Poster
DARG: Dynamic Evaluation of Large Language Models via Adaptive Reasoning Graph
Zhehao Zhang · Jiaao Chen · Diyi Yang
East Exhibit Hall A-C #2601
{kind=link}
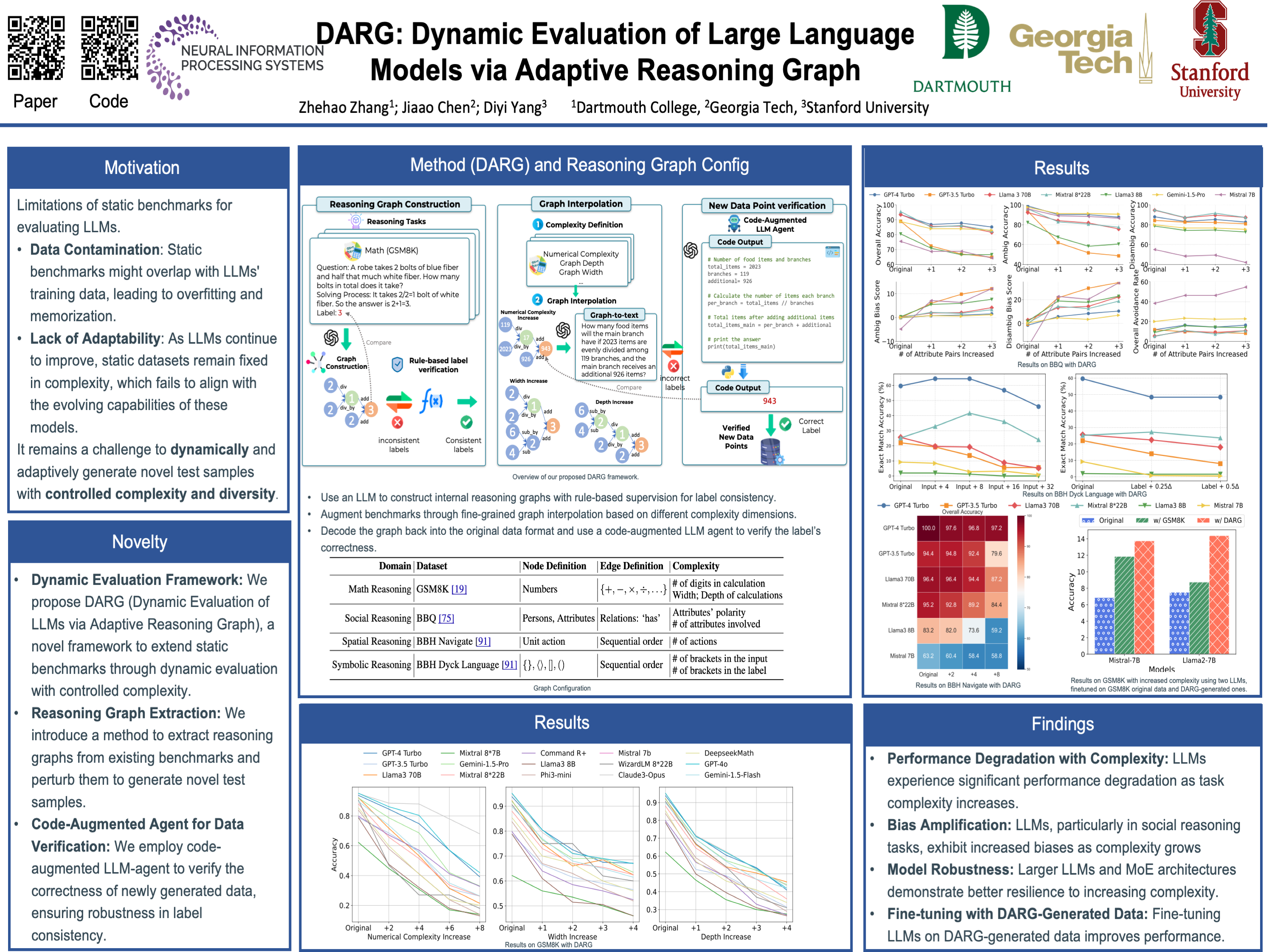
The current paradigm of evaluating Large Language Models (LLMs) through static benchmarks comes with significant limitations, such as vulnerability to data contamination and a lack of adaptability to the evolving capabilities of LLMs. Therefore, evaluation methods that can adapt and generate evaluation data with controlled complexity are urgently needed. In this work, we introduce Dynamic Evaluation of LLMs via Adaptive Reasoning Graph Evolvement (DARG) to dynamically extend current benchmarks with controlled complexity and diversity. Specifically, we first extract the reasoning graphs of data points in current benchmarks and then perturb the reasoning graphs to generate novel testing data. Such newly generated test samples can have different levels of complexity while maintaining linguistic diversity similar to the original benchmarks. We further use a code-augmented LLM to ensure the label correctness of newly generated data. We apply our DARG framework to diverse reasoning tasks in four domains with 15 state-of-the-art LLMs. Experimental results show that almost all LLMs experience a performance decrease with increased complexity and certain LLMs exhibit significant drops. Additionally, we find that LLMs exhibit more biases when being evaluated via the data generated by DARG with higher complexity levels. These observations provide useful insights into how to dynamically and adaptively evaluate LLMs.