Poster
Interpreting Learned Feedback Patterns in Large Language Models
Luke Marks · Amir Abdullah · Clement Neo · Rauno Arike · David Krueger · Philip Torr · Fazl Barez
East Exhibit Hall A-C #3301
{kind=link}
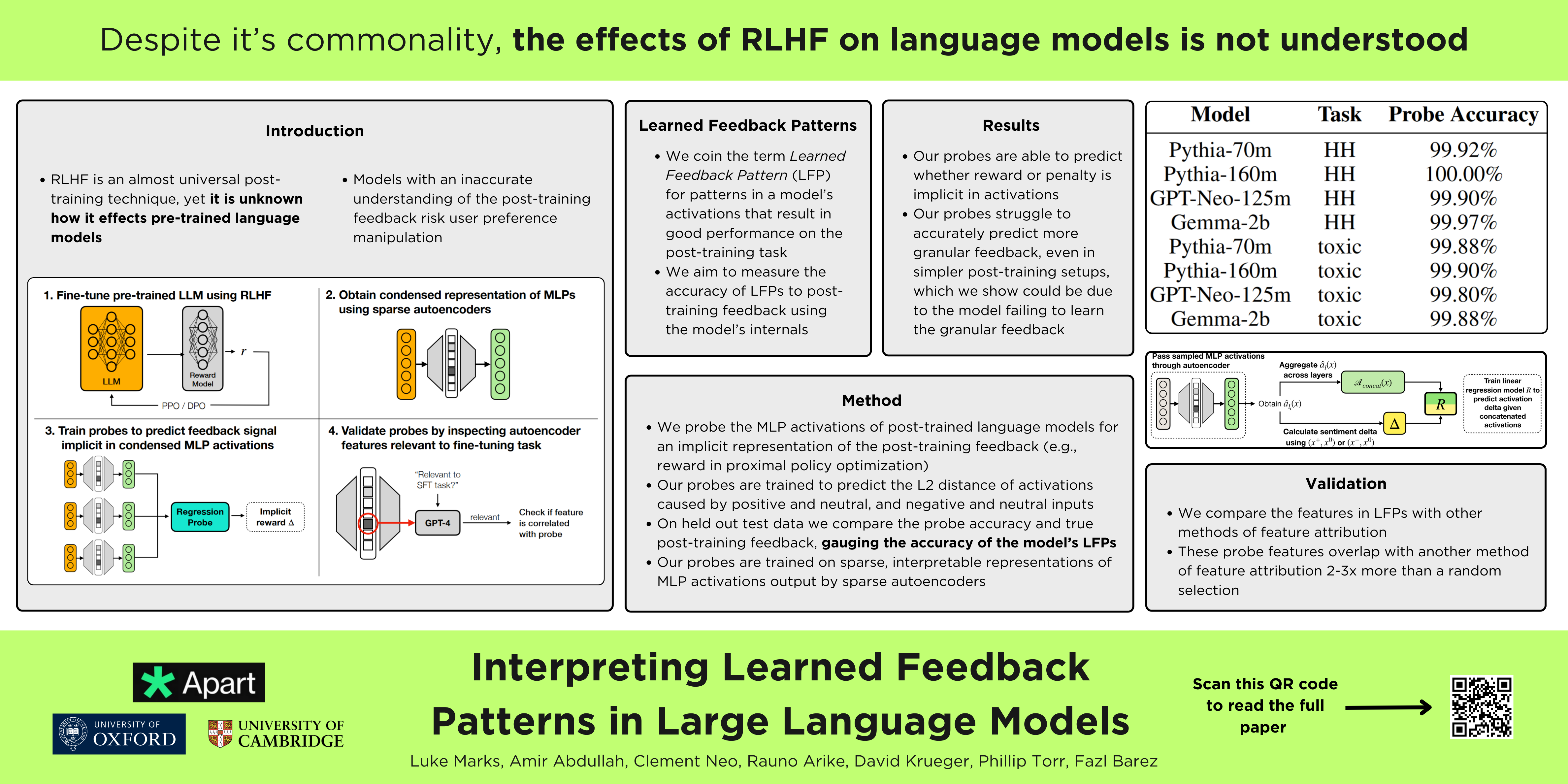
Reinforcement learning from human feedback (RLHF) is widely used to train large language models (LLMs). However, it is unclear whether LLMs accurately learn the underlying preferences in human feedback data. We coin the term Learned Feedback Pattern (LFP) for patterns in an LLM's activations learned during RLHF that improve its performance on the fine-tuning task. We hypothesize that LLMs with LFPs accurately aligned to the fine-tuning feedback exhibit consistent activation patterns for outputs that would have received similar feedback during RLHF. To test this, we train probes to estimate the feedback signal implicit in the activations of a fine-tuned LLM. We then compare these estimates to the true feedback, measuring how accurate the LFPs are to the fine-tuning feedback. Our probes are trained on a condensed, sparse and interpretable representation of LLM activations, making it easier to correlate features of the input with our probe's predictions. We validate our probes by comparing the neural features they correlate with positive feedback inputs against the features GPT-4 describes and classifies as related to LFPs. Understanding LFPs can help minimize discrepancies between LLM behavior and training objectives, which is essential for the safety and alignment of LLMs.