Poster
Into the LAION’s Den: Investigating Hate in Multimodal Datasets
Abeba Birhane · vinay prabhu · Sanghyun Han · Vishnu Boddeti · Sasha Luccioni
Great Hall & Hall B1+B2 (level 1) #1603
{kind=link}
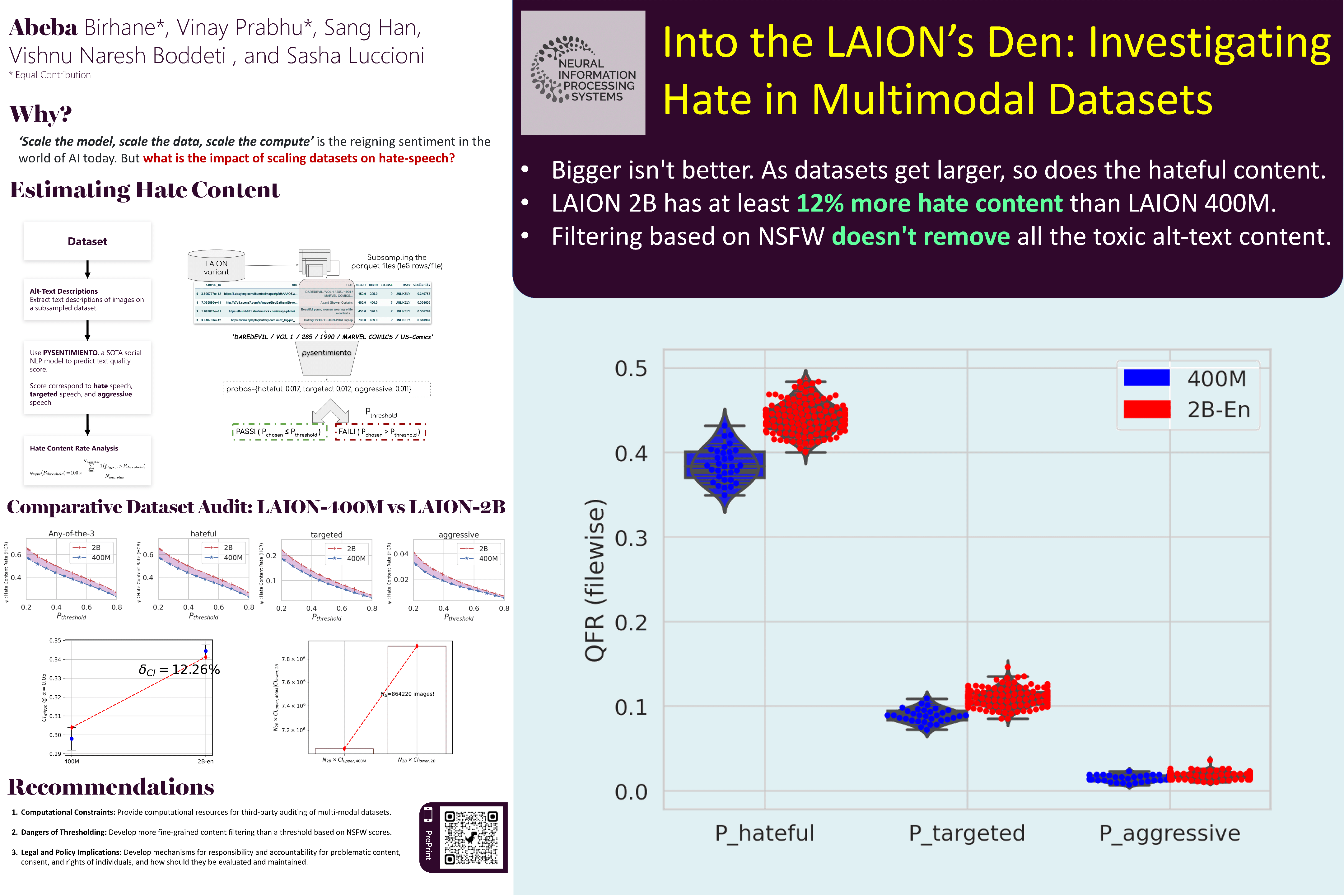
`Scale the model, scale the data, scale the compute' is the reigning sentiment in the world of generative AI today. While the impact of model scaling has been extensively studied, we are only beginning to scratch the surface of data scaling and its consequences. This is especially of critical importance in the context of vision-language datasets such as LAION. These datasets are continually growing in size and are built based on large-scale internet dumps such as the Common Crawl, which is known to have numerous drawbacks ranging from quality, legality, and content. The datasets then serve as the backbone for large generative models, contributing to the operationalization and perpetuation of harmful societal and historical biases and stereotypes. In this paper, we investigate the effect of scaling datasets on hateful content through a comparative audit of two datasets: LAION-400M and LAION-2B. Our results show that hate content increased by nearly 12% with dataset scale, measured both qualitatively and quantitatively using a metric that we term as Hate Content Rate (HCR). We also found that filtering dataset contents based on Not Safe For Work (NSFW) values calculated based on images alone does not exclude all the harmful content in alt-text. Instead, we found that trace amounts of hateful, targeted, and aggressive text remain even when carrying out conservative filtering. We end with a reflection and a discussion of the significance of our results for dataset curation and usage in the AI community.Code and the meta-data assets curated in this paper are publicly available at https://github.com/vinayprabhu/hate_scaling. Content warning: This paper contains examples of hateful text that might be disturbing, distressing, and/or offensive.