Poster
Enhancing Feature Diversity Boosts Channel-Adaptive Vision Transformers
Chau Pham · Bryan Plummer
East Exhibit Hall A-C #1205
{kind=link}
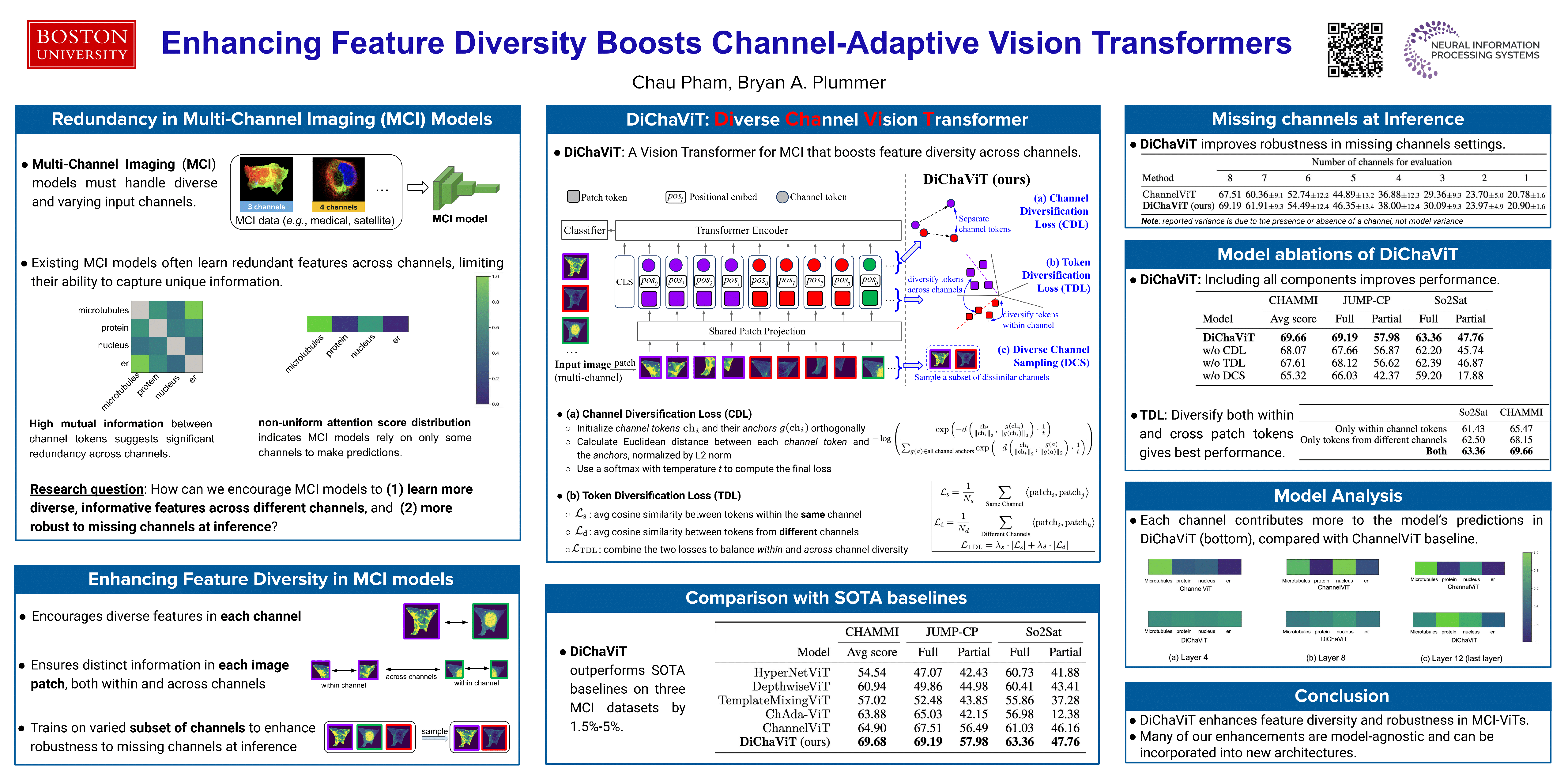
Multi-Channel Imaging (MCI) contains an array of challenges for encoding useful feature representations not present in traditional images. For example, images from two different satellites may both contain RGB channels, but the remaining channels can be different for each imaging source. Thus, MCI models must support a variety of channel configurations at test time. Recent work has extended traditional visual encoders for MCI, such as Vision Transformers (ViT), by supplementing pixel information with an encoding representing the channel configuration. However, these methods treat each channel equally, i.e., they do not consider the unique properties of each channel type, which can result in needless and potentially harmful redundancies in the learned features. For example, if RGB channels are always present, the other channels can focus on extracting information that cannot be captured by the RGB channels. To this end, we propose DiChaViT, which aims to enhance the diversity in the learned features of MCI-ViT models. This is achieved through a novel channel sampling strategy that encourages the selection of more distinct channel sets for training. Additionally, we employ regularization and initialization techniques to increase the likelihood that new information is learned from each channel. Many of our improvements are architecture agnostic and can be incorporated into new architectures as they are developed. Experiments on both satellite and cell microscopy datasets, CHAMMI, JUMP-CP, and So2Sat, report DiChaViT yields a 1.5 - 5.0% gain over the state-of-the-art. Our code is publicly available at https://github.com/chaudatascience/diversechannelvit.