Poster
Clustering with Non-adaptive Subset Queries
Hadley Black · Euiwoong Lee · Arya Mazumdar · Barna Saha
West Ballroom A-D #6707
{kind=link}
Abstract:
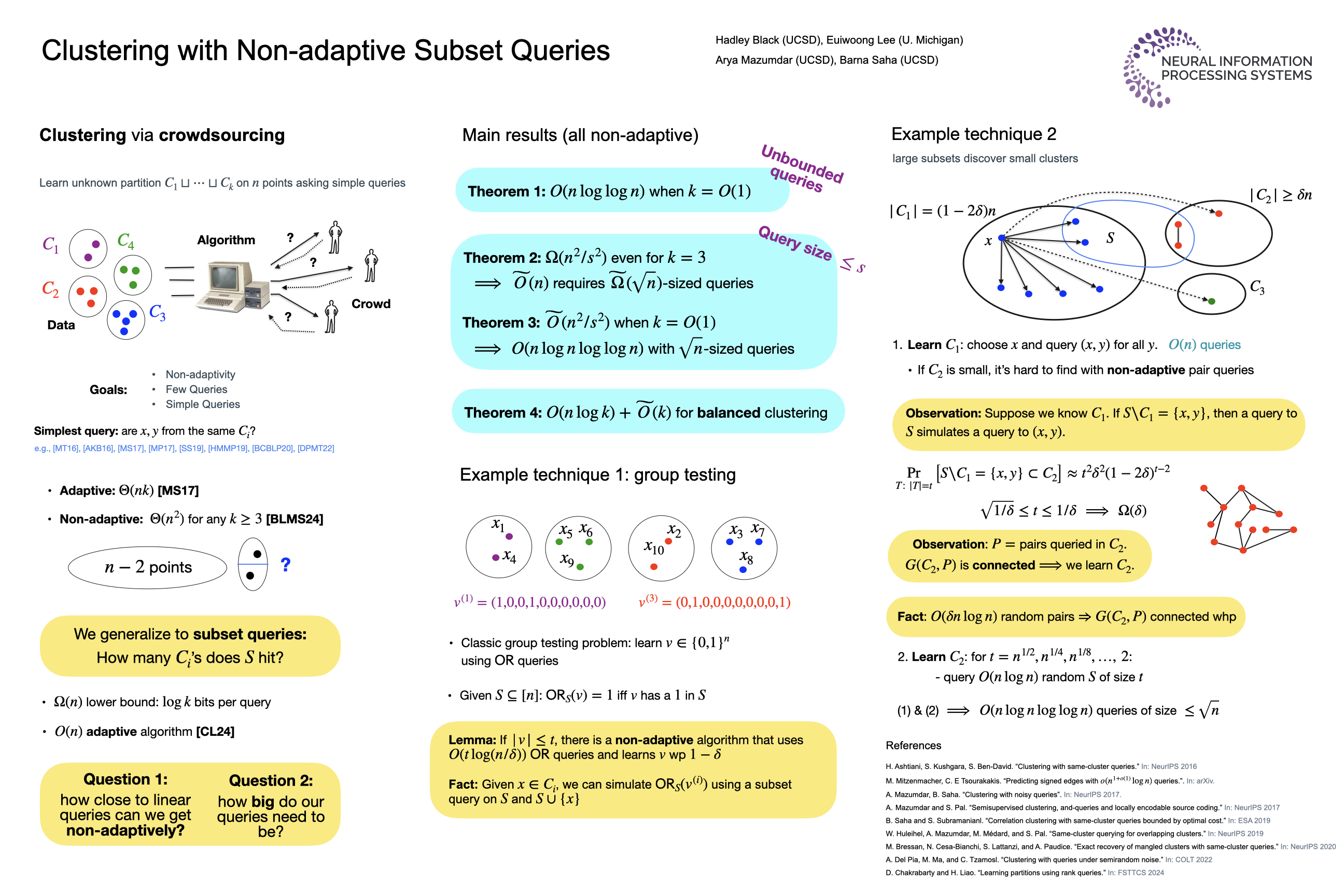
Recovering the underlying clustering of a set $U$ of $n$ points by asking pair-wise same-cluster queries has garnered significant interest in the last decade. Given a query $S \subset U$, $|S|=2$, the oracle returns "yes" if the points are in the same cluster and "no" otherwise. We study a natural generalization of this problem to subset queries for $|S|>2$, where the oracle returns the number of clusters intersecting $S$. Our aim is to determine the minimum number of queries needed for exactly recovering an arbitrary $k$-clustering. We focus on non-adaptive schemes, where all the queries are asked in one round, thus allowing for the querying process to be parallelized, which is a highly desirable property. For adaptive algorithms with pair-wise queries, the complexity is known to be $\Theta(nk)$, where $k$ is the number of clusters. In contrast, non-adaptive pair-wise query algorithms are extremely limited: even for $k=3$, such algorithms require $\Omega(n^2)$ queries, which matches the trivial $O(n^2)$ upper bound attained by querying every pair of points. Allowing for subset queries of unbounded size, $O(n)$ queries is possible with an adaptive scheme. However, the realm of non-adaptive algorithms remains completely unknown. Is it possible to attain algorithms that are non-adaptive while still making a near-linear number of queries?In this paper, we give the first non-adaptive algorithms for clustering with subset queries. We provide, (i) a non-adaptive algorithm making $O(n \log^2 n \log k)$ queries which improves to $O(n \log k)$ when the cluster sizes are within any constant factor of each other, (ii) for constant $k$, a non-adaptive algorithm making $O(n \log{\log{n}})$ queries. In addition to non-adaptivity, we take into account other practical considerations, such as enforcing a bound on query size. For constant $k$, we give an algorithm making $\smash{\widetilde{O}(n^2/s^2)}$ queries on subsets of size at most $s \leq \sqrt{n}$, which is optimal among all non-adaptive algorithms within a $\log n$-factor. For arbitrary $k$, the dependence varies as $\tilde{O}(n^2/s)$.
Chat is not available.