Poster
in
Workshop: Adaptive Foundation Models: Evolving AI for Personalized and Efficient Learning
Effective Text-to-Image Alignment with Quality Aware Pair Ranking
Kunal Singh · Mukund Khanna · Pradeep Moturi
{kind=link}
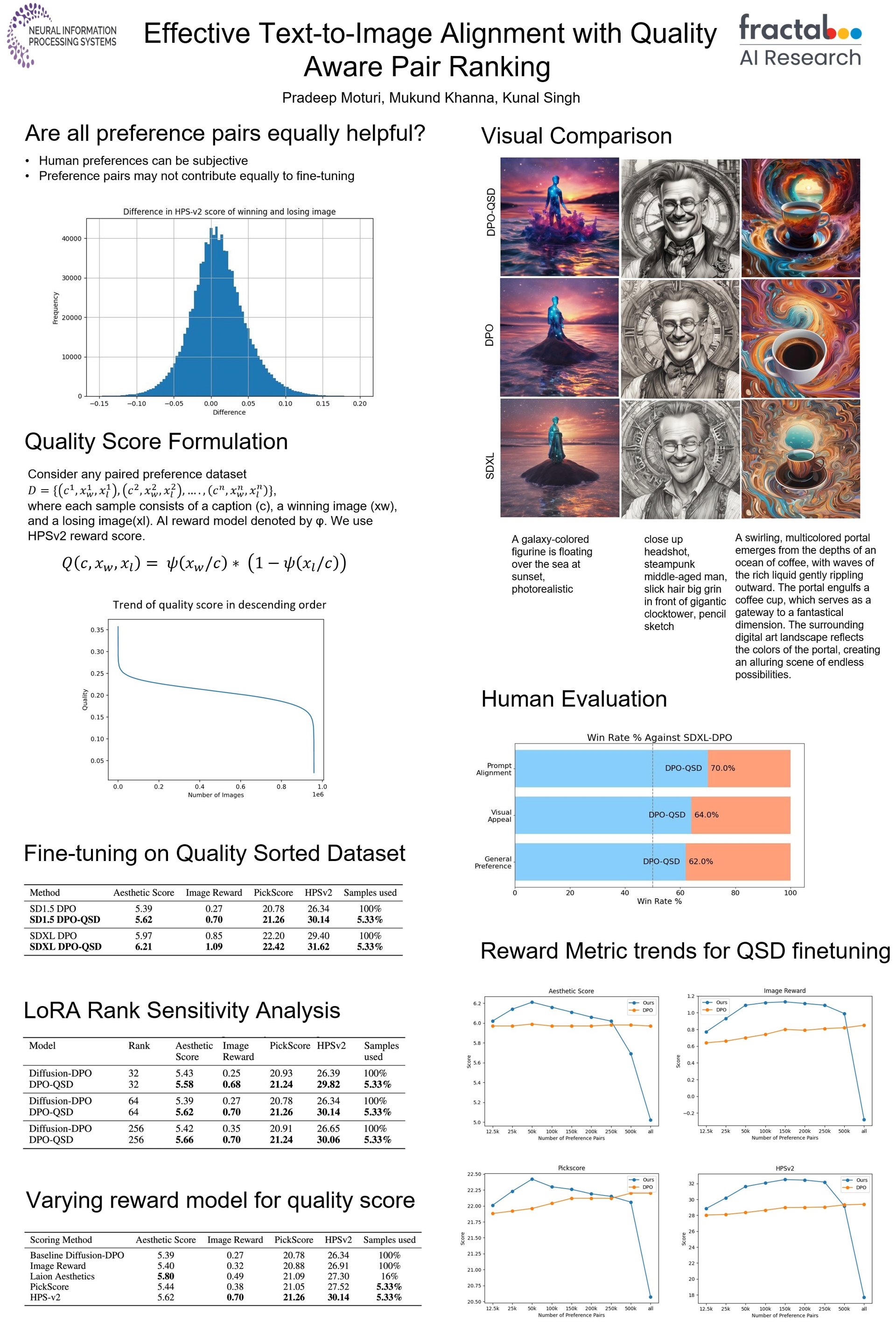
Fine-tuning techniques such as Reinforcement Learning with Human Feedback (RLHF) and Direct Preference Optimization (DPO) allow us to steer Large Language Models (LLMs) to align better with human preferences. Alignment is equally important in text-to-image generation. Recent adoption of DPO, specifically Diffusion-DPO, for Text-to-Image (T2I) diffusion models has proven to work effectively in improving visual appeal and prompt-image alignment. The mentioned works fine-tune on Pick-a-Pic dataset, consisting of approximately one million image preference pairs, collected via crowdsourcing at scale. However, do all preference pairs contribute equally to alignment fine-tuning? Preferences can be subjective at times and may not always translate into effectively aligning the model. In this work, we investigate the above-mentioned question. We develop a quality metric to rank image preference pairs and achieve effective Diffusion-DPO-based alignment fine-tuning.We show that the SD-1.5 and SDXL models fine-tuned using the top 5.33\% of the data perform better both quantitatively and qualitatively than the models fine-tuned on the full dataset. The code is available at https://anonymous.4open.science/r/DPO-QSD-28D7/README.md