Poster
SLIM: Style-Linguistics Mismatch Model for Generalized Audio Deepfake Detection
Yi Zhu · Surya Koppisetti · Trang Tran · Gaurav Bharaj
East Exhibit Hall A-C #3410
{kind=link}
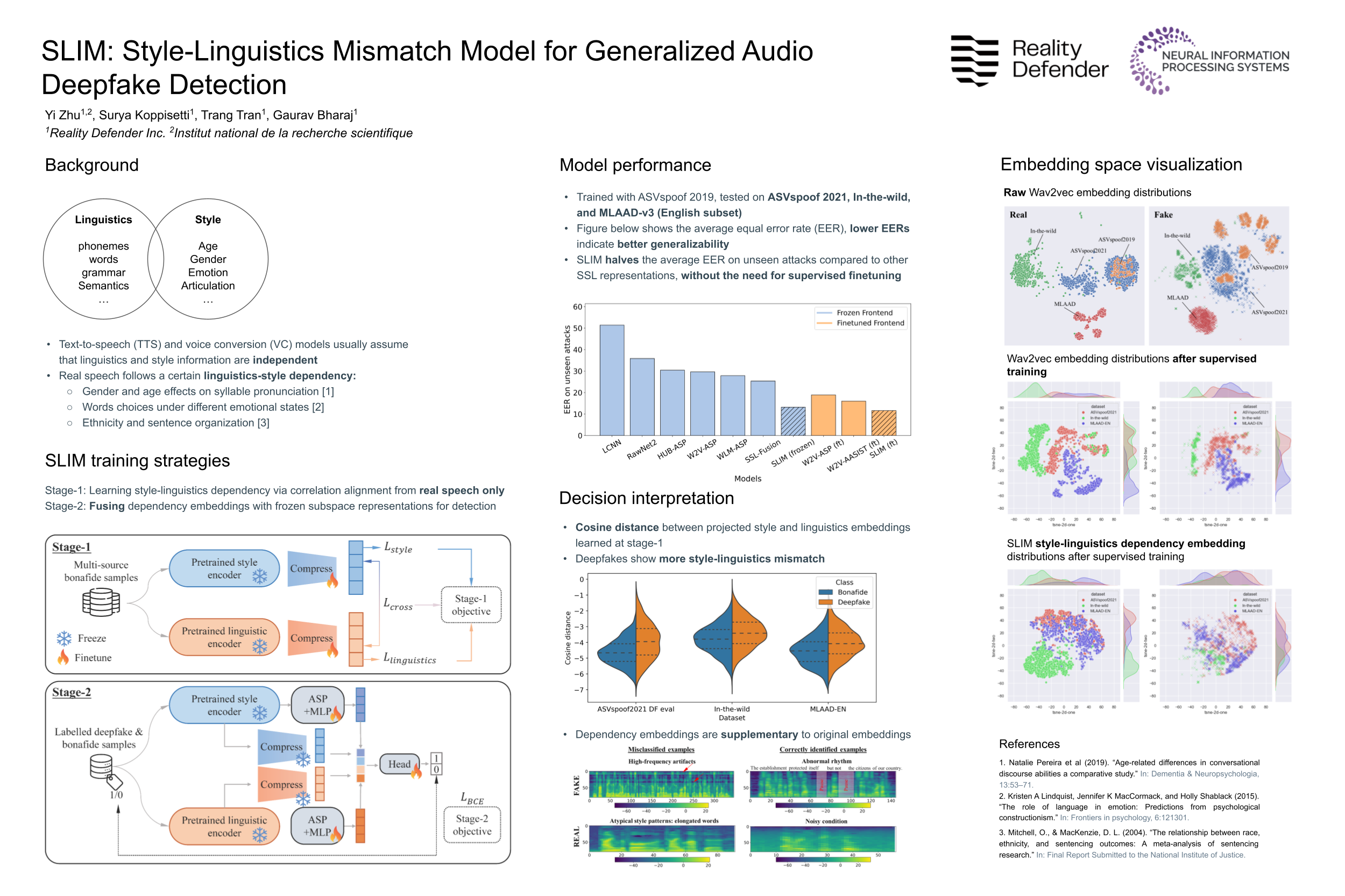
Audio deepfake detection (ADD) is crucial to combat the misuse of speech synthesized by generative AI models. Existing ADD models suffer from generalization issues to unseen attacks, with a large performance discrepancy between in-domain and out-of-domain data. Moreover, the black-box nature of existing models limits their use in real-world scenarios, where explanations are required for model decisions. To alleviate these issues, we introduce a new ADD model that explicitly uses the Style-LInguistics Mismatch (SLIM) in fake speech to separate them from real speech. SLIM first employs self-supervised pretraining on only real samples to learn the style-linguistics dependency in the real class. The learned features are then used in complement with standard pretrained acoustic features (e.g., Wav2vec) to learn a classifier on the real and fake classes. When the feature encoders are frozen, SLIM outperforms benchmark methods on out-of-domain datasets while achieving competitive results on in-domain data. The features learned by SLIM allow us to quantify the (mis)match between style and linguistic content in a sample, hence facilitating an explanation of the model decision.