Poster
Trajectory Data Suffices for Statistically Efficient Learning in Offline RL with Linear $q^\pi$-Realizability and Concentrability
Volodymyr Tkachuk · Gellert Weisz · Csaba Szepesvari
West Ballroom A-D #6909
{kind=link}
Abstract:
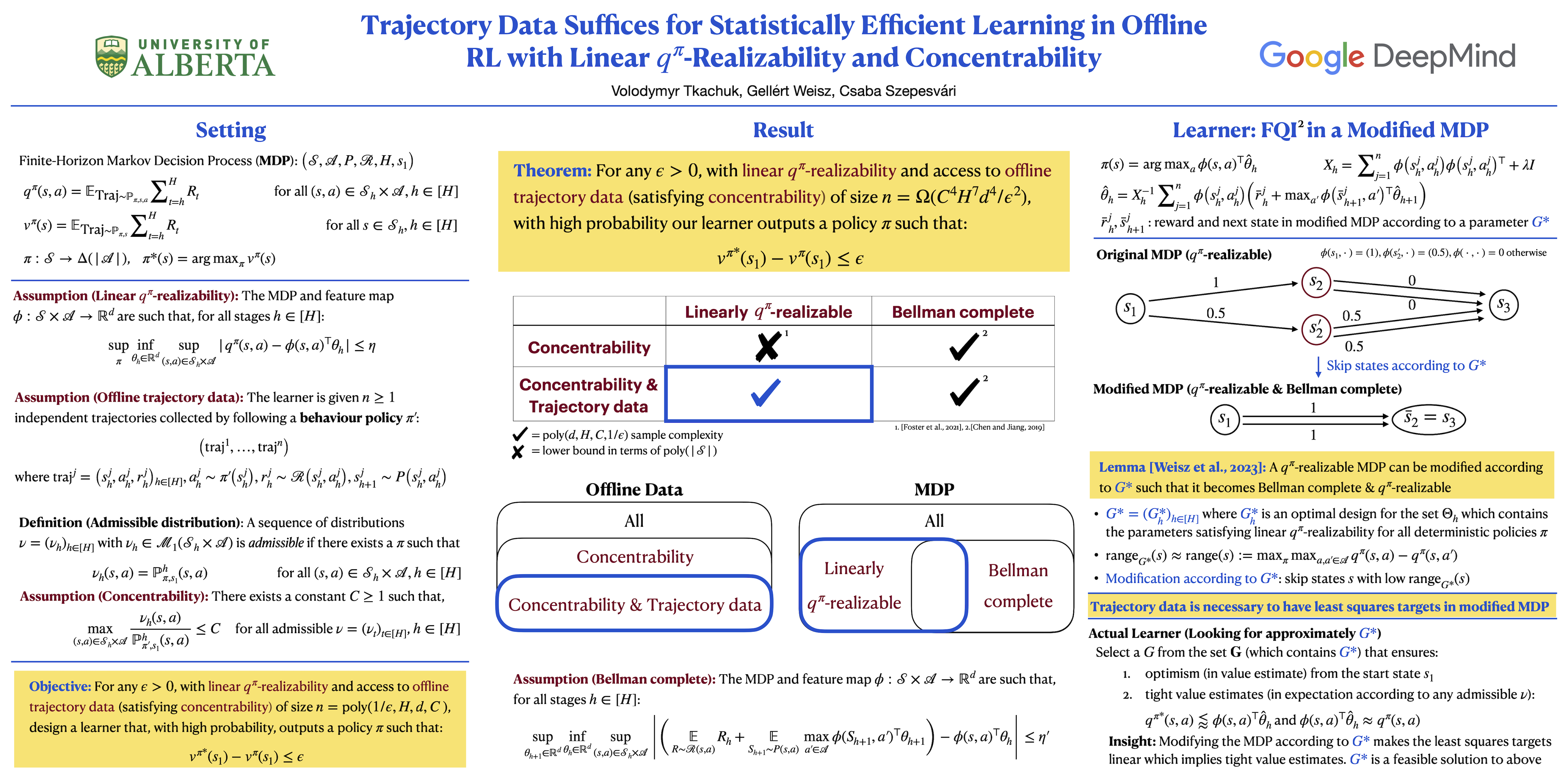
We consider offline reinforcement learning (RL) in $H$-horizon Markov decision processes (MDPs) under the linear $q^\pi$-realizability assumption, where the action-value function of every policy is linear with respect to a given $d$-dimensional feature function. The hope in this setting is that learning a good policy will be possible without requiring a sample size that scales with the number of states in the MDP. Foster et al. [2021] have shown this to be impossible even under $\text{\textit{concentrability}}$, a data coverage assumption where a coefficient $C_\text{conc}$ bounds the extent to which the state-action distribution of any policy can veer off the data distribution. However, the data in this previous work was in the form of a sequence of individual transitions. This leaves open the question of whether the negative result mentioned could be overcome if the data was composed of sequences of full trajectories. In this work we answer this question positively by proving that with trajectory data, a dataset of size $\text{poly}(d,H,C_\text{conc})/\epsilon^2$ is sufficient for deriving an $\epsilon$-optimal policy, regardless of the size of the state space. The main tool that makes this result possible is due to Weisz et al. [2023], who demonstrate that linear MDPs can be used to approximate linearly $q^\pi$-realizable MDPs. The connection to trajectory data is that the linear MDP approximation relies on "skipping" over certain states. The associated estimation problems are thus easy when working with trajectory data, while they remain nontrivial when working with individual transitions. The question of computational efficiency under our assumptions remains open.
Chat is not available.