Poster
LoRA: A Logical Reasoning Augmented Dataset for Visual Question Answering
Jingying Gao · Qi Wu · Alan Blair · Maurice Pagnucco
Great Hall & Hall B1+B2 (level 1) #220
{kind=link}
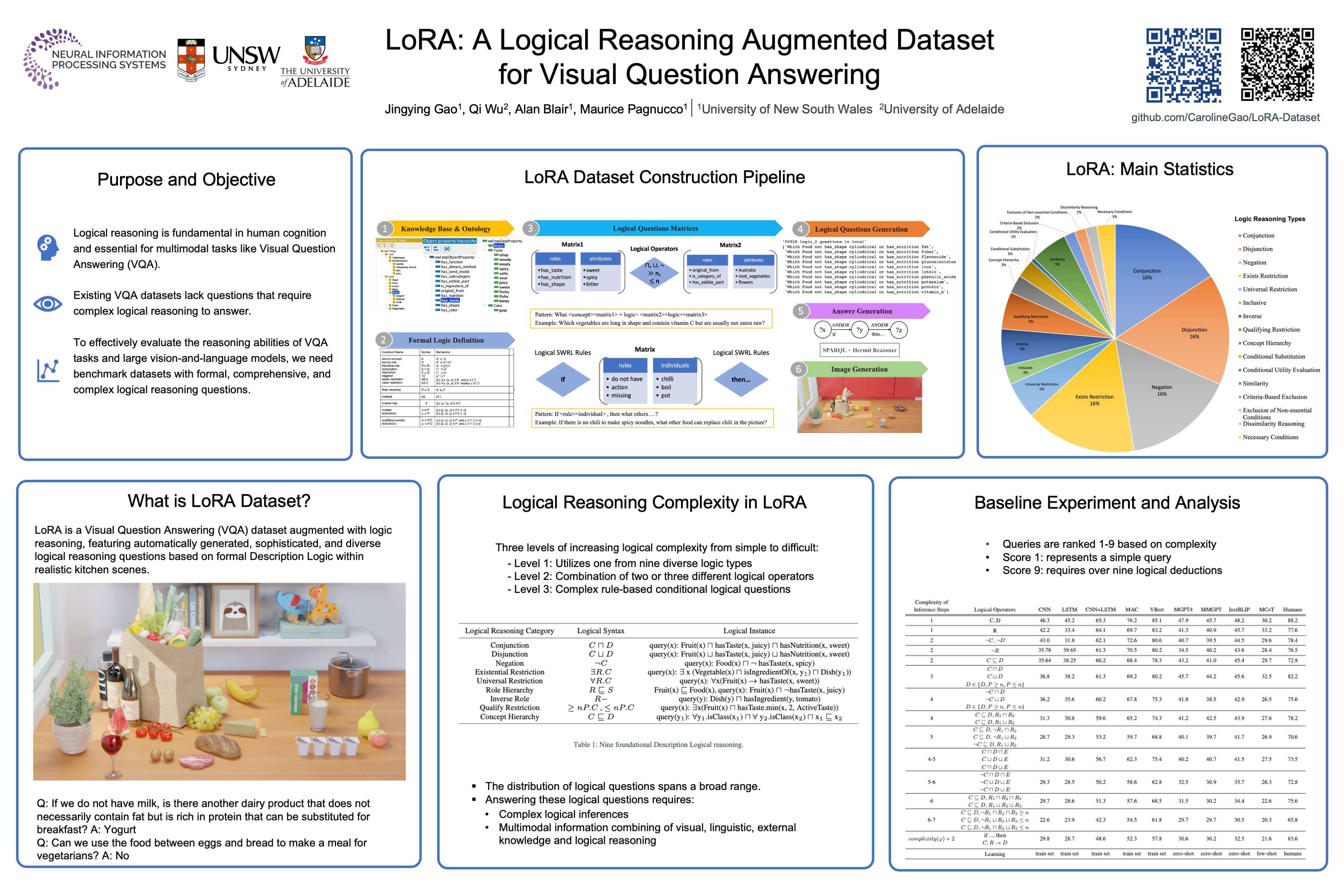
The capacity to reason logically is a hallmark of human cognition. Humans excel at integrating multimodal information for locigal reasoning, as exemplified by the Visual Question Answering (VQA) task, which is a challenging multimodal task. VQA tasks and large vision-and-language models aim to tackle reasoning problems, but the accuracy, consistency and fabrication of the generated answers is hard to evaluate in the absence of a VQA dataset that can offer formal, comprehensive and systematic complex logical reasoning questions. To address this gap, we present LoRA, a novel Logical Reasoning Augmented VQA dataset that requires formal and complex description logic reasoning based on a food-and-kitchen knowledge base. Our main objective in creating LoRA is to enhance the complex and formal logical reasoning capabilities of VQA models, which are not adequately measured by existing VQA datasets. We devise strong and flexible programs to automatically generate 200,000 diverse description logic reasoning questions based on the SROIQ Description Logic, along with realistic kitchen scenes and ground truth answers. We fine-tune the latest transformer VQA models and evaluate the zero-shot performance of the state-of-the-art large vision-and-language models on LoRA. The results reveal that LoRA presents a unique challenge in logical reasoning, setting a systematic and comprehensive evaluation standard.