Poster
OneBit: Towards Extremely Low-bit Large Language Models
Yuzhuang Xu · Xu Han · Zonghan Yang · Shuo Wang · Qingfu Zhu · Zhiyuan Liu · Weidong Liu · Wanxiang Che
East Exhibit Hall A-C #3103
{kind=link}
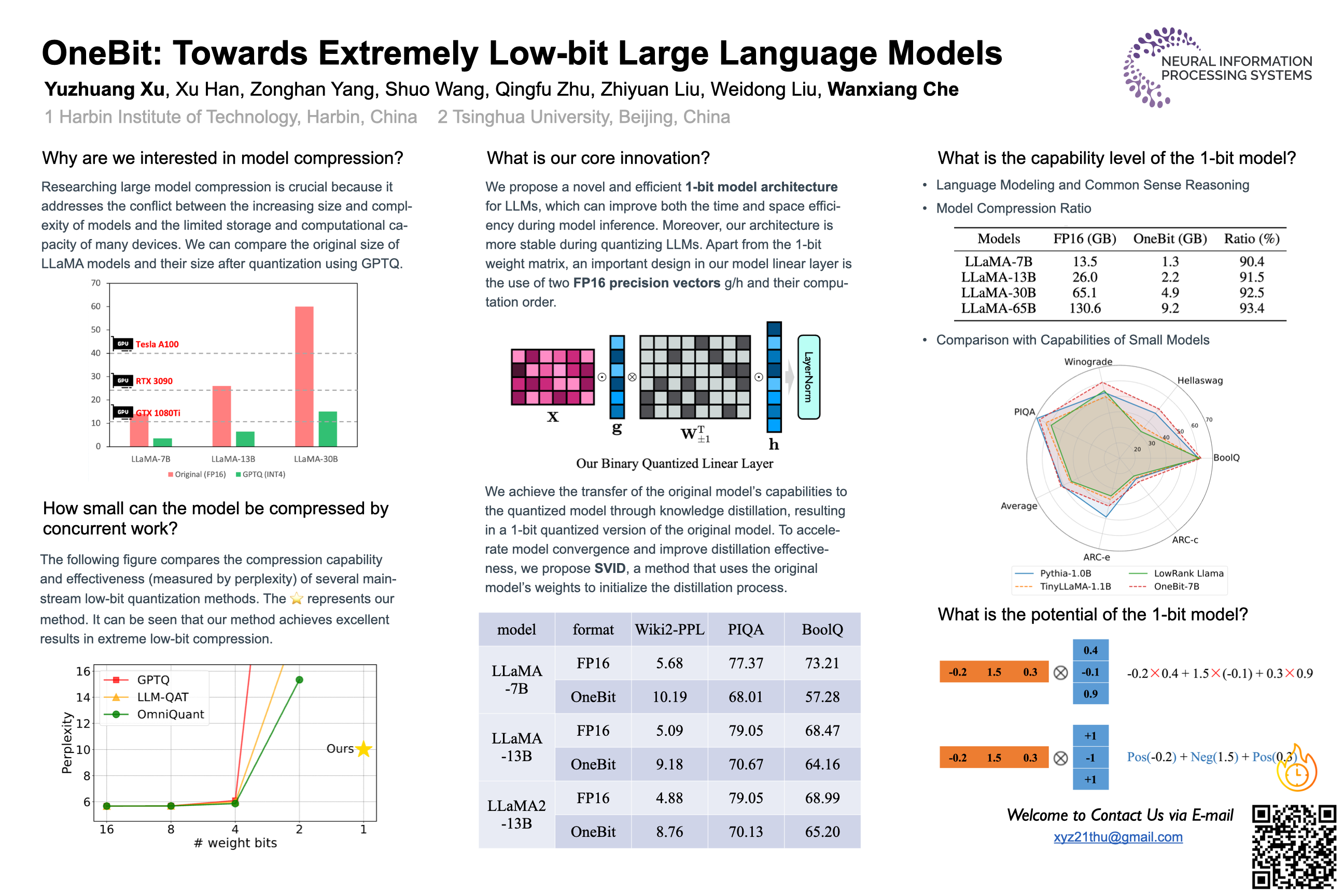
Model quantification uses low bit-width values to represent the weight matrices of existing models to be quantized, which is a promising approach to reduce both storage and computational overheads of deploying highly anticipated LLMs. However, current quantization methods suffer severe performance degradation when the bit-width is extremely reduced, and thus focus on utilizing 4-bit or 8-bit values to quantize models. This paper boldly quantizes the weight matrices of LLMs to 1-bit, paving the way for the extremely low bit-width deployment of LLMs. For this target, we introduce a 1-bit model compressing framework named OneBit, including a novel 1-bit parameter representation method to better quantize LLMs as well as an effective parameter initialization method based on matrix decomposition to improve the convergence speed of the quantization framework. Sufficient experimental results indicate that OneBit achieves good performance (at least 81% of the non-quantized performance on LLaMA models) with robust training processes when only using 1-bit weight matrices.