Poster
First-Explore, then Exploit: Meta-Learning to Solve Hard Exploration-Exploitation Trade-Offs
Ben Norman · Jeff Clune
West Ballroom A-D #6407
{kind=link}
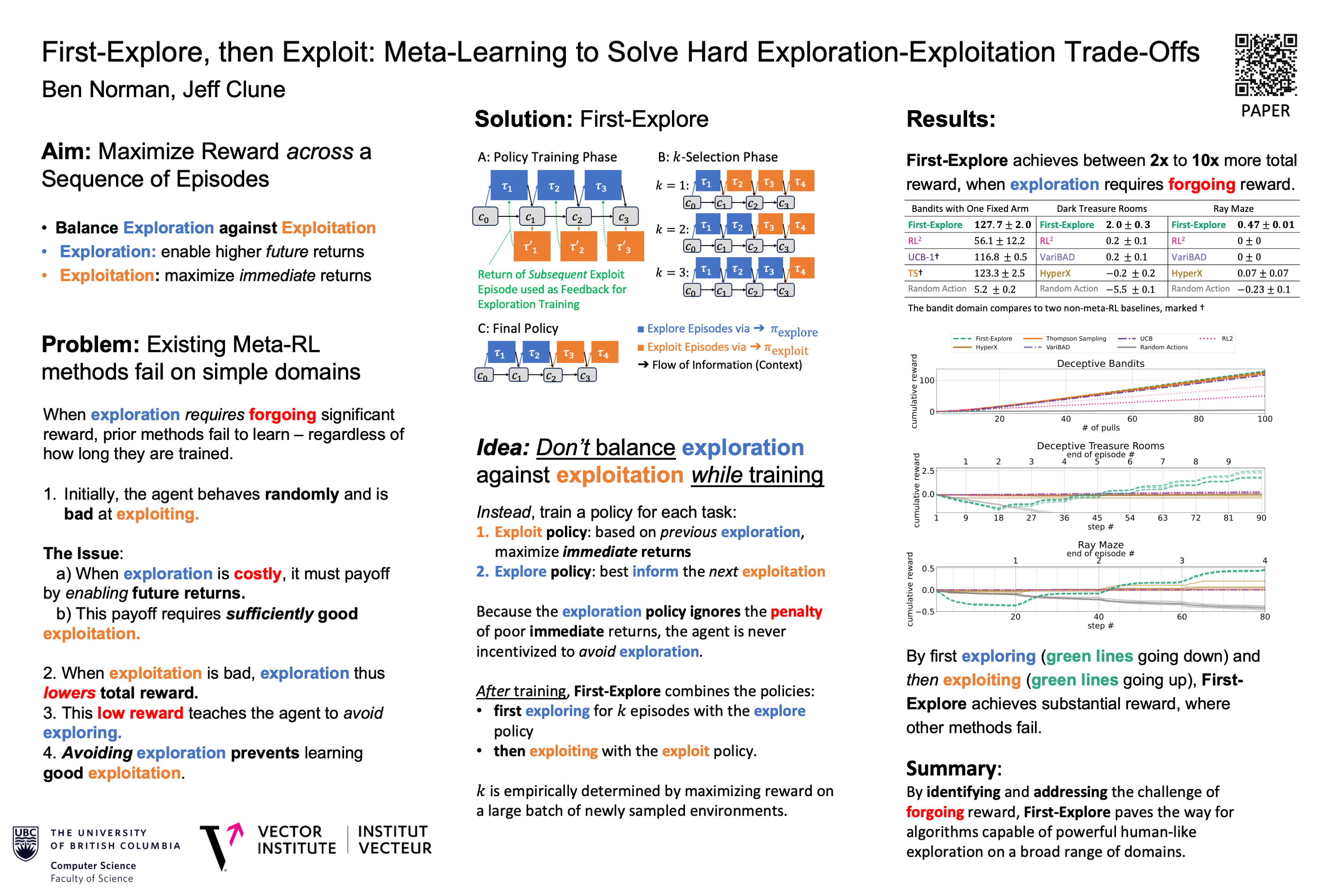
Standard reinforcement learning (RL) agents never intelligently explore like a human (i.e. taking into account complex domain priors and adapting quickly based on previous exploration). Across episodes, RL agents struggle to perform even simple exploration strategies, for example systematic search that avoids exploring the same location multiple times. This poor exploration limits performance on challenging domains. Meta-RL is a potential solution, as unlike standard RL, meta-RL can learn to explore, and potentially learn highly complex strategies far beyond those of standard RL, strategies such as experimenting in early episodes to learn new skills, or conducting experiments to learn about the current environment.Traditional meta-RL focuses on the problem of learning to optimally balance exploration and exploitation to maximize the cumulative reward of the episode sequence (e.g., aiming to maximize the total wins in a tournament -- while also improving as a player).We identify a new challenge with state-of-the-art cumulative-reward meta-RL methods.When optimal behavior requires exploration that sacrifices immediate reward to enable higher subsequent reward, existing state-of-the-art cumulative-reward meta-RL methods become stuck on the local optimum of failing to explore.Our method, First-Explore, overcomes this limitation by learning two policies: one to solely explore, and one to solely exploit. When exploring requires forgoing early-episode reward, First-Explore significantly outperforms existing cumulative meta-RL methods. By identifying and solving the previously unrecognized problem of forgoing reward in early episodes, First-Explore represents a significant step towards developing meta-RL algorithms capable of human-like exploration on a broader range of domains.