Poster
Leveraging Visual Tokens for Extended Text Contexts in Multi-Modal Learning
Alex Jinpeng Wang · Linjie Li · Yiqi Lin · Min Li · Lijuan Wang · Mike Zheng Shou
East Exhibit Hall A-C #3809
{kind=link}
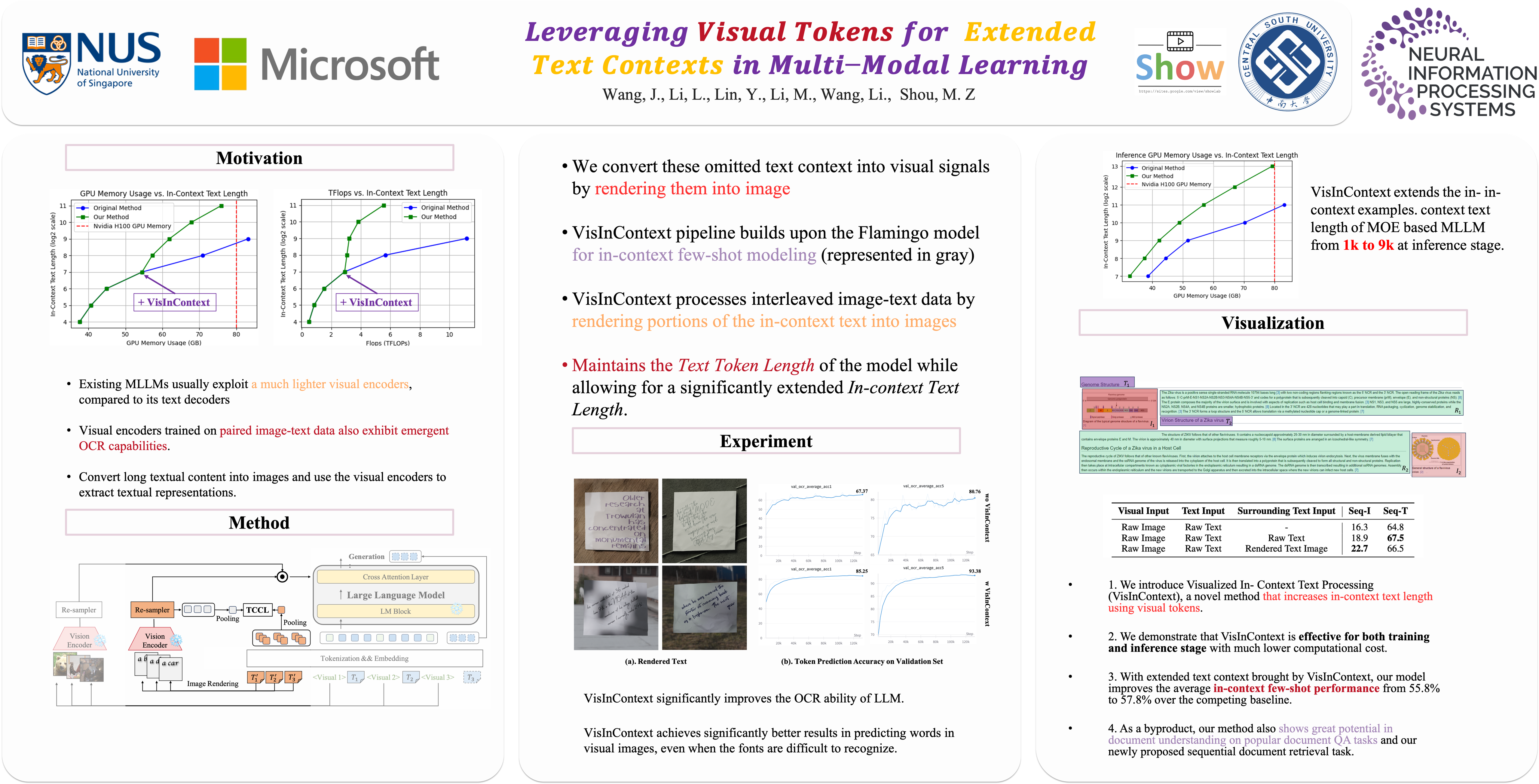
Training models with longer in-context lengths is a significant challenge for multimodal machine learning due to substantial GPU memory and computational costs. This exploratory study does not present state-of-the-art models; rather, it introduces an innovative method designed to increase in-context text length in multi-modality large language models (MLLMs) efficiently. We present \ModelFullName (\ModelName), which processes long in-context text using visual tokens. This technique significantly reduces GPU memory usage and floating point operations (FLOPs). For instance, our method expands the pre-training in-context length from 256 to 2048 tokens with fewer FLOPs for a 56 billion parameter MOE model. Experimental results demonstrate that \ModelName enhances OCR capabilities and delivers superior performance on common downstream benchmarks for in-context few-shot evaluation. Additionally, \ModelName proves effective for long context inference, achieving results comparable to full text input while maintaining computational efficiency.