Poster
Temporally Consistent Atmospheric Turbulence Mitigation with Neural Representations
Haoming Cai · Jingxi Chen · Brandon Feng · Weiyun Jiang · Mingyang Xie · Kevin Zhang · Cornelia Fermuller · Yiannis Aloimonos · Ashok Veeraraghavan · Chris Metzler
East Exhibit Hall A-C #1504
{kind=link}
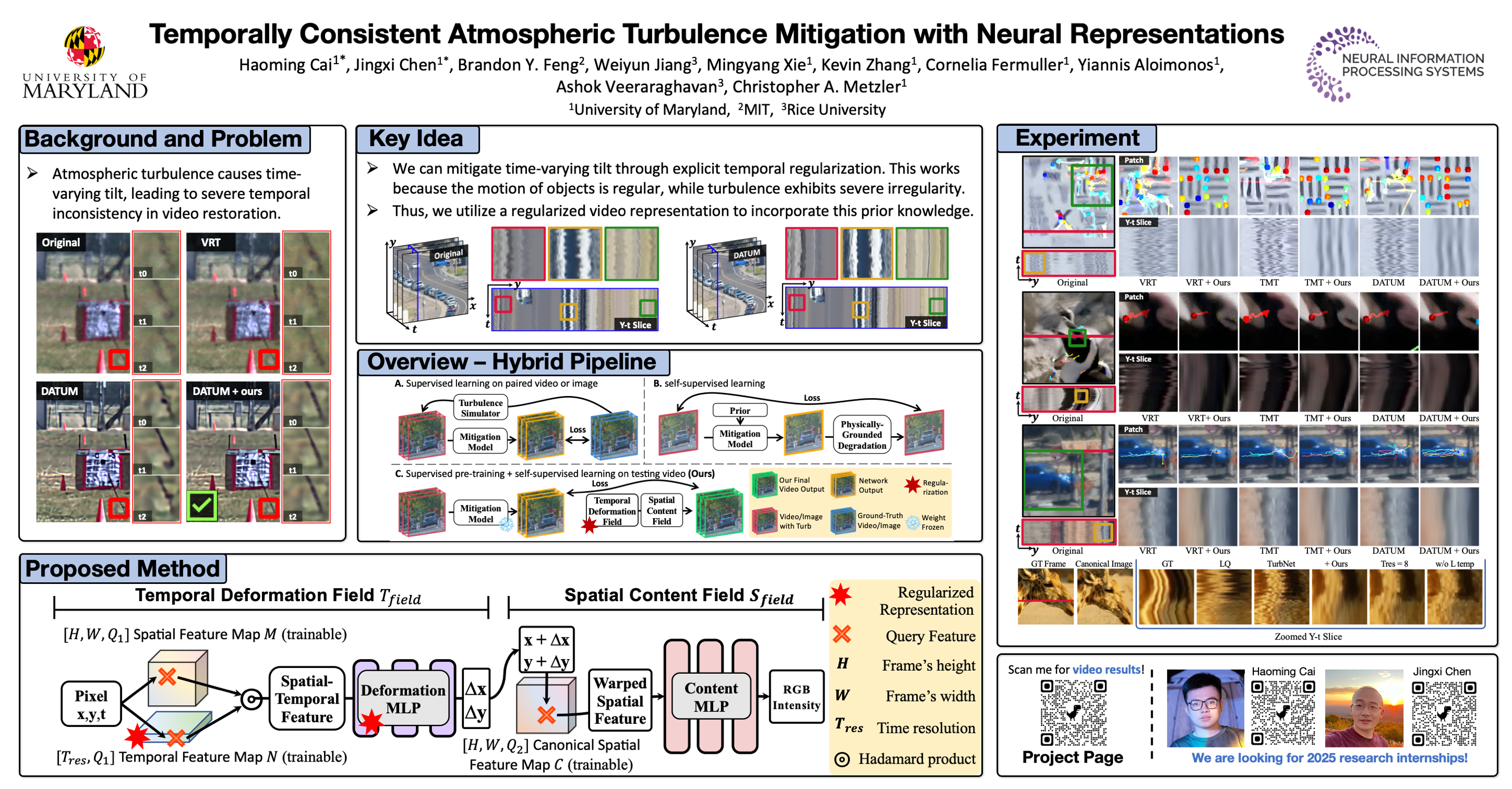
Atmospheric turbulence, caused by random fluctuations in the atmosphere's refractive index, introduces complex spatio-temporal distortions in imagery captured at long range. Video Atmospheric Turbulence Mitigation (ATM) aims to restore videos affected by these distortions. However, existing video ATM methods, both supervised and self-supervised, struggle to maintain temporally consistent mitigation across frames, leading to visually incoherent results. This limitation arises from the stochastic nature of atmospheric turbulence, which varies across space and time. Inspired by the observation that atmospheric turbulence induces high-frequency temporal variations, we propose ConVRT, a novel framework for consistent video restoration through turbulence. ConVRT introduces a neural video representation that explicitly decouples spatial and temporal information into a spatial content field and a temporal deformation field, enabling targeted regularization of the network's temporal representation capability. By leveraging the low-pass filtering properties of the regularized temporal representations, ConVRT effectively mitigates turbulence-induced temporal frequency variations and promotes temporal consistency. Furthermore, our training framework seamlessly integrates supervised pre-training on synthetic turbulence data with self-supervised learning on real-world videos, significantly improving the temporally consistent mitigation of ATM methods on diverse real-world data. More information can be found on our project page: https://convrt-2024.github.io/