Poster
in
Workshop: Workshop on Machine Learning and Compression
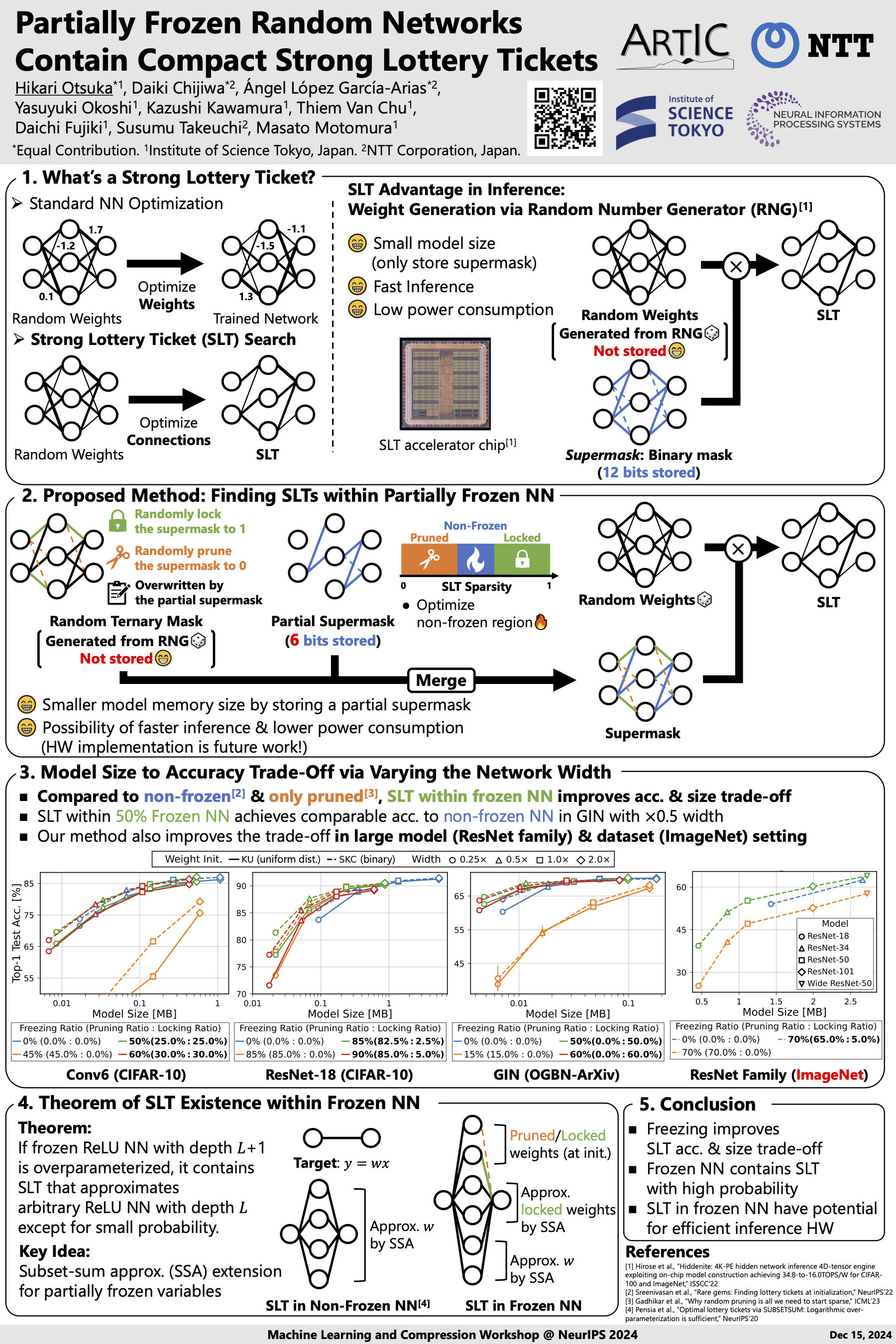
Partially Frozen Random Networks Contain Compact Strong Lottery Tickets
Hikari Otsuka · Daiki Chijiwa · Ángel López García-Arias · Yasuyuki Okoshi · Kazushi Kawamura · Thiem Van Chu · Daichi Fujiki · Susumu Takeuchi · Masato Motomura
{kind=link}
Abstract:
Randomly initialized dense networks contain subnetworks that achieve high accuracy without weight learning---strong lottery tickets (SLTs).Recently, Gadhikar et al. demonstrated that SLTs could also be found within a randomly pruned source network.This phenomenon can be exploited to further compress the small memory size required by SLTs.However, their method is limited to SLTs that are even sparser than the source, leading to worse accuracy due to unintentionally high sparsity.This paper proposes a method for reducing the SLT memory size without restricting the sparsity of the SLTs that can be found. A random subset of the initial weights is frozen by either permanently pruning them or locking them as a fixed part of the SLT, resulting in a smaller model size.Experimental results show that Edge-Popup finds SLTs with better accuracy-to-model size trade-off within frozen networks than within dense or randomly pruned source networks.In particular, freezing $70$% of a ResNet on ImageNet provides $3.3 \times$ compression compared to the SLT found within a dense counterpart, raises accuracy by up to $14.12$ points compared to the SLT found within a randomly pruned counterpart, and offers a better accuracy-model size trade-off than both.
Chat is not available.