Poster
MetaAligner: Towards Generalizable Multi-Objective Alignment of Language Models
Kailai Yang · Zhiwei Liu · Qianqian Xie · Jimin Huang · Tianlin Zhang · Sophia Ananiadou
East Exhibit Hall A-C #3110
{kind=link}
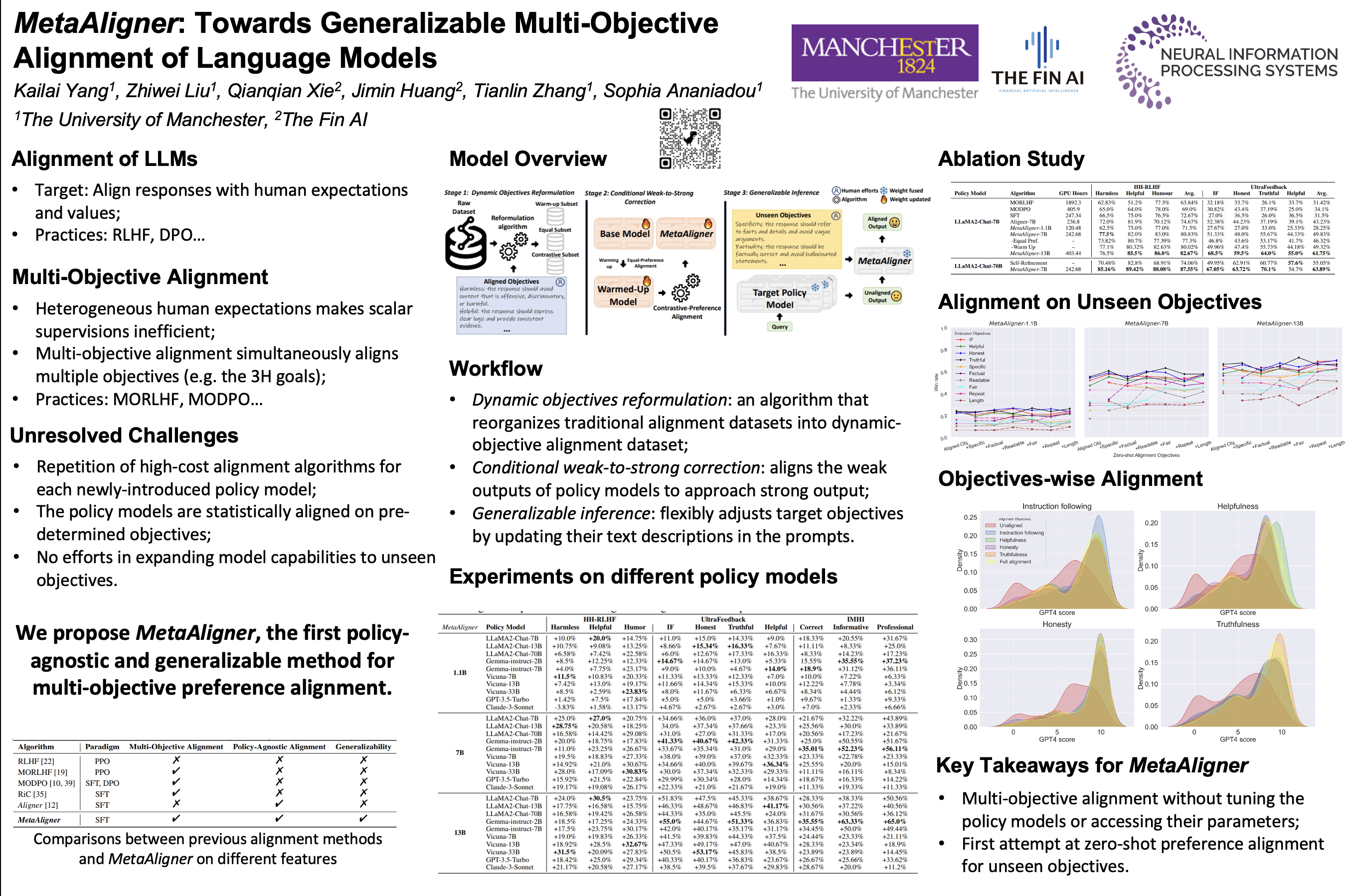
Recent advancements in large language models (LLMs) focus on aligning to heterogeneous human expectations and values via multi-objective preference alignment. However, existing methods are dependent on the policy model parameters, which require high-cost repetition of their alignment algorithms for each new policy model, and they cannot expand to unseen objectives due to their static alignment objectives. In this work, we propose Meta-Objective Aligner (MetaAligner), the first policy-agnostic and generalizable method for multi-objective preference alignment.MetaAligner models multi-objective alignment into three stages: (1) dynamic objectives reformulation algorithm reorganizes traditional alignment datasets to supervise the model on performing flexible alignment across different objectives; (2) conditional weak-to-strong correction paradigm aligns the weak outputs of fixed policy models to approach strong outputs with higher preferences in the corresponding alignment objectives, enabling plug-and-play inferences on any policy models, which significantly reduces training costs and facilitates alignment on close-source policy models; (3) generalizable inference method flexibly adjusts target objectives by updating their text descriptions in the prompts, facilitating generalizable alignment to unseen objectives.Experimental results show that MetaAligner achieves significant and balanced improvements in multi-objective alignments on 10 state-of-the-art policy models, and saves up to 93.63% of GPU training hours compared to previous alignment methods. The model also effectively aligns unseen objectives, marking the first step towards generalizable multi-objective preference alignment.