[ Great Hall & Hall B1+B2 (level 1) ]
[ Great Hall & Hall B1+B2 (level 1) ]
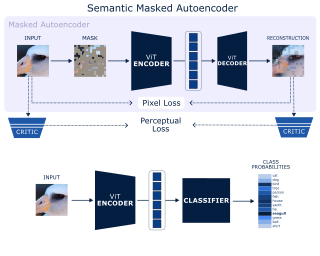
Scope of Reproducibility — The Masked Autoencoder (MAE) was recently proposed as aframework for efficient self‐supervised pre‐training in Computer Vision [1]. In this pa‐per, we attempt a replication of the MAE under significant computational constraints.Specifically, we target the claim that masking out a large part of the input image yieldsa nontrivial and meaningful self‐supervisory task, which allows training models thatgeneralize well. We also present the Semantic Masked Autoencoder (SMAE), a novel yetsimple extension of MAE which uses perceptual loss to improve encoder embeddings.Methodology — The datasets and backbones we rely on are significantly smaller than thoseused by [1]. Our main experiments are performed on Tiny ImageNet (TIN) [2] and trans‐fer learning is performed on a low‐resolution version of CUB‐200‐2011 [3]. We use aViT‐Lite [4] as backbone. We also compare the MAE to DINO, an alternative frame‐work for self‐supervised learning [5]. The ViT, MAE, as well as perceptual loss wereimplemented from scratch, without consulting the original authors’ code. Our code isavailable at https://github.com/MLReproHub/SMAE. The computational budget for ourreproduction and extension was approximately 150 GPU hours.Results — This paper successfully reproduces the claim that the MAE poses a nontrivialand meaningful self‐supervisory task. We show that models trained with this frame‐work generalize well …
[ Great Hall & Hall B1+B2 (level 1) ]
In this paper, we establish the global optimality and convergence rate of an off-policy actor critic algorithm in the tabular setting without using density ratio to correct the discrepancy between the state distribution of the behavior policy and that of the target policy. Our work goes beyond existing works on the optimality of policy gradient methods in that existing works use the exact policy gradient for updating the policy parameters while we use an approximate and stochastic update step. Our update step is not a gradient update because we do not use a density ratio to correct the state distribution, which aligns well with what practitioners do. Our update is approximate because we use a learned critic instead of the true value function. Our update is stochastic because at each step the update is done for only the current state action pair. Moreover, we remove several restrictive assumptions from existing works in our analysis. Central to our work is the finite sample analysis of a generic stochastic approximation algorithm with time-inhomogeneous update operators on time-inhomogeneous Markov chains, based on its uniform contraction properties.
[ Great Hall & Hall B1+B2 (level 1) ]
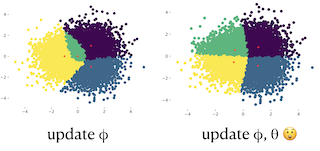
Scope of Reproducibility — Exponential family variational autoencoders struggle with reconstruction when encoders output limited information. We reproduce two experiments in which we first train the decoder and encoder separately. Then, we train both modules jointly using ELBO and observe the degradation of reconstruction. We verify how the theoretical insight into the design of the approximate posterior and decoder distributions for a discrete VAE in a semantic hashing application influences the choice of input features to improve overall performance.Methodology — We implement and train a synthetic experiment from scratch on a laptop. We use a mix of authors’ code and publicly available code to reproduce a GAN reinterpreted as a VAE. We consult authors’ code to reproduce semantic hashing experiment and make our own implementation. We train models the USI HPC cluster on machines with GTX 1080 Ti or A100 GPUs and 128 GiB of RAM. We spend under 100 GPU hours for all experiments.Results — We observe expected qualitative behavior predicted by the theory on all experiments. We improve the best semantic hashing model’s test performance by 5 nats by using a modern method for gradient estimation of discrete random variables.What was easy — Following experiment recipes was easy …
[ Great Hall & Hall B1+B2 (level 1) ]
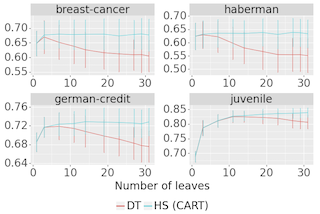
Scope of Reproducibility: The paper presents a novel post-hoc regularization technique for tree-based models, called Hierarchical Shrinkage (Agarwal 2022). Our main goal is to confirm the claims that it substantially increases the predictive performance of both decision trees and random forests, that it is faster than other regularization techniques, and that it makes the interpretation of random forests simpler.
Methodology: In our reproduction, we used the Hierarchical Shrinkage, provided by the authors in the Python package imodels. We also used their function for obtaining pre-cleaned data sets. While the algorithm code and clean datasets were provided we re-implemented the experiments as well as added additional experiments to further test the validity of the claims. The results were tested by applying Hierarchical Shrinkage to different tree models and comparing them to the authors' results.
Results: We managed to reproduce most of the results the authors get. The method works well and most of the claims are supported. The method does increase the predictive performance of tree-based models most of the time, but not always. When compared to other regularization techniques the Hierarchical Shrinkage outperforms them when used on decision trees, but not when used on random forests. Since the method is …
[ Great Hall & Hall B1+B2 (level 1) ]

We consider Generative Adversarial Networks (GANs) and address the underlying functional optimization problem ab initio within a variational setting. Strictly speaking, the optimization of the generator and discriminator functions must be carried out in accordance with the Euler-Lagrange conditions, which become particularly relevant in scenarios where the optimization cost involves regularizers comprising the derivatives of these functions. Considering Wasserstein GANs (WGANs) with a gradient-norm penalty, we show that the optimal discriminator is the solution to a Poisson differential equation. In principle, the optimal discriminator can be obtained in closed form without having to train a neural network. We illustrate this by employing a Fourier-series approximation to solve the Poisson differential equation. Experimental results based on synthesized Gaussian data demonstrate superior convergence behavior of the proposed approach in comparison with the baseline WGAN variants that employ weight-clipping, gradient or Lipschitz penalties on the discriminator on low-dimensional data. We also analyze the truncation error of the Fourier-series approximation and the estimation error of the Fourier coefficients in a high-dimensional setting. We demonstrate applications to real-world images considering latent-space prior matching in Wasserstein autoencoders and present performance comparisons on benchmark datasets such as MNIST, SVHN, CelebA, CIFAR-10, and Ukiyo-E. We demonstrate that the …
[ Great Hall & Hall B1+B2 (level 1) ]

Scope of Reproducibility — This paper analyses the reproducibility of the study Proto2Proto: Can you recognize the car, the way I do? The main contributions and claims of the study are: 1) Using Proto2Proto, a shallower student model is more faithful to the teacher in terms of interpretability than a baseline student model while also showing the same or better accuracy; 2) Global Explanation loss forces student prototypes to be close to teacher prototypes; 3) Patch‐Prototype Correspondence loss enforces the local representations of the student to be similar to those of the teacher; 4) The proposed evaluation metrics determine the faithfulness of the student to the teacher in terms of interpretability.Methodology — A public code repository was available for the paper, which provided a working but incomplete and minimally documented codebase. With some modifications we were able to carry out the experiments that were best supported by the codebase. We spent a total of 60 computational GPU hours on reproduction.Results — The results we were able to produce support claim 1, albeit weakly. Further results are in line with the paper, but we found them to go against claim 3. In addition, we carried out a theoretical analysis which provides …
[ Great Hall & Hall B1+B2 (level 1) ]
In this reproducibility study, we verify the claims and contributions in Cartoon Explanations of Image Classifiers by Kolek et al.. These include (i) A proposed technique named CartoonX used to extract visual explanations for predictions via image classification networks, (ii) CartoonX being able to reveal piece‐wise smooth regions of the image, unlike previous methods, which extract relevant pixel‐sparse regions, and (iii) CartoonX achieving lower distortion values than these methods.
[ Great Hall & Hall B1+B2 (level 1) ]

[ Great Hall & Hall B1+B2 (level 1) ]
Several algorithms involving the Variational Rényi (VR) bound have been proposed to minimize an alpha-divergence between a target posterior distribution and a variational distribution. Despite promising empirical results, those algorithms resort to biased stochastic gradient descent procedures and thus lack theoretical guarantees. In this paper, we formalize and study the VR-IWAE bound, a generalization of the importance weighted auto-encoder (IWAE) bound. We show that the VR-IWAE bound enjoys several desirable properties and notably leads to the same stochastic gradient descent procedure as the VR bound in the reparameterized case, but this time by relying on unbiased gradient estimators. We then provide two complementary theoretical analyses of the VR-IWAE bound and thus of the standard IWAE bound. Those analyses shed light on the benefits or lack thereof of these bounds. Lastly, we illustrate our theoretical claims over toy and real-data examples.
[ Great Hall & Hall B1+B2 (level 1) ]
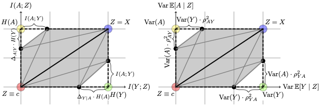
A wide range of machine learning applications such as privacy-preserving learning, algorithmic fairness, and domain adaptation/generalization among others, involve learning invariant representations of the data that aim to achieve two competing goals: (a) maximize information or accuracy with respect to a target response, and (b) maximize invariance or independence with respect to a set of protected features (e.g.\ for fairness, privacy, etc). Despite their wide applicability, theoretical understanding of the optimal tradeoffs --- with respect to accuracy, and invariance --- achievable by invariant representations is still severely lacking. In this paper, we provide an information theoretic analysis of such tradeoffs under both classification and regression settings. More precisely, we provide a geometric characterization of the accuracy and invariance achievable by any representation of the data; we term this feasible region the information plane. We provide an inner bound for this feasible region for the classification case, and an exact characterization for the regression case, which allows us to either bound or exactly characterize the Pareto optimal frontier between accuracy and invariance. Although our contributions are mainly theoretical, a key practical application of our results is in certifying the potential sub-optimality of any given representation learning algorithm for either classification or …
[ Great Hall & Hall B1+B2 (level 1) ]
The lifelong learning paradigm in machine learning is an attractive alternative to the more prominent isolated learning scheme not only due to its resemblance to biological learning but also its potential to reduce energy waste by obviating excessive model re-training. A key challenge to this paradigm is the phenomenon of catastrophic forgetting. With the increasing popularity and success of pre-trained models in machine learning, we pose the question: What role does pre-training play in lifelong learning, specifically with respect to catastrophic forgetting? We investigate existing methods in the context of large, pre-trained models and evaluate their performance on a variety of text and image classification tasks, including a large-scale study using a novel data set of 15 diverse NLP tasks. Across all settings, we observe that generic pre-training implicitly alleviates the effects of catastrophic forgetting when learning multiple tasks sequentially compared to randomly initialized models. We then further investigate why pre-training alleviates forgetting in this setting. We study this phenomenon by analyzing the loss landscape, finding that pre-trained weights appear to ease forgetting by leading to wider minima. Based on this insight, we propose jointly optimizing for current task loss and loss basin sharpness to explicitly encourage wider basins during …
[ Great Hall & Hall B1+B2 (level 1) ]
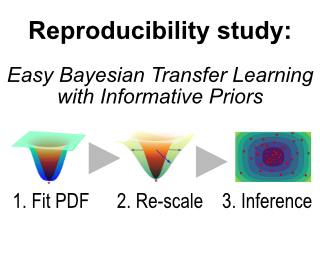
REPRODUCIBILITY SUMMARYScope of ReproducibilityIn this work, we study the reproducibility of the paper: Pre-Train Your Loss: Easy Bayesian Transfer Learning with Informative Priors. The paper proposes a three-step pipeline for replacing standard transfer learning with a pre-trained prior. The first step is training a prior, the second is re-scaling of a prior, and the third is inference.The authors claim that increasing the rank and the scaling factor improves performance on the downstream task. They also argue that using Bayesian learning with informative prior leads to a more data-efficient and improved performance compared to standard SGD transfer learning or using non-informative prior. We reproduce the main claims on one of the four data sets in the paper.MethodologyWe used a combination of the authors' and our code. The authors provided a training pipeline for the user but not the code to fully reproduce the paper. We modified the training pipeline to suit our needs and created a testing pipeline to evaluate the models. We reproduced the results for the Oxford-102-Flowers data set on an Nvidia RTX 3070 GPU using approximately 310 GPU hours for the main results.ResultsOur results confirm most of the claims tested, although we could not achieve the exact same …
[ Great Hall & Hall B1+B2 (level 1) ]

The evaluation of explanation methods is a research topic that has not yet been explored deeply, however, since explainability is supposed to strengthen trust in artificial intelligence, it is necessary to systematically review and compare explanation methods in order to confirm their correctness. Until now, no tool with focus on XAI evaluation exists that exhaustively and speedily allows researchers to evaluate the performance of explanations of neural network predictions. To increase transparency and reproducibility in the field, we therefore built Quantus—a comprehensive, evaluation toolkit in Python that includes a growing, well-organised collection of evaluation metrics and tutorials for evaluating explainable methods. The toolkit has been thoroughly tested and is available under an open-source license on PyPi (or on https://github.com/understandable-machine-intelligence-lab/Quantus/).
[ Great Hall & Hall B1+B2 (level 1) ]

Scope of reproducibility - We study the reproducibility of the paper "Quantifying Societal Bias Amplification in Image Captioning" by Hirota et al. In this paper, the authors propose a new metric to measure bias amplification, called LIC, and evaluate it on multiple image captioning models. Based on this evaluation, they make the following main claims which we aim to verify: (1) all models amplify gender bias, (2) all models amplify racial bias, (3) LIC is robust against encoders, and (4) the NIC+Equalizer model increases gender bias with respect to the baseline. We also extend upon the original work by evaluating LIC for age bias.Methodology - For our reproduction, we were able to run the code provided by the authors without any modifications. For our extension, we automatically labelled the images in the dataset with age annotations and adjusted the code to work with this dataset. In total, 38 GPU hours were needed to perform all experiments.Results - The reproduced results are close to the original results and support all four main claims. Furthermore, our additional results show that only a subset of the models amplifies age bias, while they strengthen the claim that LIC is robust against encoders. However, we …
[ Great Hall & Hall B1+B2 (level 1) ]
[ Great Hall & Hall B1+B2 (level 1) ]
Scope of Reproducibility:In this report, we aim to validate the claims of Bansal et al. These are that the recurrent architecture presented, with skip connections and a progressive loss function, prevent the original problem being forgotten or corrupted during processing allowing for the recurrent module to be applied indefinitely and that this architecture avoids the overthinking trap. We use both code released by the authors and newly developed to recreate many results presented in the paper. Additionally, we present analysis of the newly introduced alpha hyperparameter and investigate interesting perturbation behaviour of prefix sums models. Further, we conduct a hyperparameter search and provide an analysis of the Asymptotic Alignment scores of the models presented.Methodology:We use the PyTorch code released by the authors to replicate accuracy experiments. We then, independently, develop our own PyTorchFI to replicate perturbation experiments presented by Bansal et al. Overall, providing a replication of all results shown in the main body of the paper. We then extend these results, providing an analysis of the alpha hyperparameter, analysis of perturbation recovery, Asymptotic Alignment scores and a hyperparameter search. We used both a Nvidia RTX 2080Ti GPU and sets of three NVIDIA Quadro RTX6000 GPUs, taking a total of …
[ Great Hall & Hall B1+B2 (level 1) ]
[ Great Hall & Hall B1+B2 (level 1) ]

Scope of ReproducibilityIn this work we reproduce and extend the results presented in “Quantifying Societal Bias Amplification in Image Captioning” by Hirota et al. This paper introduces LIC, a metric to quantify bias amplification by image captioning models, which is tested for gender and racial bias amplification. The original paper claims that this metric is robust, and that all models amplify both gender and racial bias. It also claims that gender bias is more apparent than racial bias, and the Equalizer variation of the NIC+ model increases gender but not racial bias. We repeat the measurements to confirm these claims. We extend the analysis to whether the method can be generalized to other attributes such as bias in age.MethodologyThe authors of the paper provided a repository containing the necessary code. We had to modify it and add several scripts to be able to run all the experiments. The results were reproduced using the same subset of COCO [3] as in the original paper. Additionally, we manually labeled images according to age for our specific experiments. All experiments were ran on GPUs for a total of approximately 100 hours.ResultsAll claims made by the paper seem to hold, as the results we …
[ Great Hall & Hall B1+B2 (level 1) ]
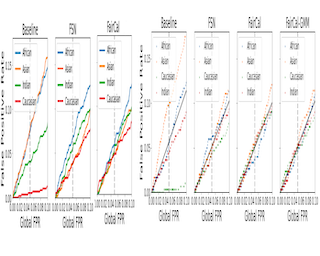
Scope of Reproducibility — This paper aims to reproduce the study FairCal: Fairness Calibration for Face Verification by Salvador et al., focused on verifying three main claims: FairCal (introduced by the authors) achieves state‐of‐the‐art (i) global accuracy, (ii) fairness-calibrated probabilities and (iii) equality in false positive rates across sensitive attributes (i.e. predictive equality). The sensitive attribute taken into account is ethnicity.Methodology — Salvador et al. provide partial code via a GitHub repository. Additional code to generate image embeddings from three pretrained neural network models were based on existing repositories. All code was refactored to fit our needs, keeping extendability and readability in mind. Two datasets were used, namely, Balanced Faces in the Wild (BFW) and Racial Faces in the Wild (RFW). Additional experiments using Gaussian mixture models instead of K‐means clustering for FairCal validate the use of unsupervised clus‐ tering methods. The code was run on an AMD Ryzen 7 2700X CPU and NVIDIA GeForce GTX1080Ti GPU with a total runtime of around 3 hours for all experiments.Results — In most cases, we were able to reproduce results from the original paper to within 1 standard deviation, and observe similar trends. However, due to missing information about image pre‐processing, we …
[ Great Hall & Hall B1+B2 (level 1) ]
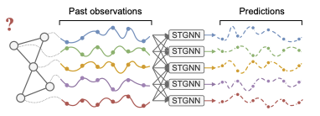
Outstanding achievements of graph neural networks for spatiotemporal time series analysis show that relational constraints introduce an effective inductive bias into neural forecasting architectures. Often, however, the relational information characterizing the underlying data-generating process is unavailable and the practitioner is left with the problem of inferring from data which relational graph to use in the subsequent processing stages. We propose novel, principled - yet practical - probabilistic score-based methods that learn the relational dependencies as distributions over graphs while maximizing end-to-end the performance at task. The proposed graph learning framework is based on consolidated variance reduction techniques for Monte Carlo score-based gradient estimation, is theoretically grounded, and, as we show, effective in practice. In this paper, we focus on the time series forecasting problem and show that, by tailoring the gradient estimators to the graph learning problem, we are able to achieve state-of-the-art performance while controlling the sparsity of the learned graph and the computational scalability. We empirically assess the effectiveness of the proposed method on synthetic and real-world benchmarks, showing that the proposed solution can be used as a stand-alone graph identification procedure as well as a graph learning component of an end-to-end forecasting architecture.
[ Great Hall & Hall B1+B2 (level 1) ]
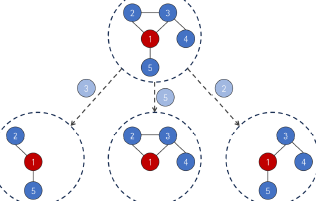
Yuan et al. claim their proposed method SubgraphX achieves (i) higher fidelity in explaining models for graph- and node classification tasks compared to other explanation techniques, namely GNNExplainer. Additionally, (ii) the computational effort of SubgraphX is at a 'reasonable level', which is not further specified by the original authors. We define this as at most ten times slower than GNNExplainer. We reimplemented the proposed algorithm in PyTorch. Then, we replicated the experiments performed by the authors on a smaller scale due to resource constraints. Additionally, we checked the performance on a new dataset and investigated the influence of hyperparameters. Lastly, we improved SubgraphX using greedy initialization and utilizing fidelity as a score function. We were able to reproduce the main claims on the MUTAG dataset, where SubgraphX has a better performance than GNNExplainer. Furthermore, SubgraphX has a reasonable runtime of about seven times longer than GNNExplainer. We successfully employed SubgraphX on the Karate Club dataset, where it outperforms GNNExplainer as well. The hyperparameter study revealed that the number of Monte-Carlo Tree search iterations and Monte-Carlo sampling steps are the most important hyperparameters and directly trade performance for runtime. Lastly, we show that our proposed improvements to SubgraphX significantly enhance fidelity …
[ Great Hall & Hall B1+B2 (level 1) ]
[ Great Hall & Hall B1+B2 (level 1) ]
[ Great Hall & Hall B1+B2 (level 1) ]

Scope of Reproducibility: The original authors' main contribution is the family of Shifty algorithms, which can guarantee that certain fairness constraints will hold with high confidence even after a demographic shift in the deployment population occurs. They claim that Shifty provides these high-confidence fairness guarantees without a loss in model performance, given enough training data.Methodology: The code provided by the original paper was used, and only some small adjustments needed to be made in order to reproduce the experiments. All model specifications and hyperparameters from the original implementation were used. Extending beyond reproducing the original paper, we investigated the sensibility of Shifty to the size of the bounding intervals limiting the possible demographic shift, and ran shifty with an additional optimization method.Results: Our results approached the results reported in the original paper. They supported the claim that \textit{Shifty} reliably guarantees fairness under demographic shift, but could not verify that Shifty performs at no loss of accuracy. What was easy: The theoretical framework laid out in the original paper was well explained and supported by additional formulas and proofs in the appendix. Further, the authors provided clear instructions on how to run the experiments and provided necessary hyperparameters.What was difficult: While …
[ Great Hall & Hall B1+B2 (level 1) ]
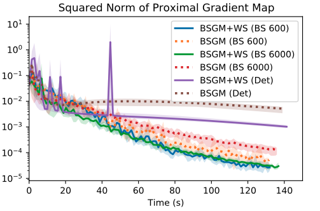
Scope of Reproducibility — CartoonX [1] is a novel explanation method for image classifiers. In this reproducibility study, we examine the claims of the original authors of CartoonX that it: (i) extracts relevant piece‐wise smooth parts of the image, resulting in explanations which are more straightforward to interpret for humans; (ii) achieves lower distortion in the model output, using fewer coefficients than other state-of‐the‐art methods; (iii) is model‐agnostic. Finally, we examine how to reduce the runtime.Methodology — The original authors’ open‐sourced implementation has been used to examine (i). We implemented the code to examine (ii), as there was no public code available for this. We tested claim (iii) by performing the same experiments with a Vision Transformer instead of a CNN. To reduce the runtime, we extended the existing implementation with multiple enhanced initialization techniques. All experiments took approximately 38.4 hours on a single NVIDIA Titan RTX.Results — Our results support the claims made by the original authors. (i) We observe that CartoonX produces piece‐wise smooth explanations. Most of the explanations give valuable insights. (ii) Most experiments, that show how CartoonX achieves lower distortion outputs compared to other methods, have been reproduced. In the cases where exact reproducibility has not …
[ Great Hall & Hall B1+B2 (level 1) ]
Scope of ReproducibilityThis study aims to reproduce the results of the paper 'FOCUS: Flexible Optimizable Counterfactual Explanations for Tree Ensembles' by Lucic et al.The main claims of the original paper are that FOCUS is able to (i) generate counterfactual explanations for all the instances in a dataset; and (ii) find counterfactual explanations that are closer to the original input for tree-based algorithms than existing methods.MethodologyThis study replicates the original experiments using the code, data, and models provided by the authors. Additionally, this study re-implements code and retrains the models to evaluate the robustness and generality of FOCUS.All the experiments were conducted on a personal laptop with a quad-core CPU with 8GB of RAM and it approximately took 33 hours in total.ResultsThis study was able to replicate the results of the original paper in terms of finding counterfactual explanations for all instances in datasets. Additional experiments were conducted to validate the robustness and generality of the conclusion. While there were slight deviations in terms of generating smaller mean distances, half of the models still outperformed the results of the existing method.What was easyThe implementation of the original paper is publicly available on GitHub. The repository contains the models and data used …
[ Great Hall & Hall B1+B2 (level 1) ]
Statistical models are central to machine learning with broad applicability across a range of downstream tasks. The models are controlled by free parameters that are typically estimated from data by maximum-likelihood estimation or approximations thereof. However, when faced with real-world data sets many of the models run into a critical issue: they are formulated in terms of fully-observed data, whereas in practice the data sets are plagued with missing data. The theory of statistical model estimation from incomplete data is conceptually similar to the estimation of latent-variable models, where powerful tools such as variational inference (VI) exist. However, in contrast to standard latent-variable models, parameter estimation with incomplete data often requires estimating exponentially-many conditional distributions of the missing variables, hence making standard VI methods intractable. We address this gap by introducing variational Gibbs inference (VGI), a new general-purpose method to estimate the parameters of statistical models from incomplete data. We validate VGI on a set of synthetic and real-world estimation tasks, estimating important machine learning models such as variational autoencoders and normalising flows from incomplete data. The proposed method, whilst general-purpose, achieves competitive or better performance than existing model-specific estimation methods.
[ Great Hall & Hall B1+B2 (level 1) ]

In this work, we present our reproducibility study of "Label-Free Explainability for Unsupervised Models", a paper that introduces two post‐hoc explanation techniques for neural networks: (1) label‐free feature importance and (2) label‐free example importance. Our study focuses on the reproducibility of the authors’ most important claims: (i) perturbing features with the highest importance scores causes higherlatent shift than perturbing random pixels, (ii) label‐free example importance scores help to identify training examples that are highly related to a given test example, (iii) unsupervised models trained on different tasks show moderate correlation among the highest scored features and (iv) low correlation in example scores measured on a fixed set of data points, and (v) increasing the disentanglement with β in a β‐VAE does not imply that latent units will focus on more different features. We reviewed the authors’ code, checked if the implementation of experiments matched with the paper, and also ran all experiments. The results are shown to be reproducible. Moreover, we extended the codebase in order to run the experiments on more datasets, and to test the claims with other experiments.
[ Great Hall & Hall B1+B2 (level 1) ]
Scope of ReproducibilityThis work aims to reproduce the findings of the paper “CrossWalk: Fairness-enhanced Node Representation Learning” by investigating the two main claims made by the authors about CrossWalk, which suggest that (i) CrossWalk enhances fairness in three graph algorithms, while only suffering from small decreases in performance, and that (ii) CrossWalk preserves the necessary structural properties of the graph while reducing disparity.MethodologyThe authors made the CrossWalk repository available, which contained most of the datasets used for their experimentation, and the scripts needed to run the experiments. However, the codebase lacked documentation and was missing logic for running all experiments and visualizing the results. We, therefore, re-implement their code from scratch and deploy it as a python package which can be run to obtain all the showcased results. ResultsOur work suggests that the first claim of the paper, which states that Crosswalk minimizes disparity and thus enhances fairness is partially reproducible, and only for the tasks of Node classification and Influence maximization as the parameters specified in the paper do not always yield similar results. Then, the second claim of the paper which states that Crosswalk attains the necessary structural properties of the graph is fully reproducible through our experiments.What …
[ Great Hall & Hall B1+B2 (level 1) ]
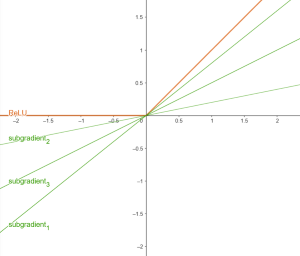
Neural networks have become very common in machine learning, and new problems and trends arise as the trade-off between theory, computational tools and real-world problems become more narrow and complex. We decided to retake the influence of the ReLU'(0) on the backpropagation as it has become more common to use lower floating point precisions in the GPUs so that more tasks can run in parallel and make training and inference more efficient. As opposed to what theory suggests, the original authors shown that when using 16- and 32-bit precision, the value of ReLU'(0) may influence the result. In this work we extended some experiments to see how the training and test loss are affected in simple and more complex models.
[ Great Hall & Hall B1+B2 (level 1) ]

We propose two novel nonparametric two-sample kernel tests based on the Maximum Mean Discrepancy (MMD). First, for a fixed kernel, we construct an MMD test using either permutations or a wild bootstrap, two popular numerical procedures to determine the test threshold. We prove that this test controls the probability of type I error non-asymptotically. Hence, it can be used reliably even in settings with small sample sizes as it remains well-calibrated, which differs from previous MMD tests which only guarantee correct test level asymptotically. When the difference in densities lies in a Sobolev ball, we prove minimax optimality of our MMD test with a specific kernel depending on the smoothness parameter of the Sobolev ball. In practice, this parameter is unknown and, hence, the optimal MMD test with this particular kernel cannot be used. To overcome this issue, we construct an aggregated test, called MMDAgg, which is adaptive to the smoothness parameter. The test power is maximised over the collection of kernels used, without requiring held-out data for kernel selection (which results in a loss of test power), or arbitrary kernel choices such as the median heuristic. We prove that MMDAgg still controls the level non-asymptotically, and achieves the minimax …
[ Great Hall & Hall B1+B2 (level 1) ]
Reproducibility SummaryScope of Reproducibility — We aim to reproduce a result from the paper “Exploring the Role of Grammar and Word Choice in Bias Toward African American English (AAE) in Hate Speech Classification” [1]. Our study is restricted specifically to the claim that the use of swear words impacts hate speech classification of AAE text. We were able to broadly validate the claim of the paper, however, the magnitude of the effect was dependent on the word replacement strategy, which was somewhat ambiguous in the original paper.Methodology — The authors did not publish source code. Therefore, we reproduce the experiments by following the methodology described in the paper. We train BERT models from TensorFlow Hub [2] to classify hate speech using the DWMW17[3] and FDCL18[4]Twitter datasets. Then, we compile a dictionary of swear words and replacement words with comparable meaning, and we use this to create “censored” versions of samples in Blodgett et al.’s[5] AAE Twitter dataset. Using the BERT models, we evaluate the hate speech classification of the original data and the censored data. Our experiments are conducted on an open‐access research testbed, Chameleon [6], and we make available both our code and instructions for reproducing the result on …
[ Great Hall & Hall B1+B2 (level 1) ]

Scope of Reproducibility — We examine the main claims of the original paper [1], whichstates that in an image classification task with imbalanced training data, (i) using purenoise to augment minority‐class images encourages generalization by improving minority‐class accuracy. This method is paired with (ii) a new batch normalization layer thatnormalizes noise images using affine parameters learned from natural images, whichimproves the model’s performance. Moreover, (iii) this improvement is robust to vary‐ing levels of data augmentation. Finally, the authors propose that (iv) adding pure noiseimages can improve classification even on balanced training data.Methodology — We implemented the training pipeline from the description of the paperusing PyTorch and integrated authors’ code snippets for sampling pure noise imagesand batch normalizing noise and natural images separately. All of our experiments wererun on a machine from a cloud computing service with one NVIDIA RTX A5000 GraphicsCard and had a total computational time of approximately 432 GPU hours.Results — We reproduced the main claims that (i) oversampling with pure noise improvesgeneralization by improving the minority‐class accuracy, (ii) the proposed batch nor‐malization (BN) method outperforms baselines, (iii) and this improvement is robustacross data augmentations. Our results also support that (iv) adding pure noise imagescan improve classification on …
[ Great Hall & Hall B1+B2 (level 1) ]

Network data are increasingly available in various research fields, motivating statistical analysis for populations of networks, where a network as a whole is viewed as a data point. The study of how a network changes as a function of covariates is often of paramount interest. However, due to the non-Euclidean nature of networks, basic statistical tools available for scalar and vector data are no longer applicable. This motivates an extension of the notion of regression to the case where responses are network data. Here we propose to adopt conditional Fréchet means implemented as M-estimators that depend on weights derived from both global and local least squares regression, extending the Fréchet regression framework to networks that are quantified by their graph Laplacians. The challenge is to characterize the space of graph Laplacians to justify the application of Fréchet regression. This characterization then leads to asymptotic rates of convergence for the corresponding M-estimators by applying empirical process methods. We demonstrate the usefulness and good practical performance of the proposed framework with simulations and with network data arising from resting-state fMRI in neuroimaging, as well as New York taxi records.
[ Great Hall & Hall B1+B2 (level 1) ]
[ Great Hall & Hall B1+B2 (level 1) ]

This article presents a novel approach to construct Intrinsic Gaussian Processes for regression on unknown manifolds with probabilistic metrics (GPUM) in point clouds. In many real world applications, one often encounters high dimensional data (e.g.‘point cloud data’) centered around some lower dimensional unknown manifolds. The geometry of manifold is in general different from the usual Euclidean geometry. Naively applying traditional smoothing methods such as Euclidean Gaussian Processes (GPs) to manifold-valued data and so ignoring the geometry of the space can potentially lead to highly misleading predictions and inferences. A manifold embedded in a high dimensional Euclidean space can be well described by a probabilistic mapping function and the corresponding latent space. We investigate the geometrical structure of the unknown manifolds using the Bayesian Gaussian Processes latent variable models(B-GPLVM) and Riemannian geometry. The distribution of the metric tensor is learned using B-GPLVM. The boundary of the resulting manifold is defined based on the uncertainty quantification of the mapping. We use the probabilistic metric tensor to simulate Brownian Motion paths on the unknown manifold. The heat kernel is estimated as the transition density of Brownian Motion and used as the covariance functions of GPUM. The applications of GPUM are illustrated in the …
[ Great Hall & Hall B1+B2 (level 1) ]
"CrossWalk: Fairness-Enhanced Node Representation Learning" is set to be reproduced and reviewed. It presents an extension to existing graph algorithms that incorporate the idea of biased random walks for obtaining node embeddings. CrossWalk incorporates fairness by up-weighting edges of nodes located near group boundaries. The authors claim that their approach outperforms baseline algorithms, such as DeepWalk and FairWalk, in terms of reducing the disparity between different classes within a graph network. The authors accompanied their paper with the publication of an open GitHub page, which includes the source code and relevant data sets. The limited size of the data sets in combination with the efficient algorithms enables the experiments to be conducted without significant difficulties and is computable on standard CPUs without the need for additional resources.In this reproducibility report, the outcomes of the experiments are in agreement with the results presented in the original paper. However, the inherent randomness of the random walks makes it difficult to quantify the extent of similarity between the reproduced results and the results as stated in the original paper. However, it can be concluded that CrossWalk results in a decreased disparity between groups in graph networks.The authors effectively conveyed the underlying concept of …
[ Great Hall & Hall B1+B2 (level 1) ]
Graph Neural Networks (GNNs) have achieved state-of-the-art results on many graph analysis tasks such as node classification and link prediction. However, important unsupervised problems on graphs, such as graph clustering, have proved more resistant to advances in GNNs. Graph clustering has the same overall goal as node pooling in GNNs—does this mean that GNN pooling methods do a good job at clustering graphs? Surprisingly, the answer is no—current GNN pooling methods often fail to recover the cluster structure in cases where simple baselines, such as k-means applied on learned representations, work well. We investigate further by carefully designing a set of experiments to study different signal-to-noise scenarios both in graph structure and attribute data. To address these methods' poor performance in clustering, we introduce Deep Modularity Networks (DMoN), an unsupervised pooling method inspired by the modularity measure of clustering quality, and show how it tackles recovery of the challenging clustering structure of real-world graphs. Similarly, on real-world data, we show that DMoN produces high quality clusters which correlate strongly with ground truth labels, achieving state-of-the-art results with over 40% improvement over other pooling methods across different metrics.
[ Great Hall & Hall B1+B2 (level 1) ]
scikit-multimodallearn is a Python library for multimodal supervised learning, licensed under Free BSD, and compatible with the well-known scikit-learn toolbox (Fabian Pedregosa, 2011). This paper details the content of the library, including a specific multimodal data formatting and classification and regression algorithms. Use cases and examples are also provided.
[ Great Hall & Hall B1+B2 (level 1) ]
Gaussian processes are widely employed as versatile modelling and predictive tools in spatial statistics, functional data analysis, computer modelling and diverse applications of machine learning. They have been widely studied over Euclidean spaces, where they are specified using covariance functions or covariograms for modelling complex dependencies. There is a growing literature on Gaussian processes over Riemannian manifolds in order to develop richer and more flexible inferential frameworks for non-Euclidean data. While numerical approximations through graph representations have been well studied for the Matern covariogram and heat kernel, the behaviour of asymptotic inference on the parameters of the covariogram has received relatively scant attention. We focus on asymptotic behaviour for Gaussian processes constructed over compact Riemannian manifolds. Building upon a recently introduced Matern covariogram on a compact Riemannian manifold, we employ formal notions and conditions for the equivalence of two Matern Gaussian random measures on compact manifolds to derive the parameter that is identifiable, also known as the microergodic parameter, and formally establish the consistency of the maximum likelihood estimate and the asymptotic optimality of the best linear unbiased predictor. The circle is studied as a specific example of compact Riemannian manifolds with numerical experiments to illustrate and corroborate the theory.
[ Great Hall & Hall B1+B2 (level 1) ]
[ Great Hall & Hall B1+B2 (level 1) ]

[ Great Hall & Hall B1+B2 (level 1) ]

Many modern applications of online changepoint detection require the ability to process high-frequency observations, sometimes with limited available computational resources. Online algorithms for detecting a change in mean often involve using a moving window, or specifying the expected size of change. Such choices affect which changes the algorithms have most power to detect. We introduce an algorithm, Functional Online CuSUM (FOCuS), which is equivalent to running these earlier methods simultaneously for all sizes of windows, or all possible values for the size of change. Our theoretical results give tight bounds on the expected computational cost per iteration of FOCuS, with this being logarithmic in the number of observations. We show how FOCuS can be applied to a number of different changes in mean scenarios, and demonstrate its practical utility through its state-of-the-art performance at detecting anomalous behaviour in computer server data.