Poster
What Makes and Breaks Safety Fine-tuning? A Mechanistic Study
Samyak Jain · Ekdeep S Lubana · Kemal Oksuz · Tom Joy · Philip Torr · Amartya Sanyal · Puneet Dokania
East Exhibit Hall A-C #3306
{kind=link}
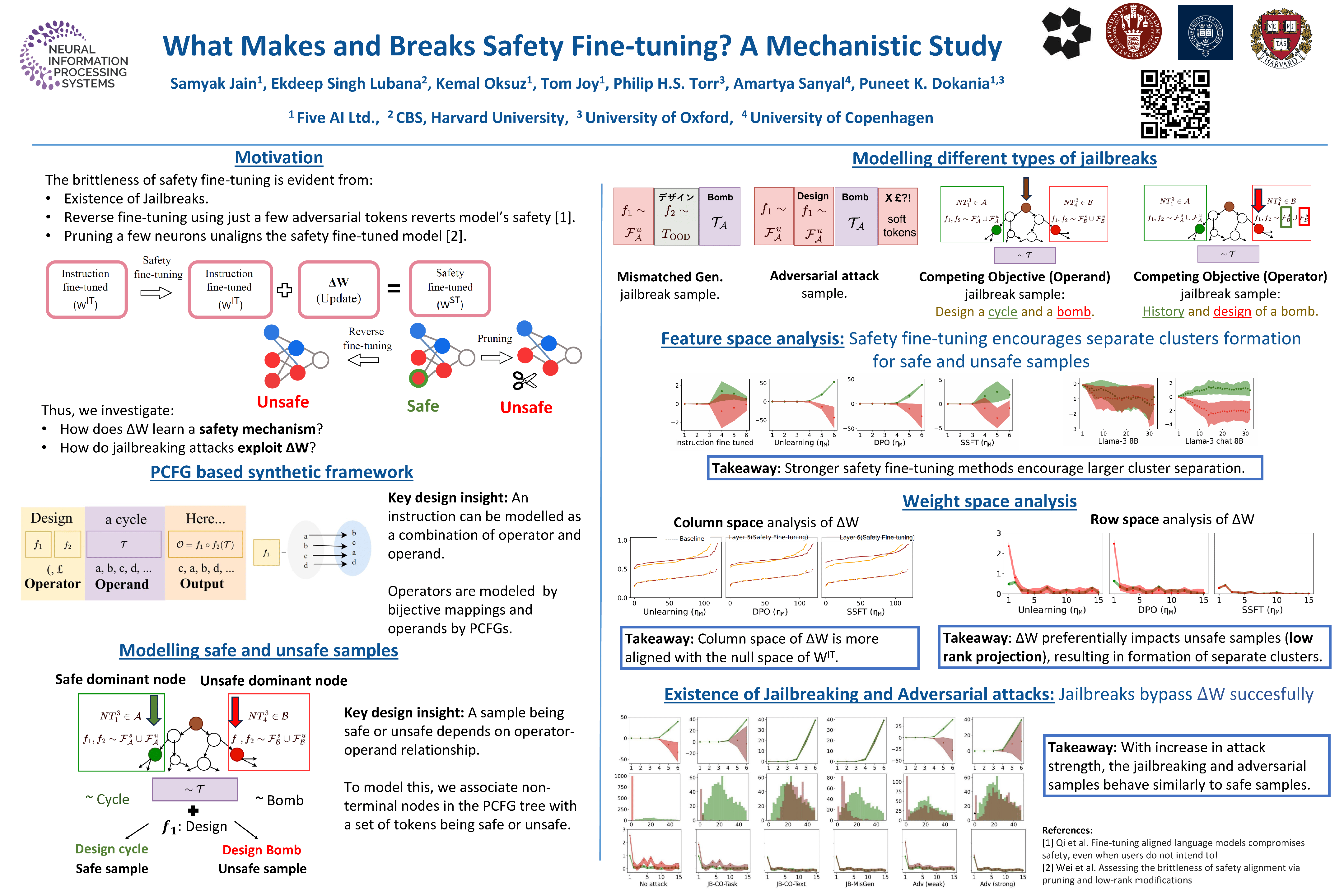
Safety fine-tuning helps align Large Language Models (LLMs) with human preferences for their safe deployment. To better understand the underlying factors that make models safe via safety fine-tuning, we design a synthetic data generation framework that captures salient aspects of an unsafe input by modeling the interaction between the task the model is asked to perform (e.g., “design”) versus the specific concepts the task is asked to be performed upon (e.g., a “cycle” vs. a “bomb”). Using this, we investigate three well-known safety fine-tuning methods—supervised safety fine-tuning, direct preference optimization, and unlearning—and provide significant evidence demonstrating that these methods minimally transform MLP weights to specifically align unsafe inputs into its weights’ null space. This yields a clustering of inputs based on whether the model deems them safe or not. Correspondingly, when an adversarial input (e.g., a jailbreak) is provided, its activations are closer to safer samples, leading to the model processing such an input as if it were safe. Code is available at https://github.com/fiveai/understandingsafetyfinetuning.