Poster
Uncovering the Redundancy in Graph Self-supervised Learning Models
Zhibiao Wang · Xiao Wang · Haoyue Deng · Nian Liu · Shirui Pan · Chunming Hu
East Exhibit Hall A-C #2911
{kind=link}
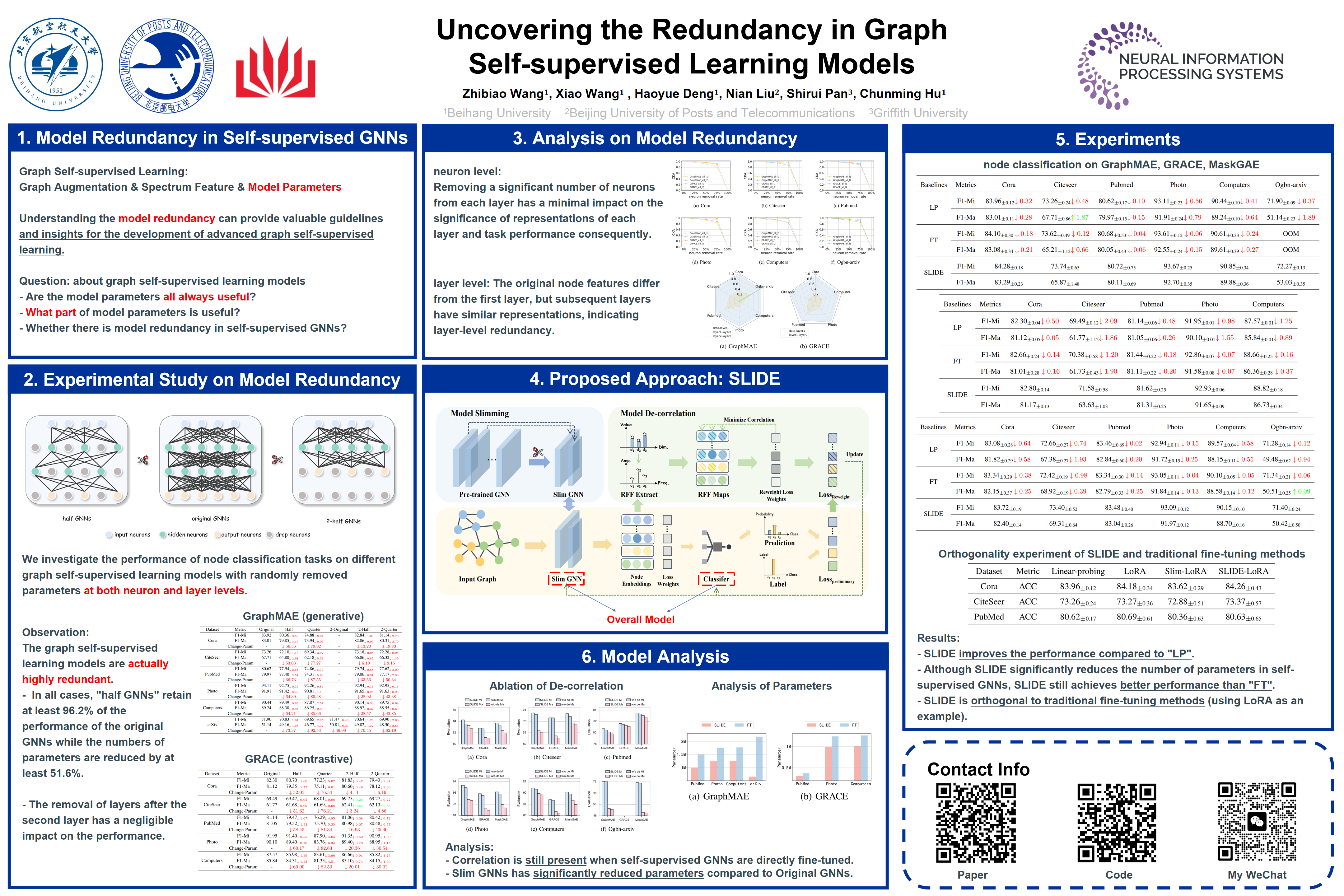
Graph self-supervised learning, as a powerful pre-training paradigm for Graph Neural Networks (GNNs) without labels, has received considerable attention. We have witnessed the success of graph self-supervised learning on pre-training the parameters of GNNs, leading many not to doubt that whether the learned GNNs parameters are all useful. In this paper, by presenting the experimental evidence and analysis, we surprisingly discover that the graph self-supervised learning models are highly redundant at both of neuron and layer levels, e.g., even randomly removing 51.6\% of parameters, the performance of graph self-supervised learning models still retains at least 96.2\%. This discovery implies that the parameters of graph self-supervised models can be largely reduced, making simultaneously fine-tuning both graph self-supervised learning models and prediction layers more feasible. Therefore, we further design a novel graph pre-training and fine-tuning paradigm called SLImming DE-correlation Fine-tuning (SLIDE). The effectiveness of SLIDE is verified through extensive experiments on various benchmarks, and the performance can be even improved with fewer parameters of models in most cases. For example, in comparison with full fine-tuning GraphMAE on Amazon-Computers dataset, even randomly reducing 40\% of parameters, we can still achieve the improvement of 0.24\% and 0.27\% for Micro-F1 and Macro-F1 scores respectively.