Poster
in
Workshop: The Fourth Workshop on Efficient Natural Language and Speech Processing (ENLSP-IV): Highlighting New Architectures for Future Foundation Models
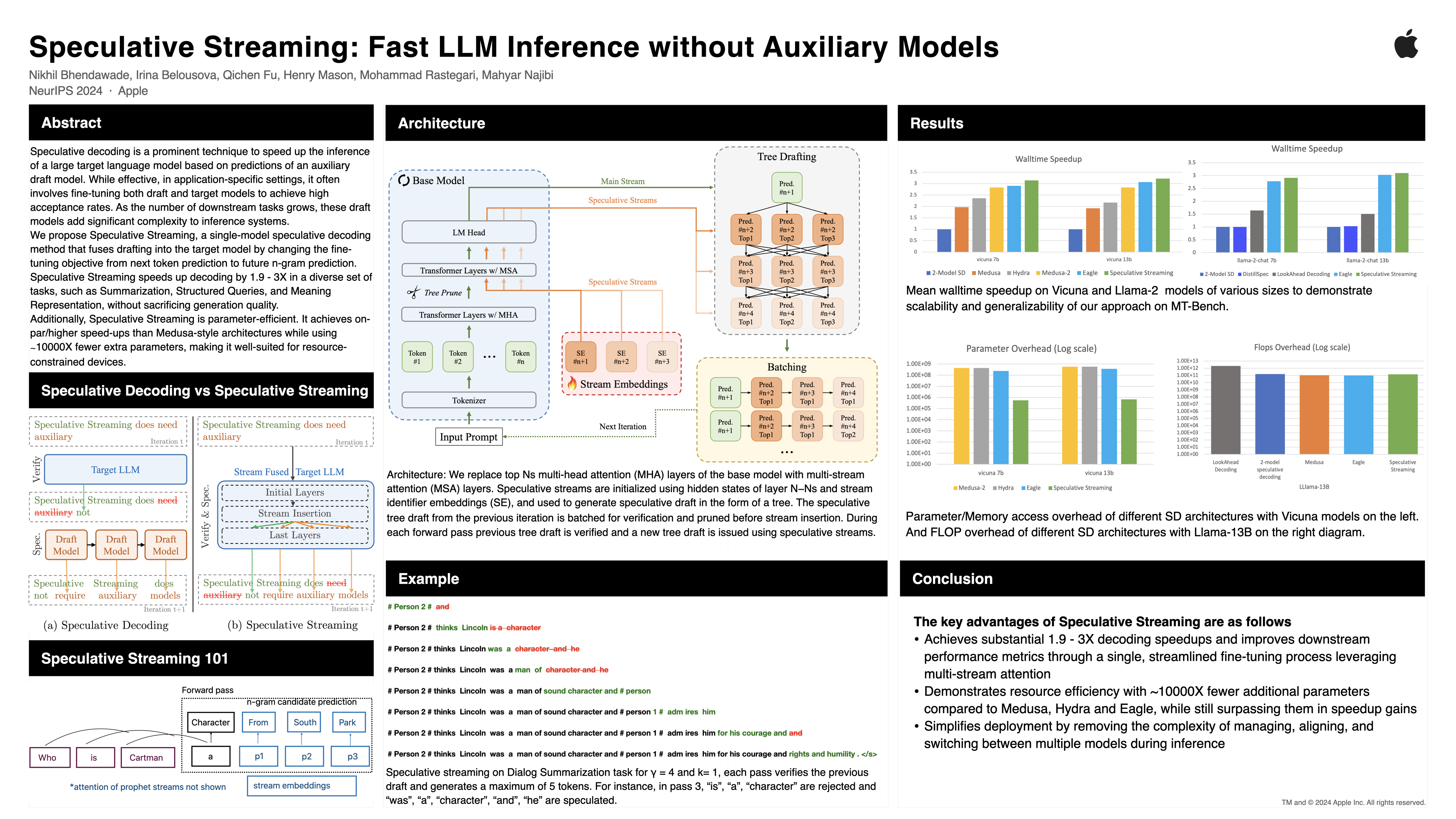
Speculative Streaming: Fast LLM Inference without Auxiliary Models
Nikhil Bhendawade · Mahyar Najibi · Irina Belousova · Qichen Fu · Henry Mason · Mohammad Rastegari
Keywords: [ Efficient Inference ]
{kind=link}
Speculative decoding is a prominent technique to accelerate large language model inference by leveraging predictions from an auxiliary draft model. While effective, in application-specific settings, it often involves fine-tuning both draft and target models to achieve high acceptance rates. As the number of downstream tasks grows, draft models add significant complexity to inference systems. Recently several single model architectures viz. Medusa have been proposed to speculate tokens in non-autoregressive manner, however, their effectiveness is limited due to lack of dependency between speculated tokens. We introduce a novel speculative decoding method that integrates drafting within the target model by using Multi-stream attention and incorporates future token planning into supervised fine-tuning objective. To the best of our knowledge, it is the first parameter-efficient approach that scales well with number of downstream tasks while improving downstream metrics. Speculative Streaming speeds up decoding by 1.9 - 3X in a diverse set of tasks, such as Summarization, Structured Queries, and Meaning Representation, while improving generation quality and using 10000X fewer extra parameters than alternative architectures, making it ideal for resource-constrained devices. Our approach can also be effectively deployed in lossless settings for generic chatbot applications that do not necessitate fine-tuning. In such setups, we achieve 2.9 - 3.2X speedup while maintaining the integrity of the base model's output.