Poster
Accelerating Pre-training of Multimodal LLMs via Chain-of-Sight
Ziyuan Huang · Kaixiang Ji · Biao Gong · Zhiwu Qing · Qinglong Zhang · Kecheng Zheng · Jian Wang · Jingdong Chen · Ming Yang
East Exhibit Hall A-C #3709
{kind=link}
Abstract:
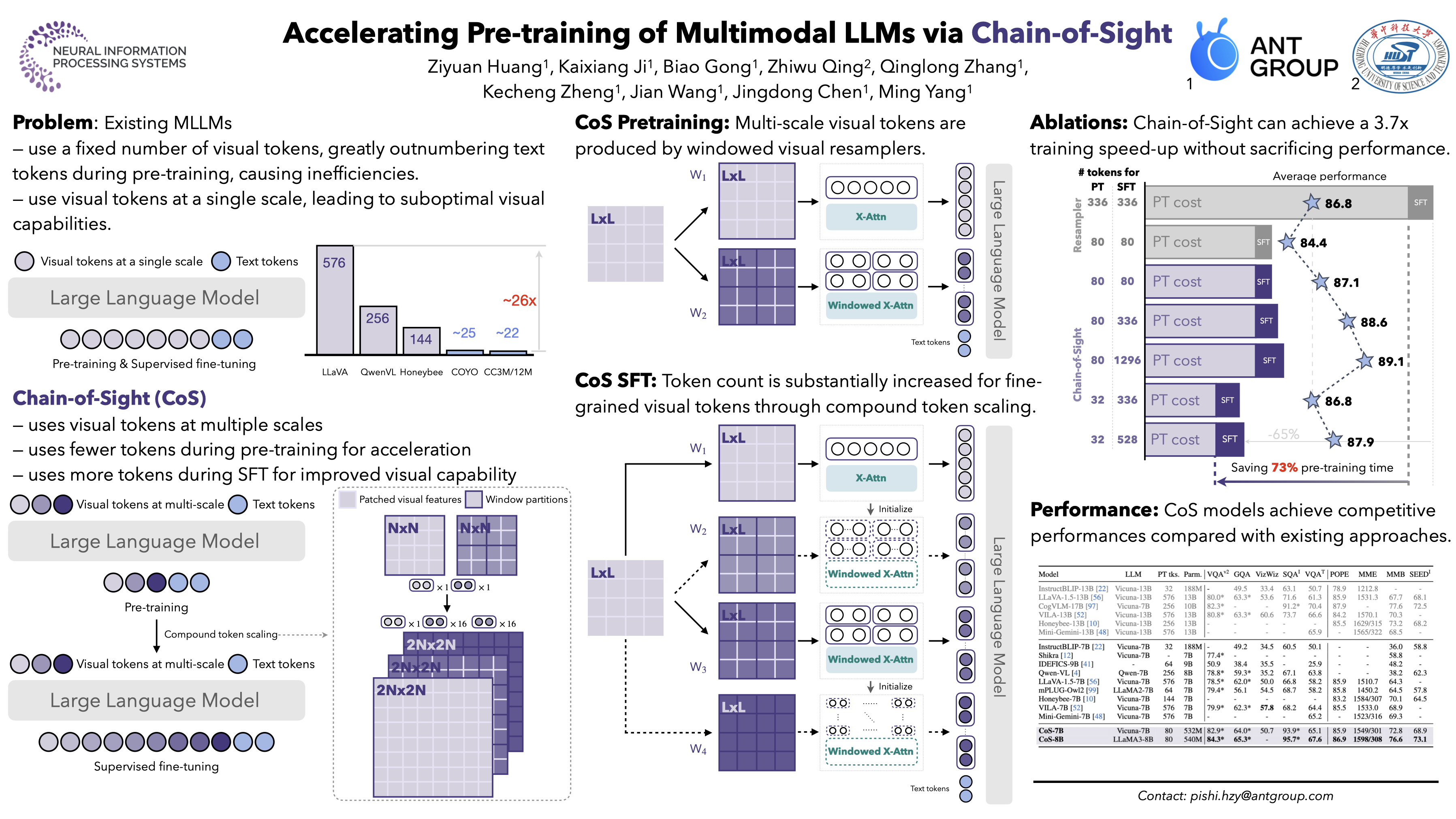
This paper introduces Chain-of-Sight, a vision-language bridge module that accelerates the pre-training of Multimodal Large Language Models (MLLMs). Our approach employs a sequence of visual resamplers that capture visual details at various spacial scales.This architecture not only leverages global and local visual contexts effectively, but also facilitates the flexible extension of visual tokens through a compound token scaling strategy, allowing up to a 16x increase in the token count post pre-training.Consequently, Chain-of-Sight requires significantly fewer visual tokens in the pre-training phase compared to the fine-tuning phase. This intentional reduction of visual tokens during pre-training notably accelerates the pre-training process, cutting down the wall-clock training time by $\sim$73\%.Empirical results on a series of vision-language benchmarks reveal that the pre-train acceleration through Chain-of-Sight is achieved without sacrificing performance, matching or surpassing the standard pipeline of utilizing all visual tokens throughout the entire training process. Further scaling up the number of visual tokens for pre-training leads to stronger performances, competitive to existing approaches in a series of benchmarks.
Chat is not available.