Poster
What makes unlearning hard and what to do about it
KAIRAN ZHAO · Meghdad Kurmanji · George-Octavian Bărbulescu · Eleni Triantafillou · Peter Triantafillou
East Exhibit Hall A-C #2310
{kind=link}
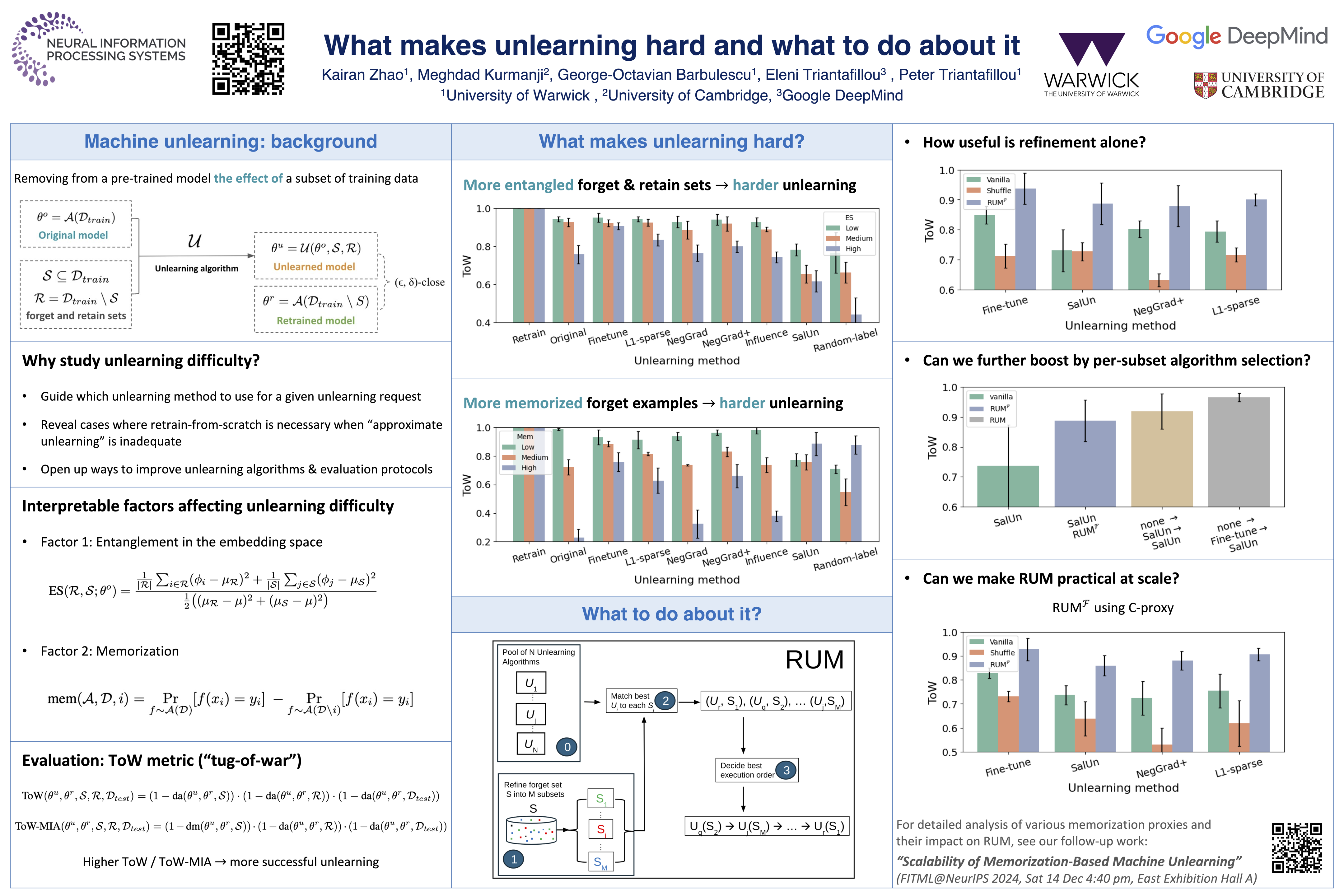
Machine unlearning is the problem of removing the effect of a subset of training data (the ``forget set'') from a trained model without damaging the model's utility e.g. to comply with users' requests to delete their data, or remove mislabeled, poisoned or otherwise problematic data.With unlearning research still being at its infancy, many fundamental open questions exist: Are there interpretable characteristics of forget sets that substantially affect the difficulty of the problem? How do these characteristics affect different state-of-the-art algorithms?With this paper, we present the first investigation aiming to answer these questions. We identify two key factors affecting unlearning difficulty and the performance of unlearning algorithms. Evaluation on forget sets that isolate these identified factors reveals previously-unknown behaviours of state-of-the-art algorithms that don't materialize on random forget sets.Based on our insights, we develop a framework coined Refined-Unlearning Meta-algorithm (RUM) that encompasses: (i) refining the forget set into homogenized subsets, according to different characteristics; and (ii) a meta-algorithm that employs existing algorithms to unlearn each subset and finally delivers a model that has unlearned the overall forget set. We find that RUM substantially improves top-performing unlearning algorithms. Overall, we view our work as an important step in (i) deepening our scientific understanding of unlearning and (ii) revealing new pathways to improving the state-of-the-art.