Poster
Reinforcement Learning with Adaptive Regularization for Safe Control of Critical Systems
Haozhe Tian · Homayoun Hamedmoghadam · Robert Shorten · Pietro Ferraro
West Ballroom A-D #6611
{kind=link}
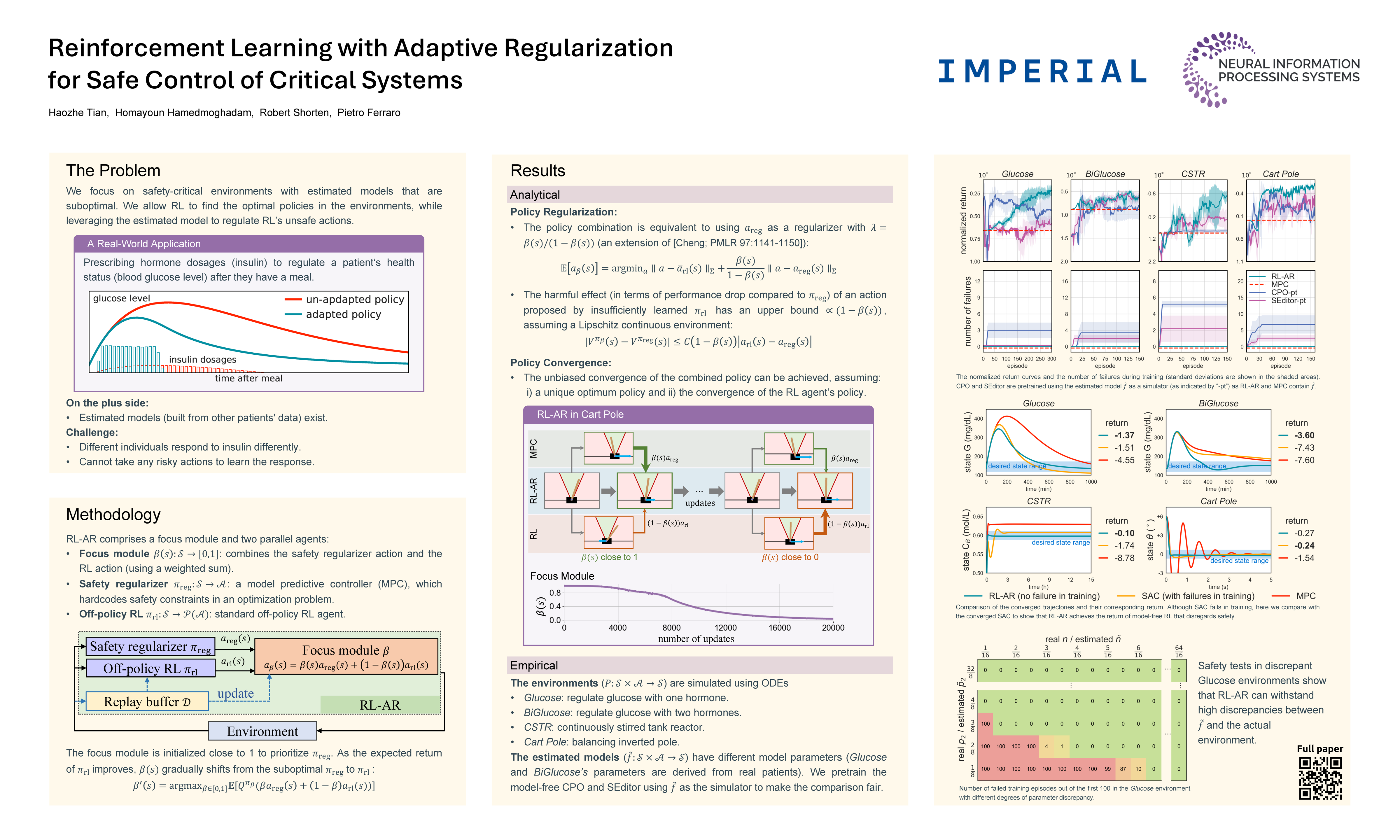
Reinforcement Learning (RL) is a powerful method for controlling dynamic systems, but its learning mechanism can lead to unpredictable actions that undermine the safety of critical systems. Here, we propose RL with Adaptive Regularization (RL-AR), an algorithm that enables safe RL exploration by combining the RL policy with a policy regularizer that hard-codes the safety constraints. RL-AR performs policy combination via a "focus module," which determines the appropriate combination depending on the state—relying more on the safe policy regularizer for less-exploited states while allowing unbiased convergence for well-exploited states. In a series of critical control applications, we demonstrate that RL-AR not only ensures safety during training but also achieves a return competitive with the standards of model-free RL that disregards safety.