performing model, indicating that CrossCodeEval is …
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
The extraordinary ability of generative models to generate photographic images has intensified concerns about the spread of disinformation, thereby leading to the demand for detectors capable of distinguishing between AI-generated fake images and real images. However, the lack of large datasets containing images from the most advanced image generators poses an obstacle to the development of such detectors. In this paper, we introduce the GenImage dataset, which has the following advantages: 1) Plenty of Images, including over one million pairs of AI-generated fake images and collected real images. 2) Rich Image Content, encompassing a broad range of image classes. 3) State-of-the-art Generators, synthesizing images with advanced diffusion models and GANs. The aforementioned advantages allow the detectors trained on GenImage to undergo a thorough evaluation and demonstrate strong applicability to diverse images. We conduct a comprehensive analysis of the dataset and propose two tasks for evaluating the detection method in resembling real-world scenarios. The cross-generator image classification task measures the performance of a detector trained on one generator when tested on the others. The degraded image classification task assesses the capability of the detectors in handling degraded images such as low-resolution, blurred, and compressed images. With the GenImage dataset, researchers can …
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
Urban mobility analysis has been extensively studied in the past decade using a vast amount of GPS trajectory data, which reveals hidden patterns in movement and human activity within urban landscapes. Despite its significant value, the availability of such datasets often faces limitations due to privacy concerns, proprietary barriers, and quality inconsistencies. To address these challenges, this paper presents a synthetic trajectory dataset with high fidelity, offering a general solution to these data accessibility issues. Specifically, the proposed dataset adopts a diffusion model as its synthesizer, with the primary aim of accurately emulating the spatial-temporal behavior of the original trajectory data. These synthesized data can retain the geo-distribution and statistical properties characteristic of real-world datasets. Through rigorous analysis and case studies, we validate the high similarity and utility between the proposed synthetic trajectory dataset and real-world counterparts. Such validation underscores the practicality of synthetic datasets for urban mobility analysis and advocates for its wider acceptance within the research community. Finally, we publicly release the trajectory synthesizer and datasets, aiming to enhance the quality and availability of synthetic trajectory datasets and encourage continued contributions to this rapidly evolving field. The dataset is released for public online availability https://github.com/Applied-Machine-Learning-Lab/SynMob.
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
Despite impressive advances in object-recognition, deep learning systems’ performance degrades significantly across geographies and lower income levels---raising pressing concerns of inequity. Addressing such performance gaps remains a challenge, as little is understood about why performance degrades across incomes or geographies.We take a step in this direction by annotating images from Dollar Street, a popular benchmark of geographically and economically diverse images, labeling each image with factors such as color, shape, and background. These annotations unlock a new granular view into how objects differ across incomes/regions. We then use these object differences to pinpoint model vulnerabilities across incomes and regions.We study a range of modern vision models, finding that performance disparities are most associated with differences in texture, occlusion, and images with darker lighting.We illustrate how insights from our factor labels can surface mitigations to improve models' performance disparities.As an example, we show that mitigating a model's vulnerability to texture can improve performance on the lower income level.We release all the factor annotations along with an interactive dashboardto facilitate research into more equitable vision systems.
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
The radiology report is the main form of communication between radiologists and other clinicians. Prior work in natural language processing in radiology reports has shown the value of developing methods tailored for individual tasks such as identifying reports with critical results or disease detection. Meanwhile, English and biomedical natural language understanding benchmarks such as the General Language Understanding and Evaluation as well as Biomedical Language Understanding and Reasoning Benchmark have motivated the development of models that can be easily adapted to address many tasks in those domains. Here, we characterize the radiology report as a distinct domain and introduce RaLEs, the Radiology Language Evaluations, as a benchmark for natural language understanding and generation in radiology. RaLEs is comprised of seven natural language understanding and generation evaluations including the extraction of anatomical and disease entities and their relations, procedure selection, and report summarization. We characterize the performance of models designed for the general, biomedical, clinical and radiology domains across these tasks. We find that advances in the general and biomedical domains do not necessarily translate to radiology, and that improved models from the general domain can perform comparably to smaller clinical-specific models. The limited performance of existing pre-trained models on RaLEs …
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
We introduce OpenIllumination, a real-world dataset containing over 108K images of 64 objects with diverse materials, captured under 72 camera views and a large number of different illuminations. For each image in the dataset, we provide accurate camera parameters, illumination ground truth, and foreground segmentation masks. Our dataset enables the quantitative evaluation of most inverse rendering and material decomposition methods for real objects. We examine several state-of-the-art inverse rendering methods on our dataset and compare their performances. The dataset and code can be found on the project page: https://oppo-us-research.github.io/OpenIllumination.
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
False arrhythmia alarms in intensive care units (ICUs) are a continuing problem despite considerable effort from industrial and academic algorithm developers. Of all life-threatening arrhythmias, ventricular tachycardia (VT) stands out as the most challenging arrhythmia to detect reliably. We introduce a new annotated VT alarm database, VTaC (Ventricular Tachycardia annotated alarms from ICUs) consisting of over 5,000 waveform recordings with VT alarms triggered by bedside monitors in the ICU. Each VT alarm waveform in the dataset has been labeled by at least two independent human expert annotators. The dataset encompasses data collected from ICUs in two major US hospitals and includes data from three leading bedside monitor manufacturers, providing a diverse and representative collection of alarm waveform data. Each waveform recording comprises at least two electrocardiogram (ECG) leads and one or more pulsatile waveforms, such as photoplethysmogram (PPG or PLETH) and arterial blood pressure (ABP) waveforms. We demonstrate the utility of this new benchmark dataset for the task of false arrhythmia alarm reduction, and present performance of multiple machine learning approaches, including conventional supervised machine learning, deep learning, semi-supervised learning, and generative approaches for the task of VT false alarm reduction.
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
Annotating medical images, particularly for organ segmentation, is laborious and time-consuming. For example, annotating an abdominal organ requires an estimated rate of 30-60 minutes per CT volume based on the expertise of an annotator and the size, visibility, and complexity of the organ. Therefore, publicly available datasets for multi-organ segmentation are often limited in data size and organ diversity. This paper proposes an active learning procedure to expedite the annotation process for organ segmentation and creates the largest multi-organ dataset (by far) with the spleen, liver, kidneys, stomach, gallbladder, pancreas, aorta, and IVC annotated in 8,448 CT volumes, equating to 3.2 million slices. The conventional annotation methods would take an experienced annotator up to 1,600 weeks (or roughly 30.8 years) to complete this task. In contrast, our annotation procedure has accomplished this task in three weeks (based on an 8-hour workday, five days a week) while maintaining a similar or even better annotation quality. This achievement is attributed to three unique properties of our method: (1) label bias reduction using multiple pre-trained segmentation models, (2) effective error detection in the model predictions, and (3) attention guidance for annotators to make corrections on the most salient errors. Furthermore, we summarize the …
[ Great Hall & Hall B1+B2 (level 1) ]
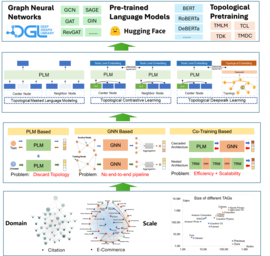
Abstract
Text-attributed graphs (TAGs) are prevalent in various real-world scenarios, where each node is associated with a text description. The cornerstone of representation learning on TAGs lies in the seamless integration of textual semantics within individual nodes and the topological connections across nodes. Recent advancements in pre-trained language models (PLMs) and graph neural networks (GNNs) have facilitated effective learning on TAGs, garnering increased research interest. However, the absence of meaningful benchmark datasets and standardized evaluation procedures for TAGs has impeded progress in this field. In this paper, we propose CS-TAG, a comprehensive and diverse collection of challenging benchmark datasets for TAGs. The CS-TAG datasets are notably large in scale and encompass a wide range of domains, spanning from citation networks to purchase graphs. In addition to building the datasets, we conduct extensive benchmark experiments over CS-TAG with various learning paradigms, including PLMs, GNNs, PLM-GNN co-training methods, and the proposed novel topological pre-training of language models. In a nutshell, we provide an overview of the CS-TAG datasets, standardized evaluation procedures, and present baseline experiments. The entire CS-TAG project is publicly accessible at \url{https://github.com/sktsherlock/TAG-Benchmark}.
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
Generating video stories from text prompts is a complex task. In addition to having high visual quality, videos need to realistically adhere to a sequence of text prompts whilst being consistent throughout the frames. Creating a benchmark for video generation requires data annotated over time, which contrasts with the single caption used often in video datasets. To fill this gap, we collect comprehensive human annotations on three existing datasets, and introduce StoryBench: a new, challenging multi-task benchmark to reliably evaluate forthcoming text-to-video models. Our benchmark includes three video generation tasks of increasing difficulty: action execution, where the next action must be generated starting from a conditioning video; story continuation, where a sequence of actions must be executed starting from a conditioning video; and story generation, where a video must be generated from only text prompts. We evaluate small yet strong text-to-video baselines, and show the benefits of training on story-like data algorithmically generated from existing video captions. Finally, we establish guidelines for human evaluation of video stories, and reaffirm the need of better automatic metrics for video generation. StoryBench aims at encouraging future research efforts in this exciting new area.
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
The development of foundation vision models has pushed the general visual recognition to a high level, but cannot well address the fine-grained recognition in specialized domain such as invasive species classification. Identifying and managing invasive species has strong social and ecological value. Currently, most invasive species datasets are limited in scale and cover a narrow range of species, which restricts the development of deep-learning based invasion biometrics systems. To fill the gap of this area, we introduced Species196, a large-scale semi-supervised dataset of 196-category invasive species. It collects over 19K images with expert-level accurate annotations (Species196-L), and 1.2M unlabeled images of invasive species (Species196-U). The dataset provides four experimental settings for benchmarking the existing models and algorithms, namely, supervised learning, semi-supervised learning and self-supervised pretraining. To facilitate future research on these four learning paradigms, we conduct an empirical study of the representative methods on the introduced dataset. The dataset will be made publicly available at https://species-dataset.github.io/.
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
In this work we explore recent advances in instruction-tuning language models on a range of open instruction-following datasets. Despite recent claims that open models can be on par with state-of-the-art proprietary models, these claims are often accompanied by limited evaluation, making it difficult to compare models across the board and determine the utility of various resources. We provide a large set of instruction-tuned models from 6.7B to 65B parameters in size, trained on 12 instruction datasets ranging from manually curated (e.g., OpenAssistant) to synthetic and distilled (e.g., Alpaca) and systematically evaluate them on their factual knowledge, reasoning, multilinguality, coding, safety, and open-ended instruction following abilities through a collection of automatic, model-based, and human-based metrics. We further introduce Tülu, our best performing instruction-tuned model suite finetuned on a combination of high-quality open resources.Our experiments show that different instruction-tuning datasets can uncover or enhance specific skills, while no single dataset (or combination) provides the best performance across all evaluations. Interestingly, we find that model and human preference-based evaluations fail to reflect differences in model capabilities exposed by benchmark-based evaluations, suggesting the need for the type of systemic evaluation performed in this work. Our evaluations show that the best model in any given …
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
Tracking an arbitrary moving target in a video sequence is the foundation for high-level tasks like video understanding. Although existing visual-based trackers have demonstrated good tracking capabilities in short video sequences, they always perform poorly in complex environments, as represented by the recently proposed global instance tracking task, which consists of longer videos with more complicated narrative content. Recently, several works have introduced natural language into object tracking, desiring to address the limitations of relying only on a single visual modality. However, these selected videos are still short sequences with uncomplicated spatio-temporal and causal relationships, and the provided semantic descriptions are too simple to characterize video content.To address these issues, we (1) first propose a new multi-modal global instance tracking benchmark named MGIT. It consists of 150 long video sequences with a total of 2.03 million frames, aiming to fully represent the complex spatio-temporal and causal relationships coupled in longer narrative content. (2) Each video sequence is annotated with three semantic grains (i.e., action, activity, and story) to model the progressive process of human cognition. We expect this multi-granular annotation strategy can provide a favorable environment for multi-modal object tracking research and long video understanding. (3) Besides, we execute comparative …
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
In the field of phase change phenomena, the lack of accessible and diverse datasets suitable for machine learning (ML) training poses a significant challenge. Existing experimental datasets are often restricted, with limited availability and sparse ground truth, impeding our understanding of this complex multiphysics phenomena. To bridge this gap, we present the BubbleML dataset which leverages physics-driven simulations to provide accurate ground truth information for various boiling scenarios, encompassing nucleate pool boiling, flow boiling, and sub-cooled boiling. This extensive dataset covers a wide range of parameters, including varying gravity conditions, flow rates, sub-cooling levels, and wall superheat, comprising 79 simulations. BubbleML is validated against experimental observations and trends, establishing it as an invaluable resource for ML research. Furthermore, we showcase its potential to facilitate the exploration of diverse downstream tasks by introducing two benchmarks: (a) optical flow analysis to capture bubble dynamics, and (b) neural PDE solvers for learning temperature and flow dynamics. The BubbleML dataset and its benchmarks aim to catalyze progress in ML-driven research on multiphysics phase change phenomena, providing robust baselines for the development and comparison of state-of-the-art techniques and models.
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
Large-scale driving datasets such as Waymo Open Dataset and nuScenes substantially accelerate autonomous driving research, especially for perception tasks such as 3D detection and trajectory forecasting. Since the driving logs in these datasets contain HD maps and detailed object annotations which accurately reflect the real-world complexity of traffic behaviors, we can harvest a massive number of complex traffic scenarios and recreate their digital twins in simulation. Compared to the hand-crafted scenarios often used in existing simulators, data-driven scenarios collected from the real world can facilitate many research opportunities in machine learning and autonomous driving. In this work, we present ScenarioNet, an open-source platform for large-scale traffic scenario modeling and simulation. ScenarioNet defines a unified scenario description format and collects a large-scale repository of real-world traffic scenarios from the heterogeneous data in various driving datasets including Waymo, nuScenes, Lyft L5, and nuPlan datasets. These scenarios can be further replayed and interacted with in multiple views from Bird-Eye-View layout to realistic 3D rendering in MetaDrive simulator. This provides a benchmark for evaluating the safety of autonomous driving stacks in simulation before their real-world deployment. We further demonstrate the strengths of ScenarioNet on large-scale scenario generation, imitation learning, and reinforcement learning in both …
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
Machine learning research has long focused on models rather than datasets, and prominent datasets are used for common ML tasks without regard to the breadth, difficulty, and faithfulness of the underlying problems. Neglecting the fundamental importance of data has given rise to inaccuracy, bias, and fragility in real-world applications, and research is hindered by saturation across existing dataset benchmarks. In response, we present DataPerf, a community-led benchmark suite for evaluating ML datasets and data-centric algorithms. We aim to foster innovation in data-centric AI through competition, comparability, and reproducibility. We enable the ML community to iterate on datasets, instead of just architectures, and we provide an open, online platform with multiple rounds of challenges to support this iterative development. The first iteration of DataPerf contains five benchmarks covering a wide spectrum of data-centric techniques, tasks, and modalities in vision, speech, acquisition, debugging, and diffusion prompting, and we support hosting new contributed benchmarks from the community. The benchmarks, online evaluation platform, and baseline implementations are open source, and the MLCommons Association will maintain DataPerf to ensure long-term benefits to academia and industry.
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
The lack of standardized benchmarks for reinforcement learning (RL) in sustainability applications has made it difficult to both track progress on specific domains and identify bottlenecks for researchers to focus their efforts. In this paper, we present SustainGym, a suite of five environments designed to test the performance of RL algorithms on realistic sustainable energy system tasks, ranging from electric vehicle charging to carbon-aware data center job scheduling. The environments test RL algorithms under realistic distribution shifts as well as in multi-agent settings. We show that standard off-the-shelf RL algorithms leave significant room for improving performance and highlight the challenges ahead for introducing RL to real-world sustainability tasks.
[ Great Hall & Hall B1+B2 (level 1) ]
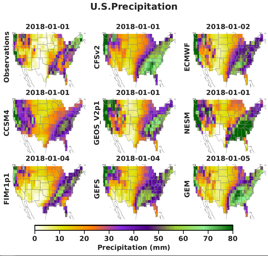
Abstract
Subseasonal forecasting of the weather two to six weeks in advance is critical for resource allocation and climate adaptation but poses many challenges for the forecasting community. At this forecast horizon, physics-based dynamical models have limited skill, and the targets for prediction depend in a complex manner on both local weather variables and global climate variables. Recently, machine learning methods have shown promise in advancing the state of the art but only at the cost of complex data curation, integrating expert knowledge with aggregation across multiple relevant data sources, file formats, and temporal and spatial resolutions.To streamline this process and accelerate future development, we introduce SubseasonalClimateUSA, a curated dataset for training and benchmarking subseasonal forecasting models in the United States. We use this dataset to benchmark a diverse suite of models, including operational dynamical models, classical meteorological baselines, and ten state-of-the-art machine learning and deep learning-based methods from the literature. Overall, our benchmarks suggest simple and effective ways to extend the accuracy of current operational models. SubseasonalClimateUSA is regularly updated and accessible via the https://github.com/microsoft/subseasonal_data/ Python package.
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
Climate models have been key for assessing the impact of climate change and simulating future climate scenarios. The machine learning (ML) community has taken an increased interest in supporting climate scientists’ efforts on various tasks such as climate model emulation, downscaling, and prediction tasks. Many of those tasks have been addressed on datasets created with single climate models. However, both the climate science and ML communities have suggested that to address those tasks at scale, we need large, consistent, and ML-ready climate model datasets. Here, we introduce ClimateSet, a dataset containing the inputs and outputs of 36 climate models from the Input4MIPs and CMIP6 archives. In addition, we provide a modular dataset pipeline for retrieving and preprocessing additional climate models and scenarios. We showcase the potential of our dataset by using it as a benchmark for ML-based climate model emulation. We gain new insights about the performance and generalization capabilities of the different ML models by analyzing their performance across different climate models. Furthermore, the dataset can be used to train an ML emulator on several climate models instead of just one. Such a “super emulator” can quickly project new climate change scenarios, complementing existing scenarios already provided to policymakers. …
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
Despite the stunning ability to generate high-quality images by recent text-to-image models, current approaches often struggle to effectively compose objects with different attributes and relationships into a complex and coherent scene. We propose T2I-CompBench, a comprehensive benchmark for open-world compositional text-to-image generation, consisting of 6,000 compositional text prompts from 3 categories (attribute binding, object relationships, and complex compositions) and 6 sub-categories (color binding, shape binding, texture binding, spatial relationships, non-spatial relationships, and complex compositions). We further propose several evaluation metrics specifically designed to evaluate compositional text-to-image generation and explore the potential and limitations of multimodal LLMs for evaluation. We introduce a new approach, Generative mOdel finetuning with Reward-driven Sample selection (GORS), to boost the compositional text-to-image generation abilities of pretrained text-to-image models. Extensive experiments and evaluations are conducted to benchmark previous methods on T2I-CompBench, and to validate the effectiveness of our proposed evaluation metrics and GORS approach. Project page is available at https://karine-h.github.io/T2I-CompBench/.
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
Accessible high-quality data is the bread and butter of machine learning research, and the demand for data has exploded as larger and more advanced ML models are built across different domains. Yet, real data often contain sensitive information, are subject to various biases, and are costly to acquire, which compromise their quality and accessibility. Synthetic data have thus emerged as a complement to, sometimes even a replacement for, real data for ML training. However, the landscape of synthetic data research has been fragmented due to the diverse range of data modalities, such as tabular, time series, and images, and the wide array of use cases, including privacy preservation, fairness considerations, and data augmentation. This fragmentation poses practical challenges when comparing and selecting synthetic data generators in for different problem settings. To this end, we develop Synthcity, an open-source Python library that allows researchers and practitioners to perform one-click benchmarking of synthetic data generators across data modalities and use cases. Beyond benchmarking, Synthcity serves as a centralized toolkit for accessing cutting-edge data generators. In addition, Synthcity’s flexible plug-in style API makes it easy to incorporate additional data generators into the framework. Using examples of tabular data generation and data augmentation, we …
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
Electronic Health Records (EHRs), which contain patients' medical histories in various multi-modal formats, often overlook the potential for joint reasoning across imaging and table modalities underexplored in current EHR Question Answering (QA) systems. In this paper, we introduce EHRXQA, a novel multi-modal question answering dataset combining structured EHRs and chest X-ray images. To develop our dataset, we first construct two uni-modal resources: 1) The MIMIC- CXR-VQA dataset, our newly created medical visual question answering (VQA) benchmark, specifically designed to augment the imaging modality in EHR QA, and 2) EHRSQL (MIMIC-IV), a refashioned version of a previously established table-based EHR QA dataset. By integrating these two uni-modal resources, we successfully construct a multi-modal EHR QA dataset that necessitates both uni-modal and cross-modal reasoning. To address the unique challenges of multi-modal questions within EHRs, we propose a NeuralSQL-based strategy equipped with an external VQA API. This pioneering endeavor enhances engagement with multi-modal EHR sources and we believe that our dataset can catalyze advances in real-world medical scenarios such as clinical decision-making and research. EHRXQA is available at https://github.com/baeseongsu/ehrxqa.
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
As machine learning-enabled Text-to-Image (TTI) systems are becoming increasingly prevalent and seeing growing adoption as commercial services, characterizing the social biases they exhibit is a necessary first step to lowering their risk of discriminatory outcomes. This evaluation, however, is made more difficult by the synthetic nature of these systems’ outputs: common definitions of diversity are grounded in social categories of people living in the world, whereas the artificial depictions of fictive humans created by these systems have no inherent gender or ethnicity. To address this need, we propose a new method for exploring the social biases in TTI systems. Our approach relies on characterizing the variation in generated images triggered by enumerating gender and ethnicity markers in the prompts, and comparing it to the variation engendered by spanning different professions. This allows us to (1) identify specific bias trends, (2) provide targeted scores to directly compare models in terms of diversity and representation, and (3) jointly model interdependent social variables to support a multidimensional analysis. We leverage this method to analyze images generated by 3 popular TTI systems (Dall·E 2 , Stable Diffusion v 1.4 and 2) and find that while all of their outputs show correlations with US labor …
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
The human visual system can effortlessly recognize an object under different extrinsic factors such as lighting, object poses, and background, yet current computer vision systems often struggle with these variations. An important step to understanding and improving artificial vision systems is to measure image similarity purely based on intrinsic object properties that define object identity. This problem has been studied in the computer vision literature as re-identification, though mostly restricted to specific object categories such as people and cars. We propose to extend it to general object categories, exploring an image similarity metric based on object intrinsics. To benchmark such measurements, we collect the Common paired objects Under differenT Extrinsics (CUTE) dataset of 18, 000 images of 180 objects under different extrinsic factors such as lighting, poses, and imaging conditions. While existing methods such as LPIPS and CLIP scores do not measure object intrinsics well, we find that combining deep features learned from contrastive self-supervised learning with foreground filtering is a simple yet effective approach to approximating the similarity. We conduct an extensive survey of pre-trained features and foreground extraction methods to arrive at a strong baseline that best measures intrinsic object-centric image similarity among current methods. Finally, we demonstrate …
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
The advent of large language models (LLMs) and their adoption by the legal community has given rise to the question: what types of legal reasoning can LLMs perform? To enable greater study of this question, we present LegalBench: a collaboratively constructed legal reasoning benchmark consisting of 162 tasks covering six different types of legal reasoning. LegalBench was built through an interdisciplinary process, in which we collected tasks designed and hand-crafted by legal professionals. Because these subject matter experts took a leading role in construction, tasks either measure legal reasoning capabilities that are practically useful, or measure reasoning skills that lawyers find interesting. To enable cross-disciplinary conversations about LLMs in the law, we additionally show how popular legal frameworks for describing legal reasoning—which distinguish between its many forms—correspond to LegalBench tasks, thus giving lawyers and LLM developers a common vocabulary. This paper describes LegalBench, presents an empirical evaluation of 20 open-source and commercial LLMs, and illustrates the types of research explorations LegalBench enables.
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
Recognizing and organizing text in correct reading order plays a crucial role in historical document analysis and preservation. While existing methods have shown promising performance, they often struggle with challenges such as diverse layouts, low image quality, style variations, and distortions. This is primarily due to the lack of consideration for these issues in the current benchmarks, which hinders the development and evaluation of historical document analysis and recognition (HDAR) methods in complex real-world scenarios. To address this gap, this paper introduces a complex multi-style Chinese historical document analysis benchmark, named M5HisDoc. The M5 indicates five properties of style, ie., Multiple layouts, Multiple document types, Multiple calligraphy styles, Multiple backgrounds, and Multiple challenges. The M5HisDoc dataset consists of two subsets, M5HisDoc-R (Regular) and M5HisDoc-H (Hard). The M5HisDoc-R subset comprises 4,000 historical document images. To ensure high-quality annotations, we meticulously perform manual annotation and triple-checking. To replicate real-world conditions for historical document analysis applications, we incorporate image rotation, distortion, and resolution reduction into M5HisDoc-R subset to form a new challenging subset named M5HisDoc-H, which contains the same number of images as M5HisDoc-R. The dataset exhibits diverse styles, significant scale variations, dense texts, and an extensive character set. We conduct benchmarking experiments …
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
We introduce VisIT-Bench (Visual InsTruction Benchmark), a benchmark for evaluating instruction-following vision-language models for real-world use. Our starting point is curating 70 "instruction families" that we envision instruction tuned vision-language models should be able to address. Extending beyond evaluations like VQAv2 and COCO, tasks range from basic recognition to game playing and creative generation. Following curation, our dataset comprises 592 test queries, each with a human-authored instruction-conditioned caption. These descriptions surface instruction-specific factors, e.g., for an instruction asking about the accessibility of a storefront for wheelchair users, the instruction-conditioned caption describes ramps/potential obstacles. These descriptions enable 1) collecting human-verified reference outputs for each instance; and 2) automatic evaluation of candidate multimodal generations using a text-only LLM, aligning with human judgment. We quantify quality gaps between models and references using both human and automatic evaluations; e.g., the top-performing instruction-following model wins against the GPT-4 reference in just 27% of the comparison. VisIT-Bench is dynamic to participate, practitioners simply submit their model's response on the project website; Data, code and leaderboard is available at https://visit-bench.github.io/.
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
The Landsat program is the longest-running Earth observation program in history, with 50+ years of data acquisition by 8 satellites. The multispectral imagery captured by sensors onboard these satellites is critical for a wide range of scientific fields. Despite the increasing popularity of deep learning and remote sensing, the majority of researchers still use decision trees and random forests for Landsat image analysis due to the prevalence of small labeled datasets and lack of foundation models. In this paper, we introduce SSL4EO-L, the first ever dataset designed for Self-Supervised Learning for Earth Observation for the Landsat family of satellites (including 3 sensors and 2 product levels) and the largest Landsat dataset in history (5M image patches). Additionally, we modernize and re-release the L7 Irish and L8 Biome cloud detection datasets, and introduce the first ML benchmark datasets for Landsats 4–5 TM and Landsat 7 ETM+ SR. Finally, we pre-train the first foundation models for Landsat imagery using SSL4EO-L and evaluate their performance on multiple semantic segmentation tasks. All datasets and model weights are available via the TorchGeo library, making reproducibility and experimentation easy, and enabling scientific advancements in the burgeoning field of remote sensing for a multitude of downstream applications.
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
Road traffic forecasting plays a critical role in smart city initiatives and has experienced significant advancements thanks to the power of deep learning in capturing non-linear patterns of traffic data. However, the promising results achieved on current public datasets may not be applicable to practical scenarios due to limitations within these datasets. First, the limited sizes of them may not reflect the real-world scale of traffic networks. Second, the temporal coverage of these datasets is typically short, posing hurdles in studying long-term patterns and acquiring sufficient samples for training deep models. Third, these datasets often lack adequate metadata for sensors, which compromises the reliability and interpretability of the data. To mitigate these limitations, we introduce the LargeST benchmark dataset. It encompasses a total number of 8,600 sensors in California with a 5-year time coverage and includes comprehensive metadata. Using LargeST, we perform in-depth data analysis to extract data insights, benchmark well-known baselines in terms of their performance and efficiency, and identify challenges as well as opportunities for future research. We release the datasets and baseline implementations at: https://github.com/liuxu77/LargeST.
[ Great Hall & Hall B1+B2 (level 1) ]
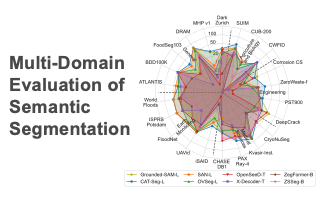
Abstract
While semantic segmentation has seen tremendous improvements in the past, there are still significant labeling efforts necessary and the problem of limited generalization to classes that have not been present during training. To address this problem, zero-shot semantic segmentation makes use of large self-supervised vision-language models, allowing zero-shot transfer to unseen classes. In this work, we build a benchmark for Multi-domain Evaluation of Zero-Shot Semantic Segmentation (MESS), which allows a holistic analysis of performance across a wide range of domain-specific datasets such as medicine, engineering, earth monitoring, biology, and agriculture. To do this, we reviewed 120 datasets, developed a taxonomy, and classified the datasets according to the developed taxonomy. We select a representative subset consisting of 22 datasets and propose it as the MESS benchmark. We evaluate eight recently published models on the proposed MESS benchmark and analyze characteristics for the performance of zero-shot transfer models. The toolkit is available at https://github.com/blumenstiel/MESS.
[ Great Hall & Hall B1+B2 (level 1) ]
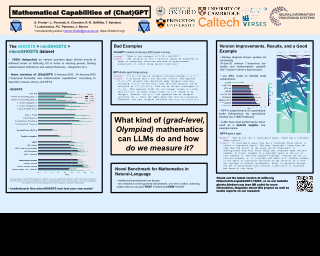
Abstract
We investigate the mathematical capabilities of two iterations of ChatGPT (released 9-January-2023 and 30-January-2023) and of GPT-4 by testing them on publicly available datasets, as well as hand-crafted ones, using a novel methodology. In contrast to formal mathematics, where large databases of formal proofs are available (e.g., mathlib, the Lean Mathematical Library), current datasets of natural-language mathematics used to benchmark language models either cover only elementary mathematics or are very small. We address this by publicly releasing two new datasets: GHOSTS and miniGHOSTS. These are the first natural-language datasets curated by working researchers in mathematics that (1) aim to cover graduate-level mathematics, (2) provide a holistic overview of the mathematical capabilities of language models, and (3) distinguish multiple dimensions of mathematical reasoning. These datasets test on 1636 human expert evaluations whether ChatGPT and GPT-4 can be helpful assistants to professional mathematicians by emulating use cases that arise in the daily professional activities of mathematicians. We benchmark the models on a range of fine-grained performance metrics. For advanced mathematics, this is the most detailed evaluation effort to date. We find that ChatGPT and GPT-4 can be used most successfully as mathematical assistants for querying facts, acting as mathematical search engines and …
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
Massive web datasets play a key role in the success of large vision-language models like CLIP and Flamingo. However, the raw web data is noisy, and existing filtering methods to reduce noise often come at the expense of data diversity. Our work focuses on caption quality as one major source of noise, and studies how generated captions can increase the utility of web-scraped datapoints with nondescript text. Through exploring different mixing strategies for raw and generated captions, we outperform the best filtering method proposed by the DataComp benchmark by 2% on ImageNet and 4% on average across 38 tasks, given a candidate pool of 128M image-text pairs. Our best approach is also 2x better at Flickr and MS-COCO retrieval. We then analyze what makes synthetic captions an effective source of text supervision. In experimenting with different image captioning models, we also demonstrate that the performance of a model on standard image captioning benchmarks (e.g., NoCaps CIDEr) is not a reliable indicator of the utility of the captions it generates for multimodal training. Finally, our experiments with using generated captions at DataComp's large scale (1.28B image-text pairs) offer insights into the limitations of synthetic text, as well as the importance of …
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
Large Language Models (LLMs) have demonstrated impressive performance in various NLP tasks, but they still suffer from challenges such as hallucination and weak numerical reasoning. To overcome these challenges, external tools can be used to enhance LLMs' question-answering abilities. However, current evaluation methods do not distinguish between questions that can be answered using LLMs' internal knowledge and those that require external information through tool use. To address this issue, we introduce a new dataset called ToolQA, which is designed to faithfully evaluate LLMs' ability to use external tools for question answering. Our development of ToolQA involved a scalable, automated process for dataset curation, along with 13 specialized tools designed for interaction with external knowledge in order to answer questions. Importantly, we strive to minimize the overlap between our benchmark data and LLMs' pre-training data, enabling a more precise evaluation of LLMs' tool-use reasoning abilities. We conducted an in-depth diagnosis of existing tool-use LLMs to highlight their strengths, weaknesses, and potential improvements. Our findings set a new benchmark for evaluating LLMs and suggest new directions for future advancements. Our data and code are freely available for the broader scientific community on GitHub.
[ Great Hall & Hall B1+B2 (level 1) ]
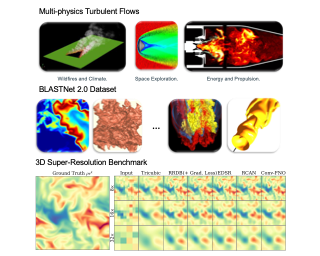
Abstract
Analysis of compressible turbulent flows is essential for applications related to propulsion, energy generation, and the environment. Here, we present BLASTNet 2.0, a 2.2 TB network-of-datasets containing 744 full-domain samples from 34 high-fidelity direct numerical simulations, which addresses the current limited availability of 3D high-fidelity reacting and non-reacting compressible turbulent flow simulation data. With this data, we benchmark a total of 49 variations of five deep learning approaches for 3D super-resolution - which can be applied for improving scientific imaging, simulations, turbulence models, as well as in computer vision applications. We perform neural scaling analysis on these models to examine the performance of different machine learning (ML) approaches, including two scientific ML techniques. We demonstrate that (i) predictive performance can scale with model size and cost, (ii) architecture matters significantly, especially for smaller models, and (iii) the benefits of physics-based losses can persist with increasing model size. The outcomes of this benchmark study are anticipated to offer insights that can aid the design of 3D super-resolution models, especially for turbulence models, while this data is expected to foster ML methods for a broad range of flow physics applications. This data is publicly available with download links and browsing tools consolidated …
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
[ Great Hall & Hall B1+B2 (level 1) ]
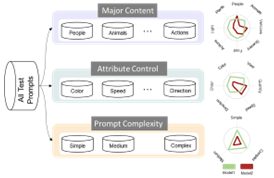
Abstract
Recently, open-domain text-to-video (T2V) generation models have made remarkable progress. However, the promising results are mainly shown by the qualitative cases of generated videos, while the quantitative evaluation of T2V models still faces two critical problems. Firstly, existing studies lack fine-grained evaluation of T2V models on different categories of text prompts. Although some benchmarks have categorized the prompts, their categorization either only focuses on a single aspect or fails to consider the temporal information in video generation. Secondly, it is unclear whether the automatic evaluation metrics are consistent with human standards. To address these problems, we propose FETV, a benchmark for Fine-grained Evaluation of Text-to-Video generation. FETV is multi-aspect, categorizing the prompts based on three orthogonal aspects: the major content, the attributes to control and the prompt complexity. FETV is also temporal-aware, which introduces several temporal categories tailored for video generation. Based on FETV, we conduct comprehensive manual evaluations of four representative T2V models, revealing their pros and cons on different categories of prompts from different aspects. We also extend FETV as a testbed to evaluate the reliability of automatic T2V metrics. The multi-aspect categorization of FETV enables fine-grained analysis of the metrics' reliability …
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
PopSign is a smartphone-based bubble-shooter game that helps hearing parentsof deaf infants learn sign language. To help parents practice their ability to sign,PopSign is integrating sign language recognition as part of its gameplay. Fortraining the recognizer, we introduce the PopSign ASL v1.0 dataset that collectsexamples of 250 isolated American Sign Language (ASL) signs using Pixel 4Asmartphone selfie cameras in a variety of environments. It is the largest publiclyavailable, isolated sign dataset by number of examples and is the first dataset tofocus on one-handed, smartphone signs. We collected over 210,000 examplesat 1944x2592 resolution made by 47 consenting Deaf adult signers for whomAmerican Sign Language is their primary language. We manually reviewed 217,866of these examples, of which 175,023 (approximately 700 per sign) were the signintended for the educational game. 39,304 examples were recognizable as a signbut were not the desired variant or were a different sign. We provide a training setof 31 signers, a validation set of eight signers, and a test set of eight signers. Abaseline LSTM model for the 250-sign vocabulary achieves 82.1% accuracy (81.9%class-weighted F1 score) on the validation set and 84.2% (83.9% class-weightedF1 score) on the test set. Gameplay suggests that accuracy will be sufficient forcreating educational games …
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
When solving decision-making tasks, humans typically depend on information from two key sources: (1) Historical policy data, which provides interaction replay from the environment, and (2) Analytical insights in natural language form, exposing the invaluable thought process or strategic considerations. Despite this, the majority of preceding research focuses on only one source: they either use historical replay exclusively to directly learn policy or value functions, or engaged in language model training utilizing mere language corpus. In this paper, we argue that a powerful autonomous agent should cover both sources. Thus, we propose ChessGPT, a GPT model bridging policy learning and language modeling by integrating data from these two sources in Chess games. Specifically, we build a large-scale game and language dataset related to chess. Leveraging the dataset, we showcase two model examples ChessCLIP and ChessGPT, integrating policy learning and language modeling. Finally, we propose a full evaluation framework for evaluating language model's chess ability. Experimental results validate our model and dataset's effectiveness. We open source our code, model, and dataset at https://github.com/waterhorse1/ChessGPT.
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
The stunning qualitative improvement of text-to-image models has led to their widespread attention and adoption. However, we lack a comprehensive quantitative understanding of their capabilities and risks. To fill this gap, we introduce a new benchmark, Holistic Evaluation of Text-to-Image Models (HEIM). Whereas previous evaluations focus mostly on image-text alignment and image quality, we identify 12 aspects, including text-image alignment, image quality, aesthetics, originality, reasoning, knowledge, bias, toxicity, fairness, robustness, multilinguality, and efficiency. We curate 62 scenarios encompassing these aspects and evaluate 26 state-of-the-art text-to-image models on this benchmark. Our results reveal that no single model excels in all aspects, with different models demonstrating different strengths. We release the generated images and human evaluation results for full transparency at https://crfm.stanford.edu/heim/latest and the code at https://github.com/stanford-crfm/helm, which is integrated with the HELM codebase
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
Modeling complex dynamical systems poses significant challenges, with traditional methods struggling to work on a variety of systems and scale to high-dimensional dynamics. In response, we present DynaDojo, a novel benchmarking platform designed for data-driven dynamical system identification. DynaDojo provides diagnostics on three ways an algorithm’s performance scales: across the number of training samples, the complexity of a dynamical system, and a target error to achieve. Furthermore, DynaDojo enables studying out-of-distribution generalization (by providing unique test conditions for each system) and active learning (by supporting closed-loop control). Through its user-friendly and easily extensible API, DynaDojo accommodates a wide range of user-defined \texttt{Algorithms}, \texttt{Systems}, and \texttt{Challenges} (evaluation metrics). The platform also prioritizes resource-efficient training with parallel processing strategies for running on a cluster. To showcase its utility, in DynaDojo 0.9, we include implementations of 7 baseline algorithms and 20 dynamical systems, along with several demos exhibiting insights researchers can glean using our platform. This work aspires to make DynaDojo a unifying benchmarking platform for system identification, paralleling the role of OpenAI’s Gym in reinforcement learning.
[ Great Hall & Hall B1+B2 (level 1) ]
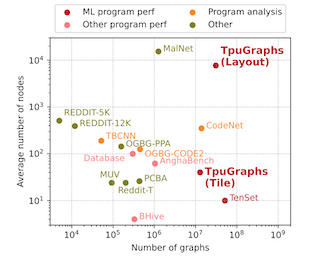
Abstract
Precise hardware performance models play a crucial role in code optimizations. They can assist compilers in making heuristic decisions or aid autotuners in identifying the optimal configuration for a given program. For example, the autotuner for XLA, a machine learning compiler, discovered 10–20\% speedup on state-of-the-art models serving substantial production traffic at Google. Although there exist a few datasets for program performance prediction, they target small sub-programs such as basic blocks or kernels. This paper introduces TpuGraphs, a performance prediction dataset on full tensor programs, represented as computational graphs, running on Tensor Processing Units (TPUs). Each graph in the dataset represents the main computation of a machine learning workload, e.g., a training epoch or an inference step. Each data sample contains a computational graph, a compilation configuration, and the execution time of the graph when compiled with the configuration. The graphs in the dataset are collected from open-source machine learning programs, featuring popular model architectures (e.g., ResNet, EfficientNet, Mask R-CNN, and Transformer). TpuGraphs provides 25x more graphs than the largest graph property prediction dataset (with comparable graph sizes), and 770x larger graphs on average compared to existing performance prediction datasets on machine learning programs. This graph-level prediction task on large …
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
Reinforcement Learning (RL)-based recommender systems (RSs) have garnered considerable attention due to their ability to learn optimal recommendation policies and maximize long-term user rewards. However, deploying RL models directly in online environments and generating authentic data through A/B tests can pose challenges and require substantial resources. Simulators offer an alternative approach by providing training and evaluation environments for RS models, reducing reliance on real-world data. Existing simulators have shown promising results but also have limitations such as simplified user feedback, lacking consistency with real-world data, the challenge of simulator evaluation, and difficulties in migration and expansion across RSs.To address these challenges, we propose KuaiSim, a comprehensive user environment that provides user feedback with multi-behavior and cross-session responses.The resulting simulator can support three levels of recommendation problems: the request level list-wise recommendation task, the whole-session level sequential recommendation task, and the cross-session level retention optimization task. For each task, KuaiSim also provides evaluation protocols and baseline recommendation algorithms that further serve as benchmarks for future research. We also restructure existing competitive simulators on the Kuairand Dataset and compare them against KuaiSim to future assess their performance and behavioral differences. Furthermore, to showcase KuaiSim's flexibility in accommodating different datasets, we demonstrate its …
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
The challenge of replicating research results has posed a significant impediment to the field of molecular biology. The advent of modern intelligent systems has led to notable progress in various domains. Consequently, we embarked on an investigation of intelligent monitoring systems as a means of tackling the issue of the reproducibility crisis. Specifically, we first curate a comprehensive multimodal dataset, named ProBio, as an initial step towards this objective. This dataset comprises fine-grained hierarchical annotations intended for the purpose of studying activity understanding in BioLab. Next, we devise two challenging benchmarks, transparent solution tracking and multimodal action recognition, to emphasize the unique characteristics and difficulties associated with activity understanding in BioLab settings. Finally, we provide a thorough experimental evaluation of contemporary video understanding models and highlight their limitations in this specialized domain to identify potential avenues for future research. We hope \dataset with associated benchmarks may garner increased focus on modern AI techniques in the realm of molecular biology.
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
Academic tabular benchmarks often contain small sets of curated features. In contrast, data scientists typically collect as many features as possible into their datasets, and even engineer new features from existing ones. To prevent over-fitting in subsequent downstream modeling, practitioners commonly use automated feature selection methods that identify a reduced subset of informative features. Existing benchmarks for tabular feature selection consider classical downstream models, toy synthetic datasets, or do not evaluate feature selectors on the basis of downstream performance. We construct a challenging feature selection benchmark evaluated on downstream neural networks including transformers, using real datasets and multiple methods for generating extraneous features. We also propose an input-gradient-based analogue of LASSO for neural networks that outperforms classical feature selection methods on challenging problems such as selecting from corrupted or second-order features.
[ Great Hall & Hall B1+B2 (level 1) ]
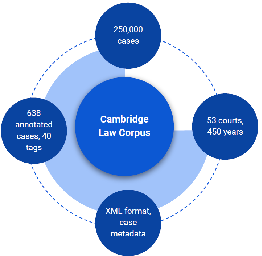
Abstract
We introduce the Cambridge Law Corpus (CLC), a corpus for legal AI research. It consists of over 250 000 court cases from the UK. Most cases are from the 21st century, but the corpus includes cases as old as the 16th century. This paper presents the first release of the corpus, containing the raw text and meta-data. Together with the corpus, we provide annotations on case outcomes for 638 cases, done by legal experts. Using our annotated data, we have trained and evaluated case outcome extraction with GPT-3, GPT-4 and RoBERTa models to provide benchmarks. We include an extensive legal and ethical discussion to address the potentially sensitive nature of this material. As a consequence, the corpus will only be released for research purposes under certain restrictions.
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
In-context vision and language models like Flamingo support arbitrarily interleaved sequences of images and text as input.This format not only enables few-shot learning via interleaving independent supervised (image, text) examples, but also, more complex prompts involving interaction between images, e.g., ``What do image A and image B have in common?''To support this interface, pretraining occurs over web corpora that similarly contain interleaved images+text.To date, however, large-scale data of this form have not been publicly available.We release Multimodal C4, an augmentation of the popular text-only C4 corpus with images interleaved.We use a linear assignment algorithm to place images into longer bodies of text using CLIP features, a process that we show outperforms alternatives.Multimodal C4 spans everyday topics like cooking, travel, technology, etc. A manual inspection of a random sample of documents shows that a vast majority (88\%) of images are topically relevant, and that linear assignment frequently selects individual sentences specifically well-aligned with each image (80\%). After filtering NSFW images, ads, etc., the resulting corpus consists of 101.2M documents with 571M images interleaved in 43B English tokens.
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
In recent years there has been a shift from heuristics based malware detection towards machine learning, which proves to be more robust in the current heavily adversarial threat landscape. While we acknowledge machine learning to be better equipped to mine for patterns in the increasingly high amounts of similar-looking files, we also note a remarkable scarcity of the data available for similarity targeted research. Moreover, we observe that the focus in the few related works falls on quantifying similarity in malware, often overlooking the clean data. This one-sided quantification is especially dangerous in the context of detection bypass. We propose to address the deficiencies in the space of similarity research on binary files, starting from EMBER — one of the largest malware classification datasets. We enhance EMBER with similarity information as well as malware class tags, to enable further research in the similarity space. Our contribution is threefold: (1) we publish EMBERSim, an augmented version of EMBER, that includes similarity informed tags; (2) we enrich EMBERSim with automatically determined malware class tags using the open-source tool AVClass on VirusTotal data and (3) we describe and share the implementation for our class scoring technique and leaf similarity method.
[ Great Hall & Hall B1+B2 (level 1) ]
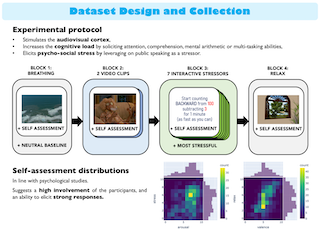
Abstract
StressID is a new dataset specifically designed for stress identification fromunimodal and multimodal data. It contains videos of facial expressions, audiorecordings, and physiological signals. The video and audio recordings are acquiredusing an RGB camera with an integrated microphone. The physiological datais composed of electrocardiography (ECG), electrodermal activity (EDA), andrespiration signals that are recorded and monitored using a wearable device. Thisexperimental setup ensures a synchronized and high-quality multimodal data col-lection. Different stress-inducing stimuli, such as emotional video clips, cognitivetasks including mathematical or comprehension exercises, and public speakingscenarios, are designed to trigger a diverse range of emotional responses. Thefinal dataset consists of recordings from 65 participants who performed 11 tasks,as well as their ratings of perceived relaxation, stress, arousal, and valence levels.StressID is one of the largest datasets for stress identification that features threedifferent sources of data and varied classes of stimuli, representing more than39 hours of annotated data in total. StressID offers baseline models for stressclassification including a cleaning, feature extraction, and classification phase foreach modality. Additionally, we provide multimodal predictive models combiningvideo, audio, and physiological inputs. The data and the code for the baselines areavailable at https://project.inria.fr/stressid/.
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
While recent advancements in vision-language models have had a transformative impact on multi-modal comprehension, the extent to which these models possess the ability to comprehend generated images remains uncertain. Synthetic images, in comparison to real data, encompass a higher level of diversity in terms of both content and style, thereby presenting significant challenges for the models to fully grasp. In light of this challenge, we introduce a comprehensive dataset, referred to as JourneyDB, that caters to the domain of generative images within the context of multi-modal visual understanding. Our meticulously curated dataset comprises 4 million distinct and high-quality generated images, each paired with the corresponding text prompts that were employed in their creation. Furthermore, we additionally introduce an external subset with results of another 22 text-to-image generative models, which makes JourneyDB a comprehensive benchmark for evaluating the comprehension of generated images. On our dataset, we have devised four benchmarks to assess the performance of generated image comprehension in relation to both content and style interpretation. These benchmarks encompass prompt inversion, style retrieval, image captioning, and visual question answering. Lastly, we evaluate the performance of state-of-the-art multi-modal models when applied to the JourneyDB dataset, providing a comprehensive analysis of their strengths …
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
Large language models (LLMs) have shown promise in proving formal theorems using proof assistants such as Lean. However, existing methods are difficult to reproduce or build on, due to private code, data, and large compute requirements. This has created substantial barriers to research on machine learning methods for theorem proving. This paper removes these barriers by introducing LeanDojo: an open-source Lean playground consisting of toolkits, data, models, and benchmarks. LeanDojo extracts data from Lean and enables interaction with the proof environment programmatically. It contains fine-grained annotations of premises in proofs, providing valuable data for premise selection—a key bottleneck in theorem proving. Using this data, we develop ReProver (Retrieval-Augmented Prover): an LLM-based prover augmented with retrieval for selecting premises from a vast math library. It is inexpensive and needs only one GPU week of training. Our retriever leverages LeanDojo's program analysis capability to identify accessible premises and hard negative examples, which makes retrieval much more effective. Furthermore, we construct a new benchmark consisting of 98,734 theorems and proofs extracted from Lean's math library. It features challenging data split requiring the prover to generalize to theorems relying on novel premises that are never used in training. We use this benchmark for training …
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
Graph Self-Supervised Learning (GSSL) provides a robust pathway for acquiring embeddings without expert labelling, a capability that carries profound implications for molecular graphs due to the staggering number of potential molecules and the high cost of obtaining labels. However, GSSL methods are designed not for optimisation within a specific domain but rather for transferability across a variety of downstream tasks. This broad applicability complicates their evaluation. Addressing this challenge, we present "Molecular Graph Representation Evaluation" (MOLGRAPHEVAL), generating detailed profiles of molecular graph embeddings with interpretable and diversified attributes. MOLGRAPHEVAL offers a suite of probing tasks grouped into three categories: (i) generic graph, (ii) molecular substructure, and (iii) embedding space properties. By leveraging MOLGRAPHEVAL to benchmark existing GSSL methods against both current downstream datasets and our suite of tasks, we uncover significant inconsistencies between inferences drawn solely from existing datasets and those derived from more nuanced probing. These findings suggest that current evaluation methodologies fail to capture the entirety of the landscape.
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
We present the Temporal Graph Benchmark (TGB), a collection of challenging and diverse benchmark datasets for realistic, reproducible, and robust evaluation of machine learning models on temporal graphs. TGB datasets are of large scale, spanning years in duration, incorporate both node and edge-level prediction tasks and cover a diverse set of domains including social, trade, transaction, and transportation networks. For both tasks, we design evaluation protocols based on realistic use-cases. We extensively benchmark each dataset and find that the performance of common models can vary drastically across datasets. In addition, on dynamic node property prediction tasks, we show that simple methods often achieve superior performance compared to existing temporal graph models. We believe that these findings open up opportunities for future research on temporal graphs. Finally, TGB provides an automated machine learning pipeline for reproducible and accessible temporal graph research, including data loading, experiment setup and performance evaluation. TGB will be maintained and updated on a regular basis and welcomes community feedback. TGB datasets, data loaders, example codes, evaluation setup, and leaderboards are publicly available at https://tgb.complexdatalab.com/.
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
Understanding comprehensive assembly knowledge from videos is critical for futuristic ultra-intelligent industry. To enable technological breakthrough, we present HA-ViD – the first human assembly video dataset that features representative industrial assembly scenarios, natural procedural knowledge acquisition process, and consistent human-robot shared annotations. Specifically, HA-ViD captures diverse collaboration patterns of real-world assembly, natural human behaviors and learning progression during assembly, and granulate action annotations to subject, action verb, manipulated object, target object, and tool. We provide 3222 multi-view and multi-modality videos), 1.5M frames, 96K temporal labels and 2M spatial labels. We benchmark four foundational video understanding tasks: action recognition, action segmentation, object detection and multi-object tracking. Importantly, we analyze their performance and the further reasoning steps for comprehending knowledge in assembly progress, process efficiency, task collaboration, skill parameters and human intention. Details of HA-ViD is available at: https://iai-hrc.github.io/ha-vid.
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
This paper presents a comprehensive and quality collection of functional human brain network data for potential research in the intersection of neuroscience, machine learning, and graph analytics. Anatomical and functional MRI images have been used to understand the functional connectivity of the human brain and are particularly important in identifying underlying neurodegenerative conditions such as Alzheimer's, Parkinson's, and Autism. Recently, the study of the brain in the form of brain networks using machine learning and graph analytics has become increasingly popular, especially to predict the early onset of these conditions. A brain network, represented as a graph, retains rich structural and positional information that traditional examination methods are unable to capture. However, the lack of publicly accessible brain network data prevents researchers from data-driven explorations. One of the main difficulties lies in the complicated domain-specific preprocessing steps and the exhaustive computation required to convert the data from MRI images into brain networks. We bridge this gap by collecting a large amount of MRI images from public databases and a private source, working with domain experts to make sensible design choices, and preprocessing the MRI images to produce a collection of brain network datasets. The datasets originate from 6 different sources, …
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
Assessing the quality and impact of individual data points is critical for improving model performance and mitigating undesirable biases within the training dataset. Several data valuation algorithms have been proposed to quantify data quality, however, there lacks a systemic and standardized benchmarking system for data valuation. In this paper, we introduce OpenDataVal, an easy-to-use and unified benchmark framework that empowers researchers and practitioners to apply and compare various data valuation algorithms. OpenDataVal provides an integrated environment that includes (i) a diverse collection of image, natural language, and tabular datasets, (ii) implementations of eleven different state-of-the-art data valuation algorithms, and (iii) a prediction model API that can import any models in scikit-learn. Furthermore, we propose four downstream machine learning tasks for evaluating the quality of data values. We perform benchmarking analysis using OpenDataVal, quantifying and comparing the efficacy of state-of-the-art data valuation approaches. We find that no single algorithm performs uniformly best across all tasks, and an appropriate algorithm should be employed for a user's downstream task. OpenDataVal is publicly available at https://opendataval.github.io with comprehensive documentation. Furthermore, we provide a leaderboard where researchers can evaluate the effectiveness of their own data valuation algorithms.
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
Building agents based on tree-search planning capabilities with learned models has achieved remarkable success in classic decision-making problems, such as Go and Atari.However, it has been deemed challenging or even infeasible to extend Monte Carlo Tree Search (MCTS) based algorithms to diverse real-world applications, especially when these environments involve complex action spaces and significant simulation costs, or inherent stochasticity.In this work, we introduce LightZero, the first unified benchmark for deploying MCTS/MuZero in general sequential decision scenarios. Specificially, we summarize the most critical challenges in designing a general MCTS-style decision-making solver, then decompose the tightly-coupled algorithm and system design of tree-search RL methods into distinct sub-modules.By incorporating more appropriate exploration and optimization strategies, we can significantly enhance these sub-modules and construct powerful LightZero agents to tackle tasks across a wide range of domains, such as board games, Atari, MuJoCo, MiniGrid and GoBigger.Detailed benchmark results reveal the significant potential of such methods in building scalable and efficient decision intelligence.The code is available as part of OpenDILab at https://github.com/opendilab/LightZero.
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
The application of deep learning to nursing procedure activity understanding has the potential to greatly enhance the quality and safety of nurse-patient interactions. By utilizing the technique, we can facilitate training and education, improve quality control, and enable operational compliance monitoring. However, the development of automatic recognition systems in this field is currently hindered by the scarcity of appropriately labeled datasets. The existing video datasets pose several limitations: 1) these datasets are small-scale in size to support comprehensive investigations of nursing activity; 2) they primarily focus on single procedures, lacking expert-level annotations for various nursing procedures and action steps; and 3) they lack temporally localized annotations, which prevents the effective localization of targeted actions within longer video sequences. To mitigate these limitations, we propose NurViD, a large video dataset with expert-level annotation for nursing procedure activity understanding. NurViD consists of over 1.5k videos totaling 144 hours, making it approximately four times longer than the existing largest nursing activity datasets. Notably, it encompasses 51 distinct nursing procedures and 177 action steps, providing a much more comprehensive coverage compared to existing datasets that primarily focus on limited procedures. To evaluate the efficacy of current deep learning methods on nursing activity understanding, we …
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
Deep learning methods have gained popularity in high energy physics for fast modeling of particle showers in detectors. Detailed simulation frameworks such as the gold standard \textsc{Geant4} are computationally intensive, and current deep generative architectures work on discretized, lower resolution versions of the detailed simulation. The development of models that work at higher spatial resolutions is currently hindered by the complexity of the full simulation data, and by the lack of simpler, more interpretable benchmarks. Our contribution is \textsc{SUPA}, the SUrrogate PArticle propagation simulator, an algorithm and software package for generating data by simulating simplified particle propagation, scattering and shower development in matter. The generation is extremely fast and easy to use compared to \textsc{Geant4}, but still exhibits the key characteristics and challenges of the detailed simulation. The proposed simulator generates thousands of particle showers per second on a desktop machine, a speed up of up to 6 orders of magnitudes over \textsc{Geant4}, and stores detailed geometric information about the shower propagation. \textsc{\textsc{SUPA}} provides much greater flexibility for setting initial conditions and defining multiple benchmarks for the development of models. Moreover, interpreting particle showers as point clouds creates a connection to geometric machine learning and provides challenging and fundamentally new …
[ Great Hall & Hall B1+B2 (level 1) ]
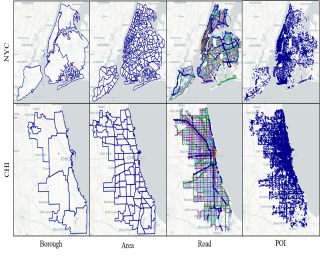
Abstract
Accurate Urban SpatioTemporal Prediction (USTP) is of great importance to the development and operation of the smart city. As an emerging building block, multi-sourced urban data are usually integrated as urban knowledge graphs (UrbanKGs) to provide critical knowledge for urban spatiotemporal prediction models. However, existing UrbanKGs are often tailored for specific downstream prediction tasks and are not publicly available, which limits the potential advancement. This paper presents UUKG, the unified urban knowledge graph dataset for knowledge-enhanced urban spatiotemporal predictions. Specifically, we first construct UrbanKGs consisting of millions of triplets for two metropolises by connecting heterogeneous urban entities such as administrative boroughs, POIs, and road segments. Moreover, we conduct qualitative and quantitative analysis on constructed UrbanKGs and uncover diverse high-order structural patterns, such as hierarchies and cycles, that can be leveraged to benefit downstream USTP tasks. To validate and facilitate the use of UrbanKGs, we implement and evaluate 15 KG embedding methods on the KG completion task and integrate the learned KG embeddings into 9 spatiotemporal models for five different USTP tasks. The extensive experimental results not only provide benchmarks of knowledge-enhanced USTP models under different task settings but also highlight the potential of state-of-the-art high-order structure-aware UrbanKG embedding methods. We …
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
This paper introduces a modular framework for Mixed-variable and Combinatorial Bayesian Optimization (MCBO) to address the lack of systematic benchmarking and standardized evaluation in the field. Current MCBO papers often introduce non-diverse or non-standard benchmarks to evaluate their methods, impeding the proper assessment of different MCBO primitives and their combinations. Additionally, papers introducing a solution for a single MCBO primitive often omit benchmarking against baselines that utilize the same methods for the remaining primitives. This omission is primarily due to the significant implementation overhead involved, resulting in a lack of controlled assessments and an inability to showcase the merits of a contribution effectively.To overcome these challenges, our proposed framework enables an effortless combination of Bayesian Optimization components, and provides a diverse set of synthetic and real-world benchmarking tasks. Leveraging this flexibility, we implement 47 novel MCBO algorithms and benchmark them against seven existing MCBO solvers and five standard black-box optimization algorithms on ten tasks, conducting over 4000 experiments. Our findings reveal a superior combination of MCBO primitives outperforming existing approaches and illustrate the significance of model fit and the use of a trust region. We make our MCBO library available under the MIT license at \url{https://github.com/huawei-noah/HEBO/tree/master/MCBO}.
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
Compositional reasoning is a hallmark of human visual intelligence. Yet, despite the size of large vision-language models, they struggle to represent simple compositions by combining objects with their attributes. To measure this lack of compositional capability, we design Cola, a text-to-image retrieval benchmark to Compose Objects Localized with Attributes. To solve Cola, a model must retrieve images with the correct configuration of attributes and objects and avoid choosing a distractor image with the same objects and attributes but in the wrong configuration. Cola contains about 1.2k composed queries of 168 objects and 197 attributes on around 30K images. Our human evaluation finds that Cola is 83.33% accurate, similar to contemporary compositionality benchmarks. Using Cola as a testbed, we explore empirical modeling designs to adapt pre-trained vision-language models to reason compositionally. We explore 6 adaptation strategies on 2 seminal vision-language models, using compositionality-centric test benchmarks - Cola and CREPE. We find the optimal adaptation strategy is to train a multi-modal attention layer that jointly attends over the frozen pre-trained image and language features. Surprisingly, training multimodal layers on CLIP performs better than tuning a larger FLAVA model with already pre-trained multimodal layers. Furthermore, our adaptation strategy improves CLIP and FLAVA to …
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
The ability to discern and comprehend pragmatic meanings is a cornerstone of social and emotional intelligence, referred to as pragmatic reasoning. Despite the strides made in the development of Large Language Models (LLMs), such as ChatGPT, these models grapple with capturing the nuanced and ambiguous facets of language, falling short of the aspiration to build human-like conversational agents. In this work, we introduce a novel benchmark, the DiPlomat, which delves into the fundamental components of conversational pragmatic reasoning, encompassing situational context reasoning, open-world knowledge acquisition, and unified figurative language understanding. We start by collecting a new human-annotated dialogue dataset, composed of 4,177 multi-turn dialogues and a vocabulary of 48,900 words. Along with the dataset, two tasks are proposed to evaluate machines' pragmatic reasoning capabilities, namely, Pragmatic Reasoning and Identification(PIR) and Conversational Question Answering (CQA). Furthermore, we probe into a zero-shot natural language inference task, where the significance of context in pragmatic reasoning is underscored. Experimental findings illustrate the existing limitations of current prevailing LLMs in the realm of pragmatic reasoning, shedding light on the pressing need for further research to facilitate the emergence of emotional intelligence within human-like conversational agents.
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
Numerous real-world systems, ranging from healthcare to energy grids, involve users competing for finite and potentially scarce resources. Designing policies for resource allocation in such real-world systems is challenging for many reasons, including the changing nature of user types and their (possibly urgent) need for resources. Researchers have developed numerous machine learning solutions for determining resource allocation policies in these challenging settings. However, a key limitation has been the absence of good methods and test-beds for benchmarking these policies; almost all resource allocation policies are benchmarked in environments which are either completely synthetic or do not allow any deviation from historical data. In this paper we introduce AllSim, which is a benchmarking environment for realistically simulating the impact and utility of policies for resource allocation in systems in which users compete for such scarce resources. Building such a benchmarking environment is challenging because it needs to successfully take into account the entire collective of potential users and the impact a resource allocation policy has on all the other users in the system. AllSim's benchmarking environment is modular (each component being parameterized individually), learnable (informed by historical data), and customizable (adaptable to changing conditions). These, when interacting with an allocation policy, …
[ Great Hall & Hall B1+B2 (level 1) ]
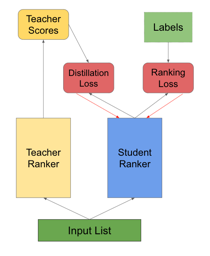
Abstract
The distillation of ranking models has become an important topic in both academia and industry. In recent years, several advanced methods have been proposed to tackle this problem, often leveraging ranking information from teacher rankers that is absent in traditional classification settings. To date, there is no well-established consensus on how to evaluate this class of models. Moreover, inconsistent benchmarking on a wide range of tasks and datasets make it difficult to assess or invigorate advances in this field. This paper first examines representative prior arts on ranking distillation, and raises three questions to be answered around methodology and reproducibility. To that end, we propose a systematic and unified benchmark, Ranking Distillation Suite (RD-Suite), which is a suite of tasks with 4 large real-world datasets, encompassing two major modalities (textual and numeric) and two applications (standard distillation and distillation transfer). RD-Suite consists of benchmark results that challenge some of the common wisdom in the field, and the release of datasets with teacher scores and evaluation scripts for future research. RD-Suite paves the way towards better understanding of ranking distillation, facilities more research in this direction, and presents new challenges.
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
Graph Structure Learning (GSL) has recently garnered considerable attention due to its ability to optimize both the parameters of Graph Neural Networks (GNNs) and the computation graph structure simultaneously. Despite the proliferation of GSL methods developed in recent years, there is no standard experimental setting or fair comparison for performance evaluation, which creates a great obstacle to understanding the progress in this field. To fill this gap, we systematically analyze the performance of GSL in different scenarios and develop a comprehensive Graph Structure Learning Benchmark (GSLB) curated from 20 diverse graph datasets and 16 distinct GSL algorithms. Specifically, GSLB systematically investigates the characteristics of GSL in terms of three dimensions: effectiveness, robustness, and complexity. We comprehensively evaluate state-of-the-art GSL algorithms in node- and graph-level tasks, and analyze their performance in robust learning and model complexity. Further, to facilitate reproducible research, we have developed an easy-to-use library for training, evaluating, and visualizing different GSL methods. Empirical results of our extensive experiments demonstrate the ability of GSL and reveal its potential benefits on various downstream tasks, offering insights and opportunities for future research. The code of GSLB is available at: https://github.com/GSL-Benchmark/GSLB.
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
Recently, commonsense reasoning in text generation has attracted much attention. Generative commonsense reasoning is the task that requires machines, given a group of keywords, to compose a single coherent sentence with commonsense plausibility. While existing datasets targeting generative commonsense reasoning focus on everyday scenarios, it is unclear how well machines reason under specific geographical and temporal contexts. We formalize this challenging task as SituatedGen, where machines with commonsense should generate a pair of contrastive sentences given a group of keywords including geographical or temporal entities. We introduce a corresponding English dataset consisting of 8,268 contrastive sentence pairs, which are built upon several existing commonsense reasoning benchmarks with minimal manual labor. Experiments show that state-of-the-art generative language models struggle to generate sentences with commonsense plausibility and still lag far behind human performance. Our dataset is publicly available at https://github.com/yunx-z/situated_gen.
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
Explainable recommendation has attracted much attention from the industry and academic communities. It has shown great potential to improve the recommendation persuasiveness, informativeness and user satisfaction. In the past few years, while a lot of promising explainable recommender models have been proposed, the datasets used to evaluate them still suffer from several limitations, for example, the explanation ground truths are not labeled by the real users, the explanations are mostly single-modal and around only one aspect. To bridge these gaps, in this paper, we build a new explainable recommendation dataset, which, to our knowledge, is the first contribution that provides a large amount of real user labeled multi-modal and multi-aspect explaination ground truths. In specific, we firstly develop a video recommendation platform, where a series of questions around the recommendation explainability are carefully designed. Then, we recruit about 3000 high-quality labelers with different backgrounds to use the system, and collect their behaviors and feedback to our questions. In this paper, we detail the construction process of our dataset and also provide extensive analysis on its characteristics. In addition, we develop a library, where ten well-known explainable recommender models are implemented in a unified framework. Based on this library, we build …
[ Great Hall & Hall B1+B2 (level 1) ]
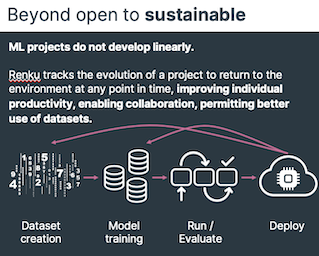
Abstract
Data and code working together is fundamental to machine learning (ML), but the context around datasets and interactions between datasets and code are in general captured only rudimentarily. Context such as how the dataset was prepared and created, what source data were used, what code was used in processing, how the dataset evolved, and where it has been used and reused can provide much insight, but this information is often poorly documented. That is unfortunate since it makes datasets into black-boxes with potentially hidden characteristics that have downstream consequences. We argue that making dataset preparation more accessible and dataset usage easier to record and document would have significant benefits for the ML community: it would allow for greater diversity in datasets by inviting modification to published sources, simplify use of alternative datasets and, in doing so, make results more transparent and robust, while allowing for all contributions to be adequately credited. We present a platform, Renku, designed to support and encourage such sustainable development and use of data, datasets, and code, and we demonstrate its benefits through a few illustrative projects which span the spectrum from dataset creation to dataset consumption and showcasing.
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
Video highlight detection is a task to automatically select the most engaging moments from a long video. This problem is highly challenging since it aims to learn a general way of finding highlights from a variety of videos in the real world.The task has an innate subjectivity because the definition of a highlight differs across individuals. Therefore, to detect consistent and meaningful highlights, prior benchmark datasets have been labeled by multiple (5-20) raters. Due to the high cost of manual labeling, most existing public benchmarks are in extremely small scale, containing only a few tens or hundreds of videos. This insufficient benchmark scale causes multiple issues such as unstable evaluation or high sensitivity in traintest splits. We present Mr. HiSum, a large-scale dataset for video highlight detection and summarization, containing 31,892 videos and reliable labels aggregated over 50,000+ users per video. We empirically prove reliability of the labels as frame importance by cross-dataset transfer and user study.
[ Great Hall & Hall B1+B2 (level 1) ]
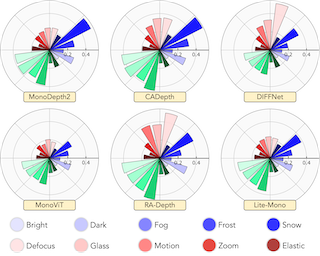
Abstract
Depth estimation from monocular images is pivotal for real-world visual perception systems. While current learning-based depth estimation models train and test on meticulously curated data, they often overlook out-of-distribution (OoD) situations. Yet, in practical settings -- especially safety-critical ones like autonomous driving -- common corruptions can arise. Addressing this oversight, we introduce a comprehensive robustness test suite, RoboDepth, encompassing 18 corruptions spanning three categories: i) weather and lighting conditions; ii) sensor failures and movement; and iii) data processing anomalies. We subsequently benchmark 42 depth estimation models across indoor and outdoor scenes to assess their resilience to these corruptions. Our findings underscore that, in the absence of a dedicated robustness evaluation framework, many leading depth estimation models may be susceptible to typical corruptions. We delve into design considerations for crafting more robust depth estimation models, touching upon pre-training, augmentation, modality, model capacity, and learning paradigms. We anticipate our benchmark will establish a foundational platform for advancing robust OoD depth estimation.
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
Automated reasoning with unstructured natural text is a key requirement for many potential applications of NLP and for developing robust AI systems. Recently, Language Models (LMs) have demonstrated complex reasoning capacities even without any finetuning. However, existing evaluation for automated reasoning assumes access to a consistent and coherent set of information over which models reason. When reasoning in the real-world, the available information is frequently inconsistent or contradictory, and therefore models need to be equipped with a strategy to resolve such conflicts when they arise. One widely-applicable way of resolving conflicts is to impose preferences over information sources (e.g., based on source credibility or information recency) and adopt the source with higher preference. In this paper, we formulate the problem of reasoning with contradictory information guided by preferences over sources as the classical problem of defeasible reasoning, and develop a dataset called BoardgameQA for measuring the reasoning capacity of LMs in this setting. BoardgameQA also incorporates reasoning with implicit background knowledge, to better reflect reasoning problems in downstream applications. We benchmark various LMs on BoardgameQA and the results reveal a significant gap in the reasoning capacity of state-of-the-art LMs on this problem, showing that reasoning with conflicting information does not …
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
We introduce HT-Step, a large-scale dataset containing temporal annotations of instructional article steps in cooking videos. It includes 122k segment-level annotations over 20k narrated videos (approximately 2.3k hours) of the HowTo100M dataset.Each annotation provides a temporal interval, and a categorical step label from a taxonomy of 4,958 unique steps automatically mined from wikiHow articles which include rich descriptions of each step.Our dataset significantly surpasses existing labeled step datasets in terms of scale, number of tasks, and richness of natural language step descriptions. Based on these annotations, we introduce a strongly supervised benchmark for aligning instructional articles with how-to videos and present a comprehensive evaluation of baseline methods for this task.By publicly releasing these annotations and defining rigorous evaluation protocols and metrics,we hope to significantly accelerate research in the field of procedural activity understanding.
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
Salient object detection (SOD) aims to identify standout elements in a scene, with recent advancements primarily focused on integrating depth data (RGB-D) or temporal data from videos to enhance SOD in complex scenes. However, the unison of two types of crucial information remains largely underexplored due to data constraints. To bridge this gap, we in this work introduce the DViSal dataset, fueling further research in the emerging field of RGB-D video salient object detection (DVSOD). Our dataset features 237 diverse RGB-D videos alongside comprehensive annotations, including object and instance-level markings, as well as bounding boxes and scribbles. These resources enable a broad scope for potential research directions. We also conduct benchmarking experiments using various SOD models, affirming the efficacy of multimodal video input for salient object detection. Lastly, we highlight some intriguing findings and promising future research avenues. To foster growth in this field, our dataset and benchmark results are publicly accessible at: https://dvsod.github.io/.
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
Camera-based physiological measurement is a fast growing field of computer vision. Remote photoplethysmography (rPPG) utilizes imaging devices (e.g., cameras) to measure the peripheral blood volume pulse (BVP) via photoplethysmography, and enables cardiac measurement via webcams and smartphones. However, the task is non-trivial with important pre-processing, modeling and post-processing steps required to obtain state-of-the-art results. Replication of results and benchmarking of new models is critical for scientific progress; however, as with many other applications of deep learning, reliable codebases are not easy to find or use. We present a comprehensive toolbox, rPPG-Toolbox, unsupervised and supervised rPPG models with support for public benchmark datasets, data augmentation and systematic evaluation: https://github.com/ubicomplab/rPPG-Toolbox.
[ Great Hall & Hall B1+B2 (level 1) ]
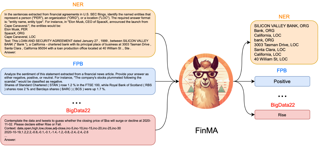
Abstract
Although large language models (LLMs) have shown great performance in natural language processing (NLP) in the financial domain, there are no publicly available financially tailored LLMs, instruction tuning datasets, and evaluation benchmarks, which is critical for continually pushing forward the open-source development of financial artificial intelligence (AI). This paper introduces PIXIU, a comprehensive framework including the first financial LLM based on fine-tuning LLaMA with instruction data, the first instruction data with 128K data samples to support the fine-tuning, and an evaluation benchmark with 8 tasks and 15 datasets. We first construct the large-scale multi-task instruction data considering a variety of financial tasks, financial document types, and financial data modalities. We then propose a financial LLM called FinMA by fine-tuning LLaMA with the constructed dataset to be able to follow instructions for various financial tasks. To support the evaluation of financial LLMs, we propose a standardized benchmark that covers a set of critical financial tasks, including six financial NLP tasks and two financial prediction tasks. With this benchmark, we conduct a detailed analysis of FinMA and several existing LLMs, uncovering their strengths and weaknesses in handling critical financial tasks. The model, datasets, benchmark, and experimental results are open-sourced to facilitate future …
[ Great Hall & Hall B1+B2 (level 1) ]
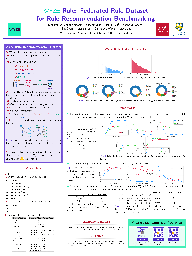
Abstract
In the rapidly evolving landscape of smart home automation, the potential of IoT devices is vast. In this realm, rules are the main tool utilized for this automation, which are predefined conditions or triggers that establish connections between devices, enabling seamless automation of specific processes. However, one significant challenge researchers face is the lack of comprehensive datasets to explore and advance the field of smart home rule recommendations. These datasets are essential for developing and evaluating intelligent algorithms that can effectively recommend rules for automating processes while preserving the privacy of the users, as it involves personal information about users' daily lives. To bridge this gap, we present the Wyze Rule Dataset, a large-scale dataset designed specifically for smart home rule recommendation research. Wyze Rule encompasses over 1 million rules gathered from a diverse user base of 300,000 individuals from Wyze Labs, offering an extensive and varied collection of real-world data. With a focus on federated learning, our dataset is tailored to address the unique challenges of a cross-device federated learning setting in the recommendation domain, featuring a large-scale number of clients with widely heterogeneous data. To establish a benchmark for comparison and evaluation, we have meticulously implemented multiple baselines …
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
The ocean is a crucial component of the Earth's system. It profoundly influences human activities and plays a critical role in climate regulation. Our understanding has significantly improved over the last decades with the advent of satellite remote sensing data, allowing us to capture essential sea surface quantities over the globe, e.g., sea surface height (SSH). Despite their ever-increasing abundance, ocean satellite data presents challenges for information extraction due to their sparsity and irregular sampling, signal complexity, and noise. Machine learning (ML) techniques have demonstrated their capabilities in dealing with large-scale, complex signals. Therefore we see an opportunity for these ML models to harness the full extent of the information contained in ocean satellite data. However, data representation and relevant evaluation metrics can be the defining factors when determining the success of applied ML. The processing steps from the raw observation data to a ML-ready state and from model outputs to interpretable quantities require domain expertise, which can be a significant barrier to entry for ML researchers. In addition, imposing fixed processing steps, like committing to specific variables, regions, and geometries, will narrow the scope of ML models and their potential impact on real-world applications. OceanBench is a unifying framework …
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
Recently, the Deep Learning community has become interested in evolutionary optimization (EO) as a means to address hard optimization problems, e.g. meta-learning through long inner loop unrolls or optimizing non-differentiable operators. One core reason for this trend has been the recent innovation in hardware acceleration and compatible software -- making distributed population evaluations much easier than before. Unlike for gradient descent-based methods though, there is a lack of hyperparameter understanding and best practices for EO – arguably due to severely less `graduate student descent' and benchmarking being performed for EO methods. Additionally, classical benchmarks from the evolutionary community provide few practical insights for Deep Learning applications. This poses challenges for newcomers to hardware-accelerated EO and hinders significant adoption. Hence, we establish a new benchmark of EO methods (NEB) tailored toward Deep Learning applications and exhaustively evaluate traditional and meta-learned EO. We investigate core scientific questions including resource allocation, fitness shaping, normalization, regularization & scalability of EO. The benchmark is open-sourced at https://github.com/neuroevobench/neuroevobench under Apache-2.0 license.
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
Generative Pre-trained Transformer (GPT) models have exhibited exciting progress in capabilities, capturing the interest of practitioners and the public alike. Yet, while the literature on the trustworthiness of GPT models remains limited, practitioners have proposed employing capable GPT models for sensitive applications to healthcare and finance – where mistakes can be costly. To this end, this work proposes a comprehensive trustworthiness evaluation for large language models with a focus on GPT-4 and GPT-3.5, considering diverse perspectives – including toxicity, stereotype bias, adversarial robustness, out-of-distribution robustness, robustness on adversarial demonstrations, privacy, machine ethics, and fairness. Based on our evaluations, we discover previously unpublished vulnerabilities to trustworthiness threats. For instance, we find that GPT models can be easily misled to generate toxic and biased outputs and leak private information in both training data and conversation history. We also find that although GPT-4 is usually more trustworthy than GPT-3.5 on standard benchmarks, GPT-4 is more vulnerable given jailbreaking system or user prompts, potentially due to the reason that GPT-4 follows the (misleading) instructions more precisely. Our work illustrates a comprehensive trustworthiness evaluation of GPT models and sheds light on the trustworthiness gaps. Our benchmark is publicly available at https://decodingtrust.github.io/.
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
Predicting the effects of mutations in proteins is critical to many applications, from understanding genetic disease to designing novel proteins to address our most pressing challenges in climate, agriculture and healthcare. Despite an increase in machine learning-based protein modeling methods, assessing their effectiveness is problematic due to the use of distinct, often contrived, experimental datasets and variable performance across different protein families. Addressing these challenges requires scale. To that end we introduce ProteinGym v1.0, a large-scale and holistic set of benchmarks specifically designed for protein fitness prediction and design. It encompasses both a broad collection of over 250 standardized deep mutational scanning assays, spanning millions of mutated sequences, as well as curated clinical datasets providing high-quality expert annotations about mutation effects. We devise a robust evaluation framework that combines metrics for both fitness prediction and design, factors in known limitations of the underlying experimental methods, and covers both zero-shot and supervised settings. We report the performance of a diverse set of over 40 high-performing models from various subfields (eg., mutation effects, inverse folding) into a unified benchmark. We open source the corresponding codebase, datasets, MSAs, structures, predictions and develop a user-friendly website that facilitates comparisons across all settings.
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
We introduce WordScape, a novel pipeline for the creation of cross-disciplinary, multilingual corpora comprising millions of pages with annotations for document layout detection. Relating visual and textual items on document pages has gained further significance with the advent of multimodal models. Various approaches proved effective for visual question answering or layout segmentation. However, the interplay of text, tables, and visuals remains challenging for a variety of document understanding tasks. In particular, many models fail to generalize well to diverse domains and new languages due to insufficient availability of training data. WordScape addresses these limitations. Our automatic annotation pipeline parses the Open XML structure of Word documents obtained from the web, jointly providing layout-annotated document images and their textual representations. In turn, WordScape offers unique properties as it (1) leverages the ubiquity of the Word file format on the internet, (2) is readily accessible through the Common Crawl web corpus, (3) is adaptive to domain-specific documents, and (4) offers culturally and linguistically diverse document pages with natural semantic structure and high-quality text. Together with the pipeline, we will additionally release 9.5M urls to word documents which can be processed using WordScape to create a dataset of over 40M pages. Finally, we …
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
Synthesizing high-fidelity head avatars is a central problem for computer vision and graphics. While head avatar synthesis algorithms have advanced rapidly, the best ones still face great obstacles in real-world scenarios. One of the vital causes is the inadequate datasets -- 1) current public datasets can only support researchers to explore high-fidelity head avatars in one or two task directions; 2) these datasets usually contain digital head assets with limited data volume, and narrow distribution over different attributes, such as expressions, ages, and accessories. In this paper, we present RenderMe-360, a comprehensive 4D human head dataset to drive advance in head avatar algorithms across different scenarios. It contains massive data assets, with 243+ million complete head frames and over 800k video sequences from 500 different identities captured by multi-view cameras at 30 FPS. It is a large-scale digital library for head avatars with three key attributes: 1) High Fidelity: all subjects are captured in 360 degrees via 60 synchronized, high-resolution 2K cameras. 2) High Diversity: The collected subjects vary from different ages, eras, ethnicities, and cultures, providing abundant materials with distinctive styles in appearance and geometry. Moreover, each subject is asked to perform various dynamic motions, such as expressions and …
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
We present DiffInfinite, a hierarchical diffusion model that generates arbitrarily large histological images while preserving long-range correlation structural information. Our approach first generates synthetic segmentation masks, subsequently used as conditions for the high-fidelity generative diffusion process. The proposed sampling method can be scaled up to any desired image size while only requiring small patches for fast training. Moreover, it can be parallelized more efficiently than previous large-content generation methods while avoiding tiling artifacts. The training leverages classifier-free guidance to augment a small, sparsely annotated dataset with unlabelled data. Our method alleviates unique challenges in histopathological imaging practice: large-scale information, costly manual annotation, and protective data handling. The biological plausibility of DiffInfinite data is evaluated in a survey by ten experienced pathologists as well as a downstream classification and segmentation task. Samples from the model score strongly on anti-copying metrics which is relevant for the protection of patient data.
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
Evaluating large language model (LLM) based chat assistants is challenging due to their broad capabilities and the inadequacy of existing benchmarks in measuring human preferences.To address this, we explore using strong LLMs as judges to evaluate these models on more open-ended questions.We examine the usage and limitations of LLM-as-a-judge, including position, verbosity, and self-enhancement biases, as well as limited reasoning ability, and propose solutions to mitigate some of them.We then verify the agreement between LLM judges and human preferences by introducing two benchmarks: MT-bench, a multi-turn question set; and Chatbot Arena, a crowdsourced battle platform.Our results reveal that strong LLM judges like GPT-4 can match both controlled and crowdsourced human preferences well, achieving over 80\% agreement, the same level of agreement between humans.Hence, LLM-as-a-judge is a scalable and explainable way to approximate human preferences, which are otherwise very expensive to obtain.Additionally, we show our benchmark and traditional benchmarks complement each other by evaluating several variants of LLaMA and Vicuna.The MT-bench questions, 3K expert votes, and 30K conversations with human preferences are publicly available at https://github.com/lm-sys/FastChat/tree/main/fastchat/llm_judge.
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
Simulation is an essential tool to develop and benchmark autonomous vehicle planning software in a safe and cost-effective manner. However, realistic simulation requires accurate modeling of multi-agent interactive behaviors to be trustworthy, behaviors which can be highly nuanced and complex. To address these challenges, we introduce Waymax, a new data-driven simulator for autonomous driving in multi-agent scenes, designed for large-scale simulation and testing. Waymax uses publicly-released, real-world driving data (e.g., the Waymo Open Motion Dataset) to initialize or play back a diverse set of multi-agent simulated scenarios. It runs entirely on hardware accelerators such as TPUs/GPUs and supports in-graph simulation for training, making it suitable for modern large-scale, distributed machine learning workflows. To support online training and evaluation, Waymax includes several learned and hard-coded behavior models that allow for realistic interaction within simulation. To supplement Waymax, we benchmark a suite of popular imitation and reinforcement learning algorithms with ablation studies on different design decisions, where we highlight the effectiveness of routes as guidance for planning agents and the ability of RL to overfit against simulated agents.
[ Great Hall & Hall B1+B2 (level 1) ]
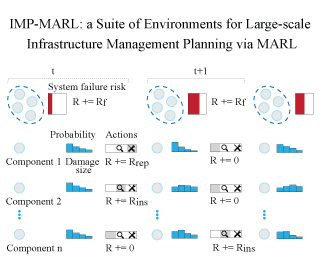
Abstract
We introduce IMP-MARL, an open-source suite of multi-agent reinforcement learning (MARL) environments for large-scale Infrastructure Management Planning (IMP), offering a platform for benchmarking the scalability of cooperative MARL methods in real-world engineering applications.In IMP, a multi-component engineering system is subject to a risk of failure due to its components' damage condition.Specifically, each agent plans inspections and repairs for a specific system component, aiming to minimise maintenance costs while cooperating to minimise system failure risk.With IMP-MARL, we release several environments including one related to offshore wind structural systems, in an effort to meet today's needs to improve management strategies to support sustainable and reliable energy systems.Supported by IMP practical engineering environments featuring up to 100 agents, we conduct a benchmark campaign, where the scalability and performance of state-of-the-art cooperative MARL methods are compared against expert-based heuristic policies. The results reveal that centralised training with decentralised execution methods scale better with the number of agents than fully centralised or decentralised RL approaches, while also outperforming expert-based heuristic policies in most IMP environments.Based on our findings, we additionally outline remaining cooperation and scalability challenges that future MARL methods should still address.Through IMP-MARL, we encourage the implementation of new environments and the further development …
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
Air pollution poses serious health concerns in developing countries, such as India, necessitating large-scale measurement for correlation analysis, policy recommendations, and informed decision-making. However, fine-grained data collection is costly. Specifically, static sensors for pollution measurement cost several thousand dollars per unit, leading to inadequate deployment and coverage. To complement the existing sparse static sensor network, we propose a mobile sensor network utilizing lower-cost PM2.5 sensors mounted on public buses in the Delhi-NCR region of India. Through this exercise, we introduce a novel dataset AirDelhi comprising PM2.5 and PM10 measurements. This dataset is made publicly available, at https://www.cse.iitd.ac.in/pollutiondata, serving as a valuable resource for machine learning (ML) researchers and environmentalists. We present three key contributions with the release of this dataset. Firstly, through in-depth statistical analysis, we demonstrate that the released dataset significantly differs from existing pollution datasets, highlighting its uniqueness and potential for new insights. Secondly, the dataset quality been validated against existing expensive sensors. Thirdly, we conduct a benchmarking exercise (https://github.com/sachin-iitd/DelhiPMDatasetBenchmark), evaluating state-of-the-art methods for interpolation, feature imputation, and forecasting on this dataset, which is the largest publicly available PM dataset to date. The results of the benchmarking exercise underscore the substantial disparities in accuracy between the proposed dataset …
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
Expressive human pose and shape estimation (EHPS) unifies body, hands, and face motion capture with numerous applications. Despite encouraging progress, current state-of-the-art methods still depend largely on a confined set of training datasets. In this work, we investigate scaling up EHPS towards the first generalist foundation model (dubbed SMPLer-X), with up to ViT-Huge as the backbone and training with up to 4.5M instances from diverse data sources. With big data and the large model, SMPLer-X exhibits strong performance across diverse test benchmarks and excellent transferability to even unseen environments. 1) For the data scaling, we perform a systematic investigation on 32 EHPS datasets, including a wide range of scenarios that a model trained on any single dataset cannot handle. More importantly, capitalizing on insights obtained from the extensive benchmarking process, we optimize our training scheme and select datasets that lead to a significant leap in EHPS capabilities. 2) For the model scaling, we take advantage of vision transformers to study the scaling law of model sizes in EHPS. Moreover, our finetuning strategy turn SMPLer-X into specialist models, allowing them to achieve further performance boosts. Notably, our foundation model SMPLer-X consistently delivers state-of-the-art results on seven benchmarks such as AGORA (107.2 …
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
Google's quantum supremacy announcement has received broad questions from academia and industry due to the debatable estimate of 10,000 years' running time for the classical simulation task on the Summit supercomputer. Has quantum supremacy already come? Or will it come in one or two decades later? To avoid hasty advertisements of quantum supremacy by tech giants or quantum startups and eliminate the cost of dedicating a team to the classical simulation task, we advocate an open-source approach to maintain a trustable benchmark performance. In this paper, we take a reinforcement learning approach for the classical simulation of quantum circuits and demonstrate its great potential by reporting an estimated simulation time of less than 4 days, a speedup of 5.40x over the state-of-the-art method. Specifically, we formulate the classical simulation task as a tensor network contraction ordering problem using the K-spin Ising model and employ a novel Hamiltonina-based reinforcement learning algorithm. Then, we establish standard criteria to evaluate the performance of classical simulation of quantum circuits. We develop a dozen of massively parallel environments to simulate quantum circuits. We open-source our parallel gym environments and benchmarks. We hope the AI/ML community and quantum physics community will collaborate to maintain reference curves …
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
A room’s acoustic properties are a product of the room’s geometry, the objects within the room, and their specific positions. A room’s acoustic properties can be characterized by its impulse response (RIR) between a source and listener location, or roughly inferred from recordings of natural signals present in the room. Variations in the positions of objects in a room can effect measurable changes in the room’s acoustic properties, as characterized by the RIR. Existing datasets of RIRs either do not systematically vary positions of objects in an environment, or they consist of only simulated RIRs. We present SoundCam, the largest dataset of unique RIRs from in-the-wild rooms publicly released to date. It includes 5,000 10-channel real-world measurements of room impulse responses and 2,000 10-channel recordings of music in three different rooms, including a controlled acoustic lab, an in-the-wild living room, and a conference room, with different humans in positions throughout each room. We show that these measurements can be used for interesting tasks, such as detecting and identifying humans, and tracking their positions.
[ Great Hall & Hall B1+B2 (level 1) ]
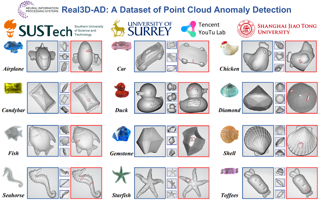
Abstract
[ Great Hall & Hall B1+B2 (level 1) ]
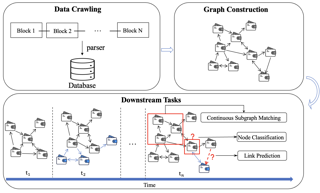
Abstract
Numerous studies have been conducted to investigate the properties of large-scale temporal graphs. Despite the ubiquity of these graphs in real-world scenarios, it's usually impractical for us to obtain the whole real-time graphs due to privacy concerns and technical limitations. In this paper, we introduce the concept of {\it Live Graph Lab} for temporal graphs, which enables open, dynamic and real transaction graphs from blockchains. Among them, Non-fungible tokens (NFTs) have become one of the most prominent parts of blockchain over the past several years. With more than \$40 billion market capitalization, this decentralized ecosystem produces massive, anonymous and real transaction activities, which naturally forms a complicated transaction network. However, there is limited understanding about the characteristics of this emerging NFT ecosystem from a temporal graph analysis perspective. To mitigate this gap, we instantiate a live graph with NFT transaction network and investigate its dynamics to provide new observations and insights. Specifically, through downloading and parsing the NFT transaction activities, we obtain a temporal graph with more than 4.5 million nodes and 124 million edges. Then, a series of measurements are presented to understand the properties of the NFT ecosystem. Through comparisons with social, citation, and web networks, our analyses …
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
This paper reexamines the research on out-of-distribution (OOD) robustness in the field of NLP. We find that the distribution shift settings in previous studies commonly lack adequate challenges, hindering the accurate evaluation of OOD robustness. To address these issues, we propose a benchmark construction protocol that ensures clear differentiation and challenging distribution shifts. Then we introduceBOSS, a Benchmark suite for Out-of-distribution robustneSS evaluation covering 5 tasks and 20 datasets. Based on BOSS, we conduct a series of experiments on pretrained language models for analysis and evaluation of OOD robustness. First, for vanilla fine-tuning, we examine the relationship between in-distribution (ID) and OOD performance. We identify three typical types that unveil the inner learningmechanism, which could potentially facilitate the forecasting of OOD robustness, correlating with the advancements on ID datasets. Then, we evaluate 5 classic methods on BOSS and find that, despite exhibiting some effectiveness in specific cases, they do not offer significant improvement compared to vanilla fine-tuning. Further, we evaluate 5 LLMs with various adaptation paradigms and find that when sufficient ID data is available, fine-tuning domain-specific models outperform LLMs on ID examples significantly. However, in the case of OOD instances, prioritizing LLMs with in-context learning yields better results. We …
[ Great Hall & Hall B1+B2 (level 1) ]
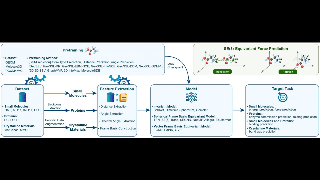
Abstract
Artificial intelligence for scientific discovery has recently generated significant interest within the machine learning and scientific communities, particularly in the domains of chemistry, biology, and material discovery. For these scientific problems, molecules serve as the fundamental building blocks, and machine learning has emerged as a highly effective and powerful tool for modeling their geometric structures. Nevertheless, due to the rapidly evolving process of the field and the knowledge gap between science ({\eg}, physics, chemistry, \& biology) and machine learning communities, a benchmarking study on geometrical representation for such data has not been conducted. To address such an issue, in this paper, we first provide a unified view of the current symmetry-informed geometric methods, classifying them into three main categories: invariance, equivariance with spherical frame basis, and equivariance with vector frame basis. Then we propose a platform, coined Geom3D, which enables benchmarking the effectiveness of geometric strategies. Geom3D contains 16 advanced symmetry-informed geometric representation models and 14 geometric pretraining methods over 52 diverse tasks, including small molecules, proteins, and crystalline materials. We hope that Geom3D can, on the one hand, eliminate barriers for machine learning researchers interested in exploring scientific problems; and, on the other hand, provide valuable guidance for researchers …
[ Great Hall & Hall B1+B2 (level 1) ]
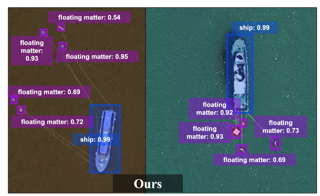
Abstract
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
Sign languages are used as a primary language by approximately 70 million D/deaf people world-wide. However, most communication technologies operate in spoken and written languages, creating inequities in access. To help tackle this problem, we release ASL Citizen, the first crowdsourced Isolated Sign Language Recognition (ISLR) dataset, collected with consent and containing 83,399 videos for 2,731 distinct signs filmed by 52 signers in a variety of environments. We propose that this dataset be used for sign language dictionary retrieval for American Sign Language (ASL), where a user demonstrates a sign to their webcam to retrieve matching signs from a dictionary. We show that training supervised machine learning classifiers with our dataset advances the state-of-the-art on metrics relevant for dictionary retrieval, achieving 63\% accuracy and a recall-at-10 of 91\%, evaluated entirely on videos of users who are not present in the training or validation sets.
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
We introduce MADLAD-400, a manually audited, general domain 3T token monolingual dataset based on CommonCrawl, spanning 419 languages. We discuss the limitations revealed by self-auditing MADLAD-400, and the role data auditing had in the dataset creation process. We then train and release a 10.7B-parameter multilingual machine translation model on 250 billion tokens covering over 450 languages using publicly available data, and find that it is competitive with models that are significantly larger, and report the results on different domains. In addition, we train a 8B-parameter language model, and assess the results on few-shot translation. We make the baseline models available to the research community.
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
We introduce Stanford-ORB, a new real-world 3D Object inverse Rendering Benchmark. Recent advances in inverse rendering have enabled a wide range of real-world applications in 3D content generation, moving rapidly from research and commercial use cases to consumer devices. While the results continue to improve, there is no real-world benchmark that can quantitatively assess and compare the performance of various inverse rendering methods. Existing real-world datasets typically only consist of the shape and multi-view images of objects, which are not sufficient for evaluating the quality of material recovery and object relighting. Methods capable of recovering material and lighting often resort to synthetic data for quantitative evaluation, which on the other hand does not guarantee generalization to complex real-world environments. We introduce a new dataset of real-world objects captured under a variety of natural scenes with ground-truth 3D scans, multi-view images, and environment lighting. Using this dataset, we establish the first comprehensive real-world evaluation benchmark for object inverse rendering tasks from in-the-wild scenes, and compare the performance of various existing methods. All data, code, and models can be accessed at https://stanfordorb.github.io/
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
Graph Neural Networks (GNNs) have emerged as the de facto standard for representation learning on graphs, owing to their ability to effectively integrate graph topology and node attributes. However, the inherent suboptimal nature of node connections, resulting from the complex and contingent formation process of graphs, presents significant challenges in modeling them effectively. To tackle this issue, Graph Structure Learning (GSL), a family of data-centric learning approaches, has garnered substantial attention in recent years. The core concept behind GSL is to jointly optimize the graph structure and the corresponding GNN models. Despite the proposal of numerous GSL methods, the progress in this field remains unclear due to inconsistent experimental protocols, including variations in datasets, data processing techniques, and splitting strategies. In this paper, we introduce OpenGSL, the first comprehensive benchmark for GSL, aimed at addressing this gap. OpenGSL enables a fair comparison among state-of-the-art GSL methods by evaluating them across various popular datasets using uniform data processing and splitting strategies. Through extensive experiments, we observe that existing GSL methods do not consistently outperform vanilla GNN counterparts. We also find that there is no significant correlation between the homophily of the learned structure and task performance, challenging the common belief. Moreover, …
[ Great Hall & Hall B1+B2 (level 1) ]
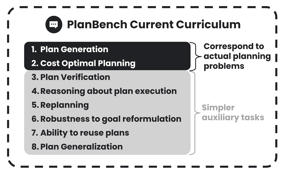
Abstract
Generating plans of action, and reasoning about change have long been considered a core competence of intelligent agents. It is thus no surprise that evaluating the planning and reasoning capabilities of large language models (LLMs) has become a hot topic of research. Most claims about LLM planning capabilities are however based on common sense tasks–where it becomes hard to tell whether LLMs are planning or merely retrieving from their vast world knowledge. There is a strong need for systematic and extensible planning benchmarks with sufficient diversity to evaluate whether LLMs have innate planning capabilities. Motivated by this, we propose PlanBench, an extensible benchmark suite based on the kinds of domains used in the automated planning community, especially in the International Planning Competition, to test the capabilities of LLMs in planning or reasoning about actions and change. PlanBench provides sufficient diversity in both the task domains and the specific planning capabilities. Our studies also show that on many critical capabilities–including plan generation–LLM performance falls quite short, even with the SOTA models. PlanBench can thus function as a useful marker of progress of LLMs in planning and reasoning.
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
The past decade has witnessed great strides in video recovery by specialist technologies, like video inpainting, completion, and error concealment. However, they typically simulate the missing content by manual-designed error masks, thus failing to fill in the realistic video loss in video communication (e.g., telepresence, live streaming, and internet video) and multimedia forensics. To address this, we introduce the bitstream-corrupted video (BSCV) benchmark, the first benchmark dataset with more than 28,000 video clips, which can be used for bitstream-corrupted video recovery in the real world. The BSCV is a collection of 1) a proposed three-parameter corruption model for video bitstream, 2) a large-scale dataset containing rich error patterns, multiple corruption levels, and flexible dataset branches, and 3) a new video recovery framework that serves as a benchmark. We evaluate state-of-the-art video inpainting methods on the BSCV dataset, demonstrating existing approaches' limitations and our framework's advantages in solving the bitstream-corrupted video recovery problem. The benchmark and dataset are released at https://github.com/LIUTIGHE/BSCV-Dataset.
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
This paper introduces Low-shot Object Learning with Mutual Exclusivity Bias (LSME), the first computational framing of mutual exclusivity bias, a phenomenon commonly observed in infants during word learning. We provide a novel dataset, comprehensive baselines, and a SOTA method to enable the ML community to tackle this challenging learning task. The goal of LSME is to analyze an RGB image of a scene containing multiple objects and correctly associate a previously-unknown object instance with a provided category label. This association is then used to perform low-shot learning to test category generalization. We provide a data generation pipeline for the LSME problem and conduct a thorough analysis of the factors that contribute to its difficulty. Additionally, we evaluate the performance of multiple baselines, including state-of-the-art foundation models. Finally, we present a baseline approach that outperforms state-of-the-art models in terms of low-shot accuracy. Code and data are available at https://github.com/rehg-lab/LSME.
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
CORL is an open-source library that provides thoroughly benchmarked single-file implementations of both deep offline and offline-to-online reinforcement learning algorithms. It emphasizes a simple developing experience with a straightforward codebase and a modern analysis tracking tool. In CORL, we isolate methods implementation into separate single files, making performance-relevant details easier to recognize. Additionally, an experiment tracking feature is available to help log metrics, hyperparameters, dependencies, and more to the cloud. Finally, we have ensured the reliability of the implementations by benchmarking commonly employed D4RL datasets providing a transparent source of results that can be reused for robust evaluation tools such as performance profiles, probability of improvement, or expected online performance.
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
Advancements in deep neural networks have allowed automatic speech recognition (ASR) systems to attain human parity on several publicly available clean speech datasets. However, even state-of-the-art ASR systems experience performance degradation when confronted with adverse conditions, as a well-trained acoustic model is sensitive to variations in the speech domain, e.g., background noise. Intuitively, humans address this issue by relying on their linguistic knowledge: the meaning of ambiguous spoken terms is usually inferred from contextual cues thereby reducing the dependency on the auditory system. Inspired by this observation, we introduce the first open-source benchmark to utilize external large language models (LLMs) for ASR error correction, where N-best decoding hypotheses provide informative elements for true transcription prediction. This approach is a paradigm shift from the traditional language model rescoring strategy that can only select one candidate hypothesis as output transcription. The proposed benchmark contains a novel dataset, "HyPoradise" (HP), encompassing more than 316,000 pairs of N-best hypotheses and corresponding accurate transcriptions across prevalent speech domains. Given this dataset, we examine three types of error correction techniques based on LLMs with varying amounts of labeled hypotheses-transcription pairs, which gains significant word error rate (WER) reduction. Experimental evidence demonstrates the proposed technique achieves a …
[ La Nouvelle Orleans Ballroom A-C (level 2) ]

Abstract
We introduce Mesogeos, a large-scale multi-purpose dataset for wildfire modeling in the Mediterranean. Mesogeos integrates variables representing wildfire drivers (meteorology, vegetation, human activity) and historical records of wildfire ignitions and burned areas for 17 years (2006-2022). It is designed as a cloud-friendly spatio-temporal dataset, namely a datacube, harmonizing all variables in a grid of 1km x 1km x 1-day resolution. The datacube structure offers opportunities to assess machine learning (ML) usage in various wildfire modeling tasks. We extract two ML-ready datasets that establish distinct tracks to demonstrate this potential: (1) short-term wildfire danger forecasting and (2) final burned area estimation given the point of ignition. We define appropriate metrics and baselines to evaluate the performance of models in each track. By publishing the datacube, along with the code to create the ML datasets and models, we encourage the community to foster the implementation of additional tracks for mitigating the increasing threat of wildfires in the Mediterranean.
[ La Nouvelle Orleans Ballroom A-C (level 2) ]
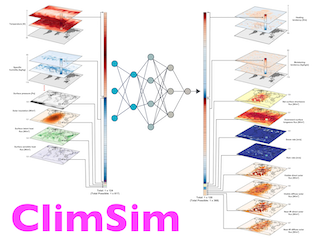
Abstract
Modern climate projections lack adequate spatial and temporal resolution due to computational constraints. A consequence is inaccurate and imprecise predictions of critical processes such as storms. Hybrid methods that combine physics with machine learning (ML) have introduced a new generation of higher fidelity climate simulators that can sidestep Moore's Law by outsourcing compute-hungry, short, high-resolution simulations to ML emulators. However, this hybrid ML-physics simulation approach requires domain-specific treatment and has been inaccessible to ML experts because of lack of training data and relevant, easy-to-use workflows. We present ClimSim, the largest-ever dataset designed for hybrid ML-physics research. It comprises multi-scale climate simulations, developed by a consortium of climate scientists and ML researchers. It consists of 5.7 billion pairs of multivariate input and output vectors that isolate the influence of locally-nested, high-resolution, high-fidelity physics on a host climate simulator's macro-scale physical state.The dataset is global in coverage, spans multiple years at high sampling frequency, and is designed such that resulting emulators are compatible with downstream coupling into operational climate simulators. We implement a range of deterministic and stochastic regression baselines to highlight the ML challenges and their scoring. The data (https://huggingface.co/datasets/LEAP/ClimSim_high-res) and code (https://leap-stc.github.io/ClimSim) are released openly to support the development of …
[ La Nouvelle Orleans Ballroom A-C (level 2) ]
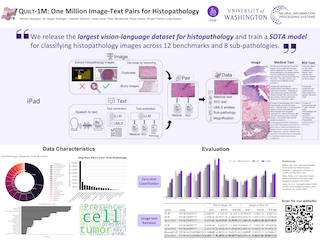
Abstract
[ La Nouvelle Orleans Ballroom A-C (level 2) ]
Abstract
The MineRL BASALT competition has served to catalyze advances in learning from human feedback through four hard-to-specify tasks in Minecraft, such as create and photograph a waterfall. Given the completion of two years of BASALT competitions, we offer to the community a formalized benchmark through the BASALT Evaluation and Demonstrations Dataset (BEDD), which serves as a resource for algorithm development and performance assessment. BEDD consists of a collection of 26 million image-action pairs from nearly 14,000 videos of human players completing the BASALT tasks in Minecraft. It also includes over 3,000 dense pairwise human evaluations of human and algorithmic agents. These comparisons serve as a fixed, preliminary leaderboard for evaluating newly-developed algorithms. To enable this comparison, we present a streamlined codebase for benchmarking new algorithms against the leaderboard. In addition to presenting these datasets, we conduct a detailed analysis of the data from both datasets to guide algorithm development and evaluation. The released code and data are available at https://github.com/minerllabs/basalt-benchmark.
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
Modern climate projections lack adequate spatial and temporal resolution due to computational constraints. A consequence is inaccurate and imprecise predictions of critical processes such as storms. Hybrid methods that combine physics with machine learning (ML) have introduced a new generation of higher fidelity climate simulators that can sidestep Moore's Law by outsourcing compute-hungry, short, high-resolution simulations to ML emulators. However, this hybrid ML-physics simulation approach requires domain-specific treatment and has been inaccessible to ML experts because of lack of training data and relevant, easy-to-use workflows. We present ClimSim, the largest-ever dataset designed for hybrid ML-physics research. It comprises multi-scale climate simulations, developed by a consortium of climate scientists and ML researchers. It consists of 5.7 billion pairs of multivariate input and output vectors that isolate the influence of locally-nested, high-resolution, high-fidelity physics on a host climate simulator's macro-scale physical state.The dataset is global in coverage, spans multiple years at high sampling frequency, and is designed such that resulting emulators are compatible with downstream coupling into operational climate simulators. We implement a range of deterministic and stochastic regression baselines to highlight the ML challenges and their scoring. The data (https://huggingface.co/datasets/LEAP/ClimSim_high-res) and code (https://leap-stc.github.io/ClimSim) are released openly to support the development of …
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
Machine learning based decision-support tools in criminal justice systems are subjects of intense discussions and academic research. There are important open questions about the utility and fairness of such tools. Academic researchers often rely on a few small datasets that are not sufficient to empirically study various real-world aspects of these questions. In this paper, we contribute WCLD, a curated large dataset of 1.5 million criminal cases from circuit courts in the U.S. state of Wisconsin. We used reliable public data from 1970 to 2020 to curate attributes like prior criminal counts and recidivism outcomes. The dataset contains large number of samples from five racial groups, in addition to information like sex and age (at judgment and first offense). Other attributes in this dataset include neighborhood characteristics obtained from census data, detailed types of offense, charge severity, case decisions, sentence lengths, year of filing etc. We also provide pseudo-identifiers for judge, county and zipcode. The dataset will not only enable researchers to more rigorously study algorithmic fairness in the context of criminal justice, but also relate algorithmic challenges with various systemic issues. We also discuss in detail the process of constructing the dataset and provide a datasheet. The WCLD dataset …
[ Great Hall & Hall B1+B2 (level 1) ]
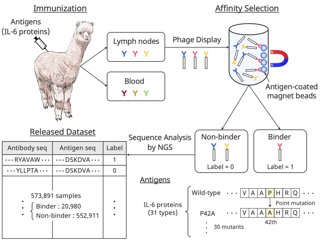
Abstract
Antibodies have become an important class of therapeutic agents to treat human diseases.To accelerate therapeutic antibody discovery, computational methods, especially machine learning, have attracted considerable interest for predicting specific interactions between antibody candidates and target antigens such as viruses and bacteria.However, the publicly available datasets in existing works have notable limitations, such as small sizes and the lack of non-binding samples and exact amino acid sequences.To overcome these limitations, we have developed AVIDa-hIL6, a large-scale dataset for predicting antigen-antibody interactions in the variable domain of heavy chain of heavy chain antibodies (VHHs), produced from an alpaca immunized with the human interleukin-6 (IL-6) protein, as antigens.By leveraging the simple structure of VHHs, which facilitates identification of full-length amino acid sequences by DNA sequencing technology, AVIDa-hIL6 contains 573,891 antigen-VHH pairs with amino acid sequences.All the antigen-VHH pairs have reliable labels for binding or non-binding, as generated by a novel labeling method.Furthermore, via introduction of artificial mutations, AVIDa-hIL6 contains 30 different mutants in addition to wild-type IL-6 protein.This characteristic provides opportunities to develop machine learning models for predicting changes in antibody binding by antigen mutations.We report experimental benchmark results on AVIDa-hIL6 by using machine learning models.The results indicate that the existing models have …
[ Great Hall & Hall B1+B2 (level 1) ]
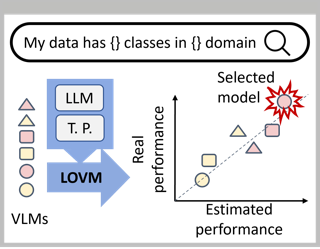
Abstract
Pre-trained multi-modal vision-language models (VLMs) are becoming increasingly popular due to their exceptional performance on downstream vision applications, particularly in the few- and zero-shot settings. However, selecting the best-performing VLM for some downstream applications is non-trivial, as it is dataset and task-dependent. Meanwhile, the exhaustive evaluation of all available VLMs on a novel application is not only time and computationally demanding but also necessitates the collection of a labeled dataset for evaluation. As the number of open-source VLM variants increases, there is a need for an efficient model selection strategy that does not require access to a curated evaluation dataset. This paper proposes a novel task and benchmark for efficiently evaluating VLMs' zero-shot performance on downstream applications without access to the downstream task dataset. Specifically, we introduce a new task LOVM: Language-Only Vision Model Selection , where methods are expected to perform both model selection and performance prediction based solely on a text description of the desired downstream application. We then introduced an extensive LOVM benchmark consisting of ground-truth evaluations of 35 pre-trained VLMs and 23 datasets, where methods are expected to rank the pre-trained VLMs and predict their zero-shot performance.
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
The MineRL BASALT competition has served to catalyze advances in learning from human feedback through four hard-to-specify tasks in Minecraft, such as create and photograph a waterfall. Given the completion of two years of BASALT competitions, we offer to the community a formalized benchmark through the BASALT Evaluation and Demonstrations Dataset (BEDD), which serves as a resource for algorithm development and performance assessment. BEDD consists of a collection of 26 million image-action pairs from nearly 14,000 videos of human players completing the BASALT tasks in Minecraft. It also includes over 3,000 dense pairwise human evaluations of human and algorithmic agents. These comparisons serve as a fixed, preliminary leaderboard for evaluating newly-developed algorithms. To enable this comparison, we present a streamlined codebase for benchmarking new algorithms against the leaderboard. In addition to presenting these datasets, we conduct a detailed analysis of the data from both datasets to guide algorithm development and evaluation. The released code and data are available at https://github.com/minerllabs/basalt-benchmark.
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
We introduce Mesogeos, a large-scale multi-purpose dataset for wildfire modeling in the Mediterranean. Mesogeos integrates variables representing wildfire drivers (meteorology, vegetation, human activity) and historical records of wildfire ignitions and burned areas for 17 years (2006-2022). It is designed as a cloud-friendly spatio-temporal dataset, namely a datacube, harmonizing all variables in a grid of 1km x 1km x 1-day resolution. The datacube structure offers opportunities to assess machine learning (ML) usage in various wildfire modeling tasks. We extract two ML-ready datasets that establish distinct tracks to demonstrate this potential: (1) short-term wildfire danger forecasting and (2) final burned area estimation given the point of ignition. We define appropriate metrics and baselines to evaluate the performance of models in each track. By publishing the datacube, along with the code to create the ML datasets and models, we encourage the community to foster the implementation of additional tracks for mitigating the increasing threat of wildfires in the Mediterranean.
[ La Nouvelle Orleans Ballroom A-C (level 2) ]

Abstract
Human-centric computer vision (HCCV) data curation practices often neglect privacy and bias concerns, leading to dataset retractions and unfair models. HCCV datasets constructed through nonconsensual web scraping lack crucial metadata for comprehensive fairness and robustness evaluations. Current remedies are post hoc, lack persuasive justification for adoption, or fail to provide proper contextualization for appropriate application. Our research focuses on proactive, domain-specific recommendations, covering purpose, privacy and consent, and diversity, for curating HCCV evaluation datasets, addressing privacy and bias concerns. We adopt an ante hoc reflective perspective, drawing from current practices, guidelines, dataset withdrawals, and audits, to inform our considerations and recommendations.
[ Room R06-R09 (level 2) ]
Abstract
Multimodal datasets are a critical component in recent breakthroughs such as CLIP, Stable Diffusion and GPT-4, yet their design does not receive the same research attention as model architectures or training algorithms. To address this shortcoming in the machine learning ecosystem, we introduce DataComp, a testbed for dataset experiments centered around a new candidate pool of 12.8 billion image-text pairs from Common Crawl. Participants in our benchmark design new filtering techniques or curate new data sources and then evaluate their new dataset by running our standardized CLIP training code and testing the resulting model on 38 downstream test sets. Our benchmark consists of multiple compute scales spanning four orders of magnitude, which enables the study of scaling trends and makes the benchmark accessible to researchers with varying resources. Our baseline experiments show that the DataComp workflow leads to better training sets. Our best baseline, DataComp-1B, enables training a CLIP ViT-L/14 from scratch to 79.2% zero-shot accuracy on ImageNet, outperforming OpenAI's CLIP ViT-L/14 by 3.7 percentage points while using the same training procedure and compute. We release \datanet and all accompanying code at www.datacomp.ai.
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
Understanding the behavior of non-human primates is crucial for improving animal welfare, modeling social behavior, and gaining insights into distinctively human and phylogenetically shared behaviors. However, the lack of datasets on non-human primate behavior hinders in-depth exploration of primate social interactions, posing challenges to research on our closest living relatives. To address these limitations, we present ChimpACT, a comprehensive dataset for quantifying the longitudinal behavior and social relations of chimpanzees within a social group. Spanning from 2015 to 2018, ChimpACT features videos of a group of over 20 chimpanzees residing at the Leipzig Zoo, Germany, with a particular focus on documenting the developmental trajectory of one young male, Azibo. ChimpACT is both comprehensive and challenging, consisting of 163 videos with a cumulative 160,500 frames, each richly annotated with detection, identification, pose estimation, and fine-grained spatiotemporal behavior labels. We benchmark representative methods of three tracks on ChimpACT: (i) tracking and identification, (ii) pose estimation, and (iii) spatiotemporal action detection of the chimpanzees. Our experiments reveal that ChimpACT offers ample opportunities for both devising new methods and adapting existing ones to solve fundamental computer vision tasks applied to chimpanzee groups, such as detection, pose estimation, and behavior analysis, ultimately deepening our comprehension …
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
Recent progress in generative artificial intelligence (gen-AI) has enabled the generation of photo-realistic and artistically-inspiring photos at a single click, catering to millions of users online. To explore how people use gen-AI models such as DALLE and StableDiffusion, it is critical to understand the themes, contents, and variations present in the AI-generated photos. In this work, we introduce TWIGMA (TWItter Generative-ai images with MetadatA), a comprehensive dataset encompassing over 800,000 gen-AI images collected from Jan 2021 to March 2023 on Twitter, with associated metadata (e.g., tweet text, creation date, number of likes). Through a comparative analysis of TWIGMA with natural images and human artwork, we find that gen-AI images possess distinctive characteristics and exhibit, on average, lower variability when compared to their non-gen-AI counterparts. Additionally, we find that the similarity between a gen-AI image and natural images is inversely correlated with the number of likes. Finally, we observe a longitudinal shift in the themes of AI-generated images on Twitter, with users increasingly sharing artistically sophisticated content such as intricate human portraits, whereas their interest in simple subjects such as natural scenes and animals has decreased. Our analyses and findings underscore the significance of TWIGMA as a unique data resource for …
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
New NLP benchmarks are urgently needed to align with the rapid development of large language models (LLMs). We present C-Eval, the first comprehensive Chinese evaluation suite designed to assess advanced knowledge and reasoning abilities of foundation models in a Chinese context. C-Eval comprises multiple-choice questions across four difficulty levels: middle school, high school, college, and professional. The questions span 52 diverse disciplines, ranging from humanities to science and engineering. C-Eval is accompanied by C-Eval Hard, a subset of very challenging subjects in C-Eval that requires advanced reasoning abilities to solve. We conduct a comprehensive evaluation of the most advanced LLMs on C-Eval, including both English- and Chinese-oriented models. Results indicate that only GPT-4 could achieve an average accuracy of over 60%, suggesting that there is still significant room for improvement for current LLMs. We anticipate C-Eval will help analyze important strengths and shortcomings of foundation models, and foster their development and growth for Chinese users.
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
Labeling neural network submodules with human-legible descriptions is useful for many downstream tasks: such descriptions can surface failures, guide interventions, and perhaps even explain important model behaviors. To date, most mechanistic descriptions of trained networks have involved small models, narrowly delimited phenomena, and large amounts of human labor. Labeling all human-interpretable sub-computations in models of increasing size and complexity will almost certainly require tools that can generate and validate descriptions automatically. Recently, techniques that use learned models in-the-loop for labeling have begun to gain traction, but methods for evaluating their efficacy are limited and ad-hoc. How should we validate and compare open-ended labeling tools? This paper introduces FIND (Function INterpretation and Description), a benchmark suite for evaluating the building blocks of automated interpretability methods. FIND contains functions that resemble components of trained neural networks, and accompanying descriptions of the kind we seek to generate. The functions are procedurally constructed across textual and numeric domains, and involve a range of real-world complexities, including noise, composition, approximation, and bias. We evaluate methods that use pretrained language models (LMs) to produce code-based and natural language descriptions of function behavior. Additionally, we introduce a new interactive method in which an Automated Interpretability Agent (AIA) …
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
Human-centric computer vision (HCCV) data curation practices often neglect privacy and bias concerns, leading to dataset retractions and unfair models. HCCV datasets constructed through nonconsensual web scraping lack crucial metadata for comprehensive fairness and robustness evaluations. Current remedies are post hoc, lack persuasive justification for adoption, or fail to provide proper contextualization for appropriate application. Our research focuses on proactive, domain-specific recommendations, covering purpose, privacy and consent, and diversity, for curating HCCV evaluation datasets, addressing privacy and bias concerns. We adopt an ante hoc reflective perspective, drawing from current practices, guidelines, dataset withdrawals, and audits, to inform our considerations and recommendations.
[ Great Hall & Hall B1+B2 (level 1) ]
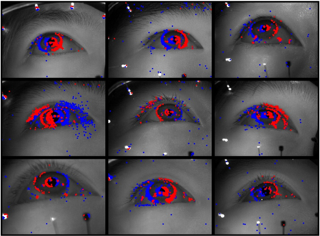
Abstract
In this paper, we present EV-Eye, a first-of-its-kind large scale multimodal eye tracking dataset aimed at inspiring research on high-frequency eye/gaze tracking. EV-Eye utilizes an emerging bio-inspired event camera to capture independent pixel-level intensity changes induced by eye movements, achieving sub-microsecond latency. Our dataset was curated over a two-week period and collected from 48 participants encompassing diverse genders and age groups. It comprises over 1.5 million near-eye grayscale images and 2.7 billion event samples generated by two DAVIS346 event cameras. Additionally, the dataset contains 675 thousands scene images and 2.7 million gaze references captured by Tobii Pro Glasses 3 eye tracker for cross-modality validation. Compared with existing event-based high-frequency eye tracking datasets, our dataset is significantly larger in size, and the gaze references involve more natural eye movement patterns, i.e., fixation, saccade and smooth pursuit. Alongside the event data, we also present a hybrid eye tracking method as benchmark, which leverages both the near-eye grayscale images and event data for robust and high-frequency eye tracking. We show that our method achieves higher accuracy for both pupil and gaze estimation tasks compared to the existing solution.
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
Multimodal datasets are a critical component in recent breakthroughs such as CLIP, Stable Diffusion and GPT-4, yet their design does not receive the same research attention as model architectures or training algorithms. To address this shortcoming in the machine learning ecosystem, we introduce DataComp, a testbed for dataset experiments centered around a new candidate pool of 12.8 billion image-text pairs from Common Crawl. Participants in our benchmark design new filtering techniques or curate new data sources and then evaluate their new dataset by running our standardized CLIP training code and testing the resulting model on 38 downstream test sets. Our benchmark consists of multiple compute scales spanning four orders of magnitude, which enables the study of scaling trends and makes the benchmark accessible to researchers with varying resources. Our baseline experiments show that the DataComp workflow leads to better training sets. Our best baseline, DataComp-1B, enables training a CLIP ViT-L/14 from scratch to 79.2% zero-shot accuracy on ImageNet, outperforming OpenAI's CLIP ViT-L/14 by 3.7 percentage points while using the same training procedure and compute. We release \datanet and all accompanying code at www.datacomp.ai.
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
Supervised machine learning approaches have been increasingly used in accelerating electronic structure prediction as surrogates of first-principle computational methods, such as density functional theory (DFT). While numerous quantum chemistry datasets focus on chemical properties and atomic forces, the ability to achieve accurate and efficient prediction of the Hamiltonian matrix is highly desired, as it is the most important and fundamental physical quantity that determines the quantum states of physical systems and chemical properties. In this work, we generate a new Quantum Hamiltonian dataset, named as QH9, to provide precise Hamiltonian matrices for 2,399 molecular dynamics trajectories and 130,831 stable molecular geometries, based on the QM9 dataset. By designing benchmark tasks with various molecules, we show that current machine learning models have the capacity to predict Hamiltonian matrices for arbitrary molecules. Both the QH9 dataset and the baseline models are provided to the community through an open-source benchmark, which can be highly valuable for developing machine learning methods and accelerating molecular and materials design for scientific and technological applications. Our benchmark is publicly available at \url{https://github.com/divelab/AIRS/tree/main/OpenDFT/QHBench}.
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
Innovation is a major driver of economic and social development, and information about many kinds of innovation is embedded in semi-structured data from patents and patent applications. Though the impact and novelty of innovations expressed in patent data are difficult to measure through traditional means, machine learning offers a promising set of techniques for evaluating novelty, summarizing contributions, and embedding semantics. In this paper, we introduce the Harvard USPTO Patent Dataset (HUPD), a large-scale, well-structured, and multi-purpose corpus of English-language patent applications filed to the United States Patent and Trademark Office (USPTO) between 2004 and 2018. With more than 4.5 million patent documents, HUPD is two to three times larger than comparable corpora. Unlike other NLP patent datasets, HUPD contains the inventor-submitted versions of patent applications, not the final versions of granted patents, allowing us to study patentability at the time of filing using NLP methods for the first time. It is also novel in its inclusion of rich structured data alongside the text of patent filings: By providing each application’s metadata along with all of its text fields, HUPD enables researchers to perform new sets of NLP tasks that leverage variation in structured covariates. As a case study on …
[ La Nouvelle Orleans Ballroom A-C (level 2) ]
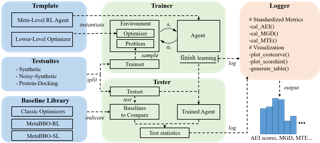
Abstract
Recently, Meta-Black-Box Optimization with Reinforcement Learning (MetaBBO-RL) has showcased the power of leveraging RL at the meta-level to mitigate manual fine-tuning of low-level black-box optimizers. However, this field is hindered by the lack of a unified benchmark. To fill this gap, we introduce MetaBox, the first benchmark platform expressly tailored for developing and evaluating MetaBBO-RL methods. MetaBox offers a flexible algorithmic template that allows users to effortlessly implement their unique designs within the platform. Moreover, it provides a broad spectrum of over 300 problem instances, collected from synthetic to realistic scenarios, and an extensive library of 19 baseline methods, including both traditional black-box optimizers and recent MetaBBO-RL methods. Besides, MetaBox introduces three standardized performance metrics, enabling a more thorough assessment of the methods. In a bid to illustrate the utility of MetaBox for facilitating rigorous evaluation and in-depth analysis, we carry out a wide-ranging benchmarking study on existing MetaBBO-RL methods. Our MetaBox is open-source and accessible at: https://github.com/GMC-DRL/MetaBox.
[ Great Hall & Hall B1+B2 (level 1) ]
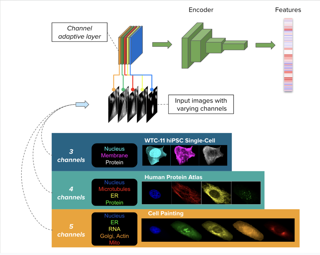
Abstract
Most neural networks assume that input images have a fixed number of channels (three for RGB images). However, there are many settings where the number of channels may vary, such as microscopy images where the number of channels changes depending on instruments and experimental goals. Yet, there has not been a systemic attempt to create and evaluate neural networks that are invariant to the number and type of channels. As a result, trained models remain specific to individual studies and are hardly reusable for other microscopy settings. In this paper, we present a benchmark for investigating channel-adaptive models in microscopy imaging, which consists of 1) a dataset of varied-channel single-cell images, and 2) a biologically relevant evaluation framework. In addition, we adapted several existing techniques to create channel-adaptive models and compared their performance on this benchmark to fixed-channel, baseline models. We find that channel-adaptive models can generalize better to out-of-domain tasks and can be computationally efficient. We contribute a curated dataset and an evaluation API to facilitate objective comparisons in future research and applications.
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
Recent breakthroughs in diffusion models, multimodal pretraining, and efficient finetuning have led to an explosion of text-to-image generative models. Given human evaluation is expensive and difficult to scale, automated methods are critical for evaluating the increasingly large number of new models. However, most current automated evaluation metrics like FID or CLIPScore only offer a distribution-level measure of image quality or image-text alignment, and are unsuited for fine-grained or instance-level analysis. In this paper, we introduce GenEval, an object-focused framework to evaluate compositional image properties such as object co-occurrence, position, count, and color. We show that current object detection models can be leveraged to evaluate text-to-image models on a variety of generation tasks with strong human agreement, and that other discriminative vision models can be linked to this pipeline to further verify properties like object color. We then evaluate several open-source text-to-image models and analyze their relative reasoning capabilities on our benchmark. We find that recent models demonstrate significant improvement on these tasks, though they are still lacking in complex capabilities such as spatial relations and attribute binding. Finally, we demonstrate how GenEval might be used to help discover existing failure modes, in order to inform development of the next generation …
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
As extreme weather events become more frequent, understanding their impact on human health becomes increasingly crucial. However, the utilization of Earth Observation to effectively analyze the environmental context in relation to health remains limited. This limitation is primarily due to the lack of fine-grained spatial and temporal data in public and population health studies, hindering a comprehensive understanding of health outcomes. Additionally, obtaining appropriate environmental indices across different geographical levels and timeframes poses a challenge. For the years 2019 (pre-COVID) and 2020 (COVID), we collected spatio-temporal indicators for all Lower Layer Super Output Areas in England. These indicators included: i) 111 sociodemographic features linked to health in existing literature, ii) 43 environmental point features (e.g., greenery and air pollution levels), iii) 4 seasonal composite satellite images each with 11 bands, and iv) prescription prevalence associated with five medical conditions (depression, anxiety, diabetes, hypertension, and asthma), opioids and total prescriptions. We combined these indicators into a single MedSat dataset, the availability of which presents an opportunity for the machine learning community to develop new techniques specific to public health. These techniques would address challenges such as handling large and complex data volumes, performing effective feature engineering on environmental and sociodemographic factors, …
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
Large multimodal models trained on natural documents, which interleave images and text, outperform models trained on image-text pairs on various multimodal benchmarks. However, the datasets used to train these models have not been released, and the collection process has not been fully specified. We introduce the OBELICS dataset, an open web-scale filtered dataset of interleaved image-text documents comprising 141 million web pages extracted from Common Crawl, 353 million associated images, and 115 billion text tokens. We describe the dataset creation process, present comprehensive filtering rules, and provide an analysis of the dataset's content. To show the viability of OBELICS, we train on the dataset vision and language models of 9 and 80 billion parameters, IDEFICS-9B and IDEFICS, and obtain competitive performance on different multimodal benchmarks. We release our dataset, models and code.
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
To generate evidence regarding the safety and efficacy of artificial intelligence (AI) enabled medical devices, AI models need to be evaluated on a diverse population of patient cases, some of which may not be readily available. We propose an evaluation approach for testing medical imaging AI models that relies on in silico imaging pipelines in which stochastic digital models of human anatomy (in object space) with and without pathology are imaged using a digital replica imaging acquisition system to generate realistic synthetic image datasets. Here, we release M-SYNTH, a dataset of cohorts with four breast fibroglandular density distributions imaged at different exposure levels using Monte Carlo x-ray simulations with the publicly available Virtual Imaging Clinical Trial for Regulatory Evaluation (VICTRE) toolkit. We utilize the synthetic dataset to analyze AI model performance and find that model performance decreases with increasing breast density and increases with higher mass density, as expected. As exposure levels decrease, AI model performance drops with the highest performance achieved at exposure levels lower than the nominal recommended dose for the breast type.
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
Systematic literature reviews (SLRs) play an essential role in summarising, synthesising and validating scientific evidence. In recent years, there has been a growing interest in using machine learning techniques to automate the identification of relevant studies for SLRs. However, the lack of standardised evaluation datasets makes comparing the performance of such automated literature screening systems difficult. In this paper, we analyse the citation screening evaluation datasets, revealing that many of the available datasets are either too small, suffer from data leakage or have limited applicability to systems treating automated literature screening as a classification task, as opposed to, for example, a retrieval or question-answering task. To address these challenges, we introduce CSMED, a meta-dataset consolidating nine publicly released collections, providing unified access to 325 SLRs from the fields of medicine and computer science. CSMED serves as a comprehensive resource for training and evaluating the performance of automated citation screening models. Additionally, we introduce CSMED-FT, a new dataset designed explicitly for evaluating the full text publication screening task. To demonstrate the utility of CSMED, we conduct experiments and establish baselines on new datasets.
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
The healthcare and AI communities have witnessed a growing interest in the development of AI-assisted systems for automated diagnosis of Parkinson's Disease (PD), one of the most prevalent neurodegenerative disorders. However, the progress in this area has been significantly impeded by the absence of a unified, publicly available benchmark, which prevents comprehensive evaluation of existing PD analysis methods and the development of advanced models. This work overcomes these challenges by introducing YouTubePD -- the first publicly available multimodal benchmark designed for PD analysis. We crowd-source existing videos featured with PD from YouTube, exploit multimodal information including in-the-wild videos, audio data, and facial landmarks across 200+ subject videos, and provide dense and diverse annotations from clinical expert. Based on our benchmark, we propose three challenging and complementary tasks encompassing both discriminative and generative tasks, along with a comprehensive set of corresponding baselines. Experimental evaluation showcases the potential of modern deep learning and computer vision techniques, in particular the generalizability of the models developed on YouTubePD to real-world clinical settings, while revealing their limitations. We hope our work paves the way for future research in this direction.
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
Assessing factuality of text generated by large language models (LLMs) is an emerging yet crucial research area, aimed at alerting users to potential errors and guiding the development of more reliable LLMs. Nonetheless, the evaluators assessing factuality necessitate suitable evaluation themselves to gauge progress and foster advancements. This direction remains under-explored, resulting in substantial impediments to the progress of factuality evaluators. To mitigate this issue, we introduce a benchmark for Factuality Evaluation of large Language Models, referred to as FELM. In this benchmark, we collect responses generated from LLMs and annotate factuality labels in a fine-grained manner. Contrary to previous studies that primarily concentrate on the factuality of world knowledge (e.g. information from Wikipedia), FELM focuses on factuality across diverse domains, spanning from world knowledge to math and reasoning. Our annotation is based on text segments, which can help pinpoint specific factual errors. The factuality annotations are further supplemented by predefined error types and reference links that either support or contradict the statement. In our experiments, we investigate the performance of several LLM-based factuality evaluators on FELM, including both vanilla LLMs and those augmented with retrieval mechanisms and chain-of-thought processes. Our findings reveal that while retrieval aids factuality evaluation, current …
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
We introduce the French Land cover from Aerospace ImageRy (FLAIR), an extensive dataset from the French National Institute of Geographical and Forest Information (IGN) that provides a unique and rich resource for large-scale geospatial analysis. FLAIR contains high-resolution aerial imagery with a ground sample distance of 20 cm and over 20 billion individually labeled pixels for precise land-cover classification. The dataset also integrates temporal and spectral data from optical satellite time series. FLAIR thus combines data with varying spatial, spectral, and temporal resolutions across over 817 km² of acquisitions representing the full landscape diversity of France. This diversity makes FLAIR a valuable resource for the development and evaluation of novel methods for large-scale land-cover semantic segmentation and raises significant challenges in terms of computer vision, data fusion, and geospatial analysis. We also provide powerful uni- and multi-sensor baseline models that can be employed to assess algorithm's performance and for downstream applications.
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
Minimally-invasive surgery (MIS) and robot-assisted minimally invasive (RAMIS) surgery offer well-documented benefits to patients such as reduced post-operative pain and shorter hospital stays.However, the automation of MIS and RAMIS through the use of AI has been slow due to difficulties in data acquisition and curation, partially caused by the ethical considerations of training, testing and deploying AI models in medical environments.We introduce \texttt{SARAMIS}, the first large-scale dataset of anatomically derived 3D rendering assets of the human abdominal anatomy.Using previously existing, open-source CT datasets of the human anatomy, we derive novel 3D meshes, tetrahedral volumes, textures and diffuse maps for over 104 different anatomical targets in the human body, representing the largest, open-source dataset of 3D rendering assets for synthetic simulation of vision tasks in MIS+RAMIS, increasing the availability of openly available 3D meshes in the literature by three orders of magnitude.We supplement our dataset with a series of GPU-enabled rendering environments, which can be used to generate datasets for realistic MIS/RAMIS tasks.Finally, we present an example of the use of \texttt{SARAMIS} assets for an autonomous navigation task in colonoscopy from CT abdomen-pelvis scans for the first time in the literature.\texttt{SARAMIS} is publically made available at https://github.com/NMontanaBrown/saramis/, with assets released under …
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
Generative, pre-trained transformers (GPTs, a type of "Foundation Models") have reshaped natural language processing (NLP) through their versatility in diverse downstream tasks. However, their potential extends far beyond NLP. This paper provides a software utility to help realize this potential, extending the applicability of GPTs to continuous-time sequences of complex events with internal dependencies, such as medical record datasets. Despite their potential, the adoption of foundation models in these domains has been hampered by the lack of suitable tools for model construction and evaluation. To bridge this gap, we introduce Event Stream GPT (ESGPT), an open-source library designed to streamline the end-to-end process for building GPTs for continuous-time event sequences. ESGPT allows users to (1) build flexible, foundation-model scale input datasets by specifying only a minimal configuration file, (2) leverage a Hugging Face compatible modeling API for GPTs over this modality that incorporates intra-event causal dependency structures and autoregressive generation capabilities, and (3) evaluate models via standardized processes that can assess few and even zero-shot performance of pre-trained models on user-specified fine-tuning tasks.
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
We introduce Dataset Grouper, a library to create large-scale group-structured (e.g., federated) datasets, enabling federated learning simulation at the scale of foundation models. This library facilitates the creation of group-structured versions of existing datasets based on user-specified partitions, and directly leads to a variety of useful heterogeneous datasets that can be plugged into existing software frameworks. Dataset Grouper offers three key advantages. First, it scales to settings where even a single group's dataset is too large to fit in memory. Second, it provides flexibility, both in choosing the base (non-partitioned) dataset and in defining partitions. Finally, it is framework-agnostic. We empirically demonstrate that Dataset Grouper enables large-scale federated language modeling simulations on datasets that are orders of magnitude larger than in previous work, allowing for federated training of language models with hundreds of millions, and even billions, of parameters. Our experimental results show that algorithms like FedAvg operate more as meta-learning methods than as empirical risk minimization methods at this scale, suggesting their utility in downstream personalization and task-specific adaptation. Dataset Grouper is available at https://github.com/google-research/dataset_grouper.
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
Robotic perception requires the modeling of both 3D geometry and semantics. Existing methods typically focus on estimating 3D bounding boxes, neglecting finer geometric details and struggling to handle general, out-of-vocabulary objects. 3D occupancy prediction, which estimates the detailed occupancy states and semantics of a scene, is an emerging task to overcome these limitations.To support 3D occupancy prediction, we develop a label generation pipeline that produces dense, visibility-aware labels for any given scene. This pipeline comprises three stages: voxel densification, occlusion reasoning, and image-guided voxel refinement. We establish two benchmarks, derived from the Waymo Open Dataset and the nuScenes Dataset, namely Occ3D-Waymo and Occ3D-nuScenes benchmarks. Furthermore, we provide an extensive analysis of the proposed dataset with various baseline models. Lastly, we propose a new model, dubbed Coarse-to-Fine Occupancy (CTF-Occ) network, which demonstrates superior performance on the Occ3D benchmarks.The code, data, and benchmarks are released at \url{https://tsinghua-mars-lab.github.io/Occ3D/}.
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
Natural language processing and 2D vision models have attained remarkable proficiency on many tasks primarily by escalating the scale of training data. However, 3D vision tasks have not seen the same progress, in part due to the challenges of acquiring high-quality 3D data. In this work, we present Objaverse-XL, a dataset of over 10 million 3D objects. Our compilation comprises deduplicated 3D objects from a diverse set of sources, including manually designed objects, photogrammetry scans of landmarks and everyday items, and professional scans of historic and antique artifacts. Representing the largest scale and diversity in the realm of 3D datasets, Objaverse-XL enables significant new possibilities for 3D vision. Our experiments demonstrate the vast improvements enabled with the scale provided by Objaverse-XL. We show that by training Zero123 on novel view synthesis, utilizing over 100 million multi-view rendered images, we achieve strong zero-shot generalization abilities. We hope that releasing Objaverse-XL will enable further innovations in the field of 3D vision at scale.
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
Short-term forecasting of residential and commercial building energy consumption is widely used in power systems and continues to grow in importance. Data-driven short-term load forecasting (STLF), although promising, has suffered from a lack of open, large-scale datasets with high building diversity. This has hindered exploring the pretrain-then-fine-tune paradigm for STLF. To help address this, we present BuildingsBench, which consists of: 1) Buildings-900K, a large-scale dataset of 900K simulated buildings representing the U.S. building stock; and 2) an evaluation platform with over 1,900 real residential and commercial buildings from 7 open datasets. BuildingsBench benchmarks two under-explored tasks: zero-shot STLF, where a pretrained model is evaluated on unseen buildings without fine-tuning, and transfer learning, where a pretrained model is fine-tuned on a target building. The main finding of our benchmark analysis is that synthetically pretrained models generalize surprisingly well to real commercial buildings. An exploration of the effect of increasing dataset size and diversity on zero-shot commercial building performance reveals a power-law with diminishing returns. We also show that fine-tuning pretrained models on real commercial and residential buildings improves performance for a majority of target buildings. We hope that BuildingsBench encourages and facilitates future research on generalizable STLF. All datasets and code …
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
Biodiversity is declining at an unprecedented rate, impacting ecosystem services necessary to ensure food, water, and human health and well-being. Understanding the distribution of species and their habitats is crucial for conservation policy planning. However, traditional methods in ecology for species distribution models (SDMs) generally focus either on narrow sets of species or narrow geographical areas and there remain significant knowledge gaps about the distribution of species. A major reason for this is the limited availability of data traditionally used, due to the prohibitive amount of effort and expertise required for traditional field monitoring. The wide availability of remote sensing data and the growing adoption of citizen science tools to collect species observations data at low cost offer an opportunity for improving biodiversity monitoring and enabling the modelling of complex ecosystems. We introduce a novel task for mapping bird species to their habitats by predicting species encounter rates from satellite images, and present SatBird, a satellite dataset of locations in the USA with labels derived from presence-absence observation data from the citizen science database eBird, considering summer (breeding) and winter seasons. We also provide a dataset in Kenya representing low-data regimes. We additionally provide environmental data and species range maps …
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
Above Ground Biomass is an important variable as forests play a crucial role in mitigating climate change as they act as an efficient, natural and cost-effective carbon sink. Traditional field and airborne LiDAR measurements have been proven to provide reliable estimations of forest biomass. Nevertheless, the use of these techniques at a large scale can be challenging and expensive. Satellite data have been widely used as a valuable tool in estimating biomass on a global scale. However, the full potential of dense multi-modal satellite time series data, in combination with modern deep learning approaches, has yet to be fully explored. The aim of the "BioMassters" data challenge and benchmark dataset is to investigate the potential of multi-modal satellite data (Sentinel-1 SAR and Sentinel-2 MSI) to estimate forest biomass at a large scale using the Finnish Forest Centre's open forest and nature airborne LiDAR data as a reference. The performance of the top three baseline models shows the potential of deep learning to produce accurate and higher-resolution biomass maps. Our benchmark dataset is publically available at https://huggingface.co/datasets/nascetti-a/BioMassters (doi:10.57967/hf/1009) and the implementation of the top three winning models are available at https://github.com/drivendataorg/the-biomassters.
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
Machine learning provides a valuable tool for analyzing high-dimensional functional neuroimaging data, and is proving effective in predicting various neurological conditions, psychiatric disorders, and cognitive patterns. In functional magnetic resonance imaging (MRI) research, interactions between brain regions are commonly modeled using graph-based representations. The potency of graph machine learning methods has been established across myriad domains, marking a transformative step in data interpretation and predictive modeling. Yet, despite their promise, the transposition of these techniques to the neuroimaging domain has been challenging due to the expansive number of potential preprocessing pipelines and the large parameter search space for graph-based dataset construction. In this paper, we introduce NeuroGraph, a collection of graph-based neuroimaging datasets, and demonstrated its utility for predicting multiple categories of behavioral and cognitive traits. We delve deeply into the dataset generation search space by crafting 35 datasets that encompass static and dynamic brain connectivity, running in excess of 15 baseline methods for benchmarking. Additionally, we provide generic frameworks for learning on both static and dynamic graphs. Our extensive experiments lead to several key observations. Notably, using correlation vectors as node features, incorporating larger number of regions of interest, and employing sparser graphs lead to improved performance. To foster …
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
We propose a novel multimodal video benchmark - the Perception Test - to evaluate the perception and reasoning skills of pre-trained multimodal models (e.g. Flamingo, BEiT-3, or GPT-4). Compared to existing benchmarks that focus on computational tasks (e.g. classification, detection or tracking), the Perception Test focuses on skills (Memory, Abstraction, Physics, Semantics) and types of reasoning (descriptive, explanatory, predictive, counterfactual) across video, audio, and text modalities, to provide a comprehensive and efficient evaluation tool. The benchmark probes pre-trained models for their transfer capabilities, in a zero-shot / few-shot or limited finetuning regime. For these purposes, the Perception Test introduces 11.6k real-world videos, 23s average length, designed to show perceptually interesting situations, filmed by around 100 participants worldwide. The videos are densely annotated with six types of labels (multiple-choice and grounded video question-answers, object and point tracks, temporal action and sound segments), enabling both language and non-language evaluations. The fine-tuning and validation splits of the benchmark are publicly available (CC-BY license), in addition to a challenge server with a held-out test split. Human baseline results compared to state-of-the-art video QA models show a significant gap in performance (91.4% vs 45.8%), suggesting that there is significant room for improvement in multimodal video …
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
Large Language Models (LLMs) with strong abilities in natural language processing tasks have emerged and have been applied in various kinds of areas such as science, finance and software engineering. However, the capability of LLMs to advance the field of chemistry remains unclear. In this paper, rather than pursuing state-of-the-art performance, we aim to evaluate capabilities of LLMs in a wide range of tasks across the chemistry domain. We identify three key chemistry-related capabilities including understanding, reasoning and explaining to explore in LLMs and establish a benchmark containing eight chemistry tasks. Our analysis draws on widely recognized datasets facilitating a broad exploration of the capacities of LLMs within the context of practical chemistry. Five LLMs (GPT-4,GPT-3.5, Davinci-003, Llama and Galactica) are evaluated for each chemistry task in zero-shot and few-shot in-context learning settings with carefully selected demonstration examples and specially crafted prompts. Our investigation found that GPT-4 outperformed other models and LLMs exhibit different competitive levels in eight chemistry tasks. In addition to the key findings from the comprehensive benchmark analysis, our work provides insights into the limitation of current LLMs and the impact of in-context learning settings on LLMs’ performance across various chemistry tasks. The code and datasets used …
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
Machine learning approaches often require training and evaluation datasets with a clear separation between positive and negative examples. This requirement overly simplifies the natural subjectivity present in many tasks, and obscures the inherent diversity in human perceptions and opinions about many content items. Preserving the variance in content and diversity in human perceptions in datasets is often quite expensive and laborious. This is especially troubling when building safety datasets for conversational AI systems, as safety is socio-culturally situated in this context. To demonstrate this crucial aspect of conversational AI safety, and to facilitate in-depth model performance analyses, we introduce the DICES (Diversity In Conversational AI Evaluation for Safety) dataset that contains fine-grained demographics information about raters, high replication of ratings per item to ensure statistical power for analyses, and encodes rater votes as distributions across different demographics to allow for in-depth explorations of different aggregation strategies. The DICES dataset enables the observation and measurement of variance, ambiguity, and diversity in the context of safety for conversational AI. We further describe a set of metrics that show how rater diversity influences safety perception across different geographic regions, ethnicity groups, age groups, and genders. The goal of the DICES dataset is to …
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
Counterfactual examples have proven to be valuable in the field of natural language processing (NLP) for both evaluating and improving the robustness of language models to spurious correlations in datasets. Despite their demonstrated utility for NLP, multimodal counterfactual examples have been relatively unexplored due to the difficulty of creating paired image-text data with minimal counterfactual changes. To address this challenge, we introduce a scalable framework for automatic generation of counterfactual examples using text-to-image diffusion models. We use our framework to create COCO-Counterfactuals, a multimodal counterfactual dataset of paired image and text captions based on the MS-COCO dataset. We validate the quality of COCO-Counterfactuals through human evaluations and show that existing multimodal models are challenged by our counterfactual image-text pairs. Additionally, we demonstrate the usefulness of COCO-Counterfactuals for improving out-of-domain generalization of multimodal vision-language models via training data augmentation. We make our code and the COCO-Counterfactuals dataset publicly available.
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
Systematic compositionality, or the ability to adapt to novel situations by creating a mental model of the world using reusable pieces of knowledge, remains a significant challenge in machine learning. While there has been considerable progress in the language domain, efforts towards systematic visual imagination, or envisioning the dynamical implications of a visual observation, are in their infancy. We introduce the Systematic Visual Imagination Benchmark (SVIB), the first benchmark designed to address this problem head-on. SVIB offers a novel framework for a minimal world modeling problem, where models are evaluated based on their ability to generate one-step image-to-image transformations under a latent world dynamics. The framework provides benefits such as the possibility to jointly optimize for systematic perception and imagination, a range of difficulty levels, and the ability to control the fraction of possible factor combinations used during training. We provide a comprehensive evaluation of various baseline models on SVIB, offering insight into the current state-of-the-art in systematic visual imagination. We hope that this benchmark will help advance visual systematic compositionality.
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
The Collaborative Research Cycle (CRC) is a National Institute of Standards and Technology (NIST) benchmarking program intended to strengthen understanding of tabular data deidentification technologies. Deidentification algorithms are vulnerable to the same bias and privacy issues that impact other data analytics and machine learning applications, and it can even amplify those issues by contaminating downstream applications. This paper summarizes four CRC contributions: theoretical work on the relationship between diverse populations and challenges for equitable deidentification; public benchmark data focused on diverse populations and challenging features; a comprehensive open source suite of evaluation metrology for deidentified datasets; and an archive of more than 450 deidentified data samples from a broad range of techniques. The initial set of evaluation results demonstrate the value of the CRC tools for investigations in this field.
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
There is a growing interest in device-control systems that can interpret human natural language instructions and execute them on a digital device by directly controlling its user interface. We present a dataset for device-control research, Android in the Wild (AitW), which is orders of magnitude larger than current datasets. The dataset contains human demonstrations of device interactions, including the screens and actions, and corresponding natural language instructions. It consists of 715k episodes spanning 30k unique instructions, four versions of Android (v10–13), and eight device types (Pixel 2 XL to Pixel 6) with varying screen resolutions. It contains multi-step tasks that require semantic understanding of language and visual context. This dataset poses a new challenge: actions available through the user interface must be inferred from their visual appearance, and, instead of simple UI element-based actions, the action space consists of precise gestures (e.g., horizontal scrolls to operate carousel widgets). We organize our dataset to encourage robustness analysis of device-control systems, i.e., how well a system performs in the presence of new task descriptions, new applications, or new platform versions. We develop two agents and report performance across the dataset. The dataset is available at https://github.com/google-research/google-research/tree/master/androidinthe_wild.
[ Great Hall & Hall B1+B2 (level 1) ]
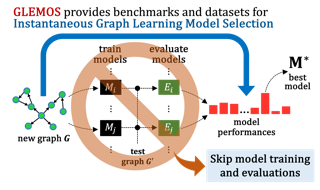
Abstract
The choice of a graph learning (GL) model (i.e., a GL algorithm and its hyperparameter settings) has a significant impact on the performance of downstream tasks. However, selecting the right GL model becomes increasingly difficult and time consuming as more and more GL models are developed. Accordingly, it is of great significance and practical value to equip users of GL with the ability to perform a near-instantaneous selection of an effective GL model without manual intervention. Despite the recent attempts to tackle this important problem, there has been no comprehensive benchmark environment to evaluate the performance of GL model selection methods. To bridge this gap, we present GLEMOS in this work, a comprehensive benchmark for instantaneous GL model selection that makes the following contributions. (i) GLEMOS provides extensive benchmark data for fundamental GL tasks, i.e., link prediction and node classification, including the performances of 366 models on 457 graphs on these tasks. (ii) GLEMOS designs multiple evaluation settings, and assesses how effectively representative model selection techniques perform in these different settings. (iii) GLEMOS is designed to be easily extended with new models, new graphs, and new performance records. (iv) Based on the experimental results, we discuss the limitations of existing …
[ Great Hall & Hall B1+B2 (level 1) ]
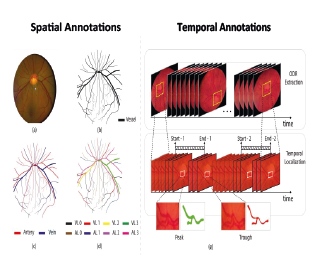
Abstract
Retinal vessel segmentation is generally grounded in image-based datasets collected with bench-top devices. The static images naturally lose the dynamic characteristics of retina fluctuation, resulting in diminished dataset richness, and the usage of bench-top devices further restricts dataset scalability due to its limited accessibility. Considering these limitations, we introduce the first video-based retinal dataset by employing handheld devices for data acquisition. The dataset comprises 635 smartphone-based fundus videos collected from four different clinics, involving 415 patients from 50 to 75 years old. It delivers comprehensive and precise annotations of retinal structures in both spatial and temporal dimensions, aiming to advance the landscape of vasculature segmentation. Specifically, the dataset provides three levels of spatial annotations: binary vessel masks for overall retinal structure delineation, general vein-artery masks for distinguishing the vein and artery, and fine-grained vein-artery masks for further characterizing the granularities of each artery and vein. In addition, the dataset offers temporal annotations that capture the vessel pulsation characteristics, assisting in detecting ocular diseases that require fine-grained recognition of hemodynamic fluctuation. In application, our dataset exhibits a significant domain shift with respect to data captured by bench-top devices, thus posing great challenges to existing methods. Thanks to rich annotations and data …
[ Great Hall & Hall B1+B2 (level 1) ]
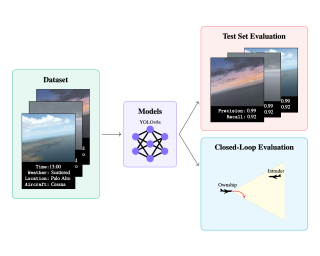
Abstract
Designing robust machine learning systems remains an open problem, and there is a need for benchmark problems that cover both environmental changes and evaluation on a downstream task. In this work, we introduce AVOIDDS, a realistic object detection benchmark for the vision-based aircraft detect-and-avoid problem. We provide a labeled dataset consisting of 72,000 photorealistic images of intruder aircraft with various lighting conditions, weather conditions, relative geometries, and geographic locations. We also provide an interface that evaluates trained models on slices of this dataset to identify changes in performance with respect to changing environmental conditions. Finally, we implement a fully-integrated, closed-loop simulator of the vision-based detect-and-avoid problem to evaluate trained models with respect to the downstream collision avoidance task. This benchmark will enable further research in the design of robust machine learning systems for use in safety-critical applications. The AVOIDDS dataset and code are publicly available at https://purl.stanford.edu/hj293cv5980 and https://github.com/sisl/VisionBasedAircraftDAA, respectively.
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
Intention-oriented object detection aims to detect desired objects based on specific intentions or requirements. For instance, when we desire to "lie down and rest", we instinctively seek out a suitable option such as a "bed" or a "sofa" that can fulfill our needs. Previous work in this area is limited either by the number of intention descriptions or by the affordance vocabulary available for intention objects. These limitations make it challenging to handle intentions in open environments effectively. To facilitate this research, we construct a comprehensive dataset called Reasoning Intention-Oriented Objects (RIO). In particular, RIO is specifically designed to incorporate diverse real-world scenarios and a wide range of object categories. It offers the following key features: 1) intention descriptions in RIO are represented as natural sentences rather than a mere word or verb phrase, making them more practical and meaningful; 2) the intention descriptions are contextually relevant to the scene, enabling a broader range of potential functionalities associated with the objects; 3) the dataset comprises a total of 40,214 images and 130,585 intention-object pairs. With the proposed RIO, we evaluate the ability of some existing models to reason intention-oriented objects in open environments.
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
In this paper, we present Motion-X, a large-scale 3D expressive whole-body motion dataset. Existing motion datasets predominantly contain body-only poses, lacking facial expressions, hand gestures, and fine-grained pose descriptions. Moreover, they are primarily collected from limited laboratory scenes with textual descriptions manually labeled, which greatly limits their scalability. To overcome these limitations, we develop a whole-body motion and text annotation pipeline, which can automatically annotate motion from either single- or multi-view videos and provide comprehensive semantic labels for each video and fine-grained whole-body pose descriptions for each frame. This pipeline is of high precision, cost-effective, and scalable for further research. Based on it, we construct Motion-X, which comprises 15.6M precise 3D whole-body pose annotations (i.e., SMPL-X) covering 81.1K motion sequences from massive scenes. Besides, Motion-X provides 15.6M frame-level whole-body pose descriptions and 81.1K sequence-level semantic labels. Comprehensive experiments demonstrate the accuracy of the annotation pipeline and the significant benefit of Motion-X in enhancing expressive, diverse, and natural motion generation, as well as 3D whole-body human mesh recovery.
[ Great Hall & Hall B1+B2 (level 1) ]
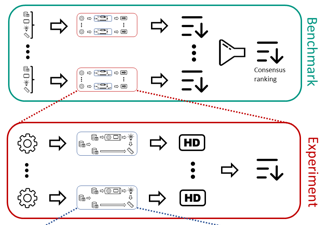
Abstract
Categorical encoders transform categorical features into numerical representations that are indispensable for a wide range of machine learning models.Existing encoder benchmark studies lack generalizability because of their limited choice of (1) encoders, (2) experimental factors, and (3) datasets. Additionally, inconsistencies arise from the adoption of varying aggregation strategies.This paper is the most comprehensive benchmark of categorical encoders to date, including an extensive evaluation of 32 configurations of encoders from diverse families, with 36 combinations of experimental factors, and on 50 datasets.The study shows the profound influence of dataset selection, experimental factors, and aggregation strategies on the benchmark's conclusions~---~aspects disregarded in previous encoder benchmarks.Our code is available at \url{https://github.com/DrCohomology/EncoderBenchmarking}.
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
Nanophotonic structures have versatile applications including solar cells, anti-reflective coatings, electromagnetic interference shielding, optical filters, and light emitting diodes. To design and understand these nanophotonic structures, electrodynamic simulations are essential. These simulations enable us to model electromagnetic fields over time and calculate optical properties. In this work, we introduce frameworks and benchmarks to evaluate nanophotonic structures in the context of parametric structure design problems. The benchmarks are instrumental in assessing the performance of optimization algorithms and identifying an optimal structure based on target optical properties. Moreover, we explore the impact of varying grid sizes in electrodynamic simulations, shedding light on how evaluation fidelity can be strategically leveraged in enhancing structure designs.
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
Human Intelligence (HI) excels at combining basic skills to solve complex tasks. This capability is vital for Artificial Intelligence (AI) and should be embedded in comprehensive AI Agents, enabling them to harness expert models for complex task-solving towards Artificial General Intelligence (AGI). Large Language Models (LLMs) show promising learning and reasoning abilities, and can effectively use external models, tools, plugins, or APIs to tackle complex problems. In this work, we introduce OpenAGI, an open-source AGI research and development platform designed for solving multi-step, real-world tasks. Specifically, OpenAGI uses a dual strategy, integrating standard benchmark tasks for benchmarking and evaluation, and open-ended tasks including more expandable models, tools, plugins, or APIs for creative problem-solving. Tasks are presented as natural language queries to the LLM, which then selects and executes appropriate models. We also propose a Reinforcement Learning from Task Feedback (RLTF) mechanism that uses task results to improve the LLM's task-solving ability, which creates a self-improving AI feedback loop. While we acknowledge that AGI is a broad and multifaceted research challenge with no singularly defined solution path, the integration of LLMs with domain-specific expert models, inspired by mirroring the blend of general and specialized intelligence in humans, offers a promising approach …
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
Millimetre-wave (mmWave) radar has emerged as an attractive and cost-effective alternative for human activity sensing compared to traditional camera-based systems. mmWave radars are also non-intrusive, providing better protection for user privacy. However, as a Radio Frequency based technology, mmWave radars rely on capturing reflected signals from objects, making them more prone to noise compared to cameras. This raises an intriguing question for the deep learning community: Can we develop more effective point set-based deep learning methods for such attractive sensors? To answer this question, our work, termed MiliPoint, delves into this idea by providing a large-scale, open dataset for the community to explore how mmWave radars can be utilised for human activity recognition. Moreover, MiliPoint stands out as it is larger in size than existing datasets, has more diverse human actions represented, and encompasses all three key tasks in human activity recognition. We have also established a range of point-based deep neural networks such as DGCNN, PointNet++ and PointTransformer, on MiliPoint, which can serve to set the ground baseline for further development.
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
Machine learning has been successfully applied to grid-based PDE modeling in various scientific applications. However, learned PDE solvers based on Lagrangian particle discretizations, which are the preferred approach to problems with free surfaces or complex physics, remain largely unexplored. We present LagrangeBench, the first benchmarking suite for Lagrangian particle problems, focusing on temporal coarse-graining. In particular, our contribution is: (a) seven new fluid mechanics datasets (four in 2D and three in 3D) generated with the Smoothed Particle Hydrodynamics (SPH) method including the Taylor-Green vortex, lid-driven cavity, reverse Poiseuille flow, and dam break, each of which includes different physics like solid wall interactions or free surface, (b) efficient JAX-based API with various recent training strategies and three neighbor search routines, and (c) JAX implementation of established Graph Neural Networks (GNNs) like GNS and SEGNN with baseline results. Finally, to measure the performance of learned surrogates we go beyond established position errors and introduce physical metrics like kinetic energy MSE and Sinkhorn distance for the particle distribution. Our codebase is available under the URL: https://github.com/tumaer/lagrangebench.
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
Simulation with realistic, interactive agents represents a key task for autonomous vehicle software development. In this work, we introduce the Waymo Open Sim Agents Challenge (WOSAC). WOSAC is the first public challenge to tackle this task and propose corresponding metrics. The goal of the challenge is to stimulate the design of realistic simulators that can be used to evaluate and train a behavior model for autonomous driving. We outline our evaluation methodology, present results for a number of different baseline simulation agent methods, and analyze several submissions to the 2023 competition which ran from March 16, 2023 to May 23, 2023. The WOSAC evaluation server remains open for submissions and we discuss open problems for the task.
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
Question answering (QA) in the field of healthcare has received much attention due to significant advancements in natural language processing. However, existing healthcare QA datasets primarily focus on medical images, clinical notes, or structured electronic health record tables. This leaves the vast potential of combining electrocardiogram (ECG) data with these systems largely untapped. To address this gap, we present ECG-QA, the first QA dataset specifically designed for ECG analysis. The dataset comprises a total of 70 question templates that cover a wide range of clinically relevant ECG topics, each validated by an ECG expert to ensure their clinical utility. As a result, our dataset includes diverse ECG interpretation questions, including those that require a comparative analysis of two different ECGs. In addition, we have conducted numerous experiments to provide valuable insights for future research directions. We believe that ECG-QA will serve as a valuable resource for the development of intelligent QA systems capable of assisting clinicians in ECG interpretations.
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
The quest for human imitative AI has been an enduring topic in AI research since inception. The technical evolution and emerging capabilities of the latest cohort of large language models (LLMs) have reinvigorated the subject beyond academia to cultural zeitgeist. While recent NLP evaluation benchmark tasks test some aspects of human-imitative behaviour (e.g., BIG-bench's `human-like behavior' tasks), few, if not none, examine creative problem solving abilities. Creative problem solving in humans is a well-studied topic in cognitive neuroscience with standardized tests that predominantly use ability to associate (heterogeneous) connections among clue words as a metric for creativity. Exposure to misleading stimuli --- distractors dubbed red herrings --- impede human performance in such tasks via the fixation effect and Einstellung paradigm. In cognitive neuroscience studies, such fixations are experimentally induced by pre-exposing participants to orthographically similar incorrect words to subsequent word-fragments or clues. The popular British quiz show Only Connect's Connecting Wall segment essentially mimics Mednick's Remote Associates Test (RAT) formulation with built-in, deliberate red herrings, that makes it an ideal proxy dataset to explore and study fixation effect and Einstellung paradigm from cognitive neuroscience in LLMs. In addition to presenting the novel Only Connect Wall (OCW) dataset, we also report …
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
In this paper, we introduce the BeaverTails dataset, aimed at fostering research on safety alignment in large language models (LLMs). This dataset uniquely separates annotations of helpfulness and harmlessness for question-answering pairs, thus offering distinct perspectives on these crucial attributes. In total, we have gathered safety meta-labels for 333,963 question-answer (QA) pairs and 361,903 pairs of expert comparison data for both the helpfulness and harmlessness metrics. We further showcase applications of BeaverTails in content moderation and reinforcement learning with human feedback (RLHF), emphasizing its potential for practical safety measures in LLMs. We believe this dataset provides vital resources for the community, contributing towards the safe development and deployment of LLMs. Our project page is available at the following URL: https://sites.google.com/view/pku-beavertails.
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
Forecasting human motion of multiple persons is very challenging. It requires to model the interactions between humans and the interactions with objects and the environment. For example, a person might want to make a coffee, but if the coffee machine is already occupied the person will haveto wait. These complex relations between scene geometry and persons ariseconstantly in our daily lives, and models that wish to accurately forecasthuman behavior will have to take them into consideration. To facilitate research in this direction, we propose Humans in Kitchens, alarge-scale multi-person human motion dataset with annotated 3D human poses, scene geometry and activities per person and frame.Our dataset consists of over 7.3h recorded data of up to 16 persons at the same time in four kitchen scenes, with more than 4M annotated human poses, represented by a parametric 3D body model. In addition, dynamic scene geometry and objects like chair or cupboard are annotated per frame. As first benchmarks, we propose two protocols for short-term and long-term human motion forecasting.
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
Human activities are goal-oriented and hierarchical, comprising primary goals at the top level, sequences of steps and substeps in the middle, and atomic actions at the lowest level. Recognizing human activities thus requires relating atomic actions and steps to their functional objectives (what the actions contribute to) and modeling their sequential and hierarchical dependencies towards achieving the goals. Current activity recognition research has primarily focused on only the lowest levels of this hierarchy, i.e., atomic or low-level actions, often in trimmed videos with annotations spanning only a few seconds. In this work, we introduce Ego4D Goal-Step, a new set of annotations on the recently released Ego4D with a novel hierarchical taxonomy of goal-oriented activity labels. It provides dense annotations for 48K procedural step segments (430 hours) and high-level goal annotations for 2,807 hours of Ego4D videos. Compared to existing procedural video datasets, it is substantially larger in size, contains hierarchical action labels (goals - steps - substeps), and provides goal-oriented auxiliary information including natural language summary description, step completion status, and step-to-goal relevance information. We take a data-driven approach to build our taxonomy, resulting in dense step annotations that do not suffer from poor label-data alignment issues resulting from a …
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
Indoor rooms are among the most common use cases in 3D scene understanding. Current state-of-the-art methods for this task are driven by large annotated datasets. Room layouts are especially important, consisting of structural elements in 3D, such as wall, floor, and ceiling. However, they are difficult to annotate, especially on pure RGB video. We propose a novel method to produce generic 3D room layouts just from 2D segmentation masks, which are easy to annotate for humans. Based on these 2D annotations, we automatically reconstruct 3D plane equations for the structural elements and their spatial extent in the scene, and connect adjacent elements at the appropriate contact edges. We annotate and publicly release 2246 3D room layouts on the RealEstate10k dataset, containing YouTube videos. We demonstrate the high quality of these 3D layouts annotations with extensive experiments.
[ Great Hall & Hall B1+B2 (level 1) ]
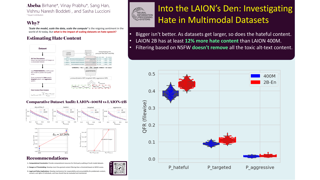
Abstract
`Scale the model, scale the data, scale the compute' is the reigning sentiment in the world of generative AI today. While the impact of model scaling has been extensively studied, we are only beginning to scratch the surface of data scaling and its consequences. This is especially of critical importance in the context of vision-language datasets such as LAION. These datasets are continually growing in size and are built based on large-scale internet dumps such as the Common Crawl, which is known to have numerous drawbacks ranging from quality, legality, and content. The datasets then serve as the backbone for large generative models, contributing to the operationalization and perpetuation of harmful societal and historical biases and stereotypes. In this paper, we investigate the effect of scaling datasets on hateful content through a comparative audit of two datasets: LAION-400M and LAION-2B. Our results show that hate content increased by nearly 12% with dataset scale, measured both qualitatively and quantitatively using a metric that we term as Hate Content Rate (HCR). We also found that filtering dataset contents based on Not Safe For Work (NSFW) values calculated based on images alone does not exclude all the harmful content in alt-text. Instead, we …
[ Great Hall & Hall B1+B2 (level 1) ]
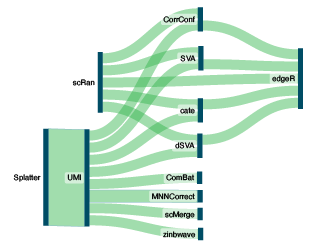
Abstract
Many of the most commonly explored natural language processing (NLP) information extraction tasks can be thought of as evaluations of declarative knowledge, or fact-based information extraction. Procedural knowledge extraction, i.e., breaking down a described process into a series of steps, has received much less attention, perhaps in part due to the lack of structured datasets that capture the knowledge extraction process from end-to-end. To address this unmet need, we present FlaMBé (Flow annotations for Multiverse Biological entities), a collection of expert-curated datasets across a series of complementary tasks that capture procedural knowledge in biomedical texts. This dataset is inspired by the observation that one ubiquitous source of procedural knowledge that is described as unstructured text is within academic papers describing their methodology. The workflows annotated in FlaMBé are from texts in the burgeoning field of single cell research, a research area that has become notorious for the number of software tools and complexity of workflows used. Additionally, FlaMBé provides, to our knowledge, the largest manually curated named entity recognition (NER) and disambiguation (NED) datasets for tissue/cell type, a fundamental biological entity that is critical for knowledge extraction in the biomedical research domain. Beyond providing a valuable dataset to enable further …
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
The success of the Segment Anything Model (SAM) demonstrates the significance of data-centric machine learning. However, due to the difficulties and high costs associated with annotating Remote Sensing (RS) images, a large amount of valuable RS data remains unlabeled, particularly at the pixel level. In this study, we leverage SAM and existing RS object detection datasets to develop an efficient pipeline for generating a large-scale RS segmentation dataset, dubbed SAMRS. SAMRS totally possesses 105,090 images and 1,668,241 instances, surpassing existing high-resolution RS segmentation datasets in size by several orders of magnitude. It provides object category, location, and instance information that can be used for semantic segmentation, instance segmentation, and object detection, either individually or in combination. We also provide a comprehensive analysis of SAMRS from various aspects. Moreover, preliminary experiments highlight the importance of conducting segmentation pre-training with SAMRS to address task discrepancies and alleviate the limitations posed by limited training data during fine-tuning. The code and dataset will be available at https://github.com/ViTAE-Transformer/SAMRS
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
We introduce Cap3D, an automatic approach for generating descriptive text for 3D objects. This approach utilizes pretrained models from image captioning, image-text alignment, and LLM to consolidate captions from multiple views of a 3D asset, completely side-stepping the time-consuming and costly process of manual annotation. We apply Cap3D to the recently introduced large-scale 3D dataset, Objaverse, resulting in 660k 3D-text pairs. Our evaluation, conducted using 41k human annotations from the same dataset, demonstrates that Cap3D surpasses human-authored descriptions in terms of quality, cost, and speed. Through effective prompt engineering, Cap3D rivals human performance in generating geometric descriptions on 17k collected annotations from the ABO dataset. Finally, we finetune Text-to-3D models on Cap3D and human captions, and show Cap3D outperforms; and benchmark the SOTA including Point·E, Shape·E, and DreamFusion.
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
The financial markets, which involve over \$90 trillion market capitals, attract the attention of innumerable profit-seeking investors globally. Recent explosion of reinforcement learning in financial trading (RLFT) research has shown stellar performance on many quantitative trading tasks. However, it is still challenging to deploy reinforcement learning (RL) methods into real-world financial markets due to the highly composite nature of this domain, which entails design choices and interactions between components that collect financial data, conduct feature engineering, build market environments, make investment decisions, evaluate model behaviors and offers user interfaces. Despite the availability of abundant financial data and advanced RL techniques, a remarkable gap still exists between the potential and realized utilization of RL in financial trading. In particular, orchestrating an RLFT project lifecycle poses challenges in engineering (i.e. hard to build), benchmarking (i.e. hard to compare) and usability (i.e. hard to optimize, maintain and use). To overcome these challenges, we introduce TradeMaster, a holistic open-source RLFT platform that serves as a i) software toolkit, ii) empirical benchmark, and iii) user interface. Our ultimate goal is to provide infrastructures for transparent and reproducible RLFT research and facilitate their real-world deployment with industry impact. TradeMaster will be updated continuously and welcomes contributions …
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
We introduce VisoGender, a novel dataset for benchmarking gender bias in vision-language models. We focus on occupation-related biases within a hegemonic system of binary gender, inspired by Winograd and Winogender schemas, where each image is associated with a caption containing a pronoun relationship of subjects and objects in the scene. VisoGender is balanced by gender representation in professional roles, supporting bias evaluation in two ways: i) resolution bias, where we evaluate the difference between pronoun resolution accuracies for image subjects with gender presentations perceived as masculine versus feminine by human annotators and ii) retrieval bias, where we compare ratios of professionals perceived to have masculine and feminine gender presentations retrieved for a gender-neutral search query. We benchmark several state-of-the-art vision-language models and find that they demonstrate bias in resolving binary gender in complex scenes. While the direction and magnitude of gender bias depends on the task and the model being evaluated, captioning models are generally less biased than Vision-Language Encoders.
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
4D human perception plays an essential role in a myriad of applications, such as home automation and metaverse avatar simulation. However, existing solutions which mainly rely on cameras and wearable devices are either privacy intrusive or inconvenient to use. To address these issues, wireless sensing has emerged as a promising alternative, leveraging LiDAR, mmWave radar, and WiFi signals for device-free human sensing. In this paper, we propose MM-Fi, the first multi-modal non-intrusive 4D human dataset with 27 daily or rehabilitation action categories, to bridge the gap between wireless sensing and high-level human perception tasks. MM-Fi consists of over 320k synchronized frames of five modalities from 40 human subjects. Various annotations are provided to support potential sensing tasks, e.g., human pose estimation and action recognition. Extensive experiments have been conducted to compare the sensing capacity of each or several modalities in terms of multiple tasks. We envision that MM-Fi can contribute to wireless sensing research with respect to action recognition, human pose estimation, multi-modal learning, cross-modal supervision, and interdisciplinary healthcare research.
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
Link prediction attempts to predict whether an unseen edge exists based on only a portion of the graph. A flurry of methods has been created in recent years that attempt to make use of graph neural networks (GNNs) for this task. Furthermore, new and diverse datasets have also been created to better evaluate the effectiveness of these new models. However, multiple limitations currently exist that hinders our ability to properly evaluate these new methods. This includes, but is not limited to: (1) The underreporting of performance on multiple baselines, (2) A lack of a unified data split and evaluation metric on some datasets, (3) An unrealistic evaluation setting that produces negative samples that are easy to classify. To overcome these challenges we first conduct a fair comparison across prominent methods and datasets, utilizing the same dataset settings and hyperparameter settings. We then create a new real-world evaluation setting that samples difficult negative samples via multiple heuristics. The new evaluation setting helps promote new challenges and opportunities in link prediction by aligning the evaluation with real-world situations.
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
The examination of blood samples at a microscopic level plays a fundamental role in clinical diagnostics. For instance, an in-depth study of White Blood Cells (WBCs), a crucial component of our blood, is essential for diagnosing blood-related diseases such as leukemia and anemia. While multiple datasets containing WBC images have been proposed, they mostly focus on cell categorization, often lacking the necessary morphological details to explain such categorizations, despite the importance of explainable artificial intelligence (XAI) in medical domains. This paper seeks to address this limitation by introducing comprehensive annotations for WBC images. Through collaboration with pathologists, a thorough literature review, and manual inspection of microscopic images, we have identified 11 morphological attributes associated with the cell and its components (nucleus, cytoplasm, and granules). We then annotated ten thousand WBC images with these attributes, resulting in 113k labels (11 attributes x 10.3k images). Annotating at this level of detail and scale is unprecedented, offering unique value to AI in pathology. Moreover, we conduct experiments to predict these attributes from cell images, and also demonstrate specific applications that can benefit from our detailed annotations. Overall, our dataset paves the way for interpreting WBC recognition models, further advancing XAI in the fields …
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
Recent advances in neural reconstruction enable high-quality 3D object reconstruction from casually captured image collections. Current techniques mostly analyze their progress on relatively simple image collections where SfM techniques can provide ground-truth (GT) camera poses. We note that SfM techniques tend to fail on in-the-wild image collections such as image search results with varying backgrounds and illuminations. To enable systematic research progress on 3D reconstruction from casual image captures, we propose `NAVI': a new dataset of category-agnostic image collections of objects with high-quality 3D scans along with per-image 2D-3D alignments providing near-perfect GT camera parameters. These 2D-3D alignments allow us to extract accurate derivative annotations such as dense pixel correspondences, depth and segmentation maps. We demonstrate the use of NAVI image collections on different problem settings and show that NAVI enables more thorough evaluations that were not possible with existing datasets. We believe NAVI is beneficial for systematic research progress on 3D reconstruction and correspondence estimation.
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
Tabular data is one of the most commonly used types of data in machine learning. Despite recent advances in neural nets (NNs) for tabular data, there is still an active discussion on whether or not NNs generally outperform gradient-boosted decision trees (GBDTs) on tabular data, with several recent works arguing either that GBDTs consistently outperform NNs on tabular data, or vice versa. In this work, we take a step back and question the importance of this debate. To this end, we conduct the largest tabular data analysis to date, comparing 19 algorithms across 176 datasets, and we find that the 'NN vs. GBDT' debate is overemphasized: for a surprisingly high number of datasets, either the performance difference between GBDTs and NNs is negligible, or light hyperparameter tuning on a GBDT is more important than choosing between NNs and GBDTs. Next, we analyze dozens of metafeatures to determine what \emph{properties} of a dataset make NNs or GBDTs better-suited to perform well. For example, we find that GBDTs are much better than NNs at handling skewed or heavy-tailed feature distributions and other forms of dataset irregularities. Our insights act as a guide for practitioners to determine which techniques may work best on …
[ Great Hall & Hall B1+B2 (level 1) ]
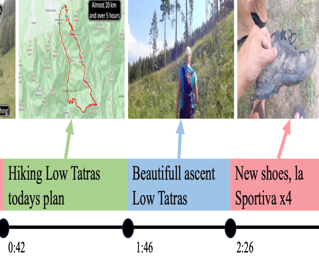
Abstract
Segmenting untrimmed videos into chapters enables users to quickly navigate to the information of their interest. This important topic has been understudied due to the lack of publicly released datasets. To address this issue, we present VidChapters-7M, a dataset of 817K user-chaptered videos including 7M chapters in total. VidChapters-7M is automatically created from videos online in a scalable manner by scraping user-annotated chapters and hence without any additional manual annotation. We introduce the following three tasks based on this data. First, the video chapter generation task consists of temporally segmenting the video and generating a chapter title for each segment. To further dissect the problem, we also define two variants of this task: video chapter generation given ground-truth boundaries, which requires generating a chapter title given an annotated video segment, and video chapter grounding, which requires temporally localizing a chapter given its annotated title. We benchmark both simple baselines as well as state-of-the-art video-language models on these three tasks. We also show that pretraining on VidChapters-7M transfers well to dense video captioning tasks, largely improving the state of the art on the YouCook2 and ViTT benchmarks. Finally, our experiments reveal that downstream performance scales well with the size of the …
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
Image classifiers are information-discarding machines, by design. Yet, how these models discard information remains mysterious. We hypothesize that one way for image classifiers to reach high accuracy is to first zoom to the most discriminative region in the image and then extract features from there to predict image labels, discarding the rest of the image. Studying six popular networks ranging from AlexNet to CLIP, we find that proper framing of the input image can lead to the correct classification of 98.91% of ImageNet images. Furthermore, we uncover positional biases in various datasets, especially a strong center bias in two popular datasets: ImageNet-A and ObjectNet. Finally, leveraging our insights into the potential of zooming, we propose a test-time augmentation (TTA) technique that improves classification accuracy by forcing models to explicitly perform zoom-in operations before making predictions.Our method is more interpretable, accurate, and faster than MEMO, a state-of-the-art (SOTA) TTA method. We introduce ImageNet-Hard, a new benchmark that challenges SOTA classifiers including large vision-language models even when optimal zooming is allowed.
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
Neural MMO 2.0 is a massively multi-agent and multi-task environment for reinforcement learning research. This version features a novel task-system that broadens the range of training settings and poses a new challenge in generalization: evaluation on and against tasks, maps, and opponents never seen during training. Maps are procedurally generated with 128 agents in the standard setting and 1-1024 supported overall. Version 2.0 is a complete rewrite of its predecessor with three-fold improved performance, effectively addressing simulation bottlenecks in online training. Enhancements to compatibility enable training with standard reinforcement learning frameworks designed for much simpler environments. Neural MMO 2.0 is free and open-source with comprehensive documentation available at neuralmmo.github.io and an active community Discord. To spark initial research on this new platform, we are concurrently running a competition at NeurIPS 2023.
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
Various adaptation methods, such as LoRA, prompts, and adapters, have been proposed to enhance the performance of pre-trained vision-language models in specific domains. As test samples in real-world applications usually differ from adaptation data, the robustness of these adaptation methods against distribution shifts are essential. In this study, we assess the robustness of 11 widely-used adaptation methods across 4 vision-language datasets under multimodal corruptions. Concretely, we introduce 7 benchmark datasets, including 96 visual and 87 textual corruptions, to investigate the robustness of different adaptation methods, the impact of available adaptation examples, and the influence of trainable parameter size during adaptation. Our analysis reveals that: 1) Adaptation methods are more sensitive to text corruptions than visual corruptions. 2) Full fine-tuning does not consistently provide the highest robustness; instead, adapters can achieve better robustness with comparable clean performance. 3) Contrary to expectations, our findings indicate that increasing the number of adaptation data and parameters does not guarantee enhanced robustness; instead, it results in even lower robustness. We hope this study could benefit future research in the development of robust multimodal adaptation methods. The benchmark, code, and dataset used in this study can be accessed at https://adarobustness.github.io.
[ Great Hall & Hall B1+B2 (level 1) ]
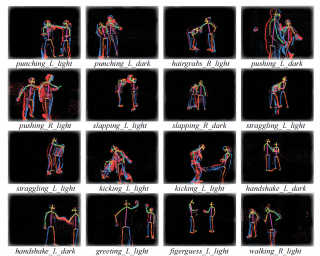
Abstract
The prevalence of violence in daily life poses significant threats to individuals' physical and mental well-being. Using surveillance cameras in public spaces has proven effective in proactively deterring and preventing such incidents. However, concerns regarding privacy invasion have emerged due to their widespread deployment.To address the problem, we leverage Dynamic Vision Sensors (DVS) cameras to detect violent incidents and preserve privacy since it captures pixel brightness variations instead of static imagery. We introduce the Bullying10K dataset, encompassing various actions, complex movements, and occlusions from real-life scenarios. It provides three benchmarks for evaluating different tasks: action recognition, temporal action localization, and pose estimation. With 10,000 event segments, totaling 12 billion events and 255 GB of data, Bullying10K contributes significantly by balancing violence detection and personal privacy persevering. And it also poses a challenge to the neuromorphic dataset. It will serve as a valuable resource for training and developing privacy-protecting video systems. The Bullying10K opens new possibilities for innovative approaches in these domains.
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
Recently, Meta-Black-Box Optimization with Reinforcement Learning (MetaBBO-RL) has showcased the power of leveraging RL at the meta-level to mitigate manual fine-tuning of low-level black-box optimizers. However, this field is hindered by the lack of a unified benchmark. To fill this gap, we introduce MetaBox, the first benchmark platform expressly tailored for developing and evaluating MetaBBO-RL methods. MetaBox offers a flexible algorithmic template that allows users to effortlessly implement their unique designs within the platform. Moreover, it provides a broad spectrum of over 300 problem instances, collected from synthetic to realistic scenarios, and an extensive library of 19 baseline methods, including both traditional black-box optimizers and recent MetaBBO-RL methods. Besides, MetaBox introduces three standardized performance metrics, enabling a more thorough assessment of the methods. In a bid to illustrate the utility of MetaBox for facilitating rigorous evaluation and in-depth analysis, we carry out a wide-ranging benchmarking study on existing MetaBBO-RL methods. Our MetaBox is open-source and accessible at: https://github.com/GMC-DRL/MetaBox.
[ Great Hall & Hall B1+B2 (level 1) ]
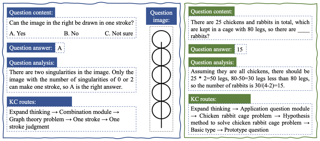
Abstract
Knowledge tracing (KT) is a task that predicts students' future performance based on their historical learning interactions. With the rapid development of deep learning techniques, existing KT approaches follow a data-driven paradigm that uses massive problem-solving records to model students' learning processes. However, although the educational contexts contain various factors that may have an influence on student learning outcomes, existing public KT datasets mainly consist of anonymized ID-like features, which may hinder the research advances towards this field. Therefore, in this work, we present, \emph{XES3G5M}, a large-scale dataset with rich auxiliary information about questions and their associated knowledge components (KCs)\footnote{\label{ft:kc}A KC is a generalization of everyday terms like concept, principle, fact, or skill.}. The XES3G5M dataset is collected from a real-world online math learning platform, which contains 7,652 questions, and 865 KCs with 5,549,635 interactions from 18,066 students. To the best of our knowledge, the XES3G5M dataset not only has the largest number of KCs in math domain but contains the richest contextual information including tree structured KC relations, question types, textual contents and analysis and student response timestamps. Furthermore, we build a comprehensive benchmark on 19 state-of-the-art deep learning based knowledge tracing (DLKT) models. Extensive experiments demonstrate the effectiveness …
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
We introduce EgoSchema, a very long-form video question-answering dataset, and benchmark to evaluate long video understanding capabilities of modern vision and language systems. Derived from Ego4D, EgoSchema consists of over 5000 human curated multiple choice question answer pairs, spanning over 250 hours of real video data, covering a very broad range of natural human activity and behavior. For each question, EgoSchema requires the correct answer to be selected between five given options based on a three-minute-long video clip. While some prior works have proposed video datasets with long clip lengths, we posit that merely the length of the video clip does not truly capture the temporal difficulty of the video task that is being considered. To remedy this, we introduce temporal certificate sets, a general notion for capturing the intrinsic temporal understanding length associated with a broad range of video understanding tasks & datasets. Based on this metric, we find EgoSchema to have intrinsic temporal lengths over 5.7x longer than the second closest dataset and 10x to 100x longer than any other video understanding dataset. Further, our evaluation of several current state-of-the-art video and language models shows them to be severely lacking in long-term video understanding capabilities. Even models with …
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
Visual Reinforcement Learning (Visual RL), coupled with high-dimensional observations, has consistently confronted the long-standing challenge of out-of-distribution generalization. Despite the focus on algorithms aimed at resolving visual generalization problems, we argue that the devil is in the existing benchmarks as they are restricted to isolated tasks and generalization categories, undermining a comprehensive evaluation of agents' visual generalization capabilities. To bridge this gap, we introduce RL-ViGen: a novel Reinforcement Learning Benchmark for Visual Generalization, which contains diverse tasks and a wide spectrum of generalization types, thereby facilitating the derivation of more reliable conclusions. Furthermore, RL-ViGen incorporates the latest generalization visual RL algorithms into a unified framework, under which the experiment results indicate that no single existing algorithm has prevailed universally across tasks. Our aspiration is that Rl-ViGen will serve as a catalyst in this area, and lay a foundation for the future creation of universal visual generalization RL agents suitable for real-world scenarios. Access to our code and implemented algorithms is provided at https://gemcollector.github.io/RL-ViGen/.
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
Large language models have emerged as a promising approach towards achieving general-purpose AI agents. The thriving open-source LLM community has greatly accelerated the development of agents that support human-machine dialogue interaction through natural language processing. However, human interaction with the world extends beyond only text as a modality, and other modalities such as vision are also crucial. Recent works on multi-modal large language models, such as GPT-4V and Bard, have demonstrated their effectiveness in handling visual modalities. However, the transparency of these works is limited and insufficient to support academic research. To the best of our knowledge, we present one of the very first open-source endeavors in the field, LAMM, encompassing a Language-Assisted Multi-Modal instruction tuning dataset, framework, and benchmark. Our aim is to establish LAMM as a growing ecosystem for training and evaluating MLLMs, with a specific focus on facilitating AI agents capable of bridging the gap between ideas and execution, thereby enabling seamless human-AI interaction. Our main contribution is three-fold: 1) We present a comprehensive dataset and benchmark, which cover a wide range of vision tasks for 2D and 3D vision. Extensive experiments validate the effectiveness of our dataset and benchmark. 2) We outline the detailed methodology of …
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
The past two years have witnessed a significant increase in interest concerning NeRF-based human body rendering. While this surge has propelled considerable advancements, it has also led to an influx of methods and datasets. This explosion complicates experimental settings and makes fair comparisons challenging. In this work, we design and execute thorough studies into unified evaluation settings and metrics to establish a fair and reasonable benchmark for human NeRF models. To reveal the effects of extant models, we benchmark them against diverse and hard scenes. Additionally, we construct a cross-subject benchmark pre-trained on large-scale datasets to assess generalizable methods. Finally, we analyze the essential components for animatability and generalizability, and make HumanNeRF from monocular videos generalizable, as the inaugural baseline. We hope these benchmarks and analyses could serve the community.
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
Accurately depicting the complex traffic scene is a vital component for autonomous vehicles to execute correct judgments. However, existing benchmarks tend to oversimplify the scene by solely focusing on lane perception tasks. Observing that human drivers rely on both lanes and traffic signals to operate their vehicles safely, we present OpenLane-V2, the first dataset on topology reasoning for traffic scene structure. The objective of the presented dataset is to advance research in understanding the structure of road scenes by examining the relationship between perceived entities, such as traffic elements and lanes. Leveraging existing datasets, OpenLane-V2 consists of 2,000 annotated road scenes that describe traffic elements and their correlation to the lanes. It comprises three primary sub-tasks, including the 3D lane detection inherited from OpenLane, accompanied by corresponding metrics to evaluate the model’s performance. We evaluate various state-of-the-art methods, and present their quantitative and qualitative results on OpenLane-V2 to indicate future avenues for investigating topology reasoning in traffic scenes.
[ Great Hall & Hall B1+B2 (level 1) ]
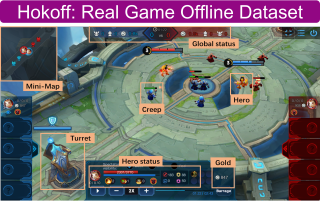
Abstract
The advancement of Offline Reinforcement Learning (RL) and Offline Multi-Agent Reinforcement Learning (MARL) critically depends on the availability of high-quality, pre-collected offline datasets that represent real-world complexities and practical applications. However, existing datasets often fall short in their simplicity and lack of realism. To address this gap, we propose Hokoff, a comprehensive set of pre-collected datasets that covers both offline RL and offline MARL, accompanied by a robust framework, to facilitate further research. This data is derived from Honor of Kings, a recognized Multiplayer Online Battle Arena (MOBA) game known for its intricate nature, closely resembling real-life situations. Utilizing this framework, we benchmark a variety of offline RL and offline MARL algorithms. We also introduce a novel baseline algorithm tailored for the inherent hierarchical action space of the game. We reveal the incompetency of current offline RL approaches in handling task complexity, generalization and multi-task learning.
[ Great Hall & Hall B1+B2 (level 1) ]
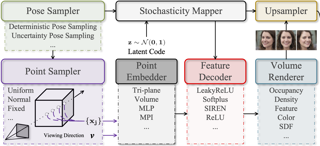
Abstract
Despite the rapid advance of 3D-aware image synthesis, existing studies usually adopt a mixture of techniques and tricks, leaving it unclear how each part contributes to the final performance in terms of generality. Following the most popular and effective paradigm in this field, which incorporates a neural radiance field (NeRF) into the generator of a generative adversarial network (GAN), we builda well-structured codebase through modularizing the generation process. Such a design allows researchers to develop and replace each module independently, and hence offers an opportunity to fairly compare various approaches and recognize their contributions from the module perspective. The reproduction of a range of cutting-edge algorithms demonstrates the availability of our modularized codebase. We also perform a variety of in-depth analyses, such as the comparison across different types of point feature, the necessity of the tailing upsampler in the generator, the reliance on the camera pose prior, etc., which deepen our understanding of existing methods and point out some further directions of the research work. Code and models will be made publicly available to facilitate the development and evaluation of this field.
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
One of the fundamental cognitive abilities of humans is to quickly resolve uncertainty by generating hypotheses and testing them via active trials. Encountering a novel phenomenon accompanied by ambiguous cause-effect relationships, humans make hypotheses against data, conduct inferences from observation, test their theory via experimentation, and correct the proposition if inconsistency arises. These iterative processes persist until the underlying mechanism becomes clear. In this work, we devise the IVRE (pronounced as "ivory") environment for evaluating artificial agents' reasoning ability under uncertainty. IVRE is an interactive environment featuring rich scenarios centered around Blicket detection. Agents in IVRE are placed into environments with various ambiguous action-effect pairs and asked to determine each object's role. They are encouraged to propose effective and efficient experiments to validate their hypotheses based on observations and actively gather new information. The game ends when all uncertainties are resolved or the maximum number of trials is consumed. By evaluating modern artificial agents in IVRE, we notice a clear failure of today's learning methods compared to humans. Such inefficacy in interactive reasoning ability under uncertainty calls for future research in building human-like intelligence.
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
Recent work has shown that generation from a prompted or fine-tuned language model can perform well at semantic parsing when the output is constrained to be a valid semantic representation. We introduce BenchCLAMP, a Benchmark to evaluate Constrained LAnguage Model Parsing, that includes context-free grammars for seven semantic parsing datasets and two syntactic parsing datasets with varied output meaning representations, as well as a constrained decoding interface to generate only valid outputs covered by these grammars. We provide low, medium, and high resource splits for each dataset, allowing accurate comparison of various language models under different data regimes. Our benchmark supports evaluation of language models using prompt-based learning as well as fine-tuning. We benchmark seven language models, including two GPT-3 variants available only through an API. Our experiments show that encoder-decoder pretrained language models can achieve similar performance or even surpass state-of-the-art methods for both syntactic and semantic parsing when the model output is constrained to be valid.
[ Great Hall & Hall B1+B2 (level 1) ]
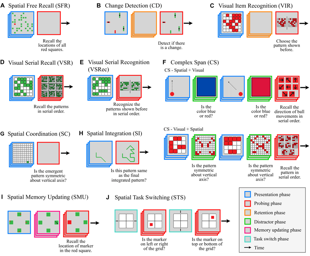
Abstract
Working memory (WM), a fundamental cognitive process facilitating the temporary storage, integration, manipulation, and retrieval of information, plays a vital role in reasoning and decision-making tasks. Robust benchmark datasets that capture the multifaceted nature of WM are crucial for the effective development and evaluation of AI WM models. Here, we introduce a comprehensive Working Memory (WorM) benchmark dataset for this purpose. WorM comprises 10 tasks and a total of 1 million trials, assessing 4 functionalities, 3 domains, and 11 behavioral and neural characteristics of WM. We jointly trained and tested state-of-the-art recurrent neural networks and transformers on all these tasks. We also include human behavioral benchmarks as an upper bound for comparison. Our results suggest that AI models replicate some characteristics of WM in the brain, most notably primacy and recency effects, and neural clusters and correlates specialized for different domains and functionalities of WM. In the experiments, we also reveal some limitations in existing models to approximate human behavior. This dataset serves as a valuable resource for communities in cognitive psychology, neuroscience, and AI, offering a standardized framework to compare and enhance WM models, investigate WM's neural underpinnings, and develop WM models with human-like capabilities. Our source code and …
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
Semantic segmentation datasets often exhibit two types of imbalance: \textit{class imbalance}, where some classes appear more frequently than others and \textit{size imbalance}, where some objects occupy more pixels than others. This causes traditional evaluation metrics to be biased towards \textit{majority classes} (e.g. overall pixel-wise accuracy) and \textit{large objects} (e.g. mean pixel-wise accuracy and per-dataset mean intersection over union). To address these shortcomings, we propose the use of fine-grained mIoUs along with corresponding worst-case metrics, thereby offering a more holistic evaluation of segmentation techniques. These fine-grained metrics offer less bias towards large objects, richer statistical information, and valuable insights into model and dataset auditing. Furthermore, we undertake an extensive benchmark study, where we train and evaluate 15 modern neural networks with the proposed metrics on 12 diverse natural and aerial segmentation datasets. Our benchmark study highlights the necessity of not basing evaluations on a single metric and confirms that fine-grained mIoUs reduce the bias towards large objects. Moreover, we identify the crucial role played by architecture designs and loss functions, which lead to best practices in optimizing fine-grained metrics. The code is available at \href{https://github.com/zifuwanggg/JDTLosses}{https://github.com/zifuwanggg/JDTLosses}.
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
High-level synthesis (HLS) aims to raise the abstraction layer in hardware design, enabling the design of domain-specific accelerators (DSAs) like field-programmable gate arrays (FPGAs) using C/C++ instead of hardware description languages (HDLs). Compiler directives in the form of pragmas play a crucial role in modifying the microarchitecture within the HLS framework. However, the space of possible microarchitectures grows exponentially with the number of pragmas. Moreover, the evaluation of each candidate design using the HLS tool consumes significant time, ranging from minutes to hours, leading to a time-consuming optimization process. To accelerate this process, machine learning models have been used to predict design quality in milliseconds. However, existing open-source datasets for training such models are limited in terms of design complexity and available optimizations. In this paper, we present HLSyn, the first benchmark that addresses these limitations. It contains more complex programs with a wider range of optimization pragmas, making it a comprehensive dataset for training and evaluating design quality prediction models. The HLSyn benchmark consists of 42 unique programs/kernels, resulting in over 42,000 labeled designs. We conduct an extensive comparison of state-of-the-art baselines to assess their effectiveness in predicting design quality. As an ongoing project, we anticipate expanding the HLSyn …
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
Representation learning has significantly driven the field to develop pretrained models that can act as a valuable starting point when transferring to new datasets. With the rising demand for reliable machine learning and uncertainty quantification, there is a need for pretrained models that not only provide embeddings but also transferable uncertainty estimates. To guide the development of such models, we propose the Uncertainty-aware Representation Learning (URL) benchmark. Besides the transferability of the representations, it also measures the zero-shot transferability of the uncertainty estimate using a novel metric. We apply URL to evaluate ten uncertainty quantifiers that are pretrained on ImageNet and transferred to eight downstream datasets. We find that approaches that focus on the uncertainty of the representation itself or estimate the prediction risk directly outperform those that are based on the probabilities of upstream classes. Yet, achieving transferable uncertainty quantification remains an open challenge. Our findings indicate that it is not necessarily in conflict with traditional representation learning goals. Code is available at https://github.com/mkirchhof/url.
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
Large scale field-phenotyping approaches have the potential to solve important questions about the relationship of plant genotype to plant phenotype. Computational approaches to measuring the phenotype (the observable plant features) are required to address the problem at a large scale, but machine learning approaches to extract phenotypes from sensor data have been hampered by limited access to (a) sufficiently large, organized multi-sensor datasets, (b) field trials that have a large scale and significant number of genotypes, (c) full genetic sequencing of those phenotypes, and (d) datasets sufficiently organized so that algorithm centered researchers can directly address the real biological problems. To address this, we present SGxP, a novel benchmark dataset from a large-scale field trial consisting of the complete genotype of over 300 sorghum varieties, and time sequences of imagery from several field plots growing each variety, taken with RGB and laser 3D scanner imaging. To lower the barrier to entry and facilitate further developments, we provide a set of well organized, multi-sensor imagery and corresponding genomic data. We implement baseline deep learning based phenotyping approaches to create baseline results for individual sensors and multi-sensor fusion for detecting genetic mutations with known impacts. We also provide and support an open-ended …
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
We introduce Alexa Arena, a user-centric simulation platform to facilitate research in building assistive conversational embodied agents. Alexa Arena features multi-room layouts and an abundance of interactable objects. With user-friendly graphics and control mechanisms, the platform supports the development of gamified robotic tasks readily accessible to general human users, allowing high-efficiency data collection and EAI system evaluation. Along with the platform, we introduce a dialog-enabled task completion benchmark with online human evaluations.
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
The rise of datathons, also known as data or data science hackathons, has provided a platform to collaborate, learn, and innovate quickly. Despite their significant potential benefits, organizations often struggle to effectively work with data due to a lack of clear guidelines and best practices for potential issues that might arise. Drawing on our own experiences and insights from organizing +80 datathon challenges with +60 partnership organizations since 2016, we provide a guide that serves as a resource for organizers to navigate the data-related complexities of datathons. We apply our proposed framework to 10 case studies.
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
With rapid development and deployment of generative language models in global settings, there is an urgent need to also scale our measurements of harm, not just in the number and types of harms covered, but also how well they account for local cultural contexts, including marginalized identities and the social biases experienced by them.Current evaluation paradigms are limited in their abilities to address this, as they are not representative of diverse, locally situated but global, socio-cultural perspectives. It is imperative that our evaluation resources are enhanced and calibrated by including people and experiences from different cultures and societies worldwide, in order to prevent gross underestimations or skews in measurements of harm. In this work, we demonstrate a socio-culturally aware expansion of evaluation resources in the Indian societal context, specifically for the harm of stereotyping. We devise a community engaged effort to build a resource which contains stereotypes for axes of disparity that are uniquely present in India. The resultant resource increases the number of stereotypes known for and in the Indian context by over 1000 stereotypes across many unique identities. We also demonstrate the utility and effectiveness of such expanded resources for evaluations of language models.CONTENT WARNING: This paper contains …
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
We introduce RealTime QA, a dynamic question answering (QA) platform that announces questions and evaluates systems on a regular basis (weekly in this version). RealTime QA inquires about the current world, and QA systems need to answer questions about novel events or information. It therefore challenges static, conventional assumptions in open-domain QA datasets and pursues instantaneous applications. We build strong baseline models upon large pretrained language models, including GPT-3 and T5. Our benchmark is an ongoing effort, and this paper presents real-time evaluation results over the past year. Our experimental results show that GPT-3 can often properly update its generation results, based on newly-retrieved documents, highlighting the importance of up-to-date information retrieval. Nonetheless, we find that GPT-3 tends to return outdated answers when retrieved documents do not provide sufficient information to find an answer. This suggests an important avenue for future research: can an open-domain QA system identify such unanswerable cases and communicate with the user or even the retrieval module to modify the retrieval results? We hope that RealTime QA will spur progress in instantaneous applications of question answering and beyond.
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
Image retrieval is a fundamental task in computer vision. Despite recent advances in this field, many techniques have been evaluated on a limited number of domains, with a small number of instance categories. Notably, most existing works only consider domains like 3D landmarks, making it difficult to generalize the conclusions made by these works to other domains, e.g., logo and other 2D flat objects. To bridge this gap, we introduce a new dataset for benchmarking visual search methods on flat images with diverse patterns. Our flat object retrieval benchmark (FORB) supplements the commonly adopted 3D object domain, and more importantly, it serves as a testbed for assessing the image embedding quality on out-of-distribution domains. In this benchmark we investigate the retrieval accuracy of representative methods in terms of candidate ranks, as well as matching score margin, a viewpoint which is largely ignored by many works. Our experiments not only highlight the challenges and rich heterogeneity of FORB, but also reveal the hidden properties of different retrieval strategies. The proposed benchmark is a growing project and we expect to expand in both quantity and variety of objects. The dataset and supporting codes are available at https://github.com/pxiangwu/FORB/.
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
Neural rendering is fuelling a unification of learning, 3D geometry and video understanding that has been waiting for more than two decades. Progress, however, is still hampered by a lack of suitable datasets and benchmarks. To address this gap, we introduce EPIC Fields, an augmentation of EPIC-KITCHENS with 3D camera information. Like other datasets for neural rendering, EPIC Fields removes the complex and expensive step of reconstructing cameras using photogrammetry, and allows researchers to focus on modelling problems. We illustrate the challenge of photogrammetry in egocentric videos of dynamic actions and propose innovations to address them. Compared to other neural rendering datasets, EPIC Fields is better tailored to video understanding because it is paired with labelled action segments and the recent VISOR segment annotations. To further motivate the community, we also evaluate two benchmark tasks in neural rendering and segmenting dynamic objects, with strong baselines that showcase what is not possible today. We also highlight the advantage of geometry in semi-supervised video object segmentations on the VISOR annotations. EPIC Fields reconstructs 96\% of videos in EPIC-KITCHENS, registering 19M frames in 99 hours recorded in 45 kitchens, and is available from: http://epic-kitchens.github.io/epic-fields
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
The focus of our work is on diagnostic tasks in personalized learning, such as cognitive diagnosis and knowledge tracing. The goal of these tasks is to assess students' latent proficiency on knowledge concepts through analyzing their historical learning records. However, existing research has been limited to single-course scenarios; cross-course studies have not been explored due to a lack of dataset. We address this issue by constructing PTADisc, a Diverse, Immense, Student-centered dataset that emphasizes its sufficient Cross-course information for personalized learning. PTADisc includes 74 courses, 1,530,100 students, 4,054 concepts, 225,615 problems, and over 680 million student response logs. Based on PTADisc, we developed a model-agnostic Cross-Course Learner Modeling Framework (CCLMF) which utilizes relationships between students' proficiency across courses to alleviate the difficulty of diagnosing student knowledge state in cold-start scenarios. CCLMF uses a meta network to generate personalized mapping functions between courses. The experimental results on PTADisc verify the effectiveness of CCLMF with an average improvement of 4.2% on AUC. We also report the performance of baseline models for cognitive diagnosis and knowledge tracing over PTADisc, demonstrating that our dataset supports a wide scope of research in personalized learning. Additionally, PTADisc contains valuable programming logs and student-group information that are …
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
Does progress on ImageNet transfer to real-world datasets? We investigate this question by evaluating ImageNet pre-trained models with varying accuracy (57% - 83%) on six practical image classification datasets. In particular, we study datasets collected with the goal of solving real-world tasks (e.g., classifying images from camera traps or satellites), as opposed to web-scraped benchmarks collected for comparing models. On multiple datasets, models with higher ImageNet accuracy do not consistently yield performance improvements. For certain tasks, interventions such as data augmentation improve performance even when architectures do not. We hope that future benchmarks will include more diverse datasets to encourage a more comprehensive approach to improving learning algorithms.
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
The dramatic growth of global e-commerce has led to a surge in demand for efficient and cost-effective order fulfillment which can increase customers' service levels and sellers' competitiveness. However, managing order fulfillment is challenging due to a series of interdependent online sequential decision-making problems. To clear this hurdle, rather than solving the problems separately as attempted in some recent researches, this paper proposes a method based on multi-agent reinforcement learning to integratively solve the series of interconnected problems, encompassing order handling, packing and pickup, storage, order consolidation, and last-mile delivery. In particular, we model the integrated problem as a Markov game, wherein a team of agents learns a joint policy via interacting with a simulated environment. Since no simulated environment supporting the complete order fulfillment problem exists, we devise Order Fulfillment COoperative mUlti-agent Reinforcement learning Scalable Environment (OFCOURSE) in the OpenAI Gym style, which allows reproduction and re-utilization to build customized applications. By constructing the fulfillment system in OFCOURSE, we optimize a joint policy that solves the integrated problem, facilitating sequential order-wise operations across all fulfillment units and minimizing the total cost of fulfilling all orders within the promised time. With OFCOURSE, we also demonstrate that the joint policy learned …
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
Over the last several years, there has been significant progress in developing neural solvers for the Schrödinger Bridge (SB) problem and applying them to generative modelling. This new research field is justifiably fruitful as it is interconnected with the practically well-performing diffusion models and theoretically grounded entropic optimal transport (EOT). Still, the area lacks non-trivial tests allowing a researcher to understand how well the methods solve SB or its equivalent continuous EOT problem. We fill this gap and propose a novel way to create pairs of probability distributions for which the ground truth OT solution is known by the construction. Our methodology is generic and works for a wide range of OT formulations, in particular, it covers the EOT which is equivalent to SB (the main interest of our study). This development allows us to create continuous benchmark distributions with the known EOT and SB solutions on high-dimensional spaces such as spaces of images. As an illustration, we use these benchmark pairs to test how well existing neural EOT/SB solvers actually compute the EOT solution. Our code for constructing benchmark pairs under different setups is available at: https://github.com/ngushchin/EntropicOTBenchmark
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
Molecular Representation Learning (MRL) has emerged as a powerful tool for drug and materials discovery in a variety of tasks such as virtual screening and inverse design. While there has been a surge of interest in advancing model-centric techniques, the influence of both data quantity and quality on molecular representations is not yet clearly understood within this field. In this paper, we delve into the neural scaling behaviors of MRL from a data-centric viewpoint, examining four key dimensions: (1) data modalities, (2) dataset splitting, (3) the role of pre-training, and (4) model capacity.Our empirical studies confirm a consistent power-law relationship between data volume and MRL performance across these dimensions. Additionally, through detailed analysis, we identify potential avenues for improving learning efficiency.To challenge these scaling laws, we adapt seven popular data pruning strategies to molecular data and benchmark their performance. Our findings underline the importance of data-centric MRL and highlight possible directions for future research.
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
Photos serve as a way for humans to record what they experience in their daily lives, and they are often regarded as trustworthy sources of information. However, there is a growing concern that the advancement of artificial intelligence (AI) technology may produce fake photos, which can create confusion and diminish trust in photographs. This study aims to comprehensively evaluate agents for distinguishing state-of-the-art AI-generated visual content. Our study benchmarks both human capability and cutting-edge fake image detection AI algorithms, using a newly collected large-scale fake image dataset Fake2M. In our human perception evaluation, titled HPBench, we discovered that humans struggle significantly to distinguish real photos from AI-generated ones, with a misclassification rate of 38.7\%. Along with this, we conduct the model capability of AI-Generated images detection evaluation MPBench and the top-performing model from MPBench achieves a 13\% failure rate under the same setting used in the human evaluation.We hope that our study can raise awareness of the potential risks of AI-generated images and facilitate further research to prevent the spread of false information. More information can refer to https://github.com/Inf-imagine/Sentry.
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
Large language models (LLMs) have been recently leveraged as training data generators for various natural language processing (NLP) tasks. While previous research has explored different approaches to training models using generated data, they generally rely on simple class-conditional prompts, which may limit the diversity of the generated data and inherit systematic biases of LLM. Thus, we investigate training data generation with diversely attributed prompts (e.g., specifying attributes like length and style), which have the potential to yield diverse and attributed generated data. Our investigation focuses on datasets with high cardinality and diverse domains, wherein we demonstrate that attributed prompts outperform simple class-conditional prompts in terms of the resulting model's performance. Additionally, we present a comprehensive empirical study on data generation encompassing vital aspects like bias, diversity, and efficiency, and highlight three key observations: firstly, synthetic datasets generated by simple prompts exhibit significant biases, such as regional bias; secondly, attribute diversity plays a pivotal role in enhancing model performance; lastly, attributed prompts achieve the performance of simple class-conditional prompts while utilizing only 5\% of the querying cost of ChatGPT associated with the latter. The data and code are available on {\url{https://github.com/yueyu1030/AttrPrompt}}.
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
Machine learning (ML) models are only as good as the data they are trained on. But recent studies have found datasets widely used to train and evaluate ML models, e.g. ImageNet, to have pervasive labeling errors. Erroneous labels on the train set hurt ML models' ability to generalize, and they impact evaluation and model selection using the test set. Consequently, learning in the presence of labeling errors is an active area of research, yet this field lacks a comprehensive benchmark to evaluate these methods. Most of these methods are evaluated on a few computer vision datasets with significant variance in the experimental protocols. With such a large pool of methods and inconsistent evaluation, it is also unclear how ML practitioners can choose the right models to assess label quality in their data. To this end, we propose a benchmarking environment AQuA to rigorously evaluate methods that enable machine learning in the presence of label noise. We also introduce a design space to delineate concrete design choices of label error detection models. We hope that our proposed design space and benchmark enable practitioners to choose the right tools to improve their label quality and that our benchmark enables objective and …
[ Great Hall & Hall B1+B2 (level 1) ]
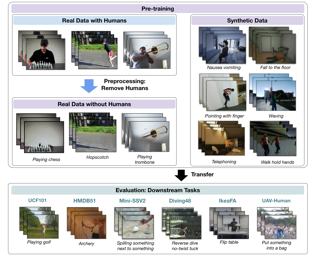
Abstract
Pre-training on massive video datasets has become essential to achieve high action recognition performance on smaller downstream datasets. However, most large-scale video datasets contain images of people and hence are accompanied with issues related to privacy, ethics, and data protection, often preventing them from being publicly shared for reproducible research. Existing work has attempted to alleviate these problems by blurring faces, downsampling videos, or training on synthetic data. On the other hand, analysis on the {\em transferability} of privacy-preserving pre-trained models to downstream tasks has been limited. In this work, we study this problem by first asking the question: can we pre-train models for human action recognition with data that does not include real humans? To this end, we present, for the first time, a benchmark that leverages real-world videos with {\em humans removed} and synthetic data containing virtual humans to pre-train a model. We then evaluate the transferability of the representation learned on this data to a diverse set of downstream action recognition benchmarks. Furthermore, we propose a novel pre-training strategy, called Privacy-Preserving MAE-Align, to effectively combine synthetic data and human-removed real data. Our approach outperforms previous baselines by up to 5\% and closes the performance gap between human …
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
As semiconductor devices become miniaturized and their structures become more complex, there is a growing need for large-scale atomic-level simulations as a less costly alternative to the trial-and-error approach during development.Although machine learning force fields (MLFFs) can meet the accuracy and scale requirements for such simulations, there are no open-access benchmarks for semiconductor materials.Hence, this study presents a comprehensive benchmark suite that consists of two semiconductor material datasets and ten MLFF models with six evaluation metrics. We select two important semiconductor thin-film materials silicon nitride and hafnium oxide, and generate their datasets using computationally expensive density functional theory simulations under various scenarios at a cost of 2.6k GPU days.Additionally, we provide a variety of architectures as baselines: descriptor-based fully connected neural networks and graph neural networks with rotational invariant or equivariant features.We assess not only the accuracy of energy and force predictions but also five additional simulation indicators to determine the practical applicability of MLFF models in molecular dynamics simulations.To facilitate further research, our benchmark suite is available at https://github.com/SAITPublic/MLFF-Framework.
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
Segmenting and recognizing diverse object parts is a crucial ability in applications spanning various computer vision and robotic tasks. While significant progress has been made in object-level Open-Vocabulary Semantic Segmentation (OVSS), i.e., segmenting objects with arbitrary text, the corresponding part-level research poses additional challenges. Firstly, part segmentation inherently involves intricate boundaries, while limited annotated data compounds the challenge. Secondly, part segmentation introduces an open granularity challenge due to the diverse and often ambiguous definitions of parts in the open world. Furthermore, the large-scale vision and language models, which play a key role in the open vocabulary setting, struggle to recognize parts as effectively as objects. To comprehensively investigate and tackle these challenges, we propose an Open-Vocabulary Part Segmentation (OV-PARTS) benchmark. OV-PARTS includes refined versions of two publicly available datasets: Pascal-Part-116 and ADE20K-Part-234. And it covers three specific tasks: Generalized Zero-Shot Part Segmentation, Cross-Dataset Part Segmentation, and Few-Shot Part Segmentation, providing insights into analogical reasoning, open granularity and few-shot adapting abilities of models. Moreover, we analyze and adapt two prevailing paradigms of existing object-level OVSS methods for OV-PARTS. Extensive experimental analysis is conducted to inspire future research in leveraging foundational models for OV-PARTS. The code and dataset are available at https://github.com/kellyiss/OV_PARTS.
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
Text-guided image editing is widely needed in daily life, ranging from personal use to professional applications such as Photoshop.However, existing methods are either zero-shot or trained on an automatically synthesized dataset, which contains a high volume of noise.Thus, they still require lots of manual tuning to produce desirable outcomes in practice.To address this issue, we introduce MagicBrush, the first large-scale, manually annotated dataset for instruction-guided real image editing that covers diverse scenarios: single-turn, multi-turn, mask-provided, and mask-free editing.MagicBrush comprises over 10K manually annotated triplets (source image, instruction, target image), which supports trainining large-scale text-guided image editing models.We fine-tune InstructPix2Pix on MagicBrush and show that the new model can produce much better images according to human evaluation.We further conduct extensive experiments to evaluate current image editing baselines from multiple dimensions including quantitative, qualitative, and human evaluations.The results reveal the challenging nature of our dataset and the gap between current baselines and real-world editing needs.
[ Great Hall & Hall B1+B2 (level 1) ]
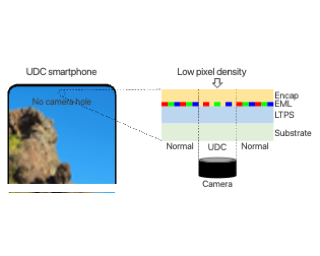
Abstract
Under Display Camera (UDC) is a novel imaging system that mounts a digital camera lens beneath a display panel with the panel covering the camera. However, the display panel causes severe degradation to captured images, such as low transmittance, blur, noise, and flare. The restoration of UDC-degraded images is challenging because of the unique luminance and diverse patterns of flares. Existing UDC dataset studies focus on unrealistic or synthetic UDC degradation rather than real-world UDC images. In this paper, we propose a real-world UDC dataset called UDC-SIT. To obtain the non-degraded and UDC-degraded images for the same scene, we propose an image-capturing system and an image alignment technique that exploits discrete Fourier transform (DFT) to align a pair of captured images. UDC-SIT also includes comprehensive annotations missing from other UDC datasets, such as light source, day/night, indoor/outdoor, and flare components (e.g., shimmers, streaks, and glares). We compare UDC-SIT with four existing representative UDC datasets and present the problems with existing UDC datasets. To show UDC-SIT's effectiveness, we compare UDC-SIT and a representative synthetic UDC dataset using four representative learnable image restoration models. The result indicates that the models trained with the synthetic UDC dataset are impractical because the synthetic UDC …
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
While the general machine learning (ML) community has benefited from public datasets, tasks, and models, the progress of ML in healthcare has been hampered by a lack of such shared assets. The success of foundation models creates new challenges for healthcare ML by requiring access to shared pretrained models to validate performance benefits. We help address these challenges through three contributions. First, we publish a new dataset, EHRSHOT, which contains de-identified structured data from the electronic health records (EHRs) of 6,739 patients from Stanford Medicine. Unlike MIMIC-III/IV and other popular EHR datasets, EHRSHOT is longitudinal and not restricted to ICU/ED patients. Second, we publish the weights of CLMBR-T-base, a 141M parameter clinical foundation model pretrained on the structured EHR data of 2.57M patients. We are one of the first to fully release such a model for coded EHR data; in contrast, most prior models released for clinical data (e.g. GatorTron, ClinicalBERT) only work with unstructured text and cannot process the rich, structured data within an EHR. We provide an end-to-end pipeline for the community to validate and build upon its performance. Third, we define 15 few-shot clinical prediction tasks, enabling evaluation of foundation models on benefits such as sample efficiency …
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
A good metric, which promises a reliable comparison between solutions, is essential for any well-defined task. Unlike most vision tasks that have per-sample ground-truth, image synthesis tasks target generating unseen data and hence are usually evaluated through a distributional distance between one set of real samples and another set of generated samples. This study presents an empirical investigation into the evaluation of synthesis performance, with generative adversarial networks (GANs) as a representative of generative models. In particular, we make in-depth analyses of various factors, including how to represent a data point in the representation space, how to calculate a fair distance using selected samples, and how many instances to use from each set. Extensive experiments conducted on multiple datasets and settings reveal several important findings. Firstly, a group of models that include both CNN-based and ViT-based architectures serve as reliable and robust feature extractors for measurement evaluation. Secondly, Centered Kernel Alignment (CKA) provides a better comparison across various extractors and hierarchical layers in one model. Finally, CKA is more sample-efficient and enjoys better agreement with human judgment in characterizing the similarity between two internal data correlations. These findings contribute to the development of a new measurement system, which enables a …
[ Great Hall & Hall B1+B2 (level 1) ]
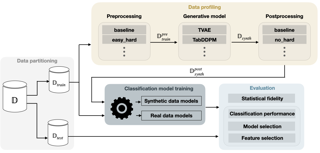
Abstract
Synthetic data serves as an alternative in training machine learning models, particularly when real-world data is limited or inaccessible. However, ensuring that synthetic data mirrors the complex nuances of real-world data is a challenging task. This paper addresses this issue by exploring the potential of integrating data-centric AI techniques which profile the data to guide the synthetic data generation process. Moreover, we shed light on the often ignored consequences of neglecting these data profiles during synthetic data generation --- despite seemingly high statistical fidelity. Subsequently, we propose a novel framework to evaluate the integration of data profiles to guide the creation of more representative synthetic data. In an empirical study, we evaluate the performance of five state-of-the-art models for tabular data generation on eleven distinct tabular datasets. The findings offer critical insights into the successes and limitations of current synthetic data generation techniques. Finally, we provide practical recommendations for integrating data-centric insights into the synthetic data generation process, with a specific focus on classification performance, model selection, and feature selection. This study aims to reevaluate conventional approaches to synthetic data generation and promote the application of data-centric AI techniques in improving the quality and effectiveness of synthetic data.
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
The two-hand interaction is one of the most challenging signals to analyze due to the self-similarity, complicated articulations, and occlusions of hands. Although several datasets have been proposed for the two-hand interaction analysis, all of them do not achieve 1) diverse and realistic image appearances and 2) diverse and large-scale groundtruth (GT) 3D poses at the same time. In this work, we propose Re:InterHand, a dataset of relighted 3D interacting hands that achieve the two goals. To this end, we employ a state-of-the-art hand relighting network with our accurately tracked two-hand 3D poses. We compare our Re:InterHand with existing 3D interacting hands datasets and show the benefit of it. Our Re:InterHand is available in https://mks0601.github.io/ReInterHand/
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
Everyday news coverage has shifted from traditional broadcasts towards a wide range of presentation formats such as first-hand, unedited video footage. Datasets that reflect the diverse array of multimodal, multilingual news sources available online could be used to teach models to benefit from this shift, but existing news video datasets focus on traditional news broadcasts produced for English-speaking audiences. We address this limitation by constructing MultiVENT, a dataset of multilingual, event-centric videos grounded in text documents across five target languages. MultiVENT includes both news broadcast videos and non-professional event footage, which we use to analyze the state of online news videos and how they can be leveraged to build robust, factually accurate models. Finally, we provide a model for complex, multilingual video retrieval to serve as a baseline for information retrieval using MultiVENT.
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
Chain-of-thought prompting (CoT) and tool augmentation have been validated in recent work as effective practices for improving large language models (LLMs) to perform step-by-step reasoning on complex math-related tasks.However, most existing math reasoning datasets may not be able to fully evaluate and analyze the ability of LLMs in manipulating tools and performing reasoning, as they often only require very few invocations of tools or miss annotations for evaluating intermediate reasoning steps, thus supporting only outcome evaluation.To address the issue, we construct CARP, a new Chinese dataset consisting of 4,886 computation-intensive algebra problems with formulated annotations on intermediate steps, facilitating the evaluation of the intermediate reasoning process.In CARP, we test four LLMs with CoT prompting, and find that they are all prone to make mistakes at the early steps of the solution, leading to incorrect answers.Based on this finding, we propose a new approach that can facilitate the deliberation on reasoning steps with tool interfaces, namely DELI.In DELI, we first initialize a step-by-step solution based on retrieved exemplars, then iterate two deliberation procedures that check and refine the intermediate steps of the generated solution, from both tool manipulation and natural language reasoning perspectives, until solutions converge or the maximum …
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
3D segmentation of nuclei images is a fundamental task for many biological studies. Despite the rapid advances of large-volume 3D imaging acquisition methods and the emergence of sophisticated algorithms to segment the nuclei in recent years, a benchmark with all cells completely annotated is still missing, making it hard to accurately assess and further improve the performance of the algorithms. The existing nuclei segmentation benchmarks either worked on 2D only or annotated a small number of 3D cells, perhaps due to the high cost of 3D annotation for large-scale data. To fulfill the critical need, we constructed NIS3D, a 3D, high cell density, large-volume, and completely annotated Nuclei Image Segmentation benchmark, assisted by our newly designed semi-automatic annotation software. NIS3D provides more than 22,000 cells across multiple most-used species in this area. Each cell is labeled by three independent annotators, so we can measure the variability of each annotation. A confidence score is computed for each cell, allowing more nuanced testing and performance comparison. A comprehensive review on the methods of segmenting 3D dense nuclei was conducted. The benchmark was used to evaluate the performance of several selected state-of-the-art segmentation algorithms. The best of current methods is still far away …
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
Object anomaly detection is an important problem in the field of machine vision and has seen remarkable progress recently. However, two significant challenges hinder its research and application. First, existing datasets lack comprehensive visual information from various pose angles. They usually have an unrealistic assumption that the anomaly-free training dataset is pose-aligned, and the testing samples have the same pose as the training data. However, in practice, anomaly may exist in any regions on a object, the training and query samples may have different poses, calling for the study on pose-agnostic anomaly detection. Second, the absence of a consensus on experimental protocols for pose-agnostic anomaly detection leads to unfair comparisons of different methods, hindering the research on pose-agnostic anomaly detection. To address these issues, we develop Multi-pose Anomaly Detection (MAD) dataset and Pose-agnostic Anomaly Detection (PAD) benchmark, which takes the first step to address the pose-agnostic anomaly detection problem. Specifically, we build MAD using 20 complex-shaped LEGO toys including 4K views with various poses, and high-quality and diverse 3D anomalies in both simulated and real environments. Additionally, we propose a novel method OmniposeAD, trained using MAD, specifically designed for pose-agnostic anomaly detection. Through comprehensive evaluations, we demonstrate the relevance of …
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
Multi-agent reinforcement learning (MARL) research is faced with a trade-off: it either uses complex environments requiring large compute resources, which makes it inaccessible to researchers with limited resources, or relies on simpler dynamics for faster execution, which makes the transferability of the results to more realistic tasks challenging. Motivated by these challenges, we present Gigastep, a fully vectorizable, MARL environment implemented in JAX, capable of executing up to one billion environment steps per second on consumer-grade hardware. Its design allows for comprehensive MARL experimentation, including a complex, high-dimensional space defined by 3D dynamics, stochasticity, and partial observations. Gigastep supports both collaborative and adversarial tasks, continuous and discrete action spaces, and provides RGB image and feature vector observations, allowing the evaluation of a wide range of MARL algorithms. We validate Gigastep's usability through an extensive set of experiments, underscoring its role in widening participation and promoting inclusivity in the MARL research community.
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
NetHack is known as the frontier of reinforcement learning research where learning-based methods still need to catch up to rule-based solutions. One of the promising directions for a breakthrough is using pre-collected datasets similar to recent developments in robotics, recommender systems, and more under the umbrella of offline reinforcement learning (ORL). Recently, a large-scale NetHack dataset was released; while it was a necessary step forward, it has yet to gain wide adoption in the ORL community. In this work, we argue that there are three major obstacles for adoption: tool-wise, implementation-wise, and benchmark-wise. To address them, we develop an open-source library that provides workflow fundamentals familiar to the ORL community: pre-defined D4RL-style tasks, uncluttered baseline implementations, and reliable evaluation tools with accompanying configs and logs synced to the cloud.
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
This paper explores the impact of occlusions in video action detection. We facilitatethis study by introducing five new benchmark datasets namely O-UCF and O-JHMDB consisting of synthetically controlled static/dynamic occlusions, OVIS-UCF and OVIS-JHMDB consisting of occlusions with realistic motions and Real-OUCF for occlusions in realistic-world scenarios. We formally confirm an intuitiveexpectation: existing models suffer a lot as occlusion severity is increased andexhibit different behaviours when occluders are static vs when they are moving.We discover several intriguing phenomenon emerging in neural nets: 1) transformerscan naturally outperform CNN models which might have even used occlusion as aform of data augmentation during training 2) incorporating symbolic-componentslike capsules to such backbones allows them to bind to occluders never even seenduring training and 3) Islands of agreement (similar to the ones hypothesized inHinton et Al’s GLOM) can emerge in realistic images/videos without instance-levelsupervision, distillation or contrastive-based objectives(eg. video-textual training).Such emergent properties allow us to derive simple yet effective training recipeswhich lead to robust occlusion models inductively satisfying the first two stages ofthe binding mechanism (grouping/segregation). Models leveraging these recipesoutperform existing video action-detectors under occlusion by 32.3% on O-UCF,32.7% on O-JHMDB & 2.6% on Real-OUCF in terms of the vMAP metric. The code for this work …
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
Robustness to distribution shift has become a growing concern for text and image models as they transition from research subjects to deployment in the real world. However, high-quality benchmarks for distribution shift in tabular machine learning tasks are still lacking despite the widespread real-world use of tabular data and differences in the models used for tabular data in comparison to text and images. As a consequence, the robustness of tabular models to distribution shift is poorly understood. To address this issue, we introduce TableShift, a distribution shift benchmark for tabular data. TableShift contains 15 binary classification tasks in total, each with an associated shift, and includes a diverse set of data sources, prediction targets, and distribution shifts. The benchmark covers domains including finance, education, public policy, healthcare, and civic participation, and is accessible using only a few lines of Python code via the TableShift API. We conduct a large-scale study comparing several state-of-the-art tabular data models alongside robust learning and domain generalization methods on the benchmark tasks. Our study demonstrates (1) a linear trend between in-distribution (ID) and out-of-distribution (OOD) accuracy; (2) domain robustness methods can reduce shift gaps but at the cost of reduced ID accuracy; (3) a strong …
[ Great Hall & Hall B1+B2 (level 1) ]
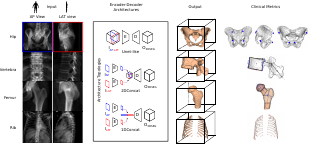
Abstract
Various deep learning models have been proposed for 3D bone shape reconstruction from two orthogonal (biplanar) X-ray images.However, it is unclear how these models compare against each other since they are evaluated on different anatomy, cohort and (often privately held) datasets.Moreover, the impact of the commonly optimized image-based segmentation metrics such as dice score on the estimation of clinical parameters relevant in 2D-3D bone shape reconstruction is not well known.To move closer toward clinical translation, we propose a benchmarking framework that evaluates tasks relevant to real-world clinical scenarios, including reconstruction of fractured bones, bones with implants, robustness to population shift, and error in estimating clinical parameters.Our open-source platform provides reference implementations of 8 models (many of whose implementations were not publicly available), APIs to easily collect and preprocess 6 public datasets, and the implementation of automatic clinical parameter and landmark extraction methods. We present an extensive evaluation of 8 2D-3D models on equal footing using 6 public datasets comprising images for four different anatomies.Our results show that attention-based methods that capture global spatial relationships tend to perform better across all anatomies and datasets; performance on clinically relevant subgroups may be overestimated without disaggregated reporting; ribs are substantially more difficult to …
[ Great Hall & Hall B1+B2 (level 1) ]
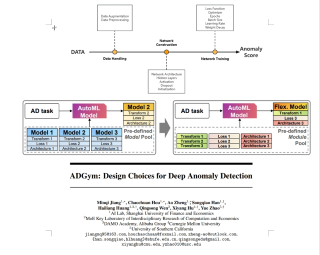
Abstract
Deep learning (DL) techniques have recently found success in anomaly detection (AD) across various fields such as finance, medical services, and cloud computing. However, most of the current research tends to view deep AD algorithms as a whole, without dissecting the contributions of individual design choices like loss functions and network architectures. This view tends to diminish the value of preliminary steps like data preprocessing, as more attention is given to newly designed loss functions, network architectures, and learning paradigms. In this paper, we aim to bridge this gap by asking two key questions: (i) Which design choices in deep AD methods are crucial for detecting anomalies? (ii) How can we automatically select the optimal design choices for a given AD dataset, instead of relying on generic, pre-existing solutions? To address these questions, we introduce ADGym, a platform specifically crafted for comprehensive evaluation and automatic selection of AD design elements in deep methods. Our extensive experiments reveal that relying solely on existing leading methods is not sufficient. In contrast, models developed using ADGym significantly surpass current state-of-the-art techniques.
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
We consider the problem of traffic accident analysis on a road network based on road network connections and traffic volume. Previous works have designed various deep-learning methods using historical records to predict traffic accident occurrences. However, there is a lack of consensus on how accurate existing methods are, and a fundamental issue is the lack of public accident datasets for comprehensive evaluations. This paper constructs a large-scale, unified dataset of traffic accident records from official reports of various states in the US, totaling 9 million records, accompanied by road networks and traffic volume reports. Using this new dataset, we evaluate existing deep-learning methods for predicting the occurrence of accidents on road networks. Our main finding is that graph neural networks such as GraphSAGE can accurately predict the number of accidents on roads with less than 22% mean absolute error (relative to the actual count) and whether an accident will occur or not with over 87% AUROC, averaged over states. We achieve these results by using multitask learning to account for cross-state variabilities (e.g., availability of accident labels) and transfer learning to combine traffic volume with accident prediction. Ablation studies highlight the importance of road graph-structural features, amongst other features. Lastly, …
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
Numerous benchmarks have been established to assess the performance of foundation models on open-ended question answering, which serves as a comprehensive test of a model's ability to understand and generate language in a manner similar to humans.Most of these works focus on proposing new datasets, however, we see two main issues within previous benchmarking pipelines, namely testing leakage and evaluation automation. In this paper, we propose a novel benchmarking framework, Language-Model-as-an-Examiner, where the LM serves as a knowledgeable examiner that formulates questions based on its knowledge and evaluates responses in a reference-free manner. Our framework allows for effortless extensibility as various LMs can be adopted as the examiner, and the questions can be constantly updated given more diverse trigger topics. For a more comprehensive and equitable evaluation, we devise three strategies: (1) We instruct the LM examiner to generate questions across a multitude of domains to probe for a broad acquisition, and raise follow-up questions to engage in a more in-depth assessment. (2) Upon evaluation, the examiner combines both scoring and ranking measurements, providing a reliable result as it aligns closely with human annotations. (3) We additionally propose a decentralized Peer-examination method to address the biases in a single examiner. …
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
Recent advancements in large language models (LLMs) have transformed the field of question answering (QA). However, evaluating LLMs in the medical field is challenging due to the lack of standardized and comprehensive datasets. To address this gap, we introduce CMExam, sourced from the Chinese National Medical Licensing Examination. CMExam consists of 60K+ multiple-choice questions for standardized and objective evaluations, as well as solution explanations for model reasoning evaluation in an open-ended manner. For in-depth analyses of LLMs, we invited medical professionals to label five additional question-wise annotations, including disease groups, clinical departments, medical disciplines, areas of competency, and question difficulty levels. Alongside the dataset, we further conducted thorough experiments with representative LLMs and QA algorithms on CMExam. The results show that GPT-4 had the best accuracy of 61.6% and a weighted F1 score of 0.617. These results highlight a great disparity when compared to human accuracy, which stood at 71.6%. For explanation tasks, while LLMs could generate relevant reasoning and demonstrate improved performance after finetuning, they fall short of a desired standard, indicating ample room for improvement. To the best of our knowledge, CMExam is the first Chinese medical exam dataset to provide comprehensive medical annotations. The experiments and findings …
[ Great Hall & Hall B1+B2 (level 1) ]
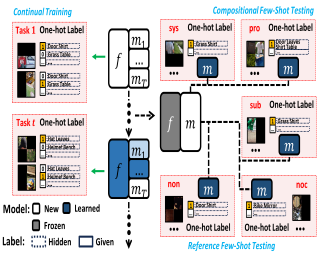
Abstract
Compositionality facilitates the comprehension of novel objects using acquired concepts and the maintenance of a knowledge pool. This is particularly crucial for continual learners to prevent catastrophic forgetting and enable compositionally forward transfer of knowledge. However, the existing state-of-the-art benchmarks inadequately evaluate the capability of compositional generalization, leaving an intriguing question unanswered. To comprehensively assess this capability, we introduce two vision benchmarks, namely Compositional GQA (CGQA) and Compositional OBJects365 (COBJ), along with a novel evaluation framework called Compositional Few-Shot Testing (CFST). These benchmarks evaluate the systematicity, productivity, and substitutivity aspects of compositional generalization. Experimental results on five baselines and two modularity-based methods demonstrate that current continual learning techniques do exhibit somewhat favorable compositionality in their learned feature extractors. Nonetheless, further efforts are required in developing modularity-based approaches to enhance compositional generalization. We anticipate that our proposed benchmarks and evaluation protocol will foster research on continual learning and compositionality.
[ Great Hall & Hall B1+B2 (level 1) ]
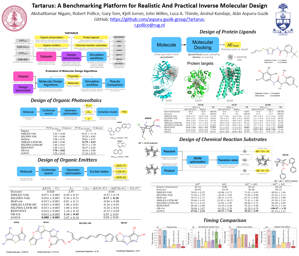
Abstract
The efficient exploration of chemical space to design molecules with intended properties enables the accelerated discovery of drugs, materials, and catalysts, and is one of the most important outstanding challenges in chemistry. Encouraged by the recent surge in computer power and artificial intelligence development, many algorithms have been developed to tackle this problem. However, despite the emergence of many new approaches in recent years, comparatively little progress has been made in developing realistic benchmarks that reflect the complexity of molecular design for real-world applications. In this work, we develop a set of practical benchmark tasks relying on physical simulation of molecular systems mimicking real-life molecular design problems for materials, drugs, and chemical reactions. Additionally, we demonstrate the utility and ease of use of our new benchmark set by demonstrating how to compare the performance of several well-established families of algorithms. Overall, we believe that our benchmark suite will help move the field towards more realistic molecular design benchmarks, and move the development of inverse molecular design algorithms closer to the practice of designing molecules that solve existing problems in both academia and industry alike.
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
As Large Language Models (LLMs) become increasingly integrated into our everyday lives, understanding their ability to comprehend human mental states becomes critical for ensuring effective interactions. However, despite the recent attempts to assess the Theory-of-Mind (ToM) reasoning capabilities of LLMs, the degree to which these models can align with human ToM remains a nuanced topic of exploration. This is primarily due to two distinct challenges: (1) the presence of inconsistent results from previous evaluations, and (2) concerns surrounding the validity of existing evaluation methodologies. To address these challenges, we present a novel framework for procedurally generating evaluations with LLMs by populating causal templates. Using our framework, we create a new social reasoning benchmark (BigToM) for LLMs which consists of 25 controls and 5,000 model-written evaluations. We find that human participants rate the quality of our benchmark higher than previous crowd-sourced evaluations and comparable to expert-written evaluations. Using BigToM, we evaluate the social reasoning capabilities of a variety of LLMs and compare model performances with human performance. Our results suggest that GPT4 has ToM capabilities that mirror human inference patterns, though less reliable, while other LLMs struggle.
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
Text-to-SQL parsing, which aims at converting natural language instructions into executable SQLs, has gained increasing attention in recent years. In particular, GPT-4 and Claude-2 have shown impressive results in this task. However, most of the prevalent benchmarks, i.e., Spider, and WikiSQL, focus on database schema with few rows of database contents leaving the gap between academic study and real-world applications. To mitigate this gap, we present BIRD, a BIg benchmark for laRge-scale Database grounded in text-to-SQL tasks, containing 12,751 pairs of text-to-SQL data and 95 databases with a total size of 33.4 GB, spanning 37 professional domains. Our emphasis on database values highlights the new challenges of dirty database contents, external knowledge between NL questions and database contents, and SQL efficiency, particularly in the context of massive databases. To solve these problems, text-to-SQL models must feature database value comprehension in addition to semantic parsing. The experimental results demonstrate the significance of database values in generating accurate text-to-SQLs for big databases. Furthermore, even the most popular and effective text-to-SQL models, i.e. GPT-4, only achieve 54.89% in execution accuracy, which is still far from the human result of 92.96%, proving that challenges still stand. We also provide an efficiency analysis to offer …
[ Great Hall & Hall B1+B2 (level 1) ]
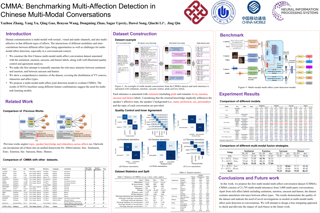
Abstract
Human communication has a multi-modal and multi-affection nature. The inter-relatedness of different emotions and sentiments poses a challenge to jointly detect multiple human affections with multi-modal clues. Recent advances in this field employed multi-task learning paradigms to render the inter-relatedness across tasks, but the scarcity of publicly available resources sets a limit to the potential of works. To fill this gap, we build the first Chinese Multi-modal Multi-Affection conversation (CMMA) dataset, which contains 3,000 multi-party conversations and 21,795 multi-modal utterances collected from various styles of TV-series. CMMA contains a wide variety of affection labels, including sentiment, emotion, sarcasm and humor, as well as the novel inter-correlations values between certain pairs of tasks. Moreover, it provides the topic and speaker information in conversations, which promotes better modeling of conversational context. On the dataset, we empirically analyze the influence of different data modalities and conversational contexts on different affection analysis tasks, and exhibit the practical benefit of inter-task correlations. The full dataset will be publicly available for research\footnote{https://github.com/annoymity2022/Chinese-Dataset}
[ Great Hall & Hall B1+B2 (level 1) ]
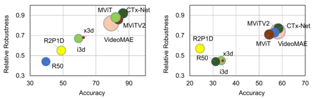
Abstract
In this work, we study the effect of occlusion on video action recognition. Tofacilitate this study, we propose three benchmark datasets and experiment withseven different video action recognition models. These datasets include two synthetic benchmarks, UCF-101-O and K-400-O, which enabled understanding the effects of fundamental properties of occlusion via controlled experiments. We also propose a real-world occlusion dataset, UCF-101-Y-OCC, which helps in further validating the findings of this study. We find several interesting insights such as 1) transformers are more robust than CNN counterparts, 2) pretraining make modelsrobust against occlusions, and 3) augmentation helps, but does not generalize well to real-world occlusions. In addition, we propose a simple transformer based compositional model, termed as CTx-Net, which generalizes well under this distribution shift. We observe that CTx-Net outperforms models which are trained using occlusions as augmentation, performing significantly better under natural occlusions. We believe this benchmark will open up interesting future research in robust video action recognition
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
[ Great Hall & Hall B1+B2 (level 1) ]
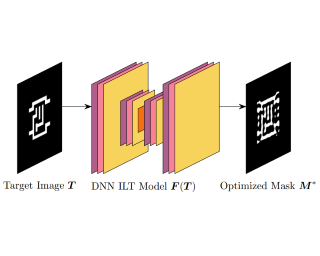
Abstract
Computational lithography provides algorithmic and mathematical support for resolution enhancement in optical lithography, which is the critical step in semiconductor manufacturing. The time-consuming lithography simulation and mask optimization processes limit the practical application of inverse lithography technology (ILT), a promising solution to the challenges of advanced-node lithography. Although various machine learning methods for ILT have shown promise for reducing the computational burden, this field is in lack of a dataset that can train the models thoroughly and evaluate the performance comprehensively. To boost the development of AI-driven computational lithography, we present the LithoBench dataset, a collection of circuit layout tiles for deep-learning-based lithography simulation and mask optimization. LithoBench consists of more than 120k tiles that are cropped from real circuit designs or synthesized according to the layout topologies of famous ILT testcases. The ground truths are generated by a famous lithography model in academia and an advanced ILT method. Based on the data, we provide a framework to design and evaluate deep neural networks (DNNs) with the data. The framework is used to benchmark state-of-the-art models on lithography simulation and mask optimization. We hope LithoBench can promote the research and development of computational lithography. LithoBench is available at https://anonymous.4open.science/r/lithobench-APPL.
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
To ensure secure and dependable mobility in environments shared by humans and robots, social navigation robots should possess the capability to accurately perceive and predict the trajectories of nearby pedestrians. In this paper, we present a novel dataset of pedestrian trajectories, referred to as Social Interactive Trajectory (SiT) dataset, which can be used to train pedestrian detection, tracking, and trajectory prediction models needed to design social navigation robots. Our dataset includes sequential raw data captured by two 3D LiDARs and five cameras covering a 360-degree view, two inertial measurement unit (IMU) sensors, and real-time kinematic positioning (RTK), as well as annotations including 2D & 3D boxes, object classes, and object IDs. Thus far, various human trajectory datasets have been introduced to support the development of pedestrian motion forecasting models. Our SiT dataset differs from these datasets in the following two respects. First, whereas the pedestrian trajectory data in other datasets was obtained from static scenes, our data was collected while the robot navigates in a crowded environment, capturing human-robot interactive scenarios in motion. Second, our dataset has been carefully organized to facilitate training and evaluation of end-to-end prediction models encompassing 3D detection, 3D multi-object tracking, and trajectory prediction. This design …
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
Large language models are commonly trained on a mixture of filtered web data and curated ``high-quality'' corpora, such as social media conversations, books, or technical papers. This curation process is believed to be necessary to produce performant models with broad zero-shot generalization abilities. However, as larger models requiring pretraining on trillions of tokens are considered, it is unclear how scalable is curation, and whether we will run out of unique high-quality data soon. At variance with previous beliefs, we show that properly filtered and deduplicated web data alone can lead to powerful models; even significantly outperforming models trained on The Pile. Despite extensive filtering, the high-quality data we extract from the web is still plentiful, and we are able to obtain five trillion tokens from CommonCrawl. We publicly release an extract of 500 billion tokens from our RefinedWeb dataset, and 1.3/7.5B parameters language models trained on it.
[ Great Hall & Hall B1+B2 (level 1) ]
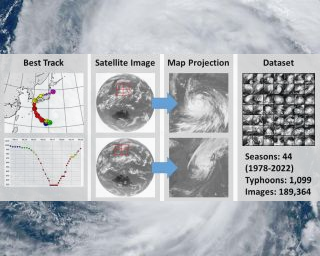
Abstract
This paper presents the official release of the Digital Typhoon dataset, the longest typhoon satellite image dataset for 40+ years aimed at benchmarking machine learning models for long-term spatio-temporal data. To build the dataset, we developed a workflow to create an infrared typhoon-centered image for cropping using Lambert azimuthal equal-area projection referring to the best track data. We also address data quality issues such as inter-satellite calibration to create a homogeneous dataset. To take advantage of the dataset, we organized machine learning tasks by the types and targets of inference, with other tasks for meteorological analysis, societal impact, and climate change. The benchmarking results on the analysis, forecasting, and reanalysis for the intensity suggest that the dataset is challenging for recent deep learning models, due to many choices that affect the performance of various models. This dataset reduces the barrier for machine learning researchers to meet large-scale real-world events called tropical cyclones and develop machine learning models that may contribute to advancing scientific knowledge on tropical cyclones as well as solving societal and sustainability issues such as disaster reduction and climate change. The dataset is publicly available at http://agora.ex.nii.ac.jp/digital-typhoon/dataset/ and https://github.com/kitamoto-lab/digital-typhoon/.
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
The capacity to reason logically is a hallmark of human cognition. Humans excel at integrating multimodal information for locigal reasoning, as exemplified by the Visual Question Answering (VQA) task, which is a challenging multimodal task. VQA tasks and large vision-and-language models aim to tackle reasoning problems, but the accuracy, consistency and fabrication of the generated answers is hard to evaluate in the absence of a VQA dataset that can offer formal, comprehensive and systematic complex logical reasoning questions. To address this gap, we present LoRA, a novel Logical Reasoning Augmented VQA dataset that requires formal and complex description logic reasoning based on a food-and-kitchen knowledge base. Our main objective in creating LoRA is to enhance the complex and formal logical reasoning capabilities of VQA models, which are not adequately measured by existing VQA datasets. We devise strong and flexible programs to automatically generate 200,000 diverse description logic reasoning questions based on the SROIQ Description Logic, along with realistic kitchen scenes and ground truth answers. We fine-tune the latest transformer VQA models and evaluate the zero-shot performance of the state-of-the-art large vision-and-language models on LoRA. The results reveal that LoRA presents a unique challenge in logical reasoning, setting a systematic and …
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
This study focuses on the evaluation of the Open Question Answering (Open-QA) task, which can directly estimate the factuality of large language models (LLMs). Current automatic evaluation methods have shown limitations, indicating that human evaluation still remains the most reliable approach. We introduce a new task, QA Evaluation (QA-Eval) and the corresponding dataset EVOUNA, designed to assess the accuracy of AI-generated answers in relation to standard answers within Open-QA. Our evaluation of these methods utilizes human-annotated results to measure their performance. Specifically, the work investigates methods that show high correlation with human evaluations, deeming them more reliable. We also discuss the pitfalls of current methods and methods to improve LLM-based evaluators. We believe this new QA-Eval task and corresponding dataset EVOUNA will facilitate the development of more effective automatic evaluation tools and prove valuable for future research in this area. All resources are available at https://github.com/wangcunxiang/QA-Eval and it is under the Apache-2.0 License.
[ Great Hall & Hall B1+B2 (level 1) ]
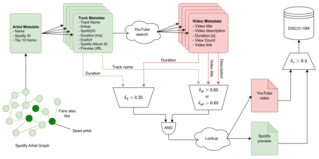
Abstract
Music datasets play a crucial role in advancing research in machine learning for music. However, existing music datasets suffer from limited size, accessibility, and lack of audio resources. To address these shortcomings, we present DISCO-10M, a novel and extensive music dataset that surpasses the largest previously available music dataset by an order of magnitude. To ensure high-quality data, we implement a multi-stage filtering process. This process incorporates similarities based on textual descriptions and audio embeddings. Moreover, we provide precomputed CLAP embeddings alongside DISCO-10M, facilitating direct application on various downstream tasks. These embeddings enable efficient exploration of machine learning applications on the provided data. With DISCO-10M, we aim to democratize and facilitate new research to help advance the development of novel machine learning models for music: https://huggingface.co/DISCOX
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
Multi-objective reinforcement learning algorithms (MORL) extend standard reinforcement learning (RL) to scenarios where agents must optimize multiple---potentially conflicting---objectives, each represented by a distinct reward function. To facilitate and accelerate research and benchmarking in multi-objective RL problems, we introduce a comprehensive collection of software libraries that includes: (i) MO-Gymnasium, an easy-to-use and flexible API enabling the rapid construction of novel MORL environments. It also includes more than 20 environments under this API. This allows researchers to effortlessly evaluate any algorithms on any existing domains; (ii) MORL-Baselines, a collection of reliable and efficient implementations of state-of-the-art MORL algorithms, designed to provide a solid foundation for advancing research. Notably, all algorithms are inherently compatible with MO-Gymnasium; and(iii) a thorough and robust set of benchmark results and comparisons of MORL-Baselines algorithms, tested across various challenging MO-Gymnasium environments. These benchmarks were constructed to serve as guidelines for the research community, underscoring the properties, advantages, and limitations of each particular state-of-the-art method.
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
The availability of challenging benchmarks has played a key role in the recent progress of machine learning. In cooperative multi-agent reinforcement learning, the StarCraft Multi-Agent Challenge (SMAC) has become a popular testbed for centralised training with decentralised execution. However, after years of sustained improvement on SMAC, algorithms now achieve near-perfect performance. In this work, we conduct new analysis demonstrating that SMAC lacks the stochasticity and partial observability to require complex closed-loop policies. In particular, we show that an open-loop policy conditioned only on the timestep can achieve non-trivial win rates for many SMAC scenarios. To address this limitation, we introduce SMACv2, a new version of the benchmark where scenarios are procedurally generated and require agents to generalise to previously unseen settings (from the same distribution) during evaluation. We also introduce the extended partial observability challenge (EPO), which augments SMACv2 to ensure meaningful partial observability. We show that these changes ensure the benchmarkrequires the use of closed-loop policies. We evaluate state-of-the-art algorithms on SMACv2 and show that it presents significant challenges not present in the original benchmark. Our analysis illustrates that SMACv2 addresses the discovered deficiencies of SMAC and can help benchmark the next generation of MARL methods. Videos of training …
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
Artificial intelligence (AI) systems possess significant potential to drive societal progress. However, their deployment often faces obstacles due to substantial safety concerns. Safe reinforcement learning (SafeRL) emerges as a solution to optimize policies while simultaneously adhering to multiple constraints, thereby addressing the challenge of integrating reinforcement learning in safety-critical scenarios. In this paper, we present an environment suite called Safety-Gymnasium, which encompasses safety-critical tasks in both single and multi-agent scenarios, accepting vector and vision-only input. Additionally, we offer a library of algorithms named Safe Policy Optimization (SafePO), comprising 16 state-of-the-art SafeRL algorithms. This comprehensive library can serve as a validation tool for the research community. By introducing this benchmark, we aim to facilitate the evaluation and comparison of safety performance, thus fostering the development of reinforcement learning for safer, more reliable, and responsible real-world applications. The website of this project can be accessed at https://sites.google.com/view/safety-gymnasium.
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
In the current landscape of pervasive smartphones and tablets, apps frequently exist across both platforms.Although apps share most graphic user interfaces (GUIs) and functionalities across phones and tablets, developers often rebuild from scratch for tablet versions, escalating costs and squandering existing design resources.Researchers are attempting to collect data and employ deep learning in automated GUIs development to enhance developers' productivity.There are currently several publicly accessible GUI page datasets for phones, but none for pairwise GUIs between phones and tablets.This poses a significant barrier to the employment of deep learning in automated GUI development.In this paper, we introduce the Papt dataset, a pioneering pairwise GUI dataset tailored for Android phones and tablets, encompassing 10,035 phone-tablet GUI page pairs sourced from 5,593 unique app pairs.We propose novel pairwise GUI collection approaches for constructing this dataset and delineate its advantages over currently prevailing datasets in the field.Through preliminary experiments on this dataset, we analyze the present challenges of utilizing deep learning in automated GUI development.
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
Foundation models are trained on increasingly immense and opaque datasets. Even while these models are now key in AI system building, it can be difficult to answer the straightforward question: has the model already encountered a given example during training? We therefore propose a widespread adoption of Data Portraits: artifacts that record training data and allow for downstream inspection. First we outline the properties of such an artifact and discuss how existing solutions can be used to increase transparency. We then propose and implement a solution based on data sketching, stressing fast and space efficient querying. Using our tools, we document a popular language modeling corpus (The Pile) and a recently released code modeling dataset (The Stack). We show that our solution enables answering questions about test set leakage and model plagiarism. Our tool is lightweight and fast, costing only 3% of the dataset size in overhead. We release a live interface of our tools at https://dataportraits.org/ and call on dataset and model creators to release Data Portraits as a complement to current documentation practices.
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
HTTP/3 is a new application layer protocol supported by most browsers. It uses QUIC as an underlying transport protocol. QUIC provides multiple benefits, like faster connection establishment, reduced latency, and improved connection migration. Hence, most popular browsers like Chrome/Chromium, Microsoft Edge, Apple Safari, and Mozilla Firefox have started supporting it. In this paper, we present an HTTP/3-supported browser dataset collection tool named H3B. It collects the application and network-level logs during YouTube streaming. We consider YouTube, as it the most popular video streaming application supporting QUIC. Using this tool, we collected a dataset of over 5936 YouTube sessions covering 5464 hours of streaming over 5 different geographical locations and 5 different bandwidth patterns. We believe our tool and as well as the dataset could be used in multiple applications such as a better configuration of application/transport protocols based on the network conditions, intelligent integration of network and application, predicting YouTube's QoE etc. We analyze the dataset and observe that during an HTTP/3 streaming not all requests are served by HTTP/3. Instead whenever the network condition is not favorable the browser chooses to fallback, and the application requests are transmitted using HTTP/2 over the old-standing transport protocol TCP. We observe that …
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
With a long history of traditional Graph Anomaly Detection (GAD) algorithms and recently popular Graph Neural Networks (GNNs), it is still not clear (1) how they perform under a standard comprehensive setting, (2) whether GNNs can outperform traditional algorithms such as tree ensembles, and (3) how about their efficiency on large-scale graphs. In response, we introduce GADBench---a benchmark tool dedicated to supervised anomalous node detection in static graphs. GADBench facilitates a detailed comparison across 29 distinct models on ten real-world GAD datasets, encompassing thousands to millions (~6M) nodes. Our main finding is that tree ensembles with simple neighborhood aggregation can outperform the latest GNNs tailored for the GAD task. We shed light on the current progress of GAD, setting a robust groundwork for subsequent investigations in this domain. GADBench is open-sourced at https://github.com/squareRoot3/GADBench.
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
In the era of extensive intersection between art and Artificial Intelligence (AI), such as image generation and fiction co-creation, AI for music remains relatively nascent, particularly in music understanding. This is evident in the limited work on deep music representations, the scarcity of large-scale datasets, and the absence of a universal and community-driven benchmark. To address this issue, we introduce the Music Audio Representation Benchmark for universaL Evaluation, termed MARBLE. It aims to provide a benchmark for various Music Information Retrieval (MIR) tasks by defining a comprehensive taxonomy with four hierarchy levels, including acoustic, performance, score, and high-level description. We then establish a unified protocol based on 18 tasks on 12 public-available datasets, providing a fair and standard assessment of representations of all open-sourced pre-trained models developed on music recordings as baselines. Besides, MARBLE offers an easy-to-use, extendable, and reproducible suite for the community, with a clear statement on copyright issues on datasets. Results suggest recently proposed large-scale pre-trained musical language models perform the best in most tasks, with room for further improvement. The leaderboard and toolkit repository are published to promote future music AI research.
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
The recent advances in natural language processing (NLP), have led to a new trend of applying large language models (LLMs) to real-world scenarios. While the latest LLMs are astonishingly fluent when interacting with humans, they suffer from the misinformation problem by unintentionally generating factually false statements. This can lead to harmful consequences, especially when produced within sensitive contexts, such as healthcare. Yet few previous works have focused on evaluating misinformation in the long-form (LF) generation of LLMs, especially for knowledge-intensive topics. Moreover, although LLMs have been shown to perform well in different languages, misinformation evaluation has been mostly conducted in English. To this end, we present a benchmark, CARE-MI, for evaluating LLM misinformation in: 1) a sensitive topic, specifically the maternity and infant care domain; and 2) a language other than English, namely Chinese. Most importantly, we provide an innovative paradigm for building LF generation evaluation benchmarks that can be transferred to other knowledge-intensive domains and low-resourced languages. Our proposed benchmark fills the gap between the extensive usage of LLMs and the lack of datasets for assessing the misinformation generated by these models. It contains 1,612 expert-checked questions, accompanied with human-selected references. Using our benchmark, we conduct extensive experiments and …
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
3D spatial understanding is highly valuable in the context of semantic modeling of environments, agents, and their relationships. Semantic modeling approaches employed on monocular video often ingest outputs from off-the-shelf SLAM/SfM pipelines, which are anecdotally observed to perform poorly or fail completely on some fraction of the videos of interest. These target videos may vary widely in complexity of scenes, activities, camera trajectory, etc. Unfortunately, such semantically-rich video data often comes with no ground-truth 3D information, and in practice it is prohibitively costly or impossible to obtain ground truth reconstructions or camera pose post-hoc. This paper proposes a novel evaluation protocol, Object Reprojection Error (ORE) to benchmark camera trajectories; ORE computes reprojection error for static objects within the video and requires only lightweight object tracklet annotations. These annotations are easy to gather on new or existing video, enabling ORE to be calculated on essentially arbitrary datasets. We show that ORE maintains high rank correlation with standard metrics based on groundtruth. Leveraging ORE, we source videos and annotations from Ego4D-EgoTracks, resulting in EgoStatic, a large-scale diverse dataset for evaluating camera trajectories in-the-wild.
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
Automated content filtering and moderation is an important tool that allows online platforms to build striving user communities that facilitate cooperation and prevent abuse. Unfortunately, resourceful actors try to bypass automated filters in a bid to post content that violate platform policies and codes of conduct. To reach this goal, these malicious actors may obfuscate policy violating images (e.g., overlay harmful images by carefully selected benign images or visual patterns) to prevent machine learning models from reaching the correct decision. In this paper, we invite researchers to tackle this specific issue and present a new image benchmark. This benchmark, based on ImageNet, simulates the type of obfuscations created by malicious actors. It goes beyond Image-Net-C and ImageNet-C-bar by proposing general, drastic, adversarial modifications that preserve the original content intent. It aims to tackle a more common adversarial threat than the one considered by lp-norm bounded adversaries. We evaluate 33 pretrained models on the benchmark and train models with different augmentations, architectures and training methods on subsets of the obfuscations to measure generalization. Our hope is that this benchmark will encourage researchers to test their models and methods and try to find new approaches that are more robust to these obfuscations.
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
A critical yet frequently overlooked challenge in the field of deepfake detection is the lack of a standardized, unified, comprehensive benchmark. This issue leads to unfair performance comparisons and potentially misleading results. Specifically, there is a lack of uniformity in data processing pipelines, resulting in inconsistent data inputs for detection models. Additionally, there are noticeable differences in experimental settings, and evaluation strategies and metrics lack standardization. To fill this gap, we present the first comprehensive benchmark for deepfake detection, called \textit{DeepfakeBench}, which offers three key contributions: 1) a unified data management system to ensure consistent input across all detectors, 2) an integrated framework for state-of-the-art methods implementation, and 3) standardized evaluation metrics and protocols to promote transparency and reproducibility. Featuring an extensible, modular-based codebase, \textit{DeepfakeBench} contains 15 state-of-the-art detection methods, 9 deepfake datasets, a series of deepfake detection evaluation protocols and analysis tools, as well as comprehensive evaluations. Moreover, we provide new insights based on extensive analysis of these evaluations from various perspectives (\eg, data augmentations, backbones). We hope that our efforts could facilitate future research and foster innovation in this increasingly critical domain. All codes, evaluations, and analyses of our benchmark are publicly available at \url{https://github.com/SCLBD/DeepfakeBench}.
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
Conversational generative AI has demonstrated remarkable promise for empowering biomedical practitioners, but current investigations focus on unimodal text. Multimodal conversational AI has seen rapid progress by leveraging billions of image-text pairs from the public web, but such general-domain vision-language models still lack sophistication in understanding and conversing about biomedical images. In this paper, we propose a cost-efficient approach for training a vision-language conversational assistant that can answer open-ended research questions of biomedical images. The key idea is to leverage a large-scale, broad-coverage biomedical figure-caption dataset extracted from PubMed Central, use GPT-4 to self-instruct open-ended instruction-following data from the captions, and then fine-tune a large general-domain vision-language model using a novel curriculum learning method. Specifically, the model first learns to align biomedical vocabulary using the figure-caption pairs as is, then learns to master open-ended conversational semantics using GPT-4 generated instruction-following data, broadly mimicking how a layperson gradually acquires biomedical knowledge. This enables us to train a Large Language and Vision Assistant for BioMedicine (LLaVA-Med) in less than 15 hours (with eight A100s). LLaVA-Med exhibits excellent multimodal conversational capability and can follow open-ended instruction to assist with inquiries about a biomedical image. On three standard biomedical visual question answering datasets, LLaVA-Med outperforms …
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
Visual object tracking is a key component to many egocentric vision problems. However, the full spectrum of challenges of egocentric tracking faced by an embodied AI is underrepresented in many existing datasets; these tend to focus on relatively short, third-person videos. Egocentric video has several distinguishing characteristics from those commonly found in past datasets: frequent large camera motions and hand interactions with objects commonly lead to occlusions or objects exiting the frame, and object appearance can change rapidly due to widely different points of view, scale, or object states. Embodied tracking is also naturally long-term, and being able to consistently (re-)associate objects to their appearances and disappearances over as long as a lifetime is critical. Previous datasets under-emphasize this re-detection problem, and their "framed" nature has led to adoption of various spatiotemporal priors that we find do not necessarily generalize to egocentric video. We thus introduce EgoTracks, a new dataset for long-term egocentric visual object tracking. Sourced from the Ego4D dataset, this new dataset presents a significant challenge to recent state-of-the-art single-object tracking models, which we find score poorly on traditional tracking metrics for our new dataset, compared to popular benchmarks. We further show improvements that can be made to …
[ Great Hall & Hall B1+B2 (level 1) ]
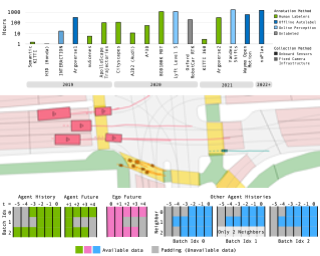
Abstract
The field of trajectory forecasting has grown significantly in recent years, partially owing to the release of numerous large-scale, real-world human trajectory datasets for autonomous vehicles (AVs) and pedestrian motion tracking. While such datasets have been a boon for the community, they each use custom and unique data formats and APIs, making it cumbersome for researchers to train and evaluate methods across multiple datasets. To remedy this, we present trajdata: a unified interface to multiple human trajectory datasets. At its core, trajdata provides a simple, uniform, and efficient representation and API for trajectory and map data. As a demonstration of its capabilities, in this work we conduct a comprehensive empirical evaluation of existing trajectory datasets, providing users with a rich understanding of the data underpinning much of current pedestrian and AV motion forecasting research, and proposing suggestions for future datasets from these insights. trajdata is permissively licensed (Apache 2.0) and can be accessed online at https://github.com/NVlabs/trajdata.
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
Recent progress in self-supervision has shown that pre-training large neural networks on vast amounts of unsupervised data can lead to substantial increases in generalization to downstream tasks. Such models, recently coined foundation models, have been transformational to the field of natural language processing.Variants have also been proposed for image data, but their applicability to remote sensing tasks is limited.To stimulate the development of foundation models for Earth monitoring, we propose a benchmark comprised of six classification and six segmentation tasks, which were carefully curated and adapted to be both relevant to the field and well-suited for model evaluation. We accompany this benchmark with a robust methodology for evaluating models and reporting aggregated results to enable a reliable assessment of progress. Finally, we report results for 20 baselines to gain information about the performance of existing models.We believe that this benchmark will be a driver of progress across a variety of Earth monitoring tasks.
[ Great Hall & Hall B1+B2 (level 1) ]
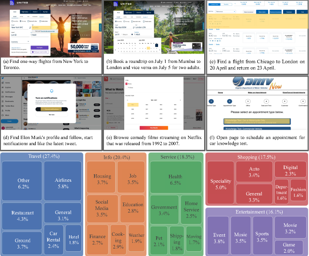
Abstract
We introduce Mind2Web, the first dataset for developing and evaluating generalist agents for the web that can follow language instructions to complete complex tasks on any website. Existing datasets for web agents either use simulated websites or only cover a limited set of websites and tasks, thus not suitable for generalist web agents. With over 2,000 open-ended tasks collected from 137 websites spanning 31 domains and crowdsourced action sequences for the tasks, Mind2Web provides three necessary ingredients for building generalist web agents: 1) diverse domains, websites, and tasks, 2) use of real-world websites instead of simulated and simplified ones, and 3) a broad spectrum of user interaction patterns. Based on Mind2Web, we conduct an initial exploration of using large language models (LLMs) for building generalist web agents. While the raw HTML of real-world websites are often too large to be fed to LLMs, we show that first filtering it with a small LM significantly improves the effectiveness and efficiency of LLMs. Our solution demonstrates a decent level of performance, even on websites or entire domains the model has never seen before, but there is still a substantial room to improve towards truly generalizable agents. We open-source our dataset, model implementation, …
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
We present RoboHive, a comprehensive software platform and ecosystem for research in the field of Robot Learning and Embodied Artificial Intelligence. Our platform encompasses a diverse range of pre-existing and novel environments, including dexterous manipulation with the Shadow Hand, whole-arm manipulation tasks with Franka and Fetch robots, quadruped locomotion, among others. Included environments are organized within and cover multiple domains such as hand manipulation, locomotion, multi-task, multi-agent, muscles, etc. In comparison to prior works, RoboHive offers a streamlined and unified task interface taking dependency on only a minimal set of well-maintained packages, features tasks with high physics fidelity and rich visual diversity, and supports common hardware drivers for real-world deployment. The unified interface of RoboHive offers a convenient and accessible abstraction for algorithmic research in imitation, reinforcement, multi-task, and hierarchical learning. Furthermore, RoboHive includes expert demonstrations and baseline results for most environments, providing a standard for benchmarking and comparisons. Details: https://sites.google.com/view/robohive
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
In an effort to catalog insect biodiversity, we propose a new large dataset of hand-labelled insect images, the BIOSCAN-1M Insect Dataset. Each record is taxonomically classified by an expert, and also has associated genetic information including raw nucleotide barcode sequences and assigned barcode index numbers, which are genetic-based proxies for species classification. This paper presents a curated million-image dataset, primarily to train computer-vision models capable of providing image-based taxonomic assessment, however, the dataset also presents compelling characteristics, the study of which would be of interest to the broader machine learning community. Driven by the biological nature inherent to the dataset, a characteristic long-tailed class-imbalance distribution is exhibited. Furthermore, taxonomic labelling is a hierarchical classification scheme, presenting a highly fine-grained classification problem at lower levels. Beyond spurring interest in biodiversity research within the machine learning community, progress on creating an image-based taxonomic classifier will also further the ultimate goal of all BIOSCAN research: to lay the foundation for a comprehensive survey of global biodiversity. This paper introduces the dataset and explores the classification task through the implementation and analysis of a baseline classifier. The code repository of the BIOSCAN-1M-Insect dataset is available at https://github.com/zahrag/BIOSCAN-1M
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
Over recent years, an increasing amount of compute and data has been poured into training large language models (LLMs), usually by doing one-pass learning on as many tokens as possible randomly selected from large-scale web corpora. While training on ever-larger portions of the internet leads to consistent performance improvements, the size of these improvements diminishes with scale, and there has been little work exploring the effect of data selection on pre-training and downstream performance beyond simple de-duplication methods such as MinHash. Here, we show that careful data selection (on top of de-duplicated data) via pre-trained model embeddings can speed up training (20% efficiency gains) and improves average downstream accuracy on 16 NLP tasks (up to 2%) at the 6.7B model scale. Furthermore, we show that repeating data intelligently consistently outperforms baseline training (while repeating random data performs worse than baseline training). Our results indicate that clever data selection can significantly improve LLM pre-training, calls into question the common practice of training for a single epoch on as much data as possible, and demonstrates a path to keep improving our models past the limits of randomly sampling web data.
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
Existing full text datasets of U.S. public domain newspapers do not recognize the often complex layouts of newspaper scans, and as a result the digitized content scrambles texts from articles, headlines, captions, advertisements, and other layout regions. OCR quality can also be low. This study develops a novel, deep learning pipeline for extracting full article texts from newspaper images and applies it to the nearly 20 million scans in Library of Congress's public domain Chronicling America collection. The pipeline includes layout detection, legibility classification, custom OCR, and association of article texts spanning multiple bounding boxes. To achieve high scalability, it is built with efficient architectures designed for mobile phones. The resulting American Stories dataset provides high quality data that could be used for pre-training a large language model to achieve better understanding of historical English and historical world knowledge. The dataset could also be added to the external database of a retrieval-augmented language model to make historical information - ranging from interpretations of political events to minutiae about the lives of people's ancestors - more widely accessible. Furthermore, structured article texts facilitate using transformer-based methods for popular social science applications like topic classification, detection of reproduced content, and news story …
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
A diversity of tasks use language models trained on semantic similarity data. While there are a variety of datasets that capture semantic similarity, they are either constructed from modern web data or are relatively small datasets created in the past decade by human annotators. This study utilizes a novel source, newly digitized articles from off-copyright, local U.S. newspapers, to assemble a massive-scale semantic similarity dataset spanning 70 years from 1920 to 1989 and containing nearly 400M positive semantic similarity pairs. Historically, around half of articles in U.S. local newspapers came from newswires like the Associated Press. While local papers reproduced articles from the newswire, they wrote their own headlines, which form abstractive summaries of the associated articles. We associate articles and their headlines by exploiting document layouts and language understanding. We then use deep neural methods to detect which articles are from the same underlying source, in the presence of substantial noise and abridgement. The headlines of reproduced articles form positive semantic similarity pairs. The resulting publicly available HEADLINES dataset is significantly larger than most existing semantic similarity datasets and covers a much longer span of time. It will facilitate the application of contrastively trained semantic similarity models to a …
[ Great Hall & Hall B1+B2 (level 1) ]
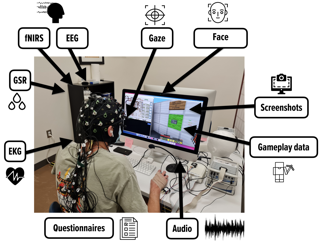
Abstract
We present a rich, multimodal dataset consisting of data from 40 teams of three humans conducting simulated urban search-and-rescue (SAR) missions in a Minecraft-based testbed, collected for the Theory of Mind-based Cognitive Architecture for Teams (ToMCAT) project. Modalities include two kinds of brain scan data---functional near-infrared spectroscopy (fNIRS) and electroencephalography (EEG), as well as skin conductance, heart rate, eye tracking, face images, spoken dialog audio data with automatic speech recognition (ASR) transcriptions, game screenshots, gameplay data, game performance data, demographic data, and self-report questionnaires. Each team undergoes up to six consecutive phases: three behavioral tasks, one mission training session, and two collaborative SAR missions. As time-synchronized multimodal data collected under a variety of circumstances, this dataset will support studying a large variety of research questions on topics including teamwork, coordination, plan recognition, affective computing, physiological linkage, entrainment, and dialog understanding. We provide an initial public release of the de-identified data, along with analyses illustrating the utility of this dataset to both computer scientists and social scientists.
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
Current dataset collection methods typically scrape large amounts of data from the web. While this technique is extremely scalable, data collected in this way tends to reinforce stereotypical biases, can contain personally identifiable information, and typically originates from Europe and North America. In this work, we rethink the dataset collection paradigm and introduce GeoDE, a geographically diverse dataset with 61,940 images from 40 classes and 6 world regions, and no personally identifiable information, collected by soliciting images from people across the world. We analyse GeoDE to understand differences in images collected in this manner compared to web-scraping. Despite the smaller size of this dataset, we demonstrate its use as both an evaluation and training dataset, allowing us to highlight shortcomings in current models, as well as demonstrate improved performance even when training on this small dataset. We release the full dataset and code at https://geodiverse-data-collection.cs.princeton.edu/
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
Synthesizing information from various data sources plays a crucial role in the practice of modern medicine. Current applications of artificial intelligence in medicine often focus on single-modality data due to a lack of publicly available, multimodal medical datasets. To address this limitation, we introduce INSPECT, which contains de-identified longitudinal records from a large cohort of pulmonary embolism (PE) patients, along with ground truth labels for multiple outcomes. INSPECT contains data from 19,402 patients, including CT images, sections of radiology reports, and structured electronic health record (EHR) data (including demographics, diagnoses, procedures, and vitals). Using our provided dataset, we develop and release a benchmark for evaluating several baseline modeling approaches on a variety of important PE related tasks. We evaluate image-only, EHR-only, and fused models. Trained models and the de-identified dataset are made available for non-commercial use under a data use agreement. To the best our knowledge, INSPECT is the largest multimodal dataset for enabling reproducible research on strategies for integrating 3D medical imaging and EHR data.
[ Great Hall & Hall B1+B2 (level 1) ]
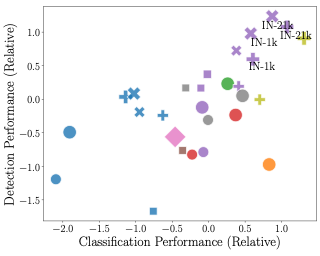
Abstract
Neural network based computer vision systems are typically built on a backbone, a pretrained or randomly initialized feature extractor. Several years ago, the default option was an ImageNet-trained convolutional neural network. However, the recent past has seen the emergence of countless backbones pretrained using various algorithms and datasets. While this abundance of choice has led to performance increases for a range of systems, it is difficult for practitioners to make informed decisions about which backbone to choose. Battle of the Backbones (BoB) makes this choice easier by benchmarking a diverse suite of pretrained models, including vision-language models, those trained via self-supervised learning, and the Stable Diffusion backbone, across a diverse set of computer vision tasks ranging from classification to object detection to OOD generalization and more. Furthermore, BoB sheds light on promising directions for the research community to advance computer vision by illuminating strengths and weakness of existing approaches through a comprehensive analysis conducted on more than 1500 training runs. While vision transformers (ViTs) and self-supervised learning (SSL) are increasingly popular, we find that convolutional neural networks pretrained in a supervised fashion on large training sets still perform best on most tasks among the models we consider. Moreover, in apples-to-apples …
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
Despite the existence of various benchmarks for evaluating natural language processing models, we argue that human exams are a more suitable means of evaluating general intelligence for large language models (LLMs), as they inherently demand a much wider range of abilities such as language understanding, domain knowledge, and problem-solving skills. To this end, we introduce M3Exam, a novel benchmark sourced from real and official human exam questions for evaluating LLMs in a multilingual, multimodal, and multilevel context. M3Exam exhibits three unique characteristics: (1) multilingualism, encompassing questions from multiple countries that require strong multilingual proficiency and cultural knowledge; (2) multimodality, accounting for the multimodal nature of many exam questions to test the model's multimodal understanding capability; and (3) multilevel structure, featuring exams from three critical educational periods to comprehensively assess a model's proficiency at different levels. In total, M3Exam contains 12,317 questions in 9 diverse languages with three educational levels, where about 23\% of the questions require processing images for successful solving. We assess the performance of top-performing LLMs on M3Exam and find that current models, including GPT-4, still struggle with multilingual text, particularly in low-resource and non-Latin script languages. Multimodal LLMs also perform poorly with complex multimodal questions. We believe …
[ Great Hall & Hall B1+B2 (level 1) ]
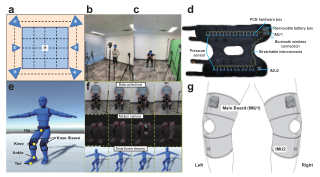
Abstract
The kinematics of human movements and locomotion are closely linked to the activation and contractions of muscles. To investigate this, we present a multimodal dataset with benchmarks collected using a novel pair of Intelligent Knee Sleeves (Texavie MarsWear Knee Sleeves) for human pose estimation. Our system utilizes synchronized datasets that comprise time-series data from the Knee Sleeves and the corresponding ground truth labels from visualized motion capture camera system. We employ these to generate 3D human models solely based on the wearable data of individuals performing different activities. We demonstrate the effectiveness of this camera-free system and machine learning algorithms in the assessment of various movements and exercises, including extension to unseen exercises and individuals. The results show an average error of 7.21 degrees across all eight lower body joints when compared to the ground truth, indicating the effectiveness and reliability of the Knee Sleeve system for the prediction of different lower body joints beyond knees. The results enable human pose estimation in a seamless manner without being limited by visual occlusion or the field of view of cameras. Our results show the potential of multimodal wearable sensing in a variety of applications from home fitness to sports, healthcare, and …
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
Humans outperform object recognizers despite the fact that models perform well on current datasets, including those explicitly designed to challenge machines with debiased images or distribution shift. This problem persists, in part, because we have no guidance on the absolute difficulty of an image or dataset making it hard to objectively assess progress toward human-level performance, to cover the range of human abilities, and to increase the challenge posed by a dataset. We develop a dataset difficulty metric MVT, Minimum Viewing Time, that addresses these three problems. Subjects view an image that flashes on screen and then classify the object in the image. Images that require brief flashes to recognize are easy, those which require seconds of viewing are hard. We compute the ImageNet and ObjectNet image difficulty distribution, which we find significantly undersamples hard images. Nearly 90% of current benchmark performance is derived from images that are easy for humans. Rather than hoping that we will make harder datasets, we can for the first time objectively guide dataset difficulty during development. We can also subset recognition performance as a function of difficulty: model performance drops precipitously while human performance remains stable. Difficulty provides a new lens through which to …
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
Multiple sequence alignments (MSAs) of proteins encode rich biological information and have been workhorses in bioinformatic methods for tasks like protein design and protein structure prediction for decades. Recent breakthroughs like AlphaFold2 that use transformers to attend directly over large quantities of raw MSAs have reaffirmed their importance. Generation of MSAs is highly computationally intensive, however, and no datasets comparable to those used to train AlphaFold2 have been made available to the research community, hindering progress in machine learning for proteins. To remedy this problem, we introduce OpenProteinSet, an open-source corpus of more than 16 million MSAs, associated structural homologs from the Protein Data Bank, and AlphaFold2 protein structure predictions. We have previously demonstrated the utility of OpenProteinSet by successfully retraining AlphaFold2 on it. We expect OpenProteinSet to be broadly useful as training and validation data for 1) diverse tasks focused on protein structure, function, and design and 2) large-scale multimodal machine learning research.
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
We present the Minigrid and Miniworld libraries which provide a suite of goal-oriented 2D and 3D environments. The libraries were explicitly created with a minimalistic design paradigm to allow users to rapidly develop new environments for a wide range of research-specific needs. As a result, both have received widescale adoption by the RL community, facilitating research in a wide range of areas. In this paper, we outline the design philosophy, environment details, and their world generation API. We also showcase the additional capabilities brought by the unified API between Minigrid and Miniworld through case studies on transfer learning (for both RL agents and humans) between the different observation spaces. The source code of Minigrid and Miniworld can be found at https://github.com/Farama-Foundation/Minigrid and https://github.com/Farama-Foundation/Miniworld along with their documentation at https://minigrid.farama.org/ and https://miniworld.farama.org/.
[ Great Hall & Hall B1+B2 (level 1) ]
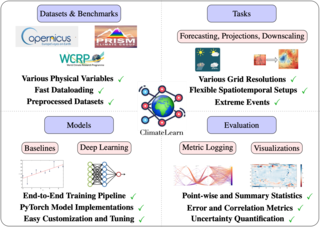
Abstract
Modeling weather and climate is an essential endeavor to understand the near- and long-term impacts of climate change, as well as to inform technology and policymaking for adaptation and mitigation efforts. In recent years, there has been a surging interest in applying data-driven methods based on machine learning for solving core problems such as weather forecasting and climate downscaling. Despite promising results, much of this progress has been impaired due to the lack of large-scale, open-source efforts for reproducibility, resulting in the use of inconsistent or underspecified datasets, training setups, and evaluations by both domain scientists and artificial intelligence researchers. We introduce ClimateLearn, an open-source PyTorch library that vastly simplifies the training and evaluation of machine learning models for data-driven climate science. ClimateLearn consists of holistic pipelines for dataset processing (e.g., ERA5, CMIP6, PRISM), implementing state-of-the-art deep learning models (e.g., Transformers, ResNets), and quantitative and qualitative evaluation for standard weather and climate modeling tasks. We supplement these functionalities with extensive documentation, contribution guides, and quickstart tutorials to expand access and promote community growth. We have also performed comprehensive forecasting and downscaling experiments to showcase the capabilities and key features of our library. To our knowledge, ClimateLearn is the first large-scale, …
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
Humans write code in a fundamentally interactive manner and rely on constant execution feedback to correct errors, resolve ambiguities, and decompose tasks. While LLMs have recently exhibited promising coding capabilities, current coding benchmarks mostly consider a static instruction-to-code sequence transduction process, which has the potential for error propagation and a disconnect between the generated code and its final execution environment. To address this gap, we introduce InterCode, a lightweight, flexible, and easy-to-use framework of interactive coding as a standard reinforcement learning (RL) environment, with code as actions and execution feedback as observations. Our framework is language and platform agnostic, uses self-contained Docker environments to provide safe and reproducible execution, and is compatible out-of-the-box with traditional seq2seq coding methods, while enabling the development of new methods for interactive code generation. We use InterCode to create three interactive code environments with Bash, SQL, and Python as action spaces, leveraging data from the static NL2Bash, Spider, and MBPP datasets. We demonstrate InterCode’s viability as a testbed by evaluating multiple state-of-the-art LLMs configured with different prompting strategies such as ReAct and Plan & Solve. Our results showcase the benefits of interactive code generation and demonstrate that InterCode can serve as a challenging benchmark for …
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
Modern perception systems rely heavily on high-resolution cameras, LiDARs, and advanced deep neural networks, enabling exceptional performance across various applications. However, these optical systems predominantly depend on geometric features and shapes of objects, which can be challenging to capture in long-range perception applications. To overcome this limitation, alternative approaches such as Doppler-based perception using high-resolution radars have been proposed. Doppler-based systems are capable of measuring micro-motions of targets remotely and with very high precision. When compared to geometric features, the resolution of micro-motion features exhibits significantly greater resilience to the influence of distance. However, the true potential of Doppler-based perception has yet to be fully realized due to several factors. These include the unintuitive nature of Doppler signals, the limited availability of public Doppler datasets, and the current datasets' inability to capture the specific co-factors that are unique to Doppler-based perception, such as the effect of the radar's observation angle and the target's motion trajectory.This paper introduces a new large multi-view Doppler dataset together with baseline perception models for micro-motion-based gait analysis and classification. The dataset captures the impact of the subject's walking trajectory and radar's observation angle on the classification performance. Additionally, baseline multi-view data fusion techniques are provided …
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
Machine learning for sign languages is bottlenecked by data. In this paper, we present YouTube-ASL, a large-scale, open-domain corpus of American Sign Language (ASL) videos and accompanying English captions drawn from YouTube. With ~1000 hours of videos and >2500 unique signers, YouTube-ASL is ~3x as large and has ~10x as many unique signers as the largest prior ASL dataset. We train baseline models for ASL to English translation on YouTube-ASL and evaluate them on How2Sign, where we achieve a new fine-tuned state of the art of 12.397 BLEU and, for the first time, nontrivial zero-shot results.
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
Estimating camera motion in deformable scenes poses a complex and open research challenge. Most existing non-rigid structure from motion techniques assume to observe also static scene parts besides deforming scene parts in order to establish an anchoring reference. However, this assumption does not hold true in certain relevant application cases such as endoscopies. Deformable odometry and SLAM pipelines, which tackle the most challenging scenario of exploratory trajectories, suffer from a lack of robustness and proper quantitative evaluation methodologies. To tackle this issue with a common benchmark, we introduce the Drunkard's Dataset, a challenging collection of synthetic data targeting visual navigation and reconstruction in deformable environments. This dataset is the first large set of exploratory camera trajectories with ground truth inside 3D scenes where every surface exhibits non-rigid deformations over time. Simulations in realistic 3D buildings lets us obtain a vast amount of data and ground truth labels, including camera poses, RGB images and depth, optical flow and normal maps at high resolution and quality. We further present a novel deformable odometry method, dubbed the Drunkard’s Odometry, which decomposes optical flow estimates into rigid-body camera motion and non-rigid scene deformations. In order to validate our data, our work contains an evaluation …
[ Great Hall & Hall B1+B2 (level 1) ]
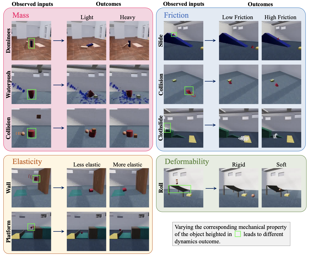
Abstract
General physical scene understanding requires more than simply localizing and recognizing objects -- it requires knowledge that objects can have different latent properties (e.g., mass or elasticity), and that those properties affect the outcome of physical events. While there has been great progress in physical and video prediction models in recent years, benchmarks to test their performance typically do not require an understanding that objects have individual physical properties, or at best test only those properties that are directly observable (e.g., size or color). This work proposes a novel dataset and benchmark, termed Physion++, that rigorously evaluates visual physical prediction in artificial systems under circumstances where those predictions rely on accurate estimates of the latent physical properties of objects in the scene. Specifically, we test scenarios where accurate prediction relies on estimates of properties such as mass, friction, elasticity, and deformability, and where the values of those properties can only be inferred by observing how objects move and interact with other objects or fluids. We evaluate the performance of a number of state-of-the-art prediction models that span a variety of levels of learning vs. built-in knowledge, and compare that performance to a set of human predictions. We find that models …
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
AI alignment refers to models acting towards human-intended goals, preferences, or ethical principles. Analyzing the similarity between models and humans can be a proxy measure for ensuring AI safety. In this paper, we focus on the models' visual perception alignment with humans, further referred to as AI-human visual alignment. Specifically, we propose a new dataset for measuring AI-human visual alignment in terms of image classification. In order to evaluate AI-human visual alignment, a dataset should encompass samples with various scenarios and have gold human perception labels. Our dataset consists of three groups of samples, namely Must-Act (i.e., Must-Classify), Must-Abstain, and Uncertain, based on the quantity and clarity of visual information in an image and further divided into eight categories. All samples have a gold human perception label; even Uncertain (e.g., severely blurry) sample labels were obtained via crowd-sourcing. The validity of our dataset is verified by sampling theory, statistical theories related to survey design, and experts in the related fields. Using our dataset, we analyze the visual alignment and reliability of five popular visual perception models and seven abstention methods. Our code and data is available at https://github.com/jiyounglee-0523/VisAlign.
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
We present WineSensed, a large multimodal wine dataset for studying the relations between visual perception, language, and flavor. The dataset encompasses 897k images of wine labels and 824k reviews of wines curated from the Vivino platform. It has over 350k unique vintages, annotated with year, region, rating, alcohol percentage, price, and grape composition. We obtained fine-grained flavor annotations on a subset by conducting a wine-tasting experiment with 256 participants who were asked to rank wines based on their similarity in flavor, resulting in more than 5k pairwise flavor distances. We propose a low-dimensional concept embedding algorithm that combines human experience with automatic machine similarity kernels. We demonstrate that this shared concept embedding space improves upon separate embedding spaces for coarse flavor classification (alcohol percentage, country, grape, price, rating) and representing human perception of flavor.
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
We propose Pgx, a suite of board game reinforcement learning (RL) environments written in JAX and optimized for GPU/TPU accelerators. By leveraging JAX's auto-vectorization and parallelization over accelerators, Pgx can efficiently scale to thousands of simultaneous simulations over accelerators. In our experiments on a DGX-A100 workstation, we discovered that Pgx can simulate RL environments 10-100x faster than existing implementations available in Python. Pgx includes RL environments commonly used as benchmarks in RL research, such as backgammon, chess, shogi, and Go. Additionally, Pgx offers miniature game sets and baseline models to facilitate rapid research cycles. We demonstrate the efficient training of the Gumbel AlphaZero algorithm with Pgx environments. Overall, Pgx provides high-performance environment simulators for researchers to accelerate their RL experiments. Pgx is available at https://github.com/sotetsuk/pgx.
[ Great Hall & Hall B1+B2 (level 1) ]
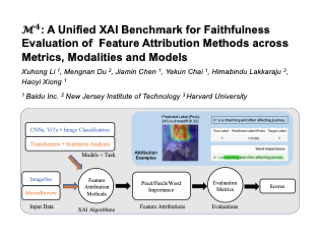
Abstract
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
While direction of arrival (DOA) of sound events is generally estimated from multichannel audio data recorded in a microphone array, sound events usually derive from visually perceptible source objects, e.g., sounds of footsteps come from the feet of a walker. This paper proposes an audio-visual sound event localization and detection (SELD) task, which uses multichannel audio and video information to estimate the temporal activation and DOA of target sound events. Audio-visual SELD systems can detect and localize sound events using signals from a microphone array and audio-visual correspondence. We also introduce an audio-visual dataset, Sony-TAu Realistic Spatial Soundscapes 2023 (STARSS23), which consists of multichannel audio data recorded with a microphone array, video data, and spatiotemporal annotation of sound events. Sound scenes in STARSS23 are recorded with instructions, which guide recording participants to ensure adequate activity and occurrences of sound events. STARSS23 also serves human-annotated temporal activation labels and human-confirmed DOA labels, which are based on tracking results of a motion capture system. Our benchmark results demonstrate the benefits of using visual object positions in audio-visual SELD tasks. The data is available at https://zenodo.org/record/7880637.
[ Great Hall & Hall B1+B2 (level 1) ]
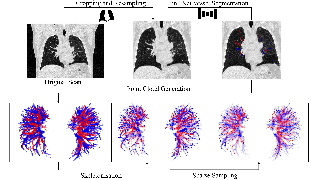
Abstract
A popular benchmark for intra-patient lung registration is provided by the DIR-LAB COPDgene dataset consisting of large-motion in- and expiratory breath-hold CT pairs. This dataset alone, however, does not provide enough samples to properly train state-of-the-art deep learning methods. Other public datasets often also provide only small sample sizes or include primarily small motions between scans that do not translate well to larger deformations. For point-based geometric registration, the PVT1010 dataset provides a large number of vessel point clouds without any correspondences and a labeled test set corresponding to the COPDgene cases. However, the absence of correspondences for supervision complicates training, and a fair comparison with image-based algorithms is infeasible, since CT scans for the training data are not publicly available.We here provide a combined benchmark for image- and point-based registration approaches. We curated a total of 248 public multi-centric in- and expiratory lung CT scans from 124 patients, which show large motion between scans, processed them to ensure sufficient homogeneity between the data and generated vessel point clouds that are well distributed even deeper inside the lungs. For supervised training, we provide vein and artery segmentations of the vessels and multiple thousand image-derived keypoint correspondences for each pair. For …
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
We propose the Multimodal Clinical Benchmark for Emergency Care (MC-BEC), a comprehensive benchmark for evaluating foundation models in Emergency Medicine using a dataset of 100K+ continuously monitored Emergency Department visits from 2020-2022. MC-BEC focuses on clinically relevant prediction tasks at timescales from minutes to days, including predicting patient decompensation, disposition, and emergency department (ED) revisit, and includes a standardized evaluation framework with train-test splits and evaluation metrics. The multimodal dataset includes a wide range of detailed clinical data, including triage information, prior diagnoses and medications, continuously measured vital signs, electrocardiogram and photoplethysmograph waveforms, orders placed and medications administered throughout the visit, free-text reports of imaging studies, and information on ED diagnosis, disposition, and subsequent revisits. We provide performance baselines for each prediction task to enable the evaluation of multimodal, multitask models. We believe that MC-BEC will encourage researchers to develop more effective, generalizable, and accessible foundation models for multimodal clinical data.
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
We present the HOH (Human-Object-Human) Handover Dataset, a large object count dataset with 136 objects, to accelerate data-driven research on handover studies, human-robot handover implementation, and artificial intelligence (AI) on handover parameter estimation from 2D and 3D data of two-person interactions. HOH contains multi-view RGB and depth data, skeletons, fused point clouds, grasp type and handedness labels, object, giver hand, and receiver hand 2D and 3D segmentations, giver and receiver comfort ratings, and paired object metadata and aligned 3D models for 2,720 handover interactions spanning 136 objects and 20 giver-receiver pairs—40 with role-reversal—organized from 40 participants. We also show experimental results of neural networks trained using HOH to perform grasp, orientation, and trajectory prediction. As the only fully markerless handover capture dataset, HOH represents natural human-human handover interactions, overcoming challenges with markered datasets that require specific suiting for body tracking, and lack high-resolution hand tracking. To date, HOH is the largest handover dataset in terms of object count, participant count, pairs with role reversal accounted for, and total interactions captured.
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
Despite impressive advancements in multilingual corpora collection and model training, developing large-scale deployments of multilingual models still presents a significant challenge. This is particularly true for language tasks that are culture-dependent. One such example is the area of multilingual sentiment analysis, where affective markers can be subtle and deeply ensconced in culture.This work presents the most extensive open massively multilingual corpus of datasets for training sentiment models. The corpus consists of 79 manually selected datasets from over 350 datasets reported in the scientific literature based on strict quality criteria. The corpus covers 27 languages representing 6 language families. Datasets can be queried using several linguistic and functional features. In addition, we present a multi-faceted sentiment classification benchmark summarizing hundreds of experiments conducted on different base models, training objectives, dataset collections, and fine-tuning strategies.
[ Great Hall & Hall B1+B2 (level 1) ]
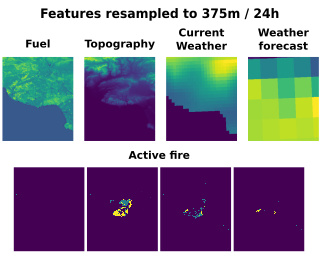
Abstract
We present a multi-temporal, multi-modal remote-sensing dataset for predicting how active wildfires will spread at a resolution of 24 hours. The dataset consists of 13607 images across 607 fire events in the United States from January 2018 to October 2021. For each fire event, the dataset contains a full time series of daily observations, containing detected active fires and variables related to fuel, topography and weather conditions. The dataset is challenging due to: a) its inputs being multi-temporal, b) the high number of 23 multi-modal input channels, c) highly imbalanced labels and d) noisy labels, due to smoke, clouds, and inaccuracies in the active fire detection. The underlying complexity of the physical processes adds to these challenges. Compared to existing public datasets in this area, WildfireSpreadTS allows for multi-temporal modeling of spreading wildfires, due to its time series structure. Furthermore, we provide additional input modalities and a high spatial resolution of 375m for the active fire maps. We publish this dataset to encourage further research on this important task with multi-temporal, noise-resistant or generative methods, uncertainty estimation or advanced optimization techniques that deal with the high-dimensional input space.
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
Table Representation Learning (TRL) models are commonly pre-trained on large open-domain datasets comprising millions of tables and then used to address downstream tasks. Choosing the right TRL model to use on proprietary data can be challenging, as the best results depend on the content domain, schema, and data quality. Our purpose is to support end-users in testing TRL models on proprietary data in two established SQL-centric tasks, i.e., Question Answering (QA) and Semantic Parsing (SP). We present QATCH (Query-Aided TRL Checklist), a toolbox to highlight TRL models’ strengths and weaknesses on relational tables unseen at training time. For an input table, QATCH automatically generates a testing checklist tailored to QA and SP. Checklist generation is driven by a SQL query engine that crafts tests of different complexity. This design facilitates inherent portability, allowing the checks to be used by alternative models. We also introduce a set of cross-task performance metrics evaluating the TRL model’s performance over its output. Finally, we show how QATCH automatically generates tests for proprietary datasets to evaluate various state-of-the-art models including TAPAS, TAPEX, and CHATGPT.
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
We present ProteinShake, a Python software package that simplifies datasetcreation and model evaluation for deep learning on protein structures. Users cancreate custom datasets or load an extensive set of pre-processed datasets fromthe Protein Data Bank (PDB) and AlphaFoldDB. Each dataset is associated withprediction tasks and evaluation functions covering a broad array of biologicalchallenges. A benchmark on these tasks shows that pre-training almost alwaysimproves performance, the optimal data modality (graphs, voxel grids, or pointclouds) is task-dependent, and models struggle to generalize to new structures.ProteinShake makes protein structure data easily accessible and comparisonamong models straightforward, providing challenging benchmark settings withreal-world implications.ProteinShake is available at: https://proteinshake.ai
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
Synthetic image datasets offer unmatched advantages for designing and evaluating deep neural networks: they make it possible to (i) render as many data samples as needed, (ii) precisely control each scene and yield granular ground truth labels (and captions), (iii) precisely control distribution shifts between training and testing to isolate variables of interest for sound experimentation.Despite such promise, the use of synthetic image data is still limited -- and often played down -- mainly due to their lack of realism. Most works therefore rely on datasets of real images, which have often been scraped from public images on the internet, and may have issues with regards to privacy, bias, and copyright, while offering little control over how objects precisely appear.In this work, we present a path to democratize the use of photorealistic synthetic data: we develop a new generation of interactive environments for representation learning research, that offer both controllability and realism. We use the Unreal Engine, a powerful game engine well known in the entertainment industry, to produce PUG (Photorealistic Unreal Graphics) environments and datasets for representation learning. Using PUG for evaluation and fine-tuning, we demonstrate the potential of PUG to both enable more rigorous evaluations and to improve …
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
Protein inverse folding has attracted increasing attention in recent years. However, we observe that current methods are usually limited to the CATH dataset and the recovery metric. The lack of a unified framework for ensembling and comparing different methods hinders the comprehensive investigation. In this paper, we propose ProteinBench, a new benchmark for protein design, which comprises extended protein design tasks, integrated models, and diverse evaluation metrics. We broaden the application of methods originally designed for single-chain protein design to new scenarios of multi-chain and \textit{de novo} protein design. Recent impressive methods, including GraphTrans, StructGNN, GVP, GCA, AlphaDesign, ProteinMPNN, PiFold and KWDesign are integrated into our framework. In addition to the recovery, we also evaluate the confidence, diversity, sc-TM, efficiency, and robustness to thoroughly revisit current protein design approaches and inspire future work. As a result, we establish the first comprehensive benchmark for protein design, which is publicly available at \url{https://github.com/A4Bio/OpenCPD}.
[ Great Hall & Hall B1+B2 (level 1) ]
Abstract
Understanding different human attributes and how they affect model behavior may become a standard need for all model creation and usage, from traditional computer vision tasks to the newest multimodal generative AI systems. In computer vision specifically, we have relied on datasets augmented with perceived attribute signals (eg, gender presentation, skin tone, and age) and benchmarks enabled by these datasets. Typically labels for these tasks come from human annotators. However, annotating attribute signals, especially skin tone, is a difficult and subjective task. Perceived skin tone is affected by technical factors, like lighting conditions, and social factors that shape an annotator's lived experience.This paper examines the subjectivity of skin tone annotation through a series of annotation experiments using the Monk Skin Tone (MST) scale~\cite{Monk2022Monk}, a small pool of professional photographers, and a much larger pool of trained crowdsourced annotators. Along with this study we release the Monk Skin Tone Examples (MST-E) dataset, containing 1515 images and 31 videos spread across the full MST scale. MST-E is designed to help train human annotators to annotate MST effectively.Our study shows that annotators can reliably annotate skin tone in a way that aligns with an expert in the MST scale, even under challenging environmental …
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
Spatio-temporal predictive learning is a learning paradigm that enables models to learn spatial and temporal patterns by predicting future frames from given past frames in an unsupervised manner. Despite remarkable progress in recent years, a lack of systematic understanding persists due to the diverse settings, complex implementation, and difficult reproducibility. Without standardization, comparisons can be unfair and insights inconclusive. To address this dilemma, we propose OpenSTL, a comprehensive benchmark for spatio-temporal predictive learning that categorizes prevalent approaches into recurrent-based and recurrent-free models. OpenSTL provides a modular and extensible framework implementing various state-of-the-art methods. We conduct standard evaluations on datasets across various domains, including synthetic moving object trajectory, human motion, driving scenes, traffic flow, and weather forecasting. Based on our observations, we provide a detailed analysis of how model architecture and dataset properties affect spatio-temporal predictive learning performance. Surprisingly, we find that recurrent-free models achieve a good balance between efficiency and performance than recurrent models. Thus, we further extend the common MetaFormers to boost recurrent-free spatial-temporal predictive learning. We open-source the code and models at https://github.com/chengtan9907/OpenSTL.
[ Great Hall & Hall B1+B2 (level 1) ]

Abstract
A privacy policy serves as an online internet protocol crafted by service providers, which details how service providers collect, process, store, manage, and use personal information when users engage with applications. However, these privacy policies are often filled with technobabble and legalese, making them "incomprehensible''. As a result, users often agree to all terms unknowingly, even some terms may conflict with the law, thereby posing a considerable risk to personal privacy information. One potential solution to alleviate this challenge is to automatically summarize privacy policies using NLP techniques. However, existing techniques primarily focus on extracting key sentences, resulting in comparatively shorter agreements, but failing to address the poor readability caused by the "incomprehensible'' of technobabble and legalese. Moreover, research on Chinese application privacy policy summarization is currently almost nonexistent, and there is a lack of a high-quality corpus suitable for addressing readability issues. To tackle these challenges, we introduce a fine-grained CAPP-130 corpus and a TCSI-pp framework. CAPP-130 contains 130 Chinese privacy policies from popular applications that have been carefully annotated and interpreted by legal experts, resulting in 52,489 annotations and 20,555 rewritten sentences. TCSI-pp first extracts sentences related to the topic specified by users and then uses a generative …
Abstract
As societal awareness of climate change grows, corporate climate policy engagements are attracting attention.We propose a dataset to estimate corporate climate policy engagement from various PDF-formatted documents.Our dataset comes from LobbyMap (a platform operated by global think tank InfluenceMap) that provides engagement categories and stances on the documents.To convert the LobbyMap data into the structured dataset, we developed a pipeline using text extraction and OCR.Our contributions are: (i) Building an NLP dataset including 10K documents on corporate climate policy engagement. (ii) Analyzing the properties and challenges of the dataset. (iii) Providing experiments for the dataset using pre-trained language models.The results show that while Longformer outperforms baselines and other pre-trained models, there is still room for significant improvement.We hope our work begins to bridge research on NLP and climate change.