Poster
in
Workshop: Safe Generative AI
Integrating Object Detection Modality into Visual Language Model for Enhanced Autonomous Driving Agent
Linfeng He · Yiming Sun · Sihao Wu · Jiaxu Liu · Xiaowei Huang
{kind=link}
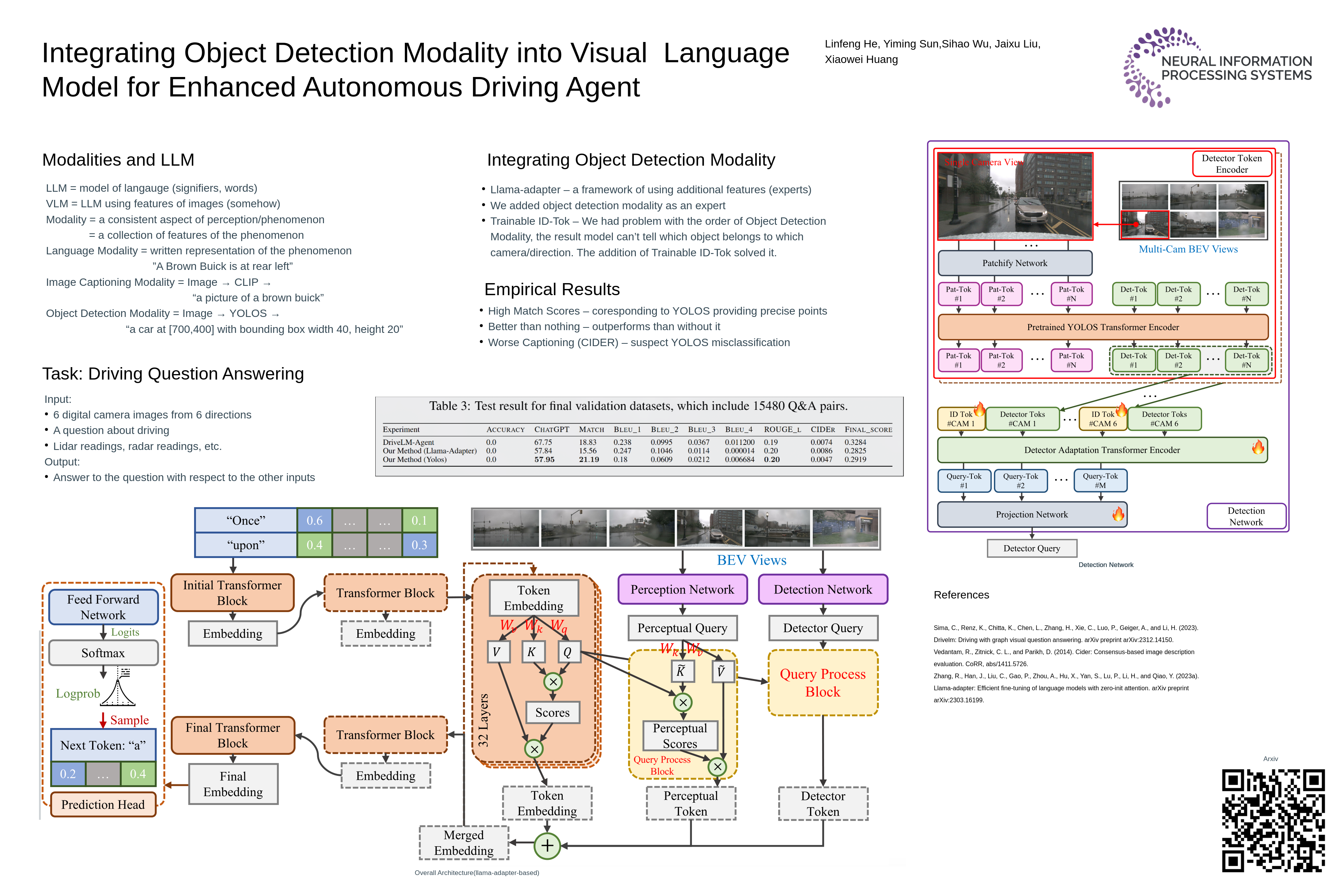
This paper proposes a novel framework for enhancing visual comprehension in autonomous driving systems by integrating visual language models (VLMs) with additional visual perception module specialized in object detection. We extend the Llama-Adapter architecture by incorporating a YOLOS-based detection network alongside the CLIP perception network, addressing limitations in object detection and localization. Our approach introduces camera ID-separators to improve multi-view processing, crucial for comprehensive environmental awareness. Experiments on the DriveLM challenge demonstrate significant improvements over baseline models, with enhanced performance in ChatGPT scores, BLEU scores, and CIDEr metrics. While accuracy metrics show room for improvement, our method represents a promising step towards more capable and interpretable autonomous driving systems. Possible safety enhancement enabled by detection modality is also discussed.