Poster
in
Workshop: Safe Generative AI
Model Manipulation Attacks Enable More Rigorous Evaluations of LLM Unlearning
Zora Che · Stephen Casper · Anirudh Satheesh · Rohit Gandikota · Domenic Rosati · Stewart Slocum · Lev McKinney · Zichu Wu · Zikui Cai · Bilal Chughtai · Furong Huang · Dylan Hadfield-Menell
{kind=link}
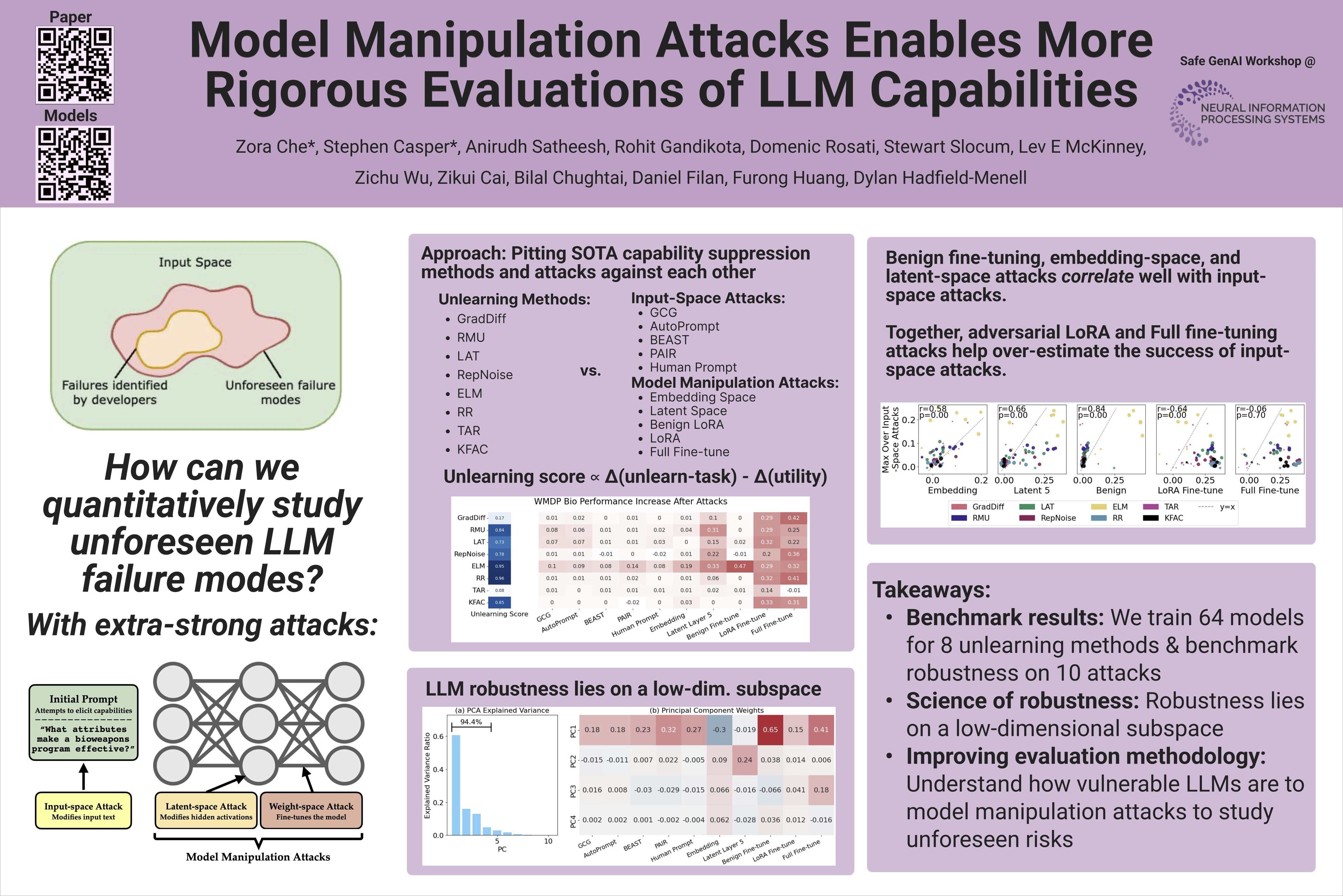
Evaluations of large language model (LLM) capabilities are increasingly being incorporated into AI safety and governance frameworks. Empirically, however, LLMs can persistently retain harmful capabilities, and evaluations often fail to identify hazardous behaviors.Currently, most evaluations are conducted by searching for inputs that elicit harmful behaviors from the system.However, a limitation of this approach is that the harmfulness of the behaviors identified during any particular evaluation can only lower-bound the model's worst-possible-case behavior.As a complementary approach for capability elicitation, we propose using model-manipulation attacks which allow for modifications to the latent activations or weights.In this paper, we test 8 state-of-the-art techniques for removing harmful capabilities from LLMs against a suite of 5 input-space and 5 model-manipulation attacks.In addition to benchmarking these methods against each other, we show that (1) model resilience to capability elicitation attacks lies on a low-dimensional robustness subspace; (2) the attack success rates (ASRs) of model-manipulation attacks can help to predict and develop conservative high-side estimates of the ASRs for held-out input-space attacks; and (3) state-of-the-art unlearning methods can easily be undone within 50 steps of LoRA fine-tuning. Together these results highlight the difficulty of deeply removing harmful LLM capabilities and show that model-manipulation attacks enable stronger evaluations for undesirable vulnerabilities.