Poster
CIFD: Controlled Information Flow to Enhance Knowledge Distillation
Yashas Malur Saidutta · Rakshith Sharma Srinivasa · Jaejin Cho · Ching-Hua Lee · Chouchang Yang · Yilin Shen · Hongxia Jin
East Exhibit Hall A-C #2206
{kind=link}
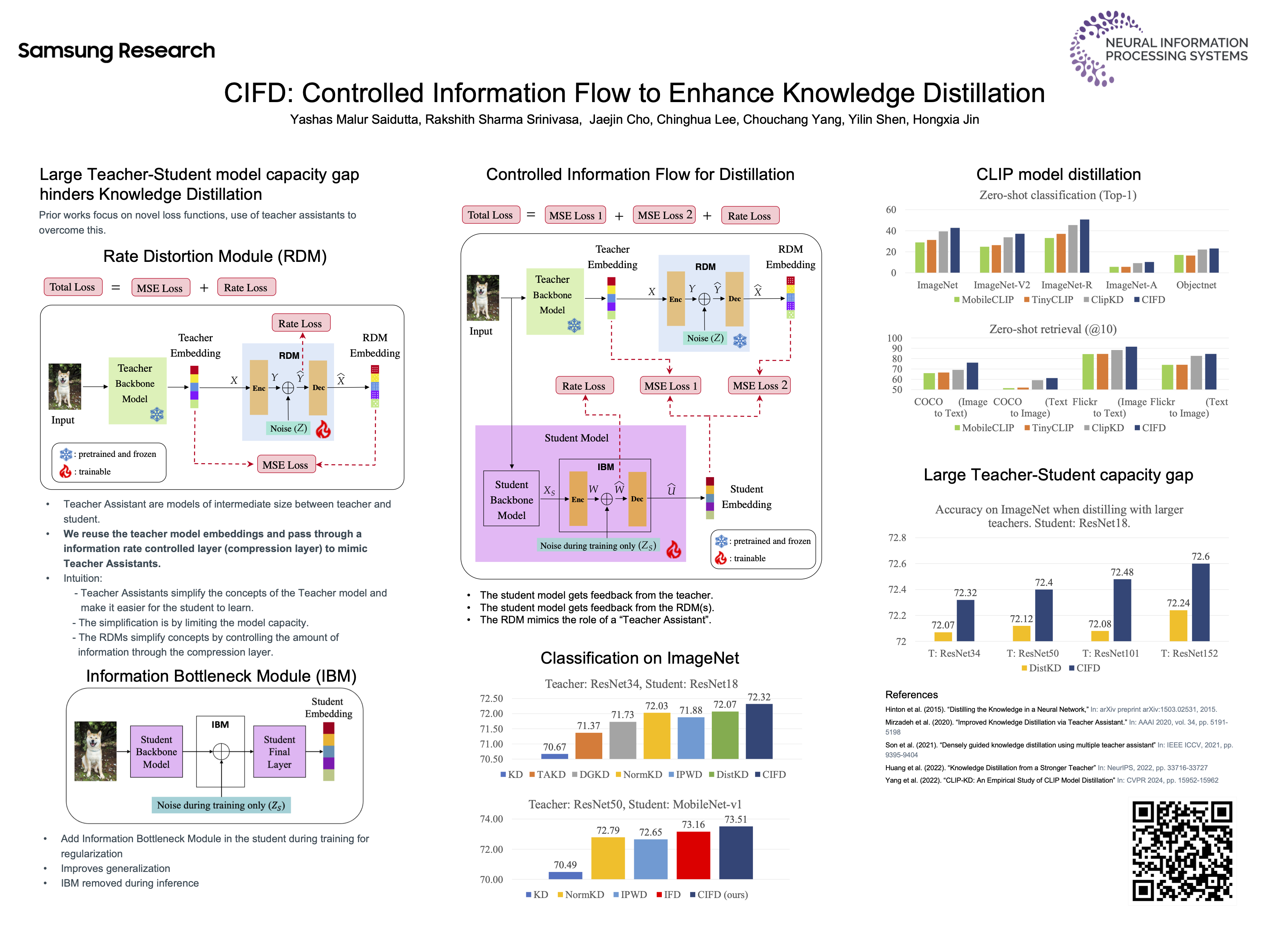
Knowledge Distillation is the mechanism by which the insights gained from a larger teacher model are transferred to a smaller student model. However, the transfer suffers when the teacher model is significantly larger than the student. To overcome this, prior works have proposed training intermediately sized models, Teacher Assistants (TAs) to help the transfer process. However, training TAs is expensive, as training these models is a knowledge transfer task in itself. Further, these TAs are larger than the student model and training them especially in large data settings can be computationally intensive. In this paper, we propose a novel framework called Controlled Information Flow for Knowledge Distillation (CIFD) consisting of two components. First, we propose a significantly smaller alternatives to TAs, the Rate-Distortion Module (RDM) which uses the teacher's penultimate layer embedding and a information rate-constrained bottleneck layer to replace the Teacher Assistant model. RDMs are smaller and easier to train than TAs, especially in large data regimes, since they operate on the teacher embeddings and do not need to relearn low level input feature extractors. Also, by varying the information rate across the bottleneck, RDMs can replace TAs of different sizes. Secondly, we propose the use of Information Bottleneck Module in the student model, which is crucial for regularization in the presence of a large number of RDMs. We show comprehensive state-of-the-art results of the proposed method over large datasets like Imagenet. Further, we show the significant improvement in distilling CLIP like models over a huge 12M image-text dataset. It outperforms CLIP specialized distillation methods across five zero-shot classification datasets and two zero-shot image-text retrieval datasets.