[ Hall C2 (level 1 gate 9 south of food court) ]
Abstract
We prove that, for finite-arm bandits with linear function approximation, the global convergence of policy gradient (PG) methods depends on inter-related properties between the policy update and the representation. textcolor{blue}{First}, we establish a few key observations that frame the study: \textbf{(i)} Global convergence can be achieved under linear function approximation without policy or reward realizability, both for the standard Softmax PG and natural policy gradient (NPG). \textbf{(ii)} Approximation error is not a key quantity for characterizing global convergence in either algorithm. \textbf{(iii)} The conditions on the representation that imply global convergence are different between these two algorithms. Overall, these observations call into question approximation error as an appropriate quantity for characterizing the global convergence of PG methods under linear function approximation. \textcolor{blue}{Second}, motivated by these observations, we establish new general results: \textbf{(i)} NPG with linear function approximation achieves global convergence \emph{if and only if} the projection of the reward onto the representable space preserves the optimal action's rank, a quantity that is not strongly related to approximation error. \textbf{(ii)} The global convergence of Softmax PG occurs if the representation satisfies a non-domination condition and can preserve the ranking of rewards, which goes well beyond policy or reward realizability. We provide …
[ Room R06-R09 (level 2) ]
Abstract
Despite extensive studies, the underlying reason as to why overparameterizedneural networks can generalize remains elusive. Existing theory shows that common stochastic optimizers prefer flatter minimizers of the training loss, and thusa natural potential explanation is that flatness implies generalization. This workcritically examines this explanation. Through theoretical and empirical investigation, we identify the following three scenarios for two-layer ReLU networks: (1)flatness provably implies generalization; (2) there exist non-generalizing flattestmodels and sharpness minimization algorithms fail to generalize poorly, and (3)perhaps most strikingly, there exist non-generalizing flattest models, but sharpnessminimization algorithms still generalize. Our results suggest that the relationshipbetween sharpness and generalization subtly depends on the data distributionsand the model architectures and sharpness minimization algorithms do not onlyminimize sharpness to achieve better generalization. This calls for the search forother explanations for the generalization of over-parameterized neural networks
[ Room R02-R05 (level 2) ]
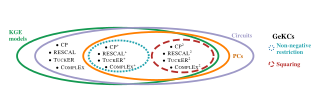
Abstract
Some of the most successful knowledge graph embedding (KGE) models for link prediction – CP, RESCAL, TuckER, ComplEx – can be interpreted as energy-based models. Under this perspective they are not amenable for exact maximum-likelihood estimation (MLE), sampling and struggle to integrate logical constraints. This work re-interprets the score functions of these KGEs as circuits – constrained computational graphs allowing efficient marginalisation. Then, we design two recipes to obtain efficient generative circuit models by either restricting their activations to be non-negative or squaring their outputs. Our interpretation comes with little or no loss of performance for link prediction, while the circuits framework unlocks exact learning by MLE, efficient sampling of new triples, and guarantee that logical constraints are satisfied by design. Furthermore, our models scale more gracefully than the original KGEs on graphs with millions of entities.
[ La Nouvelle Orleans Ballroom A-C (level 2) ]
Abstract
Large language models (LLMs) have shown promise in proving formal theorems using proof assistants such as Lean. However, existing methods are difficult to reproduce or build on, due to private code, data, and large compute requirements. This has created substantial barriers to research on machine learning methods for theorem proving. This paper removes these barriers by introducing LeanDojo: an open-source Lean playground consisting of toolkits, data, models, and benchmarks. LeanDojo extracts data from Lean and enables interaction with the proof environment programmatically. It contains fine-grained annotations of premises in proofs, providing valuable data for premise selection—a key bottleneck in theorem proving. Using this data, we develop ReProver (Retrieval-Augmented Prover): an LLM-based prover augmented with retrieval for selecting premises from a vast math library. It is inexpensive and needs only one GPU week of training. Our retriever leverages LeanDojo's program analysis capability to identify accessible premises and hard negative examples, which makes retrieval much more effective. Furthermore, we construct a new benchmark consisting of 98,734 theorems and proofs extracted from Lean's math library. It features challenging data split requiring the prover to generalize to theorems relying on novel premises that are never used in training. We use this benchmark for training …
[ Room R02-R05 (level 2) ]
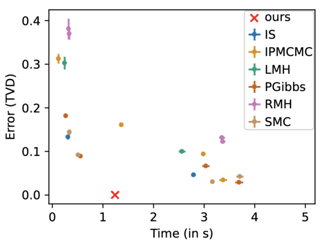
Abstract
We present an exact Bayesian inference method for discrete statistical models, which can find exact solutions to a large class of discrete inference problems, even with infinite support and continuous priors.To express such models, we introduce a probabilistic programming language that supports discrete and continuous sampling, discrete observations, affine functions, (stochastic) branching, and conditioning on discrete events.Our key tool is probability generating functions:they provide a compact closed-form representation of distributions that are definable by programs, thus enabling the exact computation of posterior probabilities, expectation, variance, and higher moments.Our inference method is provably correct and fully automated in a tool called Genfer, which uses automatic differentiation (specifically, Taylor polynomials), but does not require computer algebra.Our experiments show that Genfer is often faster than the existing exact inference tools PSI, Dice, and Prodigy.On a range of real-world inference problems that none of these exact tools can solve, Genfer's performance is competitive with approximate Monte Carlo methods, while avoiding approximation errors.
[ La Nouvelle Orleans Ballroom A-C (level 2) ]
Abstract
Aligning large language models (LLMs) with human preferences has proven to drastically improve usability and has driven rapid adoption as demonstrated by ChatGPT.Alignment techniques such as supervised fine-tuning (\textit{SFT}) and reinforcement learning from human feedback (\textit{RLHF}) greatly reduce the required skill and domain knowledge to effectively harness the capabilities of LLMs, increasing their accessibility and utility across various domains.However, state-of-the-art alignment techniques like \textit{RLHF} rely on high-quality human feedback data, which is expensive to create and often remains proprietary.In an effort to democratize research on large-scale alignment, we release OpenAssistant Conversations, a human-generated, human-annotated assistant-style conversation corpus consisting of 161,443 messages in 35 different languages, annotated with 461,292 quality ratings, resulting in over 10,000 complete and fully annotated conversation trees.The corpus is a product of a worldwide crowd-sourcing effort involving over 13,500 volunteers.Models trained on OpenAssistant Conversations show consistent improvements on standard benchmarks over respective base models.We release our code\footnote{\git} and data\footnote{\data} under a fully permissive licence.
[ Hall C2 (level 1 gate 9 south of food court) ]
Abstract
Offline inverse reinforcement learning (Offline IRL) aims to recover the structure of rewards and environment dynamics that underlie observed actions in a fixed, finite set of demonstrations from an expert agent. Accurate models of expertise in executing a task has applications in safety-sensitive applications such as clinical decision making and autonomous driving. However, the structure of an expert's preferences implicit in observed actions is closely linked to the expert's model of the environment dynamics (i.e. the ``world''). Thus, inaccurate models of the world obtained from finite data with limited coverage could compound inaccuracy in estimated rewards. To address this issue, we propose a bi-level optimization formulation of the estimation task wherein the upper level is likelihood maximization based upon a conservative model of the expert's policy (lower level). The policy model is conservative in that it maximizes reward subject to a penalty that is increasing in the uncertainty of the estimated model of the world. We propose a new algorithmic framework to solve the bi-level optimization problem formulation and provide statistical and computational guarantees of performance for the associated optimal reward estimator. Finally, we demonstrate that the proposed algorithm outperforms the state-of-the-art offline IRL and imitation learning benchmarks by a …
[ Room R06-R09 (level 2) ]
Abstract
Understanding the geometric properties of gradient descent dynamics is a key ingredient in deciphering the recent success of very large machine learning models. A striking observation is that trained over-parameterized models retain some properties of the optimization initialization. This "implicit bias" is believed to be responsible for some favorable properties of the trained models and could explain their good generalization properties. The purpose of this article is threefold. First, we rigorously expose the definition and basic properties of "conservation laws", that define quantities conserved during gradient flows of a given model (e.g. of a ReLU network with a given architecture) with any training data and any loss. Then we explain how to find the maximal number of independent conservation lawsby performing finite-dimensional algebraic manipulations on the Lie algebra generated by the Jacobian of the model. Finally, we provide algorithms to: a) compute a family of polynomial laws; b) compute the maximal number of (not necessarily polynomial) independent conservation laws. We provide showcase examples that we fully work out theoretically. Besides, applying the two algorithms confirms for a number of ReLU network architectures that all known laws are recovered by the algorithm, and that there are no other independent laws. Such …
[ Room R02-R05 (level 2) ]
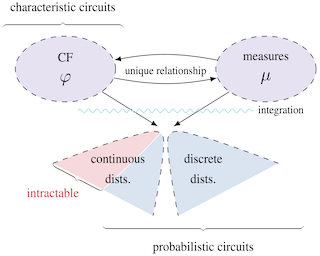
Abstract
In many real-world scenarios it is crucial to be able to reliably and efficiently reason under uncertainty while capturing complex relationships in data. Probabilistic circuits (PCs), a prominent family of tractable probabilistic models, offer a remedy to this challenge by composing simple, tractable distributions into a high-dimensional probability distribution. However, learning PCs on heterogeneous data is challenging and densities of some parametric distributions are not available in closed form, limiting their potential use. We introduce characteristic circuits (CCs), a family of tractable probabilistic models providing a unified formalization of distributions over heterogeneous data in the spectral domain. The one-to-one relationship between characteristic functions and probability measures enables us to learn high-dimensional distributions on heterogeneous data domains and facilitates efficient probabilistic inference even when no closed-form density function is available. We show that the structure and parameters of CCs can be learned efficiently from the data and find that CCs outperform state-of-the-art density estimators for heterogeneous data domains on common benchmark data sets.
[ La Nouvelle Orleans Ballroom A-C (level 2) ]
Abstract
Generative Pre-trained Transformer (GPT) models have exhibited exciting progress in capabilities, capturing the interest of practitioners and the public alike. Yet, while the literature on the trustworthiness of GPT models remains limited, practitioners have proposed employing capable GPT models for sensitive applications to healthcare and finance – where mistakes can be costly. To this end, this work proposes a comprehensive trustworthiness evaluation for large language models with a focus on GPT-4 and GPT-3.5, considering diverse perspectives – including toxicity, stereotype bias, adversarial robustness, out-of-distribution robustness, robustness on adversarial demonstrations, privacy, machine ethics, and fairness. Based on our evaluations, we discover previously unpublished vulnerabilities to trustworthiness threats. For instance, we find that GPT models can be easily misled to generate toxic and biased outputs and leak private information in both training data and conversation history. We also find that although GPT-4 is usually more trustworthy than GPT-3.5 on standard benchmarks, GPT-4 is more vulnerable given jailbreaking system or user prompts, potentially due to the reason that GPT-4 follows the (misleading) instructions more precisely. Our work illustrates a comprehensive trustworthiness evaluation of GPT models and sheds light on the trustworthiness gaps. Our benchmark is publicly available at https://decodingtrust.github.io/.
[ Hall C2 (level 1 gate 9 south of food court) ]
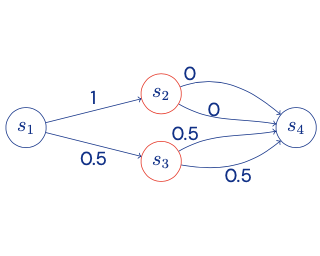
Abstract
[ Room R06-R09 (level 2) ]
Abstract
[ Room R06-R09 (level 2) ]
Abstract
[ Room R02-R05 (level 2) ]
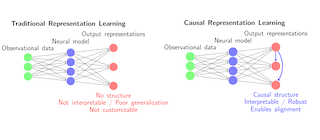
Abstract
We study the problem of learning causal representations from unknown, latent interventions in a general setting, where the latent distribution is Gaussian but the mixing function is completely general. We prove strong identifiability results given unknown single-node interventions, i.e., without having access to the intervention targets. This generalizes prior works which have focused on weaker classes, such as linear maps or paired counterfactual data. This is also the first instance of identifiability from non-paired interventions for deep neural network embeddings and general causal structures. Our proof relies on carefully uncovering the high-dimensional geometric structure present in the data distribution after a non-linear density transformation, which we capture by analyzing quadratic forms of precision matrices of the latent distributions. Finally, we propose a contrastive algorithm to identify the latent variables in practice and evaluate its performance on various tasks.
[ La Nouvelle Orleans Ballroom A-C (level 2) ]
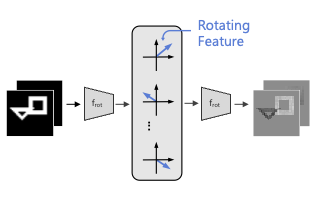
Abstract
The binding problem in human cognition, concerning how the brain represents and connects objects within a fixed network of neural connections, remains a subject of intense debate. Most machine learning efforts addressing this issue in an unsupervised setting have focused on slot-based methods, which may be limiting due to their discrete nature and difficulty to express uncertainty. Recently, the Complex AutoEncoder was proposed as an alternative that learns continuous and distributed object-centric representations. However, it is only applicable to simple toy data. In this paper, we present Rotating Features, a generalization of complex-valued features to higher dimensions, and a new evaluation procedure for extracting objects from distributed representations. Additionally, we show the applicability of our approach to pre-trained features. Together, these advancements enable us to scale distributed object-centric representations from simple toy to real-world data. We believe this work advances a new paradigm for addressing the binding problem in machine learning and has the potential to inspire further innovation in the field.
[ Hall C2 (level 1 gate 9 south of food court) ]

Abstract
[ Room R06-R09 (level 2) ]
Abstract
We propose a scheme for auditing differentially private machine learning systems with a single training run. This exploits the parallelism of being able to add or remove multiple training examples independently. We analyze this using the connection between differential privacy and statistical generalization, which avoids the cost of group privacy. Our auditing scheme requires minimal assumptions about the algorithm and can be applied in the black-box or white-box setting. We demonstrate the effectiveness of our framework by applying it to DP-SGD, where we can achieve meaningful empirical privacy lower bounds by training only one model. In contrast, standard methods would require training hundreds of models.
[ Room R02-R05 (level 2) ]
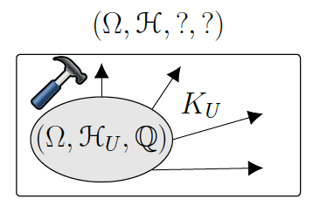
Abstract
Causality is a central concept in a wide range of research areas, yet there is still no universally agreed axiomatisation of causality. We view causality both as an extension of probability theory and as a study of what happens when one intervenes on a system, and argue in favour of taking Kolmogorov's measure-theoretic axiomatisation of probability as the starting point towards an axiomatisation of causality. To that end, we propose the notion of a causal space, consisting of a probability space along with a collection of transition probability kernels, called causal kernels, that encode the causal information of the space. Our proposed framework is not only rigorously grounded in measure theory, but it also sheds light on long-standing limitations of existing frameworks including, for example, cycles, latent variables and stochastic processes.
[ Hall C2 (level 1 gate 9 south of food court) ]
Abstract
We present QLoRA, an efficient finetuning approach that reduces memory usage enough to finetune a 65B parameter model on a single 48GB GPU while preserving full 16-bit finetuning task performance. QLoRA backpropagates gradients through a frozen, 4-bit quantized pretrained language model into Low Rank Adapters~(LoRA). Our best model family, which we name Guanaco, outperforms all previous openly released models on the Vicuna benchmark, reaching 99.3% of the performance level of ChatGPT while only requiring 24 hours of finetuning on a single GPU. QLoRA introduces a number of innovations to save memory without sacrificing performance: (a) 4-bit NormalFloat (NF4), a new data type that is information-theoretically optimal for normally distributed weights (b) Double Quantization to reduce the average memory footprint by quantizing the quantization constants, and (c) Paged Optimziers to manage memory spikes. We use QLoRA to finetune more than 1,000 models, providing a detailed analysis of instruction following and chatbot performance across 8 instruction datasets, multiple model types (LLaMA, T5), and model scales that would be infeasible to run with regular finetuning (e.g. 33B and 65B parameter models). Our results show that QLoRA finetuning on a small, high-quality dataset leads to state-of-the-art results, even when using smaller models than the …
[ La Nouvelle Orleans Ballroom A-C (level 2) ]
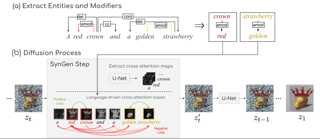
Abstract
Text-conditioned image generation models often generate incorrect associations between entities and their visual attributes. This reflects an impaired mapping between linguistic binding of entities and modifiers in the prompt and visual binding of the corresponding elements in the generated image. As one example, a query like ``a pink sunflower and a yellow flamingo'' may incorrectly produce an image of a yellow sunflower and a pink flamingo. To remedy this issue, we propose SynGen, an approach which first syntactically analyses the prompt to identify entities and their modifiers, and then uses a novel loss function that encourages the cross-attention maps to agree with the linguistic binding reflected by the syntax. Specifically, we encourage large overlap between attention maps of entities and their modifiers, and small overlap with other entities and modifier words. The loss is optimized during inference, without retraining or fine-tuning the model. Human evaluation on three datasets, including one new and challenging set, demonstrate significant improvements of SynGen compared with current state of the art methods. This work highlights how making use of sentence structure during inference can efficiently and substantially improve the faithfulness of text-to-image generation.
[ Room R02-R05 (level 2) ]
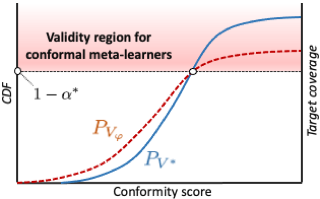
Abstract
We investigate the problem of machine learning-based (ML) predictive inference on individual treatment effects (ITEs). Previous work has focused primarily on developing ML-based “meta-learners” that can provide point estimates of the conditional average treatment effect (CATE)—these are model-agnostic approaches for combining intermediate nuisance estimates to produce estimates of CATE. In this paper, we develop conformal meta-learners, a general framework for issuing predictive intervals for ITEs by applying the standard conformal prediction (CP) procedure on top of CATE meta-learners. We focus on a broad class of meta-learners based on two-stage pseudo-outcome regression and develop a stochastic ordering framework to study their validity. We show that inference with conformal meta-learners is marginally valid if their (pseudo-outcome) conformity scores stochastically dominate “oracle” conformity scores evaluated on the unobserved ITEs. Additionally, we prove that commonly used CATE meta-learners, such as the doubly-robust learner, satisfy a model- and distribution-free stochastic (or convex) dominance condition, making their conformal inferences valid for practically-relevant levels of target coverage. Whereas existing procedures conduct inference on nuisance parameters (i.e., potential outcomes) via weighted CP, conformal meta-learners enable direct inference on the target parameter (ITE). Numerical experiments show that conformal meta-learners provide valid intervals with competitive efficiency while retaining the favorable …
[ Hall C2 (level 1 gate 9 south of food court) ]

Abstract
The current trend of scaling language models involves increasing both parameter count and training dataset size. Extrapolating this trend suggests that training dataset size may soon be limited by the amount of text data available on the internet. Motivated by this limit, we investigate scaling language models in data-constrained regimes. Specifically, we run a large set of experiments varying the extent of data repetition and compute budget, ranging up to 900 billion training tokens and 9 billion parameter models. We find that with constrained data for a fixed compute budget, training with up to 4 epochs of repeated data yields negligible changes to loss compared to having unique data. However, with more repetition, the value of adding compute eventually decays to zero. We propose and empirically validate a scaling law for compute optimality that accounts for the decreasing value of repeated tokens and excess parameters. Finally, we experiment with approaches mitigating data scarcity, including augmenting the training dataset with code data or removing commonly used filters. Models and datasets from our 400 training runs are freely available at https://github.com/huggingface/datablations.
[ Room R06-R09 (level 2) ]

Abstract
A private learner is trained on a sample of labeled points and generates a hypothesis that can be used for predicting the labels of newly sampled points while protecting the privacy of the training set [Kasiviswannathan et al., FOCS 2008]. Past research uncovered that private learners may need to exhibit significantly higher sample complexity than non-private learners as is the case of learning of one-dimensional threshold functions [Bun et al., FOCS 2015, Alon et al., STOC 2019].We explore prediction as an alternative to learning. A predictor answers a stream of classification queries instead of outputting a hypothesis. Earlier work has considered a private prediction model with a single classification query [Dwork and Feldman, COLT 2018]. We observe that when answering a stream of queries, a predictor must modify the hypothesis it uses over time, and in a manner that cannot rely solely on the training set.We introduce {\em private everlasting prediction} taking into account the privacy of both the training set {\em and} the (adaptively chosen) queries made to the predictor. We then present a generic construction of private everlasting predictors in the PAC model.The sample complexity of the initial training sample in our construction is quadratic (up to polylog …
[ La Nouvelle Orleans Ballroom A-C (level 2) ]
Abstract
We tackle the problems of latent variables identification and "out-of-support'' image generation in representation learning. We show that both are possible for a class of decoders that we call additive, which are reminiscent of decoders used for object-centric representation learning (OCRL) and well suited for images that can be decomposed as a sum of object-specific images. We provide conditions under which exactly solving the reconstruction problem using an additive decoder is guaranteed to identify the blocks of latent variables up to permutation and block-wise invertible transformations. This guarantee relies only on very weak assumptions about the distribution of the latent factors, which might present statistical dependencies and have an almost arbitrarily shaped support. Our result provides a new setting where nonlinear independent component analysis (ICA) is possible and adds to our theoretical understanding of OCRL methods. We also show theoretically that additive decoders can generate novel images by recombining observed factors of variations in novel ways, an ability we refer to as Cartesian-product extrapolation. We show empirically that additivity is crucial for both identifiability and extrapolation on simulated data.
[ Room R06-R09 (level 2) ]
Abstract
[ Hall C2 (level 1 gate 9 south of food court) ]
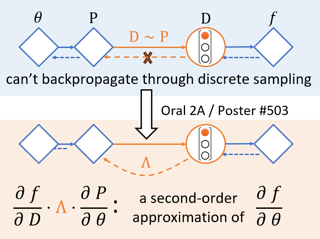
Abstract
Backpropagation, the cornerstone of deep learning, is limited to computing gradients for continuous variables. This limitation poses challenges for problems involving discrete latent variables. To address this issue, we propose a novel approach to approximate the gradient of parameters involved in generating discrete latent variables. First, we examine the widely used Straight-Through (ST) heuristic and demonstrate that it works as a first-order approximation of the gradient. Guided by our findings, we propose ReinMax, which achieves second-order accuracy by integrating Heun’s method, a second-order numerical method for solving ODEs. ReinMax does not require Hessian or other second-order derivatives, thus having negligible computation overheads. Extensive experimental results on various tasks demonstrate the superiority of ReinMax over the state of the art.
[ La Nouvelle Orleans Ballroom A-C (level 2) ]
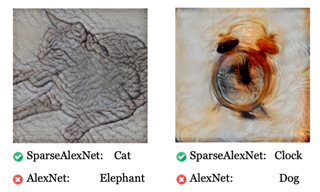
Abstract
Current deep-learning models for object recognition are known to be heavily biased toward texture. In contrast, human visual systems are known to be biased toward shape and structure. What could be the design principles in human visual systems that led to this difference? How could we introduce more shape bias into the deep learning models? In this paper, we report that sparse coding, a ubiquitous principle in the brain, can in itself introduce shape bias into the network. We found that enforcing the sparse coding constraint using a non-differential Top-K operation can lead to the emergence of structural encoding in neurons in convolutional neural networks, resulting in a smooth decomposition of objects into parts and subparts and endowing the networks with shape bias. We demonstrated this emergence of shape bias and its functional benefits for different network structures with various datasets. For object recognition convolutional neural networks, the shape bias leads to greater robustness against style and pattern change distraction. For the image synthesis generative adversary networks, the emerged shape bias leads to more coherent and decomposable structures in the synthesized images. Ablation studies suggest that sparse codes tend to encode structures, whereas the more distributed codes tend to favor …
[ Room R02-R05 (level 2) ]
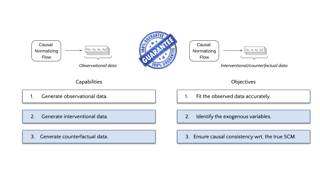
Abstract
In this work, we deepen on the use of normalizing flows for causal reasoning. Specifically, we first leverage recent results on non-linear ICA to show that causal models are identifiable from observational data given a causal ordering, and thus can be recovered using autoregressive normalizing flows (NFs). Second, we analyze different design and learning choices for causal normalizing flows to capture the underlying causal data-generating process. Third, we describe how to implement the do-operator in causal NFs, and thus, how to answer interventional and counterfactual questions. Finally, in our experiments, we validate our design and training choices through a comprehensive ablation study; compare causal NFs to other approaches for approximating causal models; and empirically demonstrate that causal NFs can be used to address real-world problems—where the presence of mixed discrete-continuous data and partial knowledge on the causal graph is the norm. The code for this work can be found at https://github.com/psanch21/causal-flows.
[ Hall C2 (level 1 gate 9 south of food court) ]

Abstract
A long standing goal in neuroscience has been to elucidate the functional organization of the brain. Within higher visual cortex, functional accounts have remained relatively coarse, focusing on regions of interest (ROIs) and taking the form of selectivity for broad categories such as faces, places, bodies, food, or words. Because the identification of such ROIs has typically relied on manually assembled stimulus sets consisting of isolated objects in non-ecological contexts, exploring functional organization without robust a priori hypotheses has been challenging. To overcome these limitations, we introduce a data-driven approach in which we synthesize images predicted to activate a given brain region using paired natural images and fMRI recordings, bypassing the need for category-specific stimuli. Our approach -- Brain Diffusion for Visual Exploration ("BrainDiVE") -- builds on recent generative methods by combining large-scale diffusion models with brain-guided image synthesis. Validating our method, we demonstrate the ability to synthesize preferred images with appropriate semantic specificity for well-characterized category-selective ROIs. We then show that BrainDiVE can characterize differences between ROIs selective for the same high-level category. Finally we identify novel functional subdivisions within these ROIs, validated with behavioral data. These results advance our understanding of the fine-grained functional organization of human visual …
[ La Nouvelle Orleans Ballroom A-C (level 2) ]
Abstract
Integrating large language models (LLMs) with various tools has led to increased attention in the field. Existing approaches either involve fine-tuning the LLM, which is both computationally costly and limited to a fixed set of tools, or prompting LLMs by in-context tool demonstrations. Although the latter method offers adaptability to new tools, it struggles with the inherent context length constraint of LLMs when many new tools are presented, and mastering a new set of tools with few-shot examples remains challenging, resulting in suboptimal performance. To address these limitations, we propose a novel solution, named ToolkenGPT, wherein LLMs effectively learn to master tools as predicting tokens through tool embeddings for solving complex tasks. In this framework, each tool is transformed into vector embeddings and plugged into the language model head. Once the function is triggered during text generation, the LLM enters a special function mode to execute the tool calls. Our experiments show that function embeddings effectively help LLMs understand tool use and improve on several tasks, including numerical reasoning, knowledge-based question answering and embodied decision-making.
[ Room R06-R09 (level 2) ]
Abstract
To achieve the highest perceptual quality, state-of-the-art diffusion models are optimized with objectives that typically look very different from the maximum likelihood and the Evidence Lower Bound (ELBO) objectives. In this work, we reveal that diffusion model objectives are actually closely related to the ELBO.Specifically, we show that all commonly used diffusion model objectives equate to a weighted integral of ELBOs over different noise levels, where the weighting depends on the specific objective used. Under the condition of monotonic weighting, the connection is even closer: the diffusion objective then equals the ELBO, combined with simple data augmentation, namely Gaussian noise perturbation. We show that this condition holds for a number of state-of-the-art diffusion models. In experiments, we explore new monotonic weightings and demonstrate their effectiveness, achieving state-of-the-art FID scores on the high-resolution ImageNet benchmark.
[ Room R06-R09 (level 2) ]
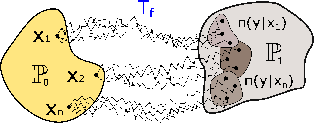
Abstract
We propose a novel neural algorithm for the fundamental problem of computing the entropic optimal transport (EOT) plan between probability distributions which are accessible by samples. Our algorithm is based on the saddle point reformulation of the dynamic version of EOT which is known as the Schrödinger Bridge problem. In contrast to the prior methods for large-scale EOT, our algorithm is end-to-end and consists of a single learning step, has fast inference procedure, and allows handling small values of the entropy regularization coefficient which is of particular importance in some applied problems. Empirically, we show the performance of the method on several large-scale EOT tasks. The code for the ENOT solver can be found at https://github.com/ngushchin/EntropicNeuralOptimalTransport
[ Hall C2 (level 1 gate 9 south of food court) ]

Abstract
Reconstructing human vision from brain activities has been an appealing task that helps to understand our cognitive process. Even though recent research has seen great success in reconstructing static images from non-invasive brain recordings, work on recovering continuous visual experiences in the form of videos is limited. In this work, we propose Mind-Video that learns spatiotemporal information from continuous fMRI data of the cerebral cortex progressively through masked brain modeling, multimodal contrastive learning with spatiotemporal attention, and co-training with an augmented Stable Diffusion model that incorporates network temporal inflation. We show that high-quality videos of arbitrary frame rates can be reconstructed with Mind-Video using adversarial guidance. The recovered videos were evaluated with various semantic and pixel-level metrics. We achieved an average accuracy of 85% in semantic classification tasks and 0.19 in structural similarity index (SSIM), outperforming the previous state-of-the-art by 45%. We also show that our model is biologically plausible and interpretable, reflecting established physiological processes.
[ La Nouvelle Orleans Ballroom A-C (level 2) ]

Abstract
Language models (LMs) exhibit remarkable abilities to solve new tasks from just a few examples or textual instructions, especially at scale. They also, paradoxically, struggle with basic functionality, such as arithmetic or factual lookup, where much simpler and smaller specialized models excel. In this paper, we show that LMs can teach themselves to use external tools via simple APIs and achieve the best of both worlds. We introduce Toolformer, a model trained to decide which APIs to call, when to call them, what arguments to pass, and how to best incorporate the results into future token prediction. This is done in a self-supervised way, requiring nothing more than a handful of demonstrations for each API. We incorporate a range of tools, including a calculator, a Q&A system, a search engine, a translation system, and a calendar. Toolformer achieves substantially improved zero-shot performance across a variety of downstream tasks, often competitive with much larger models, without sacrificing its core language modeling abilities.
[ La Nouvelle Orleans Ballroom A-C (level 2) ]
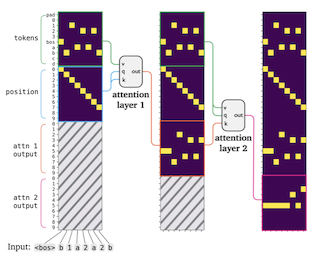
Abstract
Recent research in mechanistic interpretability has attempted to reverse-engineer Transformer models by carefully inspecting network weights and activations. However, these approaches require considerable manual effort and still fall short of providing complete, faithful descriptions of the underlying algorithms. In this work, we introduce a procedure for training Transformers that are mechanistically interpretable by design. We build on RASP [Weiss et al., 2021], a programming language that can be compiled into Transformer weights. Instead of compiling human-written programs into Transformers, we design a modified Transformer that can be trained using gradient-based optimization and then automatically converted into a discrete, human-readable program. We refer to these models as Transformer Programs. To validate our approach, we learn Transformer Programs for a variety of problems, including an in-context learning task, a suite of algorithmic problems (e.g. sorting, recognizing Dyck languages), and NLP tasks including named entity recognition and text classification. The Transformer Programs can automatically find reasonable solutions, performing on par with standard Transformers of comparable size; and, more importantly, they are easy to interpret. To demonstrate these advantages, we convert Transformers into Python programs and use off-the-shelf code analysis tools to debug model errors and identify the “circuits” used to solve different sub-problems. …
[ Hall C2 (level 1 gate 9 south of food court) ]
Abstract
A core tension in models of concept learning is that the model must carefully balance the tractability of inference against the expressivity of the hypothesis class. Humans, however, can efficiently learn a broad range of concepts. We introduce a model of inductive learning that seeks to be human-like in that sense.It implements a Bayesian reasoning process where a language model first proposes candidate hypotheses expressed in natural language, which are then re-weighed by a prior and a likelihood.By estimating the prior from human data, we can predict human judgments on learning problems involving numbers and sets, spanning concepts that are generative, discriminative, propositional, and higher-order.
[ Room R06-R09 (level 2) ]

Abstract
Nature evolves creatures with a high complexity of morphological and behavioral intelligence, meanwhile computational methods lag in approaching that diversity and efficacy. Co-optimization of artificial creatures' morphology and control in silico shows promise for applications in physical soft robotics and virtual character creation; such approaches, however, require developing new learning algorithms that can reason about function atop pure structure. In this paper, we present DiffuseBot, a physics-augmented diffusion model that generates soft robot morphologies capable of excelling in a wide spectrum of tasks. \name bridges the gap between virtually generated content and physical utility by (i) augmenting the diffusion process with a physical dynamical simulation which provides a certificate of performance, and (ii) introducing a co-design procedure that jointly optimizes physical design and control by leveraging information about physical sensitivities from differentiable simulation. We showcase a range of simulated and fabricated robots along with their capabilities. Check our website: https://diffusebot.github.io/
[ La Nouvelle Orleans Ballroom A-C (level 2) ]

Abstract
We introduce Mesogeos, a large-scale multi-purpose dataset for wildfire modeling in the Mediterranean. Mesogeos integrates variables representing wildfire drivers (meteorology, vegetation, human activity) and historical records of wildfire ignitions and burned areas for 17 years (2006-2022). It is designed as a cloud-friendly spatio-temporal dataset, namely a datacube, harmonizing all variables in a grid of 1km x 1km x 1-day resolution. The datacube structure offers opportunities to assess machine learning (ML) usage in various wildfire modeling tasks. We extract two ML-ready datasets that establish distinct tracks to demonstrate this potential: (1) short-term wildfire danger forecasting and (2) final burned area estimation given the point of ignition. We define appropriate metrics and baselines to evaluate the performance of models in each track. By publishing the datacube, along with the code to create the ML datasets and models, we encourage the community to foster the implementation of additional tracks for mitigating the increasing threat of wildfires in the Mediterranean.
[ Room R06-R09 (level 2) ]
Abstract
Humans have a powerful and mysterious capacity to reason. Working through a set of mental steps enables us to make inferences we would not be capable of making directly even though we get no additional data from the world. Similarly, when large language models generate intermediate steps (a chain of thought) before answering a question, they often produce better answers than they would directly. We investigate why and how chain-of-thought reasoning is useful in language models, testing the hypothesis that reasoning is effective when training data consists of overlapping local clusters of variables that influence each other strongly. These training conditions enable the chaining of accurate local inferences to estimate relationships between variables that were not seen together in training. We prove that there will exist a "reasoning gap", where reasoning through intermediate variables reduces bias, for the simple case of an autoregressive density estimator trained on local samples from a chain-structured probabilistic model. We then test our hypothesis experimentally in more complex models, training an autoregressive language model on samples from Bayes nets but only including a subset of variables in each sample. We test language models’ ability to match conditional probabilities with and without intermediate reasoning steps, finding …
[ Hall C2 (level 1 gate 9 south of food court) ]

Abstract
[ Hall C2 (level 1 gate 9 south of food court) ]
Abstract
[ Room R06-R09 (level 2) ]
Abstract
Language models are increasingly being deployed for general problem solving across a wide range of tasks, but are still confined to token-level, left-to-right decision-making processes during inference. This means they can fall short in tasks that require exploration, strategic lookahead, or where initial decisions play a pivotal role. To surmount these challenges, we introduce a new framework for language model inference, Tree of Thoughts (ToT), which generalizes over the popular Chain of Thought approach to prompting language models, and enables exploration over coherent units of text (thoughts) that serve as intermediate steps toward problem solving. ToT allows LMs to perform deliberate decision making by considering multiple different reasoning paths and self-evaluating choices to decide the next course of action, as well as looking ahead or backtracking when necessary to make global choices.Our experiments show that ToT significantly enhances language models’ problem-solving abilities on three novel tasks requiring non-trivial planning or search: Game of 24, Creative Writing, and Mini Crosswords. For instance, in Game of 24, while GPT-4 with chain-of-thought prompting only solved 4\% of tasks, our method achieved a success rate of 74\%. Code repo with all prompts: https://github.com/princeton-nlp/tree-of-thought-llm.
[ La Nouvelle Orleans Ballroom A-C (level 2) ]
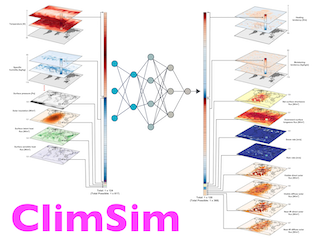
Abstract
Modern climate projections lack adequate spatial and temporal resolution due to computational constraints. A consequence is inaccurate and imprecise predictions of critical processes such as storms. Hybrid methods that combine physics with machine learning (ML) have introduced a new generation of higher fidelity climate simulators that can sidestep Moore's Law by outsourcing compute-hungry, short, high-resolution simulations to ML emulators. However, this hybrid ML-physics simulation approach requires domain-specific treatment and has been inaccessible to ML experts because of lack of training data and relevant, easy-to-use workflows. We present ClimSim, the largest-ever dataset designed for hybrid ML-physics research. It comprises multi-scale climate simulations, developed by a consortium of climate scientists and ML researchers. It consists of 5.7 billion pairs of multivariate input and output vectors that isolate the influence of locally-nested, high-resolution, high-fidelity physics on a host climate simulator's macro-scale physical state.The dataset is global in coverage, spans multiple years at high sampling frequency, and is designed such that resulting emulators are compatible with downstream coupling into operational climate simulators. We implement a range of deterministic and stochastic regression baselines to highlight the ML challenges and their scoring. The data (https://huggingface.co/datasets/LEAP/ClimSim_high-res) and code (https://leap-stc.github.io/ClimSim) are released openly to support the development of …
[ La Nouvelle Orleans Ballroom A-C (level 2) ]
Abstract
[ Room R06-R09 (level 2) ]
Abstract
Neural sequence models based on the transformer architecture have demonstrated remarkable \emph{in-context learning} (ICL) abilities, where they can perform new tasks when prompted with training and test examples, without any parameter update to the model. This work first provides a comprehensive statistical theory for transformers to perform ICL. Concretely, we show that transformers can implement a broad class of standard machine learning algorithms in context, such as least squares, ridge regression, Lasso, learning generalized linear models, and gradient descent on two-layer neural networks, with near-optimal predictive power on various in-context data distributions. Using an efficient implementation of in-context gradient descent as the underlying mechanism, our transformer constructions admit mild size bounds, and can be learned with polynomially many pretraining sequences. Building on these ``base'' ICL algorithms, intriguingly, we show that transformers can implement more complex ICL procedures involving \emph{in-context algorithm selection}, akin to what a statistician can do in real life---A \emph{single} transformer can adaptively select different base ICL algorithms---or even perform qualitatively different tasks---on different input sequences, without any explicit prompting of the right algorithm or task. We both establish this in theory by explicit constructions, and also observe this phenomenon experimentally. In theory, we construct two general mechanisms …
[ Hall C2 (level 1 gate 9 south of food court) ]

Abstract
Nonlinear independent component analysis (ICA) aims to uncover the true latent sources from their observable nonlinear mixtures. Despite its significance, the identifiability of nonlinear ICA is known to be impossible without additional assumptions. Recent advances have proposed conditions on the connective structure from sources to observed variables, known as Structural Sparsity, to achieve identifiability in an unsupervised manner. However, the sparsity constraint may not hold universally for all sources in practice. Furthermore, the assumptions of bijectivity of the mixing process and independence among all sources, which arise from the setting of ICA, may also be violated in many real-world scenarios. To address these limitations and generalize nonlinear ICA, we propose a set of new identifiability results in the general settings of undercompleteness, partial sparsity and source dependence, and flexible grouping structures. Specifically, we prove identifiability when there are more observed variables than sources (undercomplete), and when certain sparsity and/or source independence assumptions are not met for some changing sources. Moreover, we show that even in cases with flexible grouping structures (e.g., part of the sources can be divided into irreducible independent groups with various sizes), appropriate identifiability results can also be established. Theoretical claims are supported empirically on both synthetic …
[ Room R06-R09 (level 2) ]
Abstract
Recent studies have discovered that Chain-of-Thought prompting (CoT) can dramatically improve the performance of Large Language Models (LLMs), particularly when dealing with complex tasks involving mathematics or reasoning. Despite the enormous empirical success, the underlying mechanisms behind CoT and how it unlocks the potential of LLMs remain elusive. In this paper, we take a first step towards theoretically answering these questions. Specifically, we examine the expressivity of LLMs with CoT in solving fundamental mathematical and decision-making problems. By using circuit complexity theory, we first give impossibility results showing that bounded-depth Transformers are unable to directly produce correct answers for basic arithmetic/equation tasks unless the model size grows super-polynomially with respect to the input length. In contrast, we then prove by construction that autoregressive Transformers of constant size suffice to solve both tasks by generating CoT derivations using a commonly used math language format. Moreover, we show LLMs with CoT can handle a general class of decision-making problems known as Dynamic Programming, thus justifying their power in tackling complex real-world tasks. Finally, an extensive set of experiments show that, while Transformers always fail to directly predict the answers, they can consistently learn to generate correct solutions step-by-step given sufficient CoT demonstrations.
[ Hall C2 (level 1 gate 9 south of food court) ]

Abstract
Fine-tuning language models (LMs) has yielded success on diverse downstream tasks, but as LMs grow in size, backpropagation requires a prohibitively large amount of memory. Zeroth-order (ZO) methods can in principle estimate gradients using only two forward passes but are theorized to be catastrophically slow for optimizing large models. In this work, we propose a memory-efficient zerothorder optimizer (MeZO), adapting the classical ZO-SGD method to operate in-place, thereby fine-tuning LMs with the same memory footprint as inference. For example, with a single A100 80GB GPU, MeZO can train a 30-billion parameter model, whereas fine-tuning with backpropagation can train only a 2.7B LM with the same budget. We conduct comprehensive experiments across model types (masked and autoregressive LMs), model scales (up to 66B), and downstream tasks (classification, multiple-choice, and generation). Our results demonstrate that (1) MeZO significantly outperforms in-context learning and linear probing; (2) MeZO achieves comparable performance to fine-tuning with backpropagation across multiple tasks, with up to 12× memory reduction and up to 2× GPU-hour reduction in our implementation; (3) MeZO is compatible with both full-parameter and parameter-efficient tuning techniques such as LoRA and prefix tuning; (4) MeZO can effectively optimize non-differentiable objectives (e.g., maximizing accuracy or F1). We support …
[ La Nouvelle Orleans Ballroom A-C (level 2) ]
Abstract
The MineRL BASALT competition has served to catalyze advances in learning from human feedback through four hard-to-specify tasks in Minecraft, such as create and photograph a waterfall. Given the completion of two years of BASALT competitions, we offer to the community a formalized benchmark through the BASALT Evaluation and Demonstrations Dataset (BEDD), which serves as a resource for algorithm development and performance assessment. BEDD consists of a collection of 26 million image-action pairs from nearly 14,000 videos of human players completing the BASALT tasks in Minecraft. It also includes over 3,000 dense pairwise human evaluations of human and algorithmic agents. These comparisons serve as a fixed, preliminary leaderboard for evaluating newly-developed algorithms. To enable this comparison, we present a streamlined codebase for benchmarking new algorithms against the leaderboard. In addition to presenting these datasets, we conduct a detailed analysis of the data from both datasets to guide algorithm development and evaluation. The released code and data are available at https://github.com/minerllabs/basalt-benchmark.
[ Room R06-R09 (level 2) ]
Abstract
Instruction tuning large language models (LLMs) using machine-generated instruction-following data has been shown to improve zero-shot capabilities on new tasks, but the idea is less explored in the multimodal field. We present the first attempt to use language-only GPT-4 to generate multimodal language-image instruction-following data. By instruction tuning on such generated data, we introduce LLaVA: Large Language and Vision Assistant, an end-to-end trained large multimodal model that connects a vision encoder and an LLM for general-purpose visual and language understanding. To facilitate future research on visual instruction following, we construct two evaluation benchmarks with diverse and challenging application-oriented tasks. Our experiments show that LLaVA demonstrates impressive multimodal chat abilities, sometimes exhibiting the behaviors of multimodal GPT-4 on unseen images/instructions, and yields a 85.1% relative score compared with GPT-4 on a synthetic multimodal instruction-following dataset. When fine-tuned on Science QA, the synergy of LLaVA and GPT-4 achieves a new state-of-the-art accuracy of 92.53%. We make GPT-4 generated visual instruction tuning data, our model, and code publicly available.
[ La Nouvelle Orleans Ballroom A-C (level 2) ]
Abstract
Model distillation is frequently proposed as a technique to reduce the privacy leakage of machine learning. These empirical privacy defenses rely on the intuition that distilled student'' models protect the privacy of training data, as they only interact with this data indirectly through ateacher'' model. In this work, we design membership inference attacks to systematically study the privacy provided by knowledge distillation to both the teacher and student training sets. Our new attacks show that distillation alone provides only limited privacy across a number of domains. We explain the success of our attacks on distillation by showing that membership inference attacks on a private dataset can succeed even if the target model is never queried on any actual training points, but only on inputs whose predictions are highly influenced by training data. Finally, we show that our attacks are strongest when student and teacher sets are similar, or when the attacker can poison the teacher set.
[ Room R02-R05 (level 2) ]
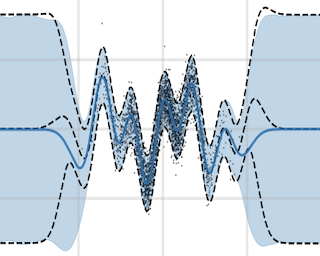
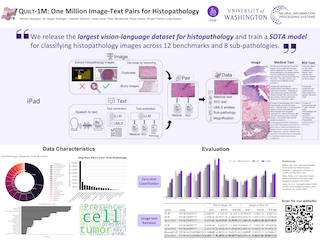
Abstract
Gaussian processes are a powerful framework for quantifying uncertainty and for sequential decision-making but are limited by the requirement of solving linear systems. In general, this has a cubic cost in dataset size and is sensitive to conditioning. We explore stochastic gradient algorithms as a computationally efficient method of approximately solving these linear systems: we develop low-variance optimization objectives for sampling from the posterior and extend these to inducing points. Counterintuitively, stochastic gradient descent often produces accurate predictions, even in cases where it does not converge quickly to the optimum. We explain this through a spectral characterization of the implicit bias from non-convergence. We show that stochastic gradient descent produces predictive distributions close to the true posterior both in regions with sufficient data coverage, and in regions sufficiently far away from the data. Experimentally, stochastic gradient descent achieves state-of-the-art performance on sufficiently large-scale or ill-conditioned regression tasks. Its uncertainty estimates match the performance of significantly more expensive baselines on a large-scale Bayesian~optimization~task.
[ Hall C2 (level 1 gate 9 south of food court) ]
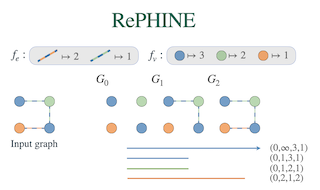
Abstract
Representational limits of message-passing graph neural networks (MP-GNNs), e.g., in terms of the Weisfeiler-Leman (WL) test for isomorphism, are well understood. Augmenting these graph models with topological features via persistent homology (PH) has gained prominence, but identifying the class of attributed graphs that PH can recognize remains open. We introduce a novel concept of color-separating sets to provide a complete resolution to this important problem. Specifically, we establish the necessary and sufficient conditions for distinguishing graphs based on the persistence of their connected components, obtained from filter functions on vertex and edge colors. Our constructions expose the limits of vertex- and edge-level PH, proving that neither category subsumes the other. Leveraging these theoretical insights, we propose RePHINE for learning topological features on graphs. RePHINE efficiently combines vertex- and edge-level PH, achieving a scheme that is provably more powerful than both. Integrating RePHINE into MP-GNNs boosts their expressive power, resulting in gains over standard PH on several benchmarks for graph classification.
[ Room R02-R05 (level 2) ]
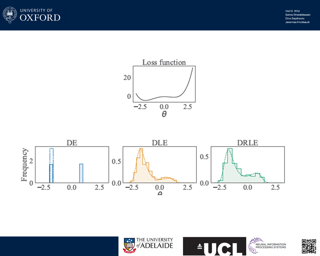
Abstract
We establish the first mathematically rigorous link between Bayesian, variational Bayesian, and ensemble methods. A key step towards this it to reformulate the non-convex optimisation problem typically encountered in deep learning as a convex optimisation in the space of probability measures. On a technical level, our contribution amounts to studying generalised variational inference through the lense of Wasserstein gradient flows. The result is a unified theory of various seemingly disconnected approaches that are commonly used for uncertainty quantification in deep learning---including deep ensembles and (variational) Bayesian methods. This offers a fresh perspective on the reasons behind the success of deep ensembles over procedures based on parameterised variational inference, and allows the derivation of new ensembling schemes with convergence guarantees. We showcase this by proposing a family of interacting deep ensembles with direct parallels to the interactions of particle systems in thermodynamics, and use our theory to prove the convergence of these algorithms to a well-defined global minimiser on the space of probability measures.
[ Hall C2 (level 1 gate 9 south of food court) ]

Abstract
[ La Nouvelle Orleans Ballroom A-C (level 2) ]
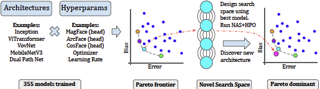
Abstract
Face recognition systems are widely deployed in safety-critical applications, including law enforcement, yet they exhibit bias across a range of socio-demographic dimensions, such as gender and race. Conventional wisdom dictates that model biases arise from biased training data. As a consequence, previous works on bias mitigation largely focused on pre-processing the training data, adding penalties to prevent bias from effecting the model during training, or post-processing predictions to debias them, yet these approaches have shown limited success on hard problems such as face recognition. In our work, we discover that biases are actually inherent to neural network architectures themselves. Following this reframing, we conduct the first neural architecture search for fairness, jointly with a search for hyperparameters. Our search outputs a suite of models which Pareto-dominate all other high-performance architectures and existing bias mitigation methods in terms of accuracy and fairness, often by large margins, on the two most widely used datasets for face identification, CelebA and VGGFace2. Furthermore, these models generalize to other datasets and sensitive attributes. We release our code, models and raw data files at https://github.com/dooleys/FR-NAS.
[ Room R06-R09 (level 2) ]
Abstract
First-person video highlights a camera-wearer's activities in the context of their persistent environment. However, current video understanding approaches reason over visual features from short video clips that are detached from the underlying physical space and capture only what is immediately visible. To facilitate human-centric environment understanding, we present an approach that links egocentric video and the environment by learning representations that are predictive of the camera-wearer's (potentially unseen) local surroundings. We train such models using videos from agents in simulated 3D environments where the environment is fully observable, and test them on human-captured real-world videos from unseen environments. On two human-centric video tasks, we show that models equipped with our environment-aware features consistently outperform their counterparts with traditional clip features. Moreover, despite being trained exclusively on simulated videos, our approach successfully handles real-world videos from HouseTours and Ego4D, and achieves state-of-the-art results on the Ego4D NLQ challenge.
[ Room R02-R05 (level 2) ]
Abstract
[ Hall C2 (level 1 gate 9 south of food court) ]
Abstract
This work studies the evaluation of explaining graph neural networks (GNNs), which is crucial to the credibility of post-hoc explainability in practical usage. Conventional evaluation metrics, and even explanation methods -- which mainly follow the paradigm of feeding the explanatory subgraph and measuring output difference -- always suffer from the notorious out-of-distribution (OOD) issue. In this work, we endeavor to confront the issue by introducing a novel evaluation metric, termed OOD-resistant Adversarial Robustness (OAR). Specifically, we draw inspiration from the notion of adversarial robustness and evaluate post-hoc explanation subgraphs by calculating their robustness under attack. On top of that, an elaborate OOD reweighting block is inserted into the pipeline to confine the evaluation process to the original data distribution. For applications involving large datasets, we further devise a Simplified version of OAR (SimOAR), which achieves a significant improvement in computational efficiency at the cost of a small amount of performance. Extensive empirical studies validate the effectiveness of our OAR and SimOAR.
[ Room R06-R09 (level 2) ]
Abstract
Multimodal datasets are a critical component in recent breakthroughs such as CLIP, Stable Diffusion and GPT-4, yet their design does not receive the same research attention as model architectures or training algorithms. To address this shortcoming in the machine learning ecosystem, we introduce DataComp, a testbed for dataset experiments centered around a new candidate pool of 12.8 billion image-text pairs from Common Crawl. Participants in our benchmark design new filtering techniques or curate new data sources and then evaluate their new dataset by running our standardized CLIP training code and testing the resulting model on 38 downstream test sets. Our benchmark consists of multiple compute scales spanning four orders of magnitude, which enables the study of scaling trends and makes the benchmark accessible to researchers with varying resources. Our baseline experiments show that the DataComp workflow leads to better training sets. Our best baseline, DataComp-1B, enables training a CLIP ViT-L/14 from scratch to 79.2% zero-shot accuracy on ImageNet, outperforming OpenAI's CLIP ViT-L/14 by 3.7 percentage points while using the same training procedure and compute. We release \datanet and all accompanying code at www.datacomp.ai.
[ La Nouvelle Orleans Ballroom A-C (level 2) ]

Abstract
Human-centric computer vision (HCCV) data curation practices often neglect privacy and bias concerns, leading to dataset retractions and unfair models. HCCV datasets constructed through nonconsensual web scraping lack crucial metadata for comprehensive fairness and robustness evaluations. Current remedies are post hoc, lack persuasive justification for adoption, or fail to provide proper contextualization for appropriate application. Our research focuses on proactive, domain-specific recommendations, covering purpose, privacy and consent, and diversity, for curating HCCV evaluation datasets, addressing privacy and bias concerns. We adopt an ante hoc reflective perspective, drawing from current practices, guidelines, dataset withdrawals, and audits, to inform our considerations and recommendations.
[ Hall C2 (level 1 gate 9 south of food court) ]
Abstract
Recent work claims that large language models display \textit{emergent abilities}, abilities not present in smaller-scale models that are present in larger-scale models.What makes emergent abilities intriguing is two-fold: their \textit{sharpness}, transitioning seemingly instantaneously from not present to present, and their \textit{unpredictability}, appearing at seemingly unforeseeable model scales.Here, we present an alternative explanation for emergent abilities: that for a particular task and model family, when analyzing fixed model outputs, emergent abilities appear due the researcher’s choice of metric rather than due to fundamental changes in model behavior with scale. Specifically, nonlinear or discontinuous metrics produce apparent emergent abilities, whereas linear or continuous metrics produce smooth, continuous, predictable changes in model performance.We present our alternative explanation in a simple mathematical model, then test it in three complementary ways: we (1) make, test and confirm three predictions on the effect of metric choice using the InstructGPT/GPT-3 family on tasks with claimed emergent abilities, (2) make, test and confirm two predictions about metric choices in a meta-analysis of emergent abilities on BIG-Bench; and (3) show how to choose metrics to produce never-before-seen seemingly emergent abilities in multiple vision tasks across diverse deep networks.Via all three analyses, we provide evidence that alleged emergent abilities evaporate …
[ La Nouvelle Orleans Ballroom A-C (level 2) ]
Abstract
[ Room R06-R09 (level 2) ]
Abstract
In this work, we aim to characterize the statistical complexity of realizable regression both in the PAC learning setting and the online learning setting. Previous work had established the sufficiency of finiteness of the fat shattering dimension for PAC learnability and the necessity of finiteness of the scaled Natarajan dimension, but little progress had been made towards a more complete characterization since the work of Simon 1997 (SICOMP '97). To this end, we first introduce a minimax instance optimal learner for realizable regression and propose a novel dimension that both qualitatively and quantitatively characterizes which classes of real-valued predictors are learnable. We then identify a combinatorial dimension related to the graph dimension that characterizes ERM learnability in the realizable setting. Finally, we establish a necessary condition for learnability based on a combinatorial dimension related to the DS dimension, and conjecture that it may also be sufficient in this context. Additionally, in the context of online learning we provide a dimension that characterizes the minimax instance optimal cumulative loss up to a constant factor and design an optimal online learner for realizable regression, thus resolving an open question raised by Daskalakis and Golowich in STOC '22.
[ Room R02-R05 (level 2) ]
Abstract
Establishing correspondence between images or scenes is a significant challenge in computer vision, especially given occlusions, viewpoint changes, and varying object appearances. In this paper, we present Siamese Masked Autoencoders (SiamMAE), a simple extension of Masked Autoencoders (MAE) for learning visual correspondence from videos. SiamMAE operates on pairs of randomly sampled video frames and asymmetrically masks them. These frames are processed independently by an encoder network, and a decoder composed of a sequence of cross-attention layers is tasked with predicting the missing patches in the future frame. By masking a large fraction (95%) of patches in the future frame while leaving the past frame unchanged, SiamMAE encourages the network to focus on object motion and learn object-centric representations. Despite its conceptual simplicity, features learned via SiamMAE outperform state-of-the-art self-supervised methods on video object segmentation, pose keypoint propagation, and semantic part propagation tasks. SiamMAE achieves competitive results without relying on data augmentation, handcrafted tracking-based pretext tasks, or other techniques to prevent representational collapse.
[ Room R02-R05 (level 2) ]
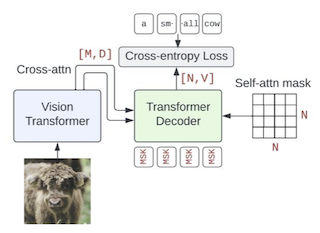
Abstract
Contrastive pretraining on image-text pairs from the web is one of the most popular large-scale pretraining strategies for vision backbones, especially in the context of large multimodal models. At the same time, image captioning on this type of data is commonly considered an inferior pretraining strategy. In this paper, we perform a fair comparison of these two pretraining strategies, carefully matching training data, compute, and model capacity. Using a standard encoder-decoder transformer, we find that captioning alone is surprisingly effective: on classification tasks, captioning produces vision encoders competitive with contrastively pretrained encoders, while surpassing them on vision & language tasks. We further analyze the effect of the model architecture and scale, as well as the pretraining data on the representation quality, and find that captioning exhibits the same or better scaling behavior along these axes. Overall our results show that plain image captioning is a more powerful pretraining strategy than was previously believed. Code is available at https://github.com/google-research/big_vision.
[ La Nouvelle Orleans Ballroom A-C (level 2) ]

Abstract
Deep reinforcement learning (RL) works impressively in some environments and fails catastrophically in others. Ideally, RL theory should be able to provide an understanding of why this is, i.e. bounds predictive of practical performance. Unfortunately, current theory does not quite have this ability. We compare standard deep RL algorithms to prior sample complexity bounds by introducing a new dataset, BRIDGE. It consists of 155 MDPs from common deep RL benchmarks, along with their corresponding tabular representations, which enables us to exactly compute instance-dependent bounds. We find that prior bounds do not correlate well with when deep RL succeeds vs. fails, but discover a surprising property that does. When actions with the highest Q-values under the random policy also have the highest Q-values under the optimal policy—i.e., when it is optimal to act greedily with respect to the random's policy Q function—deep RL tends to succeed; when they don't, deep RL tends to fail. We generalize this property into a new complexity measure of an MDP that we call the effective horizon, which roughly corresponds to how many steps of lookahead search would be needed in that MDP in order to identify the next optimal action, when leaf nodes are …
[ Hall C2 (level 1 gate 9 south of food court) ]
Abstract
Task arithmetic has recently emerged as a cost-effective and scalable approach to edit pre-trained models directly in weight space: By adding the fine-tuned weights of different tasks, the model's performance can be improved on these tasks, while negating them leads to task forgetting. Yet, our understanding of the effectiveness of task arithmetic and its underlying principles remains limited. We present a comprehensive study of task arithmetic in vision-language models and show that weight disentanglement is the crucial factor that makes it effective. This property arises during pre-training and manifests when distinct directions in weight space govern separate, localized regions in function space associated with the tasks. Notably, we show that fine-tuning models in their tangent space by linearizing them amplifies weight disentanglement. This leads to substantial performance improvements across multiple task arithmetic benchmarks and diverse models. Building on these findings, we provide theoretical and empirical analyses of the neural tangent kernel (NTK) of these models and establish a compelling link between task arithmetic and the spatial localization of the NTK eigenfunctions. Overall, our work uncovers novel insights into the fundamental mechanisms of task arithmetic and offers a more reliable and effective approach to edit pre-trained models through the NTK linearization.
[ Room R06-R09 (level 2) ]
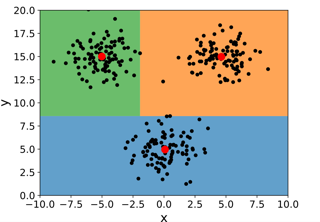
Abstract
[ Room R06-R09 (level 2) ]
Abstract
[ La Nouvelle Orleans Ballroom A-C (level 2) ]
Abstract
While large-scale unsupervised language models (LMs) learn broad world knowledge and some reasoning skills, achieving precise control of their behavior is difficult due to the completely unsupervised nature of their training. Existing methods for gaining such steerability collect human labels of the relative quality of model generations and fine-tune the unsupervised LM to align with these preferences, often with reinforcement learning from human feedback (RLHF). However, RLHF is a complex and often unstable procedure, first fitting a reward model that reflects the human preferences, and then fine-tuning the large unsupervised LM using reinforcement learning to maximize this estimated reward without drifting too far from the original model. In this paper, we leverage a mapping between reward functions and optimal policies to show that this constrained reward maximization problem can be optimized exactly with a single stage of policy training, essentially solving a classification problem on the human preference data. The resulting algorithm, which we call Direct Preference Optimization (DPO), is stable, performant, and computationally lightweight, eliminating the need for fitting a reward model, sampling from the LM during fine-tuning, or performing significant hyperparameter tuning. Our experiments show that DPO can fine-tune LMs to align with human preferences as well as …
[ Hall C2 (level 1 gate 9 south of food court) ]
Abstract
Do neural networks, trained on well-understood algorithmic tasks, reliably rediscover known algorithms? Several recent studies, on tasks ranging from group operations to in-context linear regression, have suggested that the answer is yes. Using modular addition as a prototypical problem, we show that algorithm discovery in neural networks is sometimes more complex: small changes to model hyperparameters and initializations can induce discovery of qualitatively different algorithms from a fixed training set, and even learning of multiple different solutions in parallel. In modular addition, we specifically show that models learn a known Clock algorithm, a previously undescribed, less intuitive, but comprehensible procedure we term the Pizza algorithm, and a variety of even more complex procedures. Our results show that even simple learning problems can admit a surprising diversity of solutions, motivating the development of new tools for mechanistically characterizing the behavior of neural networks across the algorithmic phase space.
[ Room R02-R05 (level 2) ]

Abstract
Denoising diffusion probabilistic models have transformed image generation with their impressive fidelity and diversity.We show that they also excel in estimating optical flow and monocular depth, surprisingly without task-specific architectures and loss functions that are predominant for these tasks. Compared to the point estimates of conventional regression-based methods, diffusion models also enable Monte Carlo inference, e.g., capturing uncertainty and ambiguity in flow and depth.With self-supervised pre-training, the combined use of synthetic and real data for supervised training, and technical innovations (infilling and step-unrolled denoising diffusion training) to handle noisy-incomplete training data, one can train state-of-the-art diffusion models for depth and optical flow estimation, with additional zero-shot coarse-to-fine refinement for high resolution estimates. Extensive experiments focus on quantitative performance against benchmarks, ablations, and the model's ability to capture uncertainty and multimodality, and impute missing values. Our model obtains a state-of-the-art relative depth error of 0.074 on the indoor NYU benchmark and an Fl-all score of 3.26\% on the KITTI optical flow benchmark, about 25\% better than the best published method.
[ Room R06-R09 (level 2) ]
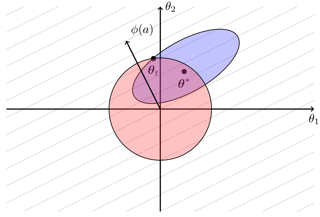
Abstract
We present improved algorithms with worst-case regret guarantees for the stochastic linear bandit problem. The widely used "optimism in the face of uncertainty" principle reduces a stochastic bandit problem to the construction of a confidence sequence for the unknown reward function. The performance of the resulting bandit algorithm depends on the size of the confidence sequence, with smaller confidence sets yielding better empirical performance and stronger regret guarantees. In this work, we use a novel tail bound for adaptive martingale mixtures to construct confidence sequences which are suitable for stochastic bandits. These confidence sequences allow for efficient action selection via convex programming. We prove that a linear bandit algorithm based on our confidence sequences is guaranteed to achieve competitive worst-case regret. We show that our confidence sequences are tighter than competitors, both empirically and theoretically. Finally, we demonstrate that our tighter confidence sequences give improved performance in several hyperparameter tuning tasks.
[ Hall C2 (level 1 gate 9 south of food court) ]
Abstract
Large language models trained for safety and harmlessness remain susceptible to adversarial misuse, as evidenced by the prevalence of “jailbreak” attacks on early releases of ChatGPT that elicit undesired behavior. Going beyond recognition of the issue, we investigate why such attacks succeed and how they can be created. We hypothesize two failure modes of safety training: competing objectives and mismatched generalization. Competing objectives arise when a model’s capabilities and safety goals conflict, while mismatched generalization occurs when safety training fails to generalize to a domain for which capabilities exist. We use these failure modes to guide jailbreak design and then evaluate state-of-the-art models, including OpenAI’s GPT-4 and Anthropic’s Claude v1.3, against both existing and newly designed attacks. We find that vulnerabilities persist despite the extensive red-teaming and safety-training efforts behind these models. Notably, new attacks utilizing our failure modes succeed on every prompt in a collection of unsafe requests from the models’ red-teaming evaluation sets and outperform existing ad hoc jailbreaks. Our analysis emphasizes the need for safety-capability parity—that safety mechanisms should be as sophisticated as the underlying model—and argues against the idea that scaling alone can resolve these safety failure modes.
[ La Nouvelle Orleans Ballroom A-C (level 2) ]
Abstract
Recently, Meta-Black-Box Optimization with Reinforcement Learning (MetaBBO-RL) has showcased the power of leveraging RL at the meta-level to mitigate manual fine-tuning of low-level black-box optimizers. However, this field is hindered by the lack of a unified benchmark. To fill this gap, we introduce MetaBox, the first benchmark platform expressly tailored for developing and evaluating MetaBBO-RL methods. MetaBox offers a flexible algorithmic template that allows users to effortlessly implement their unique designs within the platform. Moreover, it provides a broad spectrum of over 300 problem instances, collected from synthetic to realistic scenarios, and an extensive library of 19 baseline methods, including both traditional black-box optimizers and recent MetaBBO-RL methods. Besides, MetaBox introduces three standardized performance metrics, enabling a more thorough assessment of the methods. In a bid to illustrate the utility of MetaBox for facilitating rigorous evaluation and in-depth analysis, we carry out a wide-ranging benchmarking study on existing MetaBBO-RL methods. Our MetaBox is open-source and accessible at: https://github.com/GMC-DRL/MetaBox.
[ Room R02-R05 (level 2) ]
Abstract
What spatial frequency information do humans and neural networks use to recognize objects? In neuroscience, critical band masking is an established tool that can reveal the frequency-selective filters used for object recognition. Critical band masking measures the sensitivity of recognition performance to noise added at each spatial frequency. Existing critical band masking studies show that humans recognize periodic patterns (gratings) and letters by means of a spatial-frequency filter (or "channel") that has a frequency bandwidth of one octave (doubling of frequency). Here, we introduce critical band masking as a task for network-human comparison and test 14 humans and 76 neural networks on 16-way ImageNet categorization in the presence of narrowband noise. We find that humans recognize objects in natural images using the same one-octave-wide channel that they use for letters and gratings, making it a canonical feature of human object recognition. Unlike humans, the neural network channel is very broad, 2-4 times wider than the human channel. This means that the network channel extends to frequencies higher and lower than those that humans are sensitive to. Thus, noise at those frequencies will impair network performance and spare human performance. Adversarial and augmented-image training are commonly used to increase network robustness …