Poster
Towards Calibrated Robust Fine-Tuning of Vision-Language Models
Changdae Oh · Hyesu Lim · Mijoo Kim · Dongyoon Han · Sangdoo Yun · Jaegul Choo · Alexander Hauptmann · Zhi-Qi Cheng · Kyungwoo Song
East Exhibit Hall A-C #4309
{kind=link}
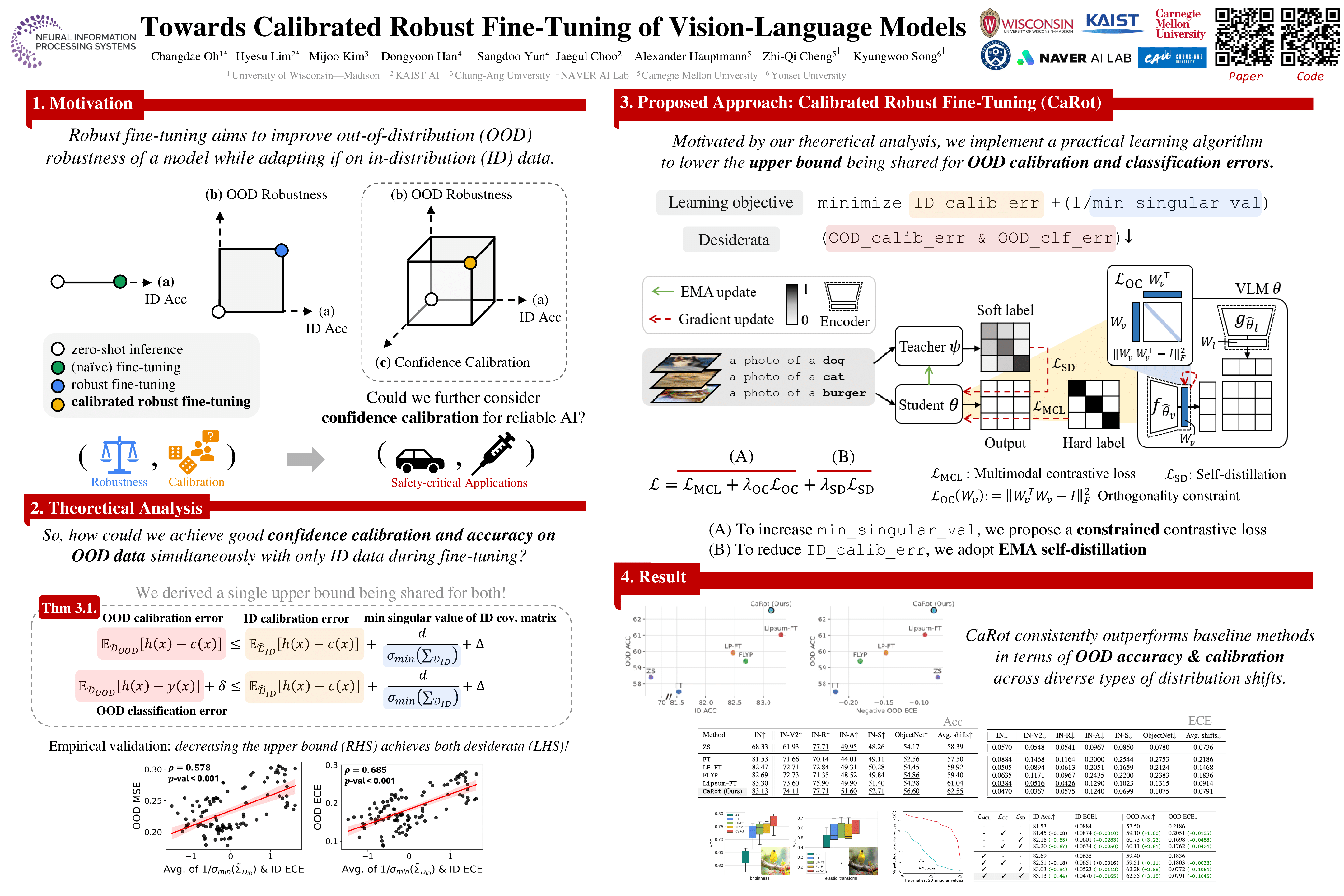
Improving out-of-distribution (OOD) generalization during in-distribution (ID) adaptation is a primary goal of robust fine-tuning of zero-shot models beyond naive fine-tuning. However, despite decent OOD generalization performance from recent robust fine-tuning methods, confidence calibration for reliable model output has not been fully addressed. This work proposes a robust fine-tuning method that improves both OOD accuracy and confidence calibration simultaneously in vision language models. Firstly, we show that both OOD classification and OOD calibration errors have a shared upper bound consisting of two terms of ID data: 1) ID calibration error and 2) the smallest singular value of the ID input covariance matrix. Based on this insight, we design a novel framework that conducts fine-tuning with a constrained multimodal contrastive loss enforcing a larger smallest singular value, which is further guided by the self-distillation of a moving-averaged model to achieve calibrated prediction as well. Starting from empirical evidence supporting our theoretical statements, we provide extensive experimental results on ImageNet distribution shift benchmarks that demonstrate the effectiveness of our theorem and its practical implementation.