Poster
Implicit Multimodal Alignment: On the Generalization of Frozen LLMs to Multimodal Inputs
Mustafa Shukor · Matthieu Cord
East Exhibit Hall A-C #3708
{kind=link}
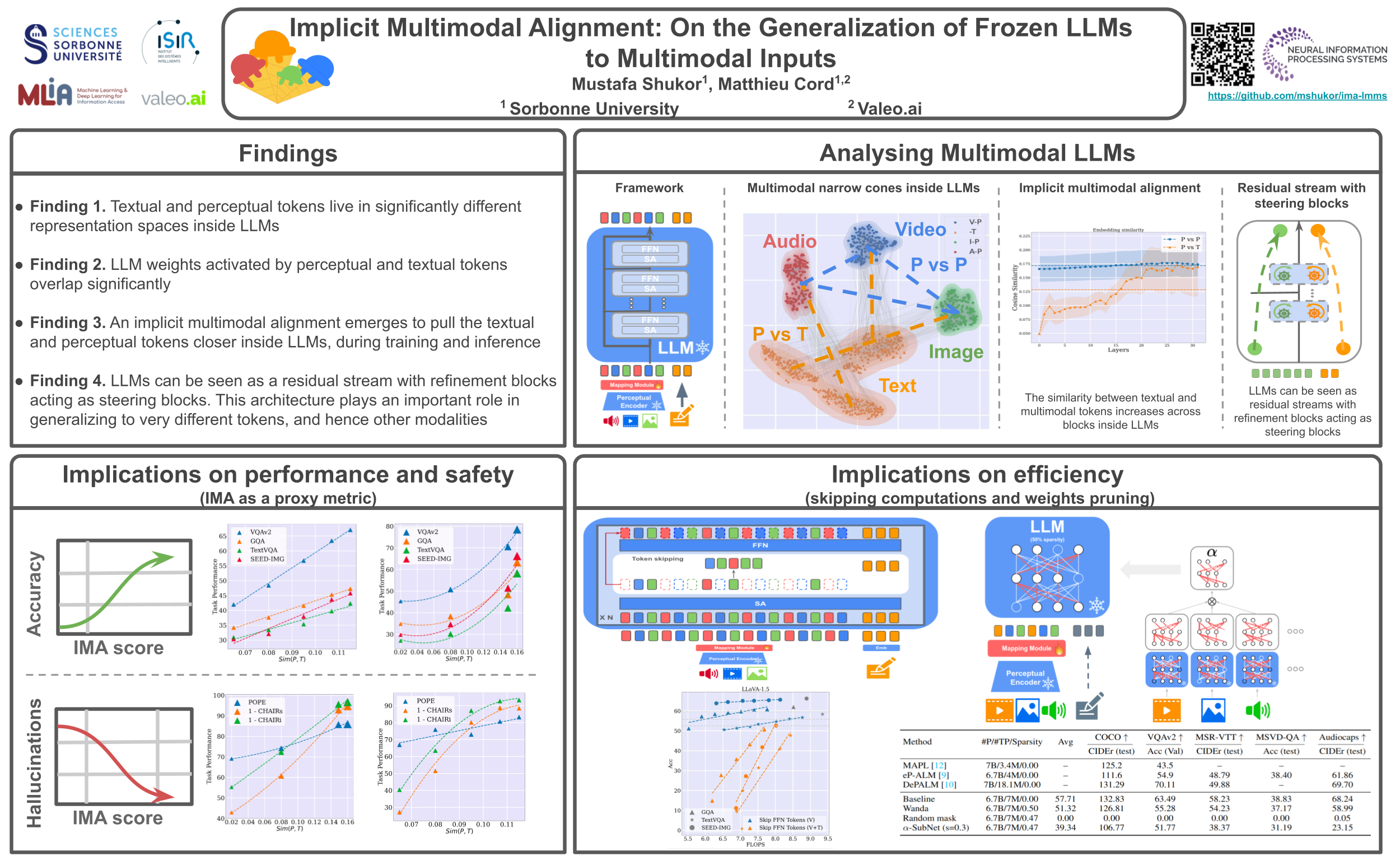
Large Language Models (LLMs) have demonstrated impressive performance on multimodal tasks, without any multimodal finetuning. They are the de facto building block for Large Multimodal Models (LMMs), yet, we still lack a proper understanding of their success. In this work, we expose frozen LLMs to image, video, audio and text inputs and analyse their internal representation with the attempt to understand their generalization beyond textual inputs. Our work provides the following findings. Perceptual tokens (1) are easily distinguishable from textual ones inside LLMs, with significantly different representations (e.g. live in different narrow cones), and complete translation to textual tokens does not exists. Yet, (2) both perceptual and textual tokens activate similar LLM weights. Despite their differences, (3) perceptual tokens are implicitly aligned to textual tokens inside LLMs, we call this the implicit multimodal alignment effect (IMA), and argue that this is linked to architectural design, helping LLMs to generalize. This provide more evidence to believe that the generalization of LLMs to multimodal inputs is mainly due to their architecture. These findings lead to several implications. This work provides several implications. (1) We find a positive correlation between the implicit alignment score and the task performance, suggesting that this could act as a proxy metric for model evaluation and selection. (2) A negative correlation exists regarding hallucinations (e.g. describing non-existing objects in images), revealing that this problem is mainly due to misalignment between the internal perceptual and textual representations. (3) Perceptual tokens change slightly throughout the model, thus, we propose different approaches to skip computations (e.g. in FFN layers), and significantly reduce the inference cost. (4) Due to the slowly changing embeddings across layers, and the high overlap between textual and multimodal activated weights, we compress LLMs by keeping only 1 subnetwork (called alpha-SubNet) that works well across a wide range of multimodal tasks. The code is available here: https://github.com/mshukor/ima-lmms.