Poster
Ultrafast classical phylogenetic method beats large protein language models on variant effect prediction
Sebastian Prillo · Wilson Wu · Yun Song
East Exhibit Hall A-C #1000
{kind=link}
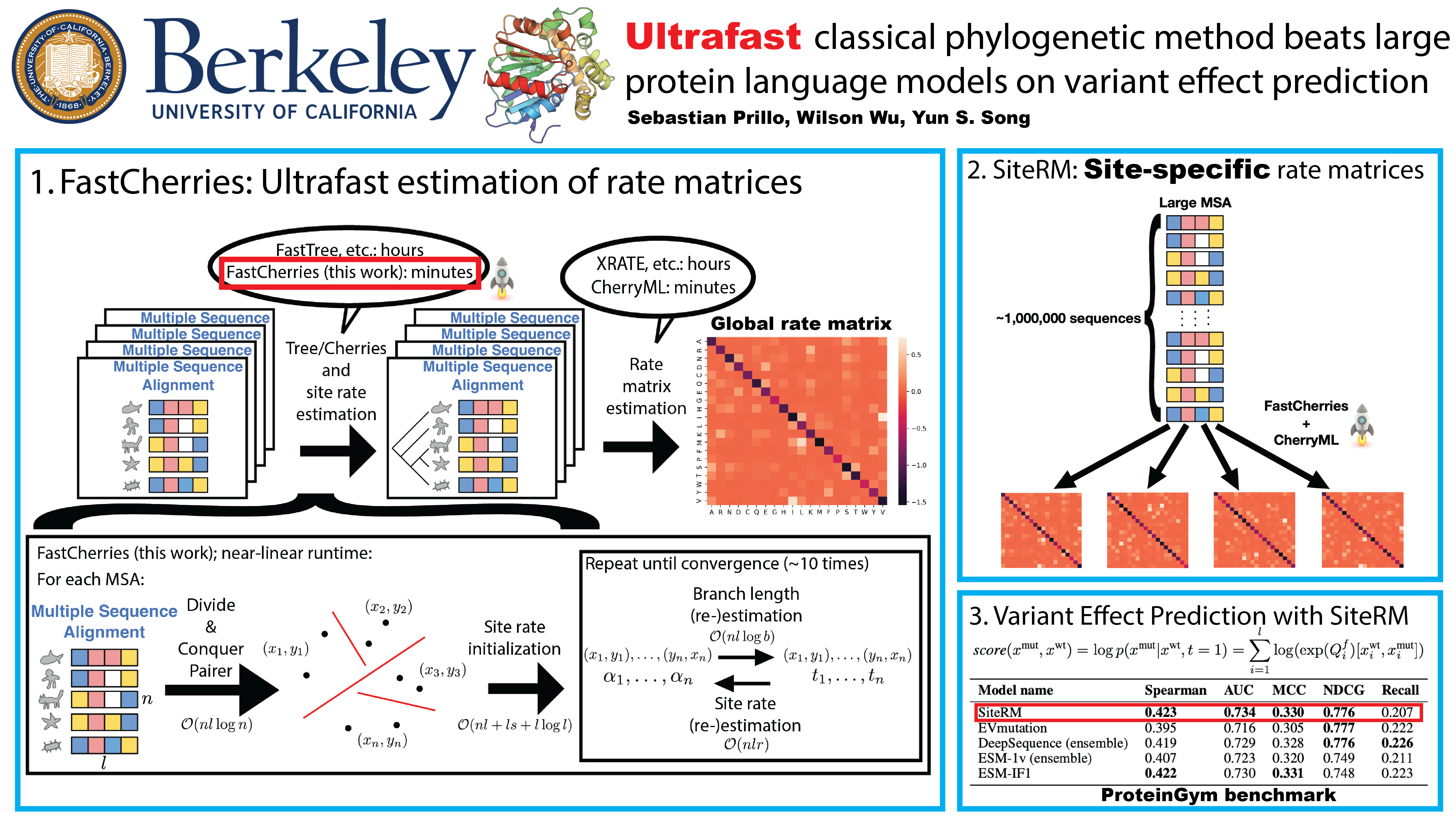
Amino acid substitution rate matrices are fundamental to statistical phylogenetics and evolutionary biology. Estimating them typically requires reconstructed trees for massive amounts of aligned proteins, which poses a major computational bottleneck. In this paper, we develop a near-linear time method to estimate these rate matrices from multiple sequence alignments (MSAs) alone, thereby speeding up computation by orders of magnitude. Our method relies on a near-linear time cherry reconstruction algorithm which we call FastCherries and it can be easily applied to MSAs with millions of sequences. On both simulated and real data, we demonstrate the speed and accuracy of our method as applied to the classical model of protein evolution. By leveraging the unprecedented scalability of our method, we develop a new, rich phylogenetic model called SiteRM, which can estimate a general site-specific rate matrix for each column of an MSA. Remarkably, in variant effect prediction for both clinical and deep mutational scanning data in ProteinGym, we show that despite being an independent-sites model, our SiteRM model outperforms large protein language models that learn complex residue-residue interactions between different sites. We attribute our increased performance to conceptual advances in our probabilistic treatment of evolutionary data and our ability to handle extremely large MSAs. We anticipate that our work will have a lasting impact across both statistical phylogenetics and computational variant effect prediction. FastCherries and SiteRM are implemented in the CherryML package https://github.com/songlab-cal/CherryML.