Poster
B-cosification: Transforming Deep Neural Networks to be Inherently Interpretable
Shreyash Arya · Sukrut Rao · Moritz Böhle · Bernt Schiele
East Exhibit Hall A-C #3108
{kind=link}
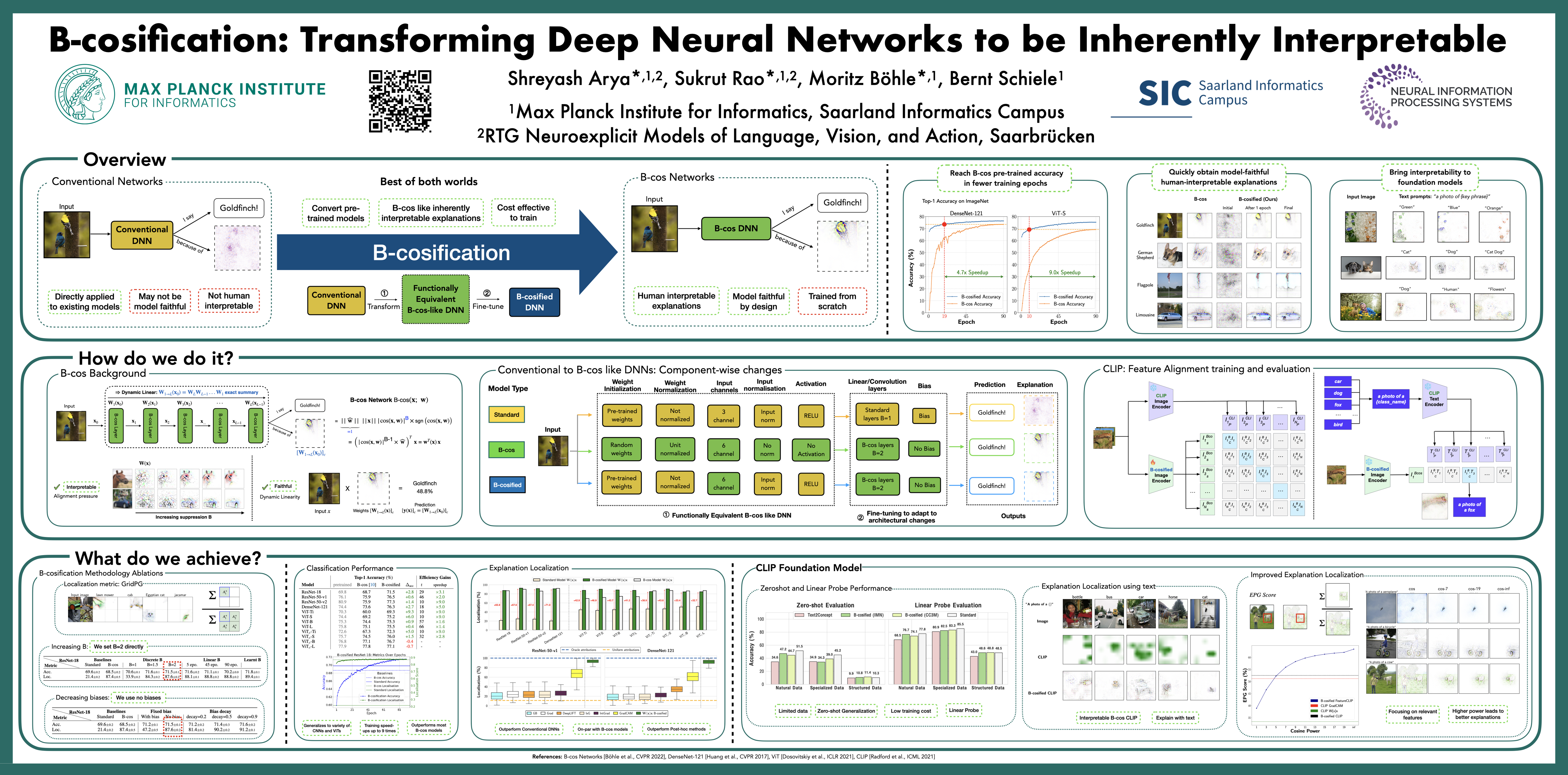
B-cos Networks have been shown to be effective for obtaining highly human interpretable explanations of model decisions by architecturally enforcing stronger alignment between inputs and weight. B-cos variants of convolutional networks (CNNs) and vision transformers (ViTs), which primarily replace linear layers with B-cos transformations, perform competitively to their respective standard variants while also yielding explanations that are faithful by design. However, it has so far been necessary to train these models from scratch, which is increasingly infeasible in the era of large, pre-trained foundation models. In this work, inspired by the architectural similarities in standard DNNs and B-cos networks, we propose ‘B-cosification’, a novel approach to transform existing pre-trained models to become inherently interpretable. We perform a thorough study of design choices to perform this conversion, both for convolutional neural networks and vision transformers. We find that B-cosification can yield models that are on par with B-cos models trained from scratch in terms of interpretability, while often outperforming them in terms of classification performance at a fraction of the training cost. Subsequently, we apply B-cosification to a pretrained CLIP model, and show that, even with limited data and compute cost, we obtain a B-cosified version that is highly interpretable and competitive on zero shot performance across a variety of datasets. We release ourcode and pre-trained model weights at https://github.com/shrebox/B-cosification.