Poster
ZipCache: Accurate and Efficient KV Cache Quantization with Salient Token Identification
Yefei He · Luoming Zhang · Weijia Wu · Jing Liu · Hong Zhou · Bohan Zhuang
East Exhibit Hall A-C #2400
{kind=link}
Abstract:
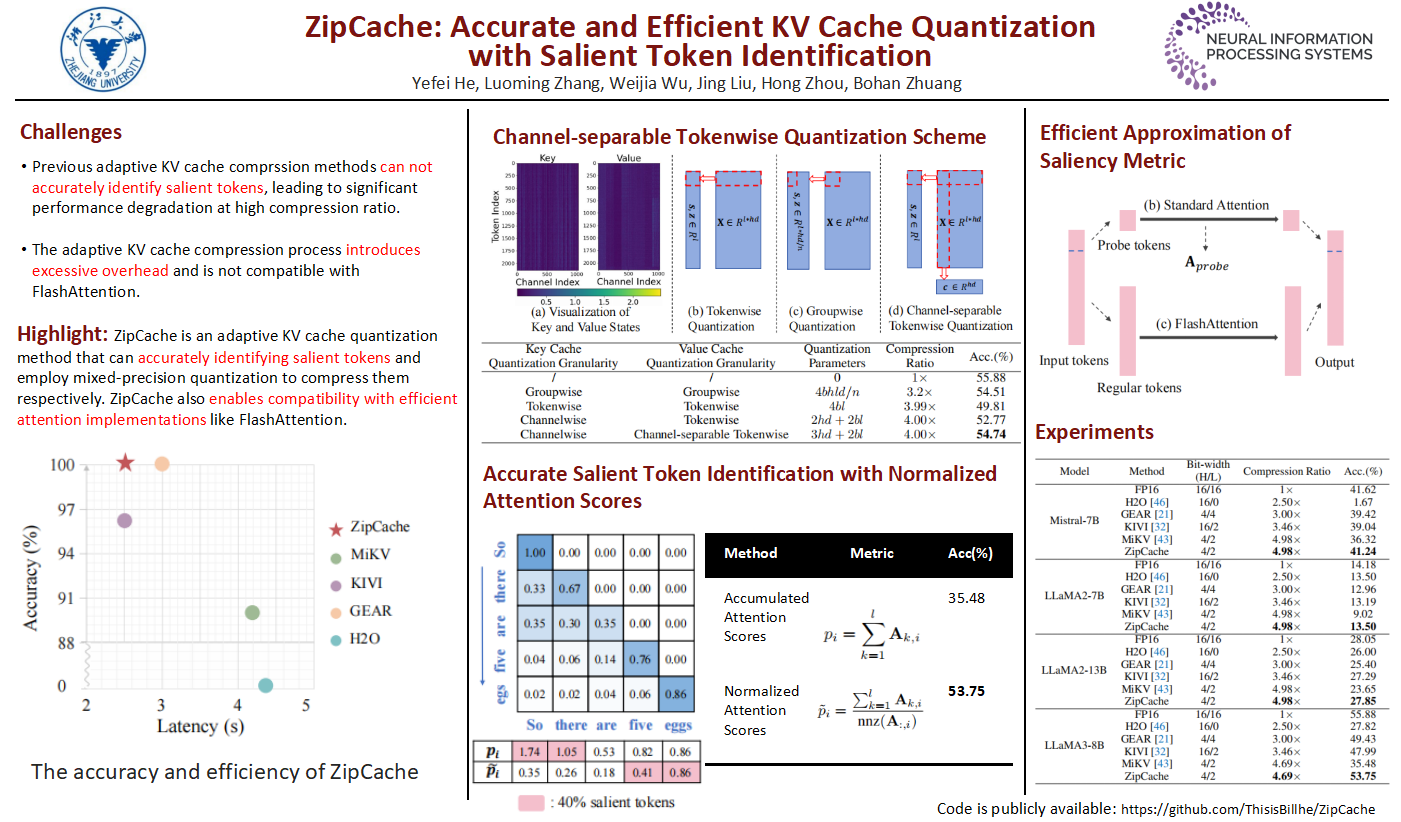
KV cache stores key and value states from previous tokens to avoid re-computation, yet it demands substantial storage space, especially for long sequences. Adaptive KV cache compression seeks to discern the saliency of tokens, preserving vital information while aggressively compressing those of less importance. However, previous methods of this approach exhibit significant performance degradation at high compression ratios due to inaccuracies in identifying salient tokens. Additionally, the compression process introduces excessive overhead, substantially increasing memory burdens and the generation latency. In this paper, we present ZipCache, an accurate and efficient KV cache quantization method for large language models (LLMs). First, we construct a strong baseline for quantizing KV cache. Through the proposed channel-separable tokenwise quantization scheme, the memory overhead of quantization parameters are substantially reduced compared to fine-grained groupwise quantization. To enhance the compression ratio, we propose normalized attention score as an effective metric for identifying salient tokens by considering the lower triangle characteristics of the attention matrix. The quantization bit-width for each token is then adaptively assigned based on their saliency. Moreover, we develop an efficient approximation method that decouples the saliency metric from full attention scores, enabling compatibility with fast attention implementations like FlashAttention. Extensive experiments demonstrate that ZipCache achieves superior compression ratios, fast generation speed and minimal performance losses compared with previous KV cache compression methods. For instance, when evaluating Mistral-7B model on GSM8k dataset, ZipCache is capable of compressing the KV cache by $4.98\times$, with only a 0.38% drop in accuracy. In terms of efficiency, ZipCache also showcases a 37.3% reduction in prefill-phase latency, a 56.9% reduction in decoding-phase latency, and a 19.8% reduction in GPU memory usage when evaluating LLaMA3-8B model with a input length of 4096. Code is available at https://github.com/ThisisBillhe/ZipCache/.
Chat is not available.