Poster
Interpreting and Analysing CLIP's Zero-Shot Image Classification via Mutual Knowledge
Fawaz Sammani · Nikos Deligiannis
East Exhibit Hall A-C #3201
{kind=link}
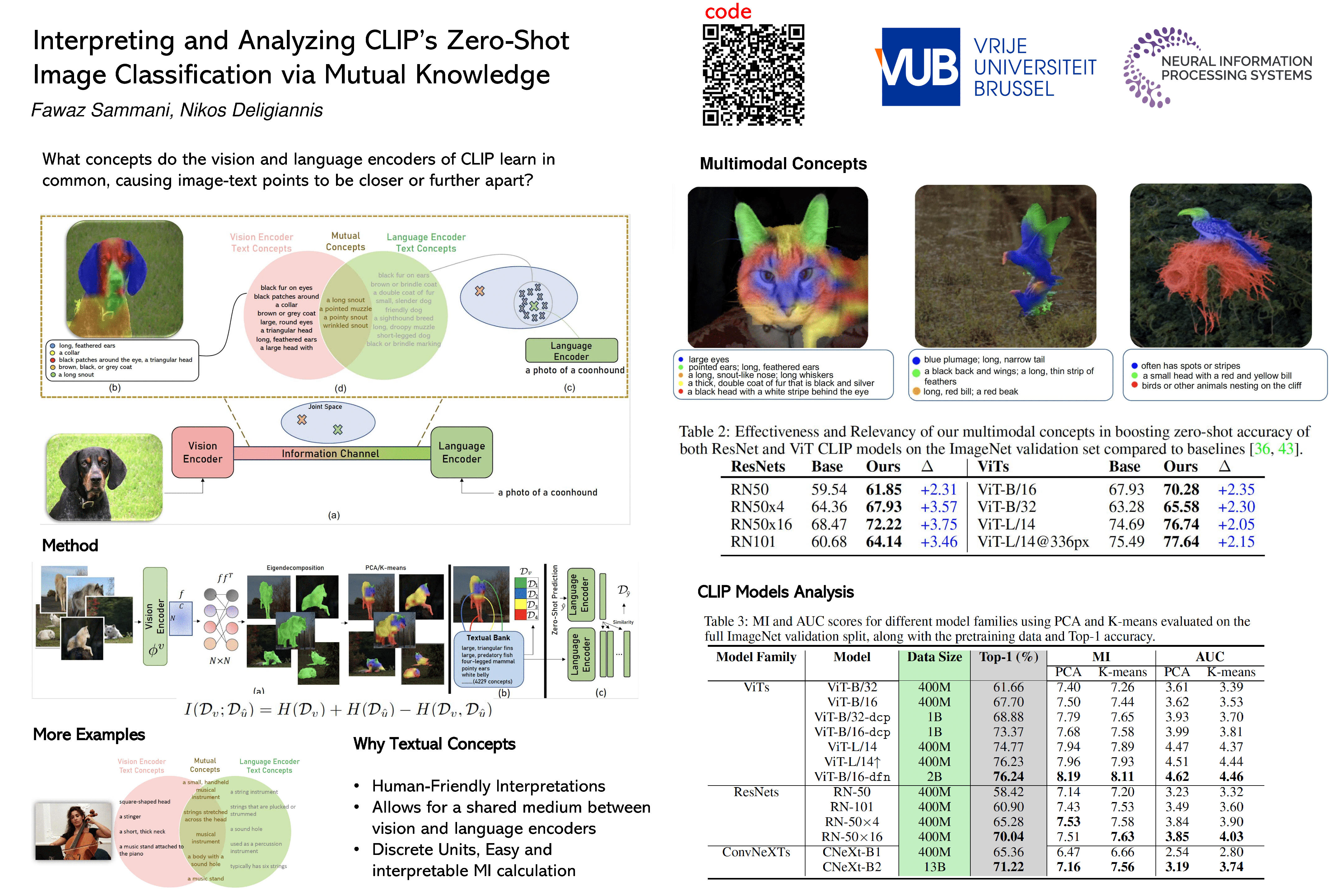
Contrastive Language-Image Pretraining (CLIP) performs zero-shot image classification by mapping images and textual class representation into a shared embedding space, then retrieving the class closest to the image. This work provides a new approach for interpreting CLIP models for image classification from the lens of mutual knowledge between the two modalities. Specifically, we ask: what concepts do both vision and language CLIP encoders learn in common that influence the joint embedding space, causing points to be closer or further apart? We answer this question via an approach of textual concept-based explanations, showing their effectiveness, and perform an analysis encompassing a pool of 13 CLIP models varying in architecture, size and pretraining datasets. We explore those different aspects in relation to mutual knowledge, and analyze zero-shot predictions. Our approach demonstrates an effective and human-friendly way of understanding zero-shot classification decisions with CLIP.