Poster
LOVA3: Learning to Visual Question Answering, Asking and Assessment
Henry Hengyuan Zhao · Pan Zhou · Difei Gao · Zechen Bai · Mike Zheng Shou
East Exhibit Hall A-C #3711
{kind=link}
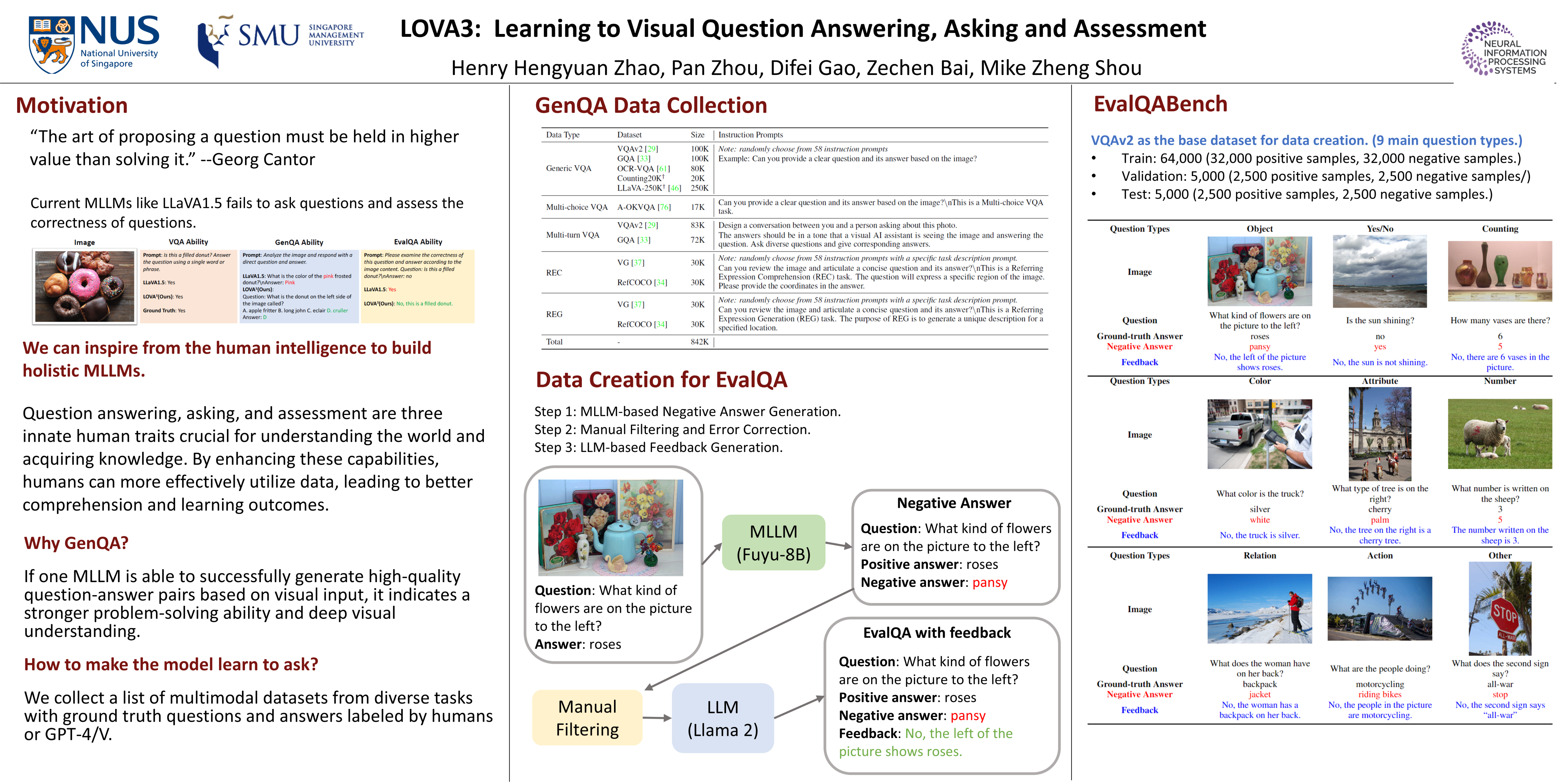
Question answering, asking, and assessment are three innate human traits crucial for understanding the world and acquiring knowledge. By enhancing these capabilities, humans can more effectively utilize data, leading to better comprehension and learning outcomes. However, current Multimodal Large Language Models (MLLMs) primarily focus on question answering, often neglecting the full potential of questioning and assessment skills. In this study, we introduce LOVA3, an innovative framework named ``Learning tO Visual Question Answering, Asking and Assessment,'' designed to equip MLLMs with these additional capabilities. Our approach involves the creation of two supplementary training tasks GenQA and EvalQA, aiming at fostering the skills of asking and assessing questions in the context of images. To develop the questioning ability, we compile a comprehensive set of multimodal foundational tasks. For assessment, we introduce a new benchmark called EvalQABench, comprising 64,000 training samples (split evenly between positive and negative samples) and 5,000 testing samples. We posit that enhancing MLLMs with the capabilities to answer, ask, and assess questions will enhance their multimodal comprehension, ultimately improving overall performance. To validate this hypothesis, we train MLLMs using the LOVA3 framework and evaluate them on a range of multimodal datasets and benchmarks. Our results demonstrate consistent performance gains, underscoring the critical role of these additional tasks in fostering comprehensive intelligence in MLLMs.