Poster
Mini-Sequence Transformers: Optimizing Intermediate Memory for Long Sequences Training
cheng Luo · Jiawei Zhao · Zhuoming Chen · Beidi Chen · Animashree Anandkumar
East Exhibit Hall A-C #2311
{kind=link}
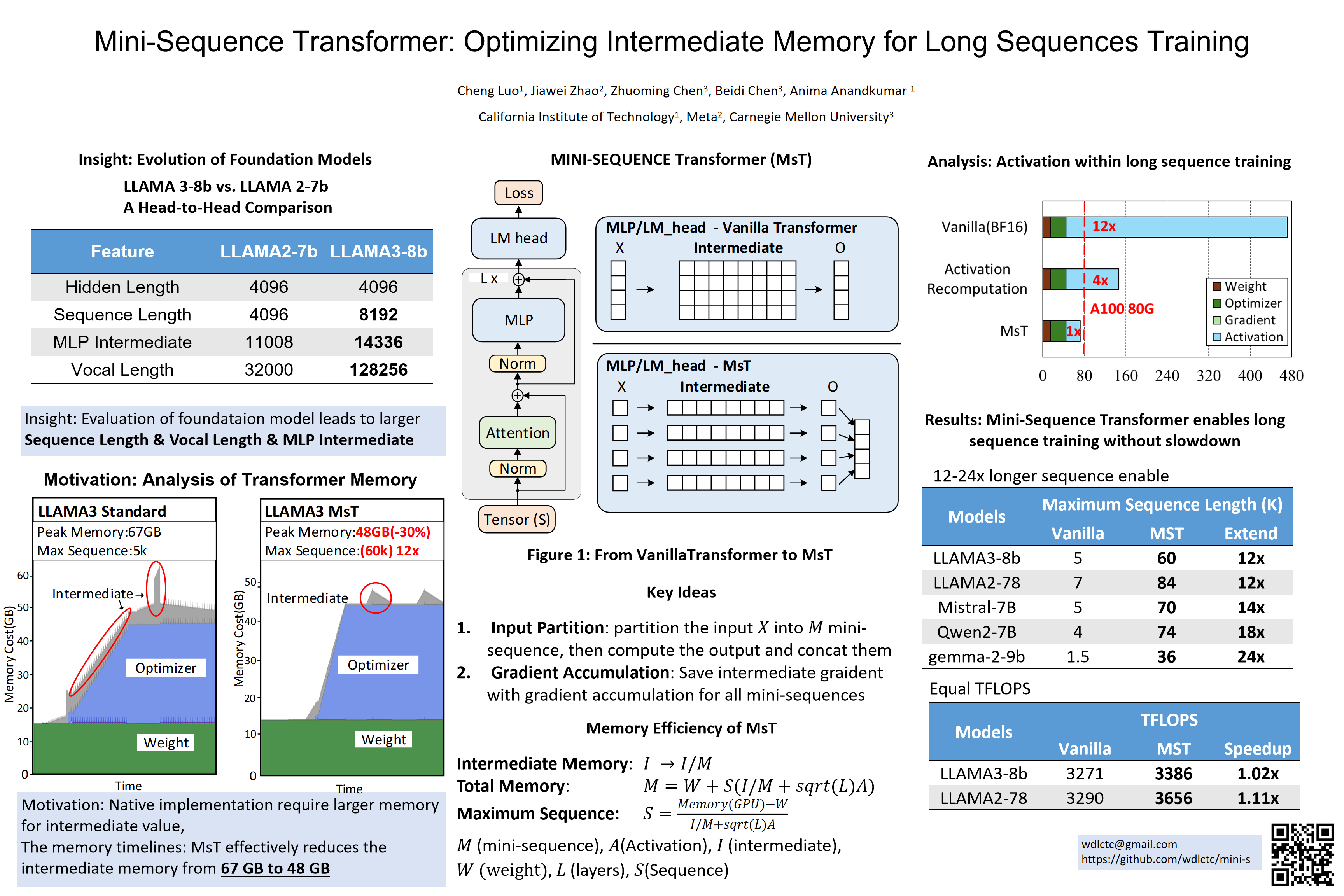
We introduce Mini-Sequence Transformer (MsT), a simple and effective methodology for highly efficient and accurate LLM training with extremely long sequences. MsT partitions input sequences and iteratively processes mini-sequences to reduce intermediate memory usage. Integrated with activation recomputation, it enables significant memory savings in both forward and backward passes. In experiments with the Llama3-8B model, with MsT, we measure no degradation in throughput or convergence even with 12x longer sequences than standard implementations. MsT is fully general, implementation-agnostic, and requires minimal code changes to integrate with existing LLM training frameworks. Integrated with the huggingface library, MsT successfully extends the maximum context length of Qwen, Mistral, and Gemma-2 by 12-24x.