Poster
in
Workshop: Workshop on Machine Learning and Compression
Does Representation Matter? Exploring Intermediate Layers in Large Language Models
Oscar Skean · Md Rifat Arefin · Ravid Shwartz-Ziv
{kind=link}
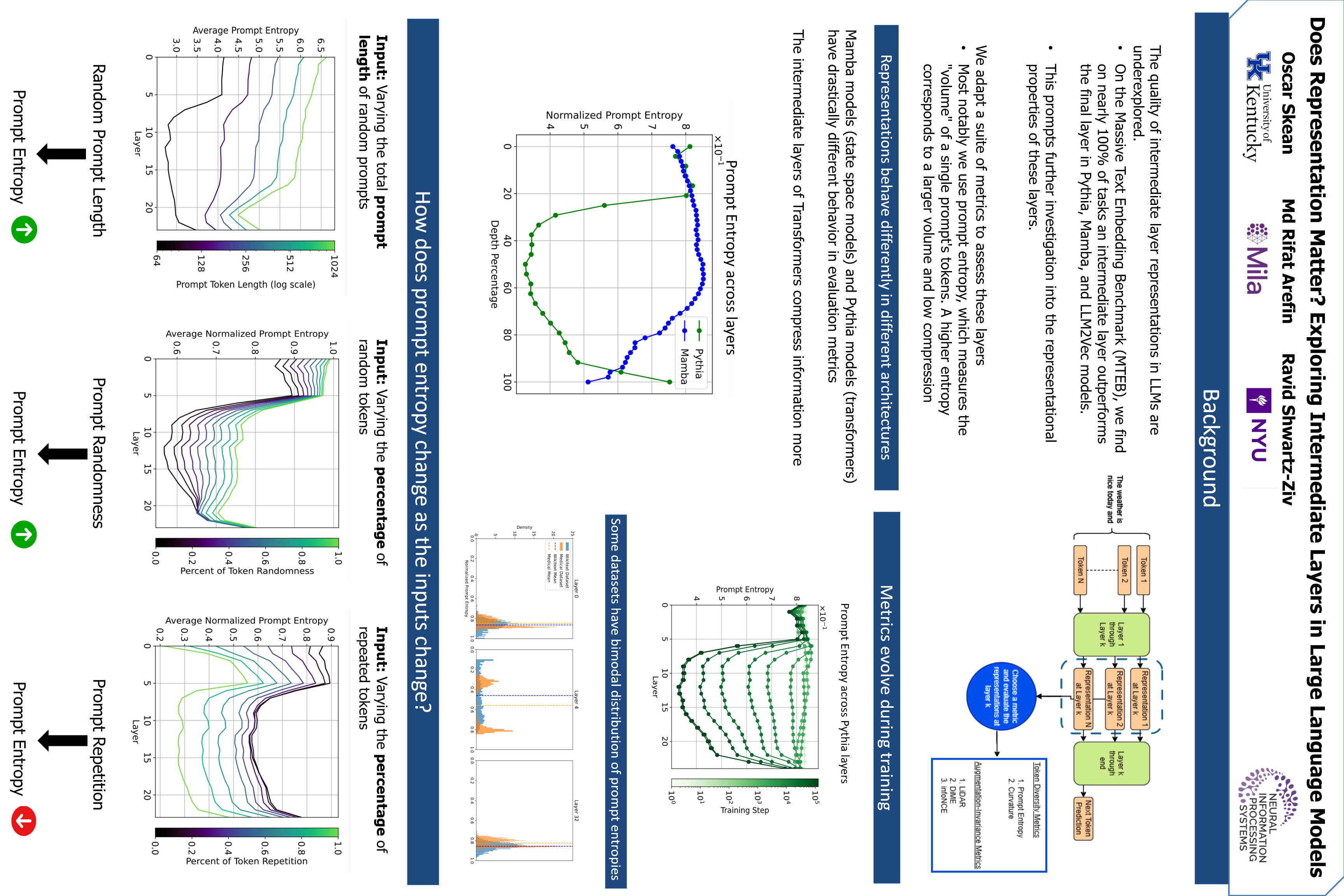
Understanding what constitutes a ``good'' representation in large language models (LLMs) is a fundamental question in natural language processing. In this paper, we investigate the quality of representations at different layers of LLMs, specifically Transformers and State Space Models (SSMs). We find that intermediate layers consistently provide better representations for downstream tasks compared to final layers. To quantify representation quality, we employ existing metrics from other contexts---such as prompt entropy, curvature, and augmentation-invariance---and apply them to LLMs. Our experiments reveal significant differences between architectures, showcase how representations evolve during training, and illustrate the impact of input randomness and prompt length on different layers. Notably, we observe a bimodal behavior in entropy within intermediate layers and explore potential causes related to training data exposure. Our findings offer valuable insights into the internal workings of LLMs and open avenues for optimizing their architectures and training processes.