Poster
VB-LoRA: Extreme Parameter Efficient Fine-Tuning with Vector Banks
Yang Li · Shaobo Han · Jonathan Shihao Ji
East Exhibit Hall A-C #2009
{kind=link}
Abstract:
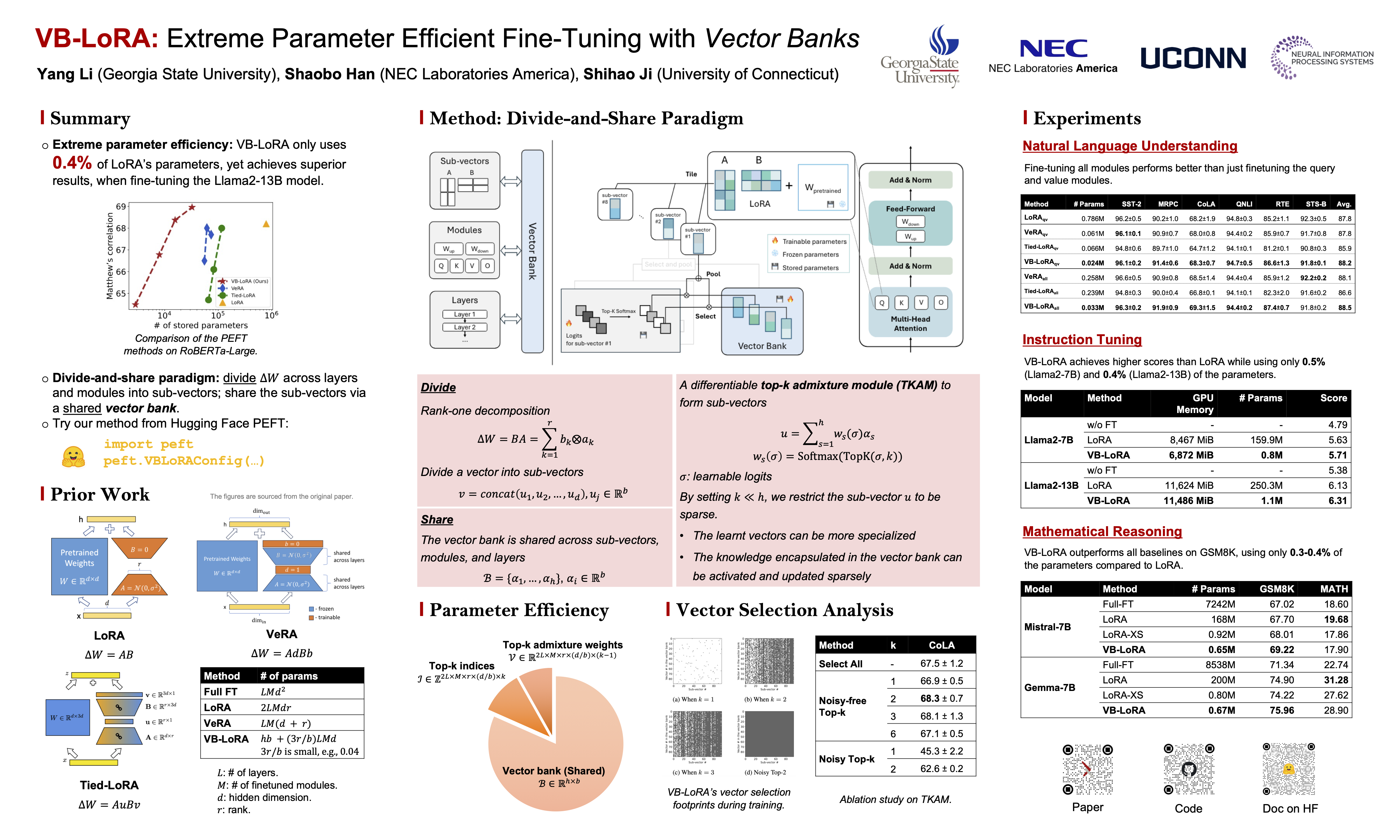
As the adoption of large language models increases and the need for per-user or per-task model customization grows, the parameter-efficient fine-tuning (PEFT) methods, such as low-rank adaptation (LoRA) and its variants, incur substantial storage and transmission costs. To further reduce stored parameters, we introduce a "divide-and-share" paradigm that breaks the barriers of low-rank decomposition across matrix dimensions, modules, and layers by sharing parameters globally via a vector bank. As an instantiation of the paradigm to LoRA, our proposed VB-LoRA composites all the low-rank matrices of LoRA from a shared vector bank with a differentiable top-$k$ admixture module. VB-LoRA achieves extreme parameter efficiency while maintaining comparable or better performance compared to state-of-the-art PEFT methods. Extensive experiments demonstrate the effectiveness of VB-LoRA on natural language understanding, natural language generation, instruction tuning, and mathematical reasoning tasks. When fine-tuning the Llama2-13B model, VB-LoRA only uses 0.4% of LoRA's stored parameters, yet achieves superior results. Our source code is available at https://github.com/leo-yangli/VB-LoRA. This method has been merged into the Hugging Face PEFT package.
Chat is not available.