Poster
Seek Commonality but Preserve Differences: Dissected Dynamics Modeling for Multi-modal Visual RL
Yangru Huang · Peixi Peng · Yifan Zhao · Guangyao Chen · Yonghong Tian
{kind=link}
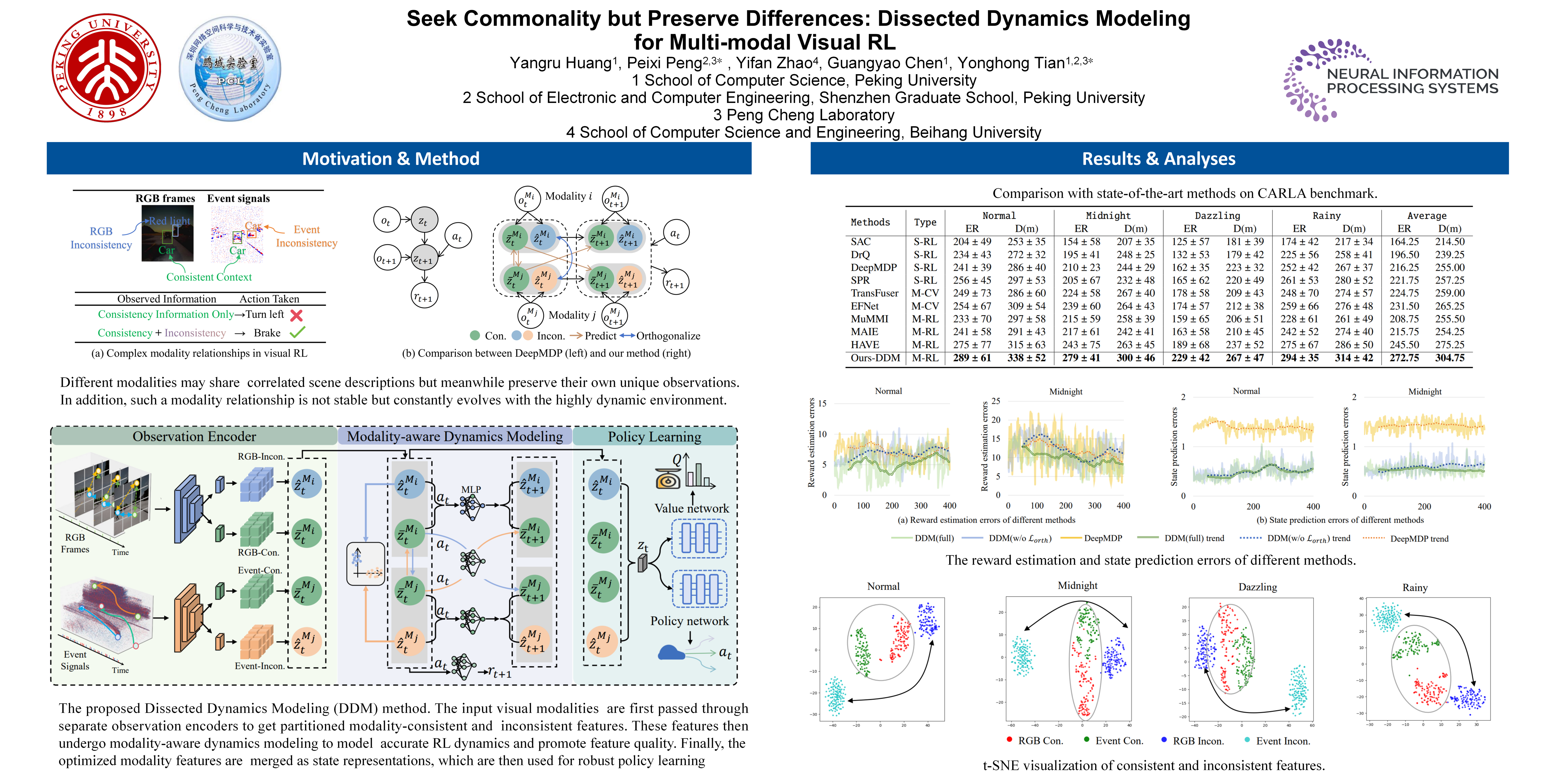
Accurate environment dynamics modeling is crucial for obtaining effective state representations in visual reinforcement learning (RL) applications. However, when facing multiple input modalities, existing dynamics modeling methods (e.g., DeepMDP) usually stumble in addressing the complex and volatile relationship between different modalities. In this paper, we study the problem of efficient dynamics modeling for multi-modal visual RL. We find that under the existence of modality heterogeneity, modality-correlated and distinct features are equally important but play different roles in reflecting the evolution of environmental dynamics. Motivated by this fact, we propose Dissected Dynamics Modeling (DDM), a novel multi-modal dynamics modeling method for visual RL. Unlike existing methods, DDM explicitly distinguishes consistent and inconsistent information across modalities and treats them separately with a divide-and-conquer strategy. This is done by dispatching the features carrying different information into distinct dynamics modeling pathways, which naturally form a series of implicit regularizations along the learning trajectories. In addition, a reward predictive function is further introduced to filter task-irrelevant information in both modality-consistent and inconsistent features, ensuring information integrity while avoiding potential distractions. Extensive experiments show that DDM consistently achieves competitive performance in challenging multi-modal visual environments.